
基于相关性分析和数据均衡的能见度分层预测模型
2022-09-07 03:20陆冰鉴
计算机应用与软件 2022年8期
陆冰鉴 周 鹏 王 兴, 周 可
1(南京信大气象科学技术研究院 江苏 南京 210044)2(南京信息工程大学大气科学与环境气象国家级实验教学示范中心 江苏 南京 210044)
0 引 言
大气能见度(Visibility)是反映大气透明度的一个指标。一般定义为具有正常视力的人在当时的天气条件下还能够看清楚目标轮廓的最大地面水平距离。大气能见度是气象监测中的一项重要指标,在道路通行、航海、航空和环境保护监测等领域应用较广[1]。20世纪60年代第二次工业革命以来,随着人类生产生活对化石能源的消耗剧增,排放到大气中的颗粒物如PM2.5、PM10越来越多,这些颗粒物凝结核形成的气溶胶降低了大气能见度,影响了交通运输业的安全运行,是导致交通事故的主要气象影响因子。在海洋和内河运输业中,大约三分之一的船舶相撞事故都是由能见度低导致的。虽然现代航船上有先进的导航系统,但低能见度仍然是一个不可忽视的隐患[2]。例如:2018年1月16日8:00“丰海18”轮与“惠丰6799”轮发生碰撞,“惠丰6799”轮沉没,后又有5艘船舶与“惠丰6799”轮相撞,据调查最主要是因为雾霾笼罩,水域能见度不良。所幸此次事故无人员伤亡,但是也造成了重大经济损失。因此,对于大气能见度的预测显得尤为重要。
当前,能见度预报仍以天气图分析预报、经验预报和数值预报为主。随着数值预报的发展,现在也有数值释用和雾模式预报等。数值释用要先了解污染物浓度和变化规律,再计算能见度。由于影响污染物浓度变化的因素和变化规律较难掌握,加上计算量较大,该方法在业务应用中开展缓慢[3]。而雾模式仅有一定的机理分析用途,难以进行实际预报[4]。近年来,学者们引入了神经网络[5]、支持向量机、线性与非线性回归[6]等方法。如梁之彦等[7]分别以径向神经网络和统计回归预报方程预报能见度,验证了径向神经网络在能见度低于10 km时预报准确率更高。由于能见度的影响因素有多种,需要寻找多元要素与能见度的关系,如蔡仁等[8]利用大气温度、相对湿度、风速等要素应用SVM和Elman神经网络方法分别建立乌鲁木齐市3 h能见度预报模型;马楚焱等[9]将7种气象因子和6种污染物浓度因子首先做主成分分析,再基于遗传神经网络模型预测输出8:00和14:00的能见度。这些方法改进能见度预报,但应用成果尚不理想,且在低能见度天气的预报上仍然薄弱。
为了解决样本不均衡、低能见度预报不准确等问题,本文提出一种基于相关性分析和数据均衡的能见度分层预测模型,主要通过相关性分析挑选主要相关因子,去除不相关因子的干扰;通过随机下采样进行数据均衡,通过先分类再回归的分层思想预测能见度。提高了网络的泛化能力,从而提高能见度类别预测的准确率,降低能见度预测的误差。
1 数 据
本文研究数据来自江苏省区域地面气象观测站,采用2000年1月至2018年12月逐日的观测数据作为实验数据,其中,将2018年之前的数据用作训练,将2018年的数据用作测试。其实验数据的主要组成如表1所示。其中数据要素主要包含45项输入因子和一项输出,45项输入因子主要包含地面因子、近地面因子和主观因子三类。
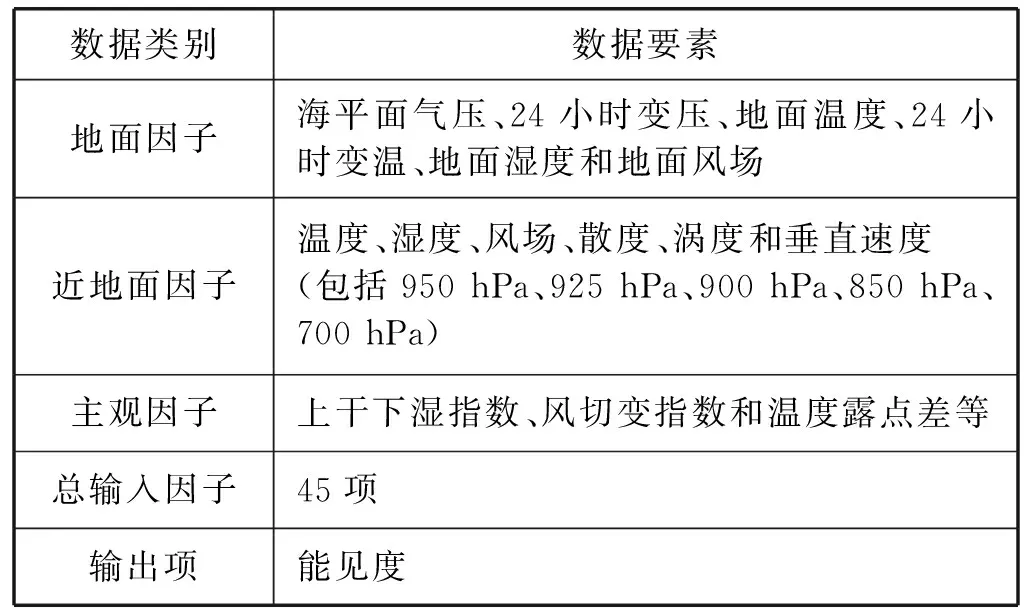
表1 数据总体构成
2 方 法
2.1 相关性分析
在本文数据总体构成中,采用45项因子作为输入项。但是考虑到在45项因子中,存在与输出项相关性很小或者不相关的因子,这些因子会干扰网络的学习,最终影响网络预测结果。因此增加对所有因子项和能见度做相关性分析,通过相关性分析结果,挑选出显著相关的因子作为输入项。
本文的相关性分析是通过SPSS软件计算Pearson相关系数分析得出,其Pearson相关系数计算结果如表2所示。表2中各要素缩写含义如表3所示。表2中数字后面带有*和**的表示显著相关,**在0.01水平(双侧)上显著相关,*在0.05水平(双侧)上显著相关。因此,挑选这样的因子作为输入因子,最后总共挑选出输入项34项。
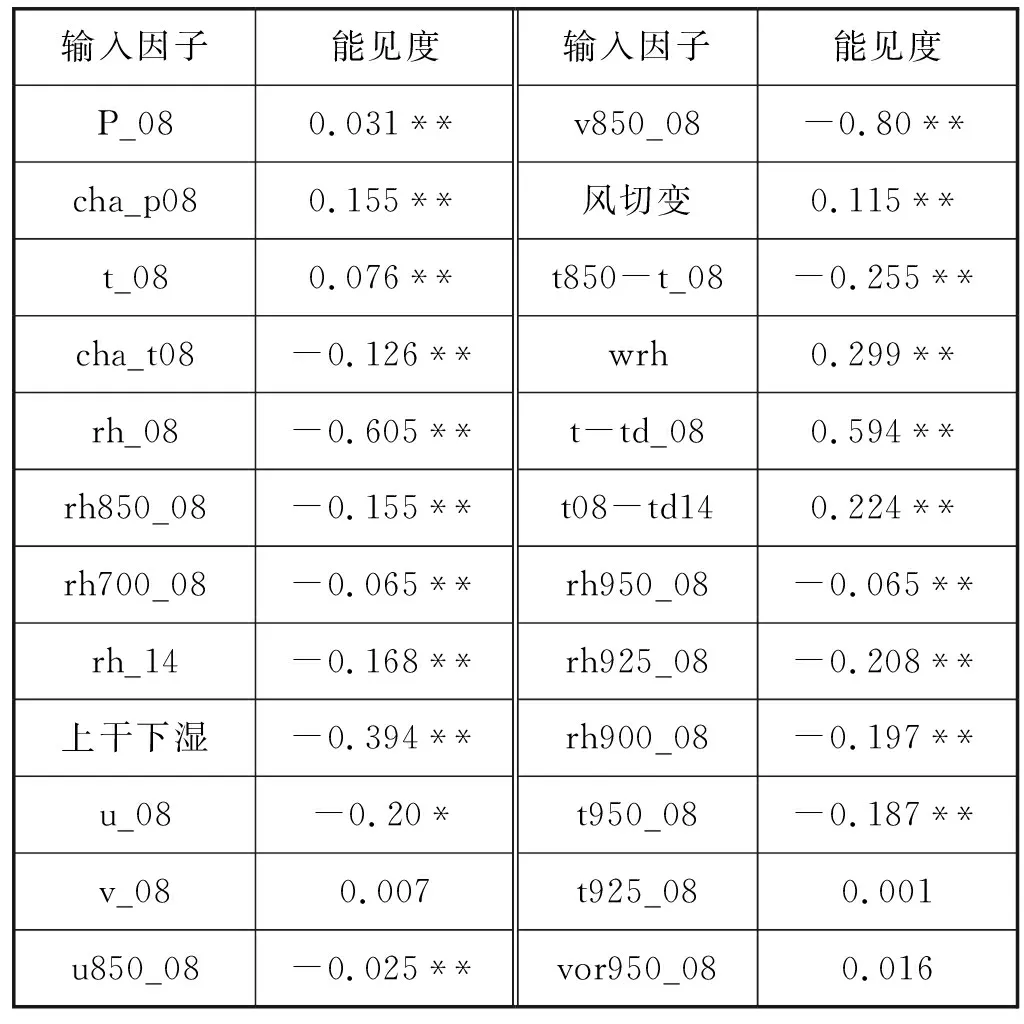
表2 各项输入因子与能见度的Pearson相关系数
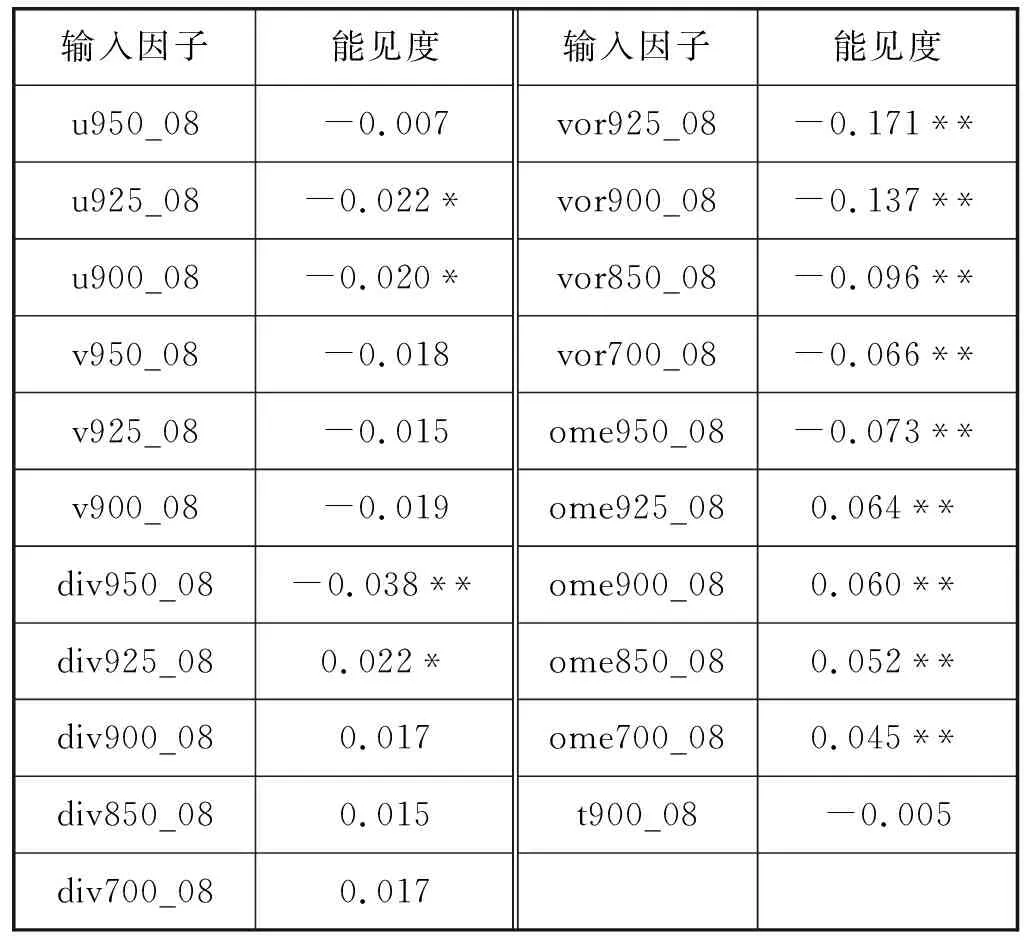
续表2
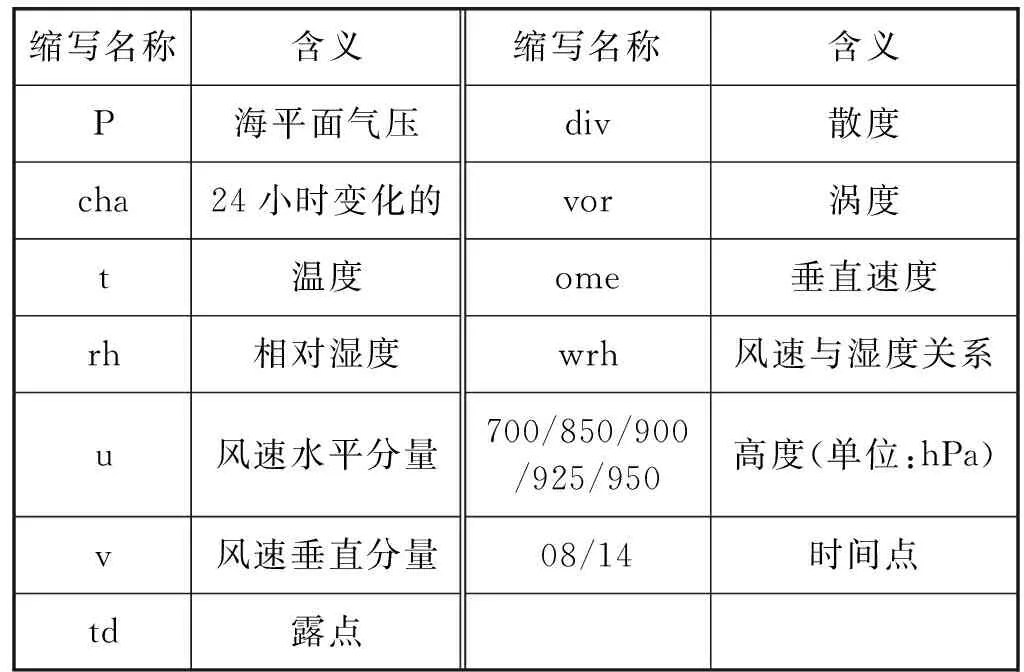
表3 各项英文缩写含义
2.2 数据均衡
由于在多数类样本中存在大量重复信息,一方面影响了样本的平衡,另一方面影响分类器的分类效果,因此需要剔除多数类样本中的冗余样本。本文采用随机下采样算法随机地选取一些多数类样本,再将这些样本从多数类中剔除,从而起到均衡原始数据的作用。
对采集的江苏省区域内各气象站点的样本数据进行统计,统计标准及统计结果如表4所示。
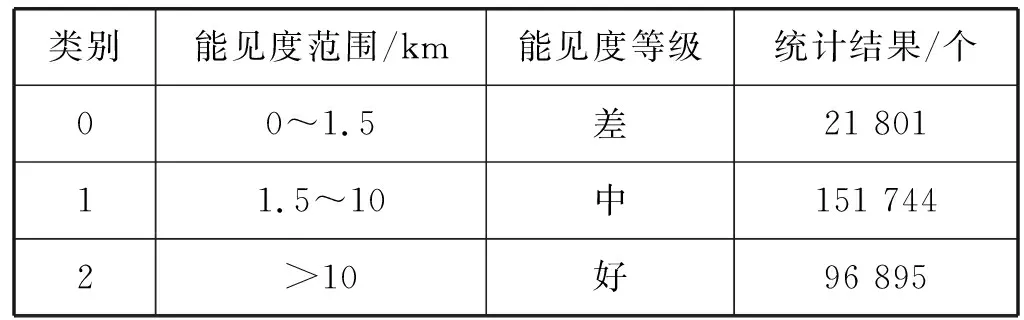
表4 能见度统计标准及结果
可以看出,能见度的各个范围的数据是严重不均衡的,这种不均衡会使得网络分类结果偏向于数量较大的那一类,影响预测准确性。因此,对总体数据样本进行均衡,即对第2和第3类样本进行随机下采样,使得第2、第3类的样本个数与第一类的样本个数相对均衡。实验中,第2和第3类样本下采样后的样本个数为20 000。
2.3 长短期记忆神经网络LSTM
LSTM是一种特殊的RNN类型,是由Hochreither等[10]提出的长短期记忆神经网络,采用记忆单元代替RNN隐含层的神经单元,用于解决RNN梯度消失的问题。LSTM记忆单元的内部结构如图1所示,包含输入门(Input gate)、输出门(Output gate)、遗忘门(Forget gate)和记忆细胞(Memory cell)。
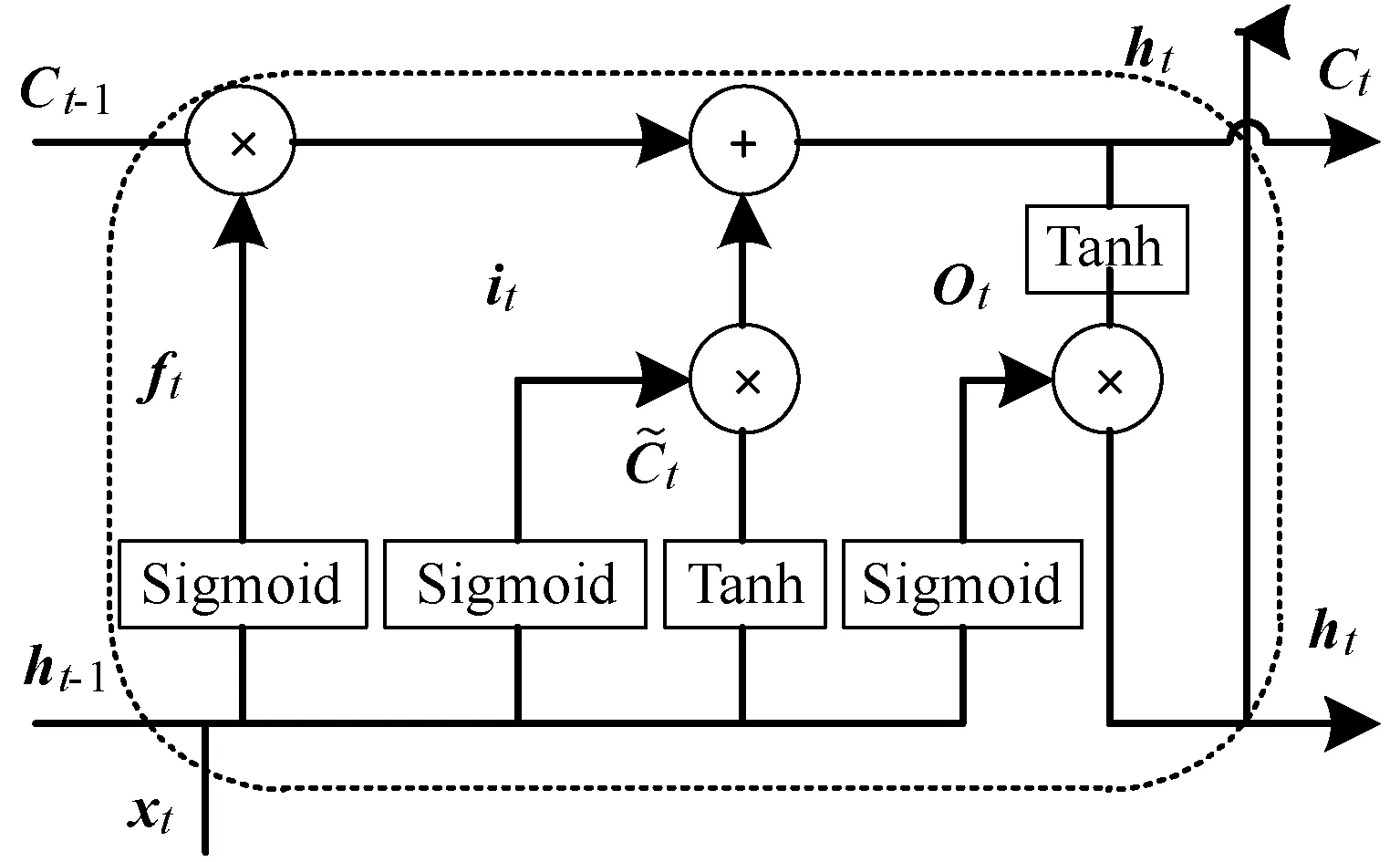
图1 LSTM记忆单元结构
图1中,xt、ht分别为t时刻网络的输入和输出。LSTM记忆单元通过以下公式迭代计算输出:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
ot=σ(Wo·[ht-1,xt]+bo)
(3)
Ct=ft×Ct-1+it×tanh(WC·[ht-1,xt]+bC)
(4)
ht=ot×tanh(Ct)
(5)
式中:ft、it、ot和Ct分别为遗忘门、输入门、输出门和记忆细胞的输出;Wf、Wi、Wo和WC分别为遗忘门、输入门、输出门和记忆细胞的权重矩阵;bf、bi、bo和bC分别为遗忘门、输入门、输出门和记忆细胞的偏置;σ为Sigmoid函数。
2.4 能见度分层预测模型
2.4.1模型总体设计
本文搭建了基于相关性分析和数据均衡的能见度分层预测模型,通过相关性分析挑选主要相关因子,去除不相关因子的干扰;通过随机下采样进行数据均衡,再通过先分类再回归的方法预测能见度。模型的第一层是基于LSTM的分类模型,第二层是基于LSTM的回归模型。该模型的总体结构如图2所示。
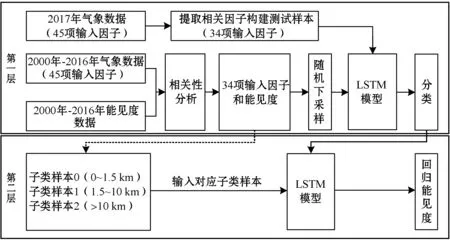
图2 基于LSTM的能见度分层预测模型结构
具体建模流程如下:
(1) 采集江苏省区域内气象站观测数据,处理为45项输入项及能见度输出项,并将2017年及以前的数据用作训练,2018年的数据用作测试,各因子如表1所示。
(2) 对45项输入项及能见度输出项做相关性分析,挑选出与能见度相关性较大的因子,其相关性分析如2.1节。
(3) 对上述处理后的样本,按照类别划分标准进行统计分析,通过随机下采样的方法均衡各类样本。
(4) 通过第一层长短期记忆神经网络(LSTM)分类模型进行样本分类。
(5) 将分类结果及对应的类别训练样本输入第二层基于LSTM的回归模型中,选择每类对应的子类样本,最终回归出能见度。
2.4.2分 类
将2017年及以前的数据做相关性分析后,提取相关因子,将原始数据形成如式(6)所示数据样本。
fi=[xi1,xi2,…,xi34,xi35]
(6)
式中:i表示样本个数;xi1,xi2,…,xi34表示第i个样本的34个输入项;xi35表示第i个样本的输出项。
根据能见度的分类标准,将上述数据样本处理成分类所需样本,如式(7)所示。
(7)
式中:Xi是输入项,Yi是类别标签。yi由式(8)得出。
(8)
将上述样本中2016年及以前的数据确定为训练样本:
S={(X1,Y1),(X2,Y2),…,(Xm,Ym)}
(9)
2017年的数据确定为测试样本:
S′={(Xm+1,Ym+1),(Xm+2,Ym+2),…,(Xi,Yi)}
(10)
式中:Xi表示第i个样本;Yi表示第i个样本的标签,即能见度的类别。
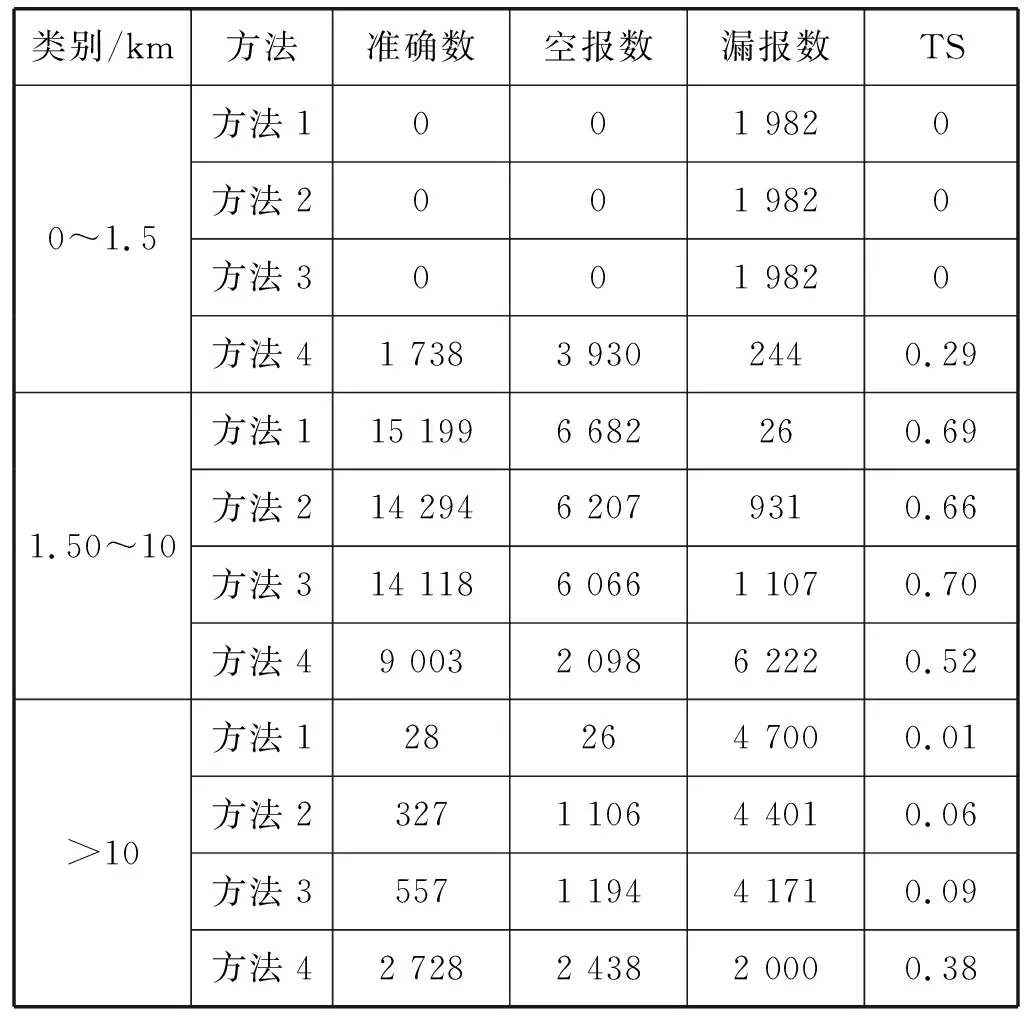
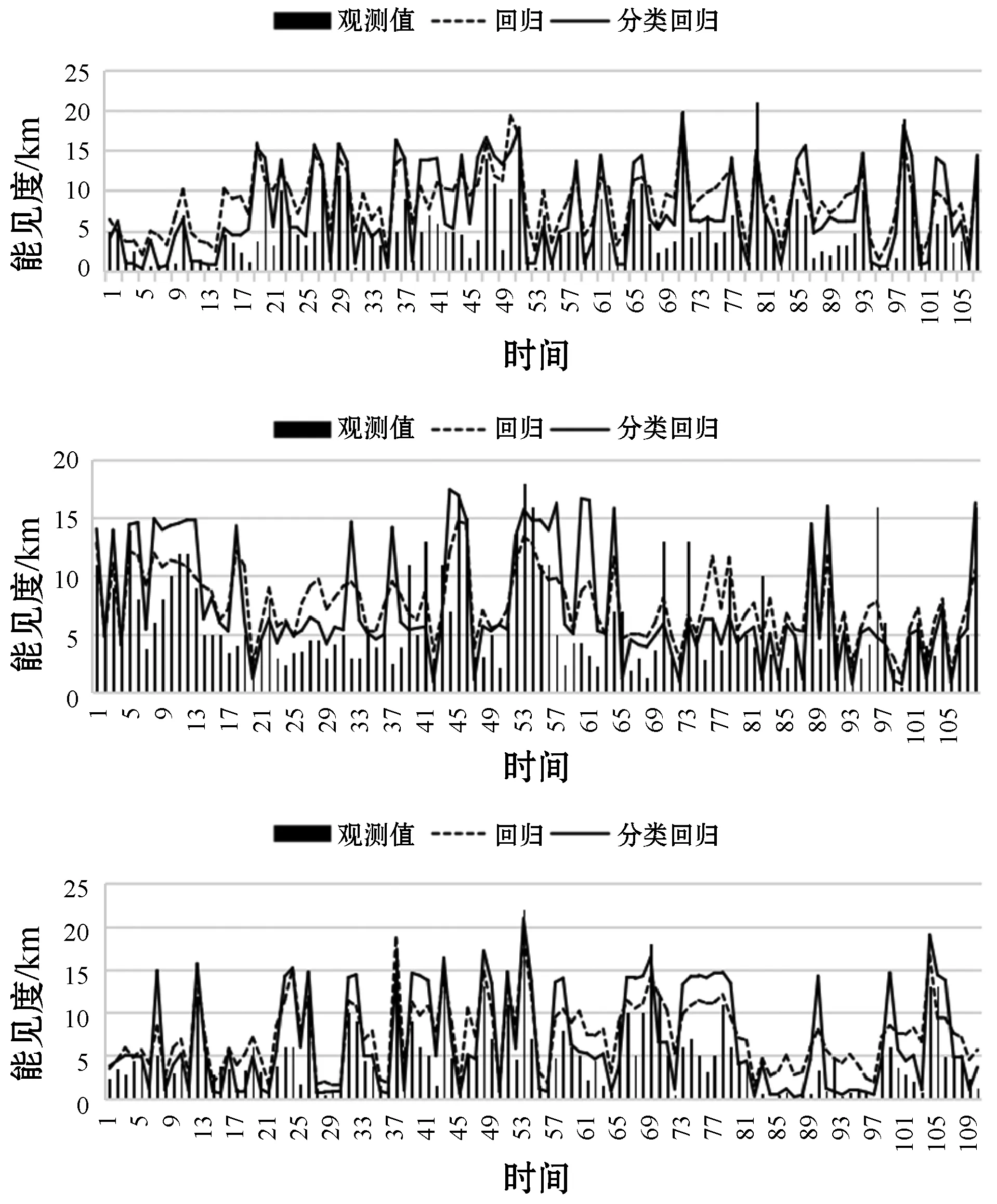
按照能见度类别,对训练样本进行随机下采样,均衡各类样本数量,使得各类样本数量相对均衡,此时训练样本如下(n S={(X1,Y1),(X2,Y2),…,(Xn,Yn)} (11) 本文采用LSTM建立能见度分类模型,其分类模型如图3所示。 图3 基于LSTM的能见度分类模型 该网络模型隐含层包含2个LSTM层和一个Dense层。采用堆叠的LSTM结构是为了防止过拟合,提高网络泛化能力。再通过Dense层可以了解特征数据与预测结果之间的函数关系。经过隐含层运算后得到该隐含层的输出hDt。网络的输出为能见度的类别,即: yt=softmax(Wyh·hDt+b) (12) 式中:Wyh为隐含层和输出层之间的权重矩阵;b为输出层的偏置量。 2.4.3回 归 基于LSTM的能见度回归模型,根据能见度的不同类别,分别训练了三种不同的回归模型用于三类能见度的回归。本文基于LSTM的能见度回归模型结构与分类模型的结构基本一致,输出层的激活函数采用Sigmoid,即第c类的网络输出为: yct=sigmoid(Wcyh·hcDt+bc) (13) 式中:c表示类别,c=0,1,2;Wcyh为c类回归模型隐含层和输出层之间的权重矩阵;hcDt为c类回归模型中经隐含层运算后得到该隐含层的输出;bc为c类回归模型输出层的偏置量;yct为回归出的c类能见度。 本次实验采用江苏省区域内气象站2018年的观测数据作为测试数据,去除缺失站点数据,总共样本为21 944个。分别进行了SVM模型、LSTM模型、引入相关性分析和引入下采样均衡数据四个实验,统计了分类结果的准确数、空报数和漏报数,计算了每种方法每个类别的TS评分。四个实验的对比结果如表5所示。表5中,准确数、空报数、漏报数及TS评分是本次实验结果的评价指标。准确数表示实际结果和预测结果同为c类的个数Right_c;空报数表示实际非c类预测为c类的个数Empty_c;漏报数表示实际为c类预测为非c类的个数Missing_c。c类的TS评分的计算公式为: (14) 表5 基于LSTM的能见度分类结果 表5中,方法1为SVM,方法2为LSTM,方法3为相关性分析及LSTM,方法4为相关性分析、数据均衡及LSTM。对比发现,相关性分析后,提取相关性较大的因子作为输入因子能够改善网络预测结果,但由于数据不均衡,效果还是不好。当通过下采样的方式进行数据均衡后,可明显看出效果提升,虽然1.5 km~10 km的准确率降低了,但是数据均衡后,1.5 km~10 km的训练样本大幅度减少,预报准确的个数肯定会有所下降,即漏报会增多,但同时会增加另外两类的准确数,从而均衡了三类的结果,提高整体的预测效果。尤其是在0~1.5 km的低能见度天气的预测上,TS准确率能达到0.29。 本次实验采用江苏省区域内气象站2018年的观测数据作为测试数据,去除缺失站点数据,总共样本为21 944个。分别进行了基于LSTM的能见度回归预测模型和基于LSTM的能见度分层预测模型两个实验,图4和图5是江苏省区域内某站点2017年的测试结果。 图4 站点1能见度两种方法测试结果 可以看出,当观测值为低能见度时,采用分类回归(分层)预测的结果与观测值更接近。同时,采用分类回归(分层)预测方法,对于能见度的峰值和谷值的预测结果更加准确。而采用直接回归方法预测在峰值和谷值处表现不佳,尤其是低能见度。 本文对江苏省区域所有站点2018年数据进行测试,统计了两种方法分类结果的TS评分及误差。两个实验的对比结果如表6所示。 可以看出,采用分层的方法在能见度0~1.5 km的预测准确率提升0.13,在大于10 km的预测准确率提升0.06,仅在1.5~10 km的区间内有所下降,这是因为分层预测模型提高了直接回归模型的泛化能力,一定程度上优化了0~1.5 km和大于10 km区间的预测准确率,牺牲了1.5~10 km的准确率。 采用分层预测方法在能见度0~1.5 km的误差比直接回归的结果降低了0.92 km,在大于10 km的误差降低了0.34 km。仅在1.5~10 km的区间内增大了0.56 km。可见,该方法一定程度上减小了预测的平均绝对误差,尤其在低能见度的表现上更好。 由于能见度的影响因素有多种,因气象场、排放源等因素的影响,传统模式预测能见度与实况存在较大误差,尤其是对低能见度的预测,准确率普遍不高。本文将传统气象统计预报方法与人工智能技术相结合,提出一种基于相关性分析和数据均衡的能见度分层预测模型,并通过实验得出以下结论: (1) 改进的能见度分层预测模型能够较好地拟合实际能见度,验证了本文方法的有效性。 (2) 改进的能见度分层预测模型改善了样本不均衡问题的影响,提高了模型的泛化能力,防止了模型过拟合现象对于能见度预测的不利影响,预测结果更接近实际能见度,具有更小的误差,有较高的应用价值。 该模型受神经网络机理的限制,尽管能够有效提高各个预报时效内的能见度均值,但对于能见度的峰值及谷值的预报,其准确性还有待提高,在进一步的研究中,考虑加入能见度空间特性及污染物浓度特征。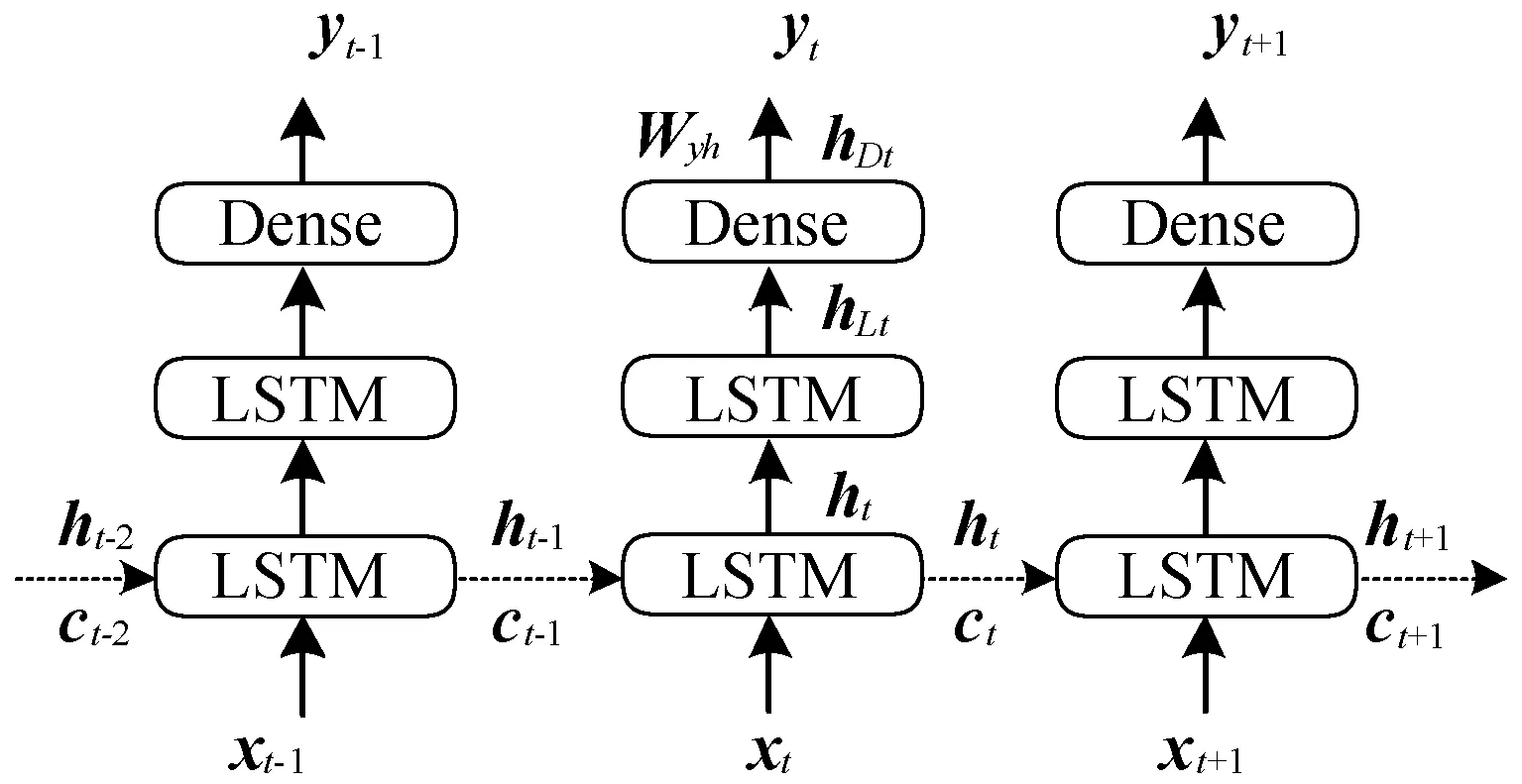
3 实验与结果分析
3.1 改进分类方法效果对比
3.2 回归与分类回归(分层)结果对比
4 结 语
猜你喜欢
赢未来(2019年15期)2019-08-14
华人时刊(2018年17期)2018-11-19
数学学习与研究(2018年7期)2018-05-16
科技创新与应用(2018年11期)2018-04-25
山东青年(2017年11期)2018-03-29
农业与技术(2017年13期)2017-08-23
数学学习与研究(2017年3期)2017-03-09
安徽农业科学(2016年4期)2016-10-21
计算技术与自动化(2014年1期)2014-12-12
现代农业科技(2009年19期)2009-03-20
