
基于多阶段演化信号博弈模型的移动目标防御决策算法
2022-09-25 08:42毕文婷林海涛张立群
计算机应用 2022年9期
毕文婷,林海涛,张立群
(海军工程大学电子工程学院,武汉 430033)
0 引言
近年来,随着人工智能、大数据、5G 通信等新兴技术的发展,互联网面临的威胁日益增加。随着当前生产和生活对网络依赖性的增强,网络攻击的数量仍在不断攀升且类型也越来越多样化[1]。传统静态被动防御手段如入侵检测系统(Intrusion Detection System,IDS)、入侵防御系统(Intrusion Prevention System,IPS)等在面对各种潜在不可预知的攻击时略显不足,因此需要一种能够对攻防行为进行分析且对防御策略进行选取的技术,从而实施主动防御。
博弈论[2-3]是一种研究在一定的条件和规则制约下,对局双方根据有限的信息和自身倾向行为进行策略选择的理论方法。攻防双方依靠所掌握的信息进而选取最优的攻防策略恰好是网络攻防对抗的思想。因此,网络攻防对抗的本质与博弈论特点相吻合,将博弈论思想应用到网络安全防御中,为网络攻防环境下防御策略选取的安全问题提供了新的思路。
移动目标防御(Moving Target Defense,MTD)是由美国国家科学技术委员会于2011 发布的《可信网络空间:联邦网络安全研发战略规划》中作为“改变游戏规则”的动态主动防御技术提出的[4]。作为一种新的主动防御思想,MTD 主要通过部署多样化的动态机制和策略,从而降低系统的同构性、静态性和确定性,使攻击者的攻击难度和成本大幅提升,直至放弃攻击。随着网络攻击手段越来越复杂多变,将MTD应用于防御策略选择中对维护网络空间安全具有重要意义。
近年来,国内外已有学者开始了相关技术研究。Lye等[5]提出了完全信息静态博弈模型分析攻击者和防御者的最优策略及纳什均衡,但攻防收益函数量化过于简单;林旺群等[6]构建了一种完全信息动态博弈主动防御模型,并将攻防分析模式由网络攻击图转换为网络博弈树,但该模型并没有给出详细的策略选取算法;文献[7]中基于完全信息非合作零和博弈建立了一个矩阵型攻防博弈模型,并设计了相应的策略选取算法,但删掉其静态模型的限制不能有效应用于动态对抗场景;王元卓等[8]建立了Petri 网的完全信息博弈模型并进行网络安全评估,但由于博弈双方的收益情况并不是互相透明公开的,所以完全信息假设前提不满足实际网络的攻防情况。针对上述问题,部分学者开始引入不完全信息博弈理论,例如:Baras 等[9]提出了利用不完全信息的重复博弈理论寻找非法节点;王增光等[10]基于军事信息网络背景,提出了不完全信息博弈攻防决策方法;弭乾坤等[11]构建了用于网络系统风险评估的不完全信息博弈模型;Lei 等[12]提出了一种基于移动目标防御的不完全信息攻防Markov 博弈决策模型,通过纳什均衡求解实现最优策略抉择;文献[22]中利用信号博弈构建了移动目标防御决策模型,增强了网络防御效能。上述研究都是基于攻击者和防御者都是完全理性的,博弈双方都知道如何实现他们的收益最大化,然而在实际网络的攻防行为中,各种其他因素也可能会影响双方的决策,因此忽视有限理性可能会导致攻防行为建模与分析出现偏差,影响最优防御策略选择方法的科学性和指导性。
综上所述,博弈论和MTD 在网络安全领域的应用已经初见成效[13-16],但还缺乏系统化的理论研究方法。为突破这一局限性,本文将MTD 策略与博弈论相结合,提出一种动态演化信号博弈模型,以防御方主动发出诱导信号对攻击方进行战略干扰,从而达到主动防御目的。其次,博弈双方通过学习和进化机制进行重复博弈突破了传统博弈有限理性约束,本文利用复制动态方程分析多种攻击方式下攻防双方策略的演化趋势,并贴合网络攻防实际将单阶段博弈状态拓展至多阶段博弈,设计了多阶段演化信号博弈模型的移动目标防御决策算法,为网络安全防御决策提供一定指导作用。
1 移动目标防御原理
MTD 技术是美国高度重视的“改变游戏规则”的网络空间革命性技术之一。与传统网络安全研究思路不同,MTD的思路是通过构建动态的、异构的、不确定的网络以增加攻击者的攻击难度及代价,以这种不断变化的部署机制增加了系统的随机性,提高了系统弹性,减少了攻击机会。MTD 技术反映了美军将静态的“死”网络改造成变化的“活”网络的下一代网络安全防御发展模式,因此MTD 相较于传统防御技术的优势相当明显。
2 多阶段演化信号博弈模型
2.1 博弈顺序
初始阶段,防御者拥有对攻击者类型的先验知识,防御者先释放最佳诱导信号,信号类型与防御者类型相对应,防御者可以自主选择发送真实正常信号或虚假信号,发送诱导信号的原理是通过部署蜜罐系统,将服务方部署成蜜罐和服务器两种类型,利用蜜罐发送虚假信号对攻击者进行欺骗,攻击者根据扫描收集的网络拓扑和防御方的系统信息(诱导信号)选择最佳攻击策略并实施,同时防御者实施最佳防御策略。博弈流程如图1 所示。
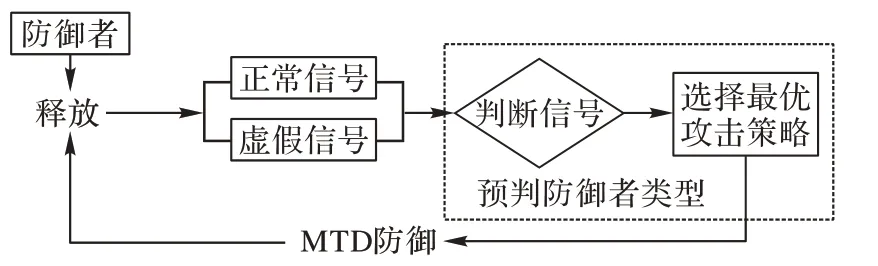
图1 博弈流程Fig.1 Flowchart of game
防御者与攻击者的博弈顺序为:
1)“自然”选择一种防御者类型,防御者主动释放干扰信号。
2)攻击者检测到防御信号,并判断信号类型。
3)攻击者结合拥有的防御者类型先验概念,选择最优攻击策略,并更新对防御者类型后验概率判断。
4)防御者观察到攻击行为后,选择最优MTD 策略进行防御。
5)循环以上过程,直至攻击结束。
2.2 多阶段演化信号博弈模型定义
定义1多阶段演化信号博弈模型(Muti-Stage Evolutionary Signal Game Model,MSESGM)可以表示为13元组:
1)N={NA,ND}为博弈的参与者集合,其中NA为攻击者,ND为防御者。
2)T={TA,TD}为博弈的参与者类型集合,其中TA={A1}为攻击者总体的类型集合,TD={D1,D2,…,Dn}为防御者总体的类型集合,且n∈N+(n≥2),n为防御者类型总数。
3)λ为段信号博弈的博弈阶段总数,G(k)当前博弈阶段为k={1,2,…,λ}。
4)SI={SI1,SI2,…,SIγ}为信号策略集合,防御方可根据情况选择真假信号发送,实现对攻击方的诱导作用。

6)Pk={pk(Dj)|j=1,2,…,n}为博弈中攻击方对防御方的先验信念集合,其中每一阶段的先验概率来自于上一博弈阶段的后验概率。
7)={(Dj|SIσ)|j=1,2,…,n;σ=1,2,…,γ}为 攻击方对防御方的后验信念集合,其中(Dj|SIσ)表示第k阶段攻击方接收到防御方发送的诱导信号SIσ时Dj攻击方概率的后验判断。
8)S={S1,S2,…,Sλ}表示各个子博弈的状态集合。

11)ρ(0 ≤ρ≤1)为贴现系数,表示未来收益较当前阶段收益的折现比例。
12)μ为状态转移概率,μij(Sj|Si)表示系统状态从Si到Sj的概率。

2.3 多阶段演化信号博弈模型分析
MTD 技术通过不断转移攻击面从而增加网络弹性,使攻击者无法有效攻击目标资源达到防御目的。信号博弈是研究如何利用信号来干扰对手判断从而影响博弈均衡的博弈理论。在多阶段进化信号博弈模型中,每一个博弈阶段中博弈系统经过动态攻防对抗达到博弈稳定状态,但是网络环境不是一成不变的,随着系统运行环境及攻击目的改变等因素,维持现有的防御策略已经不能达到预期效果,导致稳定状态打破。此时,将上一阶段后验概率作为下一阶段攻击者类型的先验概率进入下一新阶段的信号博弈。经过演化达到稳定状态后,根据稳定数值利用贝叶斯法则求解后验概率:若新阶段先验概率与后验概率一致则求得的稳定状态才是有效的;否则先验概率是不准确的,会造成结果误差,故需调整先验概率。本文引入马尔可夫决策过程(Markov Decision Process,MDP),利用不同阶段网络状态的随机跳变,构建了多阶段演化信号博弈模型对MTD 攻防行为和防御决策进行分析。
2.4 收益量化
攻防双方的收益量化是决策算法中最关键的部分。量化方法越贴近真实攻防场景对防御决策的指导性越高,但目前学术界并未对攻防收益量化进行统一化标准制定。
网络攻击的目的就是对目标网络造成破坏甚至摧毁,使正常的目标环境网络无法工作。网络安全则要保障目标网络的保密性、完整性、可用性和可靠性。参考文献[17],本文量化定义如下:
定义2攻击成本(Attack Cost,AC):指发起攻击行为所付出的代价,包括信息搜集、软硬件资源和操作成本等。
定义3攻击收益(Attack Earnings,AE):指攻击成功时,攻击方获得的好处。攻击收益由直接收益和间接收益两部分组成:直接受益指对目标网络系统的安全属性造成破坏获得的直接回报;间接收益指对发起下一步攻击目标获得的间接经验回报。
定义4诱导信号成本(Signal Cost,SC):指防御方发送诱导信号迷惑攻击方所付出的代价。
定义5防御成本(Defense Cost,DC):指防御方实行防御行动进行资源保护所付出的代价。
定义6防御收益(Defense Earnings,DE):指保障目标网络的安全属性的价值获得的回报。攻击收益由直接收益和间接收益两部分组成。直接收益指防御方成功保护网络资源避免的损失,间接收益指在攻防对抗中获得攻击方的相关知识提高防御成功率的间接收益。
定义7系统损失(System Damage Cost,SYC):指攻击行为对目标网络系统造成的损失。攻击的目标资产损失可以用攻击致命度(Attack Lethality,AL)、危险度(Criticality)、安全属性损害(Safety Damage Cost,SDC)来描述。本文采取DMAT(Defense-oriented Multidimensional Attack Taxonmoy)方法以攻击目的分类赋予致命度数值,如表1 所示,攻击致命度越高,资产受到攻击时系统损失也越大。安全属性损害由资产完整性、机密性和可用性3 个因素量化。

表1 攻击致命度Tab.1 Attack lethality
综上所述,系统损失计算方法如下:

其中:i表示主机编号,m表示受攻击主机个数。

表2 符号及其含义Tab.2 Symbols and their meanings
基于上述定义,攻击者在攻防博弈中的攻击收益为:

则在攻防博弈中的攻击收益为:

2.5 均衡求解
由于网络攻防对抗过程中存在信号衰减等一系列噪声影响,下一阶段收益也会相应衰减。故本文引入贴现预期收益准则函数来获取实际收益值,即:

引入复制动态方程求解多阶段博弈均衡:
1)防御者释放诱导信号,攻击方选取最优攻击策略。
第k阶段防御方发送的诱导信号为SIσ时,攻击收益(SIσ):

则k阶段期望收益为:

构建复制动态方程:

得到k阶段不同诱导信号下的最优攻击策略概率分布(AS)。
2)判断攻击方选择的最佳攻击策略,防御方选取最优诱导信号。
第k阶段防御类型为Dj时,防御收益:

则期望防御收益为:

构建复制动态方程:

得到k阶段不同防御方的最优诱导信号防御策略概率分布(SI)。
3)根据上述所求均衡解及贝叶斯法则求解对防御方判断的后验概率:

3 算法分析
算法1 基于多阶段演化信号博弈模型的移动目标防御决策算法。
输入 多阶段马尔可夫进化信号博弈模型(MSESGM)参数。
输出(SI)。

分析上述过程发现,步骤7)、9)和10)体现了算法时间复杂度。步骤7)主要是收益量化值的计算,此过程的时间复杂度为O(λ);在步骤9)、10)的纳什均衡求解上,整个算法的时间复杂度为O(λ(γ+n))。收益量化值和均衡计算的中间值是整个算法的主要存储对象,收益值的存储量占比是最大的,总共包含了数量为λ(γ+n)的存储单元,因此,此算法的空间复杂度为O(λγn)。将本文算法与其他算法进行比较,结果如表3 所示。

表3 不同算法的博弈属性比较Tab.3 Game properties comparison of different algorithms
4 实验仿真及分析
4.1 网络攻防仿真
通过构建一个简单的信息网络系统进行仿真实验来验证本文算法的可行性。网络系统的拓扑如图2 所示。本系统主要由安全防御设备、Web 服务器、FTP(File Transfer Protocol)服务器、应用服务器、数据库服务器、文件服务器、堡垒机等构成,并通过防火墙进行隔离,外来主机只能访问隔离区域,无法对内部网络进行访问,隔离区服务器可以访问内部网络节点,且内部网络节点可以相互访问,因此,攻击者只能通过攻击隔离区域Web 服务器获取权限,进行多步攻击,完成破坏数据库服务器的目的。
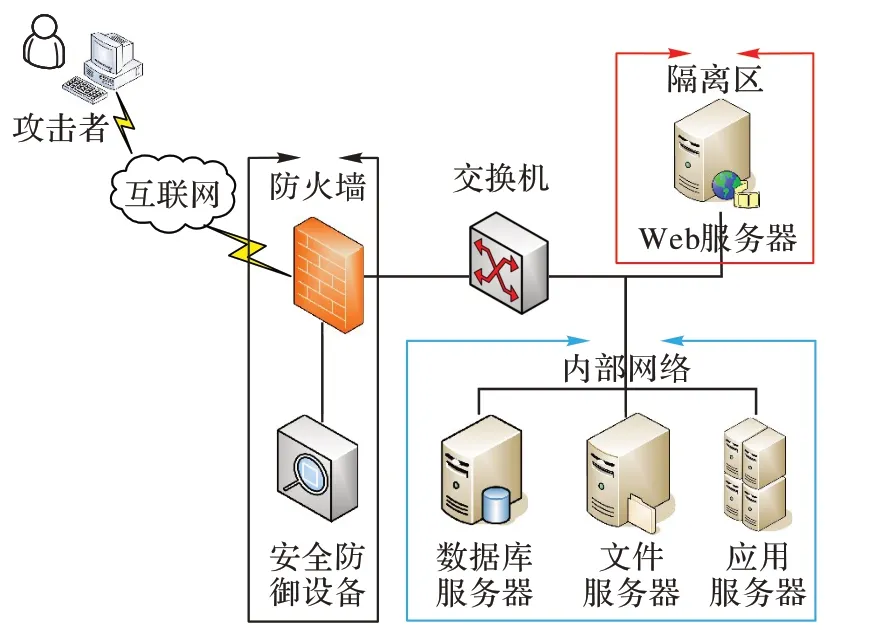
图2 仿真实验拓扑Fig.2 Simulation experiment topology
本实验以S={S1,S2,…,S5}表示每个子博弈的稳定状态集合,其中:S1表示攻击者成功入侵安全防御设备并获取root 权限的状态;S2表示攻击者利用Web 服务器的漏洞并获取其root 权限的状态;S3表示攻击者利用Web 服务器访问并获取应用服务器控制权限状态;S4表示攻击者利用FTP 服务器漏洞并获得其root 权限状态;S5表示攻击者利用数据库服务器的漏洞对数据库服务器进行攻击破坏,使系统无法向客户端提供服务。
通过漏洞扫描器Nessus 对实验系统进行扫描,对获得的漏洞数据、路由配置信息进行分析后,查询国家信息安全漏洞库(http://www.cnnvd.org.cn)有关数据,将防御者划分为高低({D1,D2})两种类型,防御信号划分为({SI1,SI2,SI3})。参照美国麻省理工学院林肯实验室对网络攻防的分类以及相关历史数据[22],结合本文定义的收益量化方法,本次实验选取的攻击策略和防御策略如表4、5 所示。状态转移概率如表6 所示。

表4 攻击策略集合Tab.4 Attack strategy set

表5 防御策略集合Tab.5 Defense strategy set

表6 各阶段状态转移概率Tab.6 State transition probability of each stage
各阶段攻防策略如表7 所示。根据本文收益量化方法及均衡求解方法,可获得表8 所示各阶段攻防收益矩阵,及表9 所示各阶段攻防均衡值。

表7 各阶段攻防策略Tab.7 Attack and defense strategies of each stage

表8 各阶段攻防收益矩阵Tab.8 Attack and defense benefit matrices of each stage

表9 各阶段攻防均衡值Tab.9 Attack and defense equilibrium values of each stage
4.2 均衡求解与分析
分析本文模型的博弈均衡和收益,以损坏数据库服务器资料为攻击目标,通过Matlab2016b 工具实现MTD 决策算法,分析图3~7 的仿真数据和图像可知,攻击者的攻击路径有如下两条:

图3 第一阶段攻防演化轨迹Fig.3 First stage attack and defense evolutionary trajectori es
路径1 安全防御设备-Web 服务器-应用服务器-文件服务器-数据库服务器。
路径2 安全防御设备-Web 服务器-应用服务器-数据库服务器。
在博弈的第一个阶段,随着攻防双方的博弈演化,当防御者采取高级防御策略时,释放高级防御信号迷惑攻击方,且攻击者采取攻击策略AS1时,该结果为一个分离均衡,平均防御收益为3 224;当防御者采取低级防御策略时,释放低级防御信号迷惑攻击方,且攻击者采取攻击策略AS2时,该结果为另一个分离均衡,平均防御收益为2 099。比较收益值,故本阶段的最优防御策略是防御者采取高级MTD 防御策略并释放高级防御信号。
攻击者成功入侵安全防御设备并获取root 权限后攻防进入第二阶段,当防御者采取高级防御策略时,释放高级防御信号迷惑攻击方,且攻击者采取攻击策略AS1时,该结果为一个分离均衡,平均防御收益为5 908;当防御者采取低级防御策略时,释放低级防御信号迷惑攻击方,且攻击者采取攻击策略AS2时,该结果为另一个分离均衡,平均防御收益为4 898。比较收益值,故本阶段的最优防御策略是防御者采取高级防御策略并释放高级防御信号。

图4 第二阶段攻防演化轨迹Fig.4 Second stage attack and defense evolutionary trajectories

图5 第三阶段攻防演化轨迹Fig.5 Third stage attack and defense evolutionary trajectories
攻击者利用Web 服务器的漏洞并获取其root 权限后进入第三阶段应用服务器和第四阶段FTP 服务器权限夺取攻防状态,此时分离均衡都为防御者采取高级防御策略时,释放高级防御信号,攻击者采取攻击策略AS2;以及防御者采取低级防御策略时,利用蜜罐改变攻击面呈现信息,释放高级防御信号对攻击者进行迷惑,且攻击者采取攻击策略AS2。比较收益值,三、四阶段的最优防御策略分别为防御者采取高级防御策略并释放高级防御信号和防御者采取低级防御策略并释放高级防御信号,且平均防御收益分别为3 598 和4 063。
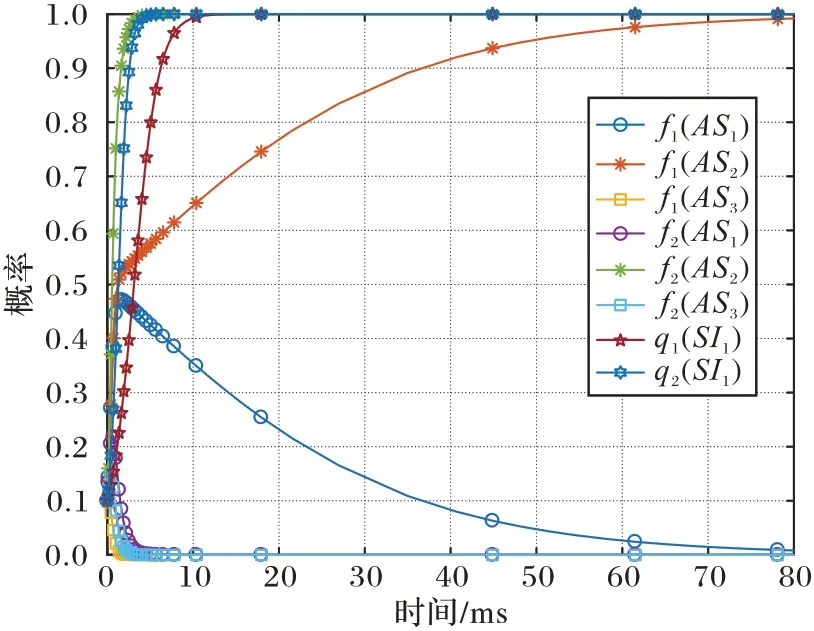
图6 第四阶段攻防演化轨迹Fig.6 Fourth stage attack and defense evolutionary trajectories
当攻防对抗进行到第五阶段保护数据库服务器时,从仿真图中分析得出,分离均衡分别为当防御者采取高级防御策略时,释放高级防御信号迷惑攻击方,且攻击者采取攻击策略AS1,平均防御收益为4 514;当防御者采取低级防御策略时,释放高级防御信号迷惑攻击方,且攻击者采取攻击策略AS1,平均防御收益为4 448。比较收益值,故本阶段的最优防御策略是防御者采取高级防御策略并释放高级防御信号。

图7 第五阶段攻防演化轨迹Fig.7 Fifth stage attack and defense evolutionary trajectories
通过以上防御收益的累计,可以看出路径1 的总防御收益大于路径2 的防御总收益,因此路径1 攻防过程更加满足防御需求。通过对两条攻击链特点分析,为降低攻击链2 形成的概率,因此需要降低状态3 跳变到状态5 的概率。分析状态3 的攻防策略,通过本文算法可得出S3的最优攻击策略为Steal account and crack it,因此防御者可以重点针对这一攻击进行移动目标防御,降低μ35(S5|S3)的值,从而达到最优防御效果。
4.3 结果分析
通过100 次蒙特卡洛仿真实验,将使用多阶段进化信号博弈最优策略选取算法(MSESGM)和传统随机均匀策略选择算法进行累积收益以及对比来验证本文算法的有效性。实验结果如图8 所示。

图8 不同策略收益比较Fig.8 Comparison of benefit between different strategies
由仿真图中可以看出随机均匀策略选择的累计收益不高且增长缓慢,而多阶段演化信号博弈最优策略的累计收益却稳定大幅上升。因为随机均匀选择策略不考虑攻防情况及收益量化,以同等概率无差别地随机选取防御策略,反而会造成大量的防御成本和资源浪费。本文模型采取多阶段演化信号博弈策略,将上一阶段的后验,在修正的基础上,作为下一阶段的先验概率,提高了对防御者类型分布的准确度,并通过主动释放干扰信号对外进行战术欺骗,对内采取针对性防御策略,不仅提高了防御模型的有效性和安全性,也使得防御资源得到最大限度的利用。
5 结语
网络安全攻防对抗的策略选取问题一直是研究的热点。本文基于多阶段演化信号博弈模型研究了MTD 策略选取决策算法。本文研究的主要工作有:1)提出演化信号博弈方法,通过生物进化理论研究攻防对抗趋势,更贴近实际网络情况;2)将移动目标防御技术作为防御策略,大幅提高了防御者的主动性及防御性能;3)考虑实际攻防多回合状况,将博弈状态从单阶段扩展至多阶段,并给出了详细的收益量化指标,使得模型具有良好的通用性,改变了网络防御的被动地位,以此提高系统安全性。下一阶段的工作任务则是进一步优化算法,使本文模型能够应用于多种新型和复杂的网络环境中。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
中国计算机报(2018年12期)2018-10-08
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
澳门月刊(2016年6期)2016-06-15
中国经济信息(2015年8期)2015-05-05
时代英语·高三(2014年5期)2014-08-26
网络与信息(2009年4期)2009-04-26
中国计算机报(2009年21期)2009-04-22
