
基于视频机器分析的目的地形象差异对比
——以北京YouTube视频为例
2022-08-22 08:17蘧浪浪
旅游学刊 2022年8期
邓 宁,蘧浪浪
(1.北京第二外国语学院旅游科学学院,北京 100024;2.北京旅游发展研究基地,北京 100024)
引言
以往人们习惯于通过游记、博客、旅行照片等文字或图片素材获取目的地信息,近年来,4G/5G通信网络的发展进一步丰富了人们获取旅游信息的方式,视频也逐渐成为潜在游客获取旅游目的地信息并建构旅游形象的主要渠道。作为一种动态视觉材料,视频比图片和文本的信息丰富度更高,可以通过丰富的叙事情节讲述故事,使受众对目的地产生更高程度的沉浸感,因而吸引越来越多的游客通过旅游视频了解目的地,并做出相应旅游决策,这也意味着目的地形象越来越受到视频传播的影响,视频俨然成为富媒体时代旅游营销的有力媒介,这为旅游目的地营销打开了一扇新的大门。
然而,不同主体发布的旅游视频对目的地形象的影响存在较大差异。长期以来,目的地营销组织(destination marketing organization,DMO)从官方视角出发投射目的地形象,其发布的视频宣传片、小册子、网站信息等职业生成内容(occupationallygenerated content,OGC)带有一定的诱导性,浏览量往往偏低,因此传播效果有限。而如今,更加独立自主的旅游者更喜好用视频来记录并分享自身旅游经历,这种分享是一种相对独立的、不含功利色彩的第三方宣传,因此相比OGC 视频,人们更愿意相信用户生成内容(user-generated content,UGC)。此外,也有研究表明,游客对目的地的印象更多受UGC投射影响,而受OGC的影响较小,这给DMO 进行目的地营销推广带来了一定的挑战。因而,有必要了解二者在投射目的地形象方面的差异,推进旅游领域对视频内容的探究,从而促进和丰富目的地形象的研究方法及研究理论。同时,希望借鉴UGC 视频在内容塑造和展示方面的成功经验,为DMO进行目的地形象营销提供实践指导。
事实上,UGC 和DMO 在投射目的地形象方面的差异已受到学界广泛关注,但已有研究所用数据仍以文本及图片素材为主,针对视频素材的研究还处于初级阶段,研究方法上以传统定性研究为主,在大数据时代其局限性越发明显。因此,本研究考虑借鉴计算机领域的研究方法和技术手段,利用机器学习深入理解视频内容,旨在解决如下几个关键问题:
(1)旅游目的地形象视频的内容结构有什么基本特征?
(2)旅游视频与文本素材在投射目的地形象方面有何差异?
(3)UGC 和OGC 视频在目的地投射形象和视频场景设计上有何差异?
1 研究综述
1.1 旅游目的地形象相关研究
目的地形象被广泛认为与目的地营销直接相关,能够直接影响潜在游客对目的地选择的决策。在目的地形象理论中,最为经典的定义由Crompton提出,即目的地形象是“一个人对于目的地的所有信念、想法、印象的总和”。
过往研究对旅游目的地形象进行了多种不同的分类,一种广为接受的分类方式是根据其面向主体的不同,分为供给侧的投射形象(projected image)和需求侧的感知形象(perceived image)。投射形象是指,旅游目的地政府、旅游企业、社会团体等旅游形象塑造者对外宣传并意图在旅游者心目中树立的形象,而感知形象则代表了旅游者对旅游目的地感受的总和。然而,在关于UGC 的研究中,往往难以明确区分游客身份,游客既属于感知者,又属于投射者,一方面受到DMO所刻意投射的形象影响,另一方面又主动将自身感知形象以文字、图片、视频等多种形式投射给社交圈层中的潜在游客。相较于OGC所投射的目的地形象,目前学术界普遍认为UGC 有着更好的口碑营销作用,其内容往往更能得到潜在游客的信任,因此其在投射目的地形象方面更具优势。
在这一现实背景下,关于UGC 和OGC 目的地形象的比较研究越来越受到学者关注,研究主要集中于对用户和DMO生成内容进行对比分析,探讨二者在建构目的地形象方面的差异,但值得注意的是,已有研究主要停留在图片表征目的地形象阶段,对视频素材表征目的地形象的探讨尚且不足。
1.2 基于视频素材的旅游目的地形象研究
早期旅游领域的学者主要聚焦视频对旅游研究重要性的剖析,研究引入了一些关于视觉的新兴观点,为旅游视觉文化的研究打下了理论基础。Urry在研究中提到旅游专业人士、学者以及游客和当地人已普遍认可旅游的本质是以视觉为中心,而旅游视频是一种描述旅游者旅游经历的视觉媒体,能够提供丰富的视觉证据,这使研究人员能观察到视频中当地人或外地游客的生活文化场景,并且洞察镜头背后的人物行为,旅游视频所隐含的丰富的目的地信息为深入开展目的地形象提供了较好的研究素材。
目前,旅游视频的研究主要以旅游宣传片、旅游广告、电影、微电影以及视频类网站的视频为数据源。其中,主流研究主要以旅游宣传片为研究素材,如Shani 等、Yan 和Santos 以旅游宣传片“CHINA,FOREVER”为素材,探讨宣传片对中国旅游形象的塑造和影响。Pan等通过对新西兰两个旅游电视广告的对比分析,揭示了两部电视广告表征内容的异同及所投射的新西兰的目的地形象。部分研究以旅游微电影或电影为素材,分析电影播放前后观看者旅游动机及对目的地感知形象的变化,而以抖音、YouTube等视频类网站数据作为数据来源开展目的地形象研究较少。
在视频分析方法方面,目前旅游领域对视频的分析主要采用传统的问卷调查、实验设计、访谈等定性方法,少数学者开始尝试借助Riva FLV Encoder、Movie Maker等视频编辑软件抓取视频画面,并对画面的图像表征进行人工归纳分析,以揭示目的地形象。整体来看,目前旅游领域对视频素材的研究还比较初级,研究方法较为传统,研究样本量较小,越来越难以全面刻画、表征大数据时代背景下目的地的整体旅游形象,因此,越来越有必要借鉴其他学科先进的研究方法和技术手段。
1.3 视频内容分析相关研究
目前,视频内容分析在计算机和机器视觉领域已有较为成熟的研究。根据Rose的研究,视频内容机器分析方面研究一般涉及特征提取、结构分析和抽象,从而将视频解析为有意义的序列、场景、镜头和帧。视频序列往往由多个视频场景构成,每个视频场景由多个镜头构成,而镜头由帧构成,其中场景定义为语义上相关、时间上相邻的一组与主题相关的镜头,关键帧是代表镜头中最重要的、有代表性的一幅或多幅图像。
视频内容分析中特征提取是通过探索视频中图像、运动、音频和文本等来分析帧和镜头,以识别每个镜头的重要特征,进而更好地理解视频内容。以往研究为了减少视频分析的复杂性往往会排除声音特征,即研究不考虑声音元素。结构分析主要是提取视频序列的时间结构信息并识别视频中有意义的视频场景的过程,关于视频的场景检测已经在各种媒体中进行了研究,但为结构化视频设计的方法往往无法成功分割旅行视频。因此Chu等提出了旅游视频场景检测的方法,他们利用同一旅程中拍摄的照片和视频之间的多模态相关性,借助图像聚类结果实现了旅游视频场景的准确检测。由于无法保证能同时获取同一旅程中的视频和照片素材,这一方法也有较多局限性,因此更进一步的研究中,他们从游客日程安排中提取关键字,利用关键字从图像搜索引擎中检索与所访问景点相关的照片,实现更准确的场景检测。视频抽象是创建关于视频结构的视觉信息表示的过程,类似于从文本文档中提取关键字或摘要,即从原始视频中提取视频数据的子集(如关键帧),这在计算机领域已有较为成熟的算法,目前常用的算法主要有基于图像帧间序列比较的关键帧提取、基于视频聚类的关键帧提取等。用关键帧表征视频内容,不但可以实现一定缩放比例的视频内容提取,同时也能够实现对视频内容的较高保真度描述。
对视频内容的进一步抽象与文本化的过程被称作视频标注,其将计算机视觉和自然语言处理(natural language processing,NLP)相结合,自动生成对视频内容的文本描述,由于其对视频数据检索的需要而成为机器视觉研究热点。机器自动描述图片内容一直是人工智能领域的难题,为解决这一问题,Google团队以encoder-decoder结构为基础,提出了NIC(neural image caption)模型,该模型能使机器自动识图并生成对图片的文本描述,为视频标注研究奠定了基础;其后,Xu 等为解决以往仅以图片作为唯一特征变量无上下文关联的缺点,引入了attention 机制使模型能理解图片背后的抽象概念,从而提高文本描述的准确性。通过文献梳理发现,计算机领域对视频内容的分析随着技术的发展不断深化,也为本研究的开展奠定了基础。
2 研究对象与数据准备
2.1 案例简介
北京是中国的首都,是中国的政治、经济和文化中心,有着丰富的旅游资源,多年被世界权威机构GaWC 评为世界一线城市,每年接待外国游客数量在国内各城市中排名第一,具有重要的国际地位,因此选择北京作为研究对象探索国际游客视角下的北京旅游形象较为合适。另外,由于北京市文化和旅游局在YouTube开设账号发布旅游宣传视频,且内容定时更新,这为本研究对比UGC和OGC内容提供了充足的数据支撑。基于以上考虑,本研究选择北京作为研究对象,研究结果将有助于了解国际游客眼里的北京旅游形象与中国投射的北京旅游形象的差异,从而为北京市打造国际一流旅游名城,同时进行海外旅游营销提供参考。
2.2 数据准备
研究选择YouTube视频作为研究素材主要有以下两点考虑:第一,研究主要讨论国际游客眼中的北京旅游形象,而YouTube 作为全球著名的视频在线分享平台,有着庞大的国际用户群体,是国际游客获取目的地信息的重要社交平台,因此,选择该平台更易获取国际游客数据。第二,YouTube 网站要求用户在上传视频时填写描述视频内容的相关信息,包括视频标题、描述、标签、分类等,其高价值的元数据为研究的开展提供了极大便利。
最终,本研究选择YouTube视频作为研究素材,以YouTube 上国际个人用户发布的旅游视频作为UGC视频样本,北京市文化和旅游局官方账号“Visit Beijing”下发布视频为OGC 视频样本。已有研究中使用关键词“travel”“trip”和目的地名称来收集数据,本研究采取相同策略,以“travel”和“visit Beijng”作为关键词进行搜索。研究于2020 年7 月10日起开始对数据进行采集,共抓取了586个UGC的视频数据集(包括视频及元数据)、106个OGC视频数据集。对于OGC 视频,研究剔除了其中仅有15 秒的6 个视频,将其余100 个视频作为研究素材。鉴于OGC视频中60%的视频时长大于2分钟,因此,本研究也选取时长在两分钟以上的UGC 视频,同时剔除视频发布日期在2017 年以前、非用户发布、非旅游类的视频,最终得到100个UGC视频。
3 研究方法
3.1 研究路线
本研究主要分为3 个阶段。首先,研究基于深度学习方法对UGC 和OGC 视频进行解析,得到机器识别的北京旅游形象维度,由于机器识别结果分类较为粗糙,且部分维度之间相互重叠,因此,研究基于已有目的地形象分类对机器识别结果进行修正,并形成北京旅游形象维度。其次,研究比较了文本及视频素材在投射北京旅游形象方面的差异。已有研究大多只是分析一种特定素材,如文本、图片或视频,本研究试图同时分析视频内容及文本素材,以期全面揭示北京旅游形象。视频描述信息包含丰富的目的地形象信息,因此,本研究选择视频描述作为文本素材,同时通过视频内容分析法对视频进行解析,以揭示视觉素材表征的北京旅游形象。最后,基于以上分析对UGC 和OGC视频在目的地投射形象及场景设计两方面进行对比研究。
3.2 研究方法和技术手段
考虑到UGC 和OGC 内容涉及视频及文本素材,研究采用内容分析法、视频内容分析法、视频标注3 种数据分析方法进行相关分析。其中,内容分析法主要借助自然语言处理领域的NLTK进行视频描述信息处理,视频内容分析则主要借鉴计算机视觉领域成熟算法深度解读视频含义,从而将视频所承载的隐性内容解读出来。
3.2.1 视频内容机器分析
内容分析法是一种常用的对信息进行客观、系统和定量描述的研究方法,它可以用于对显性内容,如字词的分析来判断内容表达的观点。为了得到文本信息所表征的目的地形象属性,研究利用NLP 领域的文本分析包——NLTK对视频描述信息进行分词、词干提取和词频统计,并进一步提取出与旅游目的地形象相关的关键词,这代表了视频文本所表征的北京旅游形象。
视频内容分析常用来对视频内容进行解析,本研究主要通过该方法将视频抽象出关键帧,并进一步从关键帧中提取出与目的地形象相关的文本信息,从而比较UGC 和OGC 视频表征的目的地形象差异。旅游视频往往涉及的场景较多,且场景之间切换频繁、画面连贯性差,这意味着视频相邻两帧之间差别较大,鉴于此本研究选择基于内容感知的场景检测算法和基于帧间差分的算法来实现视频主要场景画面的提取,由此将动态视频转化为静态图片。采取上述算法对200 个旅游视频进行解析,为保证研究结果的准确性,研究剔除了冗余帧,最后从UGC 和OGC 视频中分别提取了6359 个和5263个关键帧。
不同于以往研究人工对图片进行编码、归类,本研究利用百度开源的图像识别技术对关键帧进行识别,提取图片的主要视觉元素。研究主要利用“地标识别”和“通用物体和场景识别”API对关键帧进行识别,其中,地标识别提取了图片中的目的地地标信息,而通用物体和场景识别提取了图片的其他场景信息,包括场景的类别及具体场景(图1),这些信息就是视频所表征的目的地形象具体属性。

图1 图像识别结果示例Fig.1 Examples of image recognition results
3.2.2 视频标注
视频标注是指计算机自动生成给定视频的文本描述,这种描述往往是一个句子或短语,揭示了视频画面中多个视觉元素之间的联系,是对视频画面中重要活动、事件的描述,如“a man walking down a street in front of a building”,因此,研究采用视频标注技术对视频内容进一步挖掘,并提取出描述信息中相互关联的多个视觉元素,即人物属性及物体属性,从而能更全面揭示视频所表征的目的地形象。
视频标注一般涉及视频场景检测、图像特征提取及图像标注等环节(图2)。本研究基于深度学习框架PyTorch,利用Google 团队推出的NIC 模型,通过ResNet-101 模型结构和COCO 数据集对旅游图片进行训练,选择卷积神经网络作为图片编码器,提取视频图像特征,并将提取结果传入LSTM(long short-term memory),LSTM 作为解码器对图像视觉特征进行处理并输出序列。通过利用视频标注算法,本研究构建了一个视频文本化描述模型,该模型可以抽象旅游视频主要场景,并生成文本描述结果,是后续形象挖掘的主要技术手段。
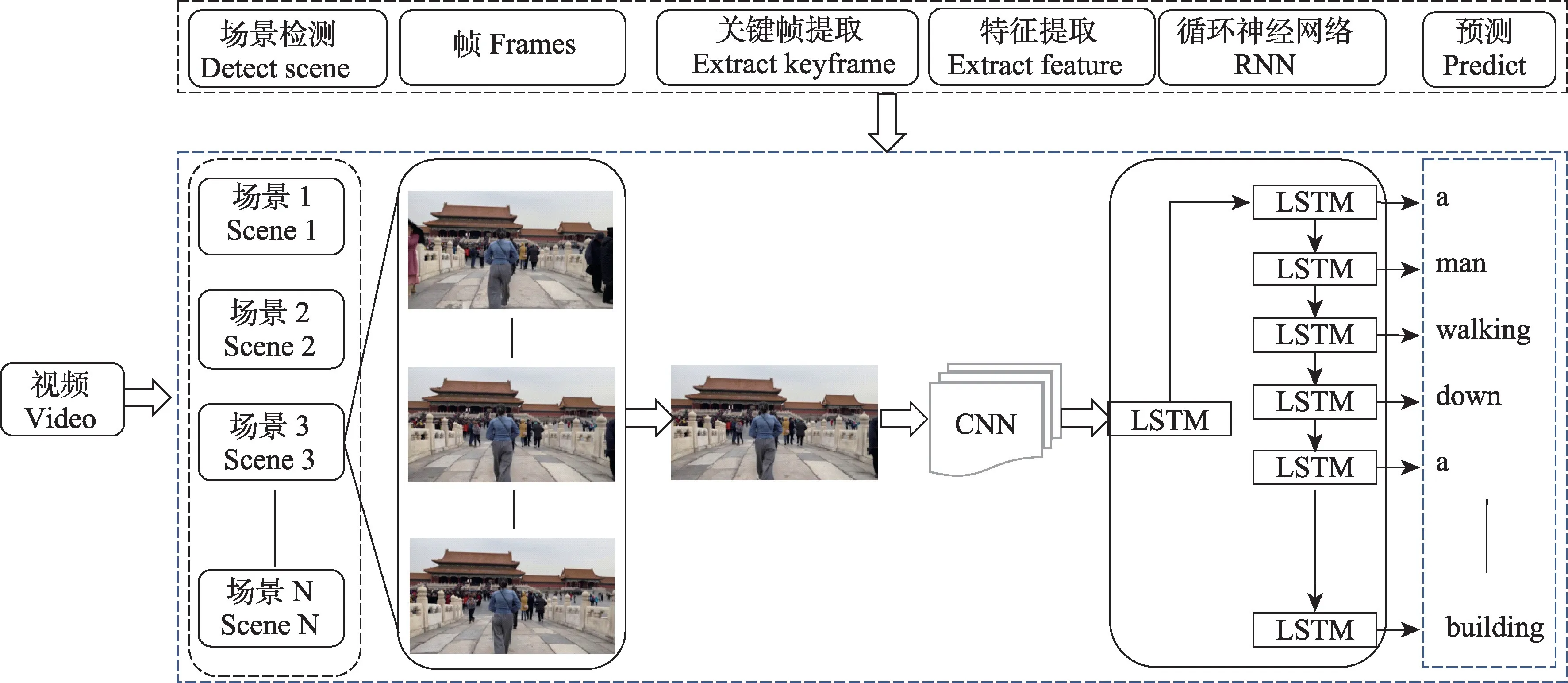
图2 视频标注技术原理示意图Fig.2 Procedure of video captioning technique
4研究内容
4.1 目的地形象维度划分
已有研究表明,没有一种能够完全包含目的地形象所有属性的维度划分方法,使用不同的研究方法得到的目的地形象维度也不同。Stepchenkova和Zhan在基于图片的目的地形象研究中,将目的地形象的主要属性分为了自然环境、人、传统服饰等20类,Mak在研究基于图片的在线目的地形象中,将目的地形象的主要属性分为了自然环境、人、文化艺术等11类,可以发现这些分类大都包含自然环境、人、文化艺术、基础设施四大维度。因此,本研究结合已有目的地形象维度分类对机器识别的目的地形象维度进行了合理调整,最终确定了本研究的目的地形象维度。
本研究通过视频内容分析方法从视频中解析出11 622个关键帧,考虑到人工对图片编码的局限性,本研究引入“图像识别”技术对大样本量图片进行自动识别、归类,得到自然风景、植物、动物等7个维度。“地标识别”结果均为旅游地标,如故宫、天安门等,因此增加“旅游景点”维度,据此初步得到机器识别的代表北京旅游形象的八大维度。在此基础上,借鉴已有研究对目的地形象维度的划分,本研究对上述8 个维度进行了修正,主要遵循3 点原则:第一,将非重点、非必要的维度合并为同一类;第二,由于机器识别的维度颗粒度较细,某一维度下同时包含其他维度的内容,因此需人工对机器识别维度进行判断,把不同维度下同属一类的内容归到相应维度;第三,去掉与目的地形象无关的维度。基于上述原则,本研究将植物类、动物类合并为动植物类,并把自然风景类中的植物划分到该类;人物类中的体育活动归为特定活动类;建筑类中的传统建筑、商品类中的工艺品和人物类中的文艺、典礼活动归为文化艺术类;商品类中的食物、人物类中的餐饮娱乐活动、建筑类中的餐饮场所归为饮食类;将建筑类中的现代建筑、商店商场、街道等一般设施、商品类中的公共设施、交通类中的索道、游览车等旅游设施归为基础设施类。经过修正,本研究最终将目的地形象调整为9个维度(图3),这几乎涵盖了目的地形象的主要属性,为本文进一步的目的地形象对比研究构建了基础框架。
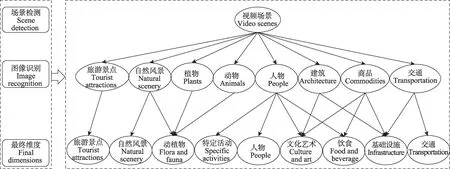
图3 北京旅游形象主要维度Fig.3 Main dimensions of Beijing tourism image
4.2 视频描述文本内容比较
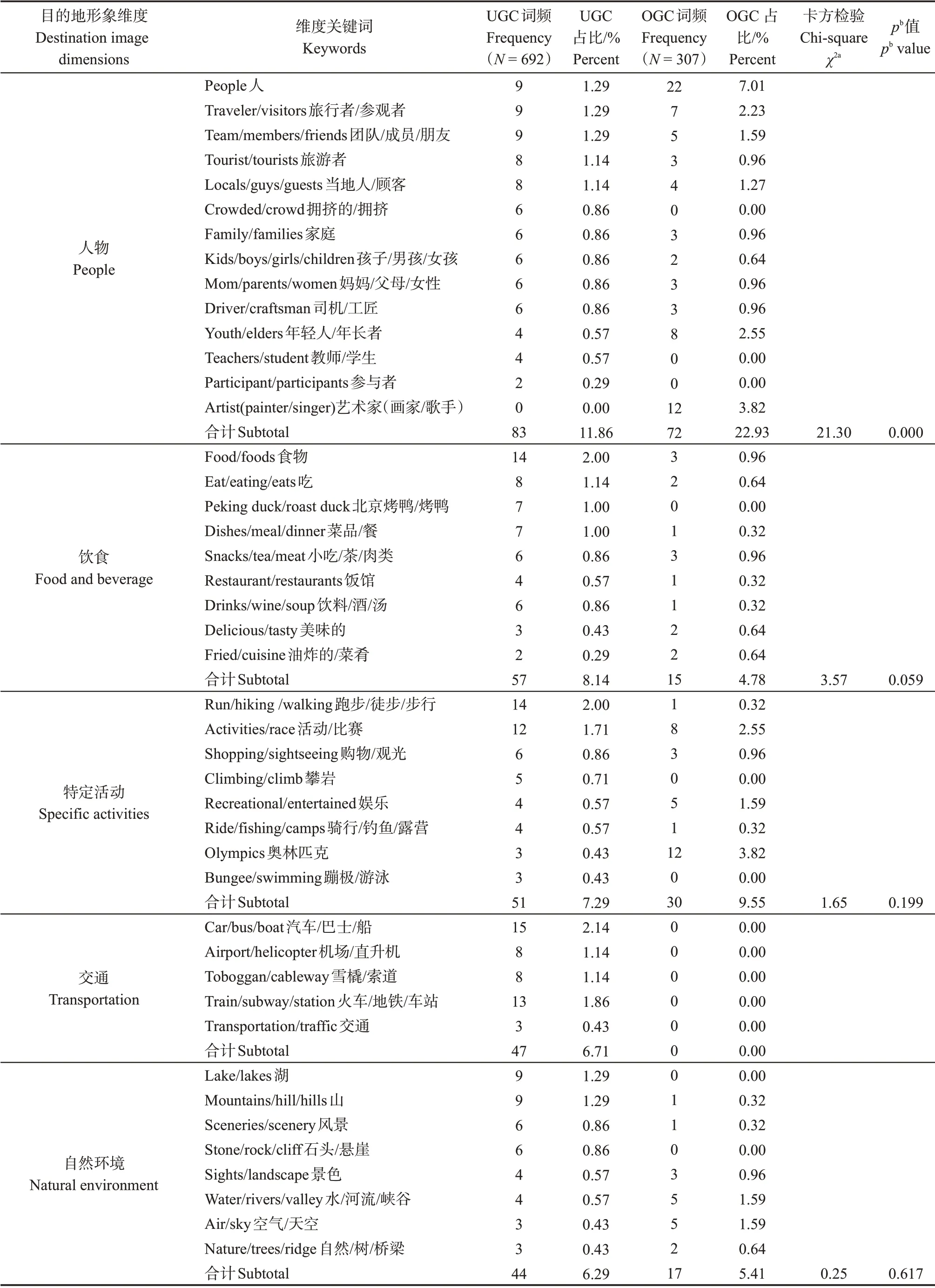
用户在YouTube网站上传视频时通常会用一段文字对视频进行简短描述,这种描述往往包含着丰富的目的地信息。因此,研究选择视频描述信息作为文本素材。首先,通过NLTK分别对UGC和OGC视频的描述文本进行分析,输出的结果为“词+词频”形式。其次,剔除结果中与目的地形象属性无关的词(如the、and、travel 等)。最后,从UGC 和OGC文本中分别确定了692和307个目的地形象相关词。
在UGC 文本中,排名前5 的词分别是Great Wall、Forbidden City、palace、street 和city,与此相对应,OGC 文本中排名前5 的词分别是city、Great Wall、traditional、culture 和imperial。在对文本素材进行分类时,一般每个内容单元仅被归为一类,因此基于上述目的地形象的维度对关键词进行分类,全部分类结果详见表1。
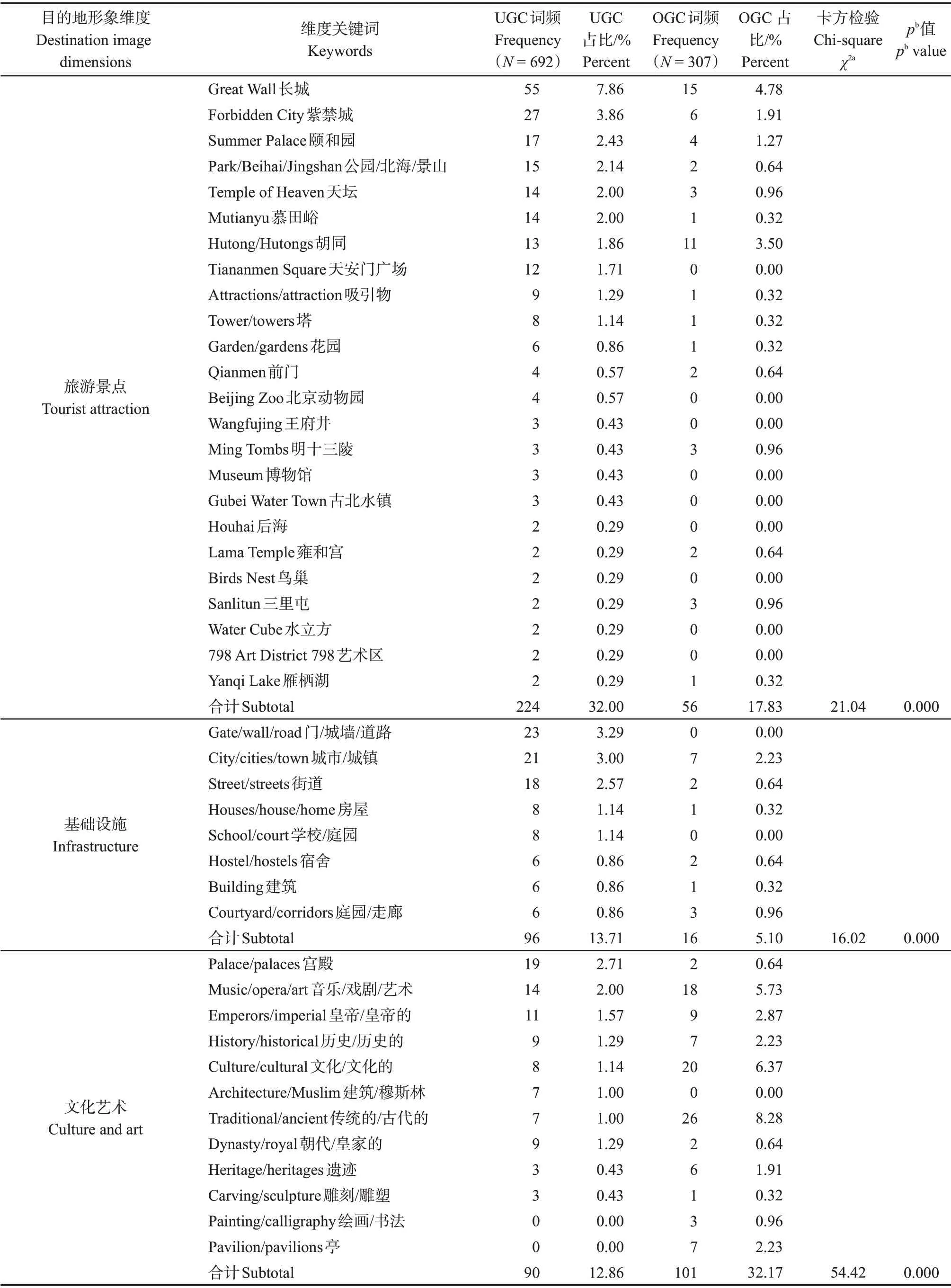
表1 UGC和OGC文本内容比较Tab.1 Content analysis of UGC and OGC textual data
续表
研究对上述目的地形象维度进行卡方检验,以探讨UGC和OGC在不同维度上的显著性。结果显示,UGC 和OGC 在饮食、特定活动和自然环境3 个维度上无统计学差异,且这3 个维度在所有维度中占比较低,这意味着DMO 在对外开展目的地营销时可能并不注重投射北京的饮食特色、自然环境。而对于国际游客而言,一方面,由于DMO投射较少使得游客对北京了解较局限;另一方面,或许是因为受北京的刻板印象使然,即国际游客多认为北京是一个富有历史气息和国际气息的大都市,而忽略了北京其他特色,因而在感知及投射时较少使用相关词汇。
UGC 和OGC 文本在旅游景点(UGC 32.00%,OGC 17.83%)、基础设施(UGC 13.71%,OGC 5.10%)、文化艺术(UGC 12.86%,OGC 32.17%)和人物(UGC 11.86%,OGC 22.93%)4 个维度上具有显著性差异。在UGC文本中,旅游景点所占比重最大,包括长城、故宫、颐和园等在内的传统著名历史文化景点仍是最吸引国际游客的方面,其次是基础设施,这具体体现在民居、小道等极富北京当地生活气息的事务上。整体来看,国际游客更侧重对北京旅游景点和基础设施的感知及投射。在OGC文本中,文化艺术所占比重最大,具体表现在ancient、culture、opera 等代表历史文化的词占比较高,这意味着DMO在开展北京旅游形象海外营销时尤其注重对北京历史文化的投射,其次人物特写也占有较高比重。整体来看,DMO在开展海外目的地营销时更侧重于对北京文化艺术和人物的投射。
4.3 视频表征比较
研究采用视频内容分析法对视频进行深度解析,提取UGC和OGC视频关键帧,并对关键帧进行场景和物体识别,剔除识别结果中与目的地形象无关的词(如非自然图像、商品-家具等),最后从UGC和OGC视频中分别确定了5246和4091组目的地形象相关词。由于图片往往包含着丰富的信息,无法简单地将其归为某一类,即使本文已将其转换为文本,但每组词仍有多个含义,如人物-餐饮娱乐活动既可以归为人物维度,又可以归为饮食维度,因此研究对目的地形象相关词组进行分类时,将每组词归类到多个维度,但最多不超过两类,具体分类如表2。
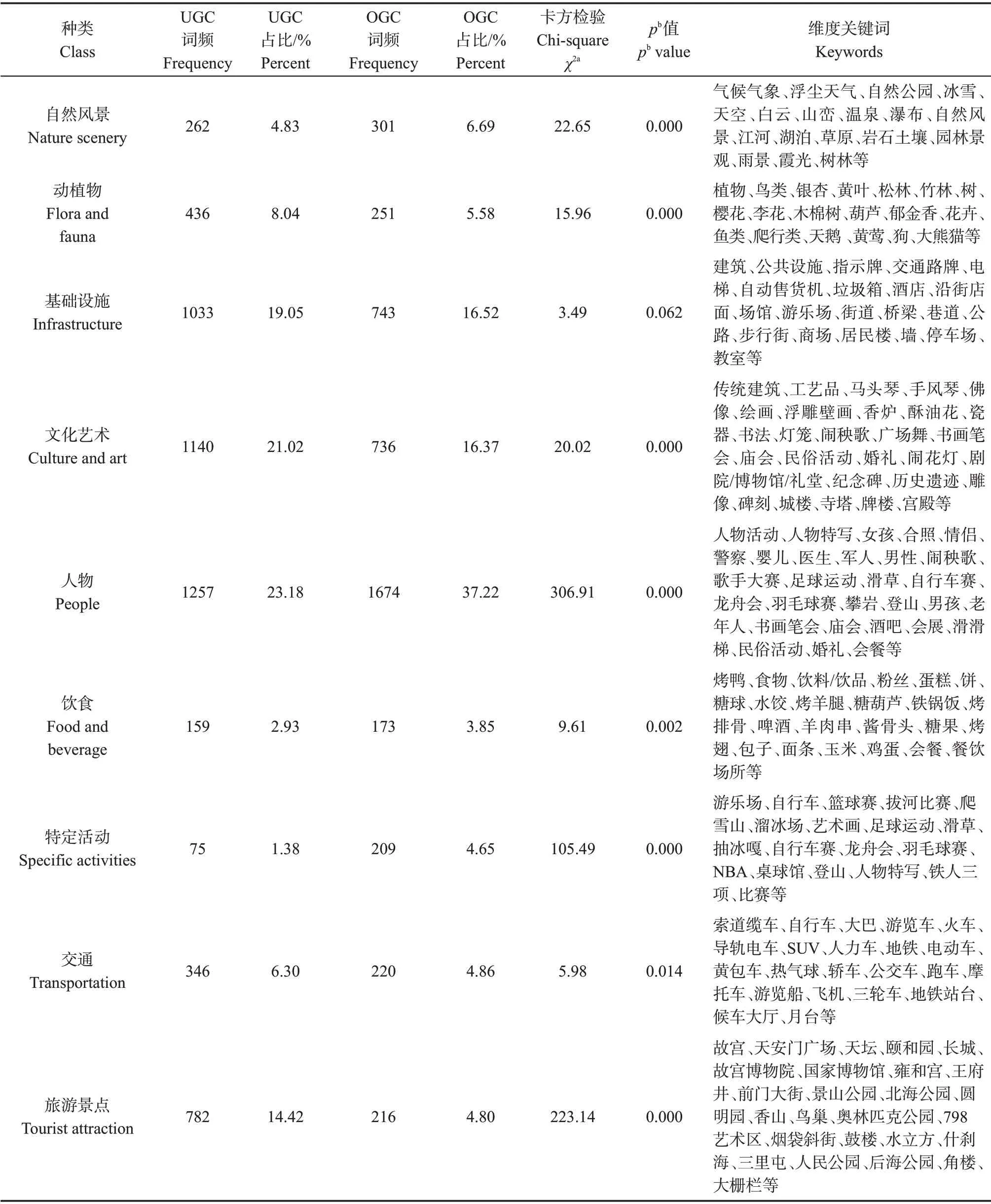
表2 UGC和OGC视频内容比较分析Tab.2 video Content analysis of UGC and OGC
对上述目的地形象维度进行卡方检验,结果显示,UGC 和OGC 视频在基础设施(UGC 19.05%,DMO 16.52%)维度无统计学差异,且人物(UGC 23.18%,OGC 37.22%)、文化艺术(UGC 21.02%,OGC 16.37%)和基础设施(UGC 19.05%,OGC 16.52%)3个维度占比最高,这意味着视频在表征北京旅游形象时尤其注重突出北京的文化艺术(如传统建筑、民俗活动等)、人物活动(如当地人生活、游客活动等)和基础设施(如建筑、街道等)。
UGC和OGC在其余8个维度具有显著性差异,与OGC 相比,UGC 更倾向于感知并投射北京文化艺术(21.02%)、旅游景点(14.42%)、动植物(8.04%)和交通(6.30%)形象。考虑到北京仍然是以诸如故宫、紫禁城、长城、天安门广场等传统著名景点为主,这些景点承载着中国悠久的历史,有着浓厚的文化气息,因此,在一定程度上旅游景点维度也可归为文化艺术维度。可以说文化元素是UGC 视频的核心,这意味着国外游客对北京的古建筑、民俗、书法等传统文化艺术有着浓厚的兴趣,在旅途中渴望寻求一种对目的地文化真实性和亲近性的感觉。在其他维度方面,已有研究表明,UGC图片比OGC更多地描述目的地的交通属性和动植物属性,我们发现这一结论在UGC 视频中同样适用,这意味着不同传播素材在传达某些目的地属性方面具有一致性。
与UGC 视频相比,OGC 倾向于投射更全面的北京形象,包括北京的人物(37.22%)、自然风景(6.69%)、特定活动(4.65%)和饮食(3.85%)。不同于UGC 视频中投射的人物多是游客和“舞台前后”当地人的日常生活,OGC视频投射的人物更多属于公众人物,如赛事活动中的运动员、公众人物等(图4和图5)。导致这种差异的原因可能与OGC和UGC 视频发布主体的性质有不同有关,即UGC 是由游客个人发布,其更渴望体验目的地当地人的真实生活,因而其视频镜头下更多的是当地人的日常生活和娱乐场景,而DMO是由旅游局发布,带有官方性质,其镜头下的人物也更宏观,更具代表性。对于自然维度占比较小的原因或许与北京文化古都的属性有关,因此,在视频中文化元素比自然元素更丰富。此外,许多关于目的地形象的研究表明,某些感知维度(如饮食)在OGC 中呈现较少,这意味着某些维度可能并非DMO投射的重点。特定活动维度在OGC 视频中有更多呈现,主要因为DMO 往往会借助重大赛事、传统节日等来宣传北京形象,如奥运会、春节、端午等。

图4 游客视角下的“人物”Fig.4“People”from the perspective of tourists

图5 DMO视角下的“人物”Fig.5“People”from the perspective of the DMO
4.4 视频和文本表征的目的地形象比较
研究发现,视频和文本素材在投射北京旅游景点、人物属性方面具有一致性,具体表现在UGC 文本及视频素材均侧重于对旅游景点的感知及投射,而OGC 文本及视频则均侧重于对北京人物属性的表征。不同之处在于OGC 文本素材(32.17%)主要表征北京文化艺术属性,但该属性在视频素材(16.37%)中表现较为匮乏,而UGC恰好相反,UGC视频素材(21.02%)主要表征北京文化艺术属性,但该属性在文本素材(12.86%)中较少呈现。研究也发现,某些目的地属性(如基础设施、人物)在视频素材中比在文本素材中有更好的展现,根据媒介丰富性理论,媒介形式越丰富所传达的信息也越丰富,尤其是在传达一些模棱两可的信息上更具优势。不同于文本素材,视频能够在符号系统间构建逻辑关系,传递视频中事件、活动的意义,因而能反映目的地形象的复杂维度,这在一定程度上可以解释为何基础设施维度在视频中有更充分的体现。例如,在文本中仅能用city、street、building等词简单描述北京基础设施,而在视频中则有更丰富的画面体现,如游客乘坐交通、在街道步行、各种交通设施等。
4.5 场景设计差异比较
4.5.1 视频场景分类
本部分采取视频标注技术对视频内容进行深度解析,识别视频每个场景的特征,最终从UGC 和OGC视频中分别得到5320个和6505个视频场景的文本描述及场景时长。基于每个视频场景的文本描述,研究提取了文本描述中的主语及非主语名词,从而能将场景中的人物属性和其他视觉元素同时考虑进来,如通过机器识别某场景视频标注结果中主语“people”及其他视觉元素“building/wall”,可知该场景主要描绘了自然环境下的人物行为。而上述图像表征主要分析了场景的主视觉元素,即每个场景仅提取出一个最主要的视觉属性,如识别某场景为自然环境,但该场景中诸如人物、建筑等视觉元素则被忽略,因此采取视频标注技术分析目的地场景构成,显然能更细致、更全面地表征了目的地形象。
研究对视频的文本描述结果进行分词,并选择最能代表视频场景内容的词作为分类标准(表3),如某场景的文本描述中识别出主语为people、man等代表“人”的词时,意味着该场景由人物和其他视觉元素组成,反之该场景仅由诸如建筑、美食、风景、交通等元素组成。基于此分类标准,将视频场景分为了两大类:人像场景和非人像场景,其中人像场景包括人+建筑、人+风景和人+其他,非人像场景包括建筑、风景和其他。建筑类场景表征了北京的传统古建筑(如宫殿、城墙、长城、雕塑、钟楼等)和现代建筑(如商场、商业街、沿街店面等),人+建筑则表征以建筑为背景的人物活动;风景类场景表征了北京的自然旅游景点和自然环境(如公园、花草、湖、山、植物等),人+风景则表征以自然风景为背景的人物活动;其他类场景主要表征北京的美食、交通、住宿、特定活动、传统文化(如戏剧、功夫、书法、皮影戏等)等,人+其他则意味着场景是以美食、交通、传统文化等为背景的人物活动。
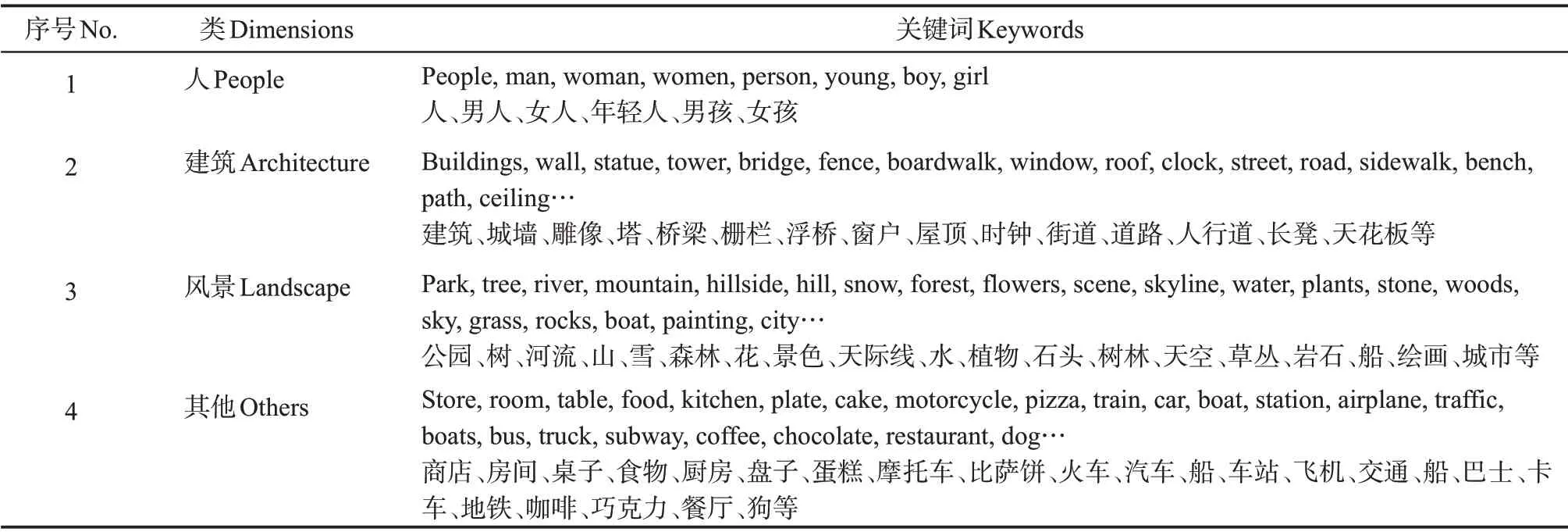
表3 场景分类维度及关键词说明Tab.3 Scene classification dimension and keywords
4.5.2 人像和非人像场景比较分析
研究对视频标注结果(即场景的文本描述)进行机器判别,将每个视频中相同类别场景时长累加,得到该视频不同类别场景的时长,时长最长的类别为该视频的最终类别。采取该方法对所有视频进行判断,最后得到每个视频的场景类别信息。
为了探讨人物元素在表征目的地形象方面的差异,研究以人像场景时长/视频总时长的占比来判断视频类型,若占比大于50%则判定该视频以人像场景为中心,否则以非人像场景为中心。人像场景为中心的视频主要由人物元素组成,这类视频主要强调人物活动,包括旅游者个人和团体的旅游活动(如游览景点、品尝美食、乘坐交通等)、当地居民的生活娱乐场景等,而其他非人物场景仅占视频很小一部分。分析结果显示,UGC 和OGC 视频在投射人物属性方面具有较高的一致性,均以人像场景为主(UGC 69 个,OGC 64 个),非人像场景占比较低(UGC 31个,OGC 30个),这一发现与Mak的发现不同,他们研究结果表明游客和DMO发布图片更注重投射周围环境而非人。然而他们研究的是文本和图片素材,而本研究是探讨视频素材,这也意味着媒体丰富度不同的素材在投射目的地形象方面存在差异。
4.5.3 场景内容比较分析
研究进一步分析了每个视频中建筑、风景和其他这3 类场景的时长,并把场景时长最长的类别作为视频最终类别。如某个视频建筑类场景的时间最长,说明该视频主要表征北京建筑元素,因此将其定义为以建筑场景为中心。基于此标准对所有视频进行判别,结果如表4所示。
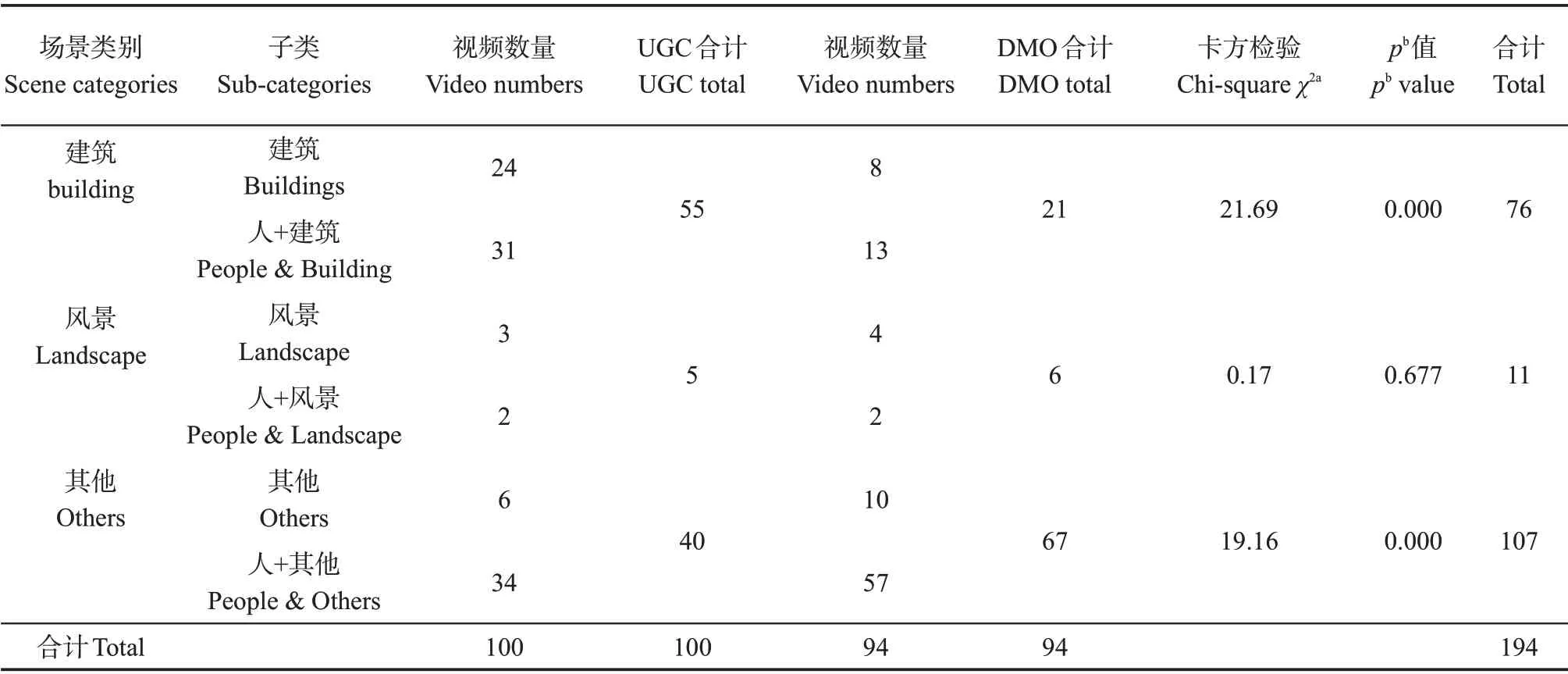
表4 UGC和DMO视频场景设计差异Tab.4 Differences of scene design in UGC and DMO videos
卡方分析结果显示,UGC 和OGC 视频在表征目的地风景属性上无统计学差异,且以风景为中心的视频占比较低,视频文本表征的自然风景属性同样占比较低,这意味着北京的自然属性可能并非游客和DMO 投射的重点。UGC 和OGC 视频在表征目的地“建筑”和“其他”属性方面有显著性差异,其中UGC 视频主要以建筑元素为中心(UGC 55 个,DMO 21个),而建筑在视频中通常表现为古建筑及现代建筑,且前文研究也表明,UGC 视频更倾向于投射北京的古建筑、书法等传统文化艺术,这表明国外游客对北京的建筑、文化更为关注。DMO 发布视频主要以“其他”元素为中心(UGC 40 个,DMO 67个),这在视频中主要表现为除自然风景和建筑之外的其他元素,其中反映美食、交通和体育运动的元素较多,这也进一步印证了DMO更倾向于展现一个更全面的北京旅游形象。
5 结论与展望
5.1 结论与讨论
本研究基于计算机领域的深度学习和视频标注技术,对目的地视频数据进行自动化分析,探讨了UGC和OGC视频在投射北京旅游形象方面的异同,并进一步比较了视频和文本素材在目的地形象投射方面的差异。研究结论主要体现在以下几方面:
第一,从视频表征的北京旅游形象内容结构来看,人物、文化艺术和基础设施是视频投射的北京主要旅游形象,已有研究表明目的地诸如文化遗产、当地基础设施为代表的物质环境具有地理吸引力,是目的地核心吸引要素,因而,北京所展现的历史文化气息及现代化设施成为游客和DMO重点投射方面。另外,从视频及文本素材表征目的地形象对比来看,目的地形象中基础设施、人物维度在视频中有较丰富的呈现,但在文本素材中呈现较弱,这意味着媒体丰富度更高的视频比文本能更有效地表征目的地某些重要属性,这与已有研究发现的图片比文本能更好揭示目的地基础设施和人物维度的结论基本一致。
第二,从UGC 和OGC 视频表征的目的地形象差异来看,UGC 视频主要表征北京的文化艺术,人物、建筑场景为其主要构成元素,而OGC 视频主要表征北京的人物、特定活动和饮食,其倾向展现一个更宏观和全面的目的地形象,人物、其他场景(包括饮食、交通等元素)为其主要构成元素。根据寻求创新理论,游客天生对非惯常环境中的文化、习俗等事物感兴趣,而北京作为具有悠久历史的文化古都,其遗留的历史建筑和文化环境(庙宇、京剧、功夫等)对国际游客有着强烈吸引力,因而驱使游客用视频投射北京文化的真实性,这与已有基于图片素材的研究发现基本一致。同时,已有研究也表明,在UGC 图片中,人物通常与建筑特写联系在一起,本文UGC 视频主要以人物+建筑场景为主是对已有结论的印证。此外,本研究与已有基于图片素材的研究均表明,DMO往往会投射目的地多方面属性,以展现其完整、全面的目的地形象。不同之处在于,本研究发现,DMO 会尤其注重投射目的地人物属性,因而OGC 视频通常以人物+其他场景为主,而以往基于图片素材的研究中OGC照片中的形象要素更集中,且主要聚焦投射周围环境而非人。
第三,本研究是旅游视频分析领域具有大数据特征的研究,尝试利用机器标注、关键帧识别等自动化手段对数以百计的目的地视频进行帧级的内容分析和场景分析,将旅游领域视频分析的数量从人工编码的几个、十几个提升至机器分析的几百量级,也为未来分析成千上万旅游视频,从更大数据尺度分析社交视频数据,形成依托大数据的视频分析范式奠定了基础,是旅游营销可视化素材挖掘领域的一次方法和研究范式的跃升。
5.2 营销启示
研究结果对DMO开展目的地营销具有以下重要实践意义。首先,研究表明视频主要表征北京的人物属性,且UGC 视频镜头下的人物多聚焦北京普通民众及旅游者,聚焦感知并投射当地居民的日常生活场景。因此,DMO 在开展目的地营销时应重视人物元素在视频中的展现,尤其可以适当增加反映本土居民生活场景的视觉素材。其次,研究也表明游客更喜爱北京的历史文化,尤其是北京的建筑环境如故宫、颐和园、长城等古建筑和历史遗迹,因此,DMO在开展海外目的地营销时应注重对北京文化元素的宣传,合理增加文化元素在视频中的占比。
6 局限与展望
本文在两个方面存在局限性:一是研究采用机器学习方法分析大样本视频数据集,是旅游领域对视频表征目的地形象研究方法的进一步尝试,但研究仅从视频表征内容分析入手开展研究,对UGC和OGC 之间差异的原因及二者的互动关系探讨尚且不足,后续研究将重点探索二者之间的互动机制。二是由于视频视觉元素较为复杂,研究初步将视频场景分为3类,这可能无法完全涵盖视频所有特征,未来将结合叙事理论对视频叙事展开探讨。
未来的研究可在以下几个方面进行深入和拓展:第一,由于UGC视频相较于OGC视频更受用户喜爱,因此目前关于二者的比较研究均强调DMO应借鉴UGC内容,但DMO作为官方组织,是否在借鉴时保留自己的权威性和引导性,能否完全借鉴UGC所有成功经验,二者之间的互动机制将是未来研究的主要方向。第二,视频是一种动态视觉材料,有着严谨的逻辑线,记载了旅游者完整的故事,因此结合叙事理论探讨视频的叙事风格及对目的地品牌的影响也将具有重大意义。第三,本研究揭示了UGC 和OGC 在表征目的地形象上的差异,但何种目的地属性更能刺激游客,从而进一步影响游客决策行为还未可知,未来可以进一步探讨视频对游客行为的影响。
猜你喜欢
小主人报(2022年7期)2022-08-16
悦游 Condé Nast Traveler(2022年2期)2022-02-18
小天使·三年级语数英综合(2021年4期)2021-06-15
民生周刊(2020年15期)2020-07-29
北广人物(2020年12期)2020-04-01
北京广播电视报(2020年1期)2020-03-11
中华诗词(2019年7期)2019-11-25
小天使·一年级语数英综合(2018年10期)2018-10-16
小猕猴学习画刊·下半月(2018年9期)2018-05-14
灯与照明(2016年4期)2016-06-05
