
基于随机森林的集成学习入侵检测方法
2022-08-31 00:54盛展陈琳
电脑知识与技术 2022年19期
盛展 陈琳

摘要:为解决网络入侵检测效果不佳的问题,提出一种基于随机森林的集成学习入侵检测方法。通过K-means和SMOTE处理数据集获得相关度高的平衡数据子集,随机森林选择出最优的特征子集,基于树的集成学习方法分类结果。本文采用CICIDS2017数据集进行本文方法可行性的研究,结果表明本文提出的方法相比传统的单一机器学习方法具备更高的检测精度和更低的时间开销。
关键词:随机森林;集成学习;入侵检测;机器学习
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2022)19-0087-02
1引言
随着机器学习在入侵检测的应用,国内外的学者对此进行了大量的研究。如使用KNN[1]、决策树[2]、随机森林[3]算法等传统机器学习算法解决网络入侵中的异常行为,判断其中的攻击特点进行预防和识别。但是传统的机器学习算法都存在一些缺点:检测精度低、运行速度慢等问题。文献[4]提出结合过滤式特征选择的入侵检测方法,该方法速度快、计算复杂度低,可以扩展到更高维的数据集。文献[5]融合特征识别异常行为,通过自回归模型对网络流量分类,虽然速度快但是模型精度不够、容易过拟合。混合不同的特征选择方案,能有效地解决各个特征选择的缺点。文献[6]结合混合过滤式和嵌入式的特征选择结合集成学习时间开销更少取得的效果更好,解决传统特征选择和机器学习时间精确的弊端。文献[7]结合混合特征选择和集成选择克服了混合特征选择和单一机器学习算法检测精度问题和鲁棒性低的问题,但由于数据集的不平衡对结果产生一定影响。
综上所述,针对网络入侵检测高维数据集检测效果不佳的问题,通过提出的随机森林特征选择和集成学习方案,相比于传统机器学习方案,提高了分类检测的效率,达到了更好的检测精度。
2网络入侵检测模型
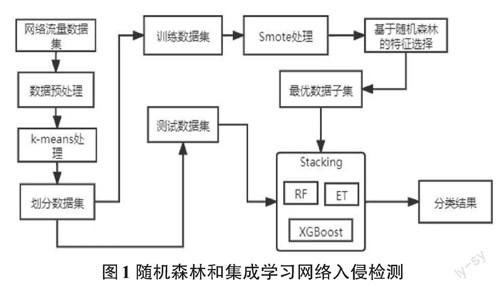
本文网络入侵检测模型具体如图1所示,分为三个阶段:数据预处理、特征选择和集成学习。
2.1数据预处理阶段
利用标签编码器对网络流量数据集进行编码,将分类特征转换为数字特征,以支持ML算法的输入。然后利用Z-score算法对网络数据集进行归一化后使用K-means聚类抽样算法对大样本数据集进行抽样处理,对数据样本进行划分为训练集和测试集,测试样本比例为30%。
2.2 混合特征选择算法
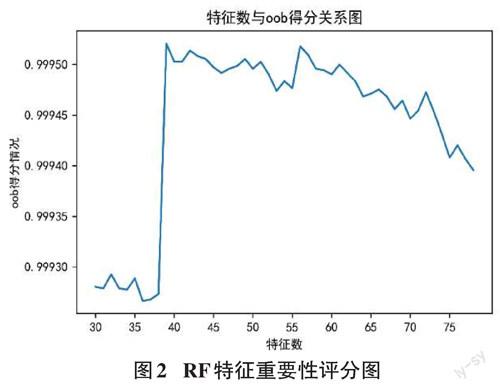
处理好的训练集使用SMOTE过采样平衡数据样本,根据Gini系数和OOB袋外样本评价指标以去除无关特征。将结果通过随机森林算法的Gini系数得到初始特征权重比例系数。再通过OOB袋外误错率的评价指标,判断选择特征的可靠性,得到特征子集。对重要的特征或者被忽略的特征OOB袋外样本误错率,能直观地反映出该特征的重要性程度具体特征权重如图2所示,选择最佳的特征为39。
Smote算法基本思想是改变数据集的平衡性来保持数据分类方法的性能,即通过增加少数类的数据与多数类的数据样本进行平衡。
[Xnew=X+rand (0,1)*Mi-X,i=1,2,…,N] [(1)]
Gini系数初步评估样本中各个特征之间的权重关系,并排序特征权重得到初始排序特征集。OOB袋外样本误错率根据每棵决策树都有一部分的特征没有纳入训练过程中,将这部分没纳入训练过程中产生的样本误差,叫作袋外样本误错率,用来最终评估特征以获得最优特征子集。
2.3 集成学习
本文采用基于树结构集成学习,分为两层结构。第一层基学习器使用集成学习的ET树、RF、XGBoost作為本文的基学习器。随机森林(RF)是选择决策树投票率最高的类作为分类结果。极限树(ET)通过处理数据集的不同子集生成的随机决策树集合。XGBoost是通过使用梯度下降法,组合多个决策树来提高速度和性能。第二层选择基学习器中精确精度最高的树模型作为元学习器。通过树模型训练的数据,并通过十折交叉验证贝叶斯优化算法[8]对各个树模型进行优化操作。在训练集上实现10倍交叉验证,以评估模型在新数据集上的性能。选择上述机器学习算法的原因在于大多数树结构ML模型使用集成学习,因此它们通常比其他单一模型(如KNN)表现出更好的性能。
3实验分析
3.1实验环境
硬件使用环境为1.8GhzCPU,软件使用环境为Python版本为3.7,sklearn版本为0.22。
3.2实验评估
本文采用多分类常用的微平均和宏平均估各个机器学习算法的性能要求。当数据不平衡时,微平均和宏平均的差异会较大。微平均根据每个类别的指标计算平均值,宏平均根据是先对每一个类别统计各个指标,然后再对所有类别计算算术平均值。
[Micro_Precision =i=1n TPii=1n TPi+FPiMicro_Recall=i=1n TPii=1n TPi+FNiMicroF1=2×MicroPrecsion×MicroRecall micro P+ micro -R] [(2)]
3.3实验结果分析
本次实验选择比较热门的KNN,SVM,DT,RF,ET,XGBoost、GBDT机器学习与本文提出的算法进行对比,所提出的算法均用贝叶斯优化算法进行优化。
[ Precision i=TPiTPi+FPi, Macro_P= precision in Recall i=TPiTPi+FPi, Macro_R= Recall inMarcoF1=2× Macro_P×Macro_RMacro_P+Macro_R] [ (3)]
本文提出的算法对比传统机器学习算法precision提高了1%~30%,召回率提高了2.2%~5.1%,F1提高了2.1%~27.6%。时间开销上有明显降低。从实验结果可以看出,本文提出的方法无论在宏平均和微平均评价指标上都能取得比较满意的效果,证明本方案的有效性和可行性。
4结论
本文针对入侵检测的检测效果不佳提出的随机森林集成学习入侵检测模型,解决了传统入侵检测精确度低、召回率低、时间开销大的问题。但该模型还有不足:在特征工程阶段初步筛选的评价指标单一,可能对初步筛选特征产生一定影响。
参考文献:
[1] 盧官宇,田秀霞,张悦.结合KNN和优化特征工程的AMI通信入侵检测研究[J].华电技术,2021,43(2):1-8.
[2] 唐亮,李飞.基于决策树的车联网安全态势预测模型研究[J].计算机科学,2021,48(S1):514-517.
[3] 周杰英,贺鹏飞,邱荣发,等.融合随机森林和梯度提升树的入侵检测研究[J].软件学报,2021,32(10):3254-3265.
[4] 胡希文,彭艳兵.基于ONE-ESVM的入侵检测系统[J].电子设计工程,2021,29(20):86-91.
[5] 孙林,赵婧,徐久成,等.基于邻域粗糙集和帝王蝶优化的特征选择算法[J].计算机应用,2022,42(5):1355-1366.
[6] 张玲,张建伟,桑永宣,等.基于随机森林与人工免疫的入侵检测算法[J].计算机工程,2020,46(8):146-152.
[7] 艾成豪,高建华,黄子杰.混合特征选择和集成学习驱动的代码异味检测[J/OL].计算机工程:1-11[2021-11-03].https://doi.org/10.19678/j.issn.1000-3428.0062165.
[8] 仉文岗,唐理斌,陈福勇,等.基于4种超参数优化算法及随机森林模型预测TBM掘进速度[J].应用基础与工程科学学报,2021,29(5):1186-1200.
收稿日期:2022-02-25
作者简介:盛展(1997—),湖北孝感人,硕士,研究方向:机器学习与人工智能;通讯作者:陈琳(1972—),男,湖北荆州人,博士研究生,教授,研究方向:网络与通信、信息安全、智慧城市、网络应用开发等。
猜你喜欢
南水北调与水利科技(2016年6期)2017-01-06
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
