
面向空间兴趣区域的路线查询
2022-11-12 11:28刘俊岭刘柏何邹鑫源孙焕良
计算机研究与发展 2022年11期
刘俊岭 刘柏何 邹鑫源 孙焕良
(沈阳建筑大学计算机科学与工程学院 沈阳 110168) (辽宁省城市建设大数据管理与分析重点实验室(沈阳建筑大学) 沈阳 110168)
广泛的位置感知应用产生了大量的空间文本数据,如用户的签到数据和评论、带有地理标记的帖子以及商业平台的基于位置的广告等,扩展了路线规划问题.结合空间文本数据,产生了符合用户给定关键字相关约束的路线查询问题[1-3].
现有的应用空间文本查询路线的研究,通常返回1条由空间兴趣点(point of interests, POI)组成的路线,每个POI是单独的空间对象[4-7].由于实际应用中POI及相关的空间关键字是海量的,并且POI的分布通常严重偏斜,使得多条路线通过相同的聚集区域,导致查询结果相似性较高,无法满足用户对于结果多样性的需求.同时路线查询需要遍历每个POI及相关的空间关键字使得查询算法的效率较低.
图1(a)为空间关键字POI路线查询示例图,其中曲线代表轨迹、实心圆代表POI点.假设查询起点为p1,给定路线长度约束及空间关键字集合,以最大化关键字收益和为目标可以得到2条路线,分别为A1(p1→p4→p5→p6)和A2(p1→p3→p5→p6).从示例中可以看出路线A1与A2存在多个重叠结点,导致路线间的相似性较大.当存在大量的POI及相关的空间关键字时,增加了搜索空间,影响了查询算法的效率.
本文提出了面向空间兴趣区域的路线查询(region of interests oriented route query, ROIR)问题.给定一个反映用户转移关系的图G、带有关键字的POI集合P及查询QU(v0,C,r,L),其中v0为查询起点,C为关键字集合,r为一个兴趣区域半径,L为路线的长度限制.ROIR返回满足长度L约束,关于关键字集C收益和最大的路线Ares,路线Ares的每个结点为一个兴趣区域.如图1(b)所示,在与图1(a)相同的查询条件下可以得到查询结果Ares(D1→D2→D3→D4),该结果由半径为r的兴趣区域序列组成,包含了图1(a)中A1和A2这2条路线.
与现有的POI路线查询相比,ROIR返回路线的结点为兴趣区域,包含了多个邻近的POI,降低了路线的相似性,增加了用户的选择空间,使得查询结果有更好的适用性.同时ROIR结果包含多条POI路线,提高了查询效率.ROIR适用于海量分布的POI及空间关键字场景下的关键字偏好路线查询,同时ROIR也适用于结伴出行情况,允许用户在兴趣区域内分别访问各自偏好的地点.
本文将空间路线查询对象由POI扩展为兴趣区域,存在的主要挑战包括:1)如何有效组织多种类型的海量POI及相关空间关键字是一个挑战.本查询涉及用户的空间转移关系、空间对象及对象的文本描述等多种数据类型.2)如何设计支持ROIR的高效算法是另一个挑战.需要建立适用于所提出查询的索引结构.ROIR是一个NP难问题,需要设计相应的高效近似算法.
为了应对以上2个挑战,本文提出一种2层数据组织模型.其中上层为反映用户转移关系的图结构,结点概括抽象了POI的聚集区域;下层为细节的POI数据及相关空间关键字信息.针对提出的空间数据组织模型,提出了综合空间对象、转移关系以及空间关键字等信息的索引结构,同时预计算了空间关键字的局部收益的统计值,并以签名方式存储在转移结点上.利用所提出的索引结构,设计了过滤—提炼2阶段ROIR精确算法以及近似算法.
本文工作的主要贡献有3个方面:
1) 定义了面向空间兴趣区域的路线查询问题,解决了现有关键字路线查询中多样性不足问题,提高了路线查询的适用性.
2) 设计了结合上层转移图与下层POI对象及相关空间关键字的2层数据组织模型.针对2层模型提出一种新的索引结构,并设计了面向空间兴趣区域的路线查询优化算法.
3) 利用真实数据集进行了详细的实验分析,评估了所提出算法的有效性.
1 问题定义
给定一个空间D、兴趣点集合P,任何一个点p∈P表示为p(p.id,p.loc,p.C),其中p.id是p的唯一身份标识,p.loc是点p的空间坐标,p.C是点p含有的关键字及其流行度的集合.对于一个兴趣点的某个关键字p.c∈p.C,收益分值p.Sc代表点p中关键字c的流行度,可用用户的访问次数表示.
转移图G(V,E)是用户在空间上轨迹转移的概括表示,反映了结点间用户流行的转移关系,其中V为结点的集合,E为边集.任意结点v∈V代表兴趣点聚集的中心点,定义为(v.id,v.loc),其中v.id是v的唯一身份标识,v.loc是结点v的空间坐标;任意边e∈E代表V中2个结点vi与vj间的转移关系.转移图的生成方法将在2.1节中介绍.


(1)

(2)

查询实例如图2所示,假设查询关键字集合为C={a,b,d,e,f}.长度约束L=17,区域半径r=2,查询起点为v1.

Fig. 2 The example of ROIR图2 ROIR实例
对于传统POI路线查询,例中针对查询关键字集合C的最优结果为序列A2(p1→p4→p5→p6),序列收益分数为29.然而,对于ROIR最优路线为A1(v1(D1)→v3(D2)→v5(D3)→v7(D4)),其收益为33,高于POI路线的收益.由定义1可知,ROIR属于空间关键字偏好的路线查询,将关键字的收益和作为优化目标.
由实例可以看出,所提出的ROIR可以提高路线的收益值.由区域组成的路线,提高了原有单个POI结点的多样性,起到对多个相似路线聚集的作用.另外,在转移图上按兴趣区域查询也可以提高查询效率.
实现ROIR是一个具有挑战性的工作.由实例可知,本查询涉及POI点、图结构以及文本信息等多种类型的数据,并且实际应用中数据具有海量性,需要对数据进行有效的组织与设计相应索引以支持查询.同时所定义的查询在转移图上进行搜索是NP难问题.假设每个结点的出度为λ,即经过结点后有λ条路可选择,在长度约束L下可以经过的结点个数为n,则代价为λn,若结点上含有关键字个数为m,则最终代价为(m·λ)n.因此,ROIR问题是NP难问题.表1简要概述了本文所使用的符号.

Table 1 Symbol Summary表1 符号总结
2 查询处理算法
本节介绍数据组织与索引结构,以及精确查询算法和近似查询算法.
2.1 数据组织与索引结构
为了有效地处理多类型的海量数据,考虑将POI及相关空间关键字密集且流行度高的区域聚集,并从具体的细节数据中分离出来,以提高查询路线的多样性和算法查询效率.因此,提出一种2层数据组织结构,如图2所示.图2中,上层为转移图,由轨迹的交叉区域提取或是密集POI点聚集生成;下层为具体的POI及其关键字信息,路线的关键字收益得分由下层数据提供.
本文首先利用用户轨迹数据,采用文献[4]的方法提取了转移图.同时,添加一些流行度高且远离现有结点的POI聚集点,采用了基于网格密度聚类的方法产生增加的聚集点[8].首先将空间网格化,统计单元格内点的数量并对稠密的单元格进行聚类;然后计算转移结点所在单元格与聚类后的单元格的转移数量,数量超过一定阈值即可生成一条转移边;最后提取聚集网格的中心点加入转移图.
针对提出的2层数据组织模型,本文借鉴文献[9]对交通网络的索引结构,并引入关键字签名,提出了结合空间文本索引与转移图结构的索引结构,命名为BIR(balance information tree).如图3所示,索引结构由3部分组成,第1部分为扩展的B+树结构,存储了转移图上的结点、邻接表以及关键字的概要签名信息,对应于图2中上层数据结构;第2部分为IR树结构,用于存储POI点空间位置及其文本信息,对应于图2中下层数据结构;第3部分为图结点与空间最小边界矩形MBR的关系表,用于连接IR树与B+树这2个索引,实现图结点到其所在MBR的联系.

Fig. 3 BIR index structure图3 BIR索引结构
IR树结构中使用签名存储2层结构中底层的POI点信息,底层结点存储POI点包含的关键字及分值,非底层结点{E1,E2,…,En}称为中间结点,代表IR树中由结点组成的矩形区域MBR.中间结点的签名由多个叶子结点的签名计算得到,为该区域内叶子结点的关键字与其最大分值.
扩展的B+树结构中每个结点存储2部分内容,分别为结点邻接表和关键字范围签名(命名为r签名).邻接表存储一个结点所有邻接结点的信息,图3中v1结点的邻接表由邻接结点v2,v3,v4组成,v1邻接表的第1行v2,5,ptr2表示v1邻接到v2,5为2点间的距离,ptr2指向v2在B+树中叶子结点的位置.
关键字范围签名存储了以结点为中心多个同心圆周范围内的关键字收益的最大值信息.图3中签名的每一列对应不同的半径r.例如,以v2结点为中心的r签名中,当r1=400 m时,(p8,p9,p10)包含在范围400 m内,取这些POI点的关键字的最大收益值,可以得到{0,2,1,2,0,0}作为签名表的1列.


(3)
文献[10]给出适宜步行距离的结论,即在787 m的步行距离以内,用户选择步行出行的可能性超过10%.本文选取1 000 m作为r的最大值,在该范围内用户选择步行分散访问所偏好的空间对象.通过预计算的r签名可以初步估算路线收益值,从而过滤大量的结点,减少候选路线的数量.
转移图结点与空间MBR关系表存储转移结点与其所在空间的MBR位置关系,分别记录了指向B+树中转移结点的指针,以及结点位置在IR树中所属MBR的指针.
由于提出的索引结构为离线构建并存储在磁盘中,索引建立的时间不会影响查询效率,因此只需分析索引的空间代价.空间代价由3部分组成:第1部分为转移图结点的B+树存储,代价为|C|×nr×h,其中|C|为关键字类别数,nr为r签名的列数,h为B+树高度;第2部分为POI点的IR树存储,代价为|C|×(|P|-1)/(mR-1),其中mR为IR树最大扇出,|P|为POI集合的大小;第3部分为图结点与空间最小边界矩形MBR的关系表,代价为NG×(|P|-1)/(mR-1),其中NG为转移图结点数.由于转移图结点数NG远小于POI数|P|,则总的空间代价为O(|P|).
2.2 ROIR精确算法
基于所提出的索引结构,本文设计了一种过滤—提炼2阶段精确查询算法,如算法1所示.算法1在过滤阶段利用上下界剪枝,过滤掉不可行解,减少对IR树的访问;在提炼阶段采用best-first方式,优先选择高收益的解,从而提高算法查询效率.
算法1.ROIR路线查询精确算法Region.
输入:QU(v0,C,r,L),由G和P建立的索引BIR;
输出:收益最高的一条路线Ares.
①A={v0},A.last=v0,LIST={};
② for (A.last未访问的邻接点v)
③ if (dist(A.last,v)+A.L>L)
④ if (Mupper(A)>Mmaxlower(LIST))
⑤LIST=LIST∪A,更新
Mmaxlower(LIST);
⑥ 删除上界分值小于Mlower(A)的路线;
⑦ end if
⑧ else
⑨A=A∪{v},A.last=v;
⑩DFS(Q,BIR,A);
算法1的过滤过程在扩展的B+树上执行如行①~所示.算法1递归调用算法2执行深度优先搜索,不断扩展路径长度,直到其满足长度约束,返回一条候选路线并计算其上下界收益值.如果生成的候选路线A的上界得分高于候选列表中路线的下界得分,需要用路线A更新候选列表,实现对候选路线的剪枝(行③~⑦),更新方法的正确性由定理1及推论1,2保证.提炼阶段在IR树上执行,如行~所示.初始计算LIST中的一条候选路线的精确收益值(行),然后用此路线精确收益对候选进行剪枝.若候选路线的精确得分高于当前最优路线的得分,则用此路线更新最优路线(行~).
算法2.DFS(Q,BIR,A).
① for (A.last未访问的邻接点v′)
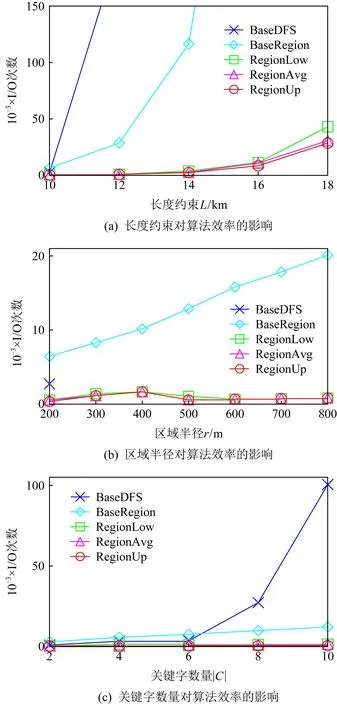
② if (A.L ③A=A∪{v′},A.last=v′; ④DFS(Q,BIR,A); ⑤ else returnA; ⑥ end if ⑦ end for 定理1.已知2条路线A和A′,当A的下界收益值Mlower(A)大于A′上界收益值Mupper(A′)时,即Mupper(A′)≤Mlower(A),则可用A剪枝A′. 定理1说明了给定2条路线A和A′,当Mupper(A′)≤Mlower(A)时路线A的实际收益值一定大于路线A′的实际收益值,则可用A剪枝A′. 算法1定义了一个存储候选路线集LIST,LIST中各候选路线应满足性质1. 性质1.LIST中的任意候选路线的上界收益都大于所有其它候选路线的下界,其下界都小于所有其它候选路线的上界. 性质1说明当LIST用于返回一个具有最高收益的结果时,LIST中候选路线收益范围是交叠的.为了便于算法剪枝,将LIST中的路线按下界收益值降序排列,将最大下界与最小下界收益值分别表示为Mmaxlower(LIST)与Mminlower(LIST).由性质1可以得出推论1与推论2,用于对候选路线的剪枝. 推论1.已知候选路线集LIST,对于任意一条新的候选路线A,若Mupper(A)≤Mmaxlower(LIST),则可以将A放弃. Fig. 4 The figure of routes in candidate set图4 候选集路线示意图 图4(a)为推论1的情况示例,A1~A4是LIST中的候选路线,纵轴为收益值,分别含有上下界收益,Mlower(A1)即为Mmaxlower(LIST).A是新的候选路线,Mupper(A) 推论2.已知候选路线集LIST,对于任意一条新的候选路线A,满足Mupper(A)>Mmaxlower(LIST),需要将A插入到LIST中.路线集LIST中任意路线A′,如果Mupper(A′)≤Mlower(A),则可将路线A′剪枝. 如图4(b)所示,路线A的上界收益值大于A1的下界收益值,可插入到LIST中.然而,在候选路线集LIST中存在路线A2和A4,Mupper(A2)≤Mlower(A)及Mupper(A4)≤Mlower(A)时,A2和A4被剪枝.利用推论2实现对LIST剪枝见算法1行⑥. 在提炼阶段,优先选择可能有较高精确收益值的候选路线,获得的精确值有利于对剩余候选路线的剪枝,从而减少IR树的访问次数.因此,本文分别采用最大上界收益值优先、最大下界收益值优先、最大平均收益值优先3种策略选取路线.实现时只需更改算法1的行即可.算法1中输入C为空间关键字集合,当实际应用中需要考虑关键字访问顺序时,可以在算法的提炼阶段中增加访问顺序作为过滤条件来实现. 通过分析可知,本文算法在过滤阶段的复杂度级别与POI点序列路线查询算法同为(mλ)n,在提炼阶段,假设剪枝后的路线为x条,每条路线的结点数依旧为n,结点范围内POI点的个数为n′,代价为n′xn,因此算法总代价为(mλ)n+n′xn,可表示为O((mλ)n).然而,由于算法过滤阶段是在转移图上进行,图中结点概要了底层POI点相关信息,因此显著降低了n的大小,从而降低整个算法代价. 由于ROIR是一个NP难问题,为了有效地实现该查询,提出了近似路线查询算法.ROIR的近似查询利用近似收益代替精确收益.路线Ares的近似收益值由式(4)计算: (4) 为了减少提炼过程的查询代价,仅保留上层空间转移图用于查询,由于转移结点上不存储精确的关键字收益值,仅在r签名存储固定区域内的关键字分值信息,查询结果返回区间收益而不能得到精确收益值.本文采用近似的方法估计转移结点在某关键字上的收益值,基本思想假定收益与圆周面积成正比,关键字近似收益如定义2. 定义2.r签名关键字近似收益.已知转移结点vj中某一关键字的下界与上界收益值分别为Si和Si+1,且ri (5) 数据组织模型只保留了上层转移图,对应的索引结构也只保留了扩展的B+树,同时设计了新的签名存储于树上的每个结点之中,索引结构命名为签名B树(balance tree with signature, BTS).以B+树为基础扩展了结点的信息,每个结点存储3部分内容,包括邻接表、r签名和长度约束签名(称为L签名).长度约束签名存储在转移图上,存储以当前结点为起始点、长度为L约束下经过的所有结点关键字的最大收益值,且半径L等间隔递增.由于转移图上结点间的距离大于r签名的半径,因此被圆周包含的结点的关键字收益值由r签名半径最大一列的收益值表示. 定义3.L签名关键字近似收益.已知转移结点v在L签名上某一关键字的下界与上界收益值分别为Si和Si+1,且Li (6) 定义4.路线预期收益.已知当前查询路线A,在剩余长度约束L下路线访问结点v时,路线预期收益为各个关键字已获与可获收益值之间的最大收益值之和,由查询路线A得到各关键字已获取的收益值,由结点v得到剩余长度下各关键字可获取的收益值,如式(7)所示: Mexp_Q(A,v)= (7) 算法3是查询一条近似路线的算法,当起始点的邻接点未全部访问时,每次优先访问收益最大的邻接点v(行②③).若路线满足长度约束,需要计算该路线的近似收益MQ(A′),并与候选路线A的近似收益MQ(A)进行比较,若当前路线的近似收益大于候选路线的近似收益,则当前路线是更优的结果,需要对候选路线进行更新(行④~⑦);若不存在候选路线,当前路线是通过best-first方法搜索出的最优路线,因此直接加入候选解中.每次比较候选路线后,需要将当前路线最后一个结点弹出并标记(行⑧⑨).当搜索长度小于约束条件时,将结点加入路线中并通过深度优先搜索(DFS)过程获取可行路线(行⑩~),与算法2类似.若路线当前结点的所有邻接点都已经被访问,将该结点从路线中删除,直到起始点的邻接点都被标记(行). 算法3.ROIR近似查询算法r-RegionApprox. 输入:QU(v0,C,r,L)、基于图G建立的索引BTSG; 输出:一条近似收益最高的路线A. ①A′={v0},A′.last=v0,A={}; ② while (A′不为空) ③ for (A′.last中未访问的邻接点v) ④ if (dist(A′.last,v)+A′.L≥L) ⑤ if (MQ(A′)>MQ(A)) ⑥A=A′; ⑦ end if ⑧vtag=A′.pop(),标记vtag; ⑨A′.last=A′.top(); ⑩ else 定理2.当一条路线A′访问到结点v时,其预期收益值小于路线A的近似收益值时,即Mexp(A′,v) 证明.当Mexp(A′,v) 证毕. 本节提出的近似ROIR,利用面积近似的方法计算路线收益值,返回结果较优的路线.采用近似的方法代替提炼过程,减少了访问IR树的I/O操作,加快了查询效率. 定理3.近似路线查询算法的收益近似率为1/ε. 证明.假设查询结果Ares,满足长度约束L,查询半径为r,查询的关键字集合为C,Ares包含n个转移结点,近似率为 (8) (9) (10) (11) 则存在 (12) 证毕. 本节对所提出的ROIR精确算法及近似算法进行实验评估. 实验采用北京市75 963条POI数据和北京市2012年10月、11月这2个月的出租车上下车数据.本文选择了宾馆、餐饮、大厦、商场、休闲娱乐等10个类别作为实验数据的关键字. 实验中类别的偏好值利用高斯函数赋值.以北京市天安门为中心,采用高斯分布为不同区域范围内的POI点赋值,从二环以内到五环以外期望值分别为8.0~2.0,标准差为1.0~3.0.将用户轨迹与近邻POI进行匹配,利用轨迹的转移关系生成转移图,通过设置区域间距大小及POI点的密度补充转移图中结点的数量.通过设置连通数的数量筛选轨迹,剪去流行度低的路线,利用长度限制剪枝结点间距离较远的路线. 本文结合现有算法设计实现了2个基准算法的ROIR,利用3种优化策略实现了相应的优化算法,比较了这些算法的收益值及查询效率,其中查询效率用I/O次数度量.各算法如下. 1) BaseDFS.文献[3]处理top-k空间多样性问题,本文采用DFS实现了top-1路线查询,作为比较算法,命名为BaseDFS.该算法在获得转移图上候选路线后,以路线各转移结点为中心,查询范围r内POI序列是否符合查询结果. 2) BaseRegion.利用文献[1]中过滤—提炼查询2阶段方式实现,实现无r签名优化的空间兴趣区域路线查询算法,在过滤阶段返回所有候选路线集,在提炼阶段求得路线精确收益值并选取收益值高的路线返回. 3) Region.本文提出的ROIR算法,该算法利用r签名在过滤阶段采用上下界收益值剪枝方法获取候选路线集,在提炼阶段遍历IR树比较求得最优路线,见算法1. 4) RegionLow,RegionUp,RegionAvg.这3个算法是在Region算法基础上采用下界收益值优先策略所实现的算法.算法在提炼阶段分别按候选路线的下界收益值、上界收益值、上下界收益值的均值从大到小次序访问IR树,对收益值进行精确计算并剪枝求得最终结果. 3.2.1 路线收益比较 本节比较了在长度和关键字数量变化的情况下,BaseDFS算法和Region算法的收益值. 图5(a)比较了长度约束对路线收益的影响,给定关键字约束{宾馆,餐馆,商场,商务中心,娱乐},各算法随着长度的增长,收益均呈上升趋势.其中,BaseDFS算法的收益值最低,Region算法的收益值最高.在r从200~800 m变化时,r越小,收益值越趋向于BaseDFS算法收益值;r越大,收益值趋向于800-Region算法收益值.随着长度增长,查询返回一条路线所包含的转移结点增多,算法收益值也会增大.BaseDFS算法返回的是POI点组成的序列路线,Region算法返回的是区域组成的路线,增大了解空间,收益值高于BaseDFS算法的收益值.另外,随着区域半径r的增大,区内包含的POI数量不断增多,算法整体收益值的差距较小. Fig. 5 Profit comparisons of the exact algorithms图5 精确算法收益比较 图5(b)比较了关键字数量对路线收益的影响,给定起始点,路线长度约束L=10 km,各算法的收益值均随着关键字数量的增多而增大.对于BaseDFS算法,每个POI点仅包含一个关键字,路线收益值来源局限于单个POI点;而Region算法利用区域对象代替点对象,区域中包含不同关键字的数量增多,使得一个区域可以提供多个关键字的收益值.因此当区域半径越小,涵盖的POI点越少,则收益越小,区域半径越大,则收益越大. Fig. 6 Effects of different constraints on algorithms efficiency图6 不同约束条件对算法效率的影响 Region算法在各类约束条件下,由于利用区域的方式扩展了POI点的数量,因此较BaseDFS算法能够获取更高的收益值.图5也验证了Region算法在路线收益值方面的优越性. 3.2.2 算法效率比较 图6是不同约束条件对算法效率的影响比较,算法效率由I/O次数度量,I/O次数越少,算法效率越高.图6(a)~(c)分别为长度约束、区域半径、关键字数量对算法效率的影响.图6(b)中当区域半径大于300 m时,BaseDFS算法由于其代价过高无法完成路线搜索.结果显示本文设计的优化算法效率均高于基本算法的效率,对比BaseDFS算法,优化算法利用兴趣区域减少了访问结点的数量;对比BaseRegion算法,本文算法设计了签名信息用于剪枝路线,减少了候选路线的数量.结果显示,RegionUp算法效率高于RegionAvg,RegionLow算法效率. 对于近似路线查询算法,本节将BaseDFS算法、BaseRegion算法、Region算法和RegionUp算法作为比较算法,比较算法的收益值及效率.RegionApprox是本文提出的算法,见算法3. 1) 近似路线收益比较 本节比较了长度及关键字数量变化情况下BaseDFS,Region,RegionApprox算法的收益,如图7所示,关键字为{宾馆,餐馆,商场,商务中心,娱乐},长度约束L=10 km,半径r=200 m. Fig. 7 Profit comparisons of approximate algorithms图7 近似算法收益比较 图7(a)是长度约束下的路线收益比较,结果显示长度越长,路线收益越大.Region算法的收益值最高,RegionApprox算法的收益值接近Region算法的收益,BaseDFS算法的收益值最低.图7(b)是不同关键字数量下的路线收益比较,结果显示关键字数量的增多会使得收益值增大,收益值由大到小排序分别是Region,RegionApprox,BaseDFS算法. Fig. 8 Efficiency comparisons of approximate algorithm图8 近似算法效率比较 2) 近似算法效率比较 本节比较了长度约束L、区域半径r及关键字数量|C|的变化下,BaseDFS,BaseRegion,RegionUp,RegionApprox算法的总I/O读取次数,如图8所示.默认设置长度约束L=10 km,半径r=200 m,关键字为{宾馆,餐馆,商场,商务中心,娱乐}.由图8(a)~(c)表明算法的总I/O读取次数均随约束条件的变化呈上升趋势,且RegionApprox算法的效率最高. RegionApprox算法利用B+树中签名的近似收益值作为解,只保留了过滤阶段的操作而不再执行提炼阶段的操作,减少了转移图上结点在IR树中的I/O次数. 本节介绍空间关键字查询、偏好路线查询等相关工作. 空间关键字查询返回满足文本约束与空间位置要求的结果,文本约束以关键字集合表示[11-12].空间关键字查询可分为POI对象查询[13-14]、组对象查询[15-16]、区域查询等[17-21].其中,POI对象查询返回单个POI对象满足查询关键字需求,包括满足关键字集且距离最近的k个对象的布尔kNN查询、返回前k个最佳对象的top-k查询、返回布尔关键字表达式且位于指定空间区域的布尔范围查询.空间关键字组对象查询指一组对象符合共同查询关键的需求.空间关键字区域查询返回一个矩形或圆形区域,其中包含最多的给定查询关键字[17-18]、区域中的关键字集合与查询关键字集合具有最高的文本相似度[20]. 本文所提出ROIR与现有的空间关键字区域查询均查找与输入查询关键字集相关的空间区域.然而,本文提出的查询返回多个区域组成的路线,具有路线规划功能. 偏好路线查询提供用户个性化的路线搜索服务,可以分为AOP(arc orienteering problem)问题[22-23]、POI及关键字覆盖路线问题[5-6,24-25]、关键字优化路线问题[2,7]. 在AOP问题中,结点上存储收益值,边表示代价(如距离成本),查询的目标是获取给定代价约束下最大化结点收益和的路线.ROIR与AOP均为在一定代价约束下最大化路线收益.区别在于,AOP路线由POI序列组成,ROIR路线由兴趣区域序列组成. POI及关键字覆盖路线查询的目的是获取由POI组成的路线,返回路线上的POI所包含的关键字覆盖了指定关键字,或者关键字满足一定的关系约束下同时最小化时间或距离代价.其中,文献[25]研究了关键字覆盖情况下top-k路线多样性问题.文献[5]搜索与用户提供的线索最匹配的路径,线索由用户提供的关键字间的关系表示.文献[6]提出了关键字访问序列约束的路线查询. 关键字优化路线问题将路线长度作为约束条件,最大化关键字收益或关键字相似度.其中,文献[1]提出了关键字敏感的路线查询,查询的目标是找到一条覆盖一组用户指定的查询关键字并最大化给定成本预算内的目标得分.文献[4]考虑查询对象不同关键字的权重,提出了一个基于关键字得分的路线优化问题.文献[2]提出一个距离成本约束下的路线查询,用于检索与用户指定关键字集最相关的路径.文献[7]提出兴趣路径查询问题,寻找收集最多查询关键字数量的最优路线. 与文献[2,7]相似,本文提出的ROIR属于空间关键字的偏好路线查询.现有的空间关键字偏好路线查询返回的路线由POI点组成,而ROIR搜索由兴趣区域组成的路线. 本文提出了一种面向空间兴趣区域的路线查询,将传统空间关键字路线查询的POI对象扩展为空间兴趣区域,提高了路线查询的适用性.设计了2层数据模型及相应的索引结构,设计了过滤与提炼2阶段算法的精确算法,以及高效的近似查询算法.通过详细的分析,验证了所提出方法的有效性.提出的ROIR可以广泛应用于兴趣路线规划,特别适用于结伴出行情况,允许用户在区域内分散访问各自偏好的地点. 作者贡献声明:刘俊岭负责问题定义、算法的提出及全文的撰写;刘柏何负责算法的实现与实验对比;邹鑫源负责算法设计与实验对比分析;孙焕良参与实验数据的收集与论文的修改.
2.3 ROIR近似算法
















3 实验分析
3.1 数据集
3.2 精确查询算法比较

3.3 近似路线查询算法比较


4 相关工作
4.1 空间关键字查询
4.2 偏好路线查询
5 结 论
猜你喜欢
保健医苑(2022年5期)2022-06-10华人时刊(2022年1期)2022-04-26电子制作(2022年1期)2022-01-28电子制作(2021年14期)2021-08-21成都信息工程大学学报(2021年6期)2021-02-12计算机应用(2020年5期)2020-06-07动漫界·幼教365(大班)(2019年10期)2019-10-28天津诗人(2017年2期)2017-03-16环球时报(2009-11-25)2009-11-25
