
知识图谱在数字资源开发与利用中的应用研究
2022-07-10 23:29孙安
河南图书馆学刊 2022年6期
孙安

关键词:知识图谱;数字资源;知识组织;语义化建设
摘 要:知识图谱强大的语义数据表示能力与智能化的语义数据检索能力深受数字资源组织青睐。文章阐述了知识图谱的概念,介绍了数字资源建设发展概况,构建了基于知识图谱的数字资源开发与利用的技术体系,总结了知识图谱在数字资源开发与利用中的特点,以期为相关研究提供参考。
中图分类号:G250.7 文献标识码:A 文章编号:1003-1588(2022)06-0121-05
自2012年5月Google公司提出“知识图谱”概念后,知识图谱强大的语义数据表示能力与智能化的语义数据检索能力深受数字资源组织青睐。近年来,数字人文研究热不断升温,图书馆作为文献信息资源的集中地,逐渐在该领域显现出“数字资源占有”这一独特优势,涌现出大量围绕数字人文数据基础设施平台建设的相关研究成果,主要讨论如何将信息资源进行数字化、数据化、语义化转变,以满足人文研究与数字计算等服务要求,这给图书馆的数字资源开发与利用工作带来了机遇与挑战[1]。
然而,学界给“知识图谱”概念赋予了多种含义,不同领域研究的知识图谱其概念所指与研究方法差异颇大。文章首先理清了知识图谱在图书情报领域中的概念内涵,并指出笔者研究的知识图谱属于知识组织领域范畴;其次分析数字资源建设发展的三个阶段,指出当前本体、知识图谱、自然语言处理等语义技术被广泛应用于数字资源的知识组织与语义描述中;再次讨论了基于知识图谱的数字资源开发与利用工作的关键步骤;最后对知识图谱在图书馆学领域的应用实践特点进行了总结,并展望了知识图谱未来的发展趋势及其研究任务。本研究可为当前图书馆、档案馆、博物馆的数字资源建设提供技术与理论指引。
1 知识图谱概念阐述
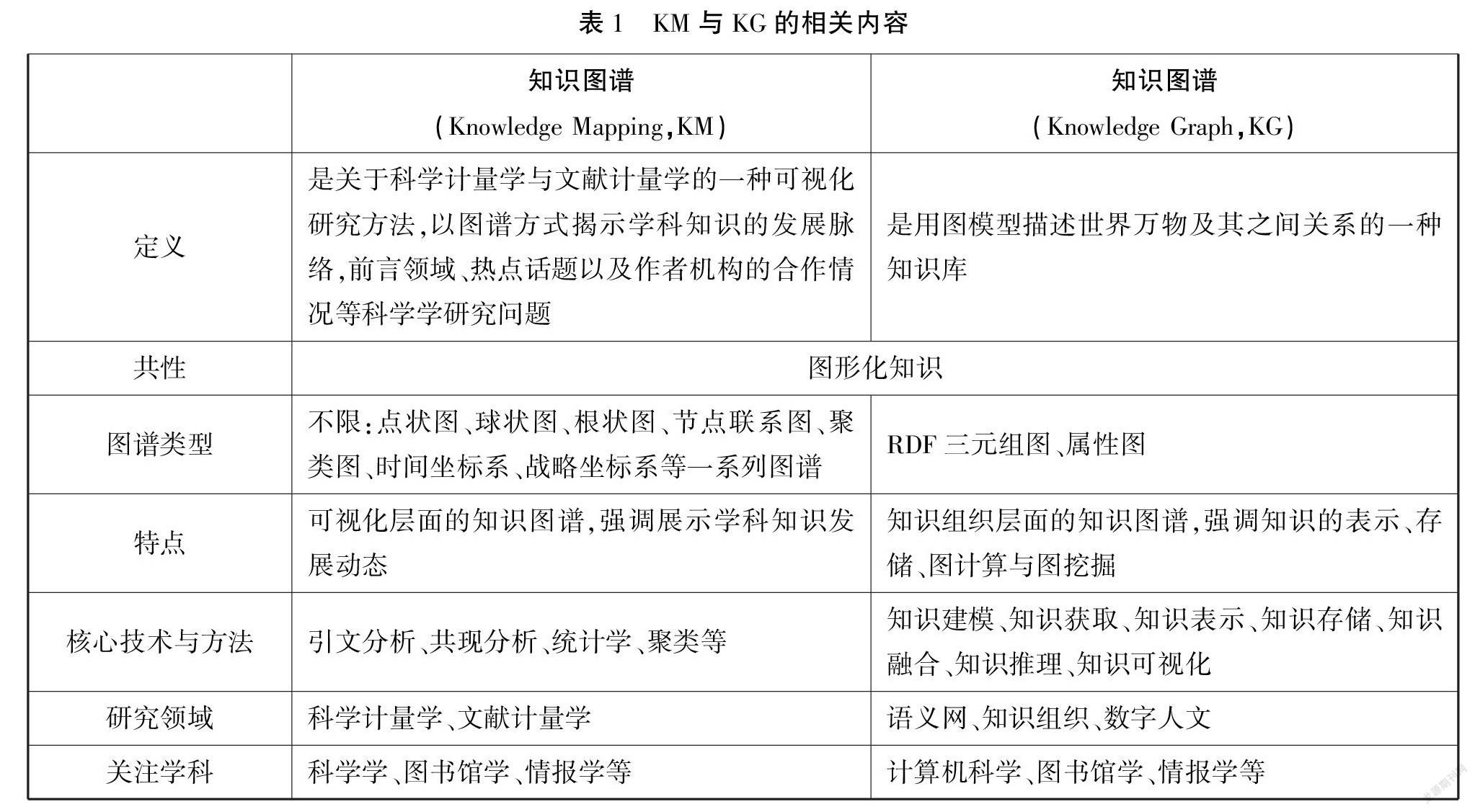
知识图谱在学界被赋予了多种含义且涉及不同研究领域,主要有两类:第一类为科学学研究范畴中的科学知识图谱,简称知识图谱(Knowledge Mapping,KM)。该研究领域主要关注科学研究发展动态及趋势、科学热点问题以及科研合作状况。其概念可被定义为:用可视化的方式描述人类随时间拥有的知识资源及其载体;绘制、挖掘、分析和显示科学技术知识以及它们之间的相互联系,在组织内创造知识共享的环境以促进科学技术研究的合作和深入[2]。研究方法主要有:引文分析、共现分析、统计分析、聚类分析等。图谱类型不限,主要有:点状图、球状图、根状图、节点联系图、聚类图、时间坐标系、战略坐标系等一系列可视化图谱[3]。
第二类为知识组织研究范畴中的知识图谱(Knowledge Graph,KG),由Google公司阿密特·辛格(Amit Singhal)于2012年5月在公司官方微博上发表的“Introducing the Knowledge Graph: things,not strings”一文中正式提出,它以图数据模型来组织互联网中的海量数据,并通过概念(concept)、实体(entity)及其之间的相互关系(relation)描述客观世界中的万事万物,实现了对客观世界从简单字符串描述向结构化语义描述的转变(things,not strings),因此也被称为语义知识图谱[4]。其研究方法主要有2类:基于本体建模+RDF三元组图模型方法(来源于关联数据技术)、基于图数据建模+属性图模型方法(来源于图数据库技术)[5]。前者强调数据的概念语义描述和数据的URI表示,有利于知识图谱的开放与互联;后者强调图数据的数据模式构建和原生图的存储,有利于图数据的大规模运算和图数据的知识挖掘。
笔者研究的是第二类知识图谱,也是当前图书馆领域关于数字资源开发与利用研究中关注较多的一类。两类知识图谱的概念、技术、方法、研究领域等相关内容如表1所示。
2 数字资源建设发展概况
随着国民数字素养的不断提高,其数字资源需求也在不断提升,其数字资源建设已成为当前信息资源建设的重点工作。回顾历史,数字资源建设按照资源的加工深度可以划分为三个发展阶段:数字化发展初始阶段、数字化向数据化发展阶段以及数据化向语义化发展阶段。
2.1 数字化发展初始阶段
数字资源建设发展初期的重点工作是将传统文献信息资源进行简单的数字化加工,即加工成电子文献。简单数字化加工主要是利用扫描仪、数码照相机、数码摄像机等光学仪器设备将纸质文献资源、实物文献资源加工成图像、视频等数字资源,任务是实现信息资源载体的数字化。目前,国内各大图书馆、档案馆、博物馆还保留了大量扫描件。该类数字资源辅以简单的元数据描述,同时采用结构化关系数据库进行存储,可以为读者提供查询、检索、下载等信息服务。由于缺乏数字资源的内容信息,数字资源蕴含的知识处于封闭状态,还需后期人工阅读与理解,不利于数字资源的有效传播与利用。
2.2 数字化向数据化发展阶段
该阶段主要是对数字资源进行数据化、文本化建设和研究。研究内容是将简单扫描、拍照获得的数字化资源进行文本识别,实现数字资源的数据化方向发展,或是在数字资源加工源头采集人工编辑录入的可编辑电子文件。此时,数字资源能够提供大量文献资源的内容数据。利用文本分析工具对数据化的文献资源进行文本分析和内容分析后,数字资源就可以支持更丰富的内容查询与检索,如:對文本内容进行词性标注、关键词自动生成、文本摘要提取、情感分析等。数字资源的数据化建设也为下一阶段数字资源的语义化建设提供了数据基础。
2.3 数据化向语义化发展阶段
该阶段主要是利用本体、知识图谱、自然语言处理等语义技术对数据化的数字资源进行语义化建设。这里的“语义”并非指对人,而是指对机器,语义化工作的目的是增强数字资源的机器可理解程度,让计算机更好地“读懂”数字资源。目前,知识图谱语义技术被广泛应用于数字资源的知识组织与知识的语义描述中。该技术先运用本体的知识建模技术将数字资源中蕴含的知识进行知识建模,获得数字资源中内容知识的概念模型,再从数字资源中抽取知识实例并按照概念模型进行组织。机器在读取数据时,可以通过知识本体明白所读取数据的概念类别、关系名称,从而增强数据的语义表示。数字资源的语义化建设对资源的语义检索、智慧服务提供了强有力的基础语义数据支撑,是当前数字资源建设研究的前沿与重点开发工作。
3 基于知识图譜的数字资源开发与利用技术体系
目前,语义化建设是数字资源建设的重点工作,富含语义表示的知识图谱KG技术被广泛应用其中,从知识的获取到知识的应用——知识图谱在数字资源开发与利用实践活动过程中已经初步形成其理论框架与技术体系,详见图1。
3.1 知识建模
知识建模即构建知识图谱的本体(ontology)或模式(schema),也即设计知识图谱的数据骨架。基于关联数据技术构造的知识图谱采用RDF三元组图数据模型,知识建模采用本体的构建思想;基于图数据库技术构造的知识图谱大多采用属性图模型,此时知识建模任务是构造图数据库的数据模式。不论是本体构建还是模式构建,其工作内涵都是定义知识图谱中有关知识的概念、类别、属性、关系,形成知识的语义关系模型,指导知识图谱中的实例对象进行语义组织。以Freebase通用知识图谱为例,其定义了2,000多个概念类型、4万个属性,并为每个类型定义了若干关系,以及关系的定义域和值域[6]。常见的知识建模方法有:骨架法[7]、TOVE法[8]、IDEF5法[9]、七步法[10]、Methontology方法等[11],总体可以概括为:确定领域及任务、罗列概念元素、确定分类关系、定义属性及关系、定义关系约束,过程中还应考虑对已有本体元素的复用,如可以通过“上海图书馆本体服务中心”下载复用已有的合适本体[12]。
3.2 知识获取
知识获取是指由“人工编辑知识”或“机器自动从海量文本数据中获取知识”。人工编辑知识主要依赖专家经验,知识产生过程耗时费力,不利于大规模知识图谱的构建。因此,如何利用机器自动地从不同数据源中获取知识是人们关注的焦点。数据源按照结构化程度可以划分为结构化、半结构化、非结构化数据源。
3.2.1 结构化数据主要来源于各个企业以及互联网公司的关系型数据库。其数据质量较高,可采用“直接映射(Direct Mapping)”法,如采用RDB2RDF方法将关系型数据库转换为RDF数据集,生成的RDF数据集的语义标签均来自原关系型数据库中表的名称及表的列属性。
3.2.2 半结构化数据是一类特殊的结构化数据。它拥有说明数据的语义标签,但其数据模式和数据组织相对结构化数据较为松散,具有结构多变、模式不统一等特点,知识抽取时较结构化数据复杂,一般采用包装器法(Wrapper)进行数据清洗、数据标注、数据转换、数据评估。自万维网出现以来,半结构化数据越来越丰富,蕴含了海量的人类知识,逐渐成为大型知识图谱获取知识的主要来源。
3.2.3 非结构化数据(纯文本)的知识获取也叫文本信息抽取(Information Extraction,IE)。它是指从自然语言文本中抽取事实知识,这些事实知识可以是一组预先指定的实体、关系或事件信息,然后将这些信息用结构化的方式进行存放,便于机器利用。随着自然语言处理(NLP)技术的不断发展,非结构化文本中的语义知识显得愈发重要,知识图谱构建技术也越来越关注如何从纯文本数据中抽取知识。
3.3 知识表示与存储
知识图谱中的知识表示是指用什么语言和方法对知识进行建模与描述,从而方便知识的存储与计算。知识图谱采用什么样的图数据模型决定了知识表示的方法与特质。当前,知识图谱主要存在两种图数据模型:一种是来自语义网技术背景下的RDF三元组图模型,另一种是来自图数据库技术背景下的属性图模型。其中,万维网联盟W3C为语义网下的知识图谱提供了RDFS/OWL本体描述语言,方便本体与本体实例数据的组织与描述,同时采用RDF三元组存储(triple store)的方式进行存储,常见的支持三元组存储的数据库管理系统有RDF4J、Virtuoso、GraphDB等。属性图模型由各个图数据库产品提供各自的知识建模语言,尚未形成行业标准,如Neo4J的Cypher语言、HugeGraph的Gremlin语言等,其存储采用原生图——“无索引邻接边”的方式进行存储,具备高效的图计算性能。这里需要指出,来自语义网技术背景下的RDF三元组图模型采用的是关联数据技术发布数据,其核心是使用URI表示资源内容,这使得知识图谱具有开放互联功能,为知识图谱的开发与利用提供了一个开放包容的互联网环境。
3.4 知识融合
知识融合是指对不同来源、不同语言或不同结构的知识进行融合,从而对已有知识图谱进行知识的补充、更新、对齐和去重。目前,关联数据开放项目(linked Open Data)会定期发布较为成熟的语义知识图谱,如通用领域的Dbpedia、行业领域的DrugBank、上海市图书馆的名人规范库等。从融合的对象看,知识融合包括本体层的融合与实例层的融合。其中,本体层融合指借助本体映射方对多个异构的本体模型进行对齐操作,包括概念、属性、关系的对齐。实例层融合主要指对概念实例、关系实例的融合,涉及实例的补充、更新和去重等工作。
3.5 知识推理
知识推理是指基于已有的事实或知识推理出未知的事实或知识的过程。目前,利用知识推理完成知识图谱的补全任务(Knowledge Base Completion,KBC)是关于知识图谱的一个研究热点。知识图谱中的知识不一定完整,通过对已有的知识进行推理获取新的知识,可以实现知识图谱的补全动作,尤其是补全一些实体之间的关系,帮助完善知识图谱的构建工作。此外,知识推理还可以用于知识图谱的质量检测任务,用于发现一些存在冲突的知识结论。
3.6 知识应用
近年来,随着人工智能的研究热度不断升温,知识图谱作为机器大脑中的知识库在各行各业中得到了越来越多的关注。例如,语义搜索、自动问答、推荐系统、决策支持、知识可视化中都能看到知识图谱的身影。在语义搜索中,知识图谱采用本体方法进行知识的组织与描述,为数据附上其所属的概念或关系语义。在自动问答中,知识图谱利用实体与实体之间的关系进行链接和推理,进而获得人们所需要的答案。在推荐系统中,系统通过知识图谱中顾客与购买商品的实体关系构建用户画像,以便获得更精准的推荐依据。在决策支持中,系统可以从知识图谱里挖掘出概率较高的关系实例作为决策依据供人采纳。知识可视化是将人物之间的人际关系进行可视化展示,如亲属圈、朋友圈、学术圈等。
4 应用实践
近年來涌现出不少关于知识图谱在数字资源建设中的应用研究成果。杨海慈(2019)将中国历代人物传记资料库CDBD作为数据源,构建了宋代学术师承关系知识图谱并将其进行可视化展示,该知识图谱的本体建模共设计了5个类,39个关系,囊括了48,018位人物和6,599条信息,并采用关联技术对外发布[13]。周莉娜(2019)设计了“诗歌—诗人”二元本体和面向史学的时空经历本体,采用网络爬虫技术从百科类网站、中文诗歌类网站、人名地名辞典、时空坐标等网站爬取数据,并按照设计好的知识本体进行知识抽取,最后采用RDF三元组构建知识图谱[14]。张娜(2019)在文物知识图谱构建关键技术研究中,对大量文物文本数据进行一定数量的实体关系人工标注,采用半监督学习方法训练获得可自动抽取文本实体关系的分类器,共定义了10种关系模式,如(博物馆、收藏、书法)等,抽取后采用RDF三元组进行组织并进行可视化研究[15]。刘芳(2020)以博物馆藏品为研究对象,构建了博物馆藏品知识图谱的本体模型,采用映射方法和D2R工具从第三方数据库系统中抽取博物馆藏品知识数据,并进行了知识融合和可视化展示[16]。孙鸣蕾(2020)收集作家名人档案数据资料,构建作家名人档案知识图谱本体,并对名人档案数据资料进行知识图谱组织与可视化研究[17]。李永卉(2021)以《中国历史地图集》、《嘉定镇江志》、《至顺镇江志》、北京大学出版社《全宋诗》、中华书局《全宋词》等近十种与宋代镇江诗词有关的历史文献作为数据源,构建了宋代镇江诗词知识图谱本体模型,并进行文本知识抽取,然后采用RDF三元组进行描述与图数据库存储,最后进行了知识图谱查询和知识推理研究[18]。梁科(2021)针对古籍《山经》中的专名进行知识图谱构建,共设计山类、水类、草类、鸟类、鱼类等15个类,采用正则表达式的匹配方法抽取《山经》文本中的实体和实体关系,并采用Neo4j图数据库进行存储和可视化研究[19]。欧阳剑(2021)从国内外古籍书目网络数据库、CBDB、在线百科等网页中抽取古代典籍书目数据,并按照自行设计的典籍知识图谱概念本体进行组织,所构建的典籍知识图谱包含649,549种古籍实体、221,783位典籍责任者、1,498,383个古籍版本、13,960个地名[20]。
5 结语
采用知识图谱的数字资源开发与利用研究工作主要集中在知识抽取、知识建模、知识的RDF三元组表示与存储、知识的可视化方面。其中,知识建模广泛采用RDF三元组图模型的本体建模方法,主要设计知识图谱中的实体概念类别及其关系类型,而采用属性图模型的研究相对较少。知识抽取研究中,大部分是基于结构化或半结构化的数据源,如:中国历代人物传记资料库CDBD、网络百科、专业领域数据库等,这类研究构造的知识图谱质量相对较高,多数研究获取的实体与实体关系数量已初具规模。而非结构化文本数据的知识抽取研究受自然语言处理技术发展限制,尚处于研究初级阶段,未来也将被广泛关注。知识应用方面,可视化研究较为普遍,而知识推理研究较少或不够深入,部分研究仅有若干条推理规则。在知识图谱的数据类型方面,研究者主要围绕文本知识图谱进行构建,图像、视频等多模态知识图谱研究相对较少,未来还有发展空间。总之,知识图谱能为学科研究提供切实、有价值的参考,其研究将持续受到关注。
参考文献:
[1] 夏翠娟.面向人文研究的“数据基础设施”建设:试论图书馆学对数字人文的方法论贡献[J].中国图书馆学报,2020(3):24-37.
[2] 陈悦,刘则渊.悄然兴起的科学知识图谱[J].科学学研究,2005(2):149-154.
[3] 秦长江,侯汉清.知识图谱:信息管理与知识管理的新领域[J].大学图书馆学报,2009(1):30-37,96.
[4] AMIT S. Introducing the Knowledge Graph: Things,Not Strings[EB/OL].[2021-05-12].https://www.blog.google/products/search/introducing-knowledge-graph- things-not/.
[5] 陈涛,刘炜,单蓉蓉,等.知识图谱在数字人文中的应用研究[J].中国图书馆学报,2019(6):34-49.
[6] 赵军,刘康,何世柱,等.知识图谱[M].北京:高等教育出版社,2018:72-73.
[7]Uschold M,Gruninger M. Ontologies: Principles,methods and applications[J].The Knowledge Engineering Review,1996(2):93-136.
[8] THAM K D, FOX M S, Gruninger M. Cost ontology for enterprise modelling[C]//Workshop on Enabling Technologies:Infrastructure for Collaborative Enterprises. IEEE,1994:111-117.
[9]SARDER M B. IDEF5 Ontology Description Capture Method [EB/OL].[2021-10-23].https://www. pomsmeetings.org/confpapers/004/004-0127.pdf.
[10] NOY N F, MCGUINES D L. A Guide to Creating YourFirst Ontology[EB/OL].[2021-10-20].https://www.docin.com/p-1005678470.html.
[11] JURISTO N. METHONTOLOGY: From Ontological Art Towards Ontological Engineering[J]. Ontological Engineering,1997(6):33-40.
[12] 上海市图书馆.本体服务中心[EB/OL].[2021-10-20].http://www.usources.cn/ont.
[13] 杨海慈,王军.宋代学术师承知识图谱的构建与可视化[J].数据分析与知识发现,2019(6):109-116.
[14] 周莉娜,洪亮,高子阳.唐诗知识图谱的构建及其智能知识服务设计[J].图书情报工作,2019(2):24-33.
[15] 张娜.文物知识图谱构建关键技术研究与应用[D].杭州:浙江大学,2019.
[16] 刘芳,谢靖.以藏品为核心的知识图谱设计与应用[J].数字图书馆论坛,2020(6):8-14.
[17] 孙鸣蕾,房小可,陈忻.数字人文视角下名人档案知识图谱构建研究:以作家档案为例[J].山西档案,2020(6):79-88.
[18] 李永卉,周树斌,周宇婷,等.基于图数据库Neo4j的宋代镇江诗词知识图谱构建研究[J].大学图书馆学报,2021(2):52-61.
[19] 梁科.《山经》专名的知识图谱构建及价值分析[D].北京:中国社会科学院研究生院,2021.
[20] 欧阳剑,梁珠芳,任树怀.大规模中国历代存世典籍知识图谱构建研究[J].图书情报工作,2021(5):126-135.
(编校:周雪芹)
猜你喜欢
现代情报(2016年10期)2016-12-15
现代情报(2016年10期)2016-12-15
教学月刊·小学综合(2016年11期)2016-12-05
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
中国远程教育(2016年9期)2016-11-19
中国集体经济(2016年26期)2016-11-19
数字技术与应用(2016年9期)2016-11-09
中国教育信息化·基础教育(2016年9期)2016-10-18
出版广角(2016年4期)2016-04-20
