
糖尿病肾病患者血浆细胞游离DNA中羟甲基化修饰lncRNA的筛选及其ceRNA调控网络构建
2022-09-21 02:56储金林马睿瑶铁璐李琳琳
山东医药 2022年26期
储金林,马睿瑶,铁璐,李琳琳
1新疆医科大学药学院,乌鲁木齐 830011;2北京大学基础医学院药理学系
糖尿病肾病(DKD)是终末期肾病的常见原因,是糖尿病的主要并发症之一,严重影响糖尿病患者的整体生活质量。细胞游离DNA(cfDNA)是由于不同组织细胞死亡而降解的DNA片段释放到血浆中,携带了起源细胞的遗传和表观遗传信息,检测血浆cfDNA可视为一种“液体活检”,有利于开展各种相关诊断,避免有创的组织活检[1]。5-羟甲基胞嘧啶(5hmC)主要是5-甲基胞嘧啶通过TET酶氧化形成,是活性DNA去甲基化相对稳定的中间体,被认为是重要的表观遗传特征[2]。研究表明,血浆cfDNA的5hmC谱是癌症及糖尿病等相关疾病早期检测和进展监测的有力工具[3-5]。长链非编码RNA(lncRNA)是在转录和转录后水平上通过调控各种机制,从而影响基因表达的重要因子[6-7]。有研究表明,lncRNA基因表达也可能受到表观DNA修饰的调控,如DNA甲基化和组蛋白修饰[8-9],而对编码lncRNA的基因组区域中潜在5hmC变化的研究较少。2021年2月—2022年2月,我们采用5hmC-Seal测序方法探讨DKD患者血浆cfDNA中编码lncRNA的基因组区域的关键5hmC改变,再进行lncRNA、miRNA和mRNA的调控网络分析,筛选可能的作用分子,为DKD的后续机制研究及诊疗策略奠定基础。
1 材料与方法
1.1 标本来源 收集北京大学第三医院收治的2型糖尿病(DM)患者14例,其中男9例、女5例,年龄31~62(47.9±6.9)岁;DKD患者17例,男9例、女8例,年龄32~77(51.1±16.7)岁。DM的诊断依据美国糖尿病协会(ADA)2020年发布的标准[10],DKD的诊断依据KDIGO 2020临床实践指南和2014年中国糖尿病学会糖尿病肾病防治共识[11]。本研究通过北京大学第三医院伦理委员会审批,受试者均知情同意。
1.2 方法
1.2.1 DKD患者血浆cfDNA的提取 采集DKD患者外周静脉血2 mL,4℃、1 350 g离心15 min分离血浆,取上清;4℃、13 500 g离心5 min去除白细胞,取上清。使用QIAamp循环核酸试剂盒(QIAGEN)提取血浆cfDNA。
1.2.2 DKD与DM患者血浆cfDNA中羟甲基化修饰差异表达基因的筛选 采用5hmC-Seal技术。通过Fragment Analyzer对每个文库样本的DNA条带大小及分布情况进行质控,在使用qPCR的方法对文库进行准确定量后,在NextSeq500测序平台上进行双端38-bp高通量测序,测序试剂盒为Illumina公司的Nextseq500/550 High Output Kit v2(75 cycles),每个样品的测序通量为1.5 Gb,测序条带大小为38 bp,最后得到文库中所有DNA片段的碱基序列。接着进行测序数据前期处理:先用Trimmomatic软件去除每个原始FASTQ数据一些低质量、无用的数据,来评估序列质量,提高后续分析的效率。用Bowtie2软件将原始reads数比对到人类hg19基因组上,并进一步用SAMtools进行筛选以保留与基因组的唯一非重复匹配,使用bedtools将对端读取进行扩展并转换为BedGraph格式,并将其归一化为对齐读取的总数量,然后使用UCSC基因组浏览器中的bedGraphToBigWig转换为bigwig格式,以便在Integrated Genomics Viewer中进行可视化。使用MACS识别潜在的5hmC富集区域,使用的参数为MACS14-p1e-3-f BAM-g hs。 使 用bedtools合 并 峰值,只保留出现在10个样本以上且小于1 000 bp的峰值区域。X和Y染色体内的5hmC富集区域被排除,并作为下游分析的输入。用DEseq2包找出差异基因,筛选条件为|log2FC|>0.5且FDR<0.05(FC为差异表达倍数,即DKD组与DM组差异表达倍数在1.5倍以上;FDR为校正后的P值)。
1.2.3 DKD患者血浆cfDNA中羟甲基化修饰lncRNA的筛选 采用加权基因共表达网络(WGCNA)程序的R语言包来构建差异羟甲基化基因的共表达网络。以拟合指数R2>0.6使得基因之间的连接服从近似无尺度网络分布,再绘制出模块和性状之间的相关性热图,以通过各个模块与性状之间的相关系数大小及P<0.05筛选出与DKD显著相关的基因模块,最后计算基因显著性(GS)和模块身份(MM),通过设置GS和MM的取值范围对network-Screening函数计算得到的基因列表进行筛选,从而识别和鉴定出关键枢纽基因,并从中筛选关键lncRNA进行后续分析。
1.2.4 羟甲基化修饰lncRNA细胞定位lncRNA在细胞中具有广泛的亚细胞分布,这决定了其功能调控的多样性,只有定位在细胞质中,才能形成ceRNA调控网络,从而为理解基因的作用机制提供研究方向。因此我们应用 lncLocator(http://www. csbio. sjtu.edu. cn/bioinf/lncLocator/)对 lncRNA 的亚细胞定位进行预测,寻找lncRNA所在的细胞位置。
1.2.5 靶向miRNA 的羟甲基化修饰lncRNA 筛选 Starbase 在线分析工具数据库主要对高通量测序的CLIP-Seq 测序分析数据和降解组测序分析数据的整合来寻找miRNA 的靶标,可为探讨miRNA的靶标提供可视化过程,该数据库包括大量miRNA-ncRNA、miRNA-mRNA、RBP-RNA 和RNA-RNA 的数据。因此,我们利用Starbase(http://starbase. sysu.edu.cn/)预测lncRNA的靶向miRNA。
1.2.6 羟甲基化修饰lncRNA 诊断价值及表达验证 对最终的关键lncRNA 进行受试者工作特征曲线(ROC)分析,若曲线下面积(AUC)≥0.8,则认为该基因具有较高的临床诊断价值。取SPF 级雄性C57BL/6 小鼠 9 只,8 周龄,体质量 20~22 g,购自北京华阜康生物科技股份有限公司,饲以蛋白含量为21%的标准饲料块,不限制饮水饮食。适应性饲养2 周后,将小鼠随机分成 DM 组、DKD 组和对照组各3 只,DM 组和 DKD 组连续 5 d 腹腔注射 60 mg/kg STZ,对照组腹腔注射柠檬酸钠缓冲液(pH 4.2~4.5)。96 h 后,断尾取血,测定血糖浓度,以血糖>16.7 mmol/L为DM造模成功。继续饲养16周,以空腹血糖>16.7 mmol/L,蛋白尿、尿素氮、血肌酐水平明显升高,为DKD 造模成功。取小鼠肾组织,-80 ℃保存。使用TRIzol 试剂提取肾组织总RNA,按试剂盒说明书进行RNA 逆转录,并进行扩增反应,目的基因的相对表达量用2-ΔΔCt法计算。
1.2.7 miRNA 靶基因的预测及功能富集 应用miRDB(https:/www. mirdb. org/)和 TargetScan(https://www.targetscan.org/)2 个在线数据库预测miRNA 的靶向 mRNA。此外,从 NCBI 的 GEO 数据库(Gene Expression Omnibus,https://www. ncbi.nlm.nih.gov/geo/)中下载 mRNA 转录组测序(RNA-seq)数据,数据编号为 GSE96804,使用相关 R 包找到差异基因(|log2FC|>0.5 且FDR<0.05)。将3 个数据库得到的靶基因取交集作为最后miRNA 靶基因集合。将靶向基因集提交Metascape(https://metascape.org/gp)网站,以P<0.05 为条件进行基因本体(GO)分析。
1.2.8 竞争内源性RNA(ceRNA)调控网络(即lncRNA-miRNA-mRNA 调控网络)的构建 mRNA、lncRNA 和circRNA 任意类型的两个RNA 分子间只要结合到相同的miRNA,就可能构成ceRNA 对,包括mRNA-mRNA、lncRNA-lncRNA、circRNA-circRNA。ceRNA 分析作为lncRNA 功能研究的一种方式,lncRNA-mRNA 共表达分析结果结合miRNA 靶基因数据集,基于筛选后竞争性吸附结合miRNA 进而调控靶mRNA表达的lncRNA-mRNA和circRNA-mRNA关系对,对lncRNA 的功能进行预测。我们使用Cytoscape(3.7.1版)绘制ceRNA网络,以确定ceRNA网络中的lncRNA在疾病中是否有关键作用,调控关键蛋白。
1.2.9 统计学方法 使用SPSS17.0 软件进行数据统计与分析,三组间比较采用单因素方差分析,组间两两比较采用t检验。P<0.05 为差异有统计学意义。使用Graph Prism 8.3.0 软件作图,使用R 语言版本4.1.0进行数据分析并生成图像。
2 结果
2.1 DKD 患者血浆cfDNA 中羟甲基化修饰差异表达基因的筛选结果 测序数据分析显示,与DM患者比较,DKD 患者的5hmC 整体分布水平明显降低。5hmC 主要在转录起始位点(TSS)和转录终止位点(TTS)内富集,在侧翼区域耗损(见OSID 码图1),说明5hmC 的累积与转录活性有关。以|log2FC|>0.5、FDR<0.05 为标准,获得 DKD 与 DM 的差异基因共1 644个。
2.2 DKD患者血浆cfDNA中羟甲基化修饰lncRNA的筛选结果 将获得的差异基因用于样本的聚类分析,表型热图分析结果见OSID 码图2A,无离群样本。计算DKD 基因间的邻接矩阵和拓扑矩阵,基于动态剪切树法把输入的差异基因分成3 个模块,分别用3 种颜色矩形表示,相似度高的基因被聚类到同种颜色的模块中,结果见OSID 码图2B。为了得到各个模块与临床表型之间的关系,我们对共表达模块与临床表型进行关联性分析,以相关性热图表示,结果见OSID 码图2C。结果显示与DKD 表型相关性最强的模块是蓝绿色模块(r=0.73,P<0.001),总体上与DKD 表型呈正相关。进一步将蓝绿色模块作为关键模块进行GS 和MM 分析,蓝绿色模块的GS 与 MM 的相关系数r=0.82,P<0.001,结果见OSID 码图 2D,最后通过对 GS 和 MM 设定条件,以GS>0.7,MM>0.9 的标准来筛选蓝绿色模块中与DKD 相关性高的关键枢纽基因。由于本研究主要分析和筛选关键羟甲基化修饰lncRNA,故最终获得15个lncRNA,见表1。
2.3 羟甲基化修饰lncRNA的亚细胞定位 为了分析这些差异lncRNA 是否参与ceRNA 竞争机制,利用lnclocater 网站对其亚细胞定位进行分析,结果显示,这15 个关键lncRNA 均定位于细胞质,大部分lncRNA 预测分数都大于0.8,结果见表1,说明对亚细胞定位的预测结果的准确性很高。
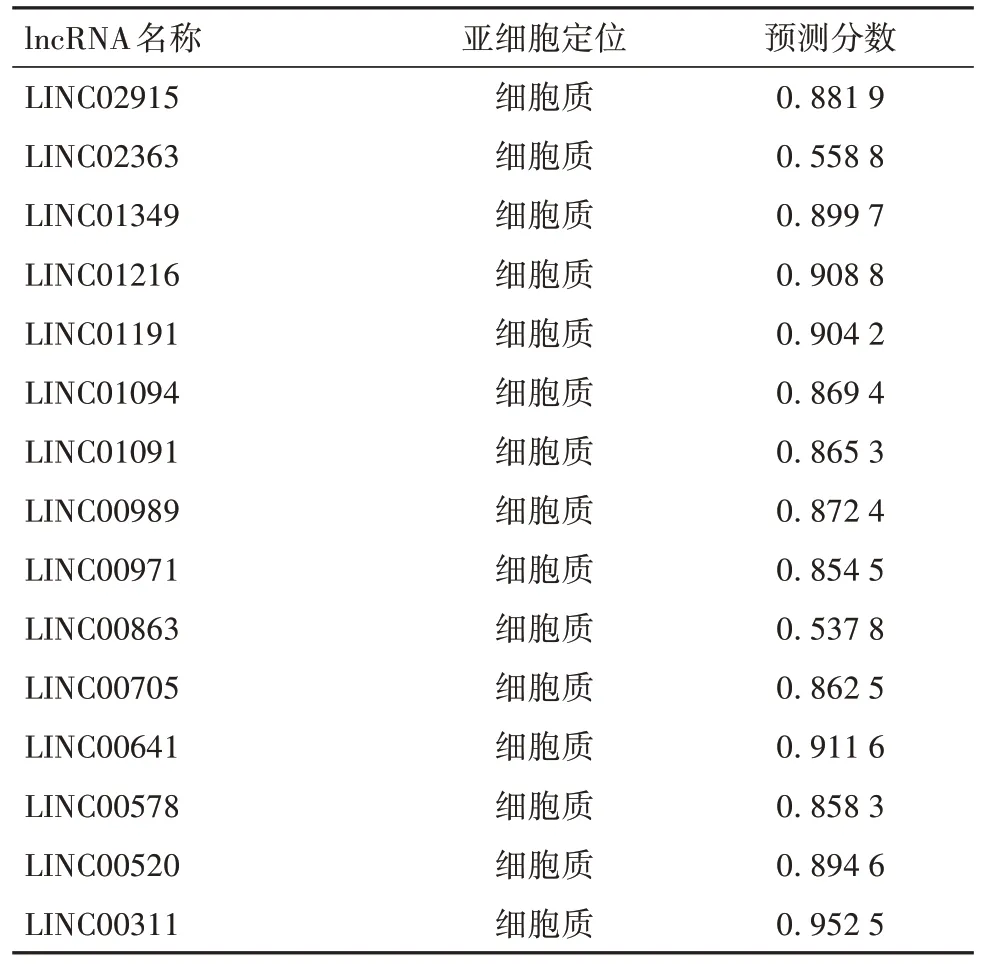
表1 羟甲基化修饰lncRNA的亚细胞定位
2.4 lncRNA 靶向miRNA 的预测结果 使用Starbase分析工具预测lncRNA的靶基因miRNA,发现只有2 个lncRNA 在数据库中有预测结果,分别是LINC00641和LINC00863。其羟甲基化水平见OSID码图 3 所示,与 DM 患者相比,DKD 患者的 2 个关键lncRNA 羟甲基化水平降低(P均<0.05)。接着以bioComplex>1 为筛选条件,LINC00641 的靶基因有12 个,分别为 hsa-miR-320b、hsa-miR-194-5p、hsamiR-320d、hsa-miR-539-5p、hsa-miR-320c、hsa-miR-153-3p、hsa-miR-378b、hsa-miR-425-5p、hsa-miR-378d、hsa-miR-378a-3p、hsa-miR-378h、hsa-miR-206。LINC00863 的靶基因为hsa-miR-218-5p。最终确定的2个关键lncRNA预测的靶基因共有13个。
2.5 羟甲基化修饰lncRNA 诊断价值及表达验证结果 对筛选得到的2 个关键lncRNA 进行ROC曲线分析,结果显示LINC00641 和LINC00863 在本数据集中诊断DKD 准确性均满足AUC≥0.8,具有较好的诊断价值,见OSID 码图4。与对照组和DM组 相 比 ,DKD 组 肾 组 织 LINC00863、LINC00641 mRNA 表达水平降低(P均<0.05),见表2。
表2 DKD小鼠肾组织中相关lncRNA的表达水平()

表2 DKD小鼠肾组织中相关lncRNA的表达水平()
注:与对照组相比,*P<0.05;与DM组相比,#P<0.05。
组别对照组DM组DKD组LINC00641 1.01±0.16 0.80±0.08 0.57±0.04**#n 3 3 3 LINC00863 1.00±0.16 0.92±0.14 0.66±0.06*#
2.6 miRNA 靶基因的筛选及功能富集结果 对DKD 肾组织转录组数据进行差异分析(|log2FC|>0.5,FDR<0.05),上调基因 1 259 个,下调基因1 386 个,见 DSID 码图 5A。使用数据库 miRDB 和TargetScan 分别预测上述13 个miRNA 的靶向mRNA,然后分别与DKD 转录组差异基因取交集、去重后,最终得到可在外部数据集中验证出的246个差异靶基因。对这246 个基因进行GO 富集分析,主要与泌尿生殖系统发育、肾脏发育、肾系统发育、肾上皮细胞及后肾的发育等生物学途径相关,见 DSID 码图 5B。
2.7 ceRNA 调控网络构建结果 将所得lncRNA、miRNA 与 mRNA 在 Cytoscape3.8.0 中绘制出 ceRNA网络,共246条通路,261个节点,259条边。见OSID码图6。
3 讨论
DKD 是一种由于DM 患者长期处于高血糖状态引起的慢性肾脏病,其发病机制复杂。研究显示,lncRNA 在多种慢性疾病的进展中起关键作用。动物实验显示,使用TGF-β1处理小鼠系膜细胞后,通过lncRNA 启动子和原癌基因Ets-1 的组蛋白乙酰化,miR-192 与其宿主 lncRNA CJ241444 共同调节,导致Smads 的富集和lncRNA 以及miR-192 的上调[12]。KATO 等[13]研究显示,具有 DKD 相关功能的关键miRNA(miR-216a和miR-217)由TGF-β1及其宿主lncRNA RP23-298H6.1-001 在系膜细胞中被诱导。其后续研究显示,lnc-megacluster(lnc-MGC)是miR-379 簇中近 40 个 miRNA 的 lncRNA 宿主,可在早期DKD 小鼠中促进系膜细胞的细胞外基质积累和肥大[14]。在 1 型和 2 型 DM 小鼠的肾小球以及暴露于高糖培养的小鼠系膜细胞中,lnc-MGC 及其几种驻留miRNA 表达增加,主要是TGF-β1通过涉及内质网应激相关转录因子CHOP(C/EBP 同源蛋白)的机制。因此,lnc-MGC 可以增加DKD 中的内质网应激,这反过来可能导致lnc-MGC 的持续表达,继续循环并可能有助于代谢记忆。值得注意的是,在暴露于高葡萄糖和TGF-β1下,人类系膜细胞中的lnc-MGC 直系同源物也会上调。这是个重要发现,因为与miRNA 不同,lncRNA 通常在物种间不太保守,这提示该lncRNA 簇可能与人类DKD 相关。此外,有研究报道,血浆cfDNA 携带了起源细胞的遗传和表观遗传信息[1]。所以,本研究基于人血浆来源cfDNA 的羟甲基化修饰lncRNA 在DKD 调控网络中进行初步探索。
本研究通过对DKD及DM 患者血浆cfDNA 进行5hmC 全基因组测序,结果显示整体5hmC 信号主要在 TSS 区域富集,RNA 的转录始于 TSS,并且 DM 与DKD 患者之间存在显著差异,表明这些区域在通过5hmC调节疾病基因(如lncRNA基因)表达中发挥关键作用。使用WGCNA 算法得到与DKD 相关编码lncRNA 的关键5hmC 标志物,用这种计算方法的优势是:以生物网络构建为基础,能够更加精准的展现生物学特性;可几乎覆盖到人类的所有编码基因;与已发表的研究偏倚性较小。该结果为后续疾病的深入研究提供了更广泛的理论基础。
此外,本研究通过亚细胞定位确定了15 个lncRNA 在细胞质中的表达,表明上述lncRNA 可通过ceRNA 机制调控基因表达参与DKD 的发病。Starbase 预测结果显示,相关lncRNA 可通过调控miRNA 从而影响DKD 中的基因表达,但我们发现只有2 个lncRNA 在Starbase 数据库中有预测结果,分别为 LINC00863 和 LINC00641,同时发现这 2 个lncRNA 的羟基化水平能很好的区分DKD 和DM。另外,在DKD小鼠肾脏组织中对这2个lncRNA的表达水平也得到了与预测一致的实验验证结果。因此,我们认为LINC00863 和LINC00641 很可能成为DKD 诊断的潜在生物标志物和治疗靶点。我们进一步对已在小鼠肾组织中得到有效验证的lncRNA,筛选得到下游调控miRNA,最后基于数据库预测上述miRNA 的靶向mRNA,为了得到较为准确的lncRNA-miRNA-mRNA 调控网络图,我们筛选与外部DKD 转录组数据集差异表达的靶向mRNA,得到具有一定可信度的ceRNA 调控网络图。但事实上ceRNA 目前还处于一个起步阶段,具体的研究案例比较少,本研究只是可视化构建了一个基本的网络,具体的调控方式还有待继续探究。另外,对于最终筛选得到的关键lncRNA文献报道较少,有研究表明LINC00641 过表达会抑制乳腺癌细胞增殖、迁移和侵袭,可通过海绵化miR-194-5p 抑制乳腺癌细胞增殖、迁移和侵袭[15]。
最后,基于Metascape网站对我们筛选出的基因进行GO 功能富集分析,结果显示,主要参与泌尿生殖系统发育和肾脏发育通路,说明持续高血糖的环境对于肾脏功能及结构会存在一定的不利影响,与DKD的发病机制息息相关。
综上所述,本研究基于临床样本数据,通过对DKD 及 DM 患者的血浆 cfDNA 进行 5hmC-Seal测序,发现了与DKD 相关编码lncRNA 的关键5hmC 标志物,构建了完整的ceRNA 调控网络,为DKD 分子机制的深入研究提供了严谨的数据支持。
猜你喜欢
中国人兽共患病学报(2022年9期)2022-10-19
现代临床医学(2022年4期)2022-09-29
昆明医科大学学报(2022年1期)2022-02-28
昆明医科大学学报(2021年4期)2021-07-23
科学导报(2021年29期)2021-06-03
中国生殖健康(2020年4期)2021-01-18
中学生物学(2020年10期)2020-12-25
康颐(2020年15期)2020-11-10
科海故事博览·下旬刊(2019年6期)2019-04-16
医学研究杂志(2015年9期)2015-07-01
