
倾向性评分匹配应用条件及SPSS软件实现
2022-07-30 07:07王瑞平
上海医药 2022年13期
王瑞平
(上海市皮肤病医院临床研究与创新转化中心 上海 200443)
近年来,随着网络信息技术的发展和国内外临床研究的持续升温,越来越多的研究者开始关注大型人群队列的建立和应用。尽管随机对照临床试验(randomized clinical trial, RCT)可以提供高级别的循证医学证据,但其往往耗费较多的人力、物力和财力,同时有些研究中干预措施的随机分组还存在伦理学问题。因此,如何基于观察性临床研究开展等效于RCT 研究的数据处理越来越受到临床研究工作者的关注。1983 年,由Paul Rosenbaum 和Donald Rubin 提出的倾向性评分匹配(propensity score matching,PSM)分析可以减少研究中的偏差和混杂变量影响,以便对观察组和对照组进行更合理的比较,较为完美地解决了上述问题[1]。本文将介绍PSM 的概念和应用条件,以及如何应用SPSS 软件实现PSM的过程,以期为研究人员开展PSM分析提供参考。
1 PSM 的概念
PSM 是一种统计学方法,主要用于处理观察性临床研究或临床试验研究数据亚组分析,可有效降低混杂偏倚,并在整个研究设计阶段,得到类似随机对照研究的效果。在观察性临床研究和RCT 研究亚组分析中,由于种种原因,导致偏倚和混杂变量较多,PSM 可以有效减少这些偏差和混杂变量的影响,以便对观察组和对照组进行更合理的比较。目前,PSM 分析在医学、公共卫生、经济学等领域应用广泛。
例如,某研究者想开展吸烟对于大众健康影响的研究,这时候往往会采用观察性研究设计,而不是随机对照研究设计。因为如果要开展随机对照试验,须要把研究对象随机分为吸烟组和不吸烟组,这种临床试验不符合科研伦理,无法实施。但面对容易获得的观察研究数据,如果不加调整,很容易获得错误的结论,比如拿吸烟组健康状况最好的一些人和不吸烟组健康状况最不好的一些人作对比,可能会得出吸烟对于健康并无负面影响的结论。从统计学角度分析,这是因为观察研究并未采用随机分组,无法基于大数定理的作用,在观察组和对照组之间削弱混杂变量的影响,很容易产生系统性的偏差。而PSM 可以解决这个问题,消除组别之间的干扰因素。
2 PSM 的应用条件
如前所述,PSM 是一种统计分析方法,主要用于处理研究组之间的不匹配或不可比的问题。PSM 分析的核心思想是控制偏倚,提高研究组之间的可比性。相比于常规的偏倚控制方法,如限制研究对象、随机化分组、匹配、分层分析、多因素分析等,PSM 能考虑更多匹配因素,提高研究效率。
PSM 的应用基于临床研究设计类型,目前主要用于描述性临床研究、分析性临床研究和RCT 临床试验研究亚组分析。PSM 的应用条件主要考虑如下两种情形:①在观察性研究和RCT 临床试验研究亚组分析中,分组间的样本量比超过1 ∶4 范围,非暴露组与暴露组直接比较的个体数量差异较大。在这种情形下,根据一定条件,选出非暴露组与暴露组交集,将这2 个可比性好的子集进行比较,可减少Ⅰ类错误增加,使研究结论更可靠。②尽管分组间在样本量比例接近1 ∶1,但衡量个体特征的参数很多,若组间存在不均衡和不可比情况,从暴露组中选出1 个跟非暴露组在各项参数上都相同或相近的子集作对比则更为可取。
3 PSM 在SPSS 软件中的实现
在应用SPSS 软件开展PSM 分析之前,研究者应提前做好如下3 个方面内容的准备:首先,研究者须安装SPSS 23.0 及以上的软件版本,较低版本的SPSS 软件无PSM 功能;其次,研究者应根据研究目的,确定暴露因素和结局变量,并确认后续分析的研究类型,如病例对照研究、队列研究或RCT 研究亚组分析;最后,在确定的研究设计类型、暴露因素和结局变量的基础上,先开展单因素分析,结合因果判定原则及有向无环图(directed acyclic graph, DAG)判定方法,找出须要匹配控制的变量。为更好地解释PSM 在SPSS 软件中的实现,本文引用项目团队前期开展的“母亲孕期二手烟暴露对新生儿低出生体重影响的队列研究”[2]举例说明。
如图1 所示,“母亲孕期二手烟暴露对新生儿低出生体重影响的队列研究”数据库主要包括9 个变量,其中暴露因素为母亲孕期二手烟暴露,结局变量为低出生体重(<2 500 g),潜在须控制的协变量包括婴儿性别、母亲年龄、母亲文化程度、家庭收入、妊娠期糖尿病史、孕前BMⅠ指数和婴儿分娩孕周。通过单因素分析(协变量分别与暴露因素、结局变量之间的分析),结合因果判定原则及DAG 判定方法,最终确定本研究应进行匹配的变量包括:母亲年龄、孕前BMⅠ、孕期妊娠糖尿病病史、母亲文化程度。
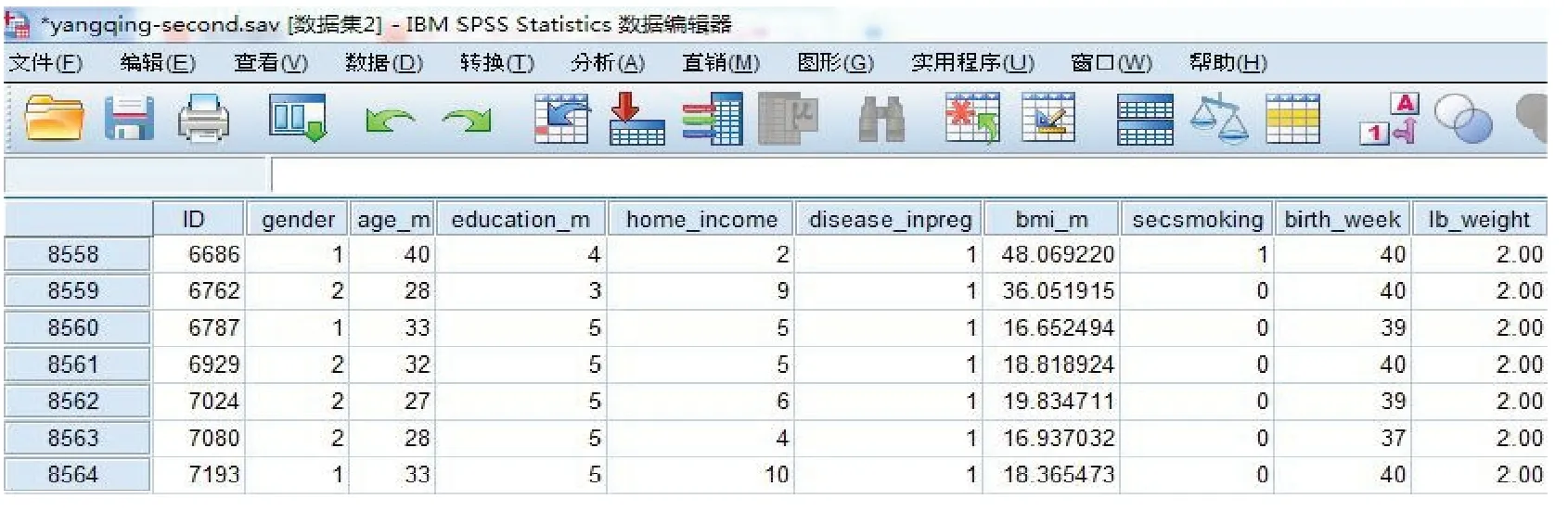
图1 母亲孕期二手烟暴露对新生儿低出生体重影响的队列研究数据库
在确定暴露因素、结局变量和须匹配的变量后,打开SPSS 23.0 软件。如图2 所示,选择“数据菜单→倾向得分匹配”后打开对话框,在“组指示符”框放入暴露因素变量,在“预测变量”框放入待匹配的变量;然后,在“倾向变量名”框定义新的“倾向性评分变量”,在“匹配容差”框中设置匹配精度条件,取值范围为[0, 1],数值越小,匹配的精度越高,但难度也相应越大;随后,在“个案ⅠD”框放入原始数据库的个案编号,在“匹配ⅠD 变量名”中定义新数据库中匹配成功对象的编号,在“输出数据集名称”中定义匹配后数据库的名称;最后,在完成上述操作后点击“选项”按钮,打开新的对话框。
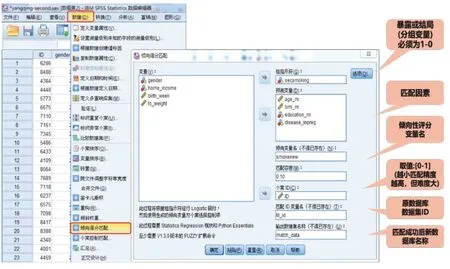
图2 PSM分析在SPSS软件中的操作步骤(一)
如图3 所示,在“合格个案变量”框中定义变量名,用于展示匹配成功的个数;同时,在“抽样”中选择“不放回”,勾选“最优化执行性能”和“抽取匹配项时随机排列个案顺序”;最后,在“随机数种子”中填入数字,以保证PSM 过程的可重现性。完成上述操作后,点击“继续→确定”按钮,即完成PSM 分析。须注意的是,第一次打开运行PSM 时可能不成功,可先运行其它功能,如使用数据菜单中PSM 下方的“个案控制匹配”,填写并运行,随后再打开PSM 即可成功。
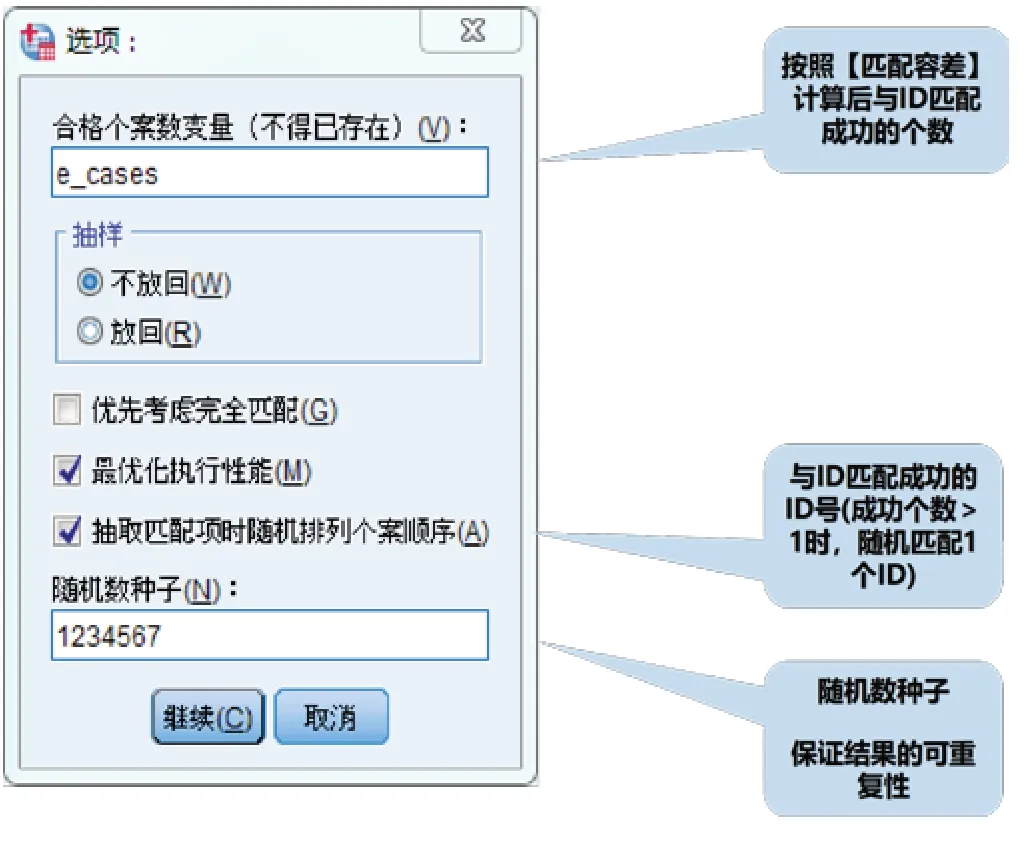
图3 PSM分析在SPSS软件中的操作步骤(二)
如图4 所示,匹配成功的“match data”数据库新增3 列数据:第1 列为基于匹配因素计算的倾向性得分情况;第2 列为按照匹配容差与原始ⅠD 匹配成功的个数;第3列为匹配成功后变量的新编号。
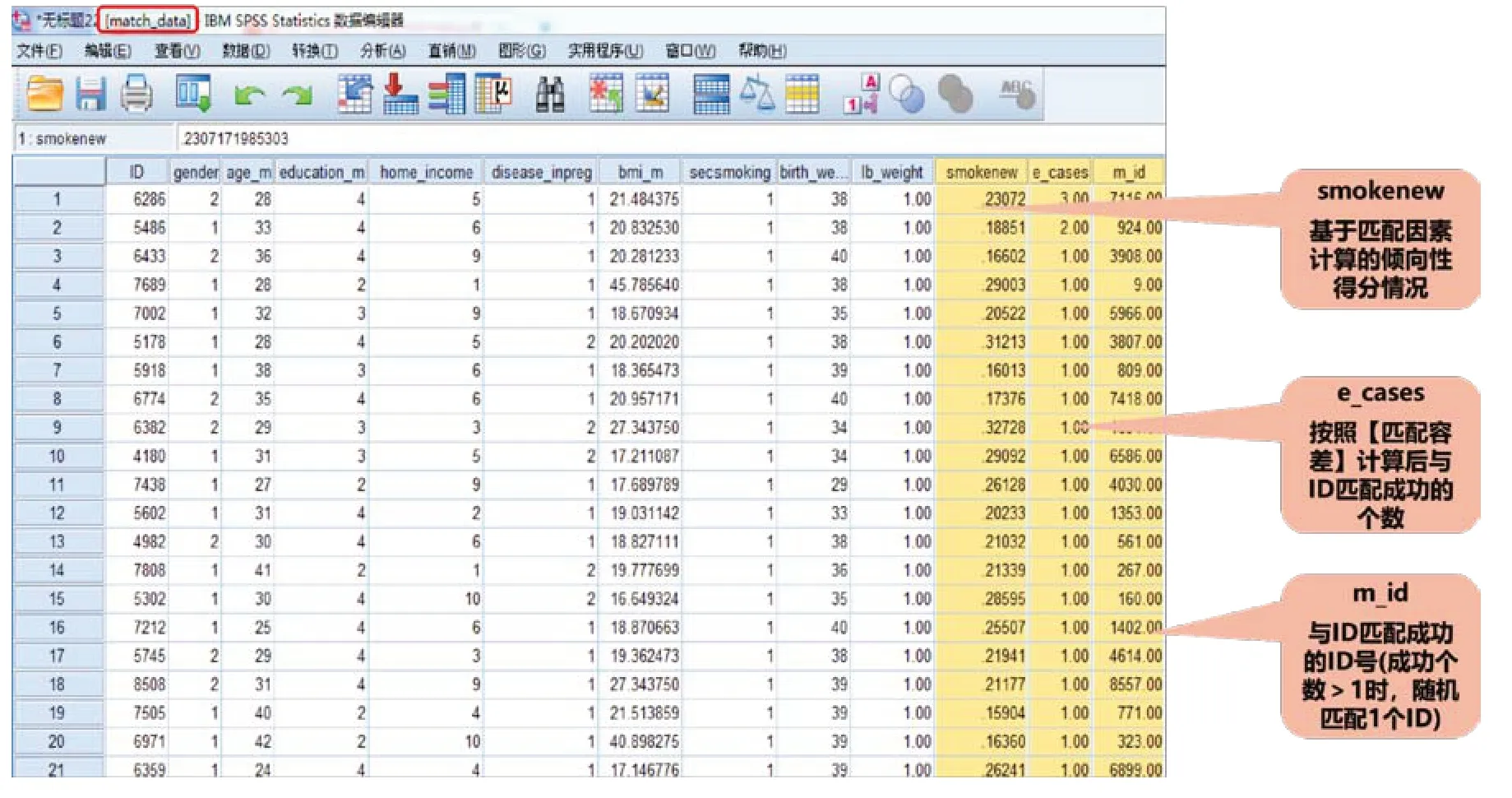
图4 PSM分析后输出的数据库
如图5 所示,经PSM 分析后,共计成功匹配1 785对个案。其中,依据前面设定的匹配容差完成“完全匹配”的有1 对,“模糊匹配”的有1 784 对。须特别指出的是,研究者在开展PSM 分析时,须对“匹配容差”进行调整测试,在保证匹配成功对数的情况下,尽可能选择“完全匹配”占比较高的数据库纳入最后的统计分析。
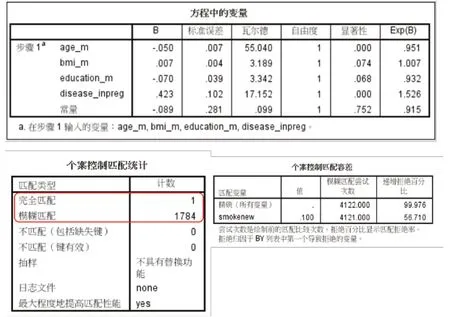
图5 PSM分析结果
猜你喜欢
实用心脑肺血管病杂志(2023年12期)2023-12-14
园林科技(2021年3期)2022-01-19
河池学院学报(2021年1期)2021-07-10
心电与循环(2020年1期)2020-02-27
英语文摘(2019年2期)2019-03-30
中华手工(2018年6期)2018-07-17
时代人物(新教育家)(2017年10期)2017-12-18
海外华文教育(2016年5期)2016-06-15
文学自由谈(2016年3期)2016-06-15
中国卫生(2015年7期)2015-11-08
