
面向混部云失败批处理作业的预测算法*
2022-10-04 12:46林伟伟李毓睿刘发贵彭绍亮王子骏
国防科技大学学报 2022年5期
林伟伟,石 方,李毓睿,刘发贵,刘 捷,彭绍亮,王子骏
(1. 华南理工大学 计算机科学与工程学院, 广东 广州 510006; 2. 鹏程实验室, 广东 深圳 518066;3. 湖南大学 信息科学与工程学院, 湖南 长沙 410082; 4. 克莱姆森大学 计算学院, 美国 克莱姆森 29634)
2015 年,Google 发表论文介绍了Borg系统,其中就提到了在线服务作业与批处理作业的混合运行,也就是混部技术[1]。阿里巴巴作为全球最大的几家互联网公司之一,使用混部技术把集群混合起来,将不同类型的任务调度到相同的物理资源上,充分利用资源能力,极大降低成本。为了让业界深入了解混部集群的特征,阿里巴巴在2018年发布了混部集群的负载数据集cluster-trace-v2018(Ali Trace 2018)[2]。
混部集群最主要的问题是:在同一硬件上分配的工作负载越多,每个工作负载受到彼此性能干扰的可能性越大。阿里巴巴的混部生产集群作为一个多租户和多用途数据中心,其中的批处理作业具有高度分散的特点,由Fuxi调度器统一调度管理[3],批处理作业执行不成功的情况时有发生,这些执行失败的批作业将在集群中重复执行,被标记为重调度作业。这些失败作业消耗了不可忽视的资源,可能造成严重的性能障碍。因此,为了提高混部集群的可靠性和容错性,预测失败作业的发生是十分有必要的。为此,本文提出了一种用于预测失败批处理作业的算法。本文的主要贡献包括:
1)对失败作业的重调度现象进行了深入分析,发现失败作业不仅浪费了大量资源,而且会影响整个集群的工作状态,预测失败作业的发生十分有必要。
2)使用K-means聚类算法对批处理作业进行了聚类分析,发现不同资源负载类别的批处理作业发生失败现象的风险不同。
3)提出了一个针对混部集群失败作业预测算法,该算法包括特征工程以及基于LightGBM[4]的二层嵌套分类模型(two-layer nested classification model, TLNM)。首先通过分类预测LightGBM模型(classification prediction lightGBM-model, CPLM)将批处理作业分为四类,然后使用三种不同的异常预测LightGBM模型(anomaly prediction lightGBM-model, APLM)分别对三类批处理作业进行二分类预测,即预测该批处理作业是否会发生失败。实验表明,该模型能够准确地预测出失败批处理作业,且在时间性能方面优于其他模型。
1 相关工作
混部集群在提升资源利用率的同时,也带来了许多问题[5-8],例如,批处理作业长期受到在线服务容器的资源挤压,导致两种不同类型的任务在资源分配上的不平衡问题。Liu等[9]研究了半集装箱云的弹性和塑性。Chen等[10]在2018年对Ali Trace 2017进行了进一步的分析,采用K-means聚类算法对运行在阿里云集群中的负载进行了聚类,并研究了得出类别的属性的共同特征,同时给出了哪几类簇通常会分配到一台物理机执行。Guo[11]等的研究发现:在阿里巴巴的混部集群中,内存似乎成了新的瓶颈,限制了资源使用效率的进一步提升。
在云数据中心的失败任务预测方面,Rosà[12-14]等分析了Google大数据集群中失败任务带来的影响,并且提出了一个神经网络分类器来预测这些失败任务。此外,他们还开发了三种在线预测模型,这些模型可以将作业和事件在开始时分为四类。文献[15]则着重于早期阶段云任务的故障预测,提出了一种基于相似作业之间的关联关系的故障预测方法,可以在较早的阶段联合预测任务的终止状态。文献[16]则使用极限学习机对Google集群的云作业进行失败预测,可以根据作业到达的顺序收集实时数据,预测作业状态,并根据这些数据更新模型。Hemmat等[17]使用随机森林分类器对云中违反服务等级协议的作业进行了预测。Shetty等[18]分析了谷歌的生产集群中的任务资源利用率并且基于XGBoost分类器对集群中的失败作业进行了预测。Chen等[19]介绍了Google集群中失败作业和失败任务的统计特征,并尝试将它们与调度约束、节点操作以及云中用户的属性相关联,此外,他们还探索了早期故障预测和作业异常检测的潜力。
2 研究背景
2.1 阿里云混部集群介绍
图1描述了阿里巴巴公司的混部集群体系结构。托管的任务由两个调度程序协调管理:Sigma用于在线服务,而Fuxi用于批处理工作负载。其中在线服务作业运行于容器(Container)当中,而批处理作业则被Fuxi调度器拆解为批处理实例(Batch Instances),这些实例直接运行于物理机之中。
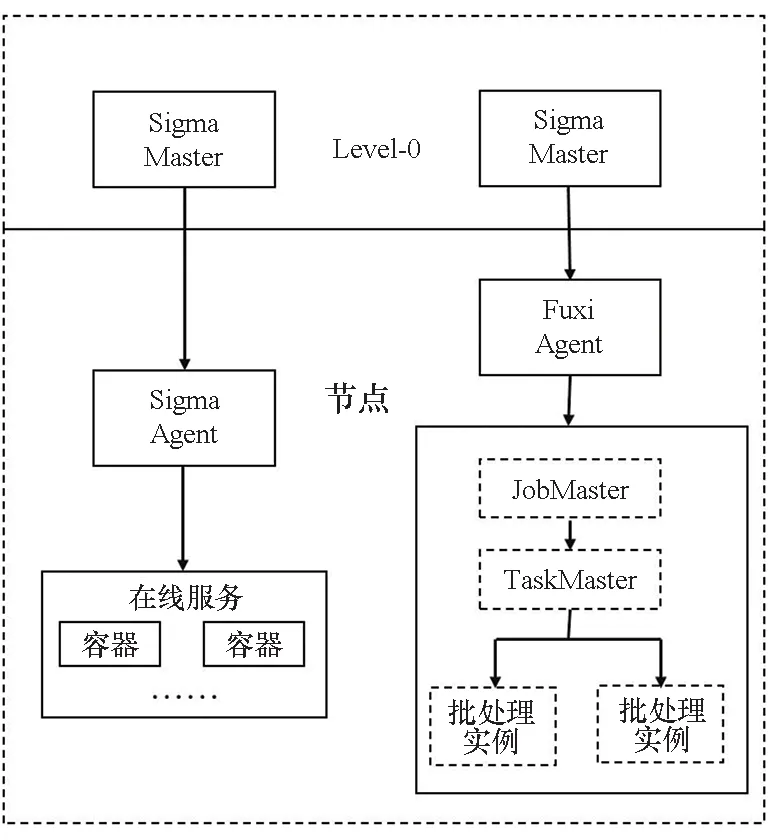
图1 阿里巴巴混部集群体系结构Fig.1 Architecture of Alibaba′s co-located datacenter
2.2 失败实例的重调度现象分析
在混部集群中,由于对共享资源的不可预测的干扰,当出现任何性能峰值时,出于对在线服务容器的资源保护,批处理作业可能会被延迟或驱逐。在阿里巴巴的集群中,当在线服务的性能受到影响时,Fuxi的代理将首先暂停批处理实例,如果仍然存在干扰,则将这些实例重新安排到另一个主机上。失败的实例将重试多次,直到成功完成为止。虽然批处理作业的失败率只有0.081%,但失败实例数达到了100万个,且20%的失败实例出现了多次重调度。此外,61%的失败实例在运行一段时间后重新调度,38%的失败实例在未运行的情况下重新调度,3%的失败实例需要很长时间才能完成有向无环图(directed acyclic graph, DAG)任务[11]。
表1列出了正常实例与失败实例在平均中央处理器(central processing unit, CPU)消耗、平均内存消耗和平均耗时之间的差异。通过对比表格中的数据可以发现,失败实例的CPU消耗高出正常实例约20%,内存消耗高出正常实例约150%,平均耗时约是正常实例的13倍。失败实例的资源浪费情况不容忽视。

表1 正常实例与失败实例对比
实例被重调度所浪费的CPU和内存时间可以假设如下:
1)设T为instance_A被重调度浪费的时间。
2)设(Mem,Cpu)为instance_A运行成功时平均内存、CPU消耗。
记TMem=T×Mem,TCpu=T×Cpu,那么向量(TMem,TCpu)为失败实例所浪费的资源。
以一个特定的实例(数据集中的ins_63835109)为例,图2为ins_63835109失败实例的生命周期示意。它首先在服务器m_1718上以时间戳373 421进行调度,然后在没有完成的情况下运行609 s。之后,它被重新调度到服务器m_177,并在时间戳374 031处开始运行,执行时间为1 196 s。那么374 031-373 421=610 s即为失败实例浪费的时间。ins_63835109的(Mem,Cpu)=(0.31,58),此实例由于重新调度而延迟了约10 min,所浪费的资源向量(TMem,TCpu)=(189.1,35 380)。

图2 失败实例的生命周期示意(以ins_63835109为例)Fig.2 Life of a failed instance (take ins_63835109 as an example)
图3和图4代表了失败实例所浪费的内存和CPU资源的累积分布函数(cumulative distribution function, CDF)图。由图可以观察到,大约超过一半的失败实例的内存资源浪费在100以上、CPU资源浪费在20 000以上(内存资源浪费量和CPU资源浪费量为标准化数值,每100内存表示消耗了一整台服务器的内存总量,每100CPU表示消耗了1个CPU核心),并且大多数失败实例浪费了大量资源。这种资源浪费在超大型数据中心是不容忽视的。虽然重调度这种动态机制保护了在线服务作业的性能,但它牺牲了批量作业的性能,间接地限制了资源效率。
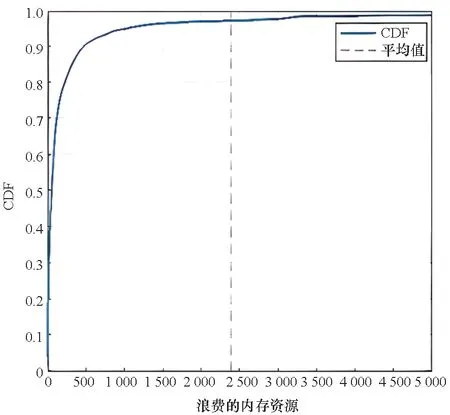
图3 内存资源浪费CDF图Fig.3 CDF of the memory wasted
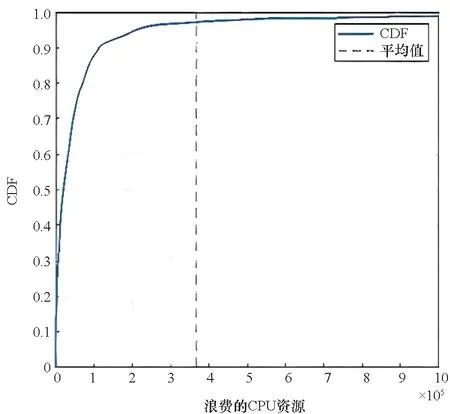
图4 CPU资源浪费CDF图Fig.4 CDF of the CPU wasted
2.3 不同类别批处理作业的失败现象分析
作为数据分析的一部分,本文对Ali Trace 2018中的批处理作业进行基于K-means的聚类与分析。本文发现了四种不同类型的批处理作业资源特征形式,而且不同类别批处理作业运行失败的风险也不同。
如表2所示,将批处理作业的平均耗时、CPU消耗、内存消耗与实例数量作为批处理作业聚类特征。在K=2,…,10中,取K=4时轮廓系数最高,为0.99。因此将批处理任务数据归为4类,每类批处理作业的资源负载特征如表2所示。
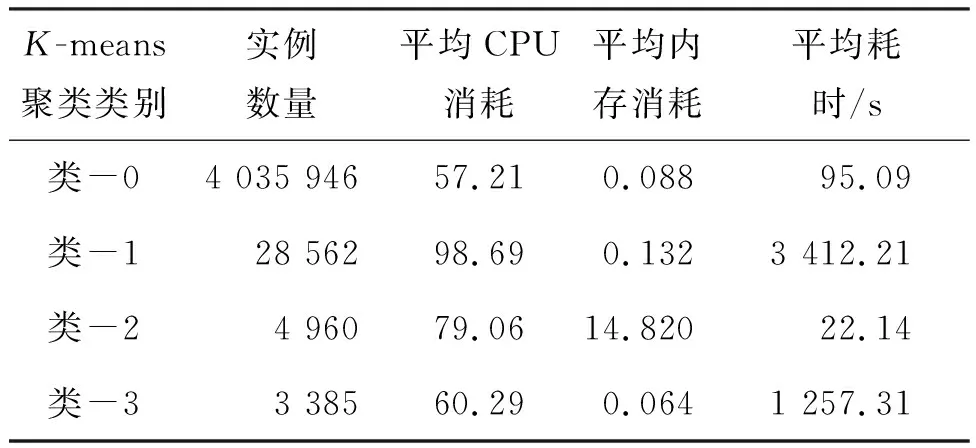
表2 不同类别批处理作业资源消耗特征
表3中列出了批处理作业各个资源画像类别中的失败作业数量与占比(失败作业表示该作业中有实例发生了重调度)。在4类批处理作业画像中,短时间运行的轻量级作业(类-2)是不会发生失败的;类-0由于簇内作业数量多,发生的失败作业数量也多,但是失败作业占比不到1%;类-1属于重量型作业,运行时间久、资源消耗多、实例数量多,因此约有3.3%的作业存在失败的情况;类-3属于长时间运行的轻量级作业,约有47%的作业存在失败的情况。

表3 不同资源画像批处理作业的失败现象
3 TLNM与基于TLNM的预测算法
为了提高混部云的可靠性与错误容忍性,本文提出了一个基于LightGBM的TLNM,并将TLNM应用在混部云的失败批处理作业预测中,实现了一个基于TLNM的混部云的失败批处理作业预测算法。
3.1 TLNM核心思想
机器学习技术被广泛应用于根据数据特征对异常点进行分类。一方面,线性分类器如支持向量机(support vector machine, SVM)或逻辑回归(logistic regression, LR)适合于表现(近似)线性关系的系统;另一方面,决策树(decision tree, DT)、随机森林(random forest, RF)和LightGBM等非线性分类器可以更好地对复杂系统建模。由于系统的高度非线性和不稳定性,本文开发了TLNM来提高分类精度。本文选择批处理作业进行失败预测,主要出于以下三个考虑:①批处理实例数据量较大,训练模型耗时过长,且不具有代表性;②通过数据分析发现,失败批处理作业中的某个实例一旦发生重调度现象,将会导致该批处理作业中其他实例也发生重调度;③批处理作业作为混部集群中各个实例的代表,可以由Fuxi调度器进行实时数据采集,可以设计实时预测系统。
前文第2节讨论了不同类别的批处理作业所表现出的失败现象,其中短时间运行的轻量级作业中并没有出现失败作业,而其他画像中的失败作业比例有很大不同。因此, TLNM的核心思想是对批处理作业进行多分类后,再进行失败预测。TLNM中有四个子模型,分别是一个CPLM和三个APLM,如图5和图6所示。其中CPLM和APLM独立工作:首先将批处理作业按照画像不同进行分类,这是一个多分类问题;然后按照不同的资源画像类别调用不同的APLM进行第二次预测,这是一个二分类问题。为了避免过度拟合偏差,通过一个由20%的作业证组成的独立验证集来交叉验证预测的准确性。

(a) CPLM

图6 TLNM组织架构Fig.6 Architecture of TLNM
3.2 基于TLNM的预测算法
由于混部云中存在混部干扰,而混部云的数据集无法充分暴露出混部干扰情况,因此需要构造一个完整的特征数据集来配合TLNM进行失败任务预测。本小节提出一个针对阿里云失败作业的预测算法,包括针对阿里云的混部特征提取算法(特征工程)和TLNM预测。算法1是混部特征提取算法的伪代码描述。以Ali Trace 2018为例,首先根据batch_instance表格中的machine_id字段找到该实例所运行的物理机ID;再根据该machine_id匹配machine_usage表格和container_usage表格,从这两个表格中找到本文需要的特征数据;然后将本文找到的物理机状态数据与容器的运行状态数据结合,形成当前实例的混部特征数据;最后再根据当前实例的混部特征数据中的job_name字段,将实例的混部特征数据整理成批处理作业的混部特征数据。该算法的时间复杂度为O(t·N),t为每个实例所需要的处理时间。

算法1 混部特征提取算法

图7 基于TLNM的预测Fig.7 TLNM based prediction
如图7所示,本文首先对混部云数据集进行混部特征提取,制作出混部特征数据集作为TLNM的输入数据集,然后对混部特征数据集进行基于TLNM预测算法的分类预测。算法2是基于TLNM的预测算法伪代码描述,TLNM首先使用混部特征数据集中的部分字段(批处理作业的平均耗时、CPU消耗、内存消耗与实例数量)进行批处理作业分类预测,然后再对分类后的批处理作业分别进行异常预测,得到预测结果,即失败作业集。该算法的时间消耗主要在模型的训练上,因此该算法的时间复杂度为O(nlogn·m·d),其中n是训练样本个数,m是特征个数,d为梯度提升迭代决策树(LightGBM也是其中一种)的深度。
4 实验评估
4.1 主要评估指标
接受者操作特性(receiver operating characteristic, ROC)分析是一种直观评估一个或多个分类器准确性的方法,并且不受不平衡数据集的影响。如表4的混淆矩阵所示,如果进行预测,会出现四种情况,即:实例是正类并且也被预测成正类,即为真正类TP(true positive);实例是负类而被预测成正类,称之为假正类FP(false positive);实例是负类且被预测成负类,称之为真负类TN(true negative);实例是正类而被预测成负类,称之为假负类FN(false negative)。

表4 混淆矩阵
1)TPR=TP/(TP+FN)表示当前分到正样本中真实的正样本占所有实际正样本的比例,即召回率;
2)FPR=FP/(FP+TN)表示当前被错误分到正样本类别中真实的实际负样本占所有负样本总数的比例;
3)精确率=TP/(TP+FN),它的含义是在所有被预测为正的样本中实际为正的样本的概率。
对于ROC来说,横坐标就是FPR,纵坐标就是TPR,当 TPR越大,而FPR越小时,说明分类结果是较好的。在样本不均衡的情况下, ROC曲线仍然能较好地评价分类器的性能,这是ROC的一个优良特性,也是一般ROC曲线使用更多的原因。除了ROC曲线的图形化评价外,还可以通过测量曲线下的面积(area under curve, AUC)来量化分类器的准确性。从直观上看,AUC越接近1,分类器就越准确,一个完美分类器的AUC等于1。
在本节的实验评估中,本文主要参考ROC曲线、AUC和召回率来证明TLNM在对比的分类器中具有最好的性能。
4.2 混部特征提取算法实验
为了说明特征工程的重要性,本文评估了TLNM算法在不同的特征数据集上的表现。本次实验使用的两个数据集分别为表2所示的批处理作业四个特征(平均CPU消耗、平均内存消耗,平均耗时和实例数量)构成的数据集与混部特征数据集。表5所示为经过混部特征提取算法的数据集与普通批处理作业数据集实验效果对比结果。通过混部特征提取算法之后,将预测的AUC值从0.62提升到0.98,召回率从0.37提高到0.95。
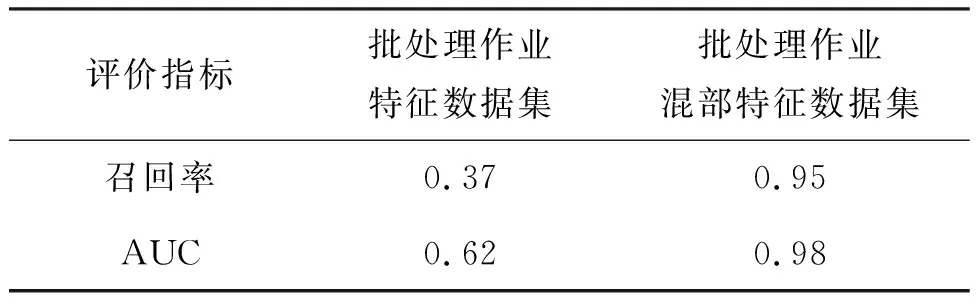
表5 TLNM算法在不同数据集上的表现
除了对比TLNM算法在不同数据集上的表现之外,本文还使用SHAP[20]工具来对特征重要度进行了进一步解释。SHAP是基于Python开发的一个“模型解释”包,可以解释任何机器学习算法的输出。其名称来源于SHapley Additive exPlanation,作者在合作博弈论的启发下构建了一个加性的解释模型,所有的特征都视为“贡献者”。对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。SHAP value最大的优势是能反映出样本中每一个特征值对预测结果的影响力,而且还表现出影响的正负性。
图8所示为混部特征数据集中各个特征的SHAP value。其中对模型预测结果影响最大的特征为批处理作业的运行时间(run_time),影响最低的两个特征分别为容器数量(container_num)和物理机内存利用率百分比(machine_mem_util_percent)。出于篇幅考虑,在此并未对每个特征的含义加以说明。图9绘制了各个特征对算法输出的影响,由点构成,每个点有三个含义:①点的竖直坐标是说明它属于哪个特征;②点的颜色代表了这个特征的数值是高还是低;③水平位置代表了这个特征在某一行数据里是提高预测值还是降低预测值。比如run_time行中最右侧的红点,说明了运行时间长的某个特征点,预测效果的SHAP value为0.75左右,提高了预测值。通过SHAP分析可以发现,对算法影响最大的是run_time这个特征,值的大小与预测的结果呈正相关性。

图8 模型中各个特征的SHAP valueFig.8 SHAP values for each feature in model

图9 每个特征对模型输出的影响Fig.9 Impact of each feature on the model output
4.3 TLNM算法与其他分类器的对比
在本小节中,通过比较TLNM算法和其他常用分类器(RF、SVM、LR、DT)在混部特征数据集上的表现,以说明TLNM算法的优势所在。从图10可以清楚地看出,TLNM算法的ROC曲线明显高于其他分类器,且AUC最高,不仅AUC接近1(取值0.978),而且与其他分类器之间的AUC也存在明显的差距。除了TLNM算法之外,第二好的分类器是RF,AUC指标为0.878,其次是DT。DT与RF的AUC相近,两者具有可比性。召回率方面,TLNM的召回率明显高于其他分类器,在高度不平衡的数据集中精确预测出所有可能运行失败的批处理作业。TLNM算法在测试数据集上预测结果的混淆矩阵如表6所示,在4 153个失败作业中准确预测出了3 948个失败作业,但是错误地把正常的48 859个批处理作业也当成了失败作业。

(a) TLNM算法与其他分类器ROC曲线(a) TLNM algorithm versus different classifiers on ROC curves
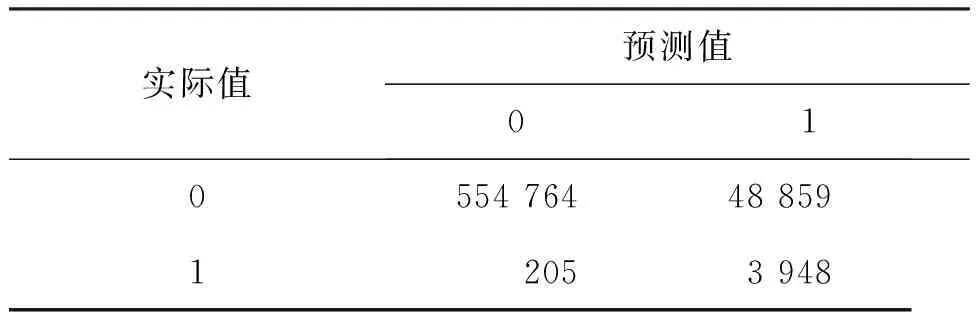
表6 TLNM算法的混淆矩阵
表7列出了TLNM算法与不同分类器在训练时的时间性能,所有训练均在同一台服务器(Intel (R) Xeon(R) CPU E5-2620 v2 @ 2.10 GHz,112 GB内存)上进行。在时间性能方面,TLNM算法中所有的模型训练时间总计为72.36 s,优于其他所有分类器。DT的训练时间为158.19 s,是时间性能表现第二佳的模型。花费最高的模型是SVM,训练时间达到1 381.72 s。

表7 不同分类器的时间性能对比
5 结论
在一个超大型数据中心中,作业运行失败的现象时有发生,本文对批处理作业的失败现象进行了深入分析,结果发现重调度现象会造成大量资源浪费。此外,为了更准确地预测出混部集群中的失败现象,对批处理作业进行了基于K-means的聚类分析,将批处理作业分为4个类别,发现不同类别的批处理作业发生失败现象的风险不同。在此基础上,提出了一种用于预测混部集群中批处理作业失败现象的二层嵌套分类模型TLNM,并开发了基于TLNM的混部云失败作业预测算法。评估结果表明,与其他分类器(LR、SVM、DT、RF)相比,TLNM算法的分类结果更优,AUC值达到最高的0.978,召回率也达到最高的0.951。总的来说,本文的研究有助于提高混部集群的资源利用率和错误容忍性,本文的预测算法允许调度系统做出主动决策。例如,基于本文预测算法的资源感知调度可以进行资源优化,通过在预测服务器上标记出可能发生失败现象的批处理作业,可以提前调整批处理作业的优先级或者暂停该作业,以优化超大规模混部集群的资源配置。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
科学导报·学术(2020年84期)2020-11-08
电子技术与软件工程(2019年18期)2019-11-18
电脑爱好者(2019年1期)2019-10-30
电脑爱好者(2017年18期)2017-11-03
电子技术与软件工程(2017年14期)2017-09-08
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
计算机应用文摘·触控(2009年15期)2009-09-27
