
高光谱成像的三七粉质量等级无损鉴别
2022-07-06 05:37张付杰李丽霞赵浩然朱银龙
光谱学与光谱分析 2022年7期
张付杰,史 磊,李丽霞,赵浩然,朱银龙
昆明理工大学现代农业工程学院,云南 昆明 650500
引 言
三七为五加科植物三七Panaxnotoginseng(Burk.)F.H.Chen的干燥根和根茎,含有许多营养成分,如皂苷、 黄酮、 氨基酸、 多糖和许多其他微量元素[1]。 三七粉是三七的主要消费和商品形式,不同质量等级的三七粉用肉眼很难分辨,外加市场上不同质量等级的三七粉价格差异较大,因此对三七粉进行质量等级鉴别具有十分重要的意义。
现在常用的三七粉质量等级鉴别方法为人工检测。 但人工检测需要检测人员有过硬的技术和丰富的经验,不具备普适性。 随着检测技术的进步,高效液相色谱、 近红外光谱等技术能够用于三七粉质量等级鉴定。 Meng[2]等利用高效液相色谱与化学模式识别相结合的方法对三七进行分类,可以清晰地区分“春七”和“冬七”。 Li[3]等利用高效液相色谱法结合PCA-MD成功鉴别了三七粉的真伪性。 Yang[4]等将近红外光谱和红外光谱数据融合并建立PSO-SVM模型对掺假物比例不同的三七粉进行分类,分类正确率分别达到了96.65%和96.97%。 Zhou[5]等人利用多传感器红外光谱结合高层次多传感器信息融合策略的RF-Bo模型对不同产地的三七进行分类,分类正确率达到了95.6%。 但高效液相色谱检测试验成本高、 周期长,而且具有破坏性。 近红外光谱技术不能提供目标图像上每个像素的光谱细节,检测精度不够高。 因此需要寻找一种更高准确率、 更高效率的无损检测方法来实现三七粉质量等级的鉴别。
高光谱成像将光谱技术和成像技术相结合,不仅可以反映样本的外部特征,还可以反映样本内部生化信息[6],已经广泛应用于农产品检测领域。 孙婷[7]等利用高光谱成像将光谱和图像信息结合并构建SVM模型对11类酿酒高粱进行分类,准确率达到了91.8%; 孙俊[8]等利用高光谱成像结合GA-PNN神经网络对江苏、 安徽、 山东三个品种的红豆进行鉴别,识别准确率达到了97.5%; Wang[9]利用高光谱图像对不同成熟的玉米种子进行分类,从胚乳侧选择特征波长结合PLS-DA,准确率达到了100%; Weng[10]等利用高光谱成像结合主成分分析网络对水稻品种进行分类,准确率达到了98.57%; Jennifer Dumont[11]利用高光谱图像结合SVM模型成功鉴别了正常的挪威云杉种子、 被Megastigmussp侵染的挪威云杉种子和空壳的挪威云杉种子,准确率达到了93.8%。 但是目前利用高光谱图像技术实现三七粉质量等级鉴别的研究还鲜有报道。
三七作为中药材,内部药用成分众多,而不同成分在光谱中的吸收波段不同。 相关研究表明,多糖在可见光光谱范围内存在吸收波段,皂苷和水分在近红外光谱范围内存在吸收波段。 不同质量等级的三七粉内在成分含量比例不同[12],在可见光光谱和近红外光谱范围内具有不同的光谱特征,因此本研究基于高光谱成像技术对三七粉进行质量等级鉴别研究。 本研究以四种不同质量等级的三七粉作为研究对象,基于不同预处理算法、 特征选择算法对三七粉的高光谱数据进行处理,并建立分类模型,以实现三七粉质量等级的无损鉴别。
1 实验部分
1.1 三七粉样本准备
选择来自云南文山的30头、 40头、 60头、 80头的三七,将不同头数的三七主根研磨成粉,制备样本,根据三七主根的头数把三七粉分为4个质量等级。 每个样本称量20 g,总共制备了384个三七粉试验样本(每个质量等级96个)。 将所有样本按2∶1的比例划分训练集和测试集,其中训练集256个样品,测试集有128样品。 4个质量等级的三七粉如图1所示,不同质量等级的三七粉存在一定的差异,但难以用肉眼判别。

图1 四种质量等级的三七粉Fig.1 Four quality grades of panax notoginseng powder
1.2 高光谱成像系统
高光谱成像系统是由高光谱图像摄影仪(VNIP-HIS-s MOS)、 卤素灯光源(UBer LED100型,IT,USA)、 分光模具(V10E型,SPECIM,Finland)、 光纤和电控平移台等组成。 高光谱图像摄影仪是由CCD相机(Zyla4.2型,Andor,UTKL)、 光谱仪等组成,光谱范围为400.68~1 001.61 nm,光谱分辨率为2.8 nm,图像分辨率为1 024×478像素。 使用的高光谱图像采集系统的主要结构如图2所示。
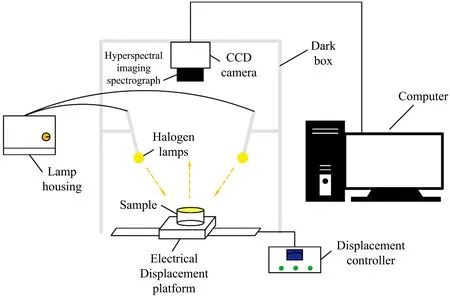
图2 高光谱成像系统结构图Fig.2 Diagram of hyperspectral imaging system
1.3 高光谱图像采集和光谱数据提取
在试验前对高光谱成像系统进行20 min的预热和黑白板标定。 黑白板标定可以减小暗电流噪声和光源强度分布不均匀对试验造成的影响,白板的反射率100%,盖上CCD相机镜头获得反射率为0%的黑板环境。 白板环境下,设定高光谱图像相机的曝光时间为7 ms; 黑板环境下,设定高光谱图像相机的曝光时间为17 ms; 设定平移台的速度为1.99 mm·s-1。 依次采集四种不同质量等级的三七粉样本的高光谱图像。
采用“矩形区域法”在每个高光谱图像中手动选择60×60像素的正方形作为感兴趣区域(region of interest,ROI),然后将ROI中像素的平均值作为每个样本的光谱值。
1.4 数据预处理
在客观环境下难以避免噪声的干扰,高光谱成像器械难以避免发生基线漂移[13]。 为了减少它们对试验结果的影响,需要对高光谱数据进行预处理。 采用卷积平滑(savitzky-golay,SG)、 多元散射校正(multiplication scatter correction,MSC)和标准正态变量变换(standard normalized variable,SNV)[14]这3种方法分别对高光谱数据进行预处理,并对比其效果,选出最优的预处理方法。
1.5 特征选择
预处理后的光谱数据分布在高维空间,但有些维度与建模无关。 为了减少光谱数据中一些无用的维数,采用特征选择的方法对光谱数据进行降维。 采用迭代保留信息变量(iteratively retains informative variables,IRIV)[15]、 变量组合集群分析(variable combination population analysis,VCPA)[16]和变量组合集群分析混合迭代保留信息变量(variables combination population analysis and iterative retained information variable,VCPA-IRIV)[17]分别从全光谱数据中提取特征波长变量。
1.6 建模方法
1.6.1 支持向量机
支持向量机(support vector machine,SVM)是一种高维信息处理的重要工具。 SVM以其良好的泛化能力在光谱数据的分类中得到了广泛的应用。 相关研究表明,惩罚因子c和核参数g的选择对SVM的性能起着至关重要的作用。 因此,有必要对SVM的参数进行优化来提升分类效果[18]。
1.6.2 引力搜索算法优化支持向量机
引力搜索算法(gravitational search algorithm,GSA)是一种种群优化算法。 用GSA对SVM的参数c和g进行寻优,具体流程如下[19]:
(1)对参数进行初始化: 随机产生质点位置的数目(群体规模)和最大迭代次数;
(2)设置质点的移动范围(参数c和g的搜索范围);
(3)设置样品训练集的交叉验证数,并通过计算粒子的适应度值确定最优质点;
(4)计算质点质量、 质点在各维数上的加速度,对质点进行位置更新;
(5)重复步骤(3)—(4),当达到最大迭代次数时,迭代停止,获得最佳的(c,g);
(6)将参数的最优值代入SVM模型中进行预测。
1.7 数据处理软件
使用五铃光学公司高光谱成像系统HSI Analyzer软件进行图像校正和感兴趣区域提取,使用The Unscrambler X 10.4软件进行预处理,使用Matlab 2016a软件进行特征选择和数据建模。
2 结果与讨论
2.1 样本的光谱特征及最优预处理方法的选择
高光谱数据容易受噪声和仪器的干扰,可能会影响后续建模的精度,因此对高光谱数据进行预处理。 原始光谱与SG,MSC和SNV预处理后的光谱如图3所示。 观察图3(a)可以发现,在采集开始时样本数据受噪声的影响较大。 对比图3(a)和图3(b)可以发现,SG预处理后的光谱曲线比原始光谱曲线更平滑。 对比图3(a)和图3(c)可以发现,MSC预处理使各高光谱曲线间差距变小,表明MSC预处理对光谱采

图3 (a)原始光谱; (b)SG预处理后光谱; (c)MSC预处理后光谱; (d)SNV预处理后光谱Fig.3 (a) Original spectra; (b) Spectra after SG pretreatment; (c) Spectra after MSC pretreatment;(d) Spectra after SNV pretreatment
集过程中因散射现象等引起的光谱误差起到了校正作用。 观察图3(d)可以发现,SNV预处理效果与MSC相似,对光谱采集过程中因散射现象等引起的光谱误差起到了校正作用,但SNV预处理的实质是对高光谱数据的标准正态化。
为了选择最优的预处理方法,采用SVM对预处理后的高光谱数据进行建模,核函数选择径向基核函数,设置参数c和g为默认值,SVM建模结果如表1所示。 通过三种预处理方法对三七粉原始光谱的处理对比分析,发现SNV预处理后的光谱具有最优的三七粉质量等级的预测能力。

表1 不同预处理方法SVM建模结果Table 1 SVM modeling results of differentpretreatment methods
2.2 特征选择
2.2.1 迭代保留信息变量
在IRIV特征选择的过程中,采用5折交叉验证的方法建立了偏最小二乘(PLS)模型。 然后以交互验证均方根误差(RMSECV)作为评价指标来选择特征波长。 在每次迭代中,剔除一些不相关和干扰的波长变量,保留特征波长变量。 从图4中可以看出,在第6次迭代之前,变量数量迅速减少,从478个减少到69个。 第10次迭代后,完全剔除了无信息变量和干扰信息变量。 最终,反向消除后保留了30个有效波长,分布在图5的平均光谱上。
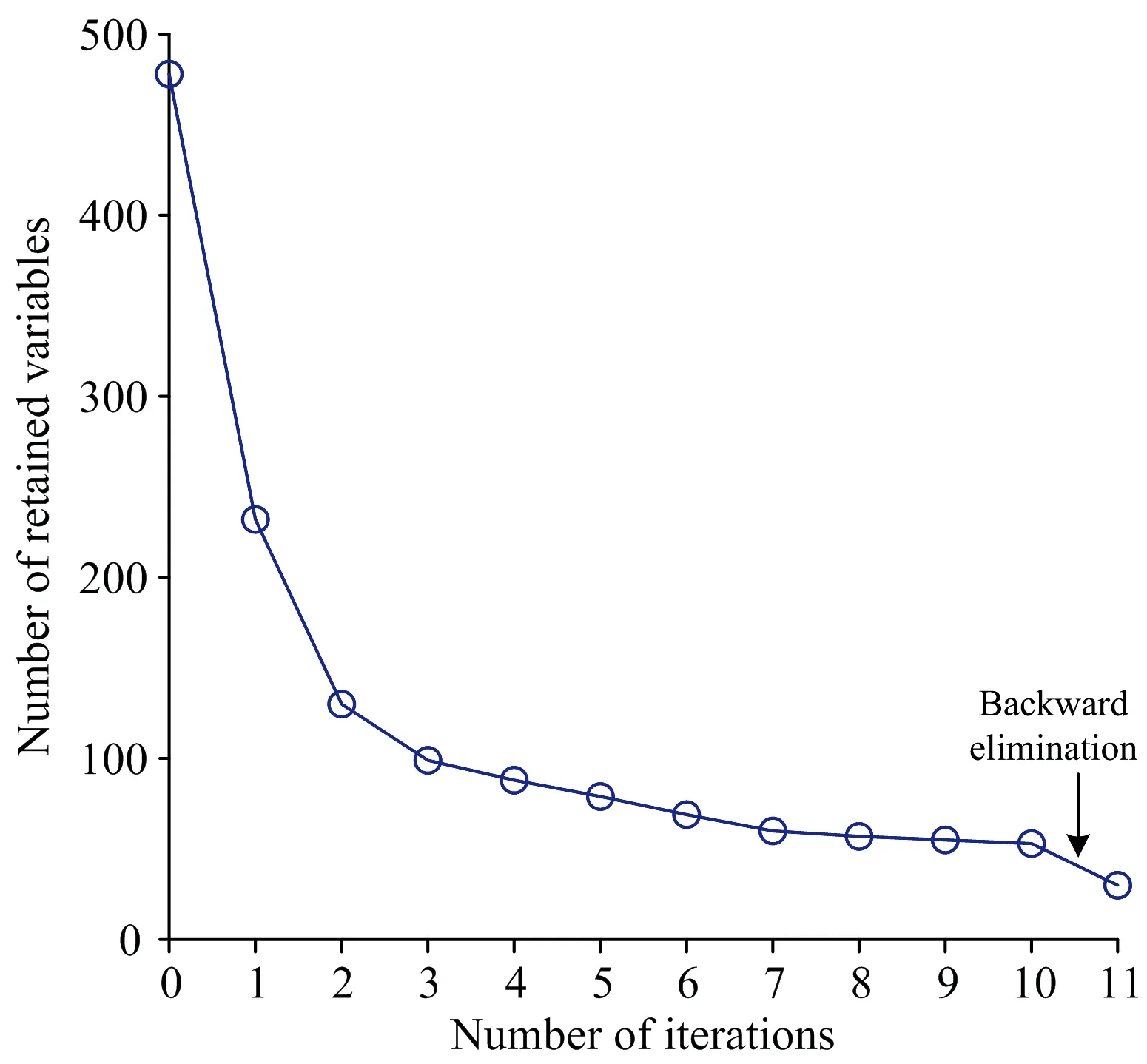
图4 IRIV选择的过程Fig.4 Process of IRIV selection
2.2.2 变量组合集群分析
在VCPA特征选择的过程中,指数递减函数(EDF)和二进制矩阵采样(BMS)运行次数分别设置为50次和1 000次,BMS初始采样权值设置为0.5,最优子集的比例设置为10%,EDF运行后剩余变量数设置为14,采用5折交叉验证的方法建立PLS模型,计算所有子集的RMSECV,以RMSECV作为评价指标筛选出最优子集; 利用EDF剔除子集中贡献率较低的变量。 迭代50次,剩余14个变量。 最后,计算这14个变量之间所有变量组合的RMSECV,提取RMSECV最小的变量组合。 最终选择了11个特征波长,分布在图6的平均光谱上。

图5 IRIV所选择的波长Fig.5 Wavelength selected by IRIV

图6 VCPA所选择的波长Fig.6 Wavelength selected by VCPA
2.2.3 变量组合集群分析混合迭代保留信息变量
VCPA-IRIV将VCPA与IRIV相结合,先通过VCPA缩小变量空间,再通过IRIV进一步优化剩余的变量。 与VCPA和IRIV相比,VCPA-IRIV消除了VCPA中最差子集对特征选择的不利影响; VCPA-IRIV通过EDF消除贡献小的变量,剩余的变量相对集中且优化,使得IRIV更容易、 更好的选择最优变量子集。 在VCPA-IRIV特征选择过程中,设置EDF运行后剩余变量数为100,其余参数与2.2.2节中相同。 首先进行VCPA,利用PLS计算所有子集的RMSECV,筛选出100个最优子集,再利用EDF剔除100个子集中贡献较低的变量,迭代50次,剩下100个变量。 再对这100个变量进行IRIV,剔除不相关和干扰的波长变量,经多次迭代直至完全剔除了无信息变量和干扰信息变量。 最终选择了18个特征波长,分布在图7的平均光谱上。

图7 VCPA-IRIV所选择的波长Fig.7 Wavelength selected by VCPA-IRIV
2.3 基于特征选择的SVM建模
建模试验由2个部分组成,第一,基于全光谱数据建立SVM模型。 第二,基于3种特征波长数据建立SVM模型。 SVM模型参数同2.1节中相同,试验结果如表2所示。

表2 基于全光谱和特征光谱的SVM建模结果Table 2 SVM modeling results based on fullspectral data and feature wavelengths
观察表2可以发现,基于全光谱和特征光谱建立的SVM分类模型均取得了较好的效果,这3种特征选择方法均保存了三七粉的有效信息。 对图5、 图6和图7进行对比分析,IRIV提取的特征波长集中在415.985~986.13 nm范围内,部分波长在受噪声影响区域内; VCPA提取的特征波长集中在510.85~689.636 nm范围内,忽视了近红外光谱区域的有效信息; VCPA-IRIV提取的特征波长分布在476.838~995.163 nm范围内,保存了三七粉在可见光光谱和近红外光谱区域内的有效信息,也没有受到噪声的影响,SVM模型的分类准确率最高。 因此认为VCPA-IRIV是最优的特征选择方法。 在模型复杂度方面,VCPA-IRIV算法简化了模型,降低了计算复杂度。 在建模精度方面,VCPA-IRIV-SVM模型的测试集分类准确率与全光谱SVM模型测试集分类准确率相同。 由于参数c和g的选择对SVM的分类精度起着重要的作用,因此引入智能优化算法GSA对SVM中参数c和g进行寻优,并与网格搜索(grid search,GS)的结果进行比较。
在GSA中,参数c和g的搜索范围分别设置为[0.01, 100]和[0. 1, 10],最大迭代次数设置为100,群体规模设置为20。 在GS中,参数c和g的搜索范围均设置为[2-8, 28],两种优化算法均采用5折交叉验证方式。 建模结果如表3所示。

表3 基于VCPA-IRIV特征选择方法的GSA-SVM 和GS-SVM建模结果Table 3 GSA-SVM and GS-SVM modeling resultsbased on VCPA-IRIV
GS具有更快的收敛速度,但由于搜索点固定,也错过了最优解,因此分类准确率低于GSA。 相比之下,VCPA-IRIV-GSA-SVM模型性能最好,训练集和测试集的分类准确率均达到了100%,最终选择VCPA-IRIV-GSA-SVM模型作为三七粉质量等级的分级模型。
3 结 论
市场上三七粉以次充好现象严重,为了保证三七粉质量,基于高光谱成像技术对不同质量等级的三七粉进行无损鉴别。 首先,采集样本的高光谱图像,通过选择ROI得到60×60像素的光谱信息,然后分别用SG,MSC和SNV对光谱数据进行预处理,反映三七粉质量等级有效信息的特征波长分别由IRIV,VCPA和VCPA-IRIV提取。 然后分别建立基于全光谱和特征光谱的SVM模型,并引入GSA和GS对SVM模型中的c和g进行优化。 结果表明:
(1)分别建立基于SG,MSC和SNV的分类模型并进行比较。 结果表明,适当的预处理方法(SNV)可以使模型具有良好的性能。
(2)分别建立IRIV-SVM,VCPA-SVM,VCPA-IRIV-SVM和全光谱的SVM模型,并进行比较。 结果表明,适当的特征选择方法(VCPA-IRIV)可以在降低模型复杂度的情况下保持模型的性能。
(3)引入GSA和GS对SVM模型中的c和g进行优化,以模型的测试集分类准确率作为评价指标。 VCPA-IRIV-GSA-SVM分类模型性能最优,训练集和测试集分类准确率均达到了100%,因此将GSA作为优化原模型的智能算法。
综上,利用可见近红外高光谱成像技术对三七粉进行质量等级鉴别是可行的,该方法为市场上三七粉的质量等级鉴别提供了参考。
猜你喜欢
温州大学学报(自然科学版)(2022年2期)2022-05-30
阅读(科学探秘)(2021年8期)2021-09-01
潍坊学院学报(2020年2期)2021-01-18
制导与引信(2017年3期)2017-11-02
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
中南大学学报(自然科学版)(2016年2期)2017-01-19
中国照明(2016年4期)2016-05-17
智能系统学报(2015年4期)2015-12-27
中国当代医药(2015年26期)2015-03-01
