
Networked Knowledge and Complex Networks: An Engineering View
2022-08-13 02:08JinhuGuanghuiWenRuqianLuYongWangandSongmaoZhang
Jinhu Lü,, Guanghui Wen,, Ruqian Lu, Yong Wang, and Songmao Zhang
Abstract—Along with the development of information technologies such as mobile Internet, information acquisition technology,cloud computing and big data technology, the traditional knowledge engineering and knowledge-based software engineering have undergone fundamental changes where the network plays an increasingly important role. Within this context, it is required to develop new methodologies as well as technical tools for network-based knowledge representation, knowledge services and knowledge engineering. Obviously, the term “network” has different meanings in different scenarios. Meanwhile, some breakthroughs in several bottleneck problems of complex networks promote the developments of the new methodologies and technical tools for network-based knowledge representation, knowledge services and knowledge engineering. This paper first reviews some recent advances on complex networks, and then, in conjunction with knowledge graph, proposes a framework of networked knowledge which models knowledge and its relationships with the perspective of complex networks. For the unique advantages of deep learning in acquiring and processing knowledge, this paper reviews its development and emphasizes the role that it played in the development of knowledge engineering.Finally, some challenges and further trends are discussed.
I. INTRODUCTION
MANY practical systems consist of a number of individuals interacting with each other where the typical examples include smart grids, WWW, and the Internet. Such systems can be generally portrayed as complex networks by modeling each individual to a node, and interactions among individuals to edges [1]. Benefiting from its highly abstract representation, the complex network has been widely applied in numerous fields as an effective tool for characterizing natural and artificial systems [2]–[5]. For exploring the information hidden in the network structure and connectivity that can be used to solve real-world problems, numerous approaches have been proposed to model and analyze the structure of real networks, obtaining a series of insightful results. For example,finding the most influential individuals in the group to predict the spread of infectious diseases and rumors [6], and determining the smallest set of nodes in the network so that control of the entire network can be achieved with small control cost [7].
Intelligent upgrading and transformation have become a common occurrence in all walks of life. Intellectualization requires machine intelligence, especially cognitive intelligence. The knowledge graph is a key technology for achieving cognitive intelligence as well as an enabler for achieving machine cognitive intelligence. The concept of knowledge graph was formally proposed by Google in 2012 [8], and its essence is a graph connecting entities through relationships among them. Further, it has attracted more and more attention to applications such as education [9], medical treatment [10],e-commerce [11], artificial intelligence [12], cognitive manufacturing network [13], etc. The realization of various knowledge graphs is based on complex networks. Also, the management and operation of knowledge graphs mainly depend on the graph and complex network-related algorithms.Integrated with complex network technology, the knowledge graph can improve the efficiency of knowledge management and analysis. Meanwhile, it enriches the concept of networked knowledge and provides the possibility to discover new knowledge.
With the development of computer science, more and more information can be stored and leveraged. As a result,traditional methods are difficult in undertaking the modeling of a large amount of data. Deep learning (DL) [14], including various data-driven models, are popular in networked knowledge exploration under big data. The neural networks (NNs)are the basic structure of DL [15]. And backpropagation algorithm [16] provides the training capability for the DL models. Facing the data with different structures, different networks of DL models can be used to learn the knowledge in the data. For instance, the convolutional neural networks(CNNs) are applied to the image task [17], [18], and the recurrent neural networks (RNNs) perform well at modeling the sequence data [19], [20]. Meanwhile, graph neural networks can model the unstructured data in complex networks[21]–[23], and generating adversarial networks are effective in generating new samples from old data [24]. Hence, rational use of different DL methods can make the process of networked knowledge discovery more intelligent and efficient.
Abundant technical methods bring us the ability to access information and knowledge from text, images, audio, and video. However, traditional knowledge engineering is no longer adapted to the explosive growth of data. To cope with the new challenges posed by big data, the concept of big knowledge has been proposed. The result in [25] defines big knowledge and presents its ten massive characteristics.Network science has unique advantages in mining information and discovering patterns from a large number of interconnected individuals, and has been successfully applied in many fields. Combining the techniques of network science, this paper proposes a framework for networked knowledge,expecting to discover new knowledge that emerges from the interaction of knowledge assets that is significantly different from individual knowledge. The idea of networked knowledge has been reflected in some studies [25], [26]. In addition, the applications of networked knowledge in various fields are also a hot issue discussed and concerned by researchers. In terms of biological networks, networked knowledge not only shows the structure and function of proteins and genes at the microlevel [27], [28], but also explores the interaction of drugs,disease discovery and the construction of medical knowledge graph at the macro level [29]–[32]. As for semantic networks,one can obtain the information of the text itself, can also catch the networked knowledge between different texts [26], [33],[34]. In the social networks, networked knowledge can play a key role in criminal investigation [35], privacy protection[36], [37], information recommendation [38], [39], etc.Regarding power networks, researchers use networked knowledge for power information visualization, information retrieval and dispatching of power networks [40]–[43], which helps to improve the efficiency and optimal management of the smart grid.
With the rise of information technologies such as mobile Internet, social networks, traditional knowledge engineering and knowledge-based software engineering are not adapting,leading to the requirement of network-based knowledge representation. Therefore, this paper aims to provide a survey of networked knowledge and complex networks from an engineering view. To achieve these goals, this paper begins with a description of the framework for conducting a literature review and then moves on to a descriptive analysis of existing studies in Section II. The research progresses of the complex network, knowledge graph, and DL are presented, respectively. Networked knowledge sparks some fresh and interesting thinking, which may potentially lead to more applications in various fields, and this is discussed in Section III.Then, research challenges and future trends are presented in Section IV. Finally, the conclusion is presented in Section V.
II. NETWORKED KNOWLEDGE IN THE CONTExT OF COMPLEx NETWORK
A. Complex Networks
Numerous natural and artificial systems are composed of a large number of individuals that interact with each other in various ways, and then perform surprising functions. Examples include gene regulation networks, protein interaction networks, power grids, infection and disease propagation networks, social networks, and brain networks [1], [44], [45].An excellent approach to capture the distinct group properties exhibited by large systems that different from individual dynamics is representing them as networks (mathematically,in terms of graphs), where nodes represent individuals in the system and edges represent information exchanges or interactions among individuals. Although some properties of the individuals are ignored in this representation, a deeper exploration of the influence of the network topology on the properties of the total system is possible. With the rapid development of several disciplines, complex networks, as an interdisciplinary discipline, become a hot topic in several fields increasingly.
1) Network Models:In the beginning, the research on complex networks was limited to the field of graph theory and focused more on regular networks. However, for extremely large and growing real networks such as the World Wide Web and the Internet, it was impractical to obtain their exact topologies due to the limited technology available at that time.For large networks without obvious connection rules, the Hungarian mathematicians Erdös and Rényi argued that the connections among individuals are completely random, and proposed the random graph theory, namely ER random graphs or networks, which occupied the research on complex networks for four decades [46]. There are two ways to define a random network: One isG(N,L), whereLedges are randomly placed amongNnodes [46], and another isG(N,p),where a pair of nodes are connected with probabilityp[47]. In fact, these two definitions are equivalent. A natural question follows that are really large networks completely random?
Researches have shown that many real networks are not random but possessed small-world properties [2], [48], i.e.,networks with large clustering coefficients and small mean path lengths. The social experiments performed by the American social psychologist Milgram found the phenomenon of six degrees of separation and got the conclusion that the average distance between any two persons in the world is six[48]. Later, a study of Facebook social networks found that the average distance between people is four, i.e., four degrees of separation [49]. To characterize the small-world properties in real networks, the WS small-world network model was proposed in [2] by creatively randomly reconnecting edges in a regular network. The proposed small-world networks provide a new perspective on synchronization, failures cascading, and the propagation of epidemics and rumors in interpersonal networks.
A common property of ER random networks and WS smallworld networks is that the degree distribution of the network approximates a Poisson distribution, while some results showed that there exist a large number of real networks whose degree distribution exhibits a power-law characteristic [3].The later are called scale-free networks. In order to understand the potential mechanism for the generation of the scale-free networks, Barabási and Albert proposed the BA scale-free network model based on the growth and preferential attachment mechanisms. Also, what can be found is that scalefree networks also have the small-world property [50]. The existence of power-law distributions has been found in many real datasets, such as earthquakes [51], terrorist attacks [52],web networks [53], etc. Since existing data analysis methods have difficulty in discerning power-law phenomena, a statistical framework was proposed to identify power-law behavior in empirical data [54]. Despite the fact that scale-free properties have been observed in many real networks,skepticism about scale-free property persists in the scientific community. A highly representative result is presented in [55],where the authors studied nearly a thousand empirical networks and concluded that “scale-free properties are rare”.The author of [56] suggested that the current controversy about scale-free networks stems from whether the degree distribution sequence is completely consistent with or close to the power law. By presenting a strict definition of power-law distribution, they argued that “scale-free networks well done”.
2) Multi-Layer Networks and Higher-Order Networks:In recent years, there has been a rise in the study of multi-layer networks, which consist of many layers, each of which is a separate network. For example, in social networks, people often participate in multiple social platforms at the same time,such as Facebook, Twitter, WeChat, LinkedIn, etc., and people have different relationships in different platforms.Multi-layer network frameworks have been widely used in various domains. The tensor algebra was shown to be a good method to describe a multi-layer network [57]. And then the network properties such as degree centrality, eigenvector centrality, and clustering coefficients of multi-layer networks were well defined. An alternative mathematical representation of multi-layer networks is the supra-Laplacian matrix which generalizes the Laplacian matrices of single-layer networks[58], [59]. The structure of the eigenvalues and eigenvectors of the supra-Laplacian is analyzed in [58] using the perturbative analysis. The approximation of the eigenvalues of the supra-Laplacian matrix was estimated in [59] and further used to analyze the diffusion and synchronization phenomena.Then, synchronization of multi-layer networks in the presence of coupling delays was studied in [60].
The successful presentation of the mathematical description of multi-layer networks in the above-mentioned literature has greatly contributed to the study of multi-layer networks[61]–[63]. The concept of symmetry on single-layer networks was extended to multi-layer networks, and the clustering synchronization problem of multi-layer networks was addressed by decoupling the dynamics and transforming them into master stability equations [61]. The master stability function approach was extended to multi-layer networks [64],and three master stability functions were obtained to study synchronization domains with complete synchronization,intra-layer synchronization, and inter-layer synchronization,respectively. The robustness of networks is an important topic in complex networks, and the effect of multi-layer structures on network robustness is also a hot topic. The optimal percolation problem on a multi-layer network is studied in[62] and the results showed that ignoring the multi-layer structure of the network leads to incorrect estimation of the network robustness. In [63], the authors constructed a biological multi-layer network containing a gene regulatory network, a protein interaction network, and a molecular network and found that the network with coupled multi-layer structure has better robustness compared to the uncoupled single-layer network.
The existence of higher-order interactions in the biological and physical worlds has attracted the attention of researchers.A method of modeling higher-order interactions is the simplicial complex, which generalizes the edges and nodes in simple networks [65]–[69]. Ad-simplex consists ofd+1 nodes. In this way, a 0-simplex is a node, a 1-simplex is an edge, a 2-simplex is a two-dimensional object made by three nodes, usually called a (full) triangle, a 3-simplex is a tetrahedron, i.e., a three-dimensional object and so on. A network consisting of simplexes is called a simplex complex. An additional requirement is that a subset of any simplex in a simplicial complex is also a simplex of the simplicial complex. The presence of higher-order interactions has been found performing a great impact on the stability of networked systems. It is found in [65] that the presence of higher-order interactions among organisms exhibits completely different stability, and therefore may be responsible for the ecological network remaining stable. The influence of higher-order interactions on social networks was deeply studied in [66],where higher-order interactions were modeled as simplicial complexes, and new homeostasis was found in which healthy and endemic states coexist. Higher-order interactions (threebody interactions herein, i.e., 2-simplex) may cause Kuramoto oscillators networks with all-to-all coupling to acquire multistable synchronized states at critical coupling strengths[67]. Replacing the all-to-all pairwise actions with 2-simplexes, a new phenomenon of abrupt desynchronization transition was found, which cannot be observed in the classical Kuramoto model [68]. For the synchronization of general simplical complexes, the results in [69] generalized the adjacency matrix and Laplacian matrix under simple networks to simplical complexes, and then defined the adjacency tensor and the generalized Laplacian matrix. The master stability functions were obtained in the case where further the network topology is all-to-all and generalized diffusion interactions are naturally coupling functions, respectively.
B. Knowledge Graph
With the advent of the era of big data, knowledge engineering has attracted extensive attention. How to extract useful knowledge from massive data is the key to big data analysis. As is known to all, the knowledge graph technology provides an effective way to extract structured knowledge from a large number of texts and images, and is widely applied. In the following part, the history of knowledge graph is briefly reviewed first. Then, several important research topics of the knowledge graph are introduced, which contains the related research contents and progresses.
1) Brief History:The origin of the knowledge graph can be traced back to the birth of the semantic network in the late 1950s and early 1960s. The semantic network can be regarded as a graph-based data structure. Inspired by the semantic network, the concept of knowledge graph was formally proposed by Google in 2012 [8]. The essence of the knowledge graph is a graph denoting the relationships among entities, that is, a semantic network revealing the relationships among entities. Its purpose is to improve the intelligent ability of search engines and enhance the quality and experience of users’ search. Moreover, this concept has been widely used in education [9], medical treatment [10], e-commerce [11] and other industries. Up to now, a large number of knowledge graphs such as YAGO [70], Probase [71], Zhishi.me [72],CN-DBpedia [73] have emerged. An example of knowledge graphs was shown in Fig. 1, and some related products are presented in Table I.
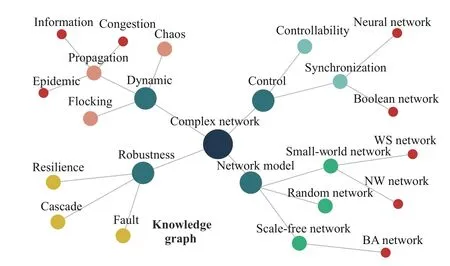
Fig. 1. An example of knowledge graph on research topics of the complex network, where edges represent inclusion relationships.
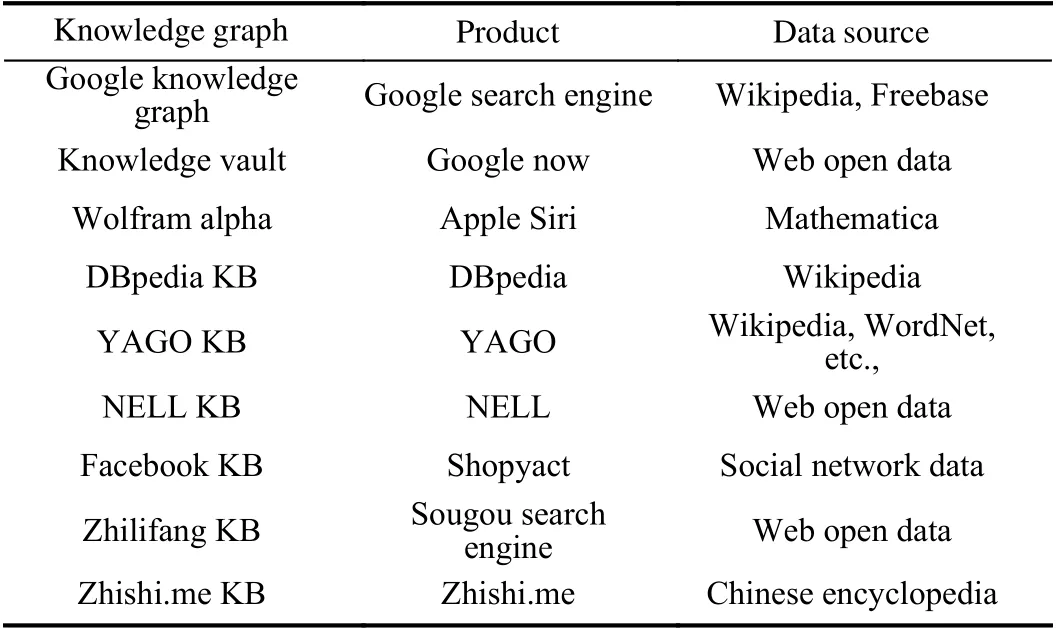
TABLE I KNOWLEDGE GRAPHS AND THEIR PRODUCTS
Compared with the early semantic network, the knowledge graph has its own characteristics. Firstly, the knowledge graph emphasizes the relationships among entities and the attribute value of entities. Secondly, an important source of knowledge graph is the encyclopedia. Knowledge of high quality as seed knowledge is obtained through the encyclopedia. And then large-scale and high-quality knowledge graphs can be quickly constructed with knowledge mining technology. This is different from the early semantic networks that were mainly constructed artificially. Finally, the construction of the knowledge graph emphasizes the integration of knowledge from different sources and the cleaning technology of knowledge.
In recent years, the knowledge graph attracted more and more attention to applications such as artificial intelligence[12], cognitive manufacturing network [13], recommender systems [74], etc. In addition to the explosive growth of technical articles about knowledge graphs, there are more and more review articles. In [75], a systematic review of knowledge graph embedding was provided, including the state-of-the-art and the latest trends. In [76], authors reviewed the basic concept of knowledge computing and the methods for computing over knowledge graphs. The computing methods are dissected into three categories: rule-based computing,distributed representation-based computing and neural network-based computing. To reveal the development context of the knowledge graph, the following parts focus on the latest progress of several important technologies of the knowledge graph. The technical framework of knowledge graphs is shown in Fig. 2.
2) Knowledge Extraction:A key problem in knowledge graphs is how to extract useful information from massive data,and knowledge extraction technology concentrates on this problem. According to the different types of information,knowledge extraction can be divided into entity extraction,relationship extraction and attribute extraction.
The main purpose of entity extraction is to identify the named entities from sample sources. The first kind of method is based on rules and dictionaries. For example, an entity extraction method was proposed in line with the dictionary,and has been applied to electronic health records [77]. The second kind of method is using machine learning technologies to identify entities. The results in [78] tried to combine the Knearest neighbor algorithm and conditional random fields to identify entities. The third kind of method is an open domainoriented extraction approach. An unsupervised open domain clustering algorithm for entity clustering is proposed to deal with the massive network data in [79].
In general, the entities obtained by entity extraction methods are discrete and unrelated. Semantic links among entities can be established with relationship extraction. Three main relation extraction technologies are introduced in the following. 1) The relation extraction is based on the template.This method has high accuracy and pertinence, but it is not suitable for large-scale data sets and is difficult to uphold. 2)The relation extraction is with supervised learning method,such as joint extraction model [80], end-to-end relation extraction with LSTMs [81]. However, model training needs a large number of corpora in these methods. Then, it is not suitable to build a large-scale knowledge base. 3) The relation extraction is with semisupervised or unsupervised learning.According to a small amount of manually labeled data or unlabeled data, relationships are extracted by using maximum expectation algorithms.
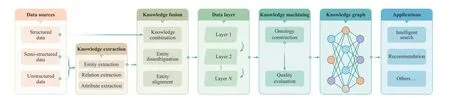
Fig. 2. The technical framework of knowledge graph.

TABLE II SOME KNOWLEDGE COMPUTING MODELS BASED ON REPRESENTATION LEARNING
The attribute extraction is another important technique in knowledge graphs. The purpose of attribute extraction is to complete the entity information, and to obtain entity attribute information or values from sample sources. Entity attribute can be further regarded as a relationship between attribute value and entities, so it can be obtained by the relationship extraction method. And some useful approaches were proposed such as the relation extraction method with tensor decomposition [82], which uses the domain knowledge of the entity type to obtain the attribute value that the entity lacks.
3) Knowledge Fusion:The formal knowledge is obtained utilizing the extraction methods. However, the quality of knowledge is uneven because of the different sources. There may be conflicts or overlaps in the extracted knowledge.Thus, it is necessary to apply fusion technologies to deal with multi-source knowledge. Then the knowledge graph can be effectively improved and enriched. With the development of knowledge graphs, some special knowledge fusion methods were proposed [83]. The main fusion approaches are introduced in the following.
The entity disambiguation is used to distinguish entities with the same name and ensures that each entity has a clear meaning. The topic model uses the text information in the knowledge base to learn the common entity group and realize the entity collective disambiguation [84]. Another disambiguation approach is based on the context and semantic similarity of entity information words in knowledge graphs [85]. In addition, some effective disambiguation methods include the integrated learning in line with the Support Vector Machine[86] and random forest models with similarity feature [87].
The knowledge combination is the integration of knowledge from the overall level, which is different from entity disambiguation and alignment. An important problem that needs to be solved is merging data layers and schema layers[88]. Moreover, knowledge conflicts often occur in the process of fusion, and one may use the conflict detection and resolution technology and the truth discovery technology to eliminate the phenomenon. Recently, the main approach is utilizing the characteristics of the graph to resolve knowledge conflicts [89].
4) Knowledge Computing:This technology can improve the integrity and accuracy of knowledge graphs. However,traditional knowledge computing methods are not appropriate for large-scale knowledge graphs. To overcome this defect,the knowledge computing strategies for large-scale knowledge graphs are introduced in the following.

The second kind of method is computing according to the graph structure and computing of statistical rule mining,which were proposed with the inspiration of the traditional computing method. Some effective methods are presented such as the path ranking algorithm [97], the reinforcement learning method [98], and depth graph propagation models[99].
The third kind of method is computing with NNs, which continuously improves the actual tuple score by training NNs,and selecting the candidate entity to complete the computing with the output score. For example, the RNN was used to model distributed semantics in knowledge graph [100]. A differentiable neural model was established combining NNs with memory systems, which achieves fast knowledge computing [101].
The fourth kind of method is computing with hybrid methods. This method combines the advantages of various strategies to improve the computing effect. Some novel efficient models and algorithms have been proposed such as rule-enhanced relational learning [102], iteratively learning embedding and rules framework [103] and so on. The above methods provide an effective way for knowledge computing of the large-scale knowledge graph.
5) Quality Evaluation:Screening new knowledge with the quality evaluation technology is an essential link in constructing knowledge graphs. There are various possible ways to evaluate the quality of knowledge graphs. In [104],Sieve was proposed to simplify the task of generating highquality data, which includes a quality evaluation model and a data fusion model, and the quality score was generated by the score function. In Google’s knowledge vault project [105], the frequency of data from the global network was used as evidence for evaluating the reliability of the information. And the credibility was further modified according to the knowledge in the existing knowledge base. This strategy reduces the uncertainty of the evaluation data results, so as to improve the quality level of knowledge. In addition, the other evaluation methodologies were proposed to check the effectiveness of various refinement methods [106].
6) Knowledge Graph and Networked Knowledge:Since Google put forward the concept of knowledge graphs, this technology is widely concerned. With the development of DL,natural language processing (NLP) and other related fields,the research progress of knowledge graph is increasing. At present, the research on knowledge graph is still in its infancy,and the relevant theoretical research needs further development. The construction of knowledge graphs is the combination of multiple disciplines, which requires the integration of multiple fields such as data mining, complex networks and machine learning.
Specifically, the realization of various knowledge graphs is based on complex networks. Also, the management and operation of knowledge graphs mainly depend on the graph and complex network-related algorithms such as subgraph search, subgraph matching, the shortest path, link prediction,etc. At the same time, to satisfy the demands of multi-source heterogeneous information processing, the knowledge graph with the complex network needs to solve some difficulties.For example, a knowledge graph is often sparse, which leads to the retrieval effect undesired with the complex networkrelated algorithm. A knowledge graph contains a large number of entities and relationships, so it is a large-scale directed heterogeneous network. Naturally, a problem of how to achieve efficient and fast clustering, matching and retrieval on large scale networks is formed.
To solve the problem, the concepts of network representation learning and knowledge representation learning have been proposed one after another in recent years [107]. The basic idea is comprehensively considering the network structure information of knowledge graph and the attribute information of nodes and relationships. The entities and relationships in the knowledge graph are mapped to a low dimensional vector space. Then the entities and relationships are computable, and the operation and modeling of knowledge graphs are simplified. Integrated with complex network technologies, the knowledge graph improves the efficiency of knowledge management and analysis. At the same time, it enriches the concept of networked knowledge and provides the possibility to discover new knowledge. More details are stated in Section III.
C. Deep Learning Technologies for Networked Knowledge
Numerous engineering problems are involved in networked knowledge, including anomaly detection in semantic networks, dispatching in power networks, etc. However, with the increase of network scale and knowledge types, the complexity of engineering problems also increases. As a result, DL technologies could be applied to solve complex engineering problems effectively. In order to better illustrate this point of view, DL technologies are first introduced in detail.
With the rapid development of computers, sensors, and storage technology, the trend of data expansion has been increasing. If human learning is the process of gaining a skill via observation, machine learning is the act of reproducing this process using computers [108]. Machine learning occupies an important position in the early stages of artificial intelligence (AI) development, which is considered as a fundamental way for computers to have intelligence [109]. As one of the machine learning research topics, DL aims to study how to automatically extract multi-layer feature representations from data. And the core idea of DL is using a series of non-linear transformations through a data-driven approach to extract features from raw data [14]. NNs are the cornerstone of DL and have gone through three significant ups and downs in their evolution.
In the following, the history is briefly reviewed, and classical models of DL are presented. Also, the basic principles of the models and the corresponding variants are introduced.
1) Brief History:In 1943, inspired by the working mode of biological neurons, McCulloch and Pitts proposed the mathematical model of neurons [110]. In 1949, Hebb introduced the idea that the strength of connections on neurons could be adjusted by training [111]. Then, a seminar at Dartmouth in the summer of 1956 initiated research into AI,which focused on symbolism and intellectual computing. In the following period, classical AI was developing rapidly[112]. However, as the ANNs were still in their early stages,the perceptron model at that time had only one layer. In 1969,Minsky and Papert pointed out that single-layer perceptrons could not handle linearly inseparable problems, and it could not map models directly to the real world according to the“black box” principle [113]. Up to that point, researches on ANNs had entered its first lull. However, this attempt has opened the way for researchers to explore machine learning based on symbolic induction and integrated machine learning.

Fig. 3. The basic structure of CNNs.
The term ANNs came into widespread use in the 1980s and soon became known simply as the NN. In 1982, Hopfield proposed a NN model with a complete theoretical foundation[15]. In 1986, the back propagation (BP) algorithm was applied to train NNs, which addressed the problem that the multilayer perceptron (MLP) could not solve [16]. Then, NN had a non-linear representation, and the MLP that trained with the BP algorithm became the most successful NN model. In the same period, Kohonen developed the self-organizing map competition learning NN model [114]. Meanwhile,unsupervised learning models such as the restrictive Boltzman machine (RBM) were also introduced during that period[115]. These approaches work effectively for many pattern recognition applications, resulting in a significant increase in NN research.
However, there are many problems with the NN approach.For example, although MLPs have a very strong non-linear representation, they also have a large number of local extrema in the parameter solution space. That is to say, the training with gradient descent can easily produce a poor local minimum, resulting in poor generalization of MLPs to many problems. In addition, NNs have many layers, which make the model is trained slowly because of the hardware limitations and the problem of gradient dissipation, resulting in very slow corrections to the weights of the deeper layers, so that only two- or three-layer NNs are used.
In 2006, Hinton and Salakhutdinov proposed a deep belief network and RBM training algorithm [116], which were applied to the recognition of handwritten characters with good results. Meanwhile, Hinton introduced a twofold method to effectively solve the problem of deep neural networks (DNNs)learning: 1) The unsupervised learning method is used to initialize the parameters layer by layer; 2) The supervised learning method is used to fine-tune the training method of the whole network. From then on, the research on DNNs flourished and was generalized to DL. Many training techniques of DL have been proposed, such as initialization methods for parameters, new activation functions, and dropout training methods [117]–[119], which address the issues of overfitting and training challenges.
In the 2012 ImageNet competition, Krizhevskyet al.used CNNs to improve accuracy by 10% [120], which significantly outperformed hand-designed features and shallow models for the first time. In 2015, Google’s DeepMind AlphaGo used DL to defeat the European Go champion in a Go tournament[121], making DL increasingly influential. The current surge in DL has been described as the third boom in AI. Since then,machine learning has entered a period of rapid development.During this phase, excellent algorithms continue to emerge[122], driving advances in speech recognition, image processing, and NLP.
2) Convolutional Neural Networks:In 1962, Hubel and Wiesel found that neurons with local sensitivity and direction selection had a unique network structure through the study of cat visual cortex cells [123]. Thus, they proposed the concept of the receptive field, that is, cells in the visual cortex have a complex structure. These cells are very sensitive to subregions of the visual input space. In 1983, Japanese scholar Fukushima proposed the recognition based on the concept of the receptive field [124], which was the first application of the concept in the field of ANNs. In 1998, LeCunet al. designed a CNN for processing images and used it for image recognition with good results [17]. Consequently, CNNs are frequently the primary option for computer vision. In addition to discriminative models such as image recognition, CNNs can also be used for generative models such as image deconvolution to make blurred images clearer. And, they are also used in other fields like NLP and drug discovery [18].CNNs usually consist of convolutional layers, pooling layers and fully connected layers with output layers. In this structure,the convolutional layers are used to extract features, and the convolutional and downsampling layers can be set up in the model with multiple layers. For an image as input, a convolutional layer contains multiple convolutional kernels,each of which can be calculated with the input image to produce a new image. And each pixel on the new image is a feature of the image in a small area covered by the convolutional kernels. In this way, different kinds of features can be extracted by calculating the image with multiple convolutional kernels. The structure of the basic CNN can be seen in Fig. 3. Unlike other NNs, the neurons in each feature extraction layer of a CNN are not connected to all the neurons in the adjacent layers. Instead, they are only connected to a fixed size. Meanwhile, the convolution kernel is scanned sequentially over the input image, and the area where it overlaps the image is called the local receptive field.
The most important idea behind convolutional layer design is local connectivity and weight sharing. Local connectivity means that each pixel of the output feature map is associated with only a small region of the previous layer’s feature map.And weight sharing means that the same convolutional kernel is used each time to traverse the entire input image, which can greatly reduce the number of parameters. Compared to the MLP, the reduction in the number of connections reduces the training time and the possibility of overfitting. Also, all neurons in a filter are connected to the same number of neurons in the previous input layer, and they are constrained to have the same sequence of weights and biases. These factors speed up the learning process and reduce the memory requirements for the model. Since the subsampling layer can reduce the size of the network, Deep CNNs can be implemented by sharing convolutional layers and subsampling layers. Although local architectures of CNNs are quite effective, applying them to high-resolution images at scale is still extremely expensive. AlexNet is constructed to propose a highly optimized 2D convolutional GPU implementation that improves the performance of the NN and reduces the training time [120]. Meanwhile, ResNet, developed by Microsoft[125], is a very deep residual network which takes first place in the 2015 ILSVRC ImageNet dataset competition. Then,VGG is introduced as a very deep CNN developed for largescale image recognition [126]. Those improved models have promoted the application of NNs in the field of images to an unprecedented speed and accuracy.
3) Long Short-Term Memory Neural Network:RNNs not only consider the previous input, but also give the network a memory function for the previous content, which means the current output of a sequence is also related to the previous output. Specifically, the network can remember the previous information and apply it to the calculation of the current output. In another word, the nodes between the hidden layers are no longer separated but connected, and the input of the hidden layers not only includes the input layer but also includes the output of the hidden layer at the previous moment. RNNs are widely used to analyze sequential data,such as speech recognition, language translation, natural language understanding, music synthesis, etc.
After years of development, a large number of improved models based on RNNs have been proposed by researchers.The long short-term memory (LSTM) neural network is an implementation of RNNs, which is first proposed by Hochreiter and Schmidhuber [127]. It is still one of the most popular forms of RNNs and its important elements consist of four basic computing unitsf(t),i(t),g(t),o(t), hidden stateh(t) and cell states(t). The specific expressions are shown below:
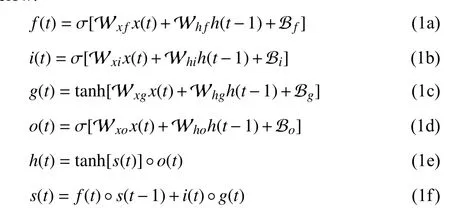
where the parameters Wx f, Wh f, Wxi, Whi, Wxg, Whg,Wxoand Whoare weight matrices for the NN. Parameters Bf, Bi, Bgand Boare called basics, which are decimals. They are also the important parameters of the NN. The NN with the basics has more complex parameter structure and better fitting abilities. All of parameters are updated by BP. Symbol◦represents the element-wise multiplication.σand tanh stand for sigmoid and tanh activation function.h(t) can be used as the input to next layer of NN.
When the gradients are passed on the network, the values of gradients should be kept within a reasonable interval. Too large or small gradient results in a bigger training difficulty. If the gradient is less than 1, the weight on the tail of the model is close to 0, which is called gradient descent. On the contrary,while the gradient is greater than 1, the weight can be a very large number by constant accumulation, called gradient explosion. This is the reason why ordinary RNNs cannot recall the long-time memory. Compared with RNNs, the gradient dissipation phenomenon in LSTM is mitigated, and improvements are made in both unit structure and optimization. To solve those problems of RNNs, three more controllers are set in LSTM, which are called input control,output control and forget control. Those controllers are also be called gates. And there is one more control for global memory. In terms of the unit structure, LSTM consists of memory cell status blocks, and signals flow through those blocks, which can be regulated by input, forget, and output gates. These gates control what is stored, read and written on the cell. LSTM adds additional implicit states to remember the information of the sequence. Meanwhile, three gates are used to control the effect of the current moment’s input on the memory. The structure of a unit in LSTM is shown in Fig. 4.With this modification, the memory can pass more smoothly through the time series and remember the information from long ago. Recently, a kind of distributed LSTM has been provided and deployed on the Internet of Things environment in [128] to handle the large-scale spatiotemporal correlation regression tasks.
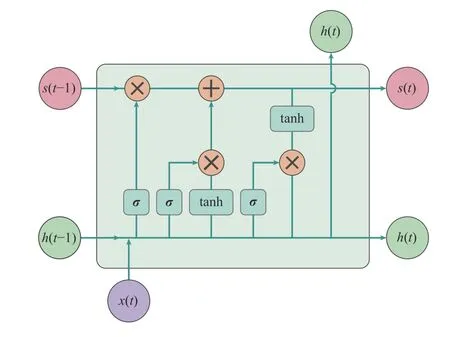
Fig. 4. The structure of a unit in LSTM.
4) Generative Adversarial Networks (GANs):In 2014,Goodfellowet al.proposed a game-theoretic-based generative model, the GANs [24]. It uses two NNs for adversarial training and updates the network weights by backpropagation.This model has attracted the attention of researchers in the field of NNs and has been studied and improved extensively since its introduction. GANs consist of Generators (G) and Discriminators (D). The generation model is a NN model whose input is a set of random numbersZand output is an image, which is mainly responsible for faking. By inputting random variables, realistic pseudo-samples are generated to deceive the discriminant model. The discriminant model is also a simple NN. It is used to judge the authenticity of input samples. When the data is recognized as coming from real data, the network’s output is close to 1, and when it comes from the original generated data, the network’s output is close to 0. The purpose of generating models and adversarial models is adversarial. The generation model to fake aims to make the discriminant model can not distinguish their own data while the purpose of the discriminant model is to distinguish the fake data. The main idea of the basic model of GANs is to make the two NNs continuously playing games, in which the model gradually learns the real sample distribution.In general, the training is considered complete when the two networks reach Nash equilibrium. Fig. 5 shows the basic model of GANs.
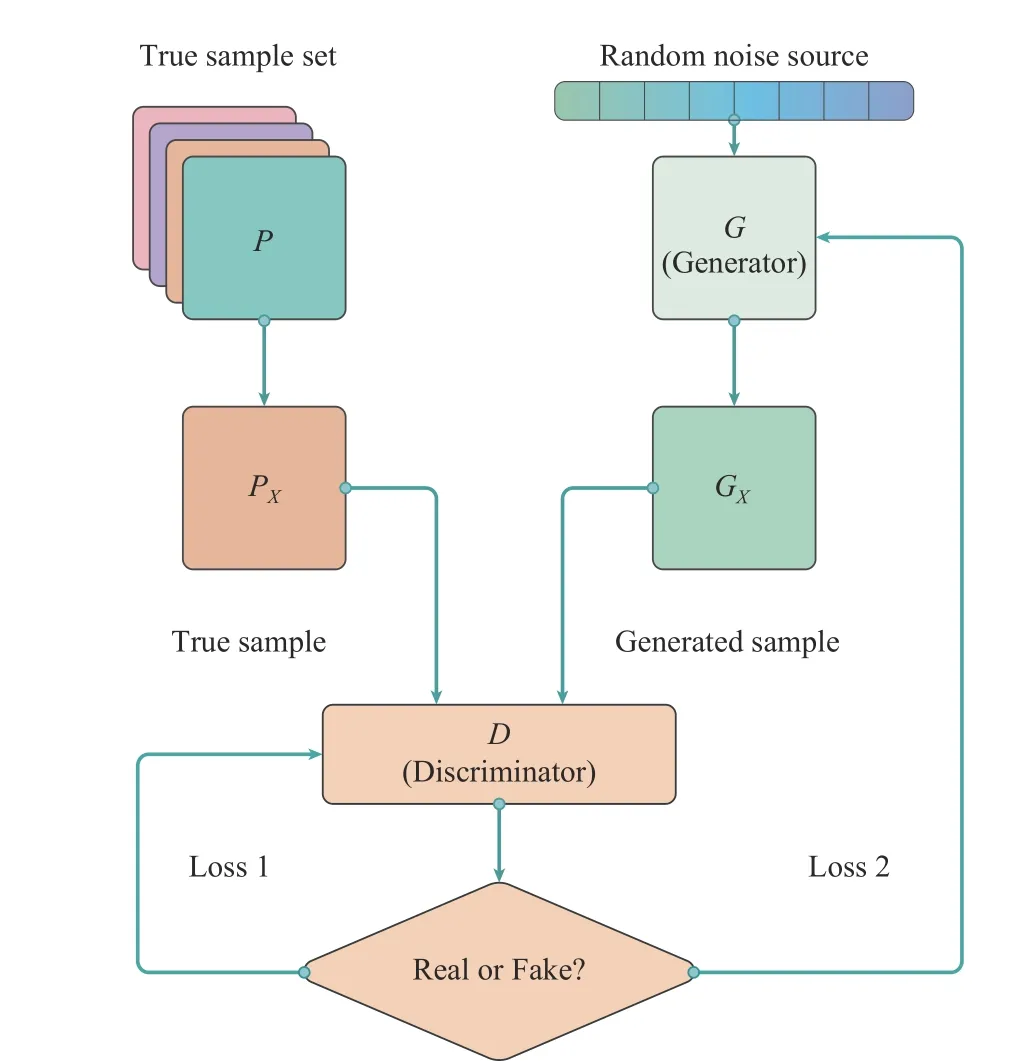
Fig. 5. The basic structure of GANs.
5) Relationship between DL and Networked Konwledge:
The goal of networked knowledge is the creation of new knowledge through the interaction and complementation of network systems as its components. In addition, networked knowledge is generated by the cross-fusion of network science and knowledge science. Therefore, the field of networked knowledge encompasses not only the basic theory of complex networks, but also the process of knowledge representation,computation, acquisition and service.
DL can deal with the process of knowledge extraction,analysis and prediction in networked knowledge. Specifically,DL can solve complex engineering problems in networked knowledge, such as image classification, target detection,scenario markup, NLP, and sample generation. Naturally, DL has made outstanding achievements in these fields. For example, the AlexNet network proposed by Krizhevsky achieved excellent results in image classification with its strong feature learning abilities, and it won the championship in the ImageNet large scale visual recognition challenge(ILSVRC) competition in 2012 [120]. R-CNNs could be used for target detection [129]. In essence, it is a kind of detector based on region. First, it fixed the size of the region, and then the features are extracted with trained CNNs, and finally, the multi-value classifier is used for detection. Farabetet al.[130]applied a multi-scale ConvNet network to the scene marking task, which reduced the time of training parameters and improved the system performance. LSTM neural network is a kind of NN specialized in processing time series, which can effectively solve the problems of gradient extinction and gradient explosion, and has been widely used in NLP [131].The align-DRAW model [132] is composed of two RNN,proposed by Mansimov, which automatically generates image samples by generating antagonism.
D. Networked Knowledge in Form of Networked Software
Networked software can be regarded as the concentration and crystallization of networked knowledge. In this regard, a brief summary of networked software research, which is given as a subset of networked knowledge in this paper, is provided.Historically, it was Valverdeet al.who have introduced complex network methodology in the study of networked software topology [133]. According to Valverde’s observation, the power exponent of the network formed by JDK(Java development kit 1.2)’s 9257 classes is 2.59. The average node-node path length of its largest subnet is 6.2. The networked software’s complex network phenomena of “scalefree” and “small world” have been also discussed in [134]. It was also pointed out by Heet al., that software systems,especially those in large scale, are kinds of artificially designed complex systems, and the structure of software can be seen as a kind of complex network topology [135].
People have also discussed the reason why networked software functions display complex network properties. A common answer to this question relates to the way software is traditionally compiled and applied. As a result, the more often reused software becomes favored network hub nodes.Moreover, due to the same reason, people detected that in software networks the in-degree of such software is usually higher than its out-degree [134]. Another reason leading to the complex network topology of software is its development methodology. This is in particular obvious in the use of software design methodology, where the software design patterns play a significant role. In the object oriented case,usually, the classes form the nodes and the call relations form the edges of networks with scale-free and small-world properties [136]. On the other hand, Valverde and Sole considered both classes and methods as nodes of complex networks and obtained similar results [137].
GitHub is the best-known platform for (open-source or private) software projects social coding [138]. Starting from 2008, GitHub supports now more than 3 million users. It provides a good opportunity for testing the complex network property of networked software. Reference [139] investigated the network consisting of 100 000 randomly selected GitHub software projects with 1 161 522 edges and 30 000 developers denoting project-project connections, where two projects are connected if they share at least one developer, and found that the average shortest path length between two arbitrary projects is 3.7.
Another framework of networked software, the concept of internetware, was proposed at the beginning of this century as a new paradigm of Web-based software development [140]. It has attracted researchers’ attention for roughly 20 years.Different from the traditional paradigm of top-down style software development such as the waterfall paradigm, the internetware paradigm is bottom-up. While traditionally the software is built by a team, the internetware is built and maintained by all programmers working on the Web. All previously developed software are kept for later new software development. They are dissolved in small parts called software entities. All these entities together with necessary specifications are called software assets and stored on a Web reservoir. Given these software assets, new software is built either upon request or automatically. This process is called software emergence. Recently a special forum for internetware has been held to present the recent results [141]. Fig. 6 shows the principle of internetware, where the emergence model is compared against the traditional waterfall model of software development. All software assets in the Web reservoir form a huge network which is the internetware. The emergence process absorbs software assets from this network,generates new software, and stores new software assets in the same network. Note that this process is very similar to the process of paper publication and referencing. It is highly plausible that the internetware forms a complex network. The authors of [142] mentioned this idea but without providing experiments data.
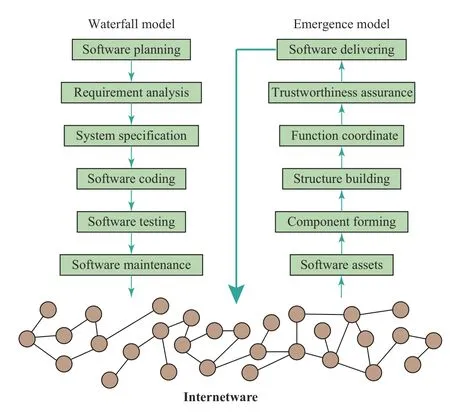
Fig. 6. The emergence of networked software.
For more information on early research about networked software see [135].
III. NETWORKED KNOWLEDGE AND POTENTIAL APPLICATIONS
The information explosion has brought about big data, and the concept of “big knowledge” has been proposed in response to the challenges of big data. In [25], the authors proposed a definition of big knowledge as a large collection of structured knowledge elements and introduced its ten massive characteristics. Further, big knowledge systems and big knowledge engineering were discussed. The weights of five of the ten massive features of big knowledge are investigated in[143]. MC2 in [25], that is the Massive connectedness,considers the degree of interconnectedness of knowledge. The two measures proposed therein coincide with the degree and average degree in network science well. The topology of interconnected knowledge has been noted in [25] to play an extremely important role in characterizing big knowledge more comprehensively. The results in [26] found that the shortest distance between semantics can well portray the similarity between semantics, revealing that the topology of semantic networks has an important role in portraying the relationships between knowledge. But, the important role of the network structure of knowledge linkage is still not directly proposed.
Here, a framework, called networked knowledge, is proposed, which is expected to study the new knowledge emerges from the aggregation of individual knowledge that is significantly different from individual knowledge. Taking knowledge as a component (node) and network as a coupling carrier, networked knowledge focuses on the new knowledge emerging through the interaction and complementarity among knowledge. The words networked knowledge is not completely new, which has been mentioned in [144]–[146].By modeling students’ thematically associated knowledge as a knowledge network, the structural features of this network,such as degree, eigenvectors and mediator centrality were investigated from network science perspectives [144]. The importance of realizing networked knowledge was found in[145], which presents a forward-looking view that networking knowledge can create a new kind of knowledge that will be much more valuable than the synthesis of individual knowledge. Here, networked knowledge was defined as Web+ Semantics, which uses the Web as a bearer medium to facilitate the dissemination of information globally. Similar to the idea of [145], a form of networked knowledge was discussed in [146], that is digital library. Its main idea is to organize and disseminate knowledge through the Web.However, the definitions of networked knowledge in the above literature have limitations, while the networked knowledge defined in this paper is fundamentally different from the one proposed in previous literature.
In our framework, the meaning of knowledge is broad in the sense that it can be any information elements such as concepts, entities, data, and even software that can be processed by computers. The network structure (rather than Web)represents the abstract relationship between knowledge, which can be reciprocal or antagonistic. The emergence of networked knowledge is based on the development of complex networks and knowledge engineering, where AI is the main tool for processing data (as shown in Fig. 7). There are already solid theories and technologies for the study of networked knowledge, for example, node correlation analysis,community discovery, self-organized evolution, etc. Compared with traditional knowledge engineering, networked knowledge is based on the rapid development of complex networks, and with the help of its theories and technologies, it can promote the further development of knowledge engineering. Possible research topics will be discussed in Section IV.
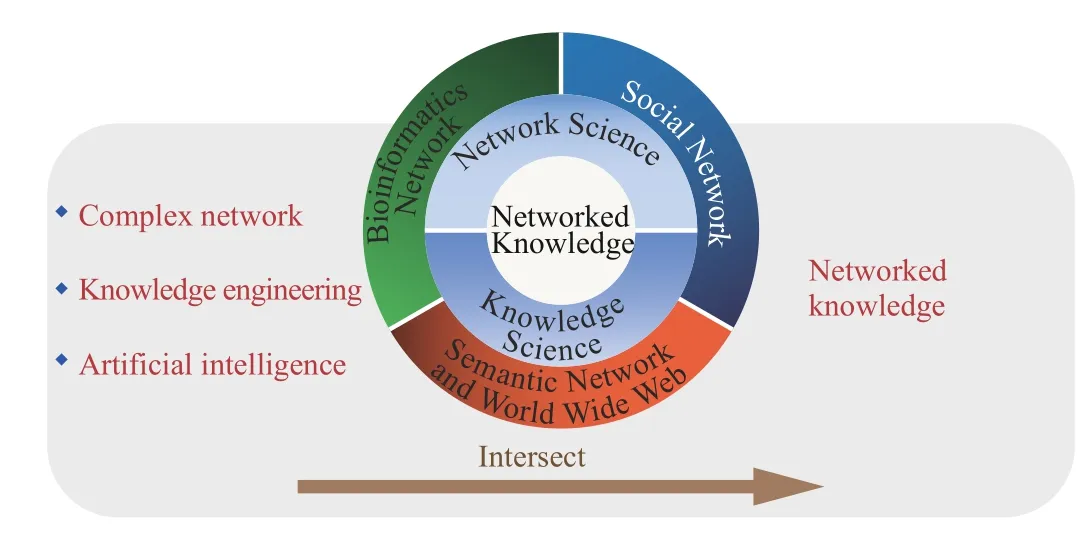
Fig. 7. The emergence of networked knowledge.
In traditional knowledge engineering, the focus is more on the knowledge or attributes themselves, and a large amount of research has focused on how to design algorithms that can better capture knowledge (entities and relationships) from materials such as texts, images or videos. Networked knowledge does not focus on how to acquire knowledge,rather on the unique knowledge that emerges through interaction in networks, such as the structural characteristics of the networked knowledge and new characteristics of nodes and relations under the networked structure. At the level of the overall nature of the network, it is unknown whether there are modalities, community structures, small-world properties and scale-free properties of networked knowledge. For the relationship between knowledge, the basic problem is how to define and find the relation between knowledge, such as similarity and the closeness of the relationship between knowledge. The two measures in MC2 [25] are an example,which measures the relation between knowledge from the perspective of network structure.
Networked knowledge is not a completely new concept, and some approaches from network science have already been applied in existing research on knowledge engineering. In the following, we will review the applications of networked knowledge on biological networks, semantic networks, social networks, and power networks.
A. Applications in Biological Networks
Humans have long suffered from diseases, among which congenital given diseases are particularly difficult to treat. The construction of a gene knowledge graph can help medical professionals understand the genetic-level causes of the emergence of congenital diseases, which can further help reduce and treat congenital diseases. The knowledge base of gene functions constructed in [28] is structured and computable, containing a large number of entities and relationships.Unlike the protein knowledge base provided separately in [27]and the gene function knowledge graph in [28], the authors of[63] constructed a multi-layered yet heterogeneous molecular network of gene-protein-metabolites where the robustness of the heterogeneous network is also analyzed. In addition, the defined importance scores therein enable better discovery of important genes. Furthermore, a systematic Gene Ontology Annotation method was proposed in [147] for Regulatory Elements by leveraging the powerful word embedding in NLP, where a framework of assemblying heterogeneous biological networks and generating knowledge graph as resources for biologist was also suggested.
The side effects of drugs have been a medical challenge and knowledge engineering is also helpful to identify and predict the side effects of drugs [29], [30]. In [148], knowledge graphs are used to provide a unified representation of heterogeneous data and present a machine-readable interconnected representation of biomedical knowledge. Adverse drug reaction prediction is then accomplished by using knowledge graphs. In [29], [30], the problem of predicting multi-drug side effects was studied using multi-relationship mapping. In particular, link prediction methods based on CNNs were shown to have good accuracy [29], [31]. For example, the prediction of multidrug side effects, drug target proteins and drug interactions was performed using linkage prediction techniques [29].
B. Applications in Semantic Networks
A semantic network is a structured way of graphically representing knowledge and can be seen as a typical complex network [149], [150]. Taking concepts as nodes and semantic relationships as edges, a semantic network can be represented intuitively. Due to the huge amount of information in the real world, manual input of semantics and the relationships between them is unrealistic. An approach based on domain knowledge graph was proposed to annotate semantics automatically in [33] to quickly search, understand and analyze massive network document resources. For the increasing importance of enterprise knowledge graphs, the authors discussed two methods for constructing semantic networks in [151]. The method in [152] combined DL and knowledge graph to present the semantic centered method for video anomaly detection which can detect anomaly more accurately.Motivated by the demand of capturing richer text content,concept frame graphs were proposed to discover knowledge from text [153]. By using information content to weight the shortest path length between concepts, the method proposed in[26] can better portray the similarity between semantics compared to other methods. The advantages of semantic networks in processing big data are fully systemized when analyzing the information, which provides a powerful help to curb the COVID-19 [34]. Combining knowledge base and semantic web services, a flexible business process management system was designed to provide support for various dynamic business processes and their continual improvements[154]. The semantic network is far from receiving enough attention as an intuitive representation of human knowledge.For example, how existing words derive new meanings and how a new word emerges. Analyzing and studying the evolutionary dynamics of the semantic network and paying attention to the emergence of human wisdom is extremely important for understanding the evolution of human civilization, which is one of the issues to be studied in the future of networked knowledge.
C. Applications in Social Networks
The social network is a social structure composed of many nodes, which usually refer to individuals or organizations. To be specific, social networks represent a variety of social relationships, through which various people or organizations are connected from casual acquaintances to tightly knit family relationships. Knowledge graphs are widely used in social networks because various relationships and attributes can be regarded as knowledge. For example, to infer linkages in the linked data of online social networks, a knowledge graphbased architecture was developed, which offers acceptable digital evidence in court and assists criminal investigators in their investigations [35]. A real-time online streaming data learning approach may be generated by embedding relational fractals online social networks into a knowledge graph. As a result, devices can enhance computational efficiency by using limited resources [155]. In [36], a knowledge graph was used to carry out de-anonymization and inference attacks in social networks, and legitimate users’ privacy will be more likely to be taken by malevolent attackers. To decrease risks in social networks, an assessing trust mechanism based on knowledge graphs was suggested, which detects honest and dishonest members in social networks [37]. A knowledge graph is built to improve NLP in social networks, and the proposed method could be applied to more than 20 products at LinkedIn [156].A knowledge graphs was used to construct a Hybrid Louvain-Clustering model of social networks in [157], then, user behaviors in a social network can be classified efficiently. A system called GeoTeGra is used to generate knowledge graphs based on social network data, which could deal with geographical and temporal information effectively. Furthermore, the system can be effectively compatible with different machine learning algorithms [158]. In [38], a novel news recommendation model was constructed through social networks and knowledge graphs. Moreover, a random walk sampling strategy was adopted to improve the effect of news recommendations. Similarly, in [39], a novel recommendation method is implemented by combining social networks and knowledge graphs, and the proposed method was used to solve the problem of recommending attendees and topicrelated content at the same time. A particular model is obtained by combining a knowledge graph and a CNN, which is used to extract serviceable information in the social graph of social networks. As a result, the node classification effect is improved [159].
Fake news in social platforms has been shown to be able to cause global bad effects. Thus, it is urgent to identify fake news. Recently, some studies have successfully implemented knowledge graph-based false news identification [160], [161].They decompose news into the form of an entity-relationshipentity triad, embed this triad into the original knowledge graph by the knowledge graph embedding technique, and discriminate fake news based on this new knowledge graph.However, how to use networked knowledge to analyze the authenticity of information remains to be studied.
D. Applications in Power Networks
Power networks include the process of energy production,transmission and consumption. Through advanced sensing and measurement technologies, advanced equipment technologies and advanced control methods, power networks are reliable,safe, economical, efficient and environmentally friendly. Not only because the power networks contain multiple network nodes, but also the data and equipment in the power networks can be abstracted as knowledge, so numerous applications of knowledge graphs can be found in power networks. More specifically, a knowledge graph-based approach was utilized to visually evaluate and mine data in a power network in order to truly sense the internal functioning status of the power network [83]. By merging knowledge graphs and graph neural networks (GNNs), a novel topology identification of power networks was suggested, which has been tested in an IEEE-188 system with positive results [40]. A graph search method based on constructed knowledge graph was proposed, which was applied to the accurate information retrieval of power equipment in power networks, so as to improve the efficiency of power equipment management [41]. In [162], a knowledge graph was used to the semi-automation effect of equipment in power networks, thus greatly improving the daily operation efficiency of equipment in power networks. Innovative dispatching of power networks based on knowledge graphs was proposed, which is proved to be effective through an experiment on power grid [163]. Similarly, a power grid dispatching method based on GNNs and knowledge graph is proposed in [42]. In order to solve the problems of insufficient cross-service information sharing and insufficient utilization of power networks, an idea of knowledge graphs of power system full-service data was proposed, and the effectiveness of the proposed method was demonstrated by experimental simulations [164]. In [165], a knowledge graph-based intelligent auxiliary operation and maintenance system for power networks was conceived and built, which significantly decreases the problem hit percentage and the problem reaction time. In [43], a knowledge graph was applied to educational resource management in power networks, the proposed method was proved to be effective in the search and analysis of educational resource management by experimental simulation.
E. Other Applications
Let us first explore the topology characterizing of the networked knowledge. Traditional researches on knowledge engineering focuses more on the knowledge itself or the relationships between knowledge, while less on the global structure of knowledge connections. Organizing knowledge into networks leads to the ability of obtaining the interaction topology of the networked knowledge. Wikipedia is a large and valuable existing knowledge base, and it is a good representative example to study the networked knowledge[166]–[168]. The results in [167] found that networking knowledge in Wikipedia under different languages, the constructed networked knowledge was found to have scalefree properties. Similarly, the results of the literature [168]showed that the networked knowledge constituted by the four topics Biology, Medicine, Mathematics and Physics has scalefree properties.
Knowledge exploration in complex networks has received some attention and results [169]–[172]. By regarding each knowledge as a node and the connections between knowledge as edges, the authors of [169] represented knowledge and its connections as a complex network on a multilayer topology,then modeling the knowledge discovery process as a random wandering process. Memory was incorporated into exploration dynamics and a self-avoiding walk was implemented to avoid passing through already visited nodes by introducing a random flight [170]. A centralized way to acquire knowledge throughout the network was considered in [171], where the existence of a center called the network brain could assemble and store all the acquired knowledge. The learning curves of sequences obtained from four random walk dynamics and four network models with different topologies were analyzed,providing an in-depth analysis of the impact of network topology and random walk dynamics on the knowledge acquisition process [172].
In addition, it has been shown that text knowledge and human language can also be represented by complex networks and such representations could provide holistic information[173]–[177]. Such a modeling approach will facilitate the authorship attribution where the author of the text can be identified from distinguishing the writing style of a book[174]. Within this context, a generalized similarity measure was suggested in [177] to compare texts which accounts for both the network structure of texts and the role of individual words in the networks and was further employed to yield a high-accuracy authorship attribution algorithm.
IV. RESEARCH CHALLENGES AND FUTURE TRENDS
Due to the rise of a large number of emerging information technologies, traditional knowledge engineering and the current form of knowledge representation has lagged behind,and the traditional forms of knowledge representation, storage and dissemination are no longer adapted to the present time in the context of big data. Big knowledge was proposed early to deal with the challenges brought by big data [25], but there is still relatively little research. On the one hand, it is because the volume of data is growing at an explosive rate, and the difficulty of acquiring complete data has risen sharply. On the other hand, traditional knowledge engineering techniques have lagged behind, and new theoretical techniques have not yet been developed. Networked knowledge is proposed as an evolution of traditional knowledge engineering to better deal with new problems in the era of big data.
In biomolecular networks, networked knowledge technology has a wide range of potential applications [63]. Due to the complexity of gene expression, the etiology of congenital diseases has been a major challenge for the medical community. The etiology of congenital diseases is closely related to biomolecular networks, and biomolecular networks contains many different layers and different organizational forms in biological systems, including gene transcription regulation network, biological metabolism and signal transduction network, protein interaction network. These networks are made up of large molecules such as genes and proteins.Therefore, the systematic and comprehensive study of biological macromolecules and their interactions has become an important direction of biological research, which has important theoretical significance and practical value for disease research, new drug development, the origin of life and many other research fields. Based on networked knowledge technology, knowledge can be extracted according to different data characteristics of biological macromolecules, and special network structures can be formed through the data interaction,so as to predict biological signal transmission, gene expression regulation, substance metabolism and cell cycle regulation process. For example, in the study of virus invasion of the human body, through the network knowledge technology,the host protein and the virus protein knowledge extraction operation, construct the virus-host protein network, and finally identify the specific functional groups in some virus infections from the network. By using three descriptors of network topology, functional annotation and tissue expression profile to characterize proteins, a method to predict virus attack targets from a human protein-protein interaction network was established.
Networked knowledge technology can be well applied in swarm intelligence technology. With the advent of the industry 4.0 era, swarm intelligence technology has been widely applied in the field of industrial production. Compared to a single agent, swarm intelligence technology’s advantages is that it can make the overall performance from organization,coordination, stability, flexibility and adaptability to the environment through the interaction of individual information,such as individual detection, cognition, independent decisionmaking, etc. Through the application of networked knowledge technology, corresponding network structure and knowledge interaction could be better designed to improve the ability of swarm intelligence to perform tasks in unknown environment,communication interference, difficult information acquisition,insufficient system capacity and limited energy supply. For example, when underwater agents carry out cooperative reconnaissance in the ocean, there are some problems such as complicated ocean environments, limited underwater communication and limited energy supply. Through the networked knowledge technology, the knowledge of each agent and the unmanned system network could be obtained, so that the swarm intelligence has better autonomy, flexibility,extensibility and robustness.
V. CONCLUSIONS
The progress of knowledge engineering has reached a stumbling block and is no longer fit for today’s high-speed development. To handle increasing difficulties in knowledge engineering, new technology is necessary. This paper begins with reviewing the evolution and technologies of complex networks, knowledge graphs, and AI. Then a framework,networked knowledge, is proposed based on network science,which focuses more on the group knowledge that cannot be represented by individuals. It is followed by a discussion of its applications in biological networks, semantic networks, social networks, and power networks. Finally, the research challenges and future trends of networked knowledge are presented.
 IEEE/CAA Journal of Automatica Sinica2022年8期
IEEE/CAA Journal of Automatica Sinica2022年8期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Consensus Control of Multi-Agent Systems Using Fault-Estimation-in-the-Loop:Dynamic Event-Triggered Case
- A PD-Type State-Dependent Riccati Equation With Iterative Learning Augmentation for Mechanical Systems
- Finite-Time Stabilization of Linear Systems With Input Constraints by Event-Triggered Control
- Exploring the Effectiveness of Gesture Interaction in Driver Assistance Systems via Virtual Reality
- Domain Adaptive Semantic Segmentation via Entropy-Ranking and Uncertain Learning-Based Self-Training
- Position Encoding Based Convolutional Neural Networks for Machine Remaining Useful Life Prediction