
融合多任务深度学习与主动学习的民航常旅客缺失数据填补
2022-09-06 13:16王怀超
计算机应用与软件 2022年8期
李 国 袁 闻 王怀超
(中国民航大学计算机科学与技术学院 天津 300300)(中国民航大学中国民航信息技术科研基地 天津 300300)
0 引 言
随着大数据与人工智能的发展,传统的CRM系统融合了数据存储、数据可视化分析、数据挖掘、商务智能等多种信息技术,各航空公司形成各种联盟(例如天合联盟、星空联盟),属于该联盟的会员旅客搭乘他们联盟下任何一家航空公司的航班均能获得相应会员积分登记。他们所维护的CRM系统也存储着海量的运营业务数据,尤其是针对本航空公司的会员旅客数据,其主要从PNR数据、票务数据、航班数据、旅客信息数据等多种数据源经过ETL加工形成,是航空公司重点进行商务分析、数据挖掘的数据。通过对此类数据分析,有助于航空公司的会员旅客进行用户画像,进而施行精准营销,提供个性化服务,提高旅客对航空公司的忠诚度[1-3]。然而在现实生产环境中,因各业务数据系统互相通信时,由于网络带宽、延时等问题往往会造成数据记录部分属性缺失,而对每条缺失的记录向上游数据系统搜寻真实值往往要花费较大的成本,因此挑选出信息量大、缺失较为严重的记录进行真实值填补,同时对含有不影响业务分析的缺失项进行模型填补是十分必要的[4]。
传统的缺失数据填补方法如MIC填补法、KNN填补法、均值填补法等仅从填补值与真实值差异方面考虑缺失数据填补问题,未考虑缺失数据的填补对后续进行相关旅客分类任务的影响。本文考虑缺失数据填补与后续相关分类挖掘任务具有相关性,将两者视为整体同时进行处理,提出基于深度主动学习的多任务网络模型。同时,考虑生产大数据环境结合Spark计算引擎的优势,提出一种Spark环境下对缺失数据填补的运行机制,使得深度主动多任务网络模型能在大数据环境下高效运行。
1 相关工作
1.1 多任务主动学习
近些年来,学术界提出许多机器学习算法被用于同时学习多个任务,此类方法被称为多任务学习。多任务学习是一类同时学习多个相关任务的机器学习算法,基本思想是在学习期间利用其他相关任务中包含的信息,更好或更快地学习任务。其优点是能同时并行学习多个任务,并且通过每个任务互相学习其他任务所附加的额外信息,能快速提升自身任务的学习性能[5-6]。主动学习有时也称为查询学习,是机器学习与人工智能领域的子分支。其关键点在于如何选取较少、高价值的数据进行标记用于训练模型,使得模型获得更高的精度。一般的监督学习系统要获得更好的性能需要收集海量带有标签的数据用于训练[7]。
多任务主动学习将多任务学习与主动学习两者优势相结合。每个任务在训练集中具有少量标记数据和大量未标记数据。每个任务都选择信息丰富的未标记数据以查询的方式来主动获取其标签。
1.2 降噪自编码器
自编码器是一种无监督学习神经网络,由编码器和解码器两部分构成。编码器通过隐藏层将输入样本数据进行降维或升维,从而起到数据编码的作用。解码器将编码器输出的样本再次通过隐藏层恢复到原来输入编码器时的维度,从而起到数据解码的作用。降噪自动编码器[7]是在自动编码器的基础上为防止模型过拟合问题从而对数据样本加入噪声。其基本结构如图1所示。

图1 降噪自编码器
编码过程为:
(1)
解码过程为:

(2)
损失函数为:
(3)
网络的参数为:
W={a,a′,b,b′}
式中:a表示编码器网络权重;b表示编码器网络偏置;a′表示解码器网络权重;b′表示解码器网络偏置。
1.3 SMOTE采样算法
SMOTE(Synthetic Minority Oversampling Technique)算法由Chawla等[8]于2002年提出,主要用于解决数据类别不平衡问题。不同于随机过采样法简单对少数类进行复制采样,SMOTE算法采用K近邻的思想,通过式(4)在少数类样本邻域间生成新的少数类样本,从而真正缓解了数据集类别不平衡,避免模型重复学习相同少数类样本造成过拟合的问题[9]。
(4)

1.4 Spark大数据计算引擎及应用
Spark于2009在UC Berkeley AMP lab诞生,是一种基于内存的大数据并行计算框架。它与Hadoop的MapReduce大数据计算方式不同,Spark充分利用内存优势将数据集抽象为分布式弹性数据集RDD(Resident Distributed Data-set),整个数据处理过程将中间结果尽量缓存至内存中,不必像Hadoop需要将中间计算结果写回至HDFS文件系统中,从而节省大量数据处理时间[9-10]。
本文主要利用Spark对缺失数据填补实现并行化处理。通过Spark将数据从HDFS文件系统并行读取后,再利用广播算子(Broadcast)将在本地环境用小量数据集已训练的初始网络模型广播到各工作节点上。之后各工作节点利用读取后的数据对模型进行参数迭代更新,并在每轮训练结束时保留各工作节点模型在验证集的性能。当模型的平均性能达到阈值时,训练模型即结束。
2 方法设计
2.1 基于降噪自编码多任务主动学习网络:MLT-AL-DAE
结合多任务学习与降噪自编码器的优势,设计出一种基于降噪自编码器的多任务学习网络模型,网络同时训练缺失数据填补和类别预测两大任务。通过共享参数层两个任务之间进行相互学习从而达到整体提高的效果,模型对缺失数据精确填补有利于提高类别预测的性能,而类别预测任务的有效监督使得缺失数据的填补以解决民航常旅客价值分类为向导。对于缺失数据填补任务采用均方差损失函数,对于类别预测任务采用交叉熵损失函数,并通过一定的任务权重系数联合训练整体网络。网络架构如图2所示。

图2 多任务降噪自编码器网络架构
图2中提出的架构由三部分组成:编码器、解码器、分类器。编码器与解码器构成堆叠降噪自编码器。参考文献[11]的架构,输出1层采用Sigmoid激活函数,输出经过解码后的样本特征,输出2层采用Softmax激活函数输出样本对应各类别的概率值,中间隐藏层采用tanh激活函数。区别于传统自动编码器架构,受Kernal SVM启发本文采用的架构在编码阶段与输入层相比,连续隐藏层中的单元数更多,试图将输入数据映射到更高维子空间,将数据扩充有助于增加数据可分性以及增强数据恢复能力。从初始Xn维输入开始,然后在每个连续的隐藏层添加a个节点,将维度增加a维。经过一些测试实验,本文采用a=8能获得稳定较好的结果。
在模型输入阶段,将输入数据进行归一化处理,使得数据数值在0和1之间,以加快模型在中小样本量时收敛,同时引入噪声,在输入层随机将输入Xn中的一半分量设置为0,使得网络能提取到更加抽象的特征,增强网络鲁棒性。因此,在模型启动训练阶段,随机将输入部分分量设置为零,从而模拟完整样本缺失,迫使模型学会在样本损坏情况下恢复到样本原始构造,即学习将缺失值恢复到原值的能力。对于降噪自编码器部分,因为由多个隐藏层构成,因此采用逐层贪婪方式先对编码器和解码器网络进行预训练,最后配合分类器对整个模型参数进行微调。由于在初始化时需要完整的数据,因此在不完整样本输入前,对于缺失的连续变量使用相应的列平均值进行初始填补,对于缺失的分类变量使用属性中出现最多的值作为初始填补。
在网络中的分类器有两大作用:(1) 用于民航常旅客价值分类任务以监督缺失数据填补任务,使得缺失数据的填补以解决民航旅客分类任务为向导。(2) 作为主动学习的样本查询函数,将未标注含缺失项的样本通过网络模型输出各类别的概率,采用不确定度准则通过计算样本不确定度,选择不确定度高的样本用于主动类别标记与缺失数据填补。原因在于,不确定度可反映模型对此样本的分类能力,不确定度较高则说明当前模型对此样本分类能力差,而缺失数据的填补与分类任务有较大的相关性,因此基于面向民航旅客分类的缺失数据填补的角度,可将样本挑选出主动进行类别标注与缺失数据填补用于下一轮模型训练,以提升网络模型的整体性能。
2.2 主动学习训练过程
将未标注数据集通过分类器输出每个样本的不确定度进行主动填补缺失值和类别标注[12-13],训练过程如下:

2) 逐层无监督训练编码器网络与解码器网络。
3) 引入分类器网络,计算联合损失对整体网络进行微调,得到初始网络模型。
4) While(模型在验证集V上的性能指标未到达阈值α且未标记缺失数据集U不为空)
(2) 挑选大于不确定度阈值γ的未标记样本进行人工专家标记与填补。
(3) 若所有样本小于阈值γ,则对未标记样本的不确定度进行降序排序,挑选排名占前5%的未标记含缺失数据样本进行人工专家标记与填补。
(4) 将经过人工专家标记与填补的样本从U中移除,并放入L中。
(5) 采用SMOTE算法对L进行类别平衡化处理得到新样本集L*。
(6) 利用新样本集L*对整体网络模型进行参数更新。
(7) 将验证集V输入整体网络模型,并输出性能指标。
5) End While
整体模型以不确定度作为主动学习查询准则,并根据最小错误准则,以验证集的模型性能作为主动学习的停止准则,有效地将高价值且缺失严重的未标记样本选出,并使用溯源法对训练模型的缺失数据进行真实填补,进而提高模型整体性能。在每轮主动查询标记后,通过SMOTE算法能有效缓解每次主动学习后新增已标记样本导致数据集类别不平衡进而影响MLT-AL-DAE网络模型的分类精度。
2.3 基于Spark的缺失数据主动填补运行机制
考虑生产大数据环境,结合Spark在处理大数据上的优势,以及主动学习能有效对缺失数据进行筛选,降低进行人工溯源真实填补的成本,提出一种基于Spark的缺失数据主动填补机制。主要由以下步骤构成:
步骤1对输入的民航旅客数据源进行数据完整度检测,将输入的数据分为完整已标注数据集Label Set和不完整或未标注数据unLabel Set。
步骤2对Label Set模拟随机完全缺失后进行MLT-AL-DAE网络模型初始预训练。
步骤3对unLabel Set将其收集后上传至HDFS文件系统中,用于后续主动学习。
步骤4采用Spark读取HDFS上的unLabel Set和已预训练的MLT-AL-DAE网络模型并进行主动学习。
步骤5引入人工专家对经过主动学习挑选出来的数据记录从unlabel Set中移除并进行类别标注和缺失数据填补。
步骤6将经过类别标注和缺失数据填补的数据合并至Label Set中,并从unLabel Set中删除。
步骤7检测MLT-AL-DAE网络模型在验证集中是否达到性能标准,若达到标准则停止主动学习训练后续unLabel Set中数据记录的通过MLT-AL-DAE进行缺失数据填补与类别标注,否则转至步骤4对unLabel Set继续进行主动学习。
开始对数据源进行数据质量检测,参照生产大数据环境,采用HDFS系统[14-15]作为数据源,将含有缺失数据且未标记数据分出并上传至HDFS系统中便于后续使用Spark进行处理。针对缺失数据采用主动学习进行判断记录的缺失数据是否适合模型填补,若记录的缺失数据通过模型填补的质量较低即不确定度较高,则引入人工专家的方式采用溯源法向上游数据系统搜寻缺失数据的真实值进行填补,极大缓解了模型对缺失数据填补与数据真实值的差距。结合使用Spark在大数据环境下训练MLT-AL-DAE模型具体过程如图3所示。

图3 使用Spark训练过程
3 实 验
3.1 数据集说明
本实验采用由中航信经过脱敏处理后某航空公司部分常旅客运营主数据。数据集大小约为21 GB,属性维度为44维。数据集中,其与核心业务相关的主要属性包括三个方面:(1) 旅客基本信息:包含旅客ID、旅客性别、旅客年龄、旅客工作所在城市、旅客价值等级、首次乘机时间等。(2) 旅客值机信息:包含旅客当前累积飞行次数、观测窗口结束时间、旅客总飞行公里数、票价收入、平均折扣率、平均乘机时间间隔、末次飞行日期等。(3) 旅客积分信息:包含总基本积分、积分兑换次数、总精英积分、促销积分等。实验以旅客价值等级为数据集预测目标类别属性,其余属性作为数据集的特征属性。
3.2 数据预处理
在删除对模型无意义的旅客ID属性同时,对数据集中的离散特征的标签类别属性如旅客性别、旅客工作所在城市等进行数值化处理。对时间点类型的属性如入会时间、首次乘机时间等,将其与观测窗口结束时间做减法,得到相应时间间隔,同时根据民航旅客价值度量LRFMC模型[16]对数据进行聚类分析后对旅客记录进行类别标注,分为高价值重要保持旅客、潜在价值重要发展旅客、重要挽留旅客、一般价值旅客、低价值旅客共5类,最后得到41维属性。
3.3 实验环境和网络模型参数
实验编程语言为Scala和Python,采用DeepLearning4j作为大数据环境下的神经网络训练框架,实验设备4核CPU、8 GB内存、40 GB硬盘的服务器,一共四台,其中一台作为Master节点,另外三台作为slave节点组成集群。其中,对于MTL-AL-DAE网络,使用Keras+TensorFlow框架完成搭建并完成本地初始化预训练,并通过DeepLearnin4j中的Keras model import模块导入在本地环境由Keras+TensorFlow框架训练完成的初始网络模型,之后使用DeepLearning4j和Spark对网络模型在大数据环境下进行训练。
经过多次预实验,网络采用4层架构,tanh函数作为编码器与解码器的激活函数,Softmax函数作为分类器输出层激活函数,优化器采用Adam优化函数用于更新网络参数。考虑到实现环境下高价值重要保持旅客样本要远低于一般价值旅客,数据集类别不平衡,因此MLT-AL-DAE模型在训练时,对于分类任务以F值[17]进行度量,对于缺失数据填补任务以均方根误差RMSE度量。
3.4 模型性能对比实验
数据缺失机制分为完全随机缺失、随机缺失、非随机缺失[18],考虑到完全随机缺失变量的缺失与自身和其他变量无关,随机度高且具有普适性,因此在模型性能对比实验中,抽取68 000条未缺失数据记录分别以0.2、0.3、0.4、0.5、0.6、0.7、0.8的缺失率模拟完全随机缺失后,数据的缺失与数据的分布不存在规律性。之后,在本地训练MLT-AL-DAE网络模型,同时将模型与KNN填补法、MIC填补法[19-20]、DAE填补法[21]、MEAN填补法进行对比,结果如图4所示。
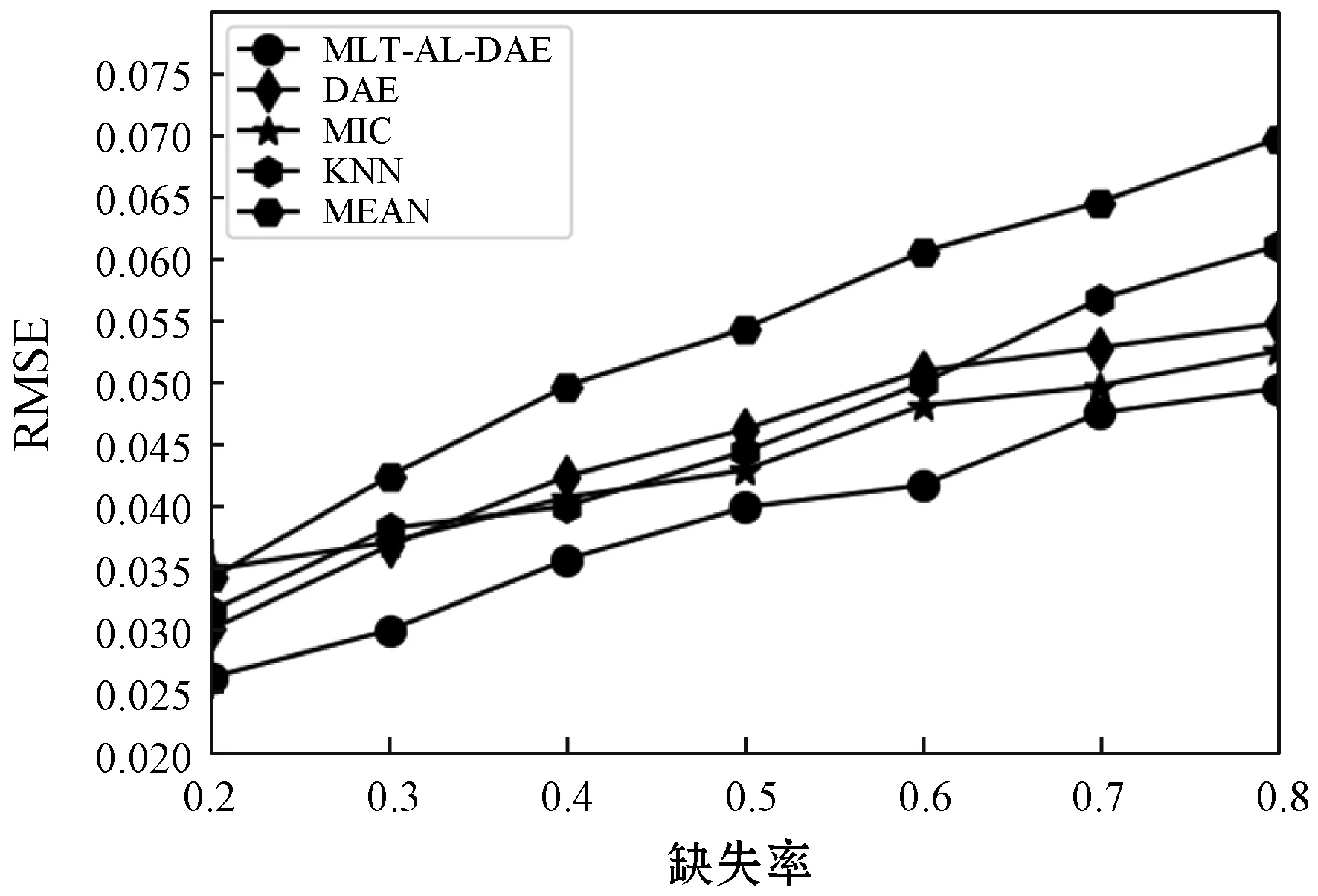
图4 缺失数据填补性能对比
从整体上看本文方法在缺失数据填补方面一直保持较稳定的效果。随着缺失率不断增大,均方根误差与其他传统方法相比较低,且差距明显。尤其是在数据集缺失率较高的情况下,配合多任务学习能对数据进行有效填补。
缺失数据填补的最终目的是有助于后续的数据挖掘与分析。因此,度量在民航旅客价值分类中的效果也是从侧面反映填补效果。在分类实验中采用F值作为度量分类任务性能指标,并将经过传统处理填补算法的数据采用SVM模型作为填补后数据集分类预测模型,综合结果如图5所示。

图5 分类补性能对比
可以看出,本文提出的MLT-AL-DAE网络模型在民航旅客价值分类上取得较好的效果,随着缺失数据集缺失率不断加大,与常规基于MIC的简单填补法的性能差距不断加大。这极大体现出多任务学习的优越性,通过任务之间的相关性,使得不同任务之间并行互相学习,从而提升模型整体性能。
3.5 多任务学习有效性验证实验
为验证本文设计的MLT-AL-DAE模型在多任务学习上的有效性,将MLT-AL-DAE模型的输出填补值对缺失数据进行填补后,分别采用逻辑回归(LR)、支持向量机(SVM)、最近邻分类器(KNN)进行旅客价值分类任务,与MLT-AL-DAE模型在分类任务的输出进行对比,实验采用F值进行度量。实验结果如图6所示。
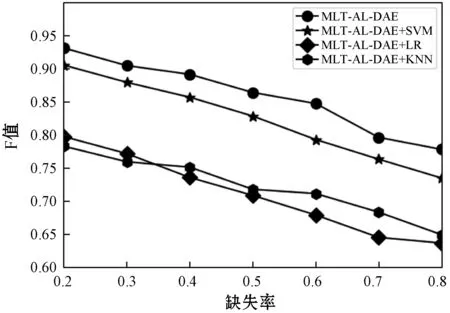
图6 多任务学习有效性验证实验对比
如图4-图6所示,MLT-AL-DAE模型性能最优,采用SVM分类器比LR、KNN分类器性能更好,原因在于经过SMOTE类别平衡化处理的样本会产生一定的噪声样本,而SVM分类器将样本映射到相应空间找到最优分类面的方式进行分类,对噪声样本不敏感,而LR、KNN分类器则对噪声样本较为敏感。相对于先进行缺失数据填补,再进行分类任务的传统方法,MLT-AL-DAE模型通过共享降噪自编码器特征提取层进行缺失数据填补与分类任务的方式,模型能学习到数据集各自任务中更高维、更抽象的特征,通过互相学习各自任务中的额外信息,最终各自任务互相提升,极大体现出多任务学习的有效性,从而达到缺失数据的填补以民航旅客流失分类任务为导向的效果。
3.6 主动学习有效性验证实验
为了进一步验证主动学习的有效性,将MLT-AL-DAE模型分别进行主动学习训练和全数据量训练。以缺失率0.2、0.4、0.6为例,在主动填补中,训练集10 000条设为已标注训练集,剩余设为未标注训练集。同时在实验过程中,对MLT-AL-DAE模型在主动学习停止时记录模型训练时通过主动学习进行标注和缺失数据填补的样本数量。两种训练方式在缺失数据填补和旅客价值分类性能对比结果如表1-表3所示。
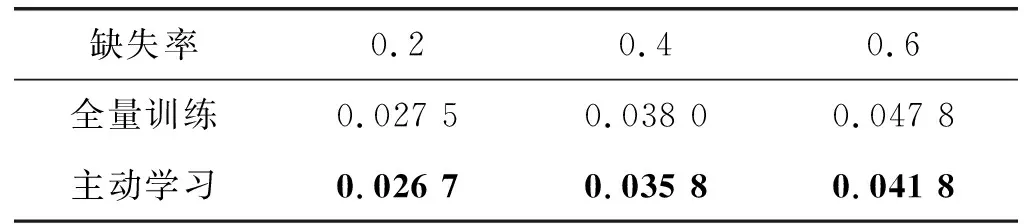
表1 MLT-AL-DAE与MLT-DAE缺失数据填补性能对比

表2 MLT-AL-DAE与MLT-DAE旅客价值分类性能对比

表3 主动学习停止时主动学习样本数量
由表1和表2可以得出,全量训练与主动学习相比,主动学习在缺失数据填补任务中保持稳定,在旅客价值分类任务中有一定的提升。由表3可知,随着数据集的缺失率不断提升,主动学习为达到相应停止准则需要的标记样本数也不断提升。在通过分类器网络模块输出的不确定度,模型能有效挑选出具有高价值、信息量大的样本进行人工专家标记与填补,进一步提升了训练集的数据质量,从而进一步减少模型进行缺失数据填补与分类任务所带来的误差,使得模型能提前到达模型最优值同时所需训练样本数量减少,在实际生产环境中有助于识别缺失数据较为严重的数据记录降低数据标注与填补成本。
3.7 Spark高效性对比实验
为验证基于Spark主动填补机制在大数据环境下的优势,将初始训练好的网络模型上传至HDFS文件系统中,同时以缺失率0.4分别对1 GB、5 GB、10 GB、15 GB大小的数据模拟完全随机缺失,最后分别采用在Spark集群和单机进行缺失数据主动填补并统计模型训练耗时,统计结果如图7所示。

图7 耗时对比统计
可以看出,当数据集大小为1 GB或小于1 GB时,由于Spark集群启动初始化和对数据集和模型进行广播以及缓存数据需要进行耗费一定的时间,同时读写HDFS也需要花费一定的时间,而数据量太小,集群优势不明显,因此通过Spark集群训练模型耗时要高于单机训练。然而,当数据量达到5 GB及以上时,Spark发挥集群的优势,快速对主动挑选出高价值、未标记样本进行真实值标注,使模型精度能提前达到阈值,进而节省大量时间,随着数据集数据量不断升高,Spark集群训练优势呈现不断加大趋势。
4 结 语
本文针对民航常旅客服务主数据记录存在缺失值较多且数据类别不平衡的情形,首先设计出一种基于降噪自编码器的多任务主动学习网络模型MLT-AL-DAE,同时并行解决民航常旅客服务缺失数据填补和旅客价值分类问题,并能有效识别出缺失项对旅客价值分类影响较大的记录进行主动学习填补。其次,考虑生产大数据环境下,数据量大单机训练耗时较长的问题,引入Spark计算引擎,提出一种基于Spark环境下的缺失数据主动填补机制,使得MLT-AL-DAE模型能在大数据环境下发挥应有的优势。通过对比实验表明,相比传统处理方法,本文方法模型考虑到现实生产环境,在缺失值填补和分类预测任务中有着较好的性能,在提升分类精度和数据质量的前提下,同时能降低数据标注和缺失数据人工溯源填补的成本,因此具有较大的工程应用价值。
猜你喜欢
应用心理学(2022年5期)2022-11-05
农业工程学报(2022年12期)2022-09-09
现代信息科技(2021年21期)2021-05-07
科技与创新(2017年5期)2017-03-28
数学学习与研究(2017年3期)2017-03-09
中国新技术新产品(2016年23期)2016-12-26
电脑知识与技术(2016年2期)2016-03-22
计算技术与自动化(2014年1期)2014-12-12
电子设计应用(2004年6期)2004-07-27
