
基于多种群遗传优化LSSVM 的中长期负荷预测方法
2022-06-29 06:08胡娱欧王佩雯
电子设计工程 2022年12期
韩 亮,胡娱欧,张 涛,张 晶,罗 异,王佩雯
(1.国家电网公司华北分部,北京 100053;2.北京清能互联科技有限公司,北京 100084)
中长期负荷预测是电网公司进行电网规划以及建设投资的重要前提和依据,准确的预测结果对保障电力系统经济和社会效益意义重大[1]。随着我国经济进入新常态,增速逐步放缓、产业结构不断优化,负荷受经济等影响更加显著,其非线性特征愈加明显,给负荷预测工作带来更大挑战[2-3]。
国内外中长期负荷预测方法包括传统方法、智能方法以及组合预测方法,传统方法预测精度依赖于负荷本身变化规律,难以描述负荷复杂的非线性特征,进而智能方法及组合方法得到更广泛的研究与应用[4]。文献[5]采用模拟退火算法对支持向量机模型参数进行优化,相比传统方法其预测准确率提升明显,但该方法未考虑负荷以外的其他影响因素。文献[6]以部分经济指标为影响因素,以支持向量机为预测核心模型,利用粒子群算法对模型参数进行优化,取得了较高的预测精度。文献[7]采用多类影响因素指标,在主成分分析降维后采用标准支持向量机模型预测,精度较降维前得到提升。文献[8]针对当前复杂的非线性宏观经济形势,采用自适应粒子群算法改进的最小二乘支持向量机用电量预测模型,相比一般粒子群算法其寻优结果更佳。以上方法相比传统方法预测精度提升明显,但面对经济新常态下中长期负荷高度非线性、不确定性的特征,单一模型很难保证各场景下都能获得满意的预测结果,组合预测可对各单一预测模型的有用信息进行优化组合,比单一预测模型更系统全面,应用场景更广[9-10]。文献[11]将人工蜂群算法与组合预测模型相结合,对线性回归等5 个单模型权重进行优化求解,预测精度相对单模型提升明显。文献[12]对支持向量机及多元回归分析模型采用拟合方差最小化为目标函数,通过求解该非线性规划问题得到权系数组合,应用年最大降温负荷进行测试验证,结果满足实际工程需求。
上述组合方法根据各模型历史预测精度分配最优权重,但模型间机理各异、同一模型在不同场景下其预测误差具有一定随机性,且各模型在采用不同样本预测同一指标时预测值与实际值偏差规律难寻,采用按历史预测误差进行权重分配的组合方法难以保证在新的预测场景延续较好的预测效果。考虑到单一模型在采用相似训练样本及输入时预测结果相近,以及各模型在采用相同样本及相似输入时预测结果分布规律相近,该文通过关联各单一模型历史预测结果组合相似性且兼顾模型参数优化,提出一种基于多种群遗传算法优化最小二乘支持向量机参数的组合预测方法,选取在考虑宏观经济等因素影响下应用较多的模型作为单模型,以全社会用电量为负荷预测对象,采用灰色关联分析进行影响因素筛选及各模型相似预测组筛选,将各模型一次预测组合与实际值作为输入与输出,采用最小二乘支持向量机为二次组合预测核心模型,通过多种群遗传算法提升模型参数寻优的可靠性、稳定性,通过实证分析证明该方法在中长期负荷预测中的有效性与实用性。
1 影响因素及相似预测组筛选
1.1 灰色关联分析建模
灰色关联分析根据不同序列曲线几何形状相似度衡量序列间联系紧密程度,可作为各序列间相互影响关系强弱量化指标[13]。
设参考对象序列为x0={x0(1),x0(2),…,x0(n)},比较序列为xi={xi(1),xi(2),…,xi(n)},i=1,2,…,m,m代表用于比较的评价对象个数,n代表序列维数。
将序列x0、xi按式(1)进行归一化处理,得到新的序列
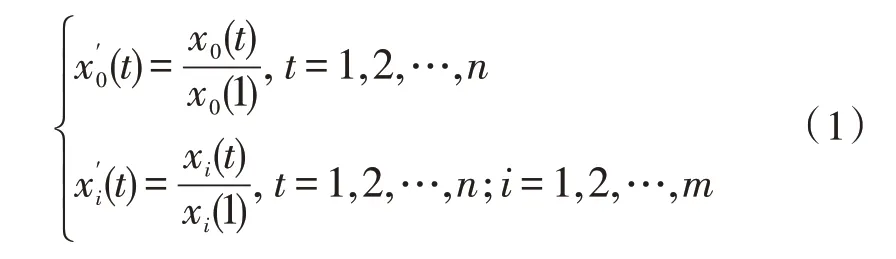
计算新序列间灰色关联系数如下:
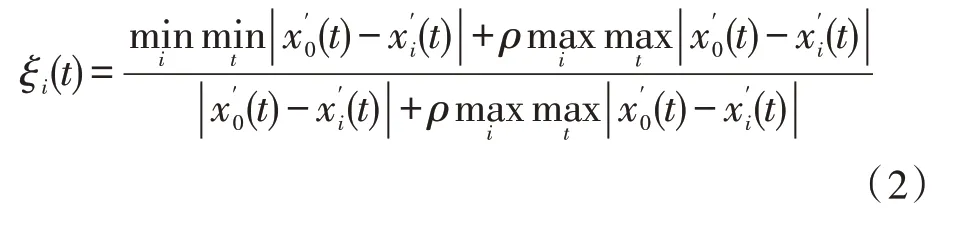
式中,ξi(t)为序列对序列在 第t个维 度指标上的关联系数,ρ为分辨系数,取值范围为[0,1],其值越大分辨率越大,值越小分辨率越小,通常ρ取值0.5。对各维度对应关联系数取平均数,得到原始序列x0与第i个评价对象xi之间的关联度为:
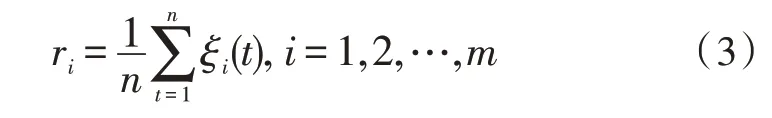
ri越大,表明该评价对象对参考对象影响程度越大或与参考对象相似度越高。
1.2 纵向模糊加权建模
历史各影响因素对负荷的影响程度往往随年份呈“近大远小”的趋势,采用纵向模糊加权法对灰色关联系数根据加权系数进行求和[14-16]。加权系数表示为w(t),t=1,2,…,n。由此得到灰色加权关联度计算公式为:
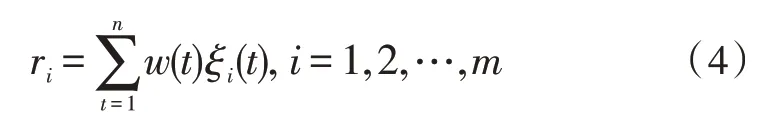
w(t)计算方法如下:
1)不同年份t1与t2间的模糊互补优先关系矩阵F=(ft1t2)n×n,ft1t2表示年份t1与t2间重要程度相对关系,且ft1t2+ft2t1=1,t1,t2=1,2,…,n。
当t1>t2时,说明年份t1比t2数据重要程度更高,取ft1t2=1;反之,当t1<t2时,取ft1t2=0;当t1=t2时,表示年份t1与t2数据重要程度相同,取ft1t2=0.5。
2)在F=(ft1t2)n×n基础上得到模糊一致矩阵S=(st1t2)n×n,其中:
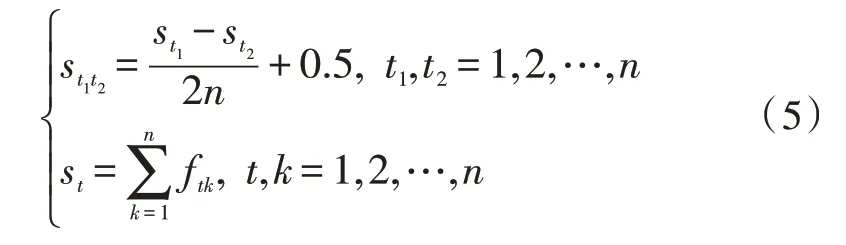
3)计算权值w(t):
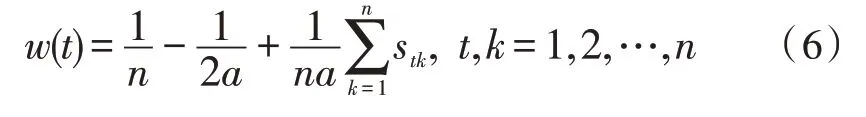
式中,a≥(n-1)/2,一般取a=(n-1)/2。
2 最小二乘支持向量机建模
最小二乘支持向量机(LSSVM)是在标准支持向量机(Support Vector Machine,SVM)基础上的进一步扩展,通过用等式约束替换SVM 中的不等式约束,将SVM 中二次规划问题转化为线性方程组求解问题,大大简化原有复杂运算过程,在处理非线性、小样本数据时优势明显,适用于中长期负荷预测场景。
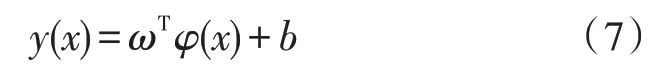
式中,ω为权值向量,b为偏置,用平方误差损失函数代替Vapnik 的不敏感损失函数,建立优化模型如下:
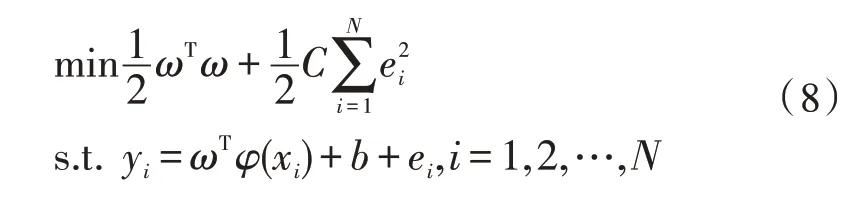
式中,ei为样本误差项,C是惩罚系数。引入拉格朗日函数:
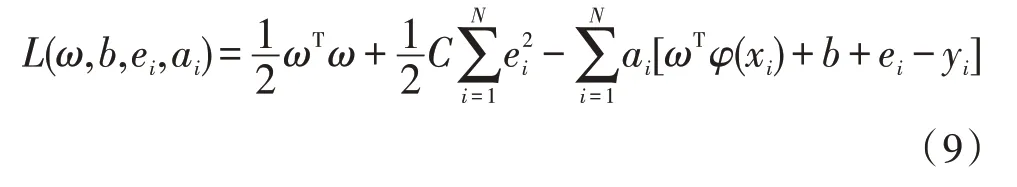
式中,ai为拉格朗日乘子。对式(9)各个自变量求偏导并取0,得到:
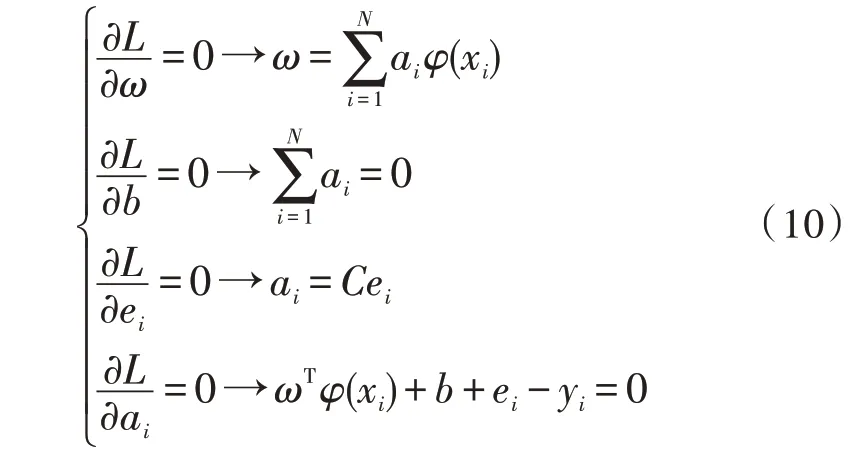
消去ei和ω,将上式转化为以下矩阵运算形式:

式中,Ω=φT(xi)φ(xi),EN=[1,1,…,1]T,a=[a1,a2,…,aN],y=[y1,y2,…,yN]T,求解得到:
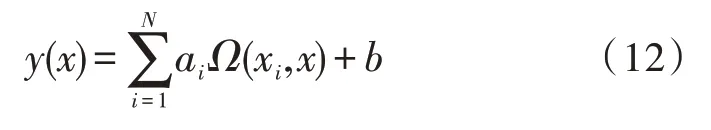
式中,Ω(xi,x)为核函数,选取径向基函数为核函数,其表达式如下:

LSSVM 模型预测精度主要受核函数参数σ2和惩罚系数C影响,对于一定样本集,选取合适的σ2和C是充分发挥LSSVM 模型优势、增强其适用性的关键。
3 多种群遗传优化LSSVM 组合预测建模
3.1 多种群遗传算法
遗传算法通过模拟生物自然选择与进化机制寻找最优解,具有高度并行、随机及自适应特征。其中多种群遗传算法(Multi Population Genetic Algorithm,MPGA)采用多种群并行进化思想,同时兼顾算法全局搜索及局部搜索,计算结果对遗传控制参数敏感性大大降低,收敛速度快,能显著克服标准遗传算法未成熟收敛问题,适合于复杂问题的优化。MPGA关键流程如图1 所示。
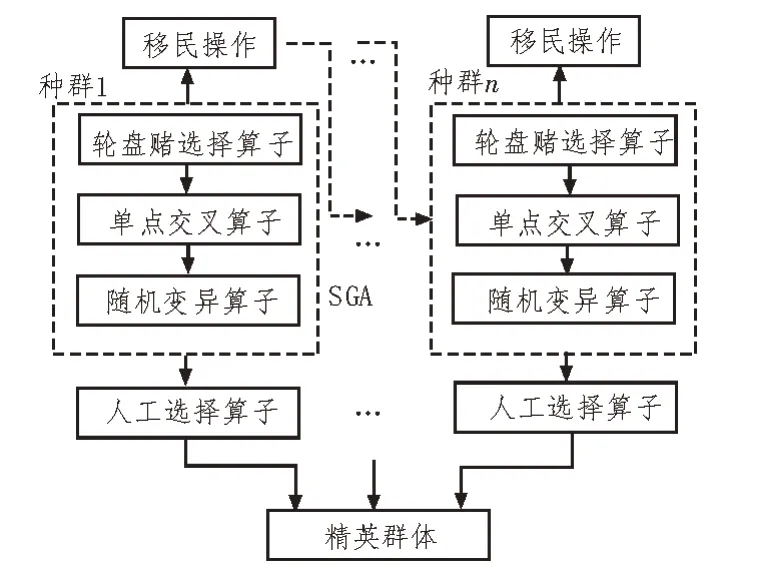
图1 MPGA关键流程
3.2 模型参数寻优及组合预测流程设计
基于MPGA 对LSSVM 模型参数寻优过程如下:
1)种群初始化
采用实数编码方式,个体为一实数串,由σ2和C两个参数组成。设定搜索区间、种群规模及个体数,随机得到初始种群。
2)确定适应度函数
将样本集划分为训练集及验证集,适应度函数取训练集及验证集平均绝对预测误差eMAPE。计算公式如下:
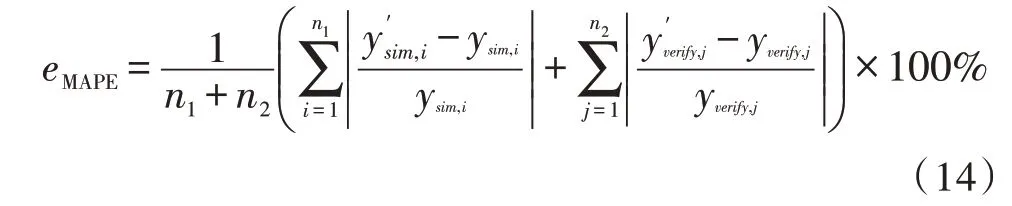
式中,n1为训练集个数,n2为验证集个数;表示第i个训练样本输入对应的预测值,ysim,i表示该训练样本实际值;y′verify,j表示第j个验证样本输入对应的预测值,yverify,j表示该验证样本实际值。
3)人工选择操作
基于适应度比例法进行个体选择,设每个个体i的选择概率为pi,计算公式如下:
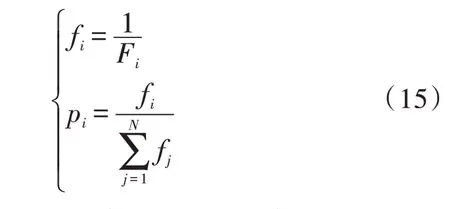
式中,N表示种群个体数,Fi为个体i的适应度值,其为个体i对应LSSVM 模型参数σ2和C组合下,根据样本训练集及验证集进行预测测试得到的平均绝对预测误差百分数eMAPE。
4)单点交叉操作
采用实数交叉法,对第k个染色体hk和第l个染色体hl在第j位进行交叉操作。
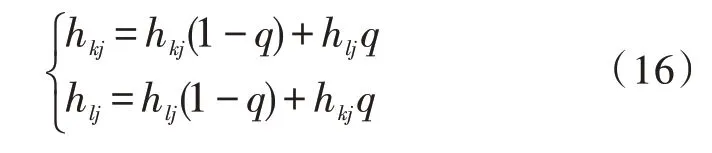
5)随机变异操作
选取第i个个体的第j个基因rij进行变异,公式如下:

式中,rmax为基因rij上界;rmin为基因rij下界;o为[0,1]间的随机数;z(g)计算公式如下:

式中,r2是[0,1]间的随机数;g为当前迭代次数;Cmax是最大进化次数。
6)移民操作和人工选择算子
移民操作实现群体间个体协同进化,用源种群群体最优自适应度个体替换目标种群群体最差适应度个体,人工选择算子对各群体各代最优个体进行选择及保存,精英群体不进行选择、交叉、变异等遗传操作,保证进化过程中各种群中产生的最优个体不被破坏和丢失。
将目前考虑多因素影响时应用较好的主成分回归分析、偏最小二乘回归分析及LSSVM 3 种模型作为一次预测所用单一预测模型,预测各年份用电量时采用相同样本及输入,得到历史各年份对应的预测值组合,并将各预测值组合与对应的实际值作为总体样本。为减小各历史预测组差异对模型参数寻优的影响,采用灰色关联分析选择与待预测输入组合相似的历史预测组作为样本,划分训练集及验证集,基于MPGA 寻求使LSSVM 在训练集及验证集上实现最优预测结果的σ2和C,以此作为待预测组预测模型参数,以待预测组合作为模型输入,得到组合预测结果,方法整体流程如图2 所示。

图2 基于MPGA优化LSSVM的组合预测流程
4 实证分析
以北京统计年鉴公布的北京地区2001~2019 年全社会年用电量数据作为中长期负荷指标,以涵盖工业、建筑业、全社会固定资产投资、国民经济、人口、人民生活及能源七方面关键指标作为影响因素。
4.1 年用电量影响因素分析
将规模以上工业总产值、建筑业总产值、全社会固定资产投资、地区生产总值、第一产业占比、第二产业占比、第三产业占比、年末常住人口、居民人均可支配收入、居民人均消费支出、能源消费总量、万元GDP 能耗这12 个待筛选的影响因素分别用X1到X12表示,全社会年用电量用Y表示,各影响因素对年用电量加权灰色关联度如表1 所示。选取关联度最大的前4 个因素为主要影响因子,表明能源消费总量与年用电量关系最紧密,体现出工业发展对能源需求量变化是电量变化的主导影响因素,其次是城市人口规模以及近年来第三产业的持续发展和居民消费水平的普遍提高影响了全社会年用电量的发展,结果与实际相符。
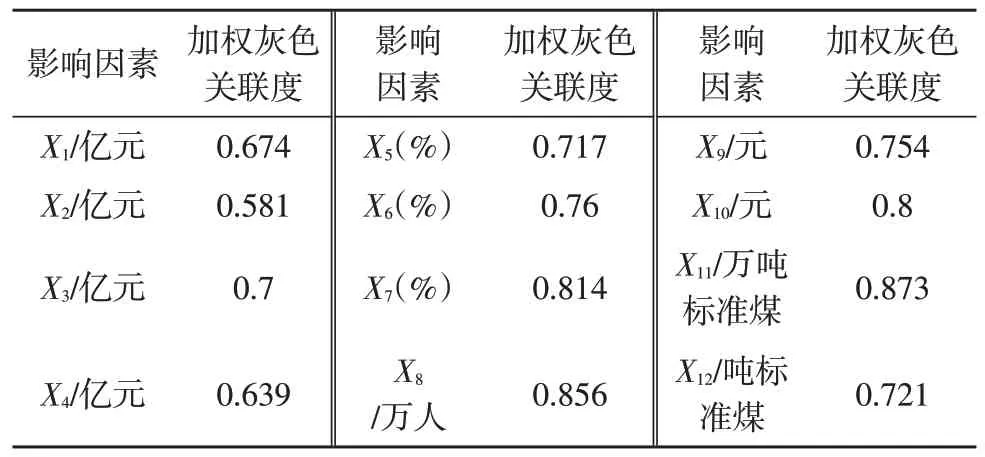
表1 加权灰色关联度
4.2 单模型一次预测
以能源消费总量、年末常住人口、第三产业占比以及居民人均消费支出4 个指标为输入,年用电量为预测,采用主成分回归分析、偏最小二乘回归分析及LSSVM 分别预测各年份年电量,并将其他年份样本作为训练集,预测不同年份时仅有一个训练样本存在差异,因此确保了较小的样本集差异度。LSSVM 模型参数为:C=6 080,σ2=150。各年份预测年电量与实际值的对比如图3 所示。

图3 各单模型一次预测结果
4.3 MPGA优化LSSVM二次组合预测
将3 种模型一次预测结果作为二次组合预测模型输入,实际年用电量作为预测输出,得到多组样本集。计算待输入预测组与样本中其他预测组关联度,得到样本各预测组与其关联度,如表2 所示。
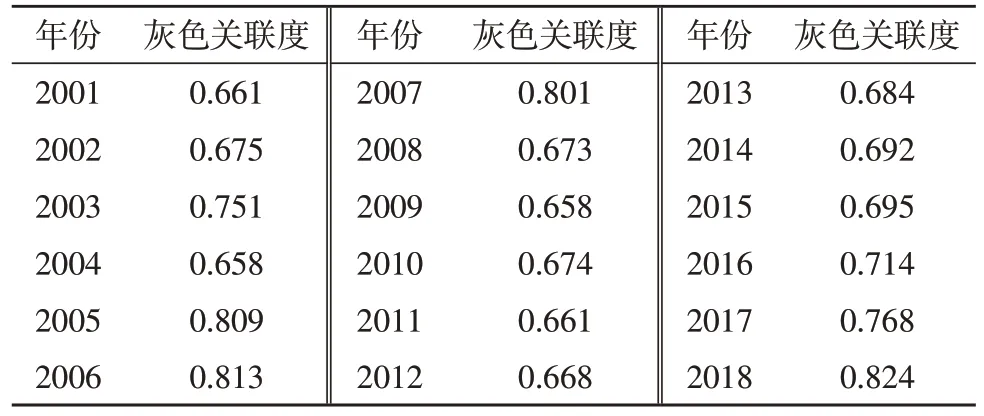
表2 各模型预测组灰色关联度
选取关联度最高的前10 个样本即2013~2018 年每年对应一次预测组为相似预测组。以2018 年预测组为验证集,其他组为训练集,2019年为测试集,分别采用SGA 与MPGA 对LSSVM 模型参数σ2、C进行优化,参数如下:进化代数均取300,单种群个体数为80;SGA 交叉概率为0.2,变异概率为0.02;MPGA 种群数为5,交叉概率变化区间为[0.2,0.6],变异概率区间为[0.001,0.05];σ2和C搜索区间为[0.000 1,10 000]。
算法最优个体适应度收敛曲线如图4 所示,结果如表3 所示。各代最优个体适应度为在各代中最优个体对应σ2和C下样本集及验证集平均绝对预测误差百分数(Mean Absolute Percentage Error,MAPE)。可见MPGA 优化LSSVM 模型参数方式相比SGA 优化LSSVM 模型参数方式在训练集、验证集及测试集上平均预测误差均更小、寻优效果更佳、模型适应性更强。
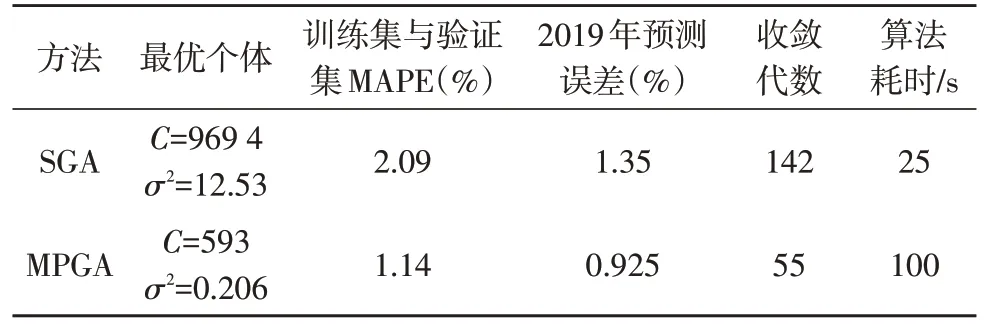
表3 SGA与MPGA两种算法结果对比

图4 SGA与MPGA两种算法最优个体适应度收敛曲线
对各年份分别进行二次组合预测,预测结果如图5 所示。
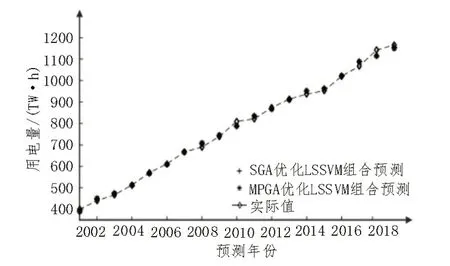
图5 两种组合预测模型预测结果对比
各模型预测MAPE 如表4 所示。结果表明该文所提方法相较于各单一预测模型取得了更好的预测效果。此外,通过采用与常规参数搜索优化算法对比可看出,所采用MPGA 算法搜索范围更大,组合预测结果更稳定,在解决LSSVM 模型关键参数σ2和C选择问题上优势明显,可有效提升其在中长期预测中的实用性。

表4 平均绝对预测误差(MAPE)统计
5 结束语
经济新常态下宏观经济环境使中长期负荷随机性、不确定性进一步提升,增加了预测工作难度。考虑到单一预测模型预测精度提升空间有限,该文提出一种考虑各模型历史预测组合相似度的组合预测方法,针对LSSVM 具有对小样本、非线性数据高效处理能力的同时又面临模型参数难以选择的难题,采用MPGA 算法进行模型参数寻优,实证验证得到如下结论:
1)MPGA 算法兼顾全局搜索及局部搜索的优势,相较于标准遗传算法等常规搜索算法能更有效克服未成熟收敛的问题,收敛代数更少且模型寻优效果更佳,可作为有效的预测模型寻优算法,提升了预测精度,同时增强了模型稳定性。
2)所提出的考虑单模型历史预测组相似样本选取及MPGA 优化LSSVM 模型参数的组合方法,其预测精度相较于单一预测模型及常规搜索算法寻优的组合预测模型更好,能更有效提升LSSVM 这一核心智能预测模型在中长期负荷预测中的优势及实用性,对中长期负荷预测工作具有一定的参考价值。
猜你喜欢
电力设备管理(2022年8期)2022-11-25
计算机仿真(2022年8期)2022-09-28
纺织标准与质量(2022年2期)2022-07-12
煤气与热力(2022年4期)2022-05-23
煤气与热力(2022年2期)2022-03-09
小资CHIC!ELEGANCE(2019年5期)2019-04-30
当代旅游(2016年10期)2017-04-17
财经理论与实践(2015年2期)2015-04-16
