
基于系统溯源图的威胁发现与取证分析综述
2022-08-04 03:38冷涛蔡利君于爱民朱子元马建刚李超飞牛瑞丞孟丹
通信学报 2022年7期
冷涛,蔡利君,于爱民,2,朱子元,2,马建刚,李超飞,2,牛瑞丞,2,孟丹,2
(1.中国科学院信息工程研究所,北京 100093;2.中国科学院大学网络空间安全学院,北京 100049;3.四川警察学院智能警务四川省重点实验室,四川 泸州 646000)
0 引言
当前,政府和企业面临着高级持续性威胁(APT,advanced persistent threat)[1]。震网攻击、极光漏洞先后发生,世界各国开始重视APT 攻击。传统的APT 攻击检测方法主要聚焦单步攻击检测,无法捕获系统长期运行行为,而APT 攻击大量应用零日漏洞,导致威胁检测困难。2015 年,美国国防部高级研究计划局提出4 年透明计算计划[2],希望找到一种高保真和可视化的方法来抽象出系统中的攻击活动。研究人员发现依靠系统监控日志数据构造具有较强抽象表达能力的溯源图进行因果关系分析,能有效表达威胁事件的起因、攻击路径和攻击影响,为威胁发现和取证分析提供较高的检测效率和稳健性[3]。Han 等[3]介绍了基于溯源图的入侵检测的机遇和挑战。Zafar 等[4]描述了安全溯源的生命周期,提出了现有安全溯源方案的分类方法,并指出了它们的优缺点。Tan 等[5]讨论了网络攻击溯源中数据源优化和数据关系分析两类文献,并围绕安全性、有效性(效能)、效率进行对比分析。Li 等[6]侧重讨论利用系统级溯源图构建攻击模型,进行威胁检测和调查。潘亚峰等[7]重点综述了APT 攻击场景重构方法。本文重点综述了基于溯源图的数据采集、数据管理(图构建、图缩减、图存储和图查询)、数据分析(威胁检测、威胁狩猎、取证分析)等工作。
本文贡献可概括为:1) 提出了基于溯源图的威胁发现和取证分析框架;2) 总结了多种场景下日志采集、数据缩减和存储方案;3) 分类总结了威胁检测、威胁狩猎、取证分析的研究方法和模型;4) 展望了下一步研究方向。
1 背景知识
1.1 溯源图
管理员通过系统审计或配置服务器可以获得多个层级的日志事件,如应用程序级、网络级、指令级和系统级[8]。应用程序级日志是应用程序产生的日志,如网站服务器等应用程序产生的日志。网络级日志可通过监控系统的网络访问获得,如Zeek捕获网络流量日志。指令级日志是指机器指令产生的日志,可提供完整信息,但很难理解。系统级日志是一串按时间顺序排列的事件元组,表示不同时间某进程(或线程)访问某个文件或网络连接的方式。Auditd、ETW 等内核级框架审计工具可获取系统调用事件日志。研究者将系统级日志事件抽象为溯源图表示[8]。
定义1溯源图。设定溯源图G=
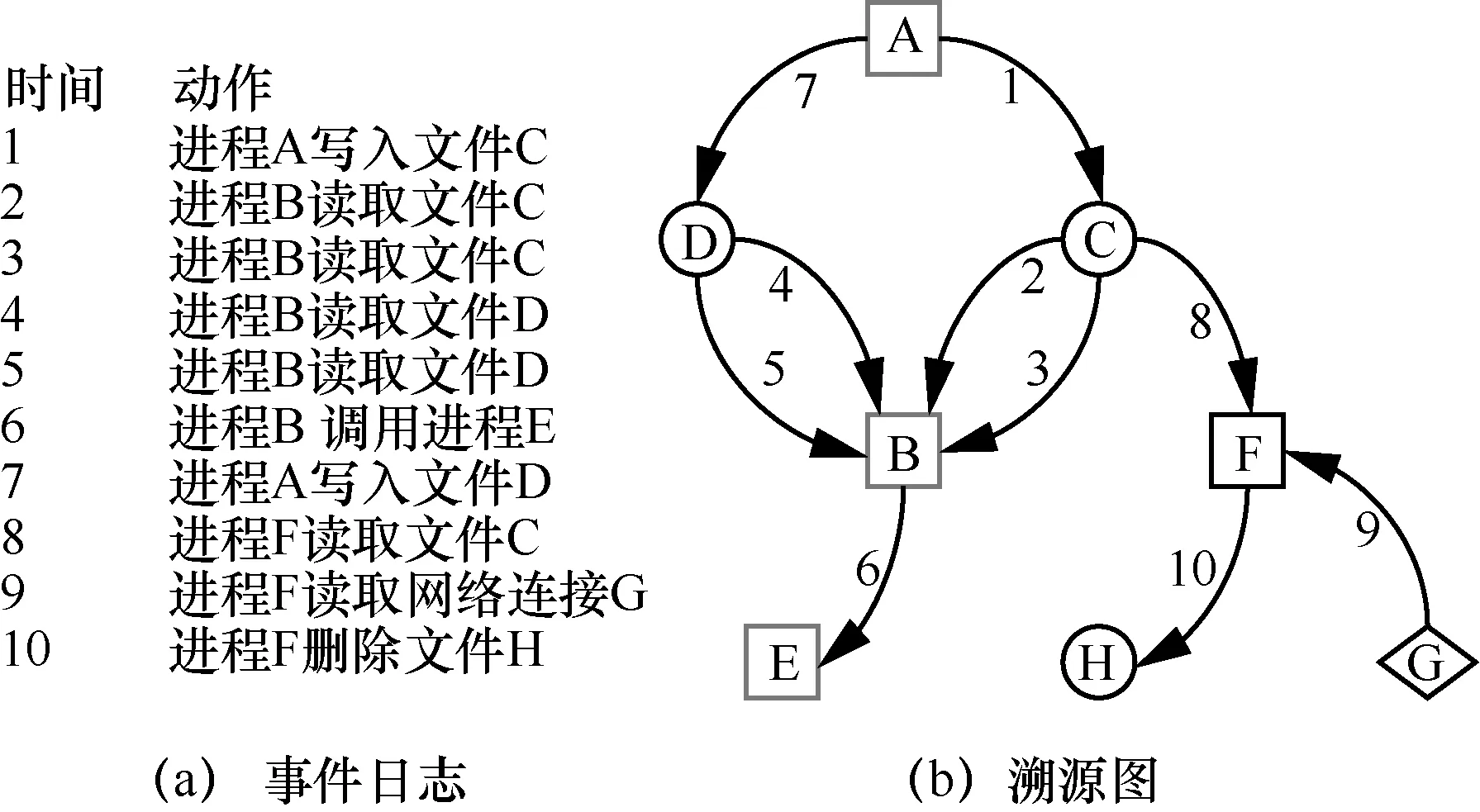
图1 事件日志与溯源图
图1(a)表示事件日志,图1(b)表示通过事件日志形成的溯源图。顶点代表系统中的实体,连接2 个顶点的边代表时间类型,箭头代表2 个实体之间的数据内容或控制信息的流动,边上的数字代表操作发生的时间(数字越小,事件发生越早)。
1.2 威胁检测
威胁检测用于分析整个安全生态系统,识别可能危及网络的任何恶意活动。威胁检测方法主要包括基于误用的检测和基于异常的检测[9]。基于误用的检测通过构建恶意样本特征进行检测,只能检测已知攻击;基于异常的检测通过构建合理行为的边界设置异常阈值,超过阈值则判断为异常。虽然基于异常的检测可判断未知攻击,但也导致了较高的误报率。APT 攻击是一种复杂攻击,跨度时间长,一般潜伏期可达半年,具有多步、隐蔽性等特点,单步检测效果不佳,研究者探索基于系统日志构造溯源图,利用规则、异常和学习等方法实现APT攻击威胁检测。
1.3 威胁狩猎
徐嘉涔等[10]将威胁狩猎定义为主动持续地在网络中搜索可以绕开安全检测或产生危害的威胁的过程。Valentina[11]将威胁狩猎定义为人为活动,通过反复搜索组织环境(网络、端点和应用程序)的妥协指标(IoC,indicator of compromise),以缩短停留时间并最大限度地减少入侵对组织的影响。常见的妥协指标包括恶意文件/进程名、病毒特征、僵尸网络的IP 地址和域名等。停留时间是指攻击侵入系统到被检测发现的时间。威胁狩猎的方法包括数据驱动、情报驱动、实体驱动、战略−技术−过程(TTP,tactic technique procedure)驱动、混合驱动5 种类型[12]。数据驱动是指查看已有数据来寻找内容,如利用代理日志查看不常见用户代理发现异常。情报驱动是指分析师利用威胁情报数据集,通过搜索和匹配威胁指标。实体驱动是指搜索关键知识产权和网络资源等高风险、高价值实体。TTP 驱动是指通过了解攻击者使用的战略、技术和过程,搜索已知的TTP,实现威胁狩猎。混合驱动是上述方法的融合。图2 展示了威胁狩猎的过程[13],其目的是缩短攻击停留的时间。
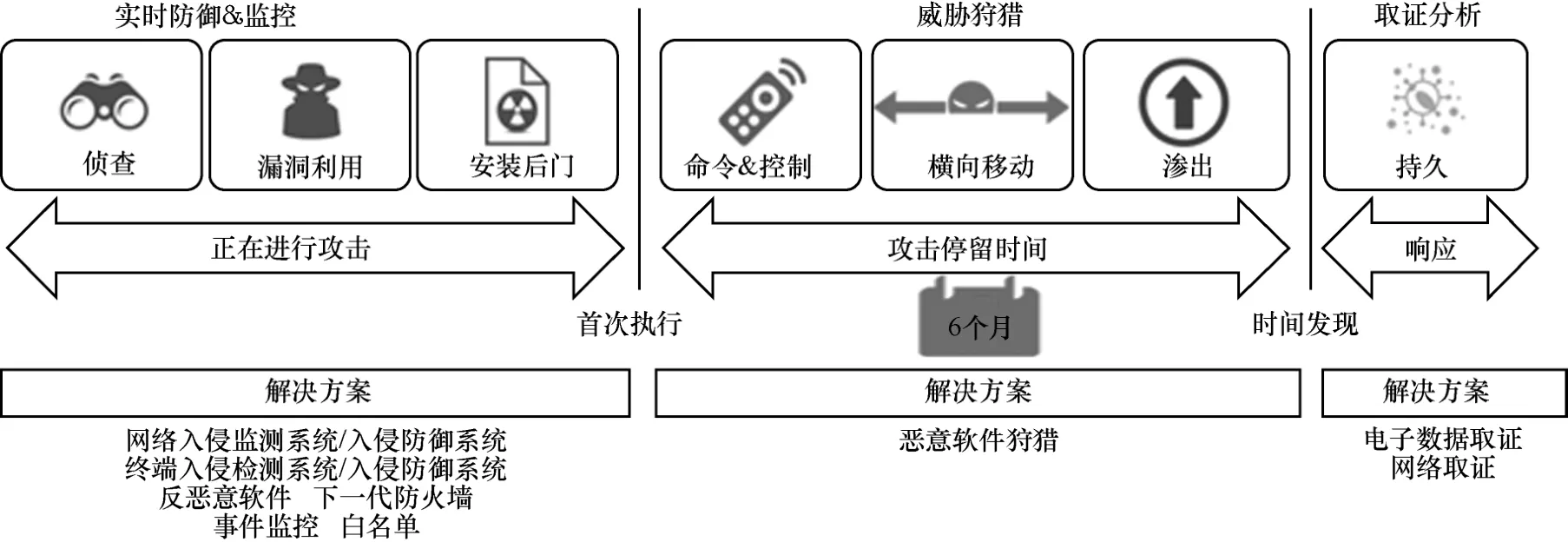
图2 威胁狩猎的过程
1.4 取证分析
取证分析概念包含的内涵较广,本文所述取证分析是指用户在发现其遭受网络攻击后,调查人员根据告警或攻击特征进行攻击溯源和攻击场景重建分析等。基于溯源图的取证分析的一般过程是在溯源图上找到攻击特征节点并执行后向查询,从而找到攻击入口点,然后根据攻击入口点执行前向查询,关联出攻击事件路径。此外,取证分析还考虑攻击场景重构,即从大量的日志数据中,根据特定的攻击行为模式和语义知识,通过分析数据之间的的关联关系,还原包含数据层攻击行为的语义信息和攻击战略战术、过程语义知识的完整攻击行为视图的过程[7]。
定义2后向查询。边e的后向查询是溯源图G的子图,表示从溯源图G 中某顶点执行逆向查询,可到达的目的顶点的边的集合。以图1 为例,假设进程E 被标记为可疑的,需要找到进程E的流入边,可以通过后向查询得到集合 {EBE−6,EDB−5,EDB−4,ECB−3,ECB−2,EAC−1},找到入口点A。注意边EAD−7不在E顶点的后向溯源边中,因为其发生时间晚于调查点E的时间。
定义3前向查询。边e的前向查询是溯源图G的子图,表示从溯源图G 中某顶点作为源顶点,执行正向查询可到达边的集合。以图1 为例,在找到攻击入口点A 后,如果要找到EAC−1的影响,执行前向查询,得到边集合为 {EAC−1,ECB−2,ECB−3,EBE−6,ECF−8,EFH−10}。
BackTracker[8]第一次引入溯源图用于入侵检测,开辟了终端主机攻击溯源的工作,通过定义终端主机进程之间、进程与文件之间以及进程与文件名之间的依赖关系来构造溯源图。攻击入口点是通过给定告警事件后向查询分析确定的,当系统中的一个实体被标记为可疑时,需要在溯源图中反复搜索其他实体对目标可疑实体的历史作用,直到该实体没有流入的边,从而确定攻击入口点。
2 研究框架
基于系统溯源图的威胁发现与取证分析包括数据采集、数据管理、数据分析3 个模块。数据采集模块包含不同场景下的数据采集;数据管理模块包括数据预处理、溯源图的存储和查询可视化;数据分析模块包括威胁检测、威胁狩猎和取证分析。威胁检测可应用于威胁狩猎的不同框架中,取证分析基于已发现的威胁开展取证调查和重建分析,整体研究框架如图3 所示。下面,详细介绍各模块的内容和方法。
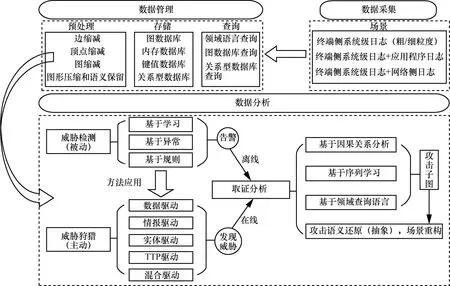
图3 整体研究框架
3 数据采集
3.1 数据采集方式
日志采集主要包括终端侧系统级日志、应用程序日志和网络侧日志等。
3.1.1 基于终端侧系统级日志采集
常见的终端侧系统内核级日志采集工具如Auditd、ETW、Dtrace 等。Lineage[14]是系统级溯源的首次尝试,该系统通过修改linux 内核调用,使用户进程从printk 缓冲区中读取捕获的内容并存储到SQL 数据库中。PASS[15]在虚拟文件系统层捕获溯源数据,PASSV1[15]提供了进程I/O 交互的函数,PASSV2[16]提供了一个跨语义层溯源集成的应用程序接口,但是系统版本的升级加大了这些方案的扩展难度。SPADE[17]是一个分布式系统日志审计工具,可支持跨平台应用。Hi-Fi[18]是第一个完整的全系统溯源,可收集完整溯源记录,除了内核和应用程序行为,还包括网络连接等;Hi-Fi 采用LSM HOOK 实现数据监控,不支持安全模式堆栈,因此容易受到攻击。Linux 溯源模块[19]创建了一个可信赖的溯源感知执行环境,解决了溯源数据可靠性限制,可收集整个系统的溯源数据。Bates 等[20]提出了DAP 捕获Web 服务组件的详细数据源,它是Linux溯源模块[19]的附加服务。CamFlow[21]是一个严格意义上的独立框架,实现了系统级日志的采集,它使用标准的内核功能,并且容易扩展。
3.1.2 基于终端侧系统级日志+应用程序日志采集
虽然系统级日志展现了进程、文件、网络连接之间的依赖关系,但与应用程序日志相比,系统级日志从系统层面挖掘系统行为的因果依赖关系没有考虑应用层语义,存在语义鸿沟问题;对于攻击取证分析,应用程序日志能提供大量的攻击相关信息,如OmegaLog[22]和ALchemist[23]尝试融合系统级日志记录和应用程序日志记录,实现语义还原。
3.1.3 基于终端侧系统级日志+网络侧日志采集
由于APT 攻击通常跨越多个主机,基于终端侧系统级日志和应用程序日志不能完全捕获数据,因此研究者探索将系统监控审计数据与网络侧数据相结合[24-27]。虽然PASS[15]可以支持使用网络文件系统来收集溯源日志,但不支持收集访问本地机器的套接字信息。例如PASS 不能记录通过远程攻击破坏或窃取本地IP 地址和端口号的行为。PDMS[24]对PASS 进行了扩展,通过监控和记录每一个网络会话,捕获连接到本地主机的每一个网络套接字,并将网络套接字视为文件对象,收集文件、管道、进程和网络套接字之间的依赖关系,准确地跟踪系统的数据流入和流出。Haas 等[25]提出了开源平台Zeek-Osquery,将操作系统级日志与网络侧日志实时关联,实现实时入侵检测,然而这种级别的跨主机攻击溯源依然会因为套接字的不确定性而存在大量的错误关联。Ji 等[26]综合了多种技术,提出了一种有效的跨主机追踪溯源方法RTAG,可以在一定程度上解决当前网络侧与终端侧数据无法关联溯源的问题。
3.2 数据采集粒度
根据系统级日志采集数据粒度不同,数据采集分为粗粒度和细粒度[5]采集。粗粒度采集是指仅追踪系统级对象(进程、文件),是一种进程级调用监控或对内核模块安装钩子进行数据拦截的方法。系统级溯源可通过系统内置审计组件监控获得。细粒度采集的目标是实现精确依赖关系,比系统进程级追踪粒度更细,常采用进程执行单元分区[28]、污点分析追踪变量变化等。一个进程可以被“分割”成多个单元,每个单元分区是一个进程的执行段,处理一个特定的对象,例如浏览器进程可根据打开的网页窗口进行划分。Lee 等[28]首先提出基于进程执行单元分区的方法,由于追踪变量的污点分析粒度太细,不适合构造因果溯源图,因此提出在进程级粗粒度和变量级细粒度之间的“单元”概念。ProTracer[29]利用基于单元的执行分区来提高压缩率,将程序划分为多个单元,以实现细粒度的污点跟踪,其中一个单元对应一个循环模式。MP[30]要求软件开发者对应用程序中的重要数据结构进行注释,通过注释实现单元划分。这些技术都依赖于源代码或二进制工具[31]。LogGC[32]引入程序工具,输出细粒度的依赖信息,不仅可以将一个进程分成多个可执行单元,还可以把一个数据文件分成多个逻辑数据单元,但其对每个应用程序的定制成本太高。UIScope[33]也借鉴单元分区的方法实现了了细粒度采集日志。
3.3 数据集
3.3.1 开源数据集
研究APT 攻击检测和取证分析的常用开源数据集有StreamSpot[34]、CERT[35]、LANL[36]、DARPA TC 系列[37-38]、OpTC[39]等。Manzoor 等[34]开源了StreamSpot 数据集,该数据集包含一个攻击和5 个普通应用场景,数据集较小,常用于对比实验[40]。CERT[35]数据集是内部威胁检测数据集,该数据集模拟恶意内部人员实施系统破坏、信息窃取、内部欺诈等攻击行为数据。LANL[36]数据集描述了一个攻击团队所进行的恶意活动,该数据集在威胁检测场景中主要用于模拟APT 攻击检测[40-43]。OpTC 数据集是DARPA TC 数据集的最新迭代,SK-Tree[44]使用该数据集进行测试。DARPA 透明计算系列提供对APT的实时检测和取证分析[23,44-53]。目前开源了DARPA TC3和DAPRPA TC5 这2 个数据集。Berrada 等[51]从DARPA TC2和DARPA TC3 中选择部分数据构造了adaptdata 数据集。Benabderrahmane等[52]基于此数据集提出基于规则的高级威胁检测方法。DAPT 2020[54]提供了APT 攻击的详细阶段,并对攻击样本打了标签,但检测模型的准确率很低,需要研究新的检测模型。
3.3.2 复现实验捕获数据集
由于APT 攻击复杂,有关APT 检测的开源数据集较少。以往的研究除了在开源数据集上检测模型,还通过自主设计实验或利用安全企业采集的数据进行分析,自主实验一般复现APT 攻击报告,自主采集日志生成数据集。常见的复现实验有数据窃取、钓鱼邮件[23,53,55]、破壳漏洞[56]、后门[29]、文件传送[57]、哈希传递攻击[53]和错误配置[29]等。
4 溯源图数据管理
APT 攻击潜伏期较长,企业需要保留半年以上的日志数据。据统计,每天每台电脑监测产生的日志超过1 GB[58],存储负担重,不利于后续查询和分析工作,因此需要对数据进行预处理,减少数据存储,同时也考虑保证攻击语义的完整性。
4.1 溯源图缩减与压缩
溯源图缩减主要围绕边缩减、顶点缩减、图缩减、图形压缩和语义保留等进行研究,溯源图缩减方法如表1 所示。
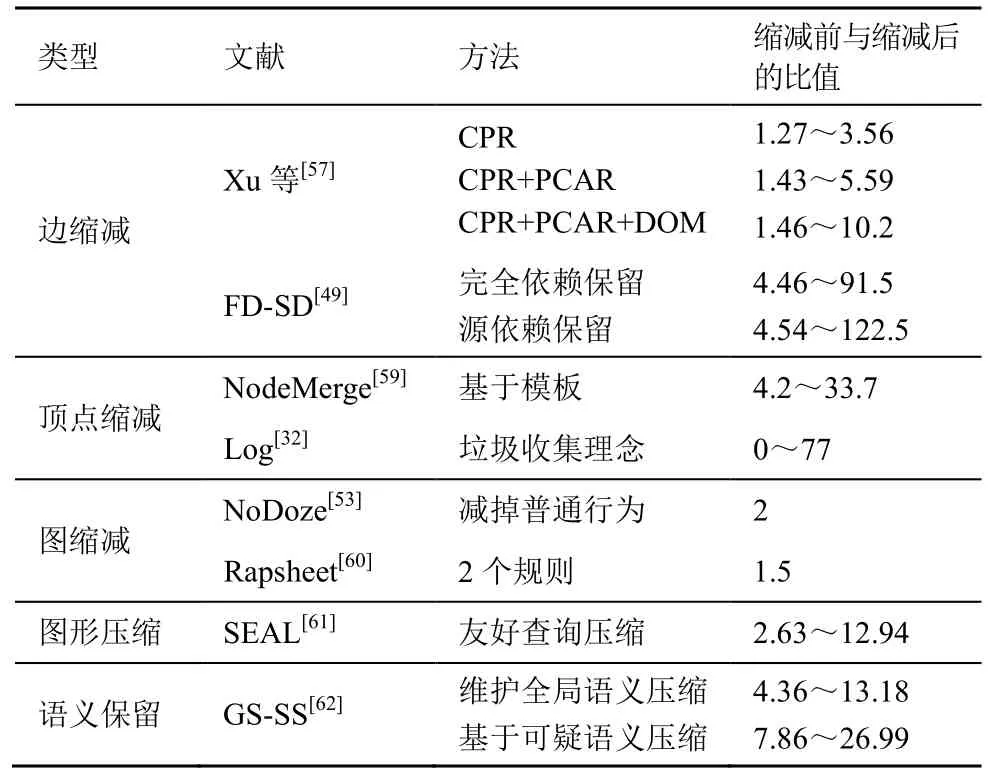
表1 溯源图缩减方法
4.1.1 边缩减
Xu 等[57]根据系统事件之间因果关系的等同性来减少日志条目的数量,提出了因果关系保全缩减(CPR,causality preserved reduction)、以进程为中心的因果关系逼近缩减(PCAR,process-centric causality approximation reduction)和基于领域知识缩减(DOM)的方法。CPR 聚合依赖性相同的事件,虽然能保留图的网络拓扑结构,但会丢失统计信息,如访问频率等。某些系统行为会导致对象和其相关邻居形成密集连接的依赖图,因此该研究提出一种保留因果关系的单跳图缩减技术PCAR,这种方法会删除与目标文件无关的重复读/写操作。基于领域知识的缩减主要是删除临时文件等。临时文件是指在其生命周期中只与一个进程有信息交换,在攻击取证中也不引入任何明确的信息流,因此可以从数据中删除所有临时文件的事件。CPR 保留了语义信息,但缩减效率有限,为进一步压缩,Hossain 等[49]提出了完全依赖保留缩减(FDPR,full dependence preserving reduction)和源依赖保留缩减(SDPR,source dependence preserving reduction)。FDPR 在缩减数据的同时保留完全依赖性,而SDPR 在FDPR基础上只考虑保留前向依赖关系,进一步提高缩减效率。但FDPR和SDPR 均放宽了因果关联的条件,使更多的重复事件可以被修剪,同样当查询有时间限制时,也可能引入假阴性。
4.1.2 顶点缩减
LogGC[32]关注对象的生命周期,引入垃圾收集理念。由于许多应用程序在执行期间会产生临时文件,这些文件在应用程序终止后会被销毁,而系统不会受到这些文件的影响,因此可将这些文件当作垃圾进行收集以节省空间。但如果删除的临时文件与网络套接字有关,攻击者所做的渗透攻击窃取数据文件可能会被遗漏。NodeMerge[59]提出了在线数据缩减方法,通过自动学习固定的库和运行程序的只读资源集作为模板,并进一步使用这些模板来缩减系统事件数据。NodeMerge 在大数据分析处理等只读事件多的缩减任务很有效,但是对于那些没有加载很多文件或在初始阶段有文件访问模式的应用程序,其缩减效果不明显。
4.1.3 图缩减
PrioTracker[55]优先考虑异常依赖关系的边,NoDoze[53]将该方法推广到异常路径而不是单条边,可将原始图的大小减小2 个数量级,加快了调查速度,不会丢失攻击的重要信息。然而,基于异常的方法需要有代表性的训练数据,训练数据的问题可能导致假阳性、假阴性。Rapsheet[60]提供2 条图缩减规则,为保证完成警报规则匹配,时间间隔必须足够长。该研究提出了可以获得更好压缩效果的一般方法,但该压缩方法需要将整个依赖图作为输入,不能处理实时流数据。
4.1.4 图形压缩
LogGC[32]、FD-SD[49]、CPR[57]和NodeMerge[59]等方法都是采用匹配预定义的模式去掉日志,实现有损压缩,虽然实验表明其因果关联具备有效性,但不能保证所有任务都能得到正确结果。无损压缩可以保存所有信息并支持因果关系分析。SEAL[61]通过系统日志生成依赖图,并对图的结构(如顶点和边)进行无损压缩,然后对边的属性(如时间戳)进行无损压缩,确保每次查询都能得到正确的回答,同时保证查询效率。
4.1.5 语义保留压缩
Zhu 等[62]提出基于通用、高效、实时的数据压缩方案,包含维护全局语义(GS,global semantics)和可疑语义(SS,suspicious semantics)2 种压缩策略。维护全局语义的数据压缩策略是确定并删除不影响全局依赖的冗余事件。GS 策略的思想是假设在源顶点的语义没有改变的情况下,信息流对同一目标的影响是等价的,等价的事件可以作为冗余被删除,只需保留对目标顶点有影响的第一个事件。在溯源图中,一个顶点没有传入边时,可以认为该顶点的语义没有发生变化,其传出边的语义也没有发生变化。基于可疑语义的数据压缩策略是根据取证分析的目的恢复攻击链。SS 策略的思想是通过使用实体上下文,自动判断该事件是否与攻击有关,与攻击无关的事件可以被删除。SS 策略默认维护2 个表,一个是高价值文件目录表,另一个是敏感进程命令行表,并定义一套可扩展的可疑语义转移规则。Michael等[58]首次提出了取证有效性度量,形式化定义了无损取证、因果保全取证、攻击保全取证3 个衡量标准,并提出了针对攻击的优化近似方法LogApprox。
4.2 数据存储模型
常见的图存储方法主要有图数据库、内存数据库、键值数据库和关系型数据库等。
4.2.1 图数据库
图数据库是一种非关系型数据库,常用来存储和表示图的数据结构、快速执行图的相关算法等。Setayeshfar 等[47]和Gao 等[63]使用图数据库进行存储;Gao 等[63]将系统进程、文件、网络连接存储为顶点,事件存储为边,并根据关键属性建立索引,提高查询速度。一般在图数据库存储之前需进行数据缩减,但政府和企业往往拥有成千上万台计算机,其原始数据量很容易达到PB 级别[62],即使经过预处理,溯源图仍然较大,每次使用时都需要将保存在图数据库中的溯源图加载入内存,这会造成巨大的开销和内存负载,而且图数据库支持的算法有限。
4.2.2 内存数据库
SLEUTH[45]、HOLMES[48]、FD-SD[49]和POIROT[64]利用内存数据库将整个因果关系数据存储在主内存中进行取证分析。SLEUTH[45]采用数据压缩和编码技术,使用可变长度编码事件特征,但增加了复杂性,降低了运行效能。HOLMES[48]利用高度紧凑的溯源图表示方法,审计日志中的每个事件平均只需要5 byte 即可表示。FD-SD[49]依靠版本图和优化算法实现紧凑性,在执行图构建任务时,执行速度比SLEUTH[45]快3倍。SWIFT[65]采用分层存储系统,设计了一个异步缓存驱逐策略,计算出因果关系图中最可疑的部分,并只将该部分缓存在主内存中,而将其余部分存储在磁盘上。KCAL[66]采用了一种内核级缓存,以消除冗余的因果事件,并减少日志从内核到用户空间的传输开销。GrAALF[47]使用内存存储作为事件的缓冲区,然后送入关系数据库或图数据库存储,并在内存存储之前提供了不压缩、无损压缩、保持取证的准确性、有损压缩4 种处理模式。
4.2.3 键值数据库
PIDAS[67]使用BerkeleyDB 数据库来存储缩减后的溯源图,pnode 号码唯一标识每个对象,IdentityDB 存储每个对象的身份信息(例如文件节点号和进程ID),ParentDB和ChildDB 分别存储一个对象与其父节点和子节点之间的依赖关系,NameDB 存储一个对象的名称和它的pnode 编号之间的映射关系,RuleDB 存储发生的事件。PDMS[24]采用同样的存储方法。Pagoda[68]使用Redis 键值数据库存储。
4.2.4 关系型数据库
PostgreSQL 是开源关系型数据库,同时支持JSON 等非关系型数据类型。Setayeshfar 等[47]、Gao等[63,69]使用PostgreSQL 进行后端存储,其中,文献[63]将从日志提取出的系统实体和系统事件存储在不同的表中,文献[69]还支持Greenplum 开源数据库。
4.3 数据查询与可视化
溯源图的构建、存储为查询系统的开发奠定基础,研究者先后开发了基于溯源图的查询系统(如CamQuery[70]、AIQL[71]、SAQL[72]、ThreaRaptor[73]),可视化应用(如ThreatRaptor WebUI[63]、AIQL UI[69]、SAQL UI[74]、GrAALF[47])。CamQuery[70]提供了一个可编程的图形处理框架,实现以顶点为中心的查询API。AIQL、SAQL 都是特定领域的查询语言,AIQL 建立在现有的监测工具和数据库之上,实现持久性存储,可以支持即时的攻击调查;SAQL 是基于流的查询系统,将企业中多个主机的实时事件反馈作为输入,并提供异常查询引擎,可实时检测基于指定异常模型的异常行为,还可以查询实时攻击足迹。ThreaRaptor[73]利用开源威胁情报自动构建威胁行为图,实现威胁狩猎穷举搜索和可视化。GrAALF[47]实现了图形化的取证分析系统,可有效加载、存储、处理、查询和显示从系统事件中提取的因果关系,以支撑取证分析,与类似系统相比,GrAALF[47]提供了关系数据库、图数据库和内存存储3 种后端存储方式,实现存储、直观查询和实时跟踪更长事件序列的能力。
经过采集系统审计日志,构造系统溯源图,利用各种算法实现对溯源图的缩减,并设计数据存储模型完成溯源图的高效存储和查询,下一步将介绍利用系统溯源图数据进行数据分析,主要包括威胁发现和取证分析两大模块。
5 基于系统溯源图的威胁发现
基于溯源图的威胁发现主要包括威胁检测和威胁狩猎。威胁检测覆盖整个攻击阶段,是被动的检测;而威胁狩猎假设攻击者已经进入系统还没有被发现,利用威胁情报驱动等方法主动发现威胁。
5.1 威胁检测
威胁检测的主要任务是检测给定网络场景的威胁,触发网络告警。MITRE ATT &CK 框架提出14 个阶段的APT 知识库来描述APT 攻击战略。HOLMES[48]根据APT 攻击杀伤链7 个阶段设计了检测指标。Li 等[40]和Xiong 等[75]提出相似的三阶段划分:1) 渗透和恶意代码执行;2) 内部侦察和横向移动;3) C&C(Command and control)通信和数据渗出。APT 攻击威胁检测研究较多,如鱼叉式钓鱼邮件检测[76]、横向移动检测[42-43]、利用域名系统(DNS,domain name system)检测妥协主机[40]等。Log2vec[42]和MLTracer[43]通过构建异构图,分别利用图嵌入和图神经网络进行异常检测。近年来基于系统溯源图检测APT 攻击成为研究热点,如表2 所示。
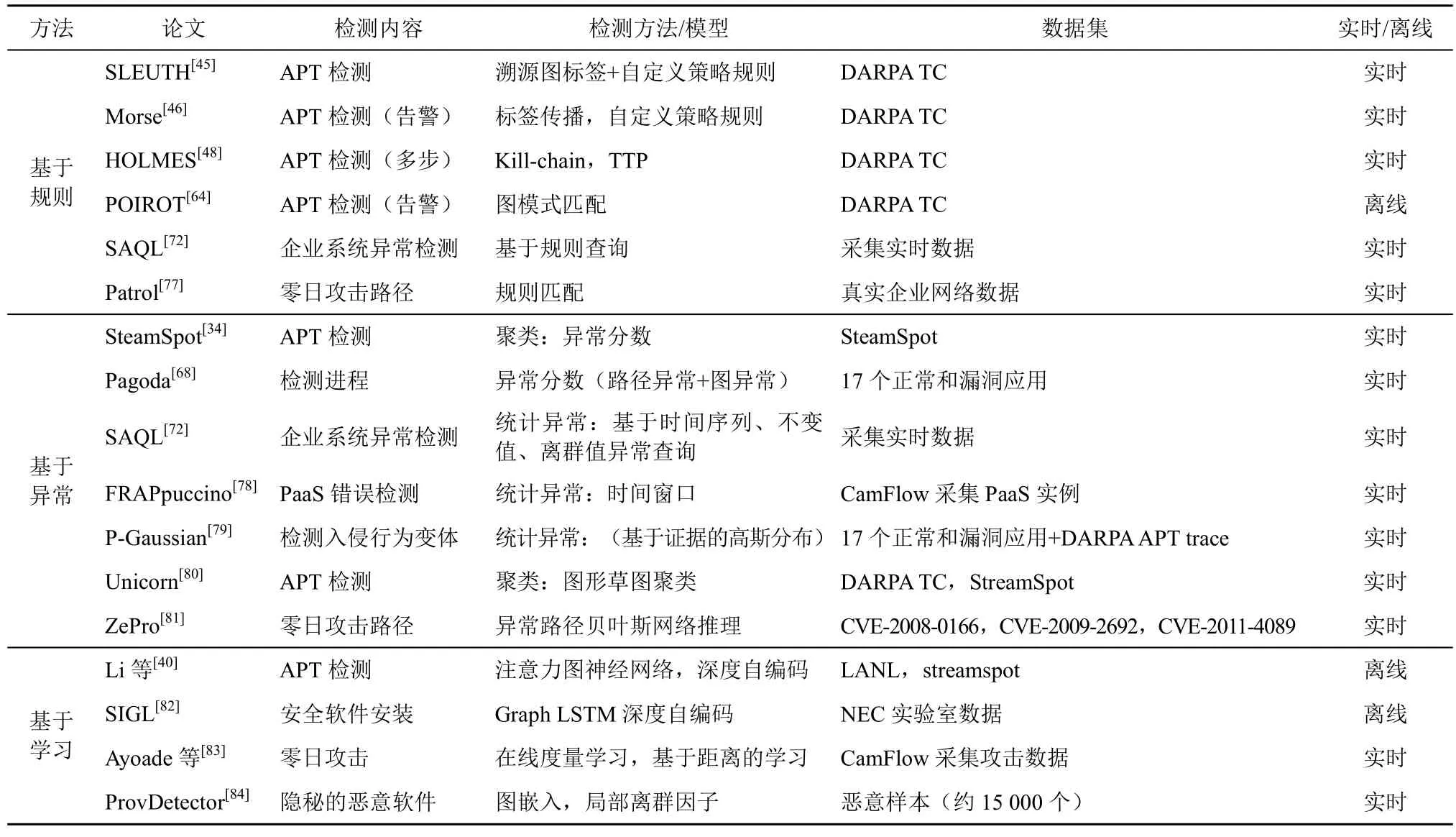
表2 威胁检测研究热点
5.1.1 基于规则的检测
基于规则的检测是指根据已知攻击制定规则策略。SLEUTH[45]结合攻击者的动机和手段,定义了5 条触发警告的规则,使用基于标签的方法,如果一段数据或代码有未知标签,就是不受信任的源。Morse[46]将本地检测结果存储在标签中,并通过标签在溯源图中的传播对攻击链进行关联,并定义了二进制代码内存执行、恶意文件执行、进程注入、修改文件权限、文件崩溃、提权、可信数据泄露7 条规则来实现攻击检测,但是如果对标签没有控制,标签会过度传播并导致依赖性爆炸问题。HOLMES[48]通过安全专家构建的威胁子图作为知识图,采用层次化的策略模板,将底层实体行为映射为ATT&CK 矩阵中的TTP,并定义了APT 攻击的7 个阶段和16 条TTP 规则,然后利用图匹配算法计算与系统溯源图中相匹配的攻击,实现语义威胁检测,并区分攻击所处的阶段。POIROT[64]利用APT 攻击报告手动构建威胁查询图,基于图对齐匹配溯源图检测威胁。SAQL[72]提供了基于规则的查询和利用特定领域语言查询威胁2 种方式。Patrol[77]通过捕获操作系统对象之间的依赖关系,通过入侵特征执行向前搜索和向后搜索,构建零日攻击路径规则,识别出可疑的候选入侵传播路径,然后进一步识别路径中未知漏洞利用的指标(如一些内核函数),从而识别出这些路径中高度可疑的候选者。对于APT 攻击,该方法可以捕获不同时间跨度的入侵传播路径,但无法将他们关联起来。
5.1.2 基于异常的检测
异常行为检测方法首先通过建立正常活动的轮廓,然后将违反正常活动的行为判定为异常。SteamSpot[34]建模主机级APT 检测问题为在流异构图中基于聚类的异常检测任务,考虑了图中不同子结构出现的频率,提出了一种基于shingling的带时间戳类型图的相似函数来表示异构有序图,并设计streamhash 维护这些摘要,采用基于质心的在线聚类和异常检测方案。Pagoda[68]不仅分析单一路径的异常程度,还分析整个溯源图的异常程度。它首先寻找可能导致入侵的入侵路径,如果找到就不用遍历整个溯源图,否则,将计算出每条路径的异常度,再乘以路径长度,得到每条路径的权重值,最后将这些权重值的总和除以所有路径的长度之和。这种方法可以快速识别出入侵过程中只对系统中的一个敏感文件或一个小的文件子集造成损害。Gao 等[72]设计了一种特定领域的查询语言SAQL 分析大规模的溯源数据,但需要专家领域知识来确定与查询相匹配的元素/模式。FRAPpuccino[78]分析了系统级溯源图,为平台即服务的应用行为建模,它使用动态滑动窗口算法来持续监测和检查应用实例是否符合所学模型。PIDAS[67]是一个基于溯源路径的入侵检测和分析系统,它使用溯源图信息作为在线入侵检测的数据源,由于溯源图代表一个对象的历史,记录了入侵发生时被感染的文件、进程和网络连接的依赖关系。通过计算由一系列依赖关系组成的一定长度路径的异常程度,并与预定的阈值相比较,可以实时判断入侵是否已经发生,但这种方法的缺点在于只使用一条路径来检测入侵,不能反映整个溯源图的行为。P-Gaussian[79]检测入侵行为及其打包加密的变体,将入侵行为变体的检测抽象为比较序列顺序或不同序列之间长度的变化。Han 等[80]设计了一个实时的异常检测系统UnicorN 来分析从流式溯源图,该检测系统随着主机系统的发展学习动态执行模型,从而捕捉模型中的行为变化,这种学习方法使其适用于检测长期运行的持久性威胁。UNICORN 使用graph sketching 技术,可以在长时间运行的系统中分析包含丰富上下文和历史信息的溯源图,从而识别未知、慢速攻击。ZePro[81]采用一种概率方法来识别零日攻击路径,通过构建一个基于实例图的贝叶斯网络,利用入侵起源,贝叶斯网络可以定量计算对象实例被感染的概率,具有高感染概率的对象实例暴露自己并形成零日攻击路径。
5.1.3 基于学习的检测
Li 等[40]提出了基于深度自编码检测系统异常,在LANL 数据集上验证了APT 攻击检测的有效性。SIGL[82]是第一个基于溯源图的异常软件安装检测系统,可以在没有事先攻击知识的情况下保证软件安装的安全;SIGL 通过对图中的异常进程节点进行分流,减轻负担。Ayoade 等[83]提出在线度量学习解决零日APT 攻击检测问题,首先模拟APT 攻击,利用CamFlow 记录日志数据,然后利用CamQuery将记录的日志转换为溯源图,溯源图过滤后生成只包含系统命令执行的子图,最后构造在线度量学习分类器检测区分新型的APT 攻击、已存在的APT攻击和良性事件,在特征提取上,利用图嵌入方法(node2vec)将图转化为向量。ProvDetector[84]利用图嵌入方法,基于概率密度的局部离群因子来检测隐蔽恶意软件,使用一种基于稀有度的路径选择算法来识别溯源图中表示进程潜在恶意行为的因果路径,然后使用doc2vec 嵌入模型和离群检测模型确定这些路径是否为恶意的,实现隐藏的恶意进程检测。
5.2 威胁狩猎
已有基于溯源图的威胁狩猎主要利用基于威胁情报驱动和基于TTP 驱动的方法。
5.2.1 基于威胁情报驱动
开源网络威胁情报(OSCTI,open-source cyber threat intelligence)是一种基于证据的知识形式,主要关注IoC。常见的威胁情报有结构化的情报(如STIX 情报)、半结构化的情报(如MISP和OpenIoC)和非结构化的情报(如安全博客和APT 报告)。
1) 威胁情报提取
POIROT[64]手动提取威胁情报,构造威胁行为查询图,查询图的顶点表示进程、文件、套接字等,边表示系统调用关系,然后利用图对齐算法匹配基于审计日志构造的溯源图,实现威胁狩猎。该实验数据集主要来源于STIX、MISP 等结构化或半结构化情报。非结构化的OSCTI 不仅包含IoC,还描述了它们之间的关系,如进程和文件之间的读取关系,这种威胁行为可以与攻击步骤联系起来,因此,ThreatRapter[73]基于OSCTI 提出了无监督自然语言处理管道提取结构化威胁行为图,图的顶点表示IoC,边表示IoC 之间的关系,实现了初始特征和关系的自动提取,其实体提取的精确率为96%,召回率为97.3%,F1 值为96.64%;关系提取的精确率为96%,召回率为89%,F1 值为92%。EXTRACTOR[85]是一种新的文本总结方法,通过区分攻击行为与其他文本,使用语义角色标记方法提取攻击行为和句子的主体、客体和行动,并以图的形式呈现攻击步骤和相关实体之间的因果信息流,通过从非结构化APT报告、公开数据集DARPA TC3 以及微软等公司的CTI 报告中提取攻击行为图,并与报告的真实活动(威胁行为图中的边)进行对比,评价精确率、召回率和F1 值,然后采用POIROT 系统验证自动生成的攻击行为图,结果证明自动生成的攻击图可用于威胁狩猎。以上3 种方法提取威胁图都是为了匹配系统溯源图或查询系统日志,实现威胁狩猎。HINTI[86]框架首次基于多粒度注意的IoC 识别方法,其IoC 包括攻击者、漏洞、设备、平台、恶意文件和攻击类型6 种类型,并从开源网络威胁情报中提取描述IoC的关系,构造异质信息网络(HIN,heterogeneous information network),提出一个基于图卷积网络的威胁情报计算框架进行知识识别。HINTI的威胁情报来源于安全博客、黑客论坛等社交网络,只对实体提取情况进行评估,其准确率为98.59%,精确率为98.72%,微观F1 值为98.69%。SecurityKG[87]是一个自动收集和管理OSCTI的系统,通过从各种来源收集OSCTI,使用人工智能和自然语言处理技术来提取威胁行为,并构建一个安全知识图,但没有对提取的准确率进行评价,HINTI和SecurityKG 表示了较为丰富的威胁知识,但没有表示系统底层日志行为,不能直接和系统溯源图进行匹配检测。
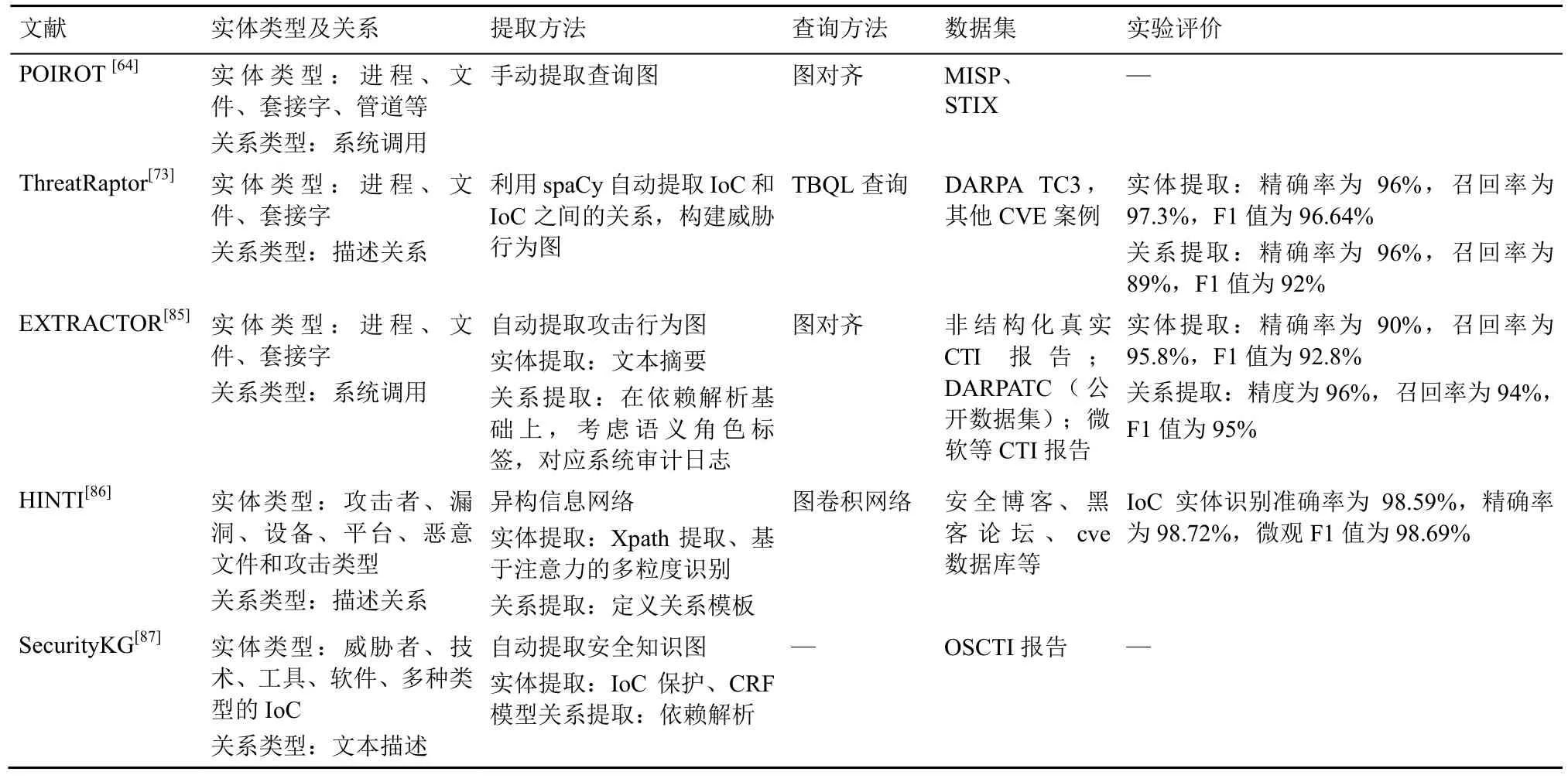
表3 威胁情报提取模型
2) 基于威胁情报的图匹配
POIROT[64]将威胁狩猎建模为一个不精确的图模式匹配问题,将STIX、MISP 等格式的威胁情报转化为攻击行为查询子图,进而主要解决威胁情报子图与系统级溯源图的节点概念对齐及匹配问题,其对齐算法包含节点对齐和图对齐,通过计算查询图和溯源图之间的图形对齐分数,能在包含数百万节点的图内进行搜索并根据查询图中的信息流搜索出溯源图中的对齐节点,可在几分钟内准确定位攻击。DeepHunter[88]也基于威胁情报驱动手动提取开源报告中的IoC 关系,然后基于图神经网络将溯源图数据与已知攻击查询图匹配,其网络架构包括属性网络和图神经网络,属性嵌入网络考虑了IoC信息,图嵌入网络捕获了IoC 之间的关系。5 个真实和合成的APT 攻击场景测试表明,DeepHunter[88]可以检测所有的攻击行为,而且其准确性和稳健性超过了POIROT。这2 种方法的局限在于威胁子图的构建需要依赖专家知识,而且对未知威胁无能为力。
3) 基于威胁情报的特定领域语言查询
特定领域语言是一种非过程化语言,研究者先后提出了CyQL[89]、τ-calculus[90]和TBQL(threat behavior query language)[73]等。CyQL 是基于MITRE CyGraph 多源异构图架构,τ-calculus 是基于IBM威胁情报计算时序图分析引擎的静态图查询;Shu等[90]提出威胁情报计算的方法,将威胁发现作为一个图计算问题。ThreatRaptor[73]通过自动解析开源威胁情报提取IoC 实体和关系,构建威胁行为图,提出了基于TBQL 对系统审计日志进行威胁查询,发现恶意的系统活动。该系统首次通过查询合成机制,自动合成一个TBQL 查询威胁行为,也支持安全分析人员对威胁查询行为进行修改,攻击案例评估结果证明了其在实际威胁狩猎中的准确性(精确率为100%,召回率为96.74%),但该系统不能狩猎针对Windows 注册表项的攻击;另外,如果自动提取的OSCTI 文本不可用或几乎不包含有用的IoC 信息,将限制其应用。WILLE[91]系统利用自然语言处理技术来自动提取和翻译已知的威胁描述,采用自动生成特定领域语言(DSL,domain specific language)进行威胁狩猎,并使用基于进化论的遗传编程方法增加IoC的遗传扰动,提高IoC的抗干扰能力,以扩大识别威胁的变体家族。
5.2.2 基于TTP 驱动
HOLMES[48]和RapSheet[60]都采用基于TTP驱动的模式,HOLMES 基于攻击链构建高级溯源图,弥合低级系统调用视角和高级攻击链视角之间的语义差距,构建了一个高级别场景图(HSG,high-level scenario graph)作为中间层。HSG 节点表示TTP 实体,边表示TTP 之间的信息流。HOLMES[48]通过专家实现了由底层日志数据到TTP的映射,但是该方法完全依赖于专家领域知识。Rapsheet[60]从战术语义角度实现构建攻击溯源,通过构建攻击行为到ATT&CK的战术映射,实现攻击行为战术溯源,大大减少溯源图规模,基于战术容易获取攻击意图。
6 基于系统溯源图的取证分析
基于系统溯源图的取证分析主要方法包括基于因果关系[92-98]、基于序列学习[99-102]、基于特定领域语言查询[47,56,70-71]和基于语义重建[103-105]的取证分析等。表4 对比分析了近年基于溯源图的取证分析相关研究。其中,ATLAS[102]以节点和边为评价指标,评价粒度效细,其他文献以图为评价指标,评价粒度较粗。

表4 取证分析相关研究
6.1 基于因果关系的取证分析
BackTracker[8]首次使用溯源图分析入侵,以确定入侵的入口点,为加速调查取证分析,提高准确率和性能,以往研究主要基于2 种思路,一种是通过图形压缩和数据缩减减少分析日志,4.1 节已做了详细介绍;另一种是解决依赖爆炸和高存储负载[50],依赖爆炸问题是由于在因果关系分析中,当一个长期运行的进程与许多输入和输出对象相互作用时,每个输出对象都被认为是对所有前面的输入对象存在因果依赖。针对依赖爆炸问题,研究者提出了执行单元分区、污点分析、记录和重放,模型推断等多种方法。
6.1.1 执行单元分区
Ma 等[31]基于Windows 事件跟踪(ETW,event tracing for Windows)审计日志,并对ETW 进行扩展,记录重要的非系统事件,然后将日志分析和二进制程序分析结合起来,推导出可以用来解析日志到单元的模型。通过单元分区精确识别事件之间的因果关系。ProPatrol[92]系统利用企业应用程序如浏览器和邮件开放式分区设计,该方法不需要利用源二进制工具,而是利用面向互联网的应用程序设计中固有的执行分区来减轻依赖爆炸程度,确定真正的依赖关系。Mnemosyne[93]基于浏览器层级划分单元分区来调查水坑攻击。
6.1.2 污点分析
污点分析可以精确追踪进程内的信息流,有效防御信息泄露和零日攻击。Newsome 等[94]提出了自动检测和分析覆盖攻击的动态污点分析方法。Yin等[95]提出了全系统细粒度污点分析,以辨别未知代码的细粒度信息访问和处理行为,然而污点分析也带来了负载。Morse[46]针对依赖爆炸,提出了标签衰减和标签衰变,设计构建了一个紧凑的场景图,可以捕捉绝大多数攻击,同时排除良性背景活动,使虚警率降低一个数量级以上。
6.1.3 记录和重放
Rain[96]使用记录重放技术实现按需细粒度信息流跟踪,通过合并进程内溯源分析和进程间的分析可以精确追踪信息流,帮助重建低级别的攻击步骤。使用粗粒度采集日志数据的方法(如系统调用)开销低、准确度低,而使用细粒度(如指令执行)准确度高,但开销大。RTAG[26]综合二者优势,在记录程序运行时,执行高级别的日志记录和分析;在重放程序运行时,执行低级别的日志记录和分析,实现了一种有效的数据流标记和追踪机制,可用于跨主机环境下的攻击调查。
6.1.4 模型推断
LDX[97]是一个双向执行因果推断模型,通过改变系统调用的输入,观察输出的状态变化来推断系统调用的关系。MCI[98]将可执行文件输入因果推理模型LDX,获得程序的因果模型,根据解析后的系统日志和相应的模型,得出事件之间的细粒度依赖关系,但该方法的压缩效果取决于大量的软件模型,而实际情况下,系统会运行许多未知软件,使该方法的覆盖率难以保证,而且软件更新也可能导致原始模型失效。
6.1.5 通用溯源
PrioTracker[55]和NoDoze[53]是基于统计特征的攻击调查方法,通过对异常事件和因果依赖进行优先级排序,排序度量指标包括频率和拓扑特性。PrioTracker 通过优先探索涉及罕见或可疑事件的路径,加快前向和后向分析,但PrioTracker 仅仅考虑了单个事件的异常,优先考虑表示异常依赖关系的边;NoDoze[53]考虑了整个事件链条的异常,提出识别目标异常路径的方法,使用统计低频路径挖掘的方法解决依赖爆炸问题,从而更准确地还原告警产生对应的溯源数据子图,但不能精确定位异常传输的IP 地址,这种基于统计的方法可能导致不稳定的结果。UIScope[33]利用低层系统事件和UI 事件相关联,将系统事件归结为单个UI 元素以避免依赖爆炸。
6.2 基于序列学习的取证分析
HERCULE[99]、Tiresias[100]、ATTACK2VEC[101]、ATLAS[102]都使用了机器学习技术来建模攻击事件,其中,HERCULE 使用社区检测算法来对攻击事件进行关联,通过将多源日志融合,以自动化的方式完成异常行为社区发现,归并其对应的攻击步骤;TIRESIAS、ATTACK2VEC、ATLAS 均采用了词嵌入将文本信息(序列)转换为向量,Tiresias和ATTACK2VEC 仅限于识别和报告日志中的单个日志中的攻击事件,ATLAS的目标是发现攻击路径,基于序列学习,在已知攻击症状的情况下,通过邻居图构造序列,经过序列学习获得攻击和非攻击序列,确定所有的攻击实体,重构攻击路径,但只支持Windows 平台,而且无法检测使用类似正常事件序列的隐藏攻击行为,比如模拟攻击。
6.3 基于特定领域语言查询的取证分析
传统的基于关系型数据库和图数据库的查询系统缺乏语言结构来表达主要攻击行为的关键属性,而且由于语义无关的设计无法利用系统监测数据的属性来加速查询的执行,所以往往执行查询的效率很低。CamQuery[70]提供了一个可编程的图形处理框架,实现以顶点为中心的查询应用程序接口;AIQL[71]通过持久性存储实现取证查询,提出了一个建立在现有监测工具和数据库之上的新型查询系统,使攻击调查查询语言(AIQL)支持即时的攻击调查。APTrace[56]利用BDL(backtracking descriptive language)语言,实现企业级因果分析查询;通过给定安全异常警告,利用BDL 执行向后查询,基于执行窗口分区算法解决依赖爆炸问题,输出溯源子图。但基于执行窗口分区的时间选择是一个难点,时间的选择将影响依赖图的大小和后续的分析。GrAALF[47]提供图形化查询系统,可有效地加载、存储、处理、查询和显示计算机取证的系统事件,实时追踪较长事件序列,帮助识别攻击。
6.4 基于语义重建的取证分析
基于特定领域语言的查询取证分析可以呈现系统级的因果关系,不能完全恢复从用户的角度发生的事情。基于语义还原的取证分析包括常规语义还原,实现程序行为动作还原,如将审计日志与应用日志相结合,解决语义鸿沟;在攻击场景下,识别告警日志数据中的攻击行为,还原TTP 语义。TGMiner[103]以感兴趣的行为中挖掘出辨别性的图形模式,并将其作为模板来识别类似行为。HOLMES[48]和RapSheet[60]将多阶段攻击视为符合TTP 规格的因果事件链。WATSON[50]利用基于系统审计日志知识图的上下文信息来实现语义推断,通过向量表示不同的行为语义,并利用语义相似行为进行聚类,可以准确抽象出良性和恶意的行为。OmegaLog[22]通过识别和模拟应用层的日志行为,使应用事件与系统层访问准确协调,通过拦截应用程序的运行时日志活动,并将这些事件移植到系统层溯源图上,使调查人员能够更精确地推断攻击的性质。ALchemist[23]将应用程序日志和审计日志结合起来,基于关系推理引擎DataLog 推理关键攻击信息,实验证明其性能优于NoDoze和OmegaLog。UIScope[33]采集用户界面元素和事件收集器以及系统事件收集器,将低层次的因果关系分析与高层次的用户界面元素和事件分析相结合,以获得两者的优势。潘亚峰等[104]提出基于ATT&CK 构建APT 攻击语义规则,通过将攻击语义文本中的语义知识抽象为针对溯源图的检测规则,实现底层审计日志数据到上层TTP 语义知识的映射,在语义规则匹配过程中设置了最小路径长度和最大路径长度,但该方法只能检测出APT 攻击生命周期中的局部行为。RATScope[105]开发了一个远程访问木马取证分析系统,由于ETW 不提供任何底层数据的输入参数,导致2 个不同的程序调用触发相同的底层系统调用行为,为解决这个语义冲突问题,提出了聚合API树记录图,利用低级别的系统调用和高级别的应用程序调用栈相结合来建立细粒度的程序行为,因为2 个不同的应用程序在应用程序调用栈是明显不同的,从而可以区分RAT的潜在恶意功能。
7 结束语
随着网络攻击的日益复杂,无文件攻击等新型攻击手法越来越隐蔽,从大规模、多源异构日志数据中有效识别复杂攻击及其意图,仍然面临许多挑战。
1) 隐蔽性威胁检测。由于APT 攻击复杂多变,开源数据集很难获得,目前常用的是DARPA TC 系列,但文档并不完善,因此研究具有多种新的APT攻击、完善文档的开源数据集具有实际意义。无文件攻击手法多样,探索无文件攻击机理和实时未知威胁检测方法成为研究热点。另外,通过多源多模态事件图谱构建,实现可解释的异常检测与威胁定位也是未来研究的一个方向。
2) 自动化威胁狩猎。威胁情报提取主要面向结构化和非结构化威胁情报进行提取,已有研究证明了自动提取威胁情报的准确性和用于威胁狩猎的可行性,但应用开源威胁情报报告中自动提取IoC 及其关系进行威胁狩猎仍然面临一些问题,如报告中记录的结构形式不统一、记录错误、省略攻击详细步骤等。面对由非规范化格式导致威胁情报行为提取准确性低等问题,需要进一步研究自然语言处理+语义辅助威胁行为图的高精度提取,探索基于学习的方法识别一些特定名词等,进一步拓展IoC 实体提取方法,构建更加丰富的威胁行为图。此外,基于TTP 行为图的构建,生成进化的IoC也是可以探索的研究热点。自动化威胁狩猎方法研究中,考虑基于自动生成的威胁查询图与自动生成的系统日志溯源图的图节点对齐、子图匹配等新算法的准确度和效率,以及针对这些技术的评估也是重点。
3) 基于攻击语义的取证分析。目前,基于系统溯源图的取证分析主要从缩减日志和减少依赖爆炸2 种思路来开展,已有的基于序列学习的取证分析方案需要学习大量已知的攻击序列。针对底层日志与上层之间的语义鸿沟问题,现有研究探索了系统日志与应用日志、UI 日志相结合;针对攻击语义问题,现有研究主要利用TTP 关联系统审计日志;针对取证分析结果的评价,现有研究大多从告警点出发,基于溯源图来执行后向和前向查询,评价粒度比较粗糙,仅有ATLAS[102]、WATSON[50]和ALchemist[23]的评价粒度较细。由于关联缺失,跨网络与终端数据难以有效同步日志触发条件,导致多源日志之间很难有效关联;另外,由于语义缺失,统计规律很难反映攻击者底层的攻击意图和战术方法。因此,探索知识图谱解决语义鸿沟问题,通过知识图谱挖掘事件元信息及上下文,进而进行关系推理,实现攻击路径溯源与取证,是将来的可探索的方向。此外,取证分析的有效性度量也是一个重要的考量因素。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
红领巾·探索(2020年5期)2020-05-19
开放教育研究(2020年2期)2020-03-31
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
长江学术(2016年4期)2016-03-11
文理导航·科普童话(2015年6期)2015-07-29
长江学术(2015年1期)2015-02-27
