
配网工程中数据挖掘模型的模糊聚类算法研究
2022-06-29 06:08潘行健林子滟
电子设计工程 2022年12期
顾 虹,杨 波,张 璐,潘行健,林子滟
(国网浙江德清县供电有限公司,浙江湖州 313200)
配网工程是构建电网的重要部分,也是直接与广大用户相连接的末端服务管理部分[1]。合理利用内部审计来强化配网工程项目精益化管理,是规范生产经营管理的主要方式之一[2]。而随着电网审计管理精度的提升,传统模式已无法满足当前配网工程数据处理控制的需求,故需及时更新数据管理技术以提高工作效率[3]。
模糊聚类算法是数据挖掘模型中的常用算法,其中使用最为广泛的为k 均值聚类(k-means)算法[4]与模糊c 均值法[5-6],二者主要通过对比不同集群的相似度来实现数据分析。当前,大部分数据挖掘聚类算法均是基于对象间的差异函数来进行聚类的[7-8]。然而,若考虑研究对象的属性变量再进行聚类,可获得更多的聚类信息。
可同时构造被指定对象与其属性变量到同质块最优划分的聚类算法,这种聚类算法被称为块聚类。其数据处理过程用来构造一个数据矩阵,其中I是行中n个对象的集合,J是列中m个属性变量的集合。然后将集合I分成s簇,再把集合J分成t簇。
块聚类算法的原理是通过重新排列s×t同质块中的行和列,找到数据矩阵的概要。研究员Duffy 与Quiroz[9]首次提出了该种聚类算法方式,并将其命名为块聚类;而Govaert 及Nadif[10]在此基础上设计了一种基于块混合模型的块分类期望最大化(Expection Maximization,EM)算法(块CEM);之后又研究了基于模糊c 均值划分的块模糊c 均值法(块FCM)[11]。文中基于模糊k 均值方法提出了块模糊k 值(块FKM)算法。
1 块模糊聚类算法
聚类分析中的一项重要技术是聚类混合[12],在考虑块CEM 算法之前,需先引入一个块混合模型。假设数据集X=(x1,…,xn)是由混合分布生成,则:
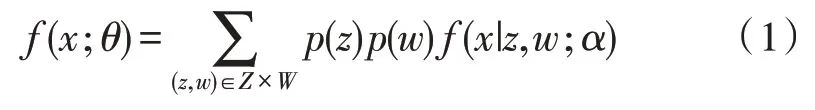
其中,Z是集合I到s簇的划分,W是集合J到t簇的划分。α是概率密度函数的一个参数,其目标是找到一个最优的分区对(z,w)。设xi是从第k个簇抽样的向量,则其概率密度函数是确定的。同时由于zi与wj固定后的随机变量是独立的,因此样本X的概率密度函数可表示为:

从而获得块混合模型为:
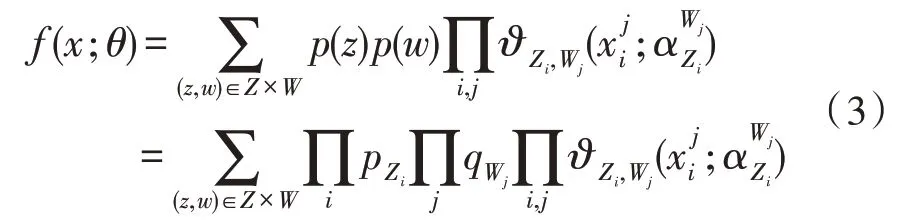
由z、w、可生成一个数据集X。为了同时处理数据与属性变量的划分,需要完成对数似然准则f(X;θ)的显性表达式。所以使用分类似然法[13],通过最大化以下分类对数似然函数提出了区块CEM:

对于最大化分类对数似然函数Lc(z,w;θ),首先需确定w和q的参数值,然后再确定参数z与p。当w及q固定时,对数似然函数Lc(z,w;θ)可表示为:
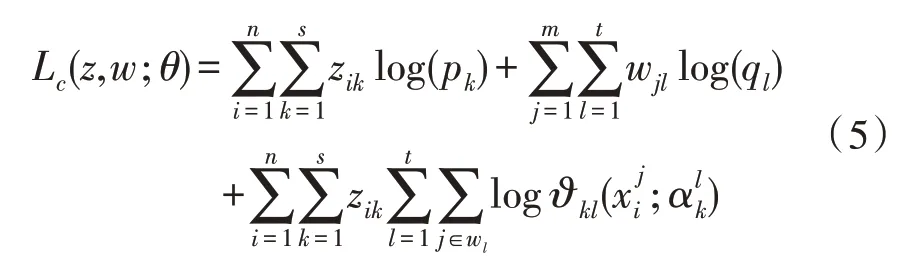
求解z固定的完全最大似然函数Lc(z,w;θ)就相当于最大化Lc(z,θ|w),故可通过应用于混合模型的CEM 算法来实现。算法的具体步骤如下:
1)令r=1,2 ≤s≤n,2 ≤t≤m,并给出初始值z(0)、w(0)和θ(0)。
2)由z(r)、w(r)、θ(r)计算z(r+1)、w(r+1)、θ(r+1):
①从z(r)、p(r)及α(r)中得到数据(u1,…,un),采用CEM 计算z(r+1)、p(r+1)和α(r);
②从w(r)、q(r)、α(r)中获取数据(v1,…,vm),且使用CEM 计算w(r+1)、q(r+1)和α(r+1)。
3)重复步骤2),直至数据收敛。
2 改进数据挖掘模型模糊聚类算法
2.1 块模糊c均值法
自从Ruspini[14]在聚类中使用模糊c 均值划分以来,模糊聚类得到了广泛的研究与应用。基于块混合模型及模糊c 均值划分,Govaert 与Nadif 提出了块FCM 作为一种新的块聚类方法,块混合模型可以表示为:

其中,θ=(p,q,α)。而Hathaway[15]对EM 做出了另一种解释:

式(7)中,c与d分别表示观测值及属性的模糊划分。Govaert 和Nadif 扩展了上述函数,提出了具有以下目标函数的块模糊c 均值方法(块FCM):

假设概率密度函数ϑkl为一个充分统计的实值函数所定义的量[15]。则式(8)可表示为:

当d和q固定时,有:

固定d与q后,最大化Fc(c,d,θ) 等效于最大化Fc(c,θ|d)。则该准则的最大化可被视为与经典混合模型相关联对数似然函数最大化的EM算法,当c和p固定时,同样可获得:

Fc(d,θ|c)的最大化可视为应用于经典混合模型的EM 算法,因此能将块FCM 算法总结如下:
1)令r=1,2 ≤s≤n,2 ≤t≤m,并给出初始值c、d和θ。
2)由c(r)、d(r)、θ(r))计算c(r+1)、d(r+1)、θ(r+1):
①从c(r)、p(r)与α(r)中获取数据(u1,…,un),并使用EM 计算c(r+1)、p(r+1)及α(r+0.5);
②从d(r)、q(r)、α(r+0.5)中得到数据(v1,…,vm),再使用EM 计算d(r+1)、q(r+1)和α(r+0.5)。
3)重复步骤2),直至数据收敛。
2.2 块模糊k值法
令Y={y1,…,yI}为一组待分类数据,使每个数据均由一组A1,…,AJ属性进行定义。而属性Aj描述了由表示的值域,其中Lj是属性Aj的类别数。假设vk=(vk1,…,vkJ)是第k个星系团的质心,每个分量vkj=(vkj1,…,vkjLj),k=1,…,K,j=1,…,J。则Sadjad 使用了以下公式来匹配相异测度:
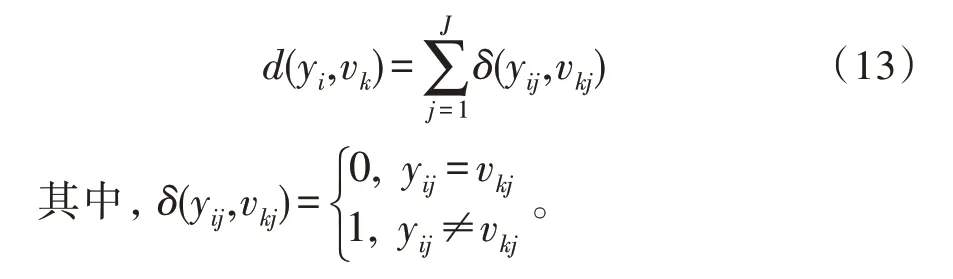

随后,引入模糊k 值模式分块聚类的概念,并提出块FKM 模型。块FKM 聚类算法旨在最小化以下目标函数:

式(15)中,若j=1,…,k,有;而当t=1,…,l,则有。X是具有n个观测值和d种属性的数据组,Y则是X的转置。
对于m1>1、m2>1、μij∈[0,1]、σij∈[0,1],块FKM的更新公式如下:

块FKM 算法步骤如下:
1)令r=1,ε>0,2 ≤k≤n,2 ≤l≤d,且给出初始值μ(0)、σ(0);
2)由μ(r-1)、σ(r-1)、v(r-1)和w(r-1)计算出μ(r)、σ(r)、v(r)和w(r);
3)比较μ(r)、σ(r)和μ(r-1)、σ(r-1),若‖μ(r)-μ(r-1)‖+‖σ(r)-σ(r-1)‖<ε,则停止;否则,令r=r+1,并返回步骤2)。
3 算法实验结果
3.1 案例一
利用真实工程数据给出的部分数值及数据集进行实验,原始数据集具有10 个观察值及9 个属性,具体如图1 所示。块FKM 与块FCM 均将数据集分类为如图2 所示的数据集,且分块结果一致。
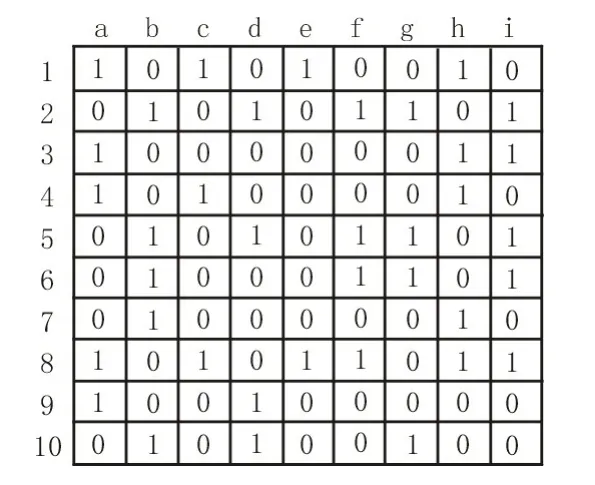
图1 原始数据集

图2 块变换修正后的数据集
经过计算迭代次数的平均值,发现FKM 区块的平均净指数约为5 倍,而FCM 区块的平均净指数超过20 倍。对比可知,未经模糊算法优化的CEM 分类值效率更低。因此,所提出的改进k 值块模糊算法FKM 比c 值块模糊算法FCM 更节省时间。
3.2 案例二
为比较FKM 块与FCM 块在进行类别区分时的准确性,对配网工程成本数据进行了简单的分类。即将其分为直接材料成本、直接人工成本、变动制造费用成本及固定制造费用成本。将101 个成本实例代入模型进行聚类,再将聚类数固定为4,来分别实现这两个算法。为了对比分析文中提出的改进k 均值块模糊算法的效果,采用了2 类和4 类两种不同属性的聚类数。
表1 列出了配网工程承包数据集属性聚类结果,并解释了两种算法对属性2 及属性4 的聚类结果。从对成本类别的聚类结果可以看出,块FKM 的精度显著高于块FCM。且在实例的聚类中,属性的聚类数越大,特征越稳定[16-17]。

表1 配网工程成本数据集属性聚类结果
4 结束语
文中提出了改进k 均值块模糊算法FKM,其可同时构造聚类对象并进行属性变量到同构块的最优划分。将所提出的区块FKM 与区块FCM 的数值数据集和真实数据集进行了比较。实验与对比分析结果表明,该方法具有较好的准确性及有效性。
在配网工程中深度应用海量数据并构建多种类别的数据高效处理模型时,仍需注意以下几个方面:1)动态获取主要数据,建立数据信息变化感知机制;2)基于历年工程海量数据的信息挖掘结果,深度分析数据走向趋势;3)综合利用数据感知模块,构建新型数据挖掘模糊聚类体系。最终融合嵌入投资预算编报链路打造“流程闭环、共建共享”的基建工程内控机制,从而创新拓展建设成果,构建配网工程数据挖掘体系应用。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
当代陕西(2021年1期)2021-02-01
考试与评价·高二版(2020年3期)2020-09-10
华人时刊(2019年15期)2019-11-26
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
发明与创新·中学生(2017年5期)2017-05-12
