
信息熵改进主成分分析模型的链路预测算法
2022-09-25 08:42孟昱煜郭静
计算机应用 2022年9期
孟昱煜,郭静
(兰州交通大学电子与信息工程学院,兰州 730070)
0 引言
复杂网络链路预测[1]指通过已知的各种信息预测给定网络中尚不存在连边的两个节点发生链接的可能性。它的应用包括在社交网络中的朋友推荐[2]、预测蛋白质之间的相互作用[3]、推断网络演化机制[4]。目前大多数研究都是基于节点相似性算法:共同邻居(Common Neighbor,CN)指标[5]关注两个节点是否处于同一个环境;Katz 指标[6]考虑了网络的全部路径;全局指标中ACT(Average Commute Time)[6]表现突出;LHNII(Leicht-Holme-Newman)指数[6]的基本思想是基于一般等效;MFI(Matrix Forest Index)[6]在协作推荐系统中取得了良好的结果;SRW(Superposed Random Walk)指数[6]使得目标节点与附近节点之间的相似性更高;局部路径(Local Path index,LP)指标[7]在共同邻居基础上,考虑了三阶路径的影响来计算节点间相似性。基于相似性算法在不同结构特征的网络中,计算结果不稳定且无法获得鲁棒性[8],而且单机制算法存在局限性,故筛选并组合若干个简单指标,即算法的集成在链路预测中是有效的算法[7]。鉴于上述问题,结合复杂网络的特点,基于不同的相似性算法,引入融合集成的思想,研究混合链路预测。
混合链路预测是指能使用多维信息或直接定义多维信息之间关系的一种算法研究[9]。吴翼腾等[9]对组合算法进行理论极限研究得出组合算法的准确性一定大于或等于各个单机制算法的链路预测准确性;He 等[10]基于有序加权平均(Ordered Weighted Averaging aggregation operator,OWA)算法设计了链路预测中经典局部指标的集成算法;Ma 等[11]利用逻辑回归设计的融合算法;吴祖峰等[12]利用机器学习中的AdaBoost 算法融合指标;Li 等[13]提出了基于Logistic 回归算法和XGBoost 算法的集成模型链路预测算法(Ensemble-Model-based Link Prediction algorithm,EMLP)。近年随着深度学习的发展,研究者提出了网络表示学习法和图神经网络[14]。
根据现有研究,融合结构相似性指标的算法可以提高链路预测的效果。受OWA 算法的启示,本文提出了一种组合模 型 PEW(information fusion model based on Principal component analysis and Entropy Weight method)用于链接预测。PEW 模型的主要思想是使用随机森林(Random Forest,RF)算法[15]确定了代表网络的不同特征的7 种链路预测相似性指标作为最佳特征集合(CN、LP、LHNII、ACT、Katz、SRW和MFI),利用信息熵改进主成分分析(Principal Component Analysis,PCA)实现了指标的非线性计算,并获得了指标融合的特征权重。在此基础上,使用所获得的特征权重校验经典相似性指标并在6 个真实数据集上测试模型,通过与混合链路预测算法对比进一步验证了PEW 模型校验单机制算法的有效性、可靠性和鲁棒性。
1 算法概述
考虑到不同类型指标之间的错分样本集可能不同,从而不同的指标可以给出互补的信息,因此本文利用随机森林选择能够代表网络的不同特征和不同思想求解的指标作为最佳特征集合,通过基于信息熵改进PCA 的特征信息融合模型(PEW)集成特征获得权重来衡量不同结构对连边的贡献程度,利用该模型对现有的相似性指标进行校验,从而对提升预测性能产生积极的影响。
1.1 基于信息熵改进PCA的特征信息融合模型
信息融合是一种多层次多方面的处理过程,通过对多源数据的检测、组合、相关和估计来决策所需完成的任务。本文利用随机森林确定指标重要性指数确定了最佳指标(CN、Katz、LP、LHNI、ACT、SRW 和MFI)。详细定义见1.2 节。
1.1.1 随机森林特征选择
机器学习中,随机森林(RF)[15]是一个包含多个决策树的分类器,输出的类别由个别树输出的类别的众数而定,可以很好地评估各个特征在分类问题上的重要性,筛选后的特征指标体系更具有代表性。生成随机森林的步骤如下:
1)从训练数据集中,应用bootstrat 有放回地随机抽取K个新的样本集,并由此构建K棵分类回归树,每次未被抽到的样本组成了K个袋外数据。
2)设有n个特征,则在每一棵树的每个节点处随机抽取mtry个特征(mtry≤n),通过计算每个特征蕴含的信息量,在mtry个特征中选择一个最具有分类能力的特征进行节点分裂。
3)每棵树最大限度地生长,不做任何剪裁。
4)将生成的多棵树组成随机森林,用随机森林对新的数据进行分类,分类结果按树分类器的投票多少而定。
通过上述步骤可以对指标进行筛选并确定指标的重要性,以此提供最优的特征集合。
1.1.2 PCA特征融合
主成分分析(PCA)是考察多个变量间相关性一种多元统计法,可以在信息丢失最小的前提下,实现多元数据的特征融合,在提取出主要特征的同时去除了多源数据间的线性相关[16]。近年来,PCA 在信号处理、模式识别、数字图像处理等领域得到了广泛应用[17]。在链路预测问题中,由于节点之间存在一定的相关关系,计算所得的多维节点相关特征也相应地存在一定的关系,为此利用PCA 对节点间相似性特征进行融合。PCA 特征融合的计算过程如下:
步骤1 对原始数据矩阵进行标准化处理,使各指标之间具有可比性,计算公式为:

其中:X表示原始矩阵,X*表示标准化后的矩阵,Xmax=max(X),Xmin=min(X)。
步骤2 计算协方差矩阵,对于集成相似性矩阵Xm*n,m表示特征个数,n表示样本个数,即节点对。计算协方差矩阵C来反映多变量之间的关系,计算公式为:

步骤3 对协方差矩阵分解,计算得到协方差矩阵的特征值λ1,λ2,…,λm(对特征值按降序排列)和对应的单位化特征向量u1,u2,…,um。计算公式为:

步骤4 按照累计贡献率选择主成分,构造映射矩阵P,取前m个主成分,计算第i(i≤m)个主成分的贡献率及累积贡献率。取前k个特征向量进行组合形成映射矩阵P,P=[u1,u2,…,uk]。贡献率的计算公式为:

步骤5 利用映射矩阵,重构主相似性特征矩阵,计算公式为:

1.1.3 信息熵改进PCA
在信息论中,用熵值可以判断指标的变异程度,可以计算出各指标的贡献率,得到主相似性特征权重[18-19]。信息熵是衡量随机变量分布的混乱程度,是随机分布各事件发生的信息量的期望值,被定义为H(X)=是随机变量x的概率分布,随机变量的取值个数越多,状态数也就越多,信息熵就越大,混乱程度就越大。信息熵改进PCA 从熵的角度,以相似性特征携带的节点相似性信息量为度量,计算相似性贡献率进行相似性特征融合,从而得到融合相似性特征权重。假设节点具有m个相似性特征a1,a2,…,am,各相似性 指标特征 提供信息 的概率为q(x1),q(x2),…,q(xm),则该数据集的相似性特征的信息结构为:

步 骤1 计算特征 值,即Q=[q1,q2,…,qm],计算公式为:

步骤2 利用特征值qi计算各相似性特征的信息熵Ei,计算公式为:
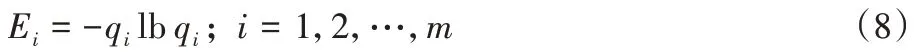
步骤3 计算相似性特征加权系数wi,构造加权矩阵W=diag[w1,w2,…,wm],计算公式为:

步骤4 利用加权矩阵W得到融合相似性特征权重,计算公式为:

步骤5 对融合相似性特征权重矩阵归一化处理得到Y_F',即特征信息融合权重。
1.2 PEW模型校验单机制算法
本文通过信息熵改进PCA 提取待融合指标的融合特征指数,也就是各结构对连边的贡献程度。对已有的指标,需要将其与信息融合特征权重结合,并对其进行校验来提升预测精度,即信息融合特征权重与单机制索引作哈达玛积,哈达玛积是维数相同的矩阵对应元素的乘积。这7 个单机制索引是从不同的角度和不同思想提出的,只有融合这样的索引指标才能获得更为全面的网络结构信息。CN 指标考虑两个节点的共同邻居的数量,计算复杂度低,但预测精度稍低;Katz 指标考虑了所有的路径,计算复杂度高;LP 指标是在CN的基础上考虑了三阶路径,复杂度低于全局指标;LHNII 是在重新定义的相似性的基础上考虑了共同邻居;ACT 是从全局随机游走的角度考虑,计算复杂度高;SRW 考虑的是局部随机游走,计算复杂度低于全局随机游走指标;MFI 指标在协同推荐系统中有较好的效果。根据它们各自的优势和不足,用信息熵改进PCA 融合用于链路预测。
1)PEW-CN指标。
CN 指标是基于局部信息的最简单的相似性指标,对于网络中的节点x,定义它的邻居集合为Γ(x),如果两个节点x和y有许多共同的邻居,则x和y更有可能具有链接[5],即=|Γ(x) ∩Γ(y)|,用PEW 模型对其进行校验,即基于共同邻居指标的PEW 模型见式(11):

2)PEW-Katz指标。

3)PEW-LP指标。

4)PEW-LHNII指标。

5)PEW-ACT指标。

6)PEW-SRW指标。
SRW 指标是基于有叠加效应的局部随机游走提出的,它将随机步行者在起始点连续释放,导致目标节点与附近节点之间的更高相似性[6],即用PEW 模型对其进行校验,即基于SRW 指标的PEW 模型见式(16):
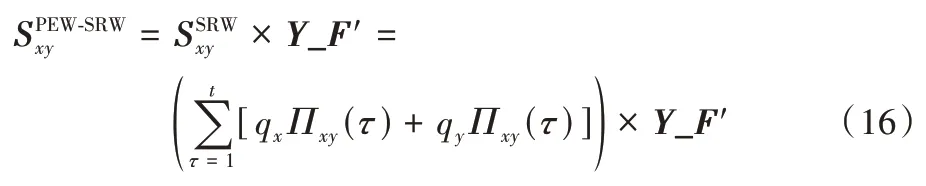
7)PEW-MFI指标。
MFI 指标是基于矩阵森林理论提出的,节点x和y之间的相似度可以被理解网络所有含一个根节点的生成森林中,有多少比例的森林是节点x和y属于同一个以节点x为根节点的树[6],即=(I+L)-1,L为网络的拉普拉斯矩阵,用PEW 模型对其进行校验,即基于MFI 指标的PEW 模型见式(17):

1.3 算法步骤
本文提出的基于信息熵改进PCA 的PEW 模型用于混合链路预测的算法步骤如下(以PEW-CN 为例,训练集Ep占比90%,测试集ET占比10%):
1)计算CN、Katz、LHNII、SRW、LP、ACT、MFI 的相似性矩阵和特征重要性指数;
2)利用信息熵改进PCA 的算法确定信息融合特征指数;
4)计算AUC(Area Under the Curve)值;
5)循环步骤3)~4)共20 次将得到预测精度AUC 值求平均并输出。
1.4 算法复杂度分析
对于一个具有n个顶点和e条边的无向网络G(n,e),网络以邻接矩阵的格式存储,对于局部指标,计算复杂度小于基于全局的指标,因此,O(CN)<O(Katz)、O(LP)<O(Katz)、和O(SRW)<O(ACT),而LHNII 可以近似看成是Katz 指标的一个推广,并且基于全局的指标的计算复杂度往往很高,则近似为O(LHNII)=O(Katz),而MFI 指标是全局指标计算复杂度也很高。本文算法的计算复杂度主要由第1)步产生,即7 个指标的并行运算,因此算法获得各个指标的相似度矩阵的计算复杂度取最大指标的复杂度,所以本文算法的计算复杂度主要受Katz、MFI 和ACT 指标的影响。
2 实验与分析
2.1 实验数据
实验使用来自6 个不同的领域的复杂网络数据集进行算法测试,包括交通网络、社会网络、生物网络、技术网络等。1)美国航空网络(USAir)(http://linkprediction.org/index.php/link/ resource/data);2)代谢网络(Celegans)(http://wwwpersonal.umich.edu/~mejn/netdata);3)路由器层次网络(Router)(http://linkprediction.org/index.php/link/resource/data);4)蛋白质相互作用网络(Yeast)(http://www-personal.umich.edu/~mejn/net data);5)有向政治博客数据集(Political Blogs,PB)(http://www-personal.umich.edu/~mejn/netdata);6)维基百科投票晋升到管理人的职位(直到2008 年1 月)(wiki-vote)(https://snap.stanford.edu/data/wiki-Vote.html)。表1 总结了它们的网络拓扑特性,其中,|V|为网络中节点数量,|E|表示边的数量,〈k〉表示网络的平均度,C表示网络平均聚集系数,D表示网络直径。

表1 数据集拓扑特征参数Tab.1 Topological feature parameters of datasets
2.2 评价指标
衡量链路预测算法好坏的主要指标有AUC[10]、精确度[10]和排序分[10]。AUC 是应用最广泛的一种衡量链路预测结果的方法,它考虑了精确度的同时也考虑了排序分,综合考虑了所有已存在边的得分顺序与不存在边的差距。AUC值越大则算法越有效,本文选取AUC 衡量预测准确度。
AUC 评价指标从整体上衡量算法的准确性,是基于测试集中边的相似值和不存在的边的相似值的比较,即:

其中:独立比较n次(n=100 000),测试集中边的相似值大于不存在的边的相似值有n'次,测试集中边的相似值等于不存在的边的相似值有n″次,AUC>0.5 的程度衡量了算法在多大程度上优于随机选择的算法。
2.3 实验
随机森林确定的最佳特征指标后,验证PEW 模型的有效性。首先,在6 个数据集中与单机制算法作对比,验证模型对单机制算法校验的有效性;然后,为了说明所提出的基于PEW 模型的混合链路预测算法的可靠性和稳定性,将其与OWA 混合链接预测算法和集成模型EMLP 混合链路预测算法进行比较。OWA 算法的核心思想是使用三种OWA 运算符以获得各种相似性指标权重。EMLP 模型的核心思想是基于Logistic 回归算法和XGBoost 算法将4 个相似性指标作为模型要学习的4 个特征,并根据集合模型的思想结合逻辑回归和堆叠技术提出的。
2.3.1 特征指标的选择
为了验证提取特征的重要性,通过对已有指标的分析,计算了随机森林集成模型对应的特征重要性指数,通过筛选指标得到了最优的特征集合并将这些特征作为PEW 模型的基准。图1 给出了每个相似性索引的重要性指数,其用随机森林特征选择算法计算的数据集中的每个特征的分数。其中,决策树的个数为100,特征的个数为7,数据集的70%为训练集,30%为测试集。

图1 特征指标的重要性指数Fig.1 Importance indexes of feature indicators
2.3.2 基于信息熵改进PCA的特征信息融合模型
对网络的多维相似性特征信息进行PCA 融合分析,以USAir 网络为例,前3 个主相似性特征对应的特征值为λ=[0.007 7,0.001 1,0.000 5],方差贡献率为p_i=[83.49%,11.41%,5.1%]。经计算前3 个主相似性特征的累计贡献率已达到100%,可以总体反映相似性特征的特征信息,因此选择前3 个主相似性特征确定特征信息融合指数。各个数据集中各个主成分的贡献率见表2,各个数据集中各个主成分的累计贡献率见表3。PEW 模型对于选取的主相似性特征,利用信息熵改进PCA 计算多维信息的特征融合指数,最终得到网络中多维信息对相似性的影响程度,即所占的权重。

表2 不同数据集中各个主成分的贡献率Tab.2 Contribution rates of principal components in different datasets
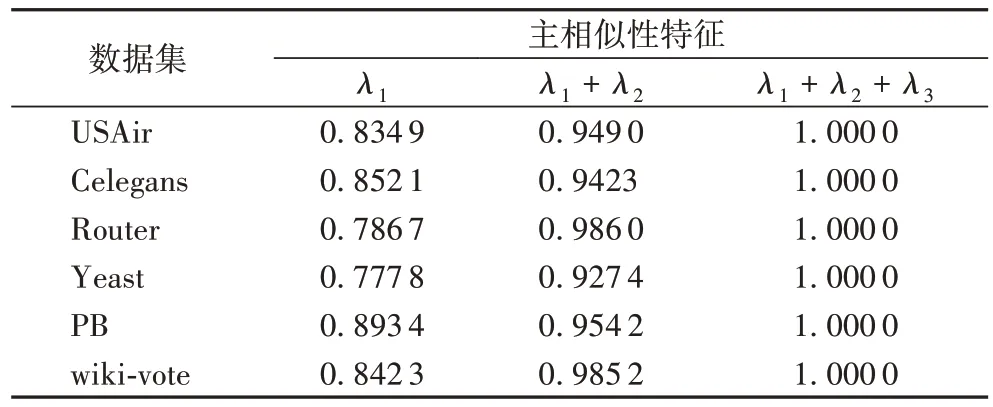
表3 不同数据集中各个主成分的累计贡献率Tab.3 Cumulative contribution rate of each principal component in different datasets
2.3.3 基于PEW模型的链路预测算法
将PEW 模型得到的特征信息融合指数用来校验单机制算法,首先将网络划分为90%的训练集和10%的测试集,求得单机制算法的节点相似性;然后,将多维特征信息融合指数与节点相似性结合,求得最终的节点相似性;最后,执行链路预测得到AUC 值并与单机制算法作对比。
为了说明所提出的PEW 模型校验单机制算法的有效性,本文将其与CN、LP、LHNII、ACT、Katz、SRW 和MFI 这7 个单机制算法做比较,具体值如表4 所示,可以看出基于PEW模型的混合链路预测算法与单机制算法相比表现良好,并且AUC 值高于其他指标。
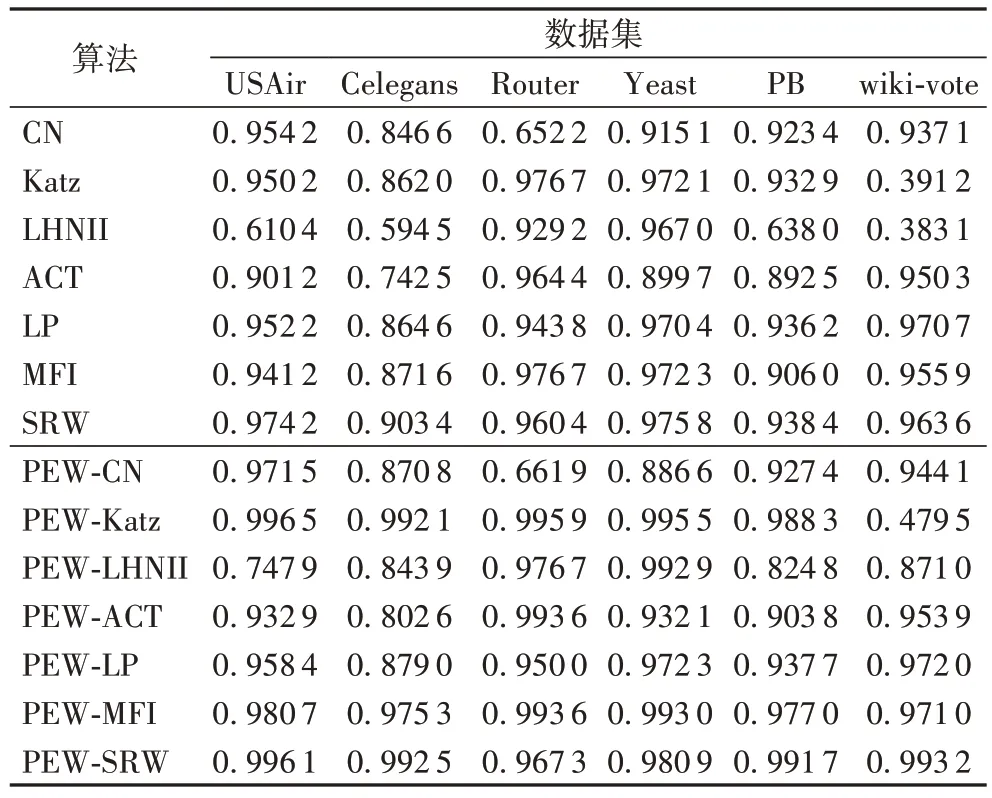
表4 单机制算法校验中各个算法的AUC值Tab.4 AUC values of each algorithm in single mechanism algorithm verification
单机制算法校验中所提算法相较对比算法的AUC 提升幅度如图2 所示,其中PEW-CN →CN 表示PEW-CN 算法对比于CN 算法的提升幅度,其他类似。
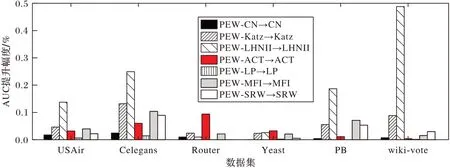
图2 单机制算法校验中所提算法相较对比算法的AUC提升幅度Fig.2 AUC improvement rate of the proposed algorithm compared with comparison algorithm in single mechanism algorithm verification
从图2 中可以看到(提升幅度为负数置为零),对本身就有很高的预测精度的单机制算法,基于PEW 模型的校验效果并不明显,比如LP 指标,这是因为算法在校验前就对网络的结构信息有很好的定义,提供了最好的预测精度,本文所提模型能补充的信息相对较少;对于预测精度较低的算法,PEW 模型能够提供更多影响相似性度量的结构信息,它的校验效果就更为突出,比如LHNII 指标。由此可见,这些单机制算法的预测精度在校验后效果都有提升。对于不同规模的数据集,基于模型校验后的算法均优于单机制相似性指标的预测精度且预测精度提升效果明显。对AUC 提升幅度求均值发现,在网络直径很大的数据集(Router 和Yeast)中预测精度提升幅度很小,这是因为在这样的网络中一个节点的相关信息受更多节点的影响,去除网络中少许几条边后可能会使原来的距离变得更长,说明基于PEW 模型获得的结构信息存在缺陷,并不是非常全面。综合来看,经PEW 模型校验后的单机制算法在预测精度方面有很大的改进,也表明PEW 模型所获取的网络特征信息更为全面且能解决单个算法计算相似性时存在的问题,尤其在网络直径较小的复杂网络中预测效果更突出。
整合各种相似性索引的链路预测研究仍处于初期阶段,所以相关研究结果较少。为了说明所提出的PEW 模型的有效性和稳定性,本文将其与OWA 链接预测算法和集成模型EMLP 链路预测算法进行比较,主要在6 个真实网络上进行验证。如表5 所示,部分算法优于OWA 算法和EMLP 算法,其中PEW-Katz、PEW-MFI 和PEW-SRW 算法在预测精度方面表现更突出。对于平均聚集系数很大的USAir 网络,本文算法虽然预测精度值优于组合算法OWA,但对于集成算法EMLP 并没有表现得更优,对于平均聚集系数很小的wiki-vote 网络亦是如此,而对于其他4 个网络大部分基于PEW 算法的预测精度相较于对比算法都有一定程度的提升。这表明基于PEW 模型的混合链路预测算法在网络中预测精度更加可靠和稳定。

表5 基于PEW模型的混合链路测算法以及OWA和EMLP算法在6个网络上的AUC值Tab.5 AUC values of hybrid link prediction algorithms based on PEW model,OWA and EMLP algorithms on six networks
综合而言,在预测精度方面,不论节点数量的多少,本文算法优势明显。利用信息熵改进PCA 将复杂网络结构的多样性融合得到对相似性影响最大的信息,并确定权重来校验单机制算法的PEW 模型可以获得高的预测精度。基于PEW模型的算法能够补充单机制算法对结构信息度量的不足,特别是网络直径较小的网络,在预测精度上也优于部分混合链路预算法。在算法有效性方面,在部分网络中有良好的预测效果且在大规模网络的链路预测中有较好的效果提升。
3 结语
与其他现有算法相比,本文提出的复杂网络链路预测算法是一种改进。传统的基于相似度的复杂网络链路预测算法着重于节点的单个相似度指标。为了更好地整合现有的相似性指标,从而进一步提高链接预测的稳定性和准确性,本文通过随机森林进行特征选择确定了7 个相似性指标,利用信息熵改进PCA 模型将7 个相似性指标组合在一起进行混合链路预测。这7 个相似性指标代表了网络的不同特征。所提的PEW 模型利用信息熵改进PCA 集成了指标并且对已有的单机制算法进行了有效的校验。利用集成的思想,通过信息融合特征指数,提出了一种新的链路预测算法,该算法考虑了不同相似性指标的互补性,因此其稳定性更强。为了证明其有效性和可行性,本文最后在6 个真实网络中与单一指标相比AUC 值,以验证所提PEW 模型的有效性,与混合链路预测算法相比验证模型的可靠性和稳定性。本文的主要贡献是整合现有的相似性指标,利用模型集成的思想引入信息熵改进PCA 获得了网络较为全面的结构信息来表征节点相似性,并对单机制算法进行了有效的校验。将来,本文工作一方面在大量的数据集中验证算法的适用网络,另一方面将采用其他算法,研究并提出更有效的模型集成算法,以设计新的链路预测框架,这对于复杂网络的链路预测将具有重要的理论和实践意义。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
中学生学习报(2022年15期)2022-04-17
机电工程技术(2021年3期)2021-09-10
电脑知识与技术·经验技巧(2017年9期)2018-02-24
电脑爱好者(2017年12期)2017-06-30
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
科技创新导报(2016年27期)2017-03-14
中国新通信(2016年13期)2016-08-12
数理化学习·高一二版(2009年2期)2009-03-30
