
适用于室内动态场景的视觉SLAM算法研究
2022-08-01 04:21冯一博张小俊王金刚
燕山大学学报 2022年4期
冯一博,张小俊,王金刚
(河北工业大学 机械工程学院,天津 300130)
0 引言
近年来,同步定位与地图构建技术(Simultaneous Localization and Mapping,SLAM)[1]作为高精度地图的代表被广泛应用到智能汽车领域。智能汽车SLAM问题可以描述为:智能汽车从未知环境的未知地点出发,在移动的过程中,通过传感器信息定位自身的位置和姿态,进而构建增量式地图,使智能汽车达到同步定位与地图构建的目的。因此,SLAM技术的发展会极大地影响智能汽车的发展,研究智能汽车SLAM技术具有一定的实际意义。
1986年由Smith Self 和Cheeseman首次提出SLAM技术,截止目前已经发展三十多年,主要经历了三个发展阶段。第一个阶段是传统阶段:SLAM问题的提出,并将该问题转换为一个状态估计问题,利用扩展卡尔曼滤波[2]、粒子滤波[3]及最大似然估计[4]等手段来求解。将视觉同步定位与地图构建问题转换为一个状态估计问题,传统阶段的传感器主要依据就激光雷达为主,该阶段的缺陷在于忽略了地图的收敛性质,把定位问题与地图构建问题分开处理。第二个阶段是算法分析阶段(2004-2015):2007年A. J. Davison教授提出的MonoSLAM[5]是第一个实时的单目视觉SLAM系统,但它不能在线运行,只能离线地进行定位与建图;同年Klein等人提出了PTAM[6](Parallel Tracking and Mapping),该算法虽然第一个使用非线性优化作为后端并且实现了跟踪与建图过程的并行化,但是它只适用于小场景下,而且在跟踪过程中容易丢失;2015 年MurArtal 等人提出的ORB-SLAM[7]是 PTAM 的继承者之一,它围绕ORB特征进行位姿估计,以词袋模型的方式克服累积误差问题,但它在旋转时容易丢帧。第三阶段就是鲁棒性-预测性阶段(2015-):鲁棒性、高级别的场景理解、计算资源优化、任务驱动的环境感知等,这些都伴随着人工智能技术的发展,让深度学习逐渐融入到视觉SLAM之中。而在SLAM系统中,当一个新的帧到来时,通过应用YOLO[8]、SSD[9]、SegNet[10]、Mask R-CNN[11]等先进的CNN结构,可以获得特征的语义标签。文献[12]使用目标检测网络SSD来检测可移动的物体,如人、狗、猫和汽车。文献[13]使用YOLO来获取语义信息,他们认为总是位于运动物体上的特征是不稳定的,并将其过滤掉。文献[14]使用SegNet在一个单独的线程中获得像素语义标签,如果一个特征被分割成“人”,则使用外极几何约束进行进一步的移动一致性检查;如果检查结果是动态的,那么语义标签为“person”的所有特征都将被分类为动态并被删除。这种方法实际上是将带有标签“person”的特征作为一个整体来处理,并且取两个结果的交集:只有在语义上和几何上都是动态的特征才被认为是动态的。文献[15]结合了Mask R-CNN和多视图几何的语义分割结果,将语义动态或几何动态的特征都被认为是动态的。
传统的视觉SLAM在建图的过程中,需要考虑两方面,一方面如何依据拍摄的图像序列估计车辆的运动轨迹,另一方面如何在三维场景中构建几何结构。而解决SLAM问题的关键是从获取的环境图像中快速提取精确特征,描述相机环境的局部特征,最后计算空间三维坐标和其他信息实现视觉的自主定位和地图构建。
特征是图像信息的另一种表达方式,特征点是图像中一些特别的地方,所以需要特征点在相机运动之后保持稳定,而传统的特征提取方法,如著名的SIFT[16]、SURF[17]、ORB[18]等在复杂环境下,容易受灰度值、动态物干扰,面对图像时会出现性能下降。因此,在传统的特征点提取中加入了语义信息,改进了SLAM系统,主要内容包括:
1) 深度学习与特征提取相结合,本文选用YOLO v3端对端的目标检测方法,准确识别地下车库中的动态物体,并且算法适应地下环境变化,有效提取图像特征。
2) 能够过滤出动态物体,快速提取稳定的局部特征点进行帧间匹配、位姿估计,提高了SLAM定位精度,增强车辆在地下出库场景中的环境感知。
1 基于YOLO v3与ORB-SLAM2的动态建图算法
本文算法依托ORB-SLAM2[19]为主体框架,视觉前端的特征点提取融合了深度学习的算法,通过分割图像中的静态和动态特征并将动态部分视为离群值,可以提高SLAM算法的鲁棒性。根据选择性跟踪算法,在视觉前端中计算出静态特征点,进行姿态估计和非线性优化,可以避免动态物体的干扰。图1给出了本文SLAM的主体框架。

图1 算法流程图Fig. 1 Algorithm flow chart
1.1 目标检测原理
YOLO v3主干网络由Darknet-53构成,它利用53个卷积层进行特征提取,而卷积层对于分析物体特征最为有效。
在前向过程中,YOLO v3输出了3个不同尺度的特征图:y1,y2,y3,其中y1检测大型物体,y2检测中型物体,y3检测小型物体,输出特征图输出维度为
R=N×N(3×(4+1+M)),
(1)
其中,N×N为输出特征图格点数,3表示每个特征图y一共3个锚框,4表示4维的检测框位置(tx,ty,tw,th),1表示检测置信度1维,M为分类个数。
在反向过程中,预测框共分3种情况:正例、负例、忽略样例。损失函数[20]为3个特征输出图的损失函数值和,分别为置信度损失、分类损失和定位损失。置信度损失用于优化框架的准确性,分类损失用于优化检测和分类,定位损失用于优化中心点坐标和宽度检测框。
损失的计算:
L(O,o,C,c,l,g)=λ1Lconf(o,c)+
λ2Lcla(O,C)+λ3Lloc(l.g)
(2)
其中,λ1,λ2,λ3为平衡系数。Lconf(o,c)为置信度损失,Lcla(O,C)为分类损失,Lloc(l,g)为定位损失。
置信度损失:
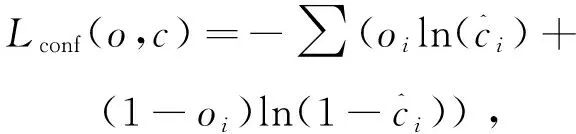
(3)
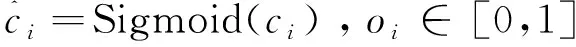
类别损失:
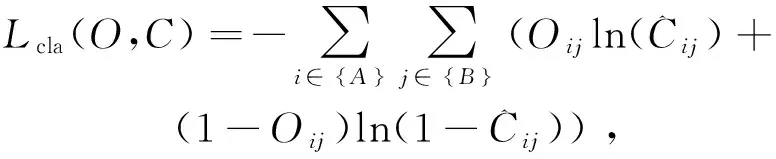
(4)
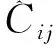
定位损失:
(5)
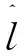
1.2 动态特征点剔除
图2是动态目标剔除算法的整体框架图,它在传统的视觉前端加入了一个并行线程:YOLO v3模块。本文使用的YOLO v3目标检测方法能够输出3个特征图,分别用于检测大型和中小型物体;并且自制了地下车库VOC数据集,标注了可能移动的类(汽车、人、自行车、公共汽车等),之后对测试集进行训练,得到预训练权重,这样能够更好地检测识别出地下车库中的动态目标,从而剔除动态特征点。
图2 动态目标剔除算法框架Fig. 2 Dynamic target elimination algorithm framework
1.3 轨迹重建
优化的算法主体框架与ORB-SLAM2相当,它可以说是ORB-SLAM2的延伸,主要是由跟踪线程、局部建图线程与闭环检测线程组成。各个线程的主要任务如下:
1) 跟踪线程:根据目标检测传回的目标区域进行特征剔除,接着进行位姿跟踪。
2) 局部建图线程:最大的特点就是借助跟踪线程的关键帧,更新地图点和位姿,从而进行局部束极调整,最后对每一个匹配好的特征点建立方程,解出最优的位姿矩阵和空间点坐标。
3) 闭环检测线程:首先计算图像的词袋向量,根据词袋之间的相似度判断是否闭环,若闭环则使用闭环关键帧对地图点进行闭环融合处理,最终位姿通过本质图优化来校正累计误差。
进入跟踪线程的前提是需要对算法进行初始化,而初始化的关键就是通过评分的方式选取合适的基本矩阵(Fundamental)或者单应矩阵(Homograph)。由于跟踪线程中使用双目相机或者RGB-D相机可以对一些3D点进行恢复,因此,单帧可创建关键点,关键帧;然而对于单目摄像头,恢复3D点只能借助时间序列上的两帧恢复。无论哪种相机,都需要借助评分选择一个更好的模型来初始化。
Fundamental模型评分:
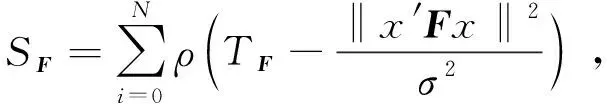
(6)
Homograph模型评分:
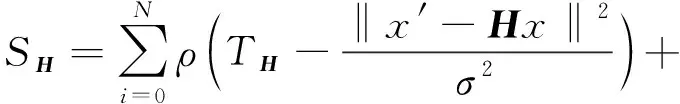
(7)
其中,当x≤0时,ρ(x)=0,当x>0时,ρ(x)=x。TF取固定阈值3.84,TH取固定阈值5.99。式(6)和式(7)中x′和x为同一个3D点在o和o′坐标系下坐标,F为基本矩阵,H为单应矩阵,i表示特征点序号,n表示特征点个数,σ为标准差。
两个模型的选择条件为
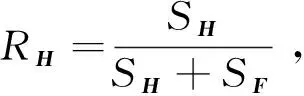
(8)
当RH≥0.45时,表示当前场景较为平坦并且视差较低,选择单应矩阵;其他的情况,选择基本矩阵。
局部建图线程主要是为了进行束极调整,先根据相机模型和A、B图像特征匹配好的像素坐标,求出A图像上的像素坐标的归一化的空间点坐标,然后根据空间点的坐标计算投影到B图像上的像素坐标,可以发现,重投影的像素坐标(估计值)与匹配好的B图像上的像素坐标(测量值)不会完全重合,这时候就需要束极调整。束极调整的目的就是对每一个匹配好的特征点建立方程,然后联立形成超定方程,解出最优的位姿矩阵或空间点坐标。
闭环检测线程主要由检测回闭环、计算Sim3、闭环融合以及优化本质图四个部分所组成。在闭环检测中,首先要求闭环与闭环之间必须超过十帧,然后计算当前帧与相邻帧之间的词袋得分,从而得到最小相似度,之后以最小相似度作为基准,若大于该基准则可能是关键帧,这就将闭环检测转变为一个类似于模式识别的问题,当相机再次来到之前到过的场景,就会因为看到相同的景物,而得到类似的词袋描述,从而检测到闭环。其次在计算Sim3中,单目系统中存在尺度的不确定性,因为针对一个三维点P来说,在单目拍摄的两幅中可以匹配到PL和PR,但是无法确定其在三角化里的具体位置,所以存在尺度模糊,而对于双目相机或者RGB-D相机,尺度可以唯一确定。之后闭环矫正是融合重复的点云,并且在共视图中插入新的边以连接闭环,接下来当前帧的位姿会根据相似变换而被矫正,与此同时所有与其相连的帧也会被矫正,矫正之后所有的被闭环处的关键帧观察到的地图通过映射在一个小范围里,然后去搜索它的近邻匹配,这样就可以对所有匹配的点进行更有效的数据融合。最后为了更好地完成闭环,将回环误差均摊到所有关键帧上,使用本质图优化所有关键帧的位姿姿态。
2 实验与分析
2.1 数据准备
采集制作含有动态目标的地下车库VOC数据,该数据集分为有车有人、有车无人、无车无人、无车有人4种情况。利用目标检测工具labelimg对采集的地下车库图片进行标注,分为person、car、bus、rider类,制作成VOC数据集。将数据集按照8∶1∶1的比例划分为训练集、验证集和测试集,即训练集包括3 200张图片,验证集和测试集各包括400张照片。
之后对测试集训练,用平均损失曲线以及平均交并比(Intersection Over Union,IOU)曲线作为训练的评价标准。由图3、4可以看出在经过40 000多次迭代后平均损失曲线接近于0.06趋向于拟合,平均交并比曲线代表预测的边界框和真实框的交集与并集之比接近于1,由此训练结果可以用来进行地下车库试验。
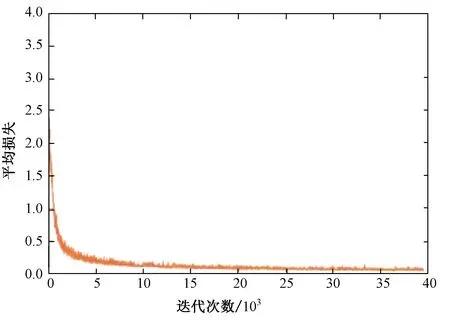
图3 平均损失曲线Fig. 3 Average loss curve
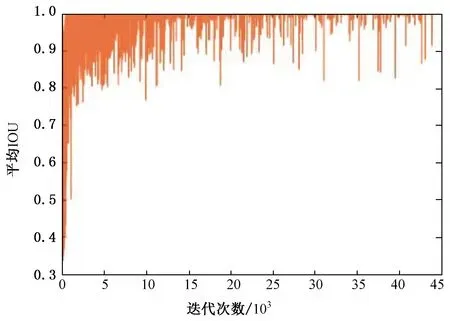
图4 平均交并比曲线 Fig. 4 Average IOU curve
2.2 检测验证
传统的视觉SLAM难以从平面像素中定义动态对象,也难以检测跟踪动态对象,因此,本文测试了ORB-SLAM2以及优化的SLAM的操作效果。
使用ORB-SLAM2的特征提取如图5所示,可以看出特征点集中在人车这些动态物上,ORB特征点大多是杂乱无章,并且对于SLAM的建图有很大影响,不但会增加冗余计算量、影响建图速度,甚至会产生漂移等影响。图6表示的是应用YOLO v3的目标检测方法进行的动态目标检测,图7表示的是识别全部的ORB特征点,图8表示的是动态特征点的剔除。

图5 ORB-SLAM2的特征提取Fig. 5 Feature extraction of ORB-SLAM

图6 YOLO v3的目标检测Fig. 6 Target detection of YOLO v3

图7 全部特征点的识别Fig. 7 Recognition of all feature points

图8 动态特征点的剔除Fig. 8 Removal of dynamic feature points
2.3 车库轨迹验证
地下车库数据集是由智能汽车平台搭载的RGB-D相机录制,数据集经历了3个场景,分别是静态场景、低动态场景、高动态场景。
用激光雷达算法LOAM测试完整个数据集,当作该数据集的真实轨迹图,图9展示了不同算法的运行轨迹,本文改进的SLAM算法相机轨迹估计比ORB-SLAM2更接近地面真实情况。在静态场景下,本文算法和ORB-SLAM2都贴近于真实轨迹;随后经历低动态场景,ORB-SLAM2产生了些许的漂移,根据回环校正,依旧可以跟踪上一帧,进行帧间匹配建图,然而到了高动态场景中,ORB-SLAM2算法中由于提取的特征点大多集中在车中,出现了严重的漂移,导致建图未能成功;相反改进的SLAM算法由于特征点提取范围从整幅图像缩小到非动态区域,能够进行有效的帧间匹配,完成建图。与ORB-SLAM2算法相比,改进的SLAM算法在动态场景中具有更强的鲁棒性,摄像机轨迹估精度也有很大提高。
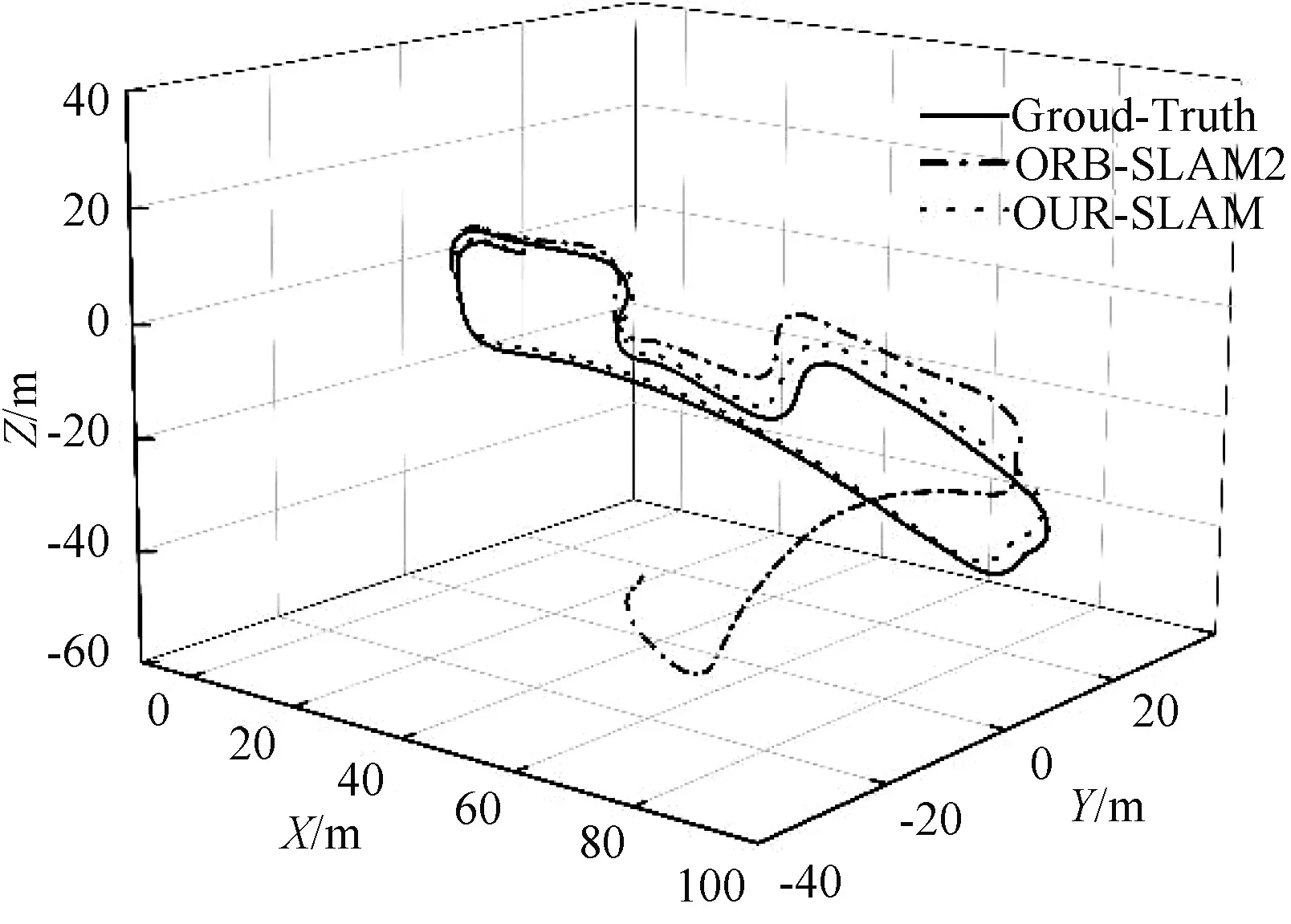
图9 不同算法的轨迹对比图Fig. 9 Trajectory comparison diagram of different algorithms
3 评价指标
对优化的SLAM算法评估可以从多个方面考虑,例如时耗、复杂度、精度。其中,算法对精度要求最高,本文采用绝对轨迹误差(Absolute Trajectory Error, ATE)和相对位姿误差(Relative Pose Error,RPE)两个精度指标。ATE被广泛用于定量评估,它评估两条轨迹之间的绝对姿态差,采用均方根误差(Root Mean Square Error, RMSE)、平均误差(Mean Error)、中位误差(Median Error)和标准差(Standard Deviation, SD)等指标进行测量。在这些指标中,RMSE和SD在反映视觉SLAM系统性能力方面更为重要。RMSE是测量误差的标准差,用ERMSE表示,它很好反映测量的精度,ERMSE越小,估计轨迹越接近地面真值轨迹。
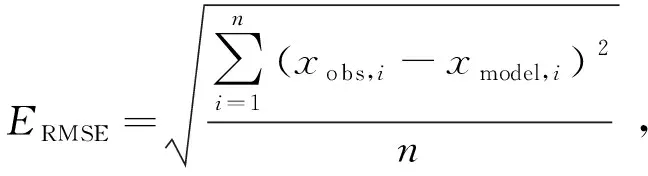
(9)
其中,n表示观测次数,i表示第i个关键帧,xobs,i表示第i个关键帧姿态的地面真实值,xmodel,i表示第i个关键帧姿态的观测值。
SD可以反映观测值的分散程度,用ESD表示
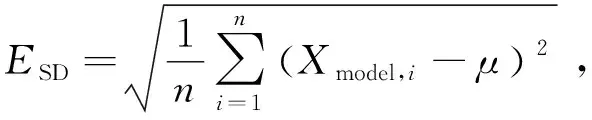
(10)
其中,n表示关键帧的数目,Xmodel,i表示第i个关键帧的观测姿态,μ是Xmodel,i的平均值。
ME是观测姿态与地面真值之间误差的算术平均值,用Emean表示:
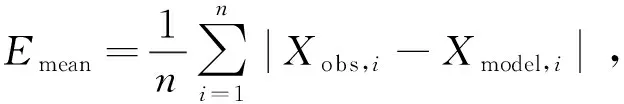
(11)
其中,n表示观测次数,i表示第i个关键帧,Xobs,i表示第i个关键帧姿态的地面真实值,Xmodel,i表示第i个关键帧姿态的观测值。
中位误差是观测姿态和地面真实值之间的误差的中间值。
RPE主要描述的是相隔固定时间差两帧位姿差的精度(相比真实位姿),相当于直接测量里程计的误差。因此第i帧的RPE定义如下:
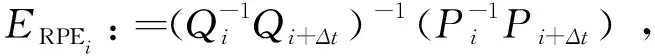
(12)
其中,Pi表示第i帧算法估计位姿,Qi表示第i帧真实位姿,Δt表示时间间隔t,Ei表示i时刻绝对或相对位姿估计误差。
采用ERMSE统计误差总体值:

(13)
其中,n表示观测次数,Δt表示时间间隔t,得到m,m=n-Δt×ERPE,Ei表示i时刻绝对或相对位姿估计误差,trans(Ei)代表相对位姿误差中的平移部分。
但是,在大多数情况下,Δt有许多选择,为了综合衡量算法的表现,计算遍历了所有时间间隔的ERMSE的平均值:
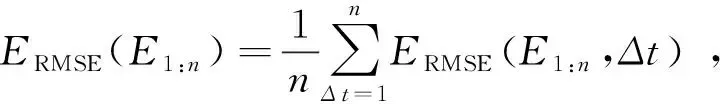
(14)
其中,n表示观测次数,Δt表示时间间隔t(t从1开始取直到观察结束n次为止),ERMSE表示均方根误差。
若遍历所有时间间隔,则存在计算复杂程度高、耗时问题,因此通过计算固定数量的RPE样本获取估计值作为最终结果。
采用系数K对比优化的SLAM算法与ORB-SLAM2的改进值:
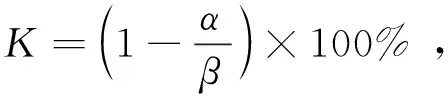
(15)
其中,α是优化的SLAM获得的值,β是ORB-SLAM2获得的值。
图10、11对ORB-SLAM2和优化的SLAM进行ATE评测:对比真值位姿,ORB-SLAM2的均方根误差为22.49 m,优化的SLAM的均方根误差为1.46 m,提升了93.50%;ORB-SLAM2的标准差为11.92 m,优化的SLAM的标准差为0.65 m,提升了94.53%。可以看出优化的SLAM算法漂移量以及分散程度明显优于ORB-SLAM2。
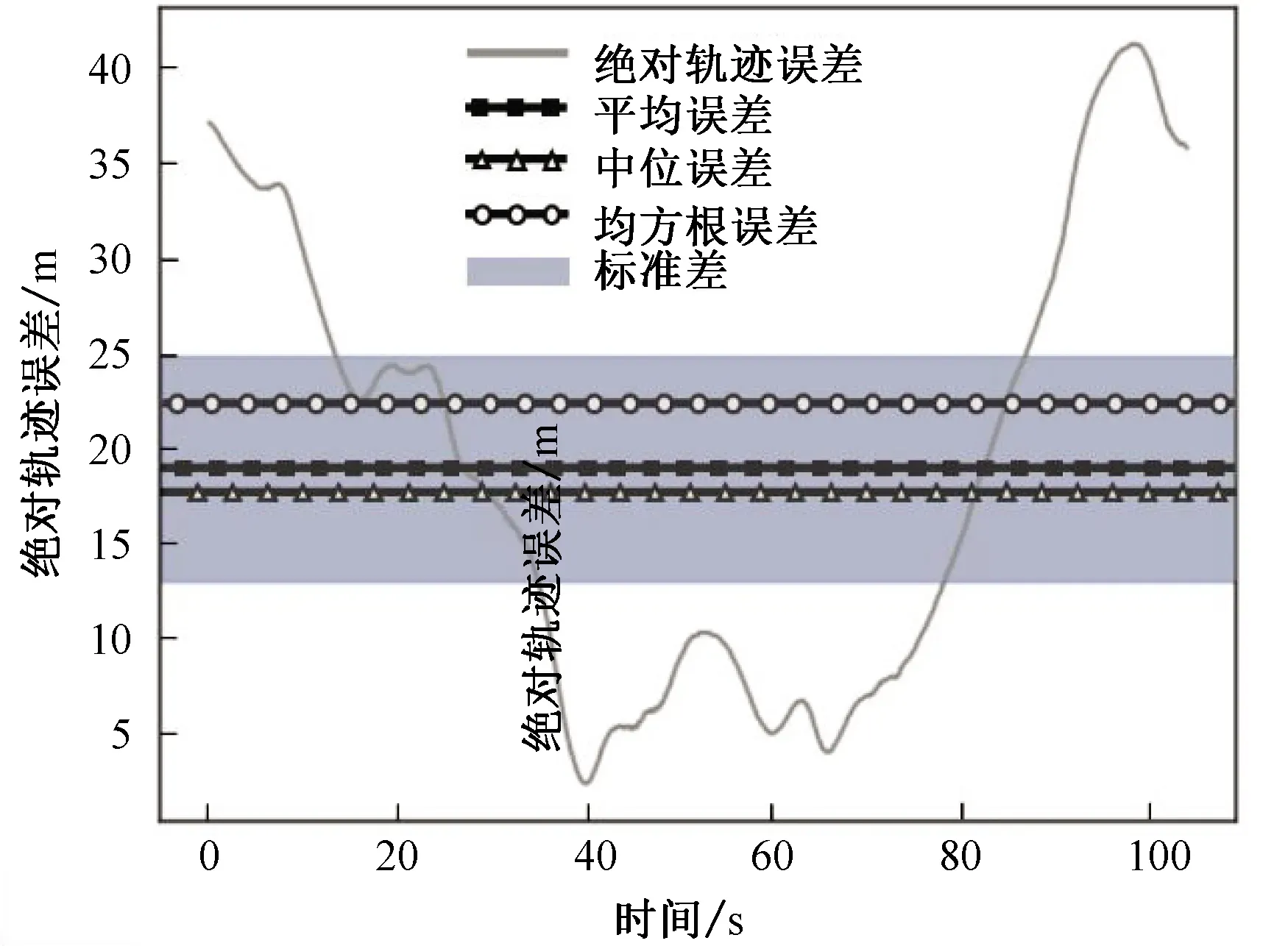
图10 ORB-SLAM2位姿与真值位姿之间的绝对轨迹误差Fig. 10 ATE between ORB-SLAM2 pose and true value pose
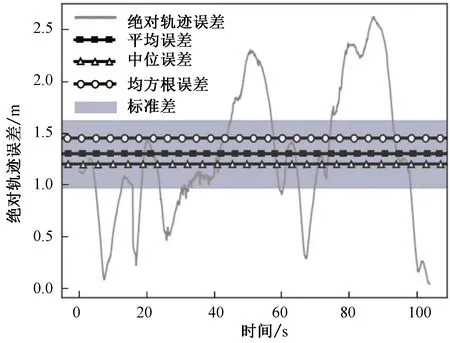
图11 优化的算法位姿与真值位姿之间的绝对轨迹误差Fig. 11 ATE between optimized algorithm and true value pose
图12、13对ORB-SLAM2和优化的SLAM分别进行RPE评测:对比真值位姿,ORB-SLAM2的均方根误差为0.24 m;优化的SLAM的均方根误差为0.040 8 m;提升了83.03%。可以看出,优化的SLAM算法漂移量明显低于ORB-SLAM2。

图12 ORB-SLAM2位姿与真值位姿之间的相对位姿误差Fig. 12 RPE between ORB-SLAM2 pose and true value pose
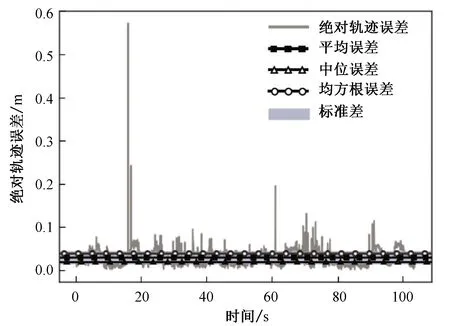
图13 优化的算法位姿与真值位姿之间的相对位姿误差Fig. 13 RPE between optimized algorithm and true value pose
4 结论
针对在地下车库光照不足,容易受动态物影响的问题,本文构造了一个完整的SLAM框架,提出了一种基于YOLO v3和ORB-SLAM2相结合的动态场景视觉SLAM算法。实验结果表明,在综合场景下本文提出的算法位姿估计精度相比于ORB-SLAM2提升了93.50%,改进后的算法大幅度提高了SLAM系统在动态环境下精度与鲁棒性,并且保证了实时性。
猜你喜欢
当代水产(2022年7期)2022-09-20
军民两用技术与产品(2022年3期)2022-06-05
纺织服装周刊(2022年16期)2022-05-11
物流科技(2022年2期)2022-05-07
现代计算机(2022年4期)2022-04-24
中国科技纵横(2020年13期)2020-12-11
现代信息科技(2020年22期)2020-06-24
山东工业技术(2019年16期)2019-07-19
软件导刊(2018年4期)2018-05-15
电脑知识与技术(2017年3期)2017-03-27
