
基于深度学习的网页违规图片检测
2022-09-07 05:05李柏岩刘晓强
现代计算机 2022年13期
余 聪,李柏岩,刘晓强
(东华大学计算机科学与技术学院,上海 201620)
0 引言
近年来,随着信息技术的高速发展,网站已经成为企业和机构与用户交互的重要平台,许多线上业务都必须依托网站开展。然而,由于网络世界的虚拟性、开放性,网络监管变得尤为困难,尤其是一些色情、暴力、垃圾广告等不良图片的传播,使得网络应用面临着巨大的风险。
针对网站中可能出现的大量不良图片,使用人工监管的方式,无疑需要耗费巨大的人力成本。随着深度学习的快速发展以及深度卷积神经网络在抽象特征提取上的巨大优势,深度学习的方法明显优于传统的图像识别算法。通过设计一个基于深度学习的智能图像审核系统,实现违规图像的自动识别,不仅可以大大节约审核人力,还可以快速、精准地对不良图像进行过滤。
网络违规图片检测目前也受到了工业界的关注。近年来,针对互联网上传播的违规图片,工业界通常提供单一接口检测单类违规图片的服务,这种检测方式存在着一定的局限性,不适用于一些中小型企业的实时在线图片监测需求。首先,对于多类违规图片检测,用户通常需要购买多个接口,检测成本高,集成效率低;其次,工业界训练的模型复杂,对硬件要求高。本文针对目前网络违规图片实时监测的需求,提出了一种基于深度学习的网页违规图片检测方案。主要贡献如下:
(1)构建了多类别违规图片数据集。基于卷积神经网络的图像识别技术,需要通过大量的数据集来学习图像中的抽象特征。本系统待检测的图片均为不良图片,现有的公开数据集十分有限。本文主要通过抽取公开数据集、网络爬虫、提取视频关键帧并对得到的数据进行清洗的方式构建违规图片数据集。
(2)基于MobileNet 设计了一个轻量级模型对色情、暴力和广告等三类不良图片实现一次性检测,在保证准确率的前提下,提高了模型检测的效率。
实验和应用表明,该模型用于检测网页违规图片时,准确率高、速度快,可以为中小型网站提供一种低成本的违规图片检测服务。
1 网页违规图片检测整体框架
网页违规图片检测主要分为样本库构建、模型构建、网页图片检测三部分,如图1 所示。为了构建图片检测模型,首先通过网络爬虫、提取视频关键帧、抽取公开数据集等方式构建初始样本库,由于违规图片样本数量有限,使用数据增强的方式来扩大训练样本数量;然后以MobileNet 作为骨干网络,搭建违规图片检测模型(illegal picture detection model, IPDMnet),在保证模型准确率与检测速度的前提下,对模型进行训练并优化;在网页图片监测阶段,以爬虫方式爬取得到网页图片,并利用违规图片检测模型IPDMnet 对爬取的图片进行检测,最后输出检测结果。
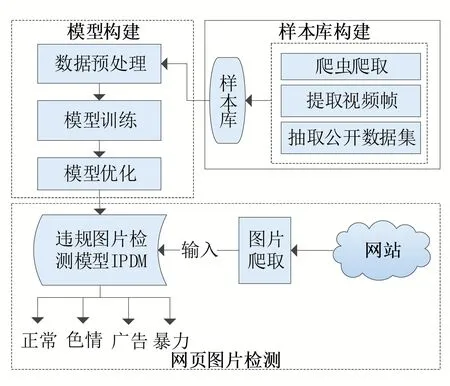
图1 网页违规图片检测整体框架图
2 基于多分类的网页违规图片检测模型
2.1 样本库构建
通过对实际业务需求的分析,将需要检测的违规图片分为正常、色情、暴恐、垃圾广告这四类。数据集样本库的来源如下。
2.1.1 正常图片
主要指不包含违规内容的图片。本文首先从公开数据集ImageNet 选取20 种最常见的类别,如人物图、动物图、风景图等,再从每个类别随机抽取一定数量的图片构建正常图片样本。
2.1.2 色情图片
主要指包含淫秽信息的图片。本文构建的色情图片分为真人和动漫两大类。由于公开的色情数据集十分有限且分辨率低,真人类色情图片主要通过抽取NSFW 图像数据集的方式构建,动漫类色情图片主要通过网络爬虫的方式从国外不良网站爬取。
2.1.3 广告图片
主要指包含二维码、手机号、推销标语等具有明显推销意图的图片。本文主要通过网络下载的方式构建。
2.1.4 暴恐图片
主要指包含明显打斗、血腥场景的图片。目前没有公开的暴恐图片数据集,本文主要从影视视频和暴恐视频数据集提取视频关键帧进行数据集构建。
2.2 数据预处理
为了提高模型的训练速度以及模型的准确率,需要对训练的图像数据进行预处理。本文主要从数据清洗和数据增强方面提高图像数据的质量。
2.2.1 数据清洗
由于采集的图片大多来自于网络,图片的形状、大小不一,将对模型训练产生一定的影响。比如图片的高宽比过大或者过小时,图片会严重变形、失真,故本文将采集到的图片数据进行过滤,去除高宽比大于5或者小于0.2的图片;而当图片的尺寸过小时,图片识别度大大降低,尺寸过大时,影响模型训练速度与成本,故本文将可用的图片数据限制在10 K~10 M之间。
实验表明,图片的格式类型同样会影响模型的训练,比如单通道灰度图像、多通道的RGB 图像和BGR 图像等。为了提高训练集数据质量与规范,本文将训练集数据规范为RGB 类型。对单通道的灰度图像,先进行通道扩充;对于BGR图像,先将其转化为RGB图像。
2.2.2 数据增强
为了进一步扩大训练数据量,从而提升模型性能,采用多种数据增量技术。传统的随机缩放裁剪方法,可以产生大量图片碎片,成倍扩充数据量。但针对本文处理的违规图片,特别是色情、暴恐类图片,当它们被裁切之后,往往会失去原有的属性,造成对应的标签错误。因此,本文在轻量级数据增强技术的基础上,引入一种免搜索的自动数据增强策略TrivialAugment。传统的自动数据增强方法如AutoAugment往往是以数据增强策略作为搜索空间,并结合强化学习得到搜索方法,但这类自动数据增强的方式往往搜索空间巨大,实验代价高。TrivialAugment 不需要任何搜索,方法十分简单:先定义一个图像增强策略集合,每次随机选择一个图像增强策略,并随机确定它的增强幅度,最后对图像进行增强。整个过程不需要任何超参数,所以不需要任何搜索。
本文首先对已有数据集图像分别水平翻转90°、180°、270°,将数据扩大为原来的4 倍,再引入TrivialAugment 进行自动数据增强。实验表明,TrivialAugment 在本文的违规图片数据集上具有良好的应用效果。
2.3 基于MobileNet的违规图片检测模型
2.3.1 IPDMnet核心结构
传统的深度卷积神经网络,如AlexNet、VGG、GoogLeNet、ResNet 在图像分类领域都取得了良好的效果。但是,这些传统的深度卷积神经网络往往模型复杂、计算量大,对硬件资源有限、模型速度要求快的场景并不适用。本文采用轻量级网络MobileNetV2 作为骨干网络。MobileNetV2网络是google 团队在2018 年提出来的,该模型准确率高、参数小、运算量低。此外,最近研究表明,通道注意力机制如SE-NET 在提升深度卷积神经网络性能方面有巨大的优势。但是,传统的注意力模块往往需要增加大量参数,提高了模型的复杂度。因此,本文在模型中引入一种轻量级注意力模块ECANET来提升模型性能。
MobileNetV2的优势主要源于倒残差结构,而SE注意力模块在残差网络结构上有良好的表现。Hu 等通过消融实验证明,将SE 模块引入残差结构之后,能够有效提高残差模型的性能。由于倒残差结构与残差结构提取特征的方式十分类似,ECA 模块也相当于对SE 模块的一个改进,本文受此启发,将ECA 模块引入Mobile-NetV2中的倒残差结构之后,构建基于倒残差结构和ECA 分支的block 块。构建的block 块为IPDM模型的核心部分,如图2所示。实验表明,ECA 与倒残差结构的融合在本文的违规图片数据集上能够取得良好的效果。
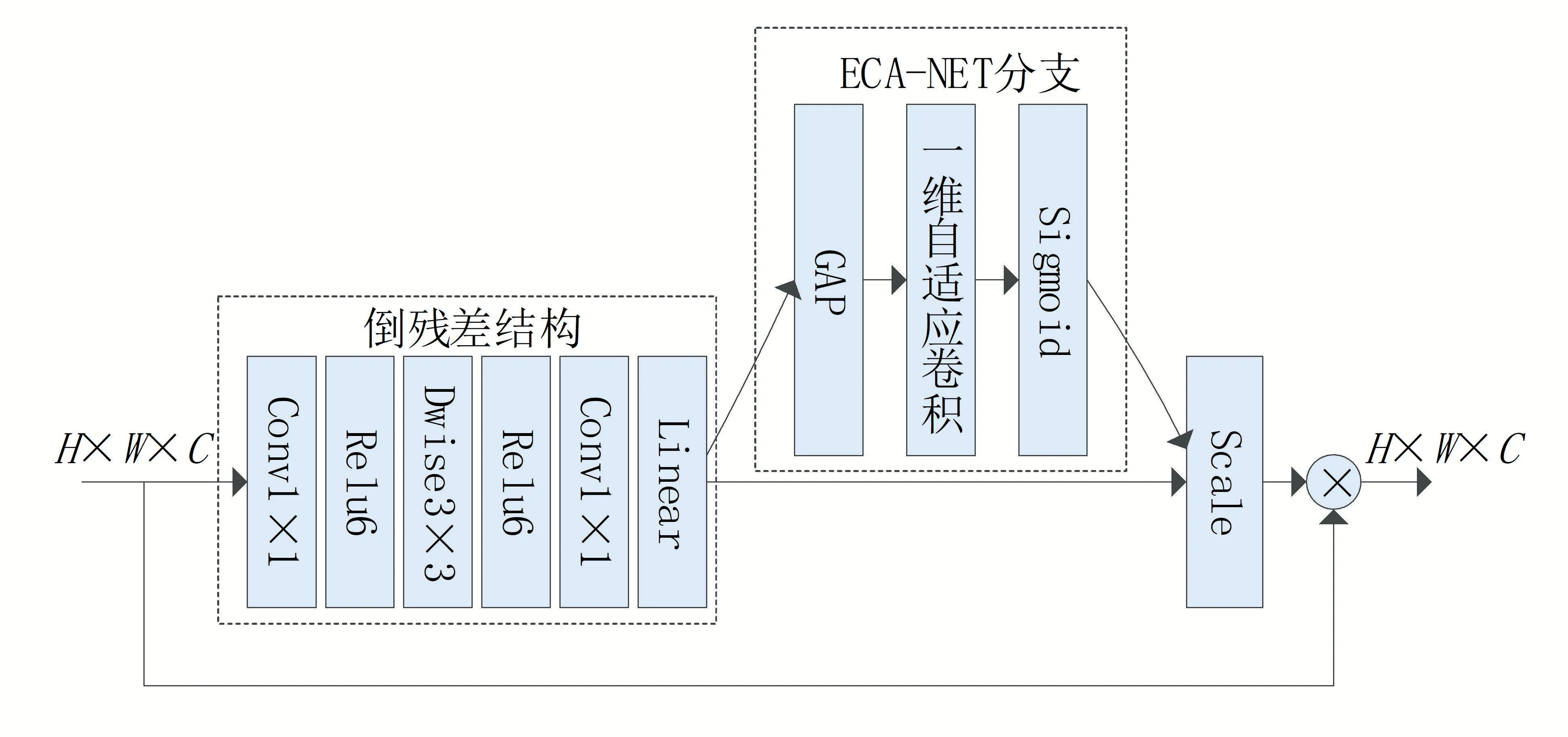
图2 IPDMnet核心结构示意图
2.3.2 倒残差网络
倒残差结构主要分为三个部分:升维卷积PW1、特征提取卷积DW、降维卷积PW2,并借鉴ResNet 的残差结构,使用shortcut 将输入与输出相加,如图3所示,它主要是为了适配DW 卷积而设计的。由于DW 卷积自身的计算特性决定了它不能改变通道数量,所以如果上一层输出的通道数较少,DW 卷积只能在低维空间提取特征,效果并不好。所以倒残差结构给每个DW卷积都配备了一个PW 卷积用于升维,通过升维系数设定。这样即使输入通道比较低,经过一个PW 卷积升维后,DW 卷积都可以在一个相对更高维的空间提取特征。另一方面,相关实验表明,激活函数在高维空间能增加非线性能力,在低维空间会破坏特征,因此,在经过PW2 卷积的降维操作后,不再使用激活函数,而是使用一个linear层线性输出。
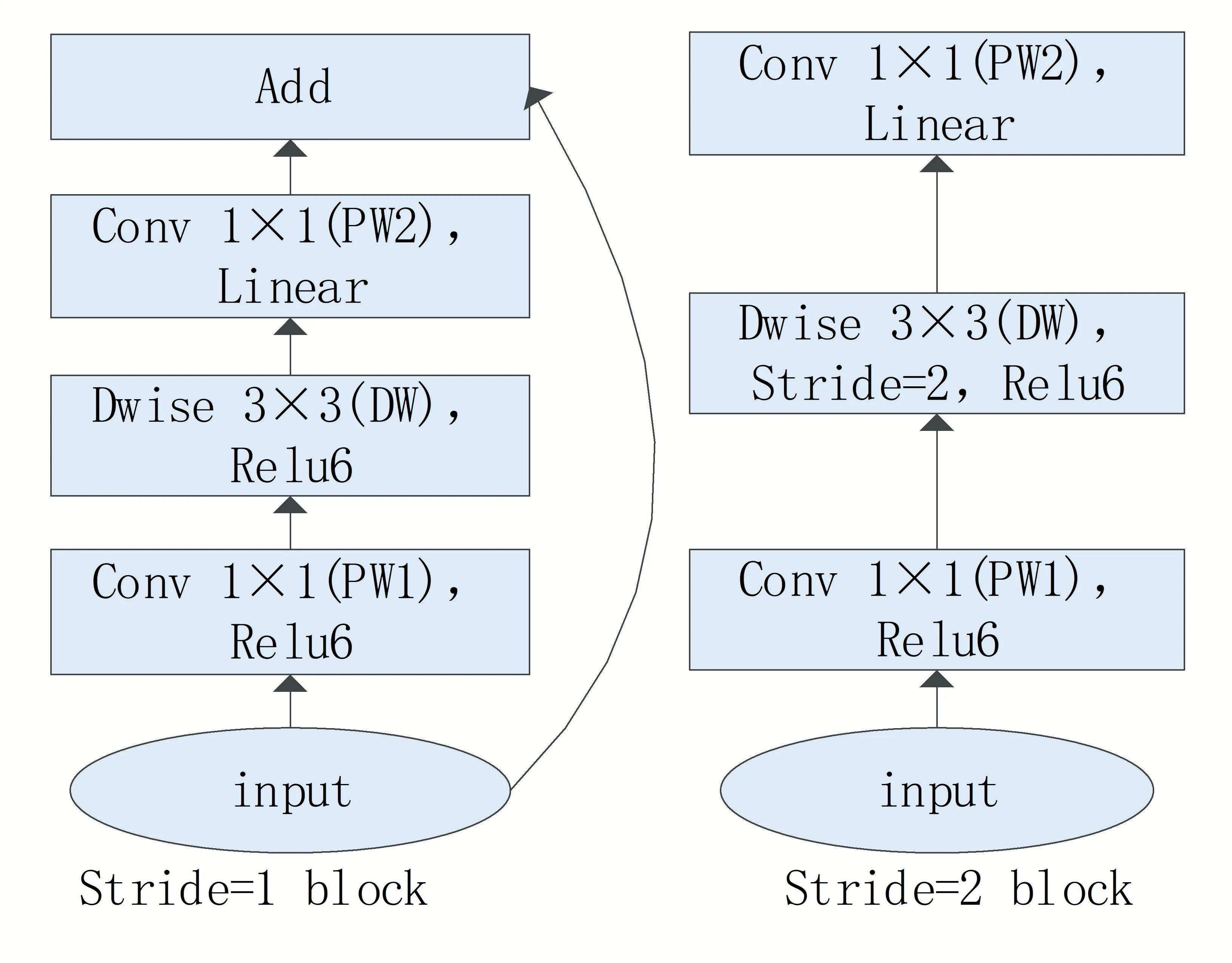
图3 倒残差结构示意图
2.3.3 ECA-NET分支
ECA-NET 是一种极轻量级的注意力模块,它以SE 模块为基础,通过引入一维卷积,不仅避免了特征维度的缩减,并且保证了通道间的信息交互,在降低复杂度的同时,保持了模型性能。ECA 模块主要包含三个部分:全局平均池化产生对应特征图,计算得到自适应的kernel_size,应用kernel_size 到一维卷积产生对应通道权重,如图4所示。通过自适应函数得到一维卷积的卷积核大小,可以使得通道数较大时进行更多的通道信息交互。自适应卷积核大小计算公式为:
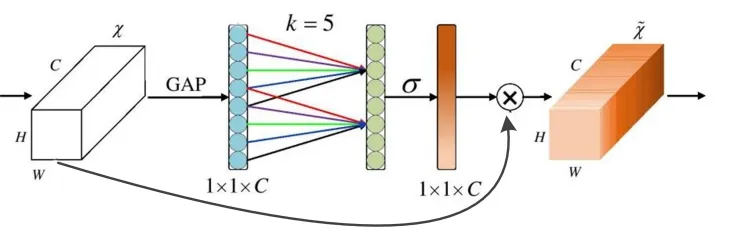
图4 ECA网络结构示意图
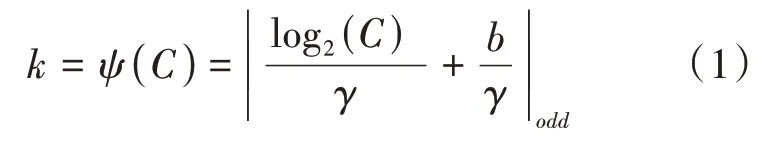
公式(1)中表示输入的通道数,其中= 2,= 1,表示选择最近的奇数。
本文模型IPDMnet 的输入为224 × 224 大小的图片,特征提取部分包含1 个卷积层和7 个基于倒残差结构和ECA 的block 块,其中构建的block 块为模型的核心部分。第一个卷积层采用32 个3 × 3 的卷积核,卷积核步长为2,卷积层后面设置一个BN 层,以加快模型的收敛,激活函数使用ReLU6;每个block 块在倒残差结构之后构建ECA 分支,并给对应的通道加权;分类器部分采用一个平均池化下采样层avgpool 和一个全连接层,为了防止模型过拟合,在全连接层中加入dropout 层并设置dropout 值为0.2。由于本文做的是4分类,最后全连接层的神经元个数设为4。
3 实验结果分析
3.1 数据集
本文通过爬虫爬取、提取视频关键帧、抽取公开数据集的方式构建初始样本库,并对得到的样本进行清洗,构建多类违规图片数据集。由于在现实应用场景中,正常图片出现的概率远远大于违规图片,所以构建数据集时,正常图片数据集的比例也要大于违规图片。本文构建的数据集如表1所示。
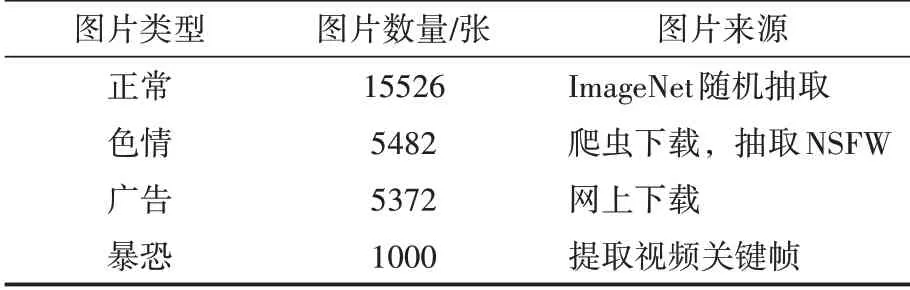
表1 数据集描述
3.2 实验环境与评价指标
实验平台操作系统为CentOS 7.7.1908,支持软件版本为Python 3.6、PyTorch 1.10.0。执行训练的服务器CPU 为Intel(R)Xeon(R)Silver 4208,64 G内存,GPU为4核GTX2080Ti。
为验证违规图片检测模型IPDMnet 的可行性,本文采用准确率、每张图片平均检测速度,模型参数大小评判模型的性能。各项评价指标的计算方法如下:

公式(2)中,表示分类正确的样本数,表示样本总数。

公式(3)中,表示检测100 张图片所消耗的时间,单位为毫秒(ms)。
3.3 模型性能分析
实验将数据集划分为训练集和测试集的比例为8∶2。通过反复的训练实验,最后将模型主要训练参数设置如下:learning_rate:0.0001,batch_size:16,num_workers:8,模型采用Adam优化器,交叉熵损失函数。由于本文违规图片数据集样本有限,为了得到更好的训练效果,首先,将模型在Caltech 256 数据集上进行迁移学习,得到预训练模型,最后再在训练集上迭代训练100轮。
根据上述实验设置以及模型评价指标,本文主要从经典深度卷积神经网络、基于注意力机制的Transformer、轻量级网络三个方面进行实验对比。以传统的深度卷积神经网络ResNet34 作为骨干网络,再融合ECA 注意力机制,模型准确率能够达到97.07%,预测单张图片需要6.08 ms;使用Swin_Transformer_Tiny 模型进行实验,模型准确率虽然也能够达到96.98%,但是预测单张图片需要12.67 ms,模型复杂度较高;最后,使用IPDMnet 进行实验,模型准确率与表现较优的ECA-ResNet34 准确率十分接近,但检测速度明显优于它和其他模型,并且模型复杂度大大降低。由于本文的违规图片检测模型主要为中小型企业提供服务,综合考虑准确率与检测成本,IPDMnet相比于其它模型将会有较大优势。
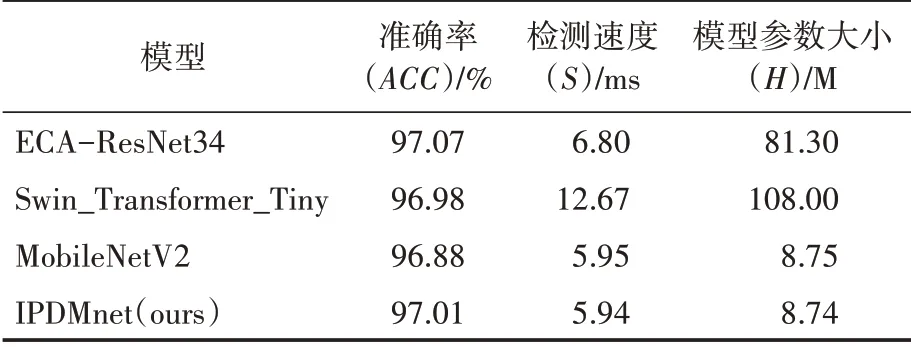
表2 不同模型的检测效果比较
4 结论与展望
网页违规图片监测是维护网络安全的重要环节,而不良图片种类繁多、形式多样,对图片实时监测提出了挑战。本文针对色情、暴恐和广告违规图片类别,构建相应的数据集,构建了一个基于深度学习算法的网络结构模型,同时实现多类违规图片的检测。实验表明,该模型准确率高、检测速度快、模型轻量,可为中小型企业提供网页违规图片实时监测服务。但由于违规图片内容复杂,具有一定的混淆性,加上违规图片数据集有限,对于一些特征比较模糊的图片,容易出现误判。接下来的工作将进一步扩充数据集,并对模型进行优化,提高
模型的识别范围以及模型准确率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
心理学报(2022年9期)2022-09-06
计算技术与自动化(2022年1期)2022-04-15
心理学报(2022年4期)2022-04-12
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
