
招聘数据可视化分析系统的设计与实现
2022-08-31 19:18黄锦帆梁少华张佳
电脑知识与技术 2022年18期
黄锦帆 梁少华 张佳
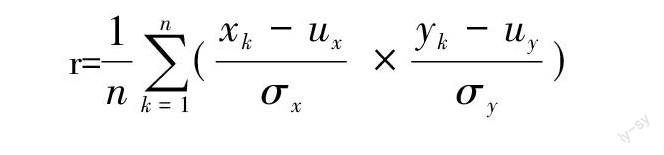
摘要:通过对当今的招聘现状进行研究,该文设计并开发出一款可视化分析系统,主要分为数据采集、存储与处理、数据分析、可视化等功能模块。通过网络爬虫爬取到的招聘数据,经预处理和分析之后,将学历、热门职位、福利待遇及技能要求等进行可视化展示,采用基于用户的协同过滤算法对职位进行推荐并实现动态更新。在一定程度上可帮助求职者了解目前的社会人才招聘需求,快速找准自身定位。
关键词:网络爬虫;招聘数据;协同过滤;可视化分析
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)18-0039-03
开放科学(资源服务)标识码(OSID):
1 引言
随着国内互联网行业的飞速发展,以及一些非传统因素的影响,网络求职招聘愈发受到人们的欢迎。但其中也出现了一些问题,最突出的就是信息繁多杂乱,人岗的信息匹配度不是很理想。求职者希望可以直观地看到某行业的现状、发展前景以及招聘要求[1]。因此,我们可以利用相应的数据可视化技术,采用图表及图示等方式来展示分析后的结果,帮助他们提高求职效率。
2 相关技术
2.1 Scrapy爬虫
它是基于Python开发的一个快速抓取Web站点并提取结构化数据的一个爬虫框架,其主要由调度器、下载器、爬虫、实体管道、Scrapy引擎构成。它的优势就是使用了Twisted异步网络框架处理网络通信,大大加快了下载速率。工作流程如下:首先爬虫将发送请求的URL经引擎交给调度器,然后其处理后通过下载中间件传给下载器,下载器对网页发起请求并接受下载响应经过引擎传给爬虫,爬虫接收响应并解析提取数据,最后将数据通过实体管道保存到本地或对应数据库[2],根据所需重复上述过程直到停止。
2.2 职位推荐算法
对求职者进行相应的职位推荐,需要精准地了解到每个人的个性职位需求, 通过他们对某类职位的搜索次数以及对详细信息的查看收藏次数,系统会进行相关热度的计算并排序。这里采用了基于用户的协同过滤算法,对历史行为数据进行度量打分,根据不同的求职者对某职位的偏好程度,使用欧几里得距离评价公式来计算他们之间的系数关系。通过求职者之间的相似度数值,选择关系最接近的用户,利用他们的喜好为当前用户进行相应的职位推荐[3]。 职位推荐信息将会随着用户的点击不断地动态实时更新,更加智能化地帮助求职者找到合适的岗位。
2.3 可视化技术
可视化技术就是将大量杂乱的数据转化为人们直观易懂的可视化形式,突出重点、条理分明地将分析结果展示出来,其中包含了科学计算可视化、数据可视化及信息可视化。Python中封装了大量的绘制图表库,如:matplotlib、bokeh等。在对网络招聘数据的分析中,如何去设计页面,使其美观又不突兀,展示出所需的结果,是需要考虑的问题。本文通过对目前主流的可视化库进行比较,最后采用的是pyecharts可视化库,它将基于百度可视化设计开源的Echarts库和Python语言相结合,方便在Python中调用Echarts接口[4],直接生成可视化图表,还可以生成可视化的HTML网页,使用起来很方便。
3 系统设计
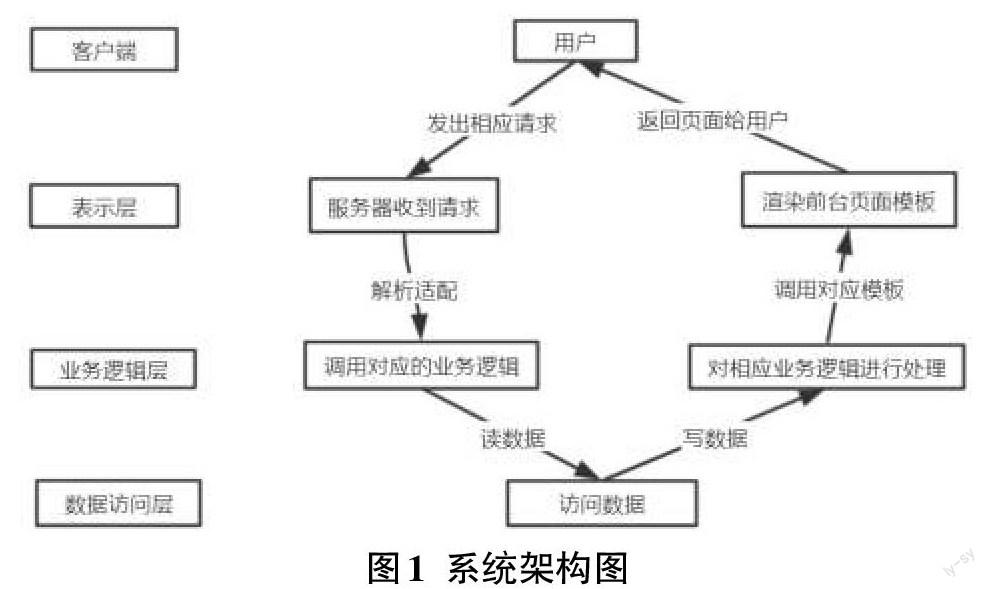
本系统基于B/S架构开发,主要分为数据采集、存储和处理、数据分析、可视化四大功能模块,将大量的业务逻辑直接在服务器端实现,降低了开发和维护成本,也方便了用户使用。使用三层结构对系统进行切片分层,模块化的迭代式开发,保证了各功能模块的独立性,便于开发和维护工作的展开。从上到下依次分为表示层、业务逻辑层、数据访问层。架构图如图1所示。
4 系统实现
4.1 数据采集模块
网络爬虫主要是通过伪装浏览器头等绕开反爬机制,编写遵循一定规则的脚本或者程序对网站的信息进行爬取,设计适宜的解析结构对网页结构进行解析得到数据。首先访问Boss直聘,点击不同的界面观察,右键检查进入开发者工具,点击Network,按F5刷新,观察URL结构。然后设计爬虫的基本结构,构造动态的URL来爬取想要的信息。为了绕开反扒机制,通过在浏览器的Headers中看到的User-Agent和Accept-Language以及Cookie,以此构造表头,让浏览器允许爬虫脚本访问。将需要爬取的key关键字存储在字典中,通过item方法进行关键字的获取,以便后面的爬取[5],使用的是request库中的request.get()方法来获取页面,返回response对象。在Resopnse中可以看到爬取的字段的网页构造,以便于后面的解析数据。
4.2 数据存储和处理模块
由于爬虫获取到的数据并不都是符合规范的,存在着重复、不一致、错误、空值等问题。为了解决此不足,本文使用了Pandas库来进行数据处理的工作。首先将数据转换为DataFrame格式,通过使用其中的isnull()方法来判断数据是否为空值,DataFrame.fillna()方法对数据进行填充;DataFrame.drop_duplicates()可以快速按行检测并删除重复的记录[6]。
Python中包含了很多的常见存储方式,如:MySQL、CSV文件、JSON文件等,这里使用的是MongoDB非关系型数据库,它基于Key-Value保存数据,能很好地适应爬虫字段变化,非常适合存储爬取到的招聘信息中的职位名称、工作地点、薪资福利待遇、学历和技能要求等结构化文本字段。用它存储数据时,需要事先安裝好MongoDB数据库并启动相应服务,在Python中导入pymongo库,然后使用client=pymongo.MongoClient(host=‘localhost,port=27017)创建数据库连接对象,导入处理之后的数据集。
4.3 数据分析模块
数据分析是整个流程中最重要的阶段,它主要的工作是将上阶段经过清洗处理之后的数据按照一定的规则方法进行分析,为之后的可视化展示提供数据支撑[7]。主要涉及:中文分词、工作经验及学历与薪资关系、热门职位、绘制职位技能关键词和福利待遇词云图、岗位地点分布等。
1)中文分词:招聘信息多为中文文本,这里采用了jieba作为分词工具。它基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的DAG,采用动态规划去查找最大的概率路径, 找出基于词频的最大切分组合。具有高性能、准确率高、速度快等特点。
2)工作经验、学历与薪资的相关性:采用最小二乘法計算两组数据的线性相关程度,公式如下:
r=[1nk=1n(xk- uxσx × yk- uyσy)]
其中,[ux]、[σx]分别表示数据列x的平均值和标准差,[uy]、[σy]分别表示数据列y的平均值和标准差。相关系数r的值越接近于[±]1,说明相关程度越强;r越接近于0,说明数据相关性越差。
3)热门职位:首先使用K-means聚类算法,将数据中的职位名称字段进行分类,统计出数量最多的职位类别。在此类中对职位名称字段使用jieba进行中文分词处理,统计它们出现的词频大小,得到出现次数最多的几个职位关键词,则它们就是此类中的热门职位。
4)绘制技能及福利词云图:每个行业类型的职位技能关键字和福利待遇词云的实现主要是通过遍历所有的职位信息,再使用jieba分析统计各种关键字出现的次数,统计词频进行格式的转换。最后使用Python的List.sort()方法设定参数进行排序,就可以得到其频率顺序,从而通过Python中的WordCloud库绘制这些词的词云,在可视化界面进行展示。
5)岗位地点分布:通过对工作城市关键字进行分词统计,计算每个的总数大小。绘制分布图来展示全国的工作岗位城市分布图,可以通过图上的颜色深浅大小来判断岗位的数量。
4.4 数据可视化模块
系统最后就是要实现对网络招聘数据的可视化分析,将分析之后的结果以图表或图画的形式展现在前台界面上。主要使用了目前的主流开发Python Web框架Django以及pyecharts开源可视化库[8]。
Django框架采用的是MVT模式,系统中的settings.py存放的是项目的各类配置文件,urls.py存放的是路由,wsgi.py是Web服务器与Django交互的入口。工作原理如下:首先是用户通过浏览器来对页面发起请求,之后请求会到达Request MiddlewaRes,其会对request做预处理或者是直接response回应,URLConf会将请求的url用来和urls.py中的进行匹配,从而找到相应的views。找到之后,就可以调用视图views中的对应函数对业务逻辑进行处理。视图views作为沟通桥梁,可以通过调用Model层来对数据库中的数据进行访问并返回。views接收到请求之后,构造一个HttpResponse响应对象,可以使用context来对上下文进行处理,context被传递给template用来生成页面。调用模板template里的render()方法并使用context传进的参数渲染HTML界面,将响应对象返回到浏览器,呈现给用户。
5 可视化分析结果
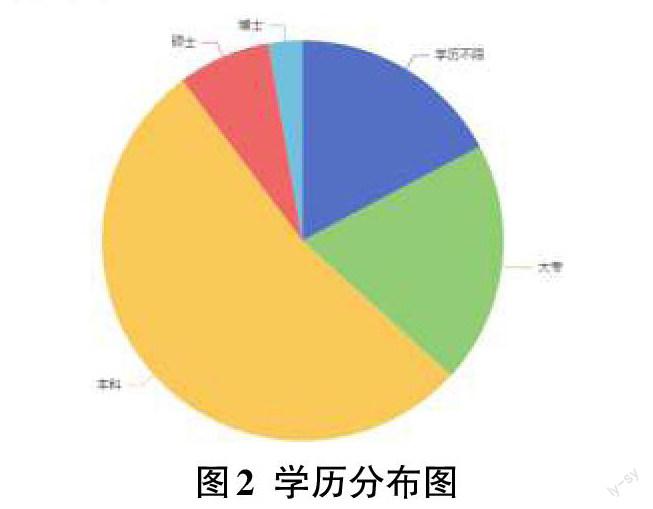
1)学历分布状况
在这个科技高速发展的时代,学历是求职的敲门砖。对于没有实践经验的应届毕业生来说,更是衡量其学习能力、自身素质的重要因素。从分析结果可知,本科占据了大多数,与目前的教育状况有关。另外,我们可以了解到现在的企业对求职者的学历层次要求,更好地找准自身定位[9]。
2)热门职位展示
随着科学技术的飞速发展,以人工智能领域为例,自动驾驶、元宇宙风头正盛,但也急需新的人工智能算法去解决出现的问题。因此,使得算法工程师、图像处理、数据挖掘等领域也日趋热门。随着国家政策的不断投入,工业产业链升级,相关的人才缺口巨大,创造了很多的就业机会。
3)数据挖掘的福利待遇词云图
以数据挖掘岗位为例,在众多的福利待遇中,五险一金是其中最基本最重要的保障,随之是绩效和年终奖等,这是激励求职者的重要手段。
4)职位技能要求词云图
以Python开发工程师为例,可以看到的是对于数据库以及Web框架、工作经验、竞赛还是比较看重的。对于之后有志从事于此的学生,要注意这方面的积累,打好坚实的专业基础。
6 结束语
针对众多的线上招聘信息,本文设计开发出一款基于网络爬虫的招聘数据可视化分析系统。采用的开发技术和方式,占用内存少,完整地实现了功能。采用基于用户的协同过滤算法对求职者进行职位推荐,以各类图表以及词云的形式直观地给用户展示了各类分析结果,为他们展示了一个清晰的招聘求职现状。它在一定程度上帮助人们找准定位,及时调整求职方式和策略,具有积极的指导意义。
参考文献:
[1] 韩月乔.中小企业网络招聘问题研究[J].价值工程,2020,39(16):223-224.
[2] 黎妍,肖卓宇.引入Scrapy框架的Python网络爬虫应用研究[J].福建电脑,2021,37(10):58-60.
[3] 王硕.基于协同过滤的农业新闻推荐系统的研究[D].长春:吉林农业大学,2021.
[4] 侯瑾菲,梁艺多.基于Python的政府开放数据可视化应用研究[J].科学技术创新,2021(34):160-162.
[5] 黎曦.基于网络爬虫的论坛数据分析系统的设计与实现[D].武汉:华中科技大学,2019.
[6] 殷丽凤,张浩然.基于Python网上招聘信息的爬取和分析[J].电子设计工程,2019,27(20):22-26.
[7] 孙亚红.基于Python的招聘信息爬虫系统设计[J].软件,2020,41(10):213-214,235.
[8] 白昌盛.基于 Django的 Python Web开发[J].信息与电脑,2019,31(24):37-40.
[9] 扶明亮,李刚.基于招聘网站大数据分析的求职者需求与企业需求匹配研究[J].统计与管理,2021,36(8):91-97.
【通联编辑:梁书】
猜你喜欢
职教论坛(2016年26期)2017-01-06
中国新通信(2016年21期)2017-01-06
科技传播(2016年19期)2016-12-27
