
基于QHAdam梯度优化算法的最小二乘逆时偏移
2022-07-05 11:11王绍文宋鹏谭军解闯赵波毛士博
地球物理学报 2022年7期
王绍文, 宋鹏,2,3*, 谭军,2,3, 解闯, 赵波,2,3, 毛士博
1 中国海洋大学海洋地球科学学院, 青岛 266100 2 青岛海洋科学与技术试点国家实验室, 海洋矿产资源评价与探测技术功能实验室, 青岛 266100 3 中国海洋大学海底科学与探测技术教育部重点实验室, 青岛 266100
0 引言
最小二乘逆时偏移(Least-Squares Reverse Time Migration, LSRTM)首先由Dai等(2010, 2011)提出,其是一种基于最小二乘反演框架下的高精度成像方法.相对逆时偏移而言,LSRTM可以有效压制成像剖面中的低频噪声,成像结果趋于实际地层反射系数,因此近年来,LSRTM一直是地球物理领域的研究热点.
经过10余年的发展,LSRTM得到长足的进步.Yao和Yakubowicz(2012, 2016)实现了基于矩阵的LSRTM和非线性的LSRTM,通过实验证明了其有效性.Dong等(2012)以及郭振波和李振春(2014)通过实验证明了LSRTM是一种真振幅成像方法,其成像结果具有明确的物理意义.Zhang等(2013b)建立互相关目标泛函,通过相位进行匹配,得到了稳定的LSRTM.Zhang等(2013a)、黄建平等(2014)将LSRTM应用于地表复杂的模型当中,得到了高精度的成像结果.李振春等(2014)将黏声介质的成像引入到LSRTM当中,避免了反Q偏移方法存在的不稳定问题,验证了其相较于常规LSRTM而言更加符合实际情况,具有更高的保幅性.Tan和Huang(2014)将计算得到的成像结果反推至背景速度模型中,不断更新背景速度模型,提高了LSRTM对背景速度模型的稳定性.刘玉金和李振春(2015)提出了扩展成像条件下的LSRTM方法,其能够在速度模型不准确的情况下获得更高的成像分辨率.刘学建和刘伊克(2016)发展了基于多次波的LSRTM成像方法,获得了更好的地下照明和覆盖效果.李庆洋等(2017)考虑到实际情况中子波空变的特征,为了避免子波的影响及降低地震数据噪声对LSRTM的影响,将Student′s t分布推广到不依赖子波的LSRTM中.Yang等(2019)利用多阶Born近似,补充线性化正演中缺失的振幅信息,降低了LSRTM的敏感程度,增强了垂直构造的成像结果.方修政等(2018)通过逆散射成像条件对梯度进行预处理,提升了LSRTM收敛效率和成像精度.黄金强和李振春(2019)发展了TTI介质中纯qP波叠前平面波LSRTM成像方法,有效提升了反演成像的效率和反演算法的鲁棒性,同时降低了LSRTM对模型参数的依赖性.郭旭等(2019)研究了基于一阶速度-应力方程的VTI介质LSRTM方法,并对速度等参数对成像结果的敏感性做出了细致的分析.巩向博等(2019)将稀疏约束引入LSRTM中,提升了小尺度散射体的成像精度.Mu等(2021)利用分离的绕射波进行LSRTM,对断层-岩溶地区进行了高精度成像,为此地区的高精度解释建立了基础.周东红等(2020)提出了适用于起伏地表的差分网格,并将其应用于LSRTM中,有效压制了成像的部分串扰噪声.刘玉敏等(2021)发展了基于衰减补偿的黏弹性波LSRTM方法,其相较于弹性波LSRTM具有更快的收敛速度和更高的成像精度.王晓毅等(2021)利用Poynting矢量对梯度算子进行改造,得到了成像噪声更小、收敛速率更快的LSRTM算法.胡勇等(2021)利用LSRTM在时频域实现了对深部构造的高精度成像.
当前的LSRTM通常采用梯度类算法迭代求解,往往需要几十次甚至上百次的迭代处理,其在整个迭代反演流程中尚存在如下问题:首先,当前采用的各种梯度求解算法,如共轭梯度(Polyak, 1969)、L-BFGS(Liu and Nocedal, 1989; Nocedal and Wright, 2006)以及截断牛顿算法(Nash, 2000)等,由其所求的梯度并没有得到优化,导致收敛效率和成像精度不高;此外,梯度类算法在每次模型更新时都需计算一个迭代步长,须付出1~2次波场延拓计算的代价,进一步降低了LSRTM的计算效率.
随着计算机技术的进步,近几年以卷积神经网络(Hinton and Salakhutdinov, 2006)、U型网络(Ronneberger et al., 2015)等为代表的深度学习技术发展迅猛.深度神经网络的学习过程本质上也是一个基于梯度的反演优化问题,以卷积神经网络为例,其每个卷积层都有若干个待求卷积核,而整个网络通常含有上百万、千万个待优化参数,因此神经网络的训练过程中都要应用RMSProp(Hinton et al., 2012)、Adam(Kingma and Ba, 2017)以及QHAdam算法(Ma and Yarats, 2019)等先进的梯度优化算法对反传梯度进行优化,以提高各卷积层参数反演的收敛效率.近年来,已有部分学者尝试将各种梯度优化算法引入地球物理领域,以解决反演优化问题.Wu等(2018)将Adam算法应用于频率域LSRTM中,结果显示相比于梯度下降算法,Adam算法的成像精度更高.Bernal-Romero和Iturrarán-Viveros(2020)将七种自适应学习率算法引入到传统时间域全波形反演算法中,结果显示与传统算法相比这些算法不但具有计算效率优势,同时具有收敛效率和反演精度优势.
本文将深度学习中的QHAdam算法(Ma and Yarats, 2019)引入到时间域LSRTM中,可在付出极小计算代价的前提下,直接获得优化的模型更新量,可显著提升LSRTM收敛效率和成像精度,同时还可避免每次迭代时迭代步长的计算,从而在一定程度上提升LSRTM的计算效率.
1 LSRTM原理及实现流程
常密度声波方程可表示为:
(1)
其中,c0为背景速度场,p0为与位于xs的震源f相关的压力场.
对背景速度施加一扰动δc,则产生的波场为p=p0+δp,其中δp为扰动波场,波场p满足方程:
(2)
其中c=c0+δc,p为与位于xs的震源f相关的压力场.
将速度项泰勒展开为:
(3)
将式(2)与(1)相减可得扰动波场δp为:
(4)
定义刻画偏移速度与真实速度偏离程度的扰动模型(或真实反射率)为m(x)=2δc(x)/c0(x),则式(4)可写为:
(5)
记录检波点位置xr上的波场值δp(xr;t;xs)即得到Born近似的模拟数据dsyn(t,xr).LSRTM即基于公式(5),通过梯度下降类算法迭代优化m来不断缩小预测数据dsyn与观测数据dobs在最小二乘意义下的误差.
根据伴随状态法可得到LSRTM中梯度计算公式为(Plessix, 2006):
(6)
其中,伴随波场q满足:
(7)
为提升LSRTM的收敛效率,通常需将梯度转换成共轭梯度,然后应用基于梯度预处理算法 (Zhang et al., 2012, 2011)、L-BFGS算法(Yang and Zhang, 2018)或截断牛顿算法(王义和董良国, 2015)等实现迭代反演.然而,无论采取何种梯度算法,常规LSRTM得到的梯度均未进行梯度优化处理,其会导致整个LSRTM的收敛效率和收敛精度不高;此外,每次迭代时,为得到模型更新量,一般还需付出1~2次波场延拓计算来求取迭代步长,这进一步降低了LSRTM的计算效率(常规LSRTM处理流程见图1).

图1 常规LSRTM实现流程Fig.1 Flow chart of LSRTM with conventional algorithms
2 基于QHAdam梯度优化算法的LSRTM
梯度优化算法在深度学习领域应用广泛.深度神经网络通常含有上百万、千万个待优化参数,因此神经网络的训练过程中都要应用RMSProp(Hinton et al., 2012)、Adam(Kingma and Ba, 2017)等先进的梯度优化算法对反传梯度进行优化,以提高各层参数反演的收敛效率.而其中Adam算法是深度学习领域中常用的梯度优化算法,目前已有部分学者尝试将Adam算法引入全波形反演(Bernal-and Iturrarán-Viveros, 2020)或最小二乘逆时偏移领域(Vamaraju et al., 2021; Wu et al., 2018),显著提高了收敛效率和计算精度.
Adam算法利用了梯度的一阶和二阶矩估计为不同参数提供自适应的步长,第k次迭代梯度的有偏一阶矩估计sk计算了前k-1(k>0)次迭代梯度的指数加权:
sk=β1sk-1+(1-β1)gk,(8)
其修正项可表示为:
(9)
第k次迭代的梯度的有偏二阶原点矩估计rk计算了前k-1次迭代梯度平方的指数加权:
rk=β2rk-1+(1-β2)gk⊙gk,(10)
其修正项可表示为:
(11)
Adolphs等(2020)证明了可以将Adam类算法视为椭球约束的一阶信赖域方法,可使用历史梯度的指数加权平均来对当前梯度进行缩放,使其步长能够自适应优化过程,Adam算法模型更新量可表示为(Kingma and Ba, 2017):
(12)
其中,mk和mk-1分别表示第k和k-1次迭代的模型参数(LSRTM中为真实反射率),s0=r0=0,β1和β2为常数,在深度学习中一般设置为0.9和0.999,α为初始迭代步长,ε为保持数值稳定的常数,一般为10-8.基于公式(12),Wu等(2018)实现了频率域的LSRTM.
然而对于Adam算法,如果某些参数的梯度接近于零,会使公式(12)第二项的分母远小于分子,此时更新量会出现异常值,导致优化过程不稳定.为解决此问题,Ma和Yarats(2019)通过大量实验证明了时间不一致性在随机优化器中的重要性,因此他们将Adam算法中的具有时间一致性的指数贴现函数(见公式(13))替换为不具有时间一致性的拟双曲贴现函数(公式(14)),由此形成了QHAdam算法,该算法可以通过设置超参数v来避免Adam算法可能会出现的不稳定问题,获得更加稳定的收敛.公式(13)和(14)为:
dEXP,β(k)=(1-β)βk,(13)
(14)
式中,v和β均为常数.
将Adam算法中的矩估计项替换为拟双曲项即可得到基于QHAdam算法的模型更新量计算公式(Ma and Yarats, 2019):
(15)
(16)
(17)
v1、v2、β1、β2以及α等参数的选取对于算法的稳定性和收敛效率均有一定的影响,本文大量实验测试结果表明,当β1=0.7、β2=0.999、v1=0.999、v2=1.0时QHAdam算法具有较优的收敛效率和稳定性;而对于初始步长α,本文采用如下所述的初始步长设置策略:在第一次模型更新迭代时,利用传统算法计算模型更新量,并将其绝对值的最大值的0.5倍(公式(18))设置为初始步长,并在随后的迭代中对初始步长施加衰减系数γ=0.99的指数衰减.公式(18)为:
αk=max{|Δm0|}/2*γk-1.
(18)

图2 基于QHAdam优化算法的LSRTM实现流程Fig.2 Flow chart of LSRTM with QHAdam algorithm
基于QHAdam算法LSRTM流程图如图2所示.对比图1和图2可知, 基于QHAdam算法的LSRTM除需第一次迭代外,后续迭代中均应用公式(15)和(18)计算优化的模型更新量,不需计算迭代步长,因此与传统算法相比,该方法具有更高的计算效率.另外,由于Adam算法和QHAdam算法分别使用梯度平方的指数贴现和拟双曲贴现来对梯度项进行缩放,能够为空间不同点的梯度提供自适应的步长,因此无需对梯度进行照明补偿,能够由梯度gk直接求取优化后的模型更新量Δmk.
3 Marmousi模型实验
本文使用的Marmousi模型深度为3.5 km(其中固定水深0.5 km),宽度为9.2 km(真实速度模型如图3a所示).实验采用主频为10 Hz,时间采样间隔为1 ms的雷克子波作为震源,共模拟460炮地震记录作为实测地震记录.每炮地震记录共460道,记录长度为4 s,炮间距设为20 m,道间隔也为20 m,炮点和检波点均放置于模型表面.成像使用的偏移速度如图3b所示,真实反射率如图3c所示.
本文分别基于L-BFGS算法、Adam算法以及QHAdam算法应用Marmousi模型进行LSRTM成像实验,第30次迭代成像结果如图4所示,切片对比结果如图5所示.其中L-BFGS算法存储了10次迭代信息用于重建Hessian矩阵且未使用照明补偿,Adam算法中β1=0.9,β2=0.999,ε=10-8;QHAdam算法中β1=0.7,β2=0.999,v1=0.999,v2=1.0,ε=10-8.

图3 Marmousi模型(a) 真实速度; (b) 偏移速度; (c) 真实反射率.Fig.3 Marmousi model(a) True velocity model; (b) Migration velocity model; (c) True reflectivity.
由图4可知,基于Adam算法和QHAdam梯度优化算法的LSRTM成像结果精度明显优于L-BFGS算法反演结果,尤其在中深层其成像精度优势更为明显.图4中4.6 km和6.2 km处单道成像结果对比见图5a、b,其中黑色曲线为真实反射率,绿色曲线为基于L-BFGS算法的成像结果,蓝色曲线为基于Adam梯度优化算法的成像结果,红色曲线为基于QHAdam梯度优化算法的成像结果.由图5可知,基于L-BFGS算法的LSRTM其成像精度最低,而基于QHAdam梯度优化算法的LSRTM具有最高的成像精度,其更接近于真实反射率模型.
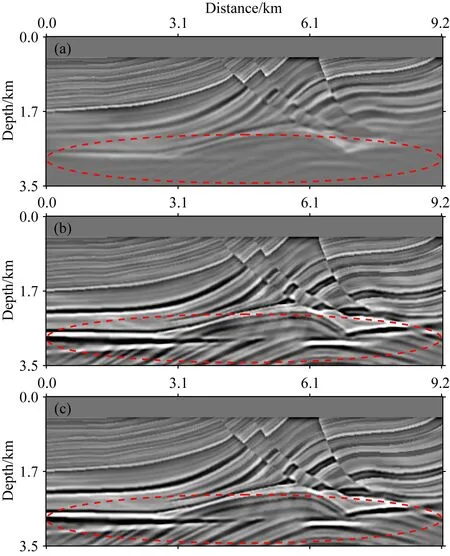
图4 基于不同优化算法的LSRTM结果(a) L-BFGS; (b) Adam; (c) QHAdam.Fig.4 LSRTM results
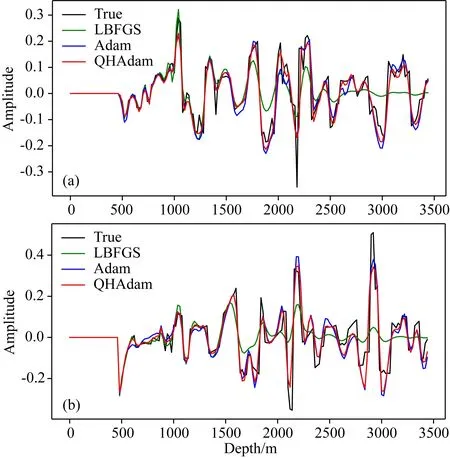
图5 基于不同算法的成像单道切片结果(a) Marmousi模型4.6 km处; (b) Marmousi模型6.2 km处.Fig.5 Single trace contrast based on different algorithm(a) Comparison of vertical amplitude at 4.6 km; (b) Comparison of vertical amplitude at 6.2 km.
为全面评估三种算法成像结果的精度,本文应用公式(19)来评估成像结果和真实反射系数的误差:
(19)
其中,mresult表示最终成像结果,mreal代表真实反射率.三种算法的成像精度评估因子迭代曲线见图6.由图6可知,相比于L-BFGS和Adam算法,基于QHAdam梯度优化算法的LSRTM具有更高的收敛效率.

图6 成像误差迭代曲线Fig.6 Imaging error curves
图7为对目标函数对数随迭代次数变化曲线,由图7可知,QHAdam算法收敛效率最高.同时我们也注意到,前7次迭代中L-BFGS的目标函数收敛要优于QHAdam算法(如图7所示),并且直到30次迭代结束,L-BFGS算法也要优于Adam算法,这主要是由于L-BFGS算法更适应于浅层的收敛成像,Adam算法和QHAdam算法注重于全局的优化成像,而由于几何扩散的影响,导致L-BFGS算法的目标函数整体优于Adam算法,前7次优于QHAdam算法.但是事实上由图6模型误差曲线可知,Adam算法要优于L-BFGS算法,并且无论从模型误差还是目标函数来看,QHAdam算法的收敛效率均优于L-BFGS算法和Adam算法.

图7 目标函数对数迭代曲线Fig.7 Logarithms objective function curves
本文基于两张Telsa-V100卡执行基于三种不同算法的LSRTM,三种算法各30次迭代计算时间如表1所示.

表1 不同梯度算法LSRTM迭代时间Table 1 Computation time of different algorithms
由表1可知,基于Adam算法和QHAdam类梯度优化算法的LSRTM其计算效率要高于常规LSRTM成像算法,这是其不需要计算梯度步长而节省的1次波场延拓计算时间所致.
4 结论
本文将深度学习中的QHAdam算法引入到传统LSRTM计算中实现了模型修改量的优化处理,其在付出极小计算代价的前提下,直接获得优化的模型更新量,避免了计算步长的求取.Marmousi模型实验结果显示,相比于常规LSRTM算法,基于QHAdam梯度优化算法的LSRTM其收敛效率和反演精度更高,且由于减少了迭代步长的求取步骤,其也具有更高的计算效率;同时相对于基于Adam算法的LSRTM,基于QHAdam梯度优化算法的LSRTM也具有更高的收敛效率和收敛精度.
致谢感谢中国海洋大学地球探测软件技术研发团队提供的资助和支持,感谢审稿专家提供的宝贵意见.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
肇庆学院学报(2022年5期)2022-09-29
成都信息工程大学学报(2021年5期)2021-12-30
数学物理学报(2021年6期)2021-12-21
石油地球物理勘探(2021年6期)2021-12-04
数学物理学报(2021年5期)2021-11-19
石油地球物理勘探(2020年5期)2020-10-17
中国惯性技术学报(2020年2期)2020-07-24
物探化探计算技术(2020年1期)2020-04-08
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
