
空中加油场景下的目标联合检测跟踪算法
2022-09-25 08:43孙永荣赵科东李华曾庆化
计算机应用 2022年9期
张 怡,孙永荣,赵科东,李华,曾庆化
(南京航空航天大学导航研究中心,南京 210016)
0 引言
空中加油作为现代空军有效扩大作战范围、提高作战能力的重要手段,已经成为世界各军事强国空中力量的标准配置[1]。我国空军和海军通常采用软管式空中加油技术,加油过程基本可以分为5 个阶段:会和、编队、对接、加油以及退出[2]。其中对接阶段尤为重要,高精度、高实时性、高可靠性的加油锥套的检测、跟踪与定位是空中加油对接成败的关键[3]。本文主要针对空中加油过程中锥套目标的跟踪问题开展相应研究。
目前主流的目标跟踪方法是基于检测的跟踪[4],即先利用检测器在每帧图片中找到目标,再根据检测框之间的关联完成目标的追踪[5]。在这种方法中,用于关联的策略大多复杂、计算量大,而且检测器与跟踪器是完全独立的,跟踪性能的好坏依赖于初始帧检测的结果。2020 年,文献[6]中提出了一种可以同时进行检测与跟踪的新型网络——CenterTrack,在CenterNet 检测器的基础上进行了改进与扩充,做到了真正的检测跟踪一体化;但也正是由于将检测与跟踪融合到了一个网络中,该网络模型的体量较大,在一台拥有两块GTX1080Ti 显卡的高性能计算机上进行150 个周期的训练使其收敛至稳定状态,共耗时54.3 h。本文将从模型设计以及优化算法两部分对CenterTrack 网络进行改进,利用膨胀卷积组与深度可分离卷积层代替网络中的部分标准卷积层以减少网络模型的参数量与计算量,并对网络做进一步的优化,采用一种带动量的随机梯度下降(Stochastic Gradient Descent,SGD)与Adam(Adaptive moment estimation)算法相结合的模型参数学习方法,从而实现对锥套目标的有效跟踪。
1 CenterTrack网络简介
CenterTrack 属于一种多目标跟踪网络,在本文应用于空中加油场景下锥套目标的跟踪。与以往的跟踪方法不同的是,在CenterTrack 网络中,目标均由边界框的中心点表示,只要按时间顺序对点进行跟踪就可以实现对目标整体的跟踪[6],显著降低了目标关联的计算量与复杂性。
该网络模型的输入输出如图1 所示,输入共分为三部分:前一帧图像、当前帧图像和根据上一帧图像渲染出的中心点位置分布热力图(heatmap),输出为当前帧图像的heatmap、检测框的尺寸以及从当前目标中心到前一帧目标中心的偏移向量,根据该偏移向量和当前目标中心即可与前一帧中的目标建立联系,从而达到学习跟踪的目的。在跟踪过程中,目标会被赋予ID(Identity Document)值,每一帧中目标ID 的变化次数也是评估跟踪效果好坏的标准之一。

图1 CenterTrack网络框架Fig.1 Framework of CenterTrack network
该模型的主干网络采用的是在DLA(Deep Layer Aggregation)基础上加入可变形卷积的分割网络DLASeg,通过迭代的方式将网络结构的特征信息聚合[7]。
2 改进的轻量化CenterTrack跟踪器
2.1 Tiny-CenterTrack模型的提出
本文对CenterTrack 网络从模型设计与优化方法两方面进行了改进,为了方便表述,下文将改进后的网络模型称作Tiny-CenterTrack。
2.2 基于膨胀卷积与深度可分离卷积的轻量化网络
基于深度学习的检测与跟踪方法相较于传统方法的一个重要优势在于可以自动提取图像特征[8],但是随着研究的深入,网络参数量也随之增加,给实际应用带来了困难。为了方便将网络移植到嵌入式平台等计算量有限的设备中,研究者们提出了轻量化网络[9]的概念,着重研究如何在保持网络模型性能的基础上减小网络的计算量,改变卷积方式便是研究方向之一。因此本文引入了膨胀卷积与深度可分离卷积,通过将部分标准卷积层替换为膨胀卷积层与深度可分离卷积层减小网络的计算量与参数量。
膨胀卷积是在标准卷积的基础上加入空洞,可以理解为等间隔采样,间隔数量与膨胀率(dilation)有关,如图2 所示,3 幅图均采用3 × 3 的卷积核。从图2 中可以看出,在卷积核尺寸相同的情况下,膨胀率越大,卷积层的感受野范围(方框)也越大,提取到的特征也越多。

图2 膨胀卷积Fig.2 Dilated convolution
该方法常被用于提高图像的分辨率,从而实现密集特征的提取[10]。除此之外,膨胀卷积可以在增大感受野的同时不增加网络的参数量和计算量[11]。
假设卷积核的大小为k×k,图像尺寸为W×H,输入、输出通道数分别为Cin、Cout。在不考虑偏置的情况下,卷积层的参数量Np为:

计算量Nc为:

在各参数相同的条件下分别对图像进行一次标准卷积和一次膨胀卷积,标准卷积得到的感受野范围为k×k,膨胀卷积得到的感受野范围R为:

一般的神经网络都需要多个连续的卷积层提取特征,若多次叠加相同膨胀率的膨胀卷积层会引起网格效应,导致信息不够连续以及局部信息丢失[12]。因此,本文将拥有不同膨胀率的卷积层组合成不同大小的block,替换原有网络的部分卷积层以避免网格效应的出现,如图3 所示。

图3 改进前后的网络结构对比Fig.3 Comparison of network structure before and after improvement
以输入模块中的当前帧图像为例,原网络中对该图像进行一次卷积核尺寸为7 的标准卷积,得到的感受野范围为7 × 7,根据式(1)和式(2)可以得到参数量为7 056,计算量约为7.2 × 109,将其替换为由两层卷积核尺寸为3 的膨胀卷积层组成的block,第一层膨胀率为1,第二层膨胀率为2,得到的感受野依然为7 × 7,参数量为1 539,计算量约为1.56 ×109。该方法可以在不改变感受野大小的前提下,减少78.2%的参数量与78.3%的计算量。
如图3 所示,本文还将head 部分的标准卷积层替换为了深度可分离卷积层。深度可分离卷积分为深度卷积与逐点卷积两部分,主要思想是将卷积核拆分为单通道形式,对输入特征图的每一个通道都进行卷积操作,然后再利用1 × 1卷积改变输出特征图的维度[13],如图4 所示。

图4 标准卷积与深度可分离卷积对比Fig.4 Comparison of standard convolution and depthwise separable convolution
假设卷积层各参数与上文相同,在偏置为1 的情况下,深度可分离卷积层的参数量Np为:

计算量Nc为:

以head 部分的中心点位置分布热力图为例,原网络对其依次进行了一次卷积核尺寸为3、一次卷积核尺寸为1 的标准卷积,根据式(4)和式(5)可得其参数量约为6.0 × 105,计算量约为3.84 × 1010,将其替换为深度可分离卷积层(图4 中分组个数g与输入通道数相同)后参数量约为0.68 × 105,计算量约为0.44 × 1010,由此可见,深度可分离卷积可以减少88.7%的计算量与88.5%的参数量。
2.3 优化策略的改进
在深度学习中,损失函数被用于评估模型预测的能力,目前最常用的损失函数优化方法主要有SGD 和Adam 算法。
随机梯度下降的基本思想是在计算过程中随机选取一组样本进行计算迭代更新,计算公式如下:

式中:gt是t时刻的梯度,θt-1是t-1 时刻损失函数中的参数,η是学习率,Δθt是参数变化量。
从式(7)中可以看出,SGD 的参数更新完全依赖于当前组样本的梯度,因此最终可能只是收敛到了局部最优而非全局最优,并且容易在局部最优值附近产生震荡[14]。为了抑制这种震荡,SGDM(SGD with Momentum)在梯度下降过程中加入了惯性思想,引入了动量的SGD 应用也更为广泛。
SGDM 采用的是单一学习率η,需要人为设置,目前很难找到一个可以获取适合当前所有样本和学习阶段学习率的通用计算方法,自适应优化方法应运而生。Adam 与经典的随机梯度下降法最大的不同之处就在于学习率的选取,它可以在学习过程中利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率[15-16],计算公式如下:

式中:mt、vt分别指的是t时刻梯度的一阶矩估计和二阶矩估计,mt-1、vt-1分别指的是t-1 时刻梯度的一阶矩估计和二阶矩估计指的是对mt、vt的校正,gt是t时刻的梯度,Δλt是参数变化量,β1、β2、ε默认设置为0.9、0.999、10-8。
从式(12)中可以看出,经过偏置校正后,对学习率形成了动态约束,参数的更新不会发生剧烈变化。
大量已有实验表明,Adam 在训练初期无论是在收敛速度还是泛化能力上都优于SGDM[17],在训练后期却因为梯度的不均匀缩放[18]导致泛化能力逊于SGDM。本文也在初始学习率相同的条件下对训练集分别采用了Adam 优化与SGDM 优化进行训练,损失函数变化曲线如图5 所示,成功率及准确率曲线对比如图6 与图7 所示。

图5 不同优化函数下的损失函数曲线Fig.5 Loss function curves with different optimization functions

图6 不同优化函数下的成功率曲线对比Fig.6 Comparison of success rate curves with different optimization functions

图7 不同优化函数下的准确率曲线对比Fig.7 Comparison of accuracy curves with different optimization functions
从loss 曲线图中可以很明显看出,在初始学习率相同的情况下,Adam 算法的收敛速度更快,而成功率及准确率对比曲线表明该网络模型中SGDM 方法在性能方面基本优于Adam。
因此,本文在锥套样本训练的初期采用Adam 优化,接近收敛后切换到带动量的随机梯度下降方法,并根据锥套样本训练实际过程对优化函数的切换时机进行调整,引入了一个超参数δ,当满足以下条件时,则认为可以切换到SGDM:

式中:se-1和se分别代表第e个epoch 及第e-1 个epoch 时的loss 函数值,在本文中δ取0.01。
为避免出现偶然现象,本文认为当连续8 个epoch 均满足式(13)则进行切换。
3 实验与分析
3.1 基于锥套数据集的算法性能分析
3.1.1 样本的制作
大量有效的样本是深度学习中各网络进行训练的基础,本文采用的样本数据主要包括真实的空中加油场景视频与地面采集的锥套相对运动视频,共有17 组视频、15 058 幅图像,按照约8∶1∶1 的比例关系将其分为训练集、验证集与测试集,如图8 所示。

图8 部分锥套样本示意图Fig.8 Schematic diagram of some drogue samples
在对样本进行简单的调整与筛选之后,需要对原始样本进行标注,本文采用COCO(Common Objects in COntext)数据集标注格式,生成的JSON(JavaScript Object Notation)文件由图片信息、目标类别、目标边界框尺寸、目标编号等部分组成。
3.1.2 算法准确性评估
考虑到跟踪是为了后续定位做准备,本文通过衡量目标在图像中二维位置的准确程度对算法的准确性进行评估,指标包括成功率与准确率。
成功率体现的是能够正确检测到目标区域的帧数的比例,认为被检测区域与实际区域的重叠度大于设定的阈值即可算作正确检测到目标,重叠度IoU(Intersection over Union)的计算方法为:

式中:area(D)表示被检测区域,area(G)表示实际区域。
准确率体现的是边界框位置偏离程度小于所给位置误差阈值的帧数的比例,位置误差一般由结果目标框与实际目标框中心点之间的欧氏距离lerr来表示,其计算方法为:

式中:(xr,yr)、(xc,yc)分别代表实际目标框中心点坐标与结果目标框中心点坐标。
3.1.3 实验测试环境
硬件环境 本文算法通过计算机平台对视频数据进行处 理,所用CPU 为Intel Core i7-6800K,GPU 为Nvidia GTX1080 Ti,内存和显存分别为32 GB 与12 GB。
软件环境 本文算法的操作平台是Ubuntu16.04 操作系统,编程语言包括C++与Python,网络框架采用的是Pytorch,环境配置包括CUDA10.0、cuDNN7.6.5、OpenCV2.4.9 和Python3.6 等。
3.1.4 实验结果与分析
利用上述模型对不同的视频序列进行测试,算法实现的效果图如图9 所示,包含了正常、遮挡、小目标、夜间四种情况。

图9 算法实现效果Fig.9 Effect of algorithm implementation
在同一个视频序列中选取连续4 帧的局部放大图,锥套目标位置变化情况如图10 所示,图中标识出了帧数、锥套的图像坐标、类别名称、ID 值、位移向量以及中心点位置分布热力图。

图10 锥套目标位置变化Fig.10 Drogue target position change
以初始值为0.000 125 的学习率对改进后的网络模型进行训练得到的损失函数曲线如图11 所示,对改进前模型训练100 个周期与改进后模型训练50 个周期统计得到的成功率与准确率曲线如图12、13 所示。

图11 改进前后的模型损失函数曲线对比Fig.11 Comparison of loss function curves before and after model optimization
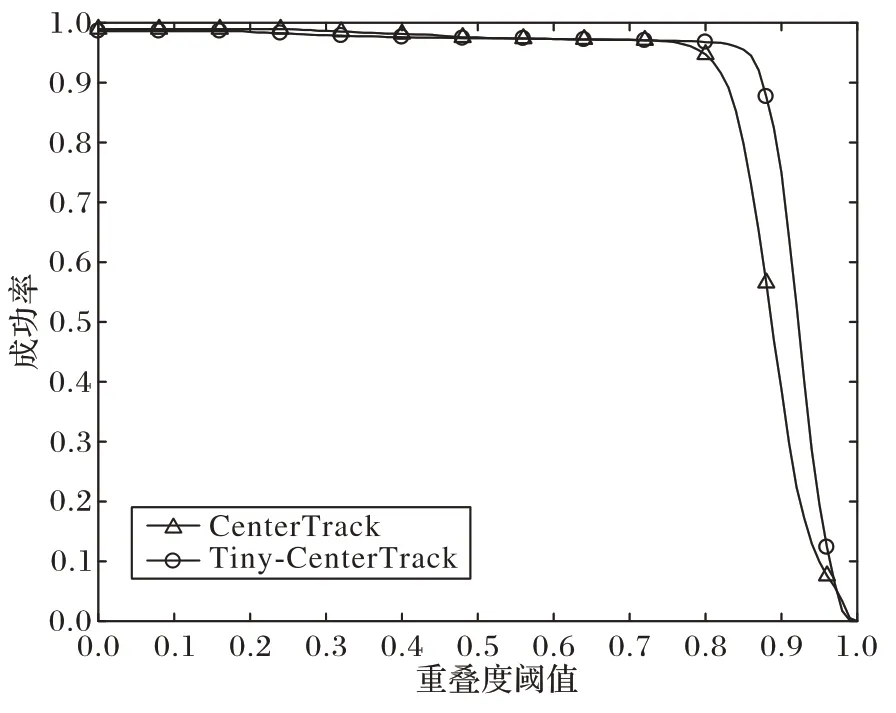
图12 改进前后模型的成功率曲线对比Fig.12 Comparison of success rate curves before and after model optimization

图13 改进前后模型的准确率曲线对比Fig.13 Comparison of accuracy curves before and after model optimization
从图11 中可以看出Tiny-CenterTrack 更快地收敛到一固定值并达到稳定;从图12、13 中可以看出,从第50 个训练周期开始,Tiny-CenterTrack 的成功率与准确率基本达到了改进前模型训练100 个周期的效果。因此,在相同的硬件条件下,改进之后的模型可将训练时长从36 h 缩减到18.5 h,大约减少了48.6%。
除此之外,在测试集中随机选取500 帧图片进行耗时测试,如图14 所示,Tiny-CenterTrack 将图像处理的平均耗时从34 ms 降到了31 ms,下降率约为8.8%。

图14 两种算法处理时间对比Fig.14 Processing time comparison of two algorithms
因此,在未损失网络性能的情况下,改进后的模型可以极大地减少训练时长,节省计算资源并且更加稳定。
3.2 基于公共数据集的算法性能分析
由于MOTChallenge(Multiple Object Tracking Challenge)是多目标跟踪领域常用的基准,因此,将本文算法在MOT17数据集上进行训练与测试,并与其他多目标跟踪方法进行比较。
3.2.1 算法性能评估指标
本文采用的算法性能评估指标如表1 所示。

表1 MOT17数据集上的部分评估指标Tab.1 Part of evaluation indicators on MOT17 dataset
3.2.2 MOT17数据集测试结果对比
由于CenterTrack 原作者提供了在MOT17-FRCNN 部分数据集上进行验证的评估结果,本文也相应进行了训练与测试,结果如表2。

表2 MOT17-FRCNN数据集上的评估结果对比Tab.2 Comparison of evaluation results on MOT17-FRCNN dataset
除与改进前的网络在公共数据集上进行对比之外,本文还将所提网络与目前MOT17 榜前的部分跟踪网络进行了比较,结果如表3 所示,其中public 表示采用公共检测器作为外部输入,private 表示无需公共检测器作为输入。

表3 MOT17数据集上的评估结果对比Tab.3 Comparison of evaluation results on MOT17 dataset
从表2、3 中可以看出,本文所提网络与改进前的CenterTrack 网络及其他多目标跟踪网络在性能上不相上下,算法的有效性得到了证实。
4 结语
针对空中加油场景下锥套目标的跟踪问题,本文将检测与跟踪一体化的CenterTrack 跟踪方法进行了改进,提出了一种空中加油场景下的目标联合检测跟踪算法。首先为了满足网络轻量化的需求,利用深度可分离卷积层与膨胀卷积层替换部分标准卷积以减小网络的计算量与参数量;然后结合Adam 优化与SGDM 优化方法的优缺点对该网络的优化策略进行了改进;最后根据真实场景下的空中加油视频以及自行采集的锥套运动视频制作了相应格式的数据集以供实验验证。
最终分别对锥套数据集与MOT17 公共数据集进行了算法的验证与评估。实验数据表明,Tiny-CenterTrack 网络模型可以更快地收敛到稳定状态,在没有损失网络性能的情况下将训练时长缩减48.6%,有效节省了计算资源,并在实时性方面提高了8.8%。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
阅读与作文(英语初中版)(2019年8期)2019-08-27
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
中国新通信(2017年9期)2017-05-27
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
