
一种基于改进邻域粗糙集中属性重要度的快速属性约简方法
2022-11-13 12:35周长顺徐久成瞿康林申凯丽
西北大学学报(自然科学版) 2022年5期
周长顺,徐久成,瞿康林,申凯丽,章 磊
(1.河南师范大学 计算机与信息工程学院,河南 新乡 453007;2.智慧商务与物联网技术河南省工程实验室,河南 新乡 453007)
冗余属性是影响分类算法运行速度和分类精度的重要因素[1], 所以进行属性约简对提高分类算法的性能有着重要意义[2-3]。 针对属性约简, 常用的有主成分分析法, 相关性分析法和Hu等人提出的可针对连续性变量进行属性约简的邻域粗糙集属性约简算法[4-6]。 主成分分析法和相关性分析法会导致原始数据中信息丢失, 而邻域粗糙集在进行属性约简时, 可在保留数据集内部信息和分类能力的同时消除原始数据集中重复和冗余的特征[4]。 基于邻域粗糙集的属性约简算法在进行属性约简计算时, 主要有两个步骤需占用大量时间, 即第一步正域的计算和第二步属性重要度的计算。 文献[2]提出了属性约简算法FARNeMF(forward attribute reduction based on neiborhood rough sets and fast search[2]),FARNeMF在进行正域计算时不需对样本重复计算正域,减少了正域计算中样本计算次数。文献[7]在FARNeMF的基础上提出了快速哈希属性约简算法(fast hash attribute reduct algorithm,FHARA)[7],为减少样本计算次数, 该算法通过对原始样本进行划分, 在正域计算中只计算邻域和相同域内且未加入到正域的样本, 进一步减少了正域计算的时间。 以上所提的改进算法减少了正域计算的时间, 然而在属性重要度计算时, 计算次数并没有减少。
上文所提的FHARA等算法在属性重要度计算时是贪心式的, 其计算步骤如下, 如针对有N个条件属性的数据集, 求加入约简集的第一个属性时, 需要对N个条件属性计算正域, 选取正域最大的一个条件属性加入到约简集中, 加入第二个属性时需要对N-1个条件属性进行正域计算[8-10], 针对FHARA等属性约简算法计算属性重要度消耗时间过多, 尤其是面对高维数据时会消耗大量时间的问题, 本文提出了一种基于改进KNN属性重要度的邻域粗糙集属性约简算法(KNN of fast hash attribute reduct algorithm, KFHARA),该算法首先在FHARA的基础上给出一种新的邻域粗糙集属性重要度方法,利用该方法对数据集条件属性进行排序时,只需对条件属性集计算一次属性重要度。利用排序好的属性重要度,约简集每加入一个条件属性只需要计算一次正域,减少了算法的运行时间。
1 相关工作
1.1 邻域粗糙集
设NDS=〈U,C∪D,δ〉是一个邻域粗糙集决策系统,U=(x1,x2,…,xn)代表存在n个样本的集合,C=(a1,a2,…,aN)是全部样本的条件属性集合,B⊆C,N代表特征数量,D为决策属性集,xi(i=1,…,n)为样本空间中的点。
定义1[1]任意xi∈U,定义xi的邻域为
δB(xi)={x|x∈U,ΔB(xi,x)≤δ}
(1)
其中,ΔB(xi,x)表示点之间的距离函数。δB(xi)表示与样本xi在条件属性集B中取值在一定范围内的点,即在样本空间中与xi距离处于预设半径范围内的样本子集,称为x的邻域距离函数通常采用范数距离公式。
定义2[2]任意属性,Minkowski距离公式为
f(x2,ai)|P)1/P
(2)
定义2是相对于数值型属性的,但邻域概念可很容易地将数值计算扩展到实值数据。
定义3[2]设dai(x,y)为样本点x和y在属性ai上的函数
(3)
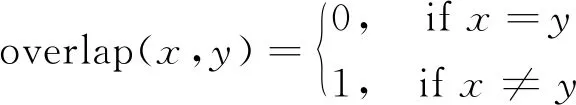
(4)
定义3中可同时处理数值型和名义型属性,即使样本属性的类型或者取值dai(x,y)未知时也可以使用。
定义4[2]邻域粗糙集上、下近似、边界域分别定义为
(5)
(6)

(7)
其中,X⊆U。
定义5[1]B⊆C,B相对于D的邻域依赖度γB(D)定义为
(8)

1.2 邻域粗糙集的属性约简
邻域粗糙集进行属性约简时,每个属性的重要度由该属性增加正域的大小来确定,属性加入的正域越大属性重要度越高。邻域粗糙集属性约简算法的流程可简单描述为:将约简集合初始为空集,将当前条件属性集合中增加最大正域的一个属性加入到约简属性集合中,每增加一个属性就需对未加入到约简集合的每个条件属性计算一次正域[11-13]。例如,目前有N个待约简的条件属性,样本个数为Q,约简集每加入一个属性增加的正域个数为ki(i=1,…,k-1),约简集合第一次添加属性时需要对所有条件属性进行正域计算,计算次数为N,加入第二个条件属性时计算正域次数为(N-1),以此类推,如果约简后的集合有k个属性,那么正域计算次数为
(N+(N-1)+…+(N-k+1))
(9)
计算第k个属性正域的时间为Posk,那么邻域粗糙集属性约简算法的时间复杂度为
Q×N×Pos1+(Q-k1)×(N-1)×Pos2+
…+(Q-kk-1)×(N-k+1)×Posk
(10)
上文所提的传统邻域粗糙集属性约简算法在属性约简计算中有很多关于正域的重复计算。为减少邻域粗糙集属性约简中正域计算次数,文献[7]提出了FHARA算法如图1所示,它利用桶划分的方式将样本空间利用距离因子δ映射划分成一个个的扇形区域,在计算正域时,无需对所有样本进行计算,只需对本邻域和相邻邻域的且未加入正域的样本进行正域计算。
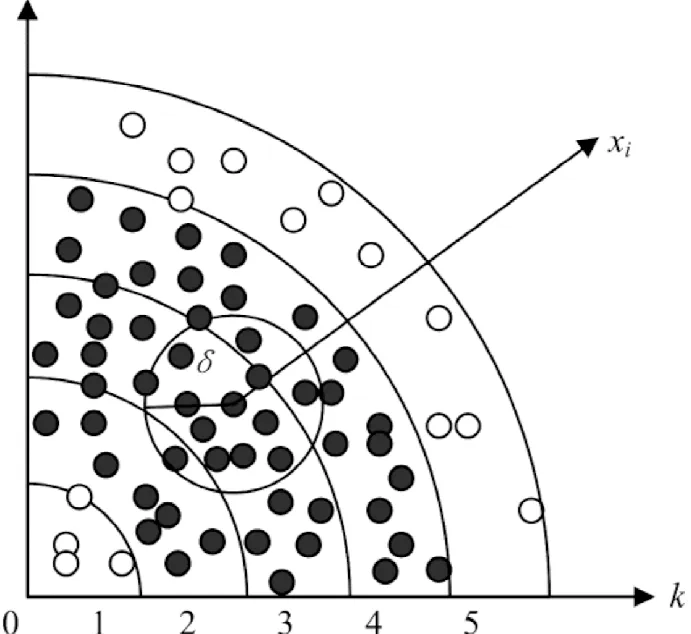
图1 FHARA正域计算示意图
2 基于改进属性重要度的约简算法
2.1 改进的KNN属性重要度
根据上节邻域粗糙集属性约简算法的相关知识,可知邻域粗糙集属性约简算法的时间复杂度与每次正域计算时间和正域计算次数有关,FHARA算法通过对原始数据进行桶划分,将数据利用距离因子δ分成一层层的桶,在计算正域时对本层和相邻层的样本进行正域计算,在面对样本数较多的数据时可有效减少正域计算时间,降低时间复杂度。目前有很多基于正域重要度来对属性进行重要度排序的算法,如基于信息熵重要度的算法和基于属性相关性的算法,这些算法在进行属性重要度判断时,时间并没有减少[14]。为了减少属性重要度的计算时间,本文提出一种快速属性约简算法KFHARA。 KFHARA在FHARA算法的基础上给出一种基于改进KNN属性重要度的属性约简算法,改进后的算法在对属性个数为N的数据集进行属性重要度排序时,计算量从N2降为N。该算法进行属性约简时,只需进行一次属性重要度计算即可获得所有条件属性的重要度排序。对于一个数据集,样本个数为Q,属性个数为N,样本间距离定义如下。
定义6在N维实数空间RN上,空间中任意两点xi=(xi1,xi2,…,xiN)与xj=(xj1,xj2,…,xjN)的距离d(xi,xj)为

(11)
按照定义6中公式计算距离矩阵d,d是一个U×U的对称矩阵,主对角线元素为0,d[i,j](i=1,…,m;j=1,…,m)代表点xi与xj间的距离。首先在Q个样本中抽取h个样本,为了保证抽样结果的不失真[15],需对每一类数据都抽取相同个数的样本,设数据集分类结果的种类为g,则在每一类中抽取(h/g)个样本。对抽取的每一个样本,根据距离矩阵d求距离该样本最近的k个同类样本和k个异类样本,并求它们的距离序列。
定义7在N维实数空间RN上,空间中任意两点xi=(xi1,xi2,…,xiN)与xj=(xj1,xj2,…,xjN)的距离序列dt(xi,xj)的计算公式为
dt(xi,xj)=|(xi1-xj1,xi2-xj2,…,xiN-xjN)|
(12)
对于经式(12)计算得到的所有距离序列dt,same和dt,false,这两个距离序列都为h×g行、N列。

(13)

(14)
其中:xy(j=1,…,h)代表抽取的h个样本;xp(y=1,…,k),xq(y=1,…,k)分别代表距离每个抽取样本最近的k个同类和异类样本;dt,same和dt,false分别按列求和,得到两个长度为N的一维数组dsame和dfalse,数组中N个元素代表所抽取样本在N个条件属性上的距离和。将dfalse和dsame按位相除即dfalse/dsame得到长度为N的属性重要度序列Sig,dfalse,i和dsame,i分别为为dfalse和dsame的第i个属性,第i个属性的重要度Sigi即为

(15)
约简定义如下:在进行属性约简时,将约简集初始为空,根据属性重要度Sig,每次把重要度最大的属性加入约简集,对加入该属性之后的约简集合进行正域计算,若所得正域大于零,将该属性加入约简集并加入新的属性进行下一次正域计算;若所得正域等于零,结束运算舍弃当前属性,输出约简集合。
改进的KNN属性重要度(式(15)计算的Sig)的含义为:对于在每个类上平均抽取的h个样本的最近的k个同类样本和最近的k个异类样本,计算他们在每个属性上的距离,在每一个属性上,分别对得到的所有同类样本点的距离求和,所有异类样本点的距离求和得到长度为N的数组dsame,dfalse。对某一属性i(i=1,…,N)来说,dsame[i]越小,代表同类样本在这一属性上越集中,该属性越利于分类,dfalse[i]越小,代表不同类样本在这一属性上越集中,该属性越不利于分类。基于此,构建属性重要度函数Sig=dfalse/dsame,将dfalse置于分子的位置,将dsame置于分母的位置,若某一属性的Sig越大,代表该属性越有利于分类,属性重要度就越大。KFHARA和FRABVAL[16](fast attribute reducation algorithm based on importance of voting attribute)算法相比,KFHARA算法无需遍历所有样本来进行属性重要度的排序,只需通过所抽取的h个样本计算属性重要度,减少了算法运行的时间;其次,FRABVAL算法在计算重要度时只选取最近的一个同类和异类样本,可能会受噪声点的影响,而KFHARA算法选取k个同类和异类样本进行的计算减少了噪声点的影响。同时,为了防止所抽取的数据失真,在每一类数据上均匀采样;FRABVAL算法在对属性重要度排序时是投票式,按照所得属性距离顺序每一个属性都比前一个属性加1,KFHARA算法对样本属性之差再求和,保留了更多数据的原始信息。
2.2 基于改进KNN属性重要度的KFHARA算法
结合2.1提出的改进的KNN属性重要度,构建KFHARA算法,第一步先求属性重要度Sig。
算法1基于改进KNN的属性重要度算法
输入:数据集Data,包含条件属性C决策属性D,样本总个数n,样本抽样次数h,条件属性个数N,分类类别数g,最近样本个数k。
输出:属性重要度集合Sig。
1) fori=1:n
forj=i:n/*求样本间的距离*/
d(xi,xj)/*计算样本间的距离*/
d(xj,xi)=d(xi,xj)
end for
end for;
2) fora=1:g/*对每个类抽取(h/g)个样本*/
fors=1:h/g
x=x.append(xs)
end for
end for;
3) forw=1:h/*对抽取到的样本求距离序列*/
fore=1:k
dsame(xw,xe)/*计算同类样本序列*/
dfalse(xw,xe)/*计算异类样本序列*/
end for
end for;
4) foro=1:N/*对得到的序列按列求和*/
dsame=dsame+dsame,i
dfalse=dfalse+dfalse,i
end for;
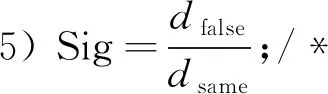
6) Sort(Sig);/*对属性重要度进行排序*/
7) return Sig./*输出属性重要度*/
第二步利用求得的属性重要度进行属性约简见算法2。
算法2属性约简算法
输入:数据集Data,包含条件属性C,决策属性D属性重要度Sig,距离因子δ。
输出:约简集合reduce。
1) 初始化reduce=∅,pos=∅,pos-tag=[0];/*初始化*/
2) forv=1:N
pos=Pos(pos-tag,[reduce,Csig[v]])/*计算正域*/
if pos≠∅/*属性增加正域加入约简集*/
reduce=[reduce,Csig[v]]
pos-tag=update(pos-tag,pos)/*更新标志位*/
else
break
end for;
3) return reduce./*输出约简集*/
KFHARA属性重要度算法时间复杂度为
(16)
KFHARA算法的总时间复杂度为:
Pos1+Pos2+…+Posk
(17)
与改进前的邻域粗糙集属性约简算法相比(公式(10))KFHARA算法大大减少了计算量。KFHARA算法流程图如图2所示。

图2 KFHARA算法流程
3 实验结果与分析
3.1 实验准备
本实验使用Python语言,基于Pycharm环境,为验证本文提出的KFHARA算法的效果,从UCI数据库中选取7组公开数据集进行实验,经过实验验证本方法中的k取4时,得到的约简集合具有较好的分类效果。表1 是对实验所用数据集描述。

表1 数据集描述
在进行实验时邻域阈值δ的选取非常重要,本文使用文献[16]中的方法,每个条件属性上的δ等于这一条件属性的标准差。
3.2 实验算法验证
为了验证KFHARA算法的有效性,将KFHARA算法与FHARA, FRABVA和F2HARNRS[17](neighborhood rough set based hetergenerous future subset selection)等基于邻域粗糙集的属性约简算法进行对比。实验采用10折交叉验证,通过实验结果对比,证明了本文提出的KFHARA算法的有效性。
3.2.1 算法运行时间对比 表2和图3显示了对比算法和所提出的KFHARA算法在7个数据集下的平均运行时间,时间以s为单位。

表2 算法运行时间对比
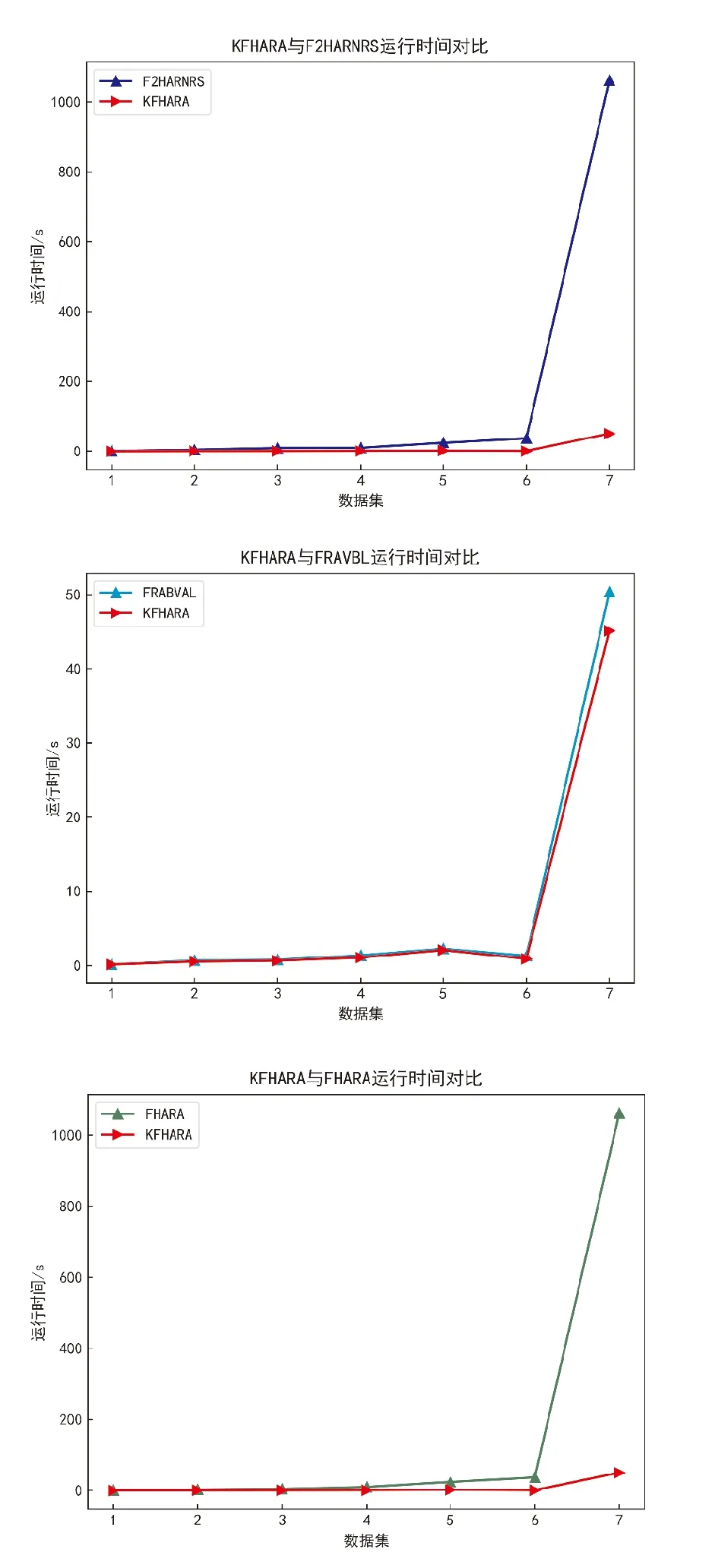
图3 算法运行时间对比
随着原始数据集的属性数量和样本数量逐渐增多,FHARA和F2HARNRS算法耗费的时间越来越大,当数据集为高维数据时,算法消耗时间成指数级增长,FRABVAL算法因为利用投票式的属性重要度排序,算法消耗时间与前两种算法相比明显降低,KFHARA算法的运行时间远低于前两种算法,略低于第3种算法,该算法从处理低维数据到处理高维数据的运行时间是线性增长的,面对高维数据时可以大大降低算法运行时间。如图3在7个数据集上KFHARA算法运行时间都小于其他算法。
3.2.2 算法约简属性对比 表3显示了算法约简后所剩属性个数。 整体来看, 算法都约简掉了大量的属性, 约简后的属性个数都小于10, 可见KFHARA算法对原始数据集具有良好的约简效果。
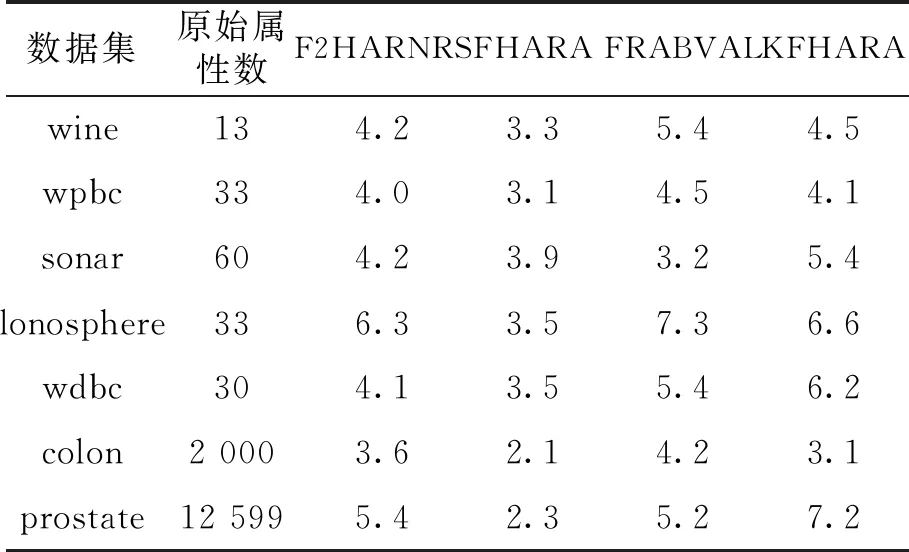
表3 属性约简个数比较
3.2.3 分类精度对比 为得到约简集的分类精度,将经过KFHARA等4种算法约简后的属性子集放入不同分类器中做对比,分别使用KNN,SVM和决策树分类,得到算法平均分类精度。KNN分类精度表和KNN分类精度图分别如表4、图4所示;SVM分类精度表和SVM分类精度图分别如表5、图5所示;决策树分类精度表和决策树分类精度图分别如表6、图6所示。
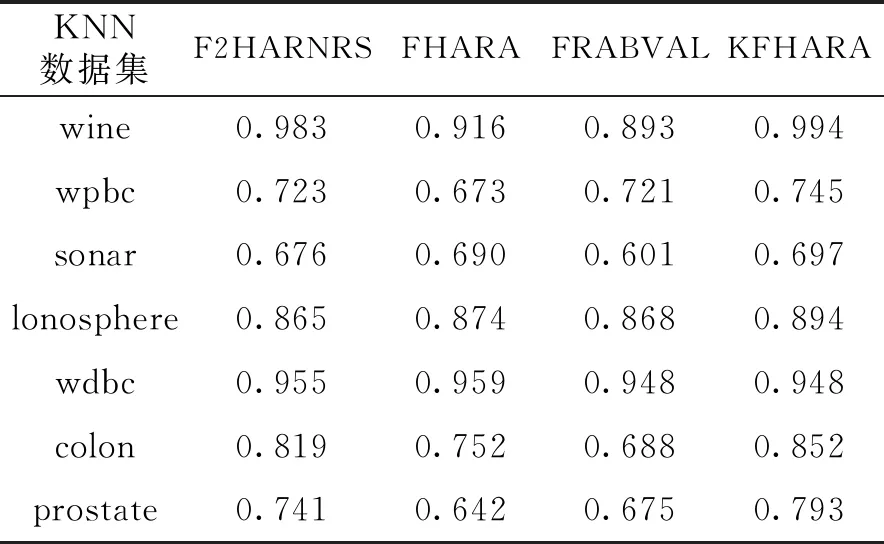
表4 KNN分类精度

表5 SVM分类精度
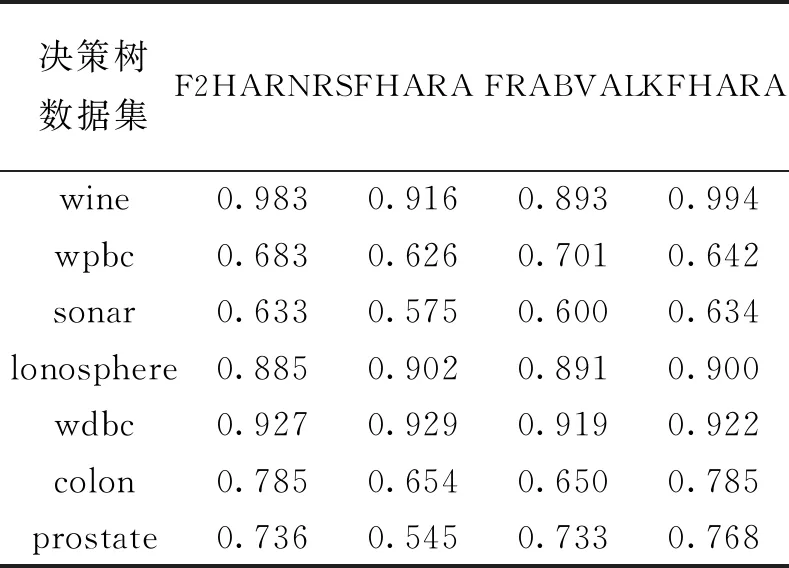
表6 决策树分类精度

图4 KNN分类精度

图5 SVM分类精度

图6 决策树分类精度
经过KFHARA算法约简后的子集在3种分类器下的7个数据集中进行实验,从运行时间来看,相较于FHARA和F2HARNRS算法,KFHARA算法的运行时间得到明显提升, 和同类的针对属性重要度的快速属性约简算法FRABVAL相比,运行时间也有所提升。从分类精度上来看,KFHAR分类精度和其他3种算法相比,略微优于精度最高、运行时间最长的F2HARNRS算法,明显优于其他两种算法。实验证明,在保证精度不损失的情况下,KFHARA算法有效地减少了属性约简的时间,尤其是面对高维数据展现了良好的性能。
4 结语
为减少冗余属性对分类算法运行速度和分类精度的影响,本文提出了一种快速属性约简方法KFHARA。该方法通过改进的KNN属性重要度来进行属性排序,在不影响精度的情况下通过减少属性重要度计算次数来减少算法的运行时间,从而降低时间复杂度。本文所提的约简算法得到的属性子集中属性数量较多,未来的研究目标是在不影响约简速度和分类精度的情况下,逐步减少约简子集中属性的个数。
猜你喜欢
聊城大学学报(自然科学版)(2022年5期)2022-10-29
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
农业工程学报(2022年7期)2022-07-09
闽南师范大学学报(自然科学版)(2022年1期)2022-03-28
逻辑学研究(2021年3期)2021-09-29
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
海峡科技与产业(2016年11期)2016-12-26
数学学习与研究(2016年22期)2016-12-23
知识力量·教育理论与教学研究(2013年11期)2013-11-11
