
基于YOLO网络的自主空中加油锥套识别方法
2022-09-09 13:22沈嘉禾袁冬莉杨征帆闫建国肖冰邢小军
西北工业大学学报 2022年4期
沈嘉禾, 袁冬莉, 杨征帆, 闫建国, 肖冰, 邢小军
(西北工业大学 自动化学院, 陕西 西安 710072)
随着国际形势的变化,空军力量成为一个国家国力的标志。在执行飞行任务途中,加油机可以使受油机在没有条件降落时补充燃油,世界各个强国纷纷使用空中加油技术(aerial refueling)加强自己空军力量的打击半径[1]。空中加油技术在过去几十年中,大都是高度依赖于飞行员的技术水平。随着无人技术的发展,自主空中加油技术[2]也成为了一种重要的战略部署方向。自主空中加油技术能够提高无人机远航航程以及作战半径,增加飞机的有效留空时间,提升飞机的有效载重,也可以辅助有人机飞行员进行复杂情况下的对接工作。基于我国国情,改装方便、技术简单的软式加油方法成为了主流选择,大量应用飞机上[3]。
在AAR中,判定锥套位置对加油活动十分重要。国内外研究者对锥套的运动机理做了许多探索和研究,一般采用有限元思想,将锥套软管看为质点系或者多连杆系统来建模。Pollini等[4]将软管划分为有限个数的规则柱体,使用经典力学进行建模;全权等[5]对软管-锥套式加油方法进行了建模和控制综述,对输油管使用连杆建模方法进行物理建模;刘志杰等[6]使用偏微分方法描述了一个分布式参数模型,对加油软管进行建模;Salehi等[7]在偏微分方程建模的基础上考虑了软管弯曲力的影响。尽管这些工作对锥套运动规律进行了物理建模,对识别锥套的位置规律做出了贡献,但其都是基于实验室条件下理想的数学模型,在复杂环境下不准确。
针对上述不足,识别真实锥套位置从而拟合锥套运动规律成为一种可能的研究路径。近些年来,目标识别(target recognition)方法成为从图片中获取信息以及规律的一种重要方法。目标识别的发展经历了许多阶段,最初使用人工设计特征,如HOG(histogram of oriented gradients)[8]、SHIFT(scale-invariant feature transform)[9]等。在使用滑动窗口时,会产生大量运算,时间和空间复杂度高,效果也不优异。针对这些问题,1943年神经科学家McCilloch等[10]发表的论文中提出MCP模型(McCulloch-Pitts mode),即神经网络和数学模型,开创了神经网络的先河。2012年,Krizhevsky等[11]提出了AlexNet方法,此后基于深度学习的目标识别方法大都参考经典的卷积网络方法。与此同时,深度学习在语音、图像、自然语言处理等方面都有广泛的应用[12]。
深度学习方法可以针对具体应用情景的不同,将训练数据中获取的深层、不可见的特征作为学习依据,与传统方法相比,能够自动生成特征并进行分类,泛化、鲁棒性更强,适合目标背景复杂、尺度多变的情况。目前主流的检测方法主要是TWO-STAGE(如R-CNN[13]、FastR-CNN[14])和ONE-STAGE方法(如YOLO[15]、SSD[16])。ONE-STAGE方法可以直接使用回归,得出目标物体的类别概率和位置坐标,速度快,但精度较低。TWO-STAGE方法先生成一系列候选框,再进行样本分类,速度慢,但是精度较高。2018年Redmon等发布了YOLO-v3[17]方法,该方法现已成为目标识别主流方法之一。该方法将目标检测问题转换为直接从图像中提取边界框和类别概率的单个回归问题,从而检测目标类别和位置。与文献[18]类似,一些学者也将目标识别方法应用在了空中加油任务中。李柱[19]提出了一种基于双目视觉的无人机自主空中加油近距离对接导航方法,获得锥套的位置与姿态,该方法使用了灰度化、二值分割等传统图像特征处理方法。徐小斌等[20]使用了基于深度学习的CNN方法获得加油锥套位置,对复杂环境下的锥套进行检测。然而之前基于深度学习的工作依赖于环境,且需要在GPU上进行训练和预测,计算量大,难以真正应用到实际活动中,有待进一步改进。
针对以上不足,本文拟提出一种新的基于YOLO的锥套识别方法,进一步减少计算量,并使其符合机载操作系统VxWorks的要求。与其他常规的典型网络相比,YOLO网络较小,速度较快,且有基于C语言的Darknet框架作为支撑。相比于解释型语言(如Python),C语言是编译型基础语言,更符合VxWorks系统的代码要求。本文在常规卷积神经网络模型以及YOLO算法的基础上,改变了anchor box、改进了网络内部结构、优化了损失函数,在提高识别率的同时,识别速度、网络大小均有一定的改良,为神经网络能够加载在普适性的硬件上提供了一种可行方案。
1 卷积神经网络理论
1.1 网络的基本结构
卷积神经网络通常由卷积层(convolutional layer),池化层(pooling layer)和全连接层(fully connected layer)交错组合而成,如图1所示。

图1 典型神经网络结构
其中,卷积处理是卷积层的核心,利用大小不一的卷积核就可以以不同的感受野去“读取”图像中隐含着的特征信息,学习数据特征;池化层增强了整个网络的非线性,寻找特征的关联;全连接层一般位于输出部分,目的是将一系列经过处理的数据进行分类与组合,以完成目标任务。
对于神经网络来说,感受野是十分重要的参数。在初始化处理时,一般会使用416×416或者512×512大小的输入图像。输入图片过小,则分辨率减小,对于小物体等目标的识别精度下降;输入图片过大,将导致运算需求猛增,对于性能优化有负面的影响。
1.2 YOLO网络的基本原理
与传统的特征提取与识别方法不同,神经网络学习到的特征更具有代表性,能够更好地区分目标物体与干扰项,鲁棒性好,对于干扰不敏感,泛化性更优异。网络的层级与能提取到的特征有关,层级越深,特征越抽象。YOLO算法将图片分为诸多窗口,当所识别的目标物体落入窗口内部时,该窗口输出多个预测框以及其置信度(confidence)和位置参数。
YOLO的骨架是Darknet网络结构,类似于VGG模型,但加入了残差网络,训练收敛比起VGG更快。作为特征融合的主要骨干,Darknet网络结构占用了许多内存,对硬件的计算能力提出了更严峻的挑战。
2 锥套图像识别卷积神经网络建模
现今存在的CNN网络纷繁复杂,但没有一种可以不经过优化直接应用到实践中去的。针对空中加油条件下锥套图像的识别,需要结合应用实际情况建立符合要求的神经网络模型。
特别地,小目标像素特征少、不明显,因此和大目标相比,小目标的检测率低,这在任何算法上都是无法避免的。对于卷积神经网络,检测小目标需要很高的分辨率,但即便如此,识别框仍然存在漂移。
针对锥套图片数据集所设计出的网络模型结构,为提高识别率在特征提取结构、识别模块和损失函数3个方面,做出了改进工作。下面对这三部分进行详细阐述,给出设计思想与实现方法。
2.1 网络模型的设计要求
网络模型在设计之初就要考虑到实用因素,现将对网络的要求进行汇总分析:
1) 硬件要求
本文选用TI TMS320C6678 DSP(digital signal processor)作为运算平台。虽然该型芯片是商用芯片,但其具有通用性强、可移植性高的特点,同时符合国军标对硬件芯片的性能要求。本文的实验属于神经网络布署于DSP的前瞻研究,若代码成功运行并达到预期要求,代码也可以移植到同类国产DSP芯片中。硬件平台如图2所示。

图2 TMS320C6678型号DSP硬件平台
由于该DSP缓冲区小,在运行过程中直接读取weights文件会导致卡死。DSP的文件读写操作只能在编程软件Debug模式下,需要与上位机进行通讯,在实际工作状态下难以进行该操作。为了解决该问题,需要将网络的结构参数、训练好的网络权重等一系列数据集成在代码内部。这种离线式的检测方法将代码直接烧录至DSP,避免了与上位机通讯,提升了运行速度。受限于硬件的计算能力,在保证识别进度的基础上需要尽可能地减少网络大小。在应用过程中避免使用很大的卷积核,倾向于使用较少的卷积核个数以及1×1,3×3,5×5大小的卷积核去提取特征。与此同时,使用池化层以增强非线性、减少网络参数。
使用C语言编写代码,内部实现逻辑如图3所示。图像输入后,经过预处理再输入经过参数固化后的YOLO网络,此时计时函数开始计时,网络经过非极大值抑制后输出锥套的检测位置。

图3 C语言逻辑示意图
2) 分类准确率和识别框准确率要求
网络最后的输出层输出5个参数,分别是Icof,x,y,w,h,分别代表识别结果的置信度、x方向坐标、y方向坐标、识别框宽度、识别框高度,这些参数在学习时遵循梯度下降和误差反向传播原则。要使网络能检出物体,就要使Icof至少大于网络设定的检出阈值;要使网络输出的位置精确,就需要x,y,w,h贴近真实框。影响这几个参数准确度的主要因素是:模型结构、anchor box基础值以及损失函数。本文基于以上要求提出了一种新模型,模型使用了新的预设框,并将原始的损失函数进行了优化。
2.2 特征识别模块改进
YOLO网络使用原始卷积网络输出层的全连接方法,利用回归方法来预测图像位置。由于网络本身的anchor box拟合锥套数据集效果不佳,使用聚类方法更改anchor box以减少识别框的漂移情况。使用该方法有以下几点考虑:
1) 针对锥套数据集的特殊情况,多尺度提取特征后特殊化的识别模块,可以提高识别精度。
2) 由于本文只需要识别一个目标物体,更改后对于干扰项有较好的分辨能力。
本文针对锥套图像数据集进行特化,将人工标注的近1 000张图片标注框的长宽进行处理分析,得到图4。不同尺度、不同角度下锥套的标注框位置存在一定的重合,这是由于锥套本身属于规范的漏斗状物体,直径一般在18 cm左右,根据机型的变化有一定的浮动。针对锥套特征,本文使用k-means++[21]聚类方法和训练集数据调整anchor box,减少网络误差,加快模型收敛,提高预测精度。

图4 人工标注框大小分析
图4分为2种图,一种是散点图,一种是柱状图,皆无量纲。散点图中每一个散点对应的坐标数字代表了一个标注框的长(宽)占原图片长(宽)的比例。由于图片大小为416×416像素,416乘以散点对应的x,y坐标即可得到长宽的像素个数。柱状图为直方图,横坐标为标注框的长(宽)占原图片长(宽)的比例,纵坐标为个数。分析人工标注框的大小,不难发现,宽落在[0.1,0.15]范围内、长落在[0.2,0.25]范围内的点最为密集。这种情况适用于k-means++聚类。使用该聚类方法进行聚类时,需要先确定邻近性度量SSE(sum of the squared errors)和计算簇的质心位置αi。
(1)
式中:ci代表被分到第i个类的所有点的集合;k代表共需分为几类,即聚类的簇总数,本文中k取10。经过100轮迭代,将经过归一化的聚类结果映射到416×416大小的输入图像上,得到网络新的anchor box示意图(见图5)及具体数值(见(2)式)。请注意,本节中使用的Aanchor值的单位是像素,如果输入图片大小不同,需要根据实际情况进行修改。Aanchor矩阵中,第一列代表预选框的长,第二列代表预选框的宽。在YOLO网络的预测过程中,会使用10个大小不同的anchor box进行识别,其长宽依照(2)式给出。
(2)

图5 网络新的anchor box示意图
2.3 网络结构改进
本文的目的之一就是维持精度不变的情况下,减少大量的计算量,网络更小。
网络内部的计算量大都来源于高维度的卷积核,加入1×1卷积核和池化层可以改善网络大小。与此同时,网络内部使用不同大小的feature map,可以对尺度变换做出更好的应答。
综合以上的设计思想和设计方法,最终设计的锥套图像识别卷积神经网络模型包括14个卷积层,4个池化层,输出部分有3个全连接层。
网络示意图如图6、表1所示,卷积模块右下角三角形代表池化层。竖向的箭头表示数据的传输方向,最终3个不同大小的特征图输入YOLO检测层。网络层内部存在route单元,可以进行特征层的融合。网络中不同大小的特征图会经过处理后,在网络内部进行融合,这样网络可以得到之前的信息,增加了训练的非线性。

图6 锥套图像识别网络结构示意图

表1 改进后的网络结构
训练完成的网络可以用于大、中、小3个尺度的预测,这是由于网络内部有3种不同大小的feature map,保证了识别多尺度目标物体时的精确度。
2.4 网络损失函数改进
YOLO本身的损失函数策略基于均方误差回归算法(mean square error,MSE),即如(3)式所示
(3)

(3)式等号右边第一项代表了预测框的中心坐标误差(x,y),第二项代表了预测框的长宽误差(w,h),使用了算术平方根,减小了框尺度大小对误差的影响,第三项和第四项代表了该框包含物体以及不包含物体时的置信度损失,第五项代表了该网格预测后类别损失。
本文中只识别空中加油的锥套一种物体,故第五项可以进行改进。将原来的类别损失改为GIOU[22](generalized intersection over union)损失,以改进网络预测框的IOU(intersection over union)。与此同时,将第二项的损失函数(即长宽误差)的权重进行更改,使网络更快地贴近真实值。GIOU函数改进了IOU方法,改善了在预测时网络的预测框如果没有与真实框进行重合时IOU会一直为0的问题。但GIOU无法表示方位,本文中将其作为损失函数的一部分参与运算而非直接作为损失函数。
如图7所示,令目标的真实框为A,网络预测框为B,C为包含A,B框的最小框,那么GIOU可以表示为
(4)

图7 GIOU示意图
本文使用的损失函数为
(5)
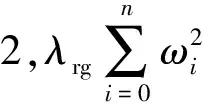
3 实验与分析
3.1 实验平台
硬件环境使用了Tesla K80作为GPU的工作站,操作系统为Windows,软件环境为python3.8+C语言,网络基于目标检测框架darknet以及YOLOv3网络进行构建并训练。训练以及预测的具体架构如图8所示。离线训练使用了Python方法,在线预测使用了C语言方法。

图8 训练、预测架构图
3.2 实验数据
空中加油目前主流仍是人工操作,缺乏一个统一、有公信力的锥套图像数据集。为了进行本文所述的表2改进模型与原始模型比较结果图像处理和识别工作,需要一定数量的图像结果作为数据支撑。本次训练和测试使用了1 000张锥套图像,分别来自于实验室锥套地面试验平台和网络视频截图。每一张图片都会经过前期的数据处理,如旋转、模糊、加噪声、改变色相等方法,以确保训练网络对干扰的鲁棒性。该数据集分辨率高、尺度多样、与航天应用场景有极高的相似度。

表2 改进模型与原始模型比较结果
3.3 实验内容
本次实验分别针对YOLO-v3、VGG+SSD-300、Inception-v3[23]以及改进后的new-YOLO 4种网络进行训练和预测,采用锥套图像数据集作为训练输入,对数据完整迭代3 000次,基础学习率为0.002,在训练至第1 500,2 400次时衰减至1/10。
将所有图片分为3组,按照4∶1∶1的比例随机分给训练集、测试集和验证集,保证图像数据尽可能少地暴露给测试集。
3.4 锥套图像识别结果
本次实验分别针对YOLO-v3、VGG+SSD-300、Inception-v3以及改进后的new-YOLO 4种网络在锥套测试集上进行测试,对检测结果进行处理,仅保留置信度大于阈值0.4的结果,并采用IOU阈值为0.5来计算平均精度和平均召回率,单位均为像素。表2展示了4种网络的浮点操作数BFLOPs,平均精度、平均召回率。可见本文提出的网络对比原YOLO-v3网络,检测精度和召回率分别提升了6.24%,2.06%,BFLOPs降低了93.81%。相比于Inception-v3,VGG+SSD-300,检测精度提升了14.46%,6.39%,召回率提升了10.33%,2.70%,BFLOPs降低了18.40%,86.84%。
改进后的new-YOLO在计算量减少了近94%的情况下,仍然有着优于典型网络6%的检测精度。由于网络准确率由IOU进行计算,IOU亦可以代表输出结果的漂移程度,故训练结果精度亦表明,网络识别结果的漂移情况也得到了一定改善。
在训练过程中,损失随着网络训练轮次的进行整体上迅速下降。经过3 000轮次的训练迭代,网络的损失函数趋于稳定。训练中损失函数最低为0.133 5,表明网络训练对目标图片数据集的识别与泛化能力好。
3.5 锥套图像测试结果
利用改进的算法对2个视频进行了测试,分别为实验室运行模型以及真实飞行视频数据,测试结果如图9所示。图9a)~9d)为实验平台图像,图9e)~9f)是真实对接过程的一帧。检测效果表示本文提出的基于YOLO算法的改进方法对锥套目标图像有着较好的检测效果。

图9 测试结果示意图
4 结 论
本文针对空中加油的锥套图像特点,提出了一种基于YOLO网络的空中加油锥套图像识别方法,在原本深度学习框架的基础上,实现了目标对象的有效识别。本文根据硬件实际情况,对网络结构进行了集成,使网络运行脱离上位机;为了提高检测精度以及检测速度,使用了k-means++算法聚类人工标注真实框的长宽,使网络内部检测层的anchor box更贴近真实情况,更容易达到精度要求;修改了网络内部结构,使用3层不同大小的feature map分别对应大、中、小3种尺度的待测物体,提高检测精度,减少计算量,降低对硬件的要求;对网络的损失函数进行了优化改进,使用了新的回归策略,进一步提高了检测效率和精确度。实验结果和测试结果表明,本文提出的new-YOLO算法相比于标准YOLO算法网络检测精度提升了约6%,计算量减少了近94%,且能够布署在DSP上运行,为空中加油的智能化奠定了基础。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
北京航空航天大学学报(2020年10期)2020-11-14
软件(2017年6期)2017-09-23
航空世界(2014年7期)2014-09-24
