
基于影响度的统计显著序列模式挖掘算法
2022-09-25 08:42欧阳艾嘉张琳
计算机应用 2022年9期
吴 军,欧阳艾嘉,张琳
(遵义师范学院信息工程学院,贵州遵义 563006)
0 引言
数据挖掘技术能够从海量数据中提取有价值的信息,帮助人们理解数据并做出正确的决策。序列模式发现是数据挖掘领域中一个核心的研究任务,该任务的目标是找到序列记录集合中满足最小兴趣度阈值约束的模式[1]。这些序列模式中蕴藏着许多有价值的信息,因而研究人员将序列模式发现应用到了不同的领域中。例如,在移动网络中发现移动目标的行为规律[2]、在电子政务中向用户推荐相关服务[3]等。
目前,针对序列模式挖掘任务,人们提出了许多有效的算法[4-5],其中大部分算法使用了支持度作为序列模式的兴趣度度量方法,并将核心注意力放在了如何高效快速地挖掘满足约束的序列模式上,即探索高效的生成策略和剪枝方法。通过分析发现,这些算法存在两个问题。
第一个问题是这些算法使用的支持度是兴趣度最基础的度量方法,在一些情况下无法真实地体现模式的兴趣度,从而导致挖掘到的部分序列模式提供的信息是无价值的。具体而言,表1 展示了ATS(Adventures of Tom Sawyer)文本序列记录集合中支持度最大的5 个序列模式[6]。从表1 中可以看出:一方面,5 个序列模式均是由ATS 集合中支持度最大的项and、to 和of 组成,即便and、to 和of 不具备任何关联,它们重复和组合得到的序列模式也很有可能呈现较大的支持度,因此,依据支持度无法判断上述5 个序列模式是否真的有趣。另一方面和两个序列模式支持度相差不大,表明and 和to 两个项的顺序无关紧要,这与序列模式定义中顺序的重要性相违背,这两个模式不应该出现在最终的结果中。在以上两种情况中,支持度均无法真实地体现序列模式的兴趣度。

表1 ATS文本序列记录集合中支持度最大的5个序列模式Tab.1 Top-5 sequential patterns with largest degree of support in ATS dataset
第二个问题是这些算法没有对挖掘到的序列模式进行质量评估,导致结果中会存在大量的假阳性序列模式[7]。假阳性序列模式是随着数据随机波动产生的满足算法兴趣度约束的模式,这样的序列模式没有真实地反映序列记录集合的总体特征,因此,根据它们提供的错误信息做出的分析和决策会走向错误的方向,甚至可能造成重大的损失。
为了更为如实地度量序列模式的兴趣度并减少结果中的假阳性序列模式,本文提出了一个基于影响度的统计显著序列模式挖掘算法——ISSPM(Influence-based Significant Sequential Patterns Mining)。该算法针对支持度造成的兴趣度偏差问题,设计了一个新的兴趣度度量方法称为影响度。该影响度不仅考虑了序列模式包含的项的支持度造成的影响,还考虑了这些项之间的顺序特征。针对质量评估问题,ISSPM 算法引入了两个多重假设检验约束:错误率发现族(Family-Wise Error Rate,FWER)和伪发现 率(False Discovery Rate,FDR)[8],并提出了一个面向无类型标签序列记录集合的置换检验方法控制结果中假阳性序列模式的数量。真实序列记录集合和仿真序列记录集合中的实验结果表明,ISSPM 算法报告的统计显著序列模式不仅兴趣度更强,而且假阳性序列模式数量更少,从而这些模式提供的信息更有价值且更加可靠。
1 相关工作
模式发现算法按照面向的数据类型可以分为非序列模式挖掘算法和序列模式挖掘算法。在非序列模式挖掘任务中,文献[9]中通过构建并递归地挖掘频繁模式树得到频繁模式,该算法只需要扫描两次序列记录集合即可;文献[10]中采用前缀投影的思想,通过分治法将频繁模式挖掘工作划分为独立的任务实现了并行挖掘;其余非序列模式挖掘算法可以参考文献[11-12]。在序列模式挖掘任务中,为了减少候选序列模式的生成,文献[13]中提出了一个在投影数据中单个项支持度的计算方法,并采用深度优先的方式递归生成序列模式;文献[14]中使用回溯策略计算候选序列模式在网络树上的非重叠支持度,并且还设计了三种剪枝策略缩小搜索空间;其余序列模式挖掘算法可以参考文献[4-5]。非序列模式挖掘任务和序列模式挖掘任务的区别在于是否考虑项之间的顺序,因而序列模式挖掘任务通常更具有挑战性。
以上算法主要在模式挖掘效率方面进行了探索,除此之外,研究人员还将注意力投向了兴趣度度量方法的研究中。支持度是模式兴趣度最为基础的度量方法,除此以外,在支持度的基础上还定义了一些其他的度量方法,例如,置信度[15]、提升度[16]和杠杆率[17]等。置信度能够体现项集与项集之间的联系情况;提升度能够反映模式与包含项之间的独立程度;杠杆率能够弱化项对模式兴趣度的影响;但是,以上兴趣度度量方法均无法体现模式在不同类型记录集合中的分布差异。为了刻画这样的分布差异,又提出了成长率[18]和比值比[19]等兴趣度度量方法。成长率能够体现模式在不同类型记录集合中的绝对支持度占比情况,而比值比能够反映模式在不同类型记录集合中的相对支持度占比情况。通常而言,符合最小兴趣度约束的模式数量通常较多,为了降低结果的冗余程度,一些算法从模式集合的角度设计了全局兴趣度度量方法。例如,文献[20]中设计了覆盖率,覆盖率体现了模式与模式之间支持度的依赖情况;文献[21]中定义了最大子杠杆率,该度量方法考虑了子模式兴趣度的影响。关于不同兴趣度度量方法更为详细的对比和选择策略可以参考文献[22]。
近年来,为了减少结果中假阳性序列模式的数量,从而降低错误决策造成的损失,使用统计显著性检验评估挖掘到的模式质量成为模式发现任务中的热门研究问题。比如,文献[23]中引入标准置换检验构建零分布以过滤低质量的序列模式;文献[24]中提出了一个新的无条件检验,随后使用该检验计算模式的p值并根据该值返回统计显著的序列模式。更多的统计显著性检验评估方法可以参考文献[7]。
2 基本定义
2.1 序列模式

假设D={d1,d2,…,d|D|}是一个有限的序列记录的集合,其中每一条记录di是由C中的项构成。如果一个序列s是一条记录di的子序列,则称di包含s,表示为s⊆di。s在D中的覆盖数量指的是D中包含s的序列记录的数量,即cov(s,D)=| {di|di∈D∧s⊆di}|。s在D中的支持度被定义为D中包含s的序列记录的比例,即sup(s,D)=cov(s,D)/|D|。
兴趣度是衡量一个序列是否提供了有用信息的指标,其中,支持度是最为基础的兴趣度度量方法。具有兴趣度的序列被称为序列模式。由于单个项无法表现顺序特征,从而只考虑长度大于等于2 的序列模式。序列模式发现任务的目的是找到序列记录集合中满足最小兴趣度阈值θins约束的序列模式,这些满足约束的序列模式被认定为有趣的序列模式。
2.2 统计显著序列模式
研究发现,基于兴趣度约束的挖掘算法报告的结果中存在一定数量的假阳性序列模式,即这些序列模式满足约束的兴趣度是由于数据随机波动性造成的,因此,假阳性序列模式所反映的信息并不能够体现序列记录集合的真实特征。
统计显著性检验方法是常用的过滤假阳性序列模式的途径。该方法的步骤是:首先构建任务相关的零假设;其次定义并收集统计度量构建零分布;最后根据计算得到的统计显著性拒绝或者接受零假设。在序列模式发现任务中,零假设为序列模式在原始集合中的兴趣度与其在随机集合中兴趣度一致,即序列模式是由数据随机波动性产生的。依据该零假设,设计了统计度量和相应的收集方法,详细内容见3.1~3.3 节。在统计显著性检验中,每个被评估的序列模式s的统计显著性由一个p值度量,p值的定义是在随机集合中观察到比该模式的原始兴趣度值更大的兴趣度值的概率。p值越小表明该序列模式的统计显著性越强。
由于算法报告的序列模式通常很多,尤其是在兴趣度约束阈值设置得比较小时,不宜采用单重假设检验对序列模式进行逐一评估。多个序列模式被一同评估的情况被称作多重假设检验。错误率判断族和伪发现率被广泛应用于多重假设检验中约束假阳性结果数量的上限。其中,错误率判断族的定义是发现一个被错误拒绝的零假设的概率;伪发现率的定义是被错误拒绝的零假设占所有被拒绝的零假设的比例的期望值。通过统计显著性检验的序列模式被称为统计显著序列模式。统计显著序列模式发现任务的目标是运用多重假设检验找到在统计显著水平为θsig下统计显著的序列模式。
3 ISSPM算法
3.1 影响度
观察发现直接使用支持度作为序列模式的兴趣度度量方法会存在两个问题:
1)序列模式包含的项的支持度对其本身的支持度存在着较大影响;
2)序列模式的支持度无法体现包含的项的顺序特征。
因此支持度无法如实地度量某些模式的兴趣度。经过分析,解决第1 个问题的一种可行的策略是对序列模式的支持度进行修正。具体而言,给定一个序列模式s=如果构成s的各个项是互相独立的,那么由这些项构成s的支持度的期望值为:
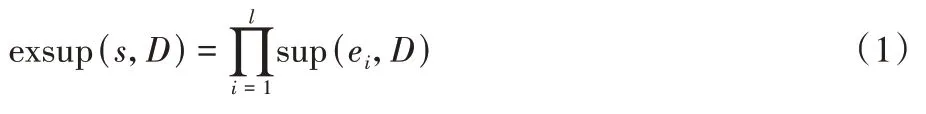
该期望值表达的含义是即使s的各个项之间不具备顺序联系,s也会有较大的概率在D中出现exsup(s,D) ×|D|次。因此,exsup(s,D)在一定程度上量化了各个项的支持度对序列模式本身支持度的影响,从而可以通过减去该影响得到s的修正支持度,即:

在问题2)中,给定两个序列模式sa=和sb=sa与sb的支持度均超过了最小兴趣度阈值θins且比较接近。虽然sa和sb的支持度均满足θins约束,但它们不应该被认定为有趣的序列模式,否则这样会导致c1和c2的顺序无关紧要。造成上述问题的原因是支持度本身没有考虑项的顺序特征。分析发现,大部分算法在得到一个长度大于等于2的序列模式时,都采用了两个子模式按照一定的规则拼接的方式。因此,一种可行的解决问题2)的策略是在忽略拼接规则的条件下计算两个子模式可能构成的序列模式的支持度以判断这些项的顺序是否重要。

其中:Gger表示ger(sa,sb)的结果集合,avg()表示Gger集合中序列模式支持度的平均值。上述inf()被称作s的影响度,其不仅考虑了s包含的项的支持度对s本身支持度的影响,也考虑了项之间的顺序特征。ISSPM 算法将采用影响度作为序列模式的兴趣度度量方法和统计度量方法。
3.2 项集置换
根据零假设的定义,生成的随机序列记录集合D'要和原始序列记录集合D保持特征的一致性,即保证D'中序列记录数量与D中相等;D'中序列记录的长度与D中相等;D'中每个项的出现频率与D中相等。如果D'没有满足上述要求,将会引入额外的误差。
标准置换方法是最简单的生成随机序列记录集合的方式。由于序列模式发现任务面向的原始序列记录集合不一定含有类型标签,从而无法通过直接交换类型标签的方式生成随机序列记录集合[25],因此,针对无类型标签序列记录集合设计了一种新的置换方法叫作项集置换方法,步骤如下:
1)计算出D中最短的序列记录长度lmin,并从1 到lmin随机选择一个整数α,该整数表示每条序列记录需要交换的项的数量。
2)生成一个序列记录编号的置换顺序,再为每条序列记录随机挑选α个不重复的项,并记录下这些项对应的位置。
3)针对每一条序列记录,将对应位置的项置换给置换顺序中相应的序列记录,置换的位置为该序列记录在第2)步中记录的位置。
例如,假定字母表C={c1,c2,…,c15},D由8 条序列记录构成,序列记录的最短长度为5,最长长度为9,详细情况见图1(a)。
第一步 假定从1~5 中随机选择的α为3,表示每条序列记录需要置换3 个项。
第二步 依据序列记录的编号,生成了一个随机的置换顺序为:d5,d3,d8,d7,d1,d2,d6,d4;再为每一条序列记录随机挑选3 个项,并记录这些项的位置。得到的结果为{d1:3,5,7},{d2:4,1,2},{d3:7,3,4},{d4:6,1,3},{d5:1,6,2},{d6:2,5,1},{d7:3,9,4},{d8:5,8,4}。
第三步 根据置换顺序和项的位置置换相应的项,具体而言,将d1的第3、5、7 位置对应的项置换到d5的第1、6、2 位置;将d2的第4、1、2 位置对应的项置换到d3的第7、3、4 位置;不断执行上述置换操作,直到将d8的第5、8、4 位置对应的项置换到d4的第6、1、3 位置就得到了一个随机序列记录集合D',如图1(b)所示。

图1 项集置换方法生成的随机序列记录集合Fig.1 Random sequential record dataset generated by itemset permuting method
由于项集置换方法没有生成新的序列记录,因此其生成的D'包含的序列记录数量与D中相等;此外,项集置换方法从每条序列记录中挑选的项数量一样,且保证了这些被挑选的项都被置换到了新的位置,因此其生成的D'中的序列记录长度和各个项的出现频率与D中相等。综上,项集置换方法满足一致性中的3 个要求。
3.3 假阳性结果约束
使用一定次数的项集置换方法可以生成多个不同的随机序列记录集合D',对每个D'实施挖掘能够得到一定数量有趣的序列模式,将这些有趣的序列模式的影响度存储在集合H中就完成了收集统计度量值的任务。为了减少收集统计度量值的计算开销,使用文献[7]中的一次挖掘技术。此外,考虑到不同长度序列模式之间共用零分布可能会产生一定程度的干扰,从而为不同长度的序列模式构建了不同的零分布nud(H,l)。
每个从D中挖掘得到的序列模式s的统计显著性由各自的p值量化。p值表示在给定零假设为真的前提下,从随机序列记录集合中发现一个至少和s的影响度一样大的序列模式的概率,s的p值计算公式如下:

为了严格控制假阳性序列模式的数量,ISSPM 算法使用了多重假设检验,即将同一长度的模式一同评估,并引入了Bonferroni 和Benjamini 校正来约束同一长度模式的错误率判断族和伪发现率[8],从而约束了假阳性序列模式的数量。具体而言,错误率判断族通过Bonferroni 校正的计算公式为:
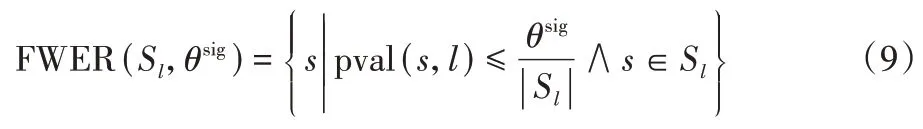
其中Sl表示D中长度为l的序列模式的集合。在使用Benjamini 校正约束伪发现率时,首先需要将Sl中的序列模式根据p值从小到大的顺序进行排序得到Sl',然后通过公式计算得到:
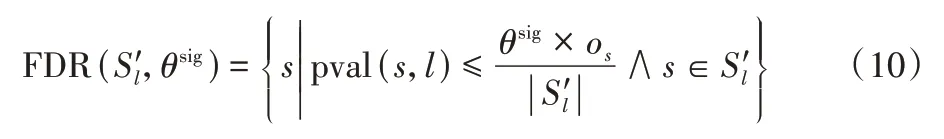
其中os表示s在S'l中的位置。通过式(9)和式(10)保留的序列模式就是统计显著序列模式。
3.4 算法过程
ISSPM 算法首先递归地以深度优先的方式挖掘满足最小兴趣度阈值约束的序列模式;随后,使用置换检验构建相应的零分布并计算出被评估模式的p值;最后,依据不同的多重假设检验约束返回各自的统计显著序列模式。详细的ISSPM 算法步骤见算法1。
算法1 ISSPM(D,C,θins,θsig,β)。
输入 序列记录集合D,字母表C,最小兴趣度阈值θins,统计显著水平θsig,置换次数β;
输出 统计显著序列模式的集合MFWER和MFDR。


其中,inf_mine()方法是从序列记录集合D中挖掘得到满足兴趣度约束θins的模式,其详细的步骤见算法2 和算法3;per_test()方法是使用项集置换方法构建零分布,并计算出被评估序列模式的p值,其详细的步骤见算法4;len_divi()方法是依据长度对序列模式进行分组。
算法2 inf_mine(D,C,θins)。
输入 序列记录集合D,字母表C,最小兴趣度阈值θins;
输出 满足兴趣度约束的有趣的序列模式集合G。

算法2 首先将原始序列记录集合转换成了垂直表示形式Dver,即将每条序列记录包含多个项的表示形式转换成每个项被哪几条序列记录所包含的表示形式(第1)步)。随后,过滤掉支持度小于θins的项(第2)~5)步)。接着,将挖掘过程中代表模式长度的变量l初始化为1;将挖掘过程中存储有趣的序列模式的集合G初始化为空集(第6)~7)步)。最后,通过递归地调用dep_mine()方法以深度优先的方式找到所有满足θins约束的序列模式(详细步骤见算法3),并将其返回(第8)~9)步)。
算法3 dep_mine(Q,θins,G,l,Dver)。
输入 用于拼接的模式集合Q,最小兴趣度阈值θins,存储有趣的序列模式集合G,拼接模式的长度l,垂直序列记录集合Dver;
输出 无。

算法3 首先将Q中每个非1 长度的序列模式放入G中,并引入Gcom集合来存储拼接后满足θins约束的序列模式(第1)~4)步);接着,使用pat_comb()方法对Q中模式进行两两拼接,拼接的条件是sa和sb模式l-1 个前缀项必须相同(第5)~6)步);然后,通过修正支持度zads和可能构成的模式集合Gger计算模式stmp的影响度zinf,如果zinf满足θins约束,便将其放入Gcom集合中(第7)~12)步);最后,如果Gcom集合不为空集,将递归地使用dep_mine()方法进行l+1 长度模式的拼接,直到找到所有影响度满足θins约束的有趣的序列模式(第13)~15)步)。
算法4 per_test(D,C,G,θins,β)。
输入 序列记录集合D,字母表C,有趣的序列模式集合G,最小兴趣度阈值θins,置换次数β;
输出 计算出p值的序列模式集合S。

算法4 详细的步骤描述如下:
1)利用len_divi()方法依据长度对序列模式进行分组,分组的目的是使不同长度的序列模式从不同的零分布中计算p值(第1)步)。
2)采用项集置换方法生成β个随机序列记录集合D',并从这些D'中收集统计度量值(第2)~9)步)。具体而言,首先利用num_sele()方法得到每条记录交换的项数量α;接着利用seq_gene()和ind_gene()方法生成随机置换顺序和每条序列记录需要交换的项的位置;然后利用ite_perm()方法依据置换顺序和项的位置进行置换得到D';最后利用inf_upda()方法更新序列模式在D'中的影响度,并将其保存在集合H中。
3)对于被评估的每组序列模式Gl,使用nud()方法为该组序列模式建立零分布Hl,再从该零分布计算出这组中每个序列模式的p值,最后将这些序列模式返回(第10)~14)步)。
分析ISSPM 算法的步骤,发现其时间复杂度主要由序列模式挖掘、置换检验和非统计显著模式过滤三部分构成。在挖掘部分中,找到满足θins约束的序列模式的算法使用了基于前缀树构建的策略,根据文献[13]的分析,其相应的时间复杂度为O(|D|(lmax)2),其中lmax表示D中最长的序列记录长度。在置换检验部分中,针对每一次置换,首先需要生成随机序列记录集合D',其相应的时间复杂度为O(α|D|);随后,使用了文献[7]中的一次挖掘技术直接更新了G中每个序列模式在D'中的影响度,即从前缀树的根以深度优先的方式递归更新每个节点的影响度,其相应的时间复杂度为O(|G||D|)。置换检验零分布的构建需要执行β次置换,因此序列模式置换检验部分的时间复杂度为O(β|D|(α+|G|))。在非统计显著模式过滤部分中,主要对|G|个模式分组并分别进行FEWR 和FDR 约束计算。FWER 和FDR 的计算开销为常数,故该部分的时间复杂度为O(|G|)。综上,ISSPM 算法总的时间复杂度为O(|D|(lmax)2+β|D|(α+|G|)+|G|)。
4 实验与结果分析
为了验证ISSPM 算法的性能,实验使用了4 个真实序列记录集合和10 个仿真序列记录集合作为实验数据,并对比了3 个高效的序列模式挖掘算法:PSPM(Prefix-projected Sequential Patterns Mining)[13]、SPDL(Sequential Patterns Discovering under Leverage)[17]和 PSDSP(Permutation Strategies for Discovering Sequential Patterns)[23]。其中:PSPM算法使用支持度作为兴趣度度量方法,SPDL 算法使用杠杆率作为兴趣度度量方法,PSDSP 算法不仅使用了支持度度量兴趣度还采用了置换检验评估序列模式的质量。实验中,置换检验的次数设置为1 000,所有算法均以Java 语言实现,实验设备为一台2.40 GHz CPU 和16 GB 内存的计算机设备。
4.1 真实序列记录集合实验
4.1.1 真实序列记录集合简介
4 个不同类型的真实序列记录集合分别为:Book、Unix、Peptide 和Bike:Book 是图书摘要文本的序列记录集合[21];Unix 是用户操作命令的序列记录集合[26];Peptide 是人类肽段的序列记录集合[27];Bike 是共享单车停靠站的序列记录集合[23]。详细信息如表2 所示。

表2 真实序列记录集合的信息Tab.2 Information of real-world sequential record datasets
4.1.2 真实序列记录集合实验结果
为了能够对比各个算法挖掘序列模式的能力,实验首先在相同的兴趣度约束θins和统计显著性水平θsig下运行了各个算法,然后统计了各个算法报告的模式中支持度超过一定数值的序列模式数量,实验结果见图2,其中ISSPMFWER表示ISSPM 算法使用FWER约束,ISSPMFDR表表示ISSPM算法使用FDR 约束。
从图2 可知,PSPM 算法在各个序列记录集合中报告的模式数量最多,其原因是PSPM 算法直接使用了支持度作为兴趣度约束,只要模式的支持度超过了最小兴趣度阈值,该模式就被认定为有趣的序列模式;由于SPDL 和PSDSP 算法在支持度的基础上分别使用了杠杆率和统计显著性检验约束,从而SPDL 和PSDSP 算法报告的模式数量比PSPM 算法少;ISSPMFWER和ISSPMFDR算法报告的模式数量最少,其原因包括两个方面:一方面,ISSPMFWER和ISSPMFDR算法使用了影响度作为兴趣度度量方法,影响度不仅考虑了项的支持度对模式本身支持度的影响,还考虑了模式包含的项之间的顺序特征,因此影响度相较于支持度约束性更强;另一方面,ISSPMFWER和ISSPMFDR算法还对挖掘结果进行了置换检验,通过FWER 和FDR 约束了假阳性序列模式的数量,从而又过滤了大量的假阳性序列模式。

图2 各个算法在真实序列记录集合上报告的序列模式数量Fig.2 Number of sequential patterns reported by each algorithm on real-world sequential record datasets
图2 中,PSDSP、ISSPMFWER和ISSPMFDR算法报告的模式数量少于PSPM 和SPDL 算法,这是因为PSPM 和SPDL 算法是基于兴趣度约束的算法,而PSDSP、ISSPMFWER和ISSPMFDR算法在兴趣度约束上还引入了统计显著性检验评估模式的质量。多重假设检验是对所有报告的模式进行约束,而不是单一地判断某个模式是否满足了约束,从而统计显著性检验的约束能力通常更强且结果更可靠。此外,ISSPMFWER算法报告的模式数量少于ISSPMFDR算法,其原因是在相同的统计显著水平下错误率判断族的约束能力强于伪发现率。
上述实验只是从各个算法报告的模式数量方面进行了讨论,由于真实序列记录集合中缺少真正有趣的序列模式信息,便无法直接判断哪个算法报告的结果中真正有趣的序列模式占比最多。为了间接对比各个算法的挖掘能力,提取了各个算法在Book 序列记录集合中报告的兴趣度值最大的7个2 长度序列模式,详细的结果见表3。
根据表3 中的信息可以看出PSPM 和PSDSP 算法结果相同,这是因为它们都使用了支持度作为兴趣度度量方法。观察这两个算法报告的结果发现7 个2 长度序列模式均由支持度最大的项algorithm、learn、data 和model 重复或组合而成,因此这些序列模式的支持度主要源自其包含的项,支持度并没有体现它们真实的兴趣度,从而导致这些序列模式提供了无意义的信息。

表3 各个算法在Book序列记录集合上报告的兴趣度最大的7个2长度的序列模式Tab.3 Top 7 2-length sequential patterns with the largest interestingness reported by each algorithm on Book dataset
SPDL 算法在表3 中的7 个模式虽然均不为algorithm、learn、data 和model 这4 个单词组 合,但其报告 的和序列模式具有相差不大的支持度,因此和algorithm,problem 序列模式均不应该被认定为有趣的序列模式。造成这个结果的原因是杠杆率没有体现项的顺序特征。
ISSPMFWER和ISSPMFDR算法计算兴趣度的方法相同,故表3 中使用ISSPM 算法表示其共同的结果。从这7 个序列模式可知两点:一是它们均不由algorithm、learn、data 和model 这4个单词共同组成;二是不存在诸如和这样项顺序置换的模式。这证明了ISSPM 算法使用的影响度不仅减弱了项的支持度对模式本身支持度的影响,还捕获了模式中项的顺序特征,更为真实地反映了序列模式的兴趣度。
综上,ISSPM 算法在真实序列记录集合中报告的序列模式数量更少且兴趣度更强,这些统计显著序列模式能更好地反映序列记录集合中有价值的信息。
4.2 仿真序列记录集合实验
4.2.1 仿真序列记录集合生成
由于真实序列记录集合中缺少真正有趣的序列模式的相关信息,接下来的实验采用人工嵌入有趣的序列模式的方式生成了仿真序列记录集合。详细的仿真序列记录集合生成步骤如下:
1)设字母表C={c1,c2,…,c60}包含60 个项,序列记录的最短长度lmin=8,最长长度lmax=16。
2)随机生成一个属于[lmin,lmax]的整数l*,并从字母表中随机有放回抽取l*个项。根据抽取顺序将这l*个项表示成一条序列记录。重复上述过程直到生成10 000 条序列记录。
3)从C*={c37,c38,…,c60}中随机挑选10 个不同的项构成5 个2 长度的序列模式,这些序列模式的支持度在[0.1,0.2]。接着,将这些序列模式按照相应的支持度随机嵌入到10 000 条序列记录中。为了不引入额外的干扰模式,一条序列记录至多只能嵌入一个2 长度序列模式。
4)用C*余下的项构成3 个3 长度和1 个4 长度序列模式,这些序列模式的支持度均在[0.1,0.2]。然后以第3)步中相同的方式将其嵌入序列记录中。
经过上述步骤生成的仿真序列记录集合中包含了人工嵌入的5 个2 长度模式、3 个3 长度模式和1 个4 长度模式,这9 个序列模式被认为是真正有趣的序列模式。在各个算法报告的序列模式中,如果某个序列模式的所有项均在C-C*集合中,那么该序列模式被认定为假阳性序列模式,因为其没有包含任何有用的信息;反之,如果某个序列模式含有C*集合中的项,该序列模式被认定为非假阳性序列模式。此外,为了避免偶然性,实验中生成了10 个仿真序列记录集合。
4.2.2 仿真序列记录集合实验结果
各个对比算法分别在相同的θins和θsig参数下对10 个仿真序列记录集合实施了序列模式挖掘。为了能够比较各个算法的挖掘能力,实验统计了每个算法报告的模式中支持度超过一定数值的序列模式情况,具体的信息见表4,其中对10 个仿真序列记录集合的结果取了平均值。

表4 各个算法在仿真序列记录集合上报告的非假阳性序列模式和假阳性序列模式的数量Tab.4 Number of non-false positive patterns and false positive patterns reported by each algorithm on synthetic sequential pattern datasets
根据表4 的统计信息可以看出,PSPM 和SPDL 算法报告的序列模式中假阳性序列模式的数量占比达到了78%以上。导致这个情况的原因是PSPM 和SPDL 算法是纯粹基于兴趣度约束的算法,只要序列模式满足了约束,就会被认定为有趣的序列模式,没有考虑这些序列模式可能是因为数据的随机性导致的;而PSDSP、ISSPMFWER和ISSPMFDR算法均使用了置换检验对报告的模式进行评估,过滤了大量的假阳性序列模式。
PSDSP 和ISSPMFDR算法均用了伪发现率作为假阳性序列模式数量的约束,但PSDSP 算法的结果中假阳性序列模式数量占比为4.51%,而ISSPMFDR算法的结果中假阳性序列模式数量占比为3.39%。其原因有两点:一是PSDSP 算法使用的置换方法不满足一致性要求,引入了额外的误差;二是ISSPMFDR算法使用的影响度减弱了项的支持度对模式本身支持度的影响,从而过滤了少量的假阳性序列模式。此外,ISSPMFWER算法的结果中假阳性序列模式数量占比为0.93%,这再次验证了错误率发现族约束能力强于伪发现率,但ISSPMFWER算法报告的非假阳性序列模式数量也少于ISSPMFDR算法。当错误决策会造成相当严重的后果时,应当考虑使用ISSPMFWER算法,否则可以选择ISSPMFDR算法保留更多有价值的信息。
除了统计每个算法报告的序列模式数量外,实验还分析了每个算法在10 个仿真序列记录集中报告的兴趣度最大的20 个模式中嵌入序列模式的发现率,具体的结果见表5。根据表5 能够发现,PSPM 和PSDSP 算法发现嵌入序列模式的数量最少。造成这个结果的原因是支持度排名前列的单个项重复或者组合形成的2 长度序列模式拥有非常大的支持度,从而导致嵌入序列模式的支持度未能排进前20。甚至如果θins设置得较大,嵌入序列模式很可能不会出现在这两个算法报告的结果中,这再次说明支持度没有如实地表达这些模式的兴趣度。
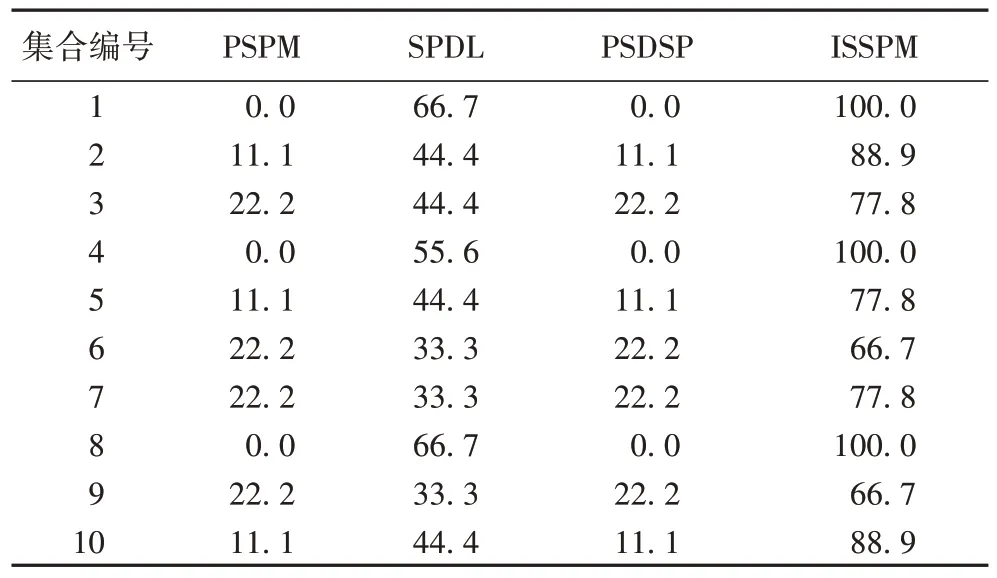
表5 各个算法在仿真序列记录集合上嵌入模式的发现率 单位:%Tab.5 Embedded patterns discovery rate reported by each algorithm on synthetic sequential pattern datasets unit:%
SPDL 算法报告的嵌入模式数量不及ISSPM 算法,这是因为SPDL 算法虽然考虑了模式包含项的影响,但忽略了项之间的顺序特征,从而导致一些项相同但顺序不同的2 长度序列模式出现在结果中;ISSPM 算法使用的影响度,既考虑了模式包含项的支持度的影响,又考虑了这些项的顺序特征,因此更为真实地反映了序列模式的兴趣度,结果中嵌入模式的发现率最高。ISSPM 算法在某几个仿真序列记录集合中未能发现所有的嵌入序列模式,造成这个结果的主要原因是ISSPM 算法允许一个序列模式的子模式也成为有趣的序列模式。在这几个仿真序列记录集合中,嵌入的3 长度和4 长度序列模式的子模式也表现出了很高的兴趣度,从而导致某些嵌入的2 长度序列模式的兴趣度没有排进前20,但值得注意的是这些子模式也包含了真实有用的信息。
接下来的实验对比了各个算法在10 个仿真序列记录集合中的平均运行时间,详细的实验结果见表6。

表6 各个算法在仿真序列记录集合上的平均运行时间 单位:sTab.6 Average running time of each algorithm on synthetic sequential pattern datasets unit:s
从表6 中可知,PSPM 和SPDL 算法在挖掘阶段的时间多于PSDSP 和ISSPM 算法,这是因为PSPM 和SPDL 算法使用的逐层通用序列模式挖掘算法计算开销高于PSDSP 和ISSPM算法使用的树形垂直序列模式挖掘算法。由于ISSPM 算法在挖掘过程中需要计算两个模式可能构成的序列模式的修正支持度,故计算开销大于PSDSP 算法,但也在可接受的时间范围之内。在评估阶段,PSDSP 和ISSPM 算法分别使用了不同的置换检验方法评估挖掘到的序列模式质量,但PSDSP算法的运行时间远远高于ISSPM 算法,根本原因是PSDSP 算法生成随机序列记录集合后需要对该集合进行挖掘以提取相应的支持度来构建零分布,而ISSPM 算法使用的一次挖掘技术在生成随机序列记录集合后仅需要更新相应序列模式的影响度即可。由于挖掘过程的计算开销非常大,导致大幅增加了PSDSP 算法的运行时间。
综上,ISSPM 算法在仿真序列记录集合中报告的统计显著序列模式不仅兴趣度更强,并且假阳性序列模式的占比更少,运行时间相较于使用了不同置换检验方法的PSDSP 算法更少。
5 结语
为了能够更真实地度量序列模式的兴趣度并提升挖掘结果的质量,提出了一个使用影响度的挖掘算法——ISSPM算法。该算法在挖掘过程中不仅考虑了模式包含的项的支持度对模式本身支持度的影响,还考虑了这些项之间的顺序特征;此外,ISSPM 算法还设计了一个基于项集置换的置换检验方法过滤假阳性序列模式。实验使用了真实序列记录集合和仿真序列记录集合,实验结果表明,ISSPM 算法相较于PSPM、SPDL 和PSDSP 算法不仅能够找到兴趣度更强的序列模式,还能够过滤大量的假阳性序列模式,因此,ISSPM 算法报告的统计显著序列模式提供的信息更有价值且更加可靠。实验过程中发现ISSPM 算法的计算开销较大,仔细分析这些计算开销主要源自两个方面:随机序列记录集合的生成和序列模式影响度的更新。未来工作将从模式发现算法并行化的角度出发降低ISSPM 算法的运行时间;ISSPM 算法允许超模式和子模式同时成为有趣的序列模式,导致某些超模式与子模式有可能提供了重复的信息,因此同时保存它们会造成不必要的资源浪费,后续工作也会研究如何判定统计显著序列模式的冗余性,并提出相关的冗余模式过滤算法;此外,还会尝试将三支决策应用到统计显著序列模式挖掘中,以发现更多的高质量模式。
猜你喜欢
中国临床新医学(2022年6期)2022-11-15
大众科学(2022年7期)2022-08-19
上海文化(文化研究)(2022年3期)2022-06-28
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
英美文学研究论丛(2018年2期)2018-08-27
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
小学阅读指南·低年级版(2017年1期)2017-03-13
计算机辅助工程(2012年5期)2012-11-21
祝您健康(1993年3期)1993-12-30
