
多级共享缓存性能和安全性联合改进
2022-11-23 11:31刘洋
兰州工业学院学报 2022年5期
刘 洋
(池州职业技术学院 教育系,安徽 池州 247000)
高密度单核处理器因性能和功率问题而发展受限[1],为提高整体性能,多处理器系统芯片越来越多地用于电脑和服务器平台[2]。典型的多核处理器系统在一个域的处理核心上并行运行线程(也称为线程级并行[3-4]),可能会引发对共享资源的竞争,从而降低芯片的性能[5-6]。在所有类型的资源竞争中,缓存竞争已被证明对整体芯片性能的影响最不利[7]。缓存竞争导致的不良结果主要是1个线程驱逐了属于其他共同运行线程的活动数据块[8]。缓存竞争会增加额外的内存访问,导致性能下降。许多研究都集中在这个主题上,并且已经设计了各种方法来减少竞争。然而,这些技术会增加巨大的运行开销。文献[9-10]提出了一种缓存分区技术,但存在一些效率低下的问题。Huang等人[11]建议在缓存架构中使用元数据,但硬件开销非常大。在基于软件的技术中,研究人员主要使用调度算法来减少缓存竞争。Zhuravlev等[8]提出的基于分离域的方法,具有高缓存缺失率的线程,往往会占用所有的缓存块,从而影响性能。Sahneh等人[12]使用每周期指令数(IPC)作为检测冲突线程的指标,提出的算法会反复检查系统中每个域的IPC,导致效率较低。
针对前人研究存在的缺点,本文采用基于软件的解决方案,不会增加硬件开销。并且,在前人工作中,系统资源的可用性并没有作为安全目标直接在多级缓存中得到解决,因此将可用性作为本文研究安全性的重点。通过引入安全性和性能感知的线程映射,将线程映射到域的核心上,使线程之间的竞争最小化,改进多级共享缓存处理器的性能和安全性问题。该方法的基本特点是简单,开销非常低。
1 攻击模型
本文提出的缓存攻击通过故意诱导缓存竞争,增加任务/线程在多核系统特定核心上的执行时间,如图1所示。该攻击的关键特征是独立访问私有代码/数据空间,将执行时间延长5倍。
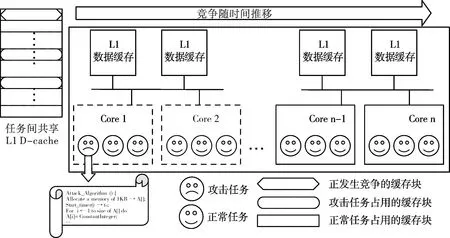
图1 本文提出的攻击概念模型
该攻击包括正常任务、共享内存、攻击任务3部分。攻击任务遵循算法1,实现缓存竞争攻击。它在运行时分配的内存中执行随机访问,以占用共享缓存,增加正常任务的缺失率。为度量攻击任务成功攻击所需的时间,定义了一个大于1 K的整数数组,并发出顺序地址,将该数组的所有单元初始化为1个常量。该操作所需的时间(Δt)将被记录为该操作的正常时间,即参考时间。然后,攻击任务向数组发出随机地址跟踪,并再次捕获时间。当随机访问需要至少2倍时间访问数组时,攻击任务将此视为成功攻击。为解决多级共享缓存的动态行为,攻击任务每2个周期调用算法1。
算法1:
Function Attack_Algorithm():
Allocate a memory of 1KB→ A[];
Start_timer()→ t0;
for i ← 1 to size of A[]do
A[i]= ConstantInteger;
end
End_timer()→ t1;
Δt=t1+ t0;
for j ← 1 to 10 do
Start_timer()→ t0;
Tj←random trace of addresses to A[];
For all addressesm∈Tj: A[m]++;
End_timer()→ t1;
if((t1-t0)≥ 2Δt)then
Save theTj;
Exit the For loop;/*attack successful*/
end
end
if(attackhasnotbeensuccessful)then
ReleaseArrayA[];
CallAttack_Algorithm();
end
End Function
本文已经在一个Linux操作系统上实现了攻击,该系统运行的是Mibench套件[13]的不同应用程序。然后,使用OProfile性能监视工具[14]记录应用程序的执行时间。如图2所示,在出现提出的攻击时,任务的原始执行时间已经延长。在这个实验中,使用500和5 000入口长度的数组来实现攻击,相比500的数组,5 000的数组执行时间更长,受到了更严重的延迟。这是因为较长的数组使攻击任务有机会进行更远的跳转和更不可预测的地址模式。另一个观察结果是,攻击任务对应用程序执行时间的影响并不总是相同的。例如,在快速排序(qsort)和拼凑(sha)任务中,输入长度为500和5 000的攻击可以将执行时间延长5倍。然而,在循环冗余检查(crc32)基准测试中,500和5 000的攻击延长时间的倍数分别为1.5倍和2.5倍。这是由于crc32发布的扩展地址比sha和qsort的少。

图2 不同基准测试集下所提缓存攻击对执行时间的影响
2 性能和安全性敏感的线程映射
本节提出了一个线程映射算法来联合改进多级共享缓存的性能和安全性问题。该算法基于IPC的平均数量对每个域的核进行动态线程映射/重映射。平均IPC是该域中所有运行线程的算术平均值。假设1个域中存在1个缓存竞争,它将导致缓存意外的丢失,降低域的性能。具有竞态条件的域显示的IPC比无竞态条件的其他域要低。将IPC1,IPC2,...,IPCm分别定义为多核系统中D1到Dm域的平均IPC。关于每个域的平均IPC,定义以下工作状态(如图3所示)。
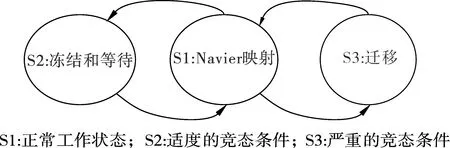
图3 所提线程映射算法的状态转变
状态S1:一种正常的状态,所有域都工作,没有缓存竞争。当所有域的平均IPC大于预期的IPC阈值(即IPC1,IPC2,...,IPCm≥ThIPC)时,可以检测到。
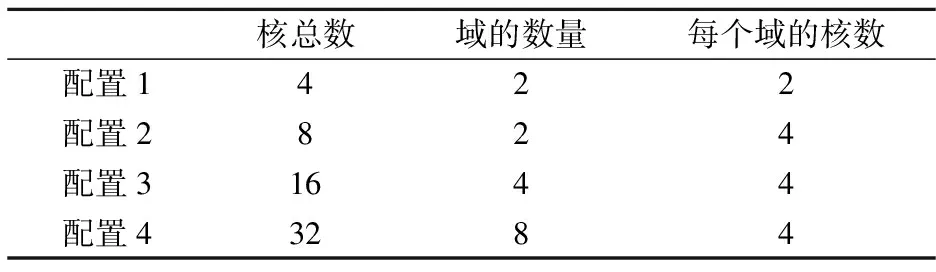
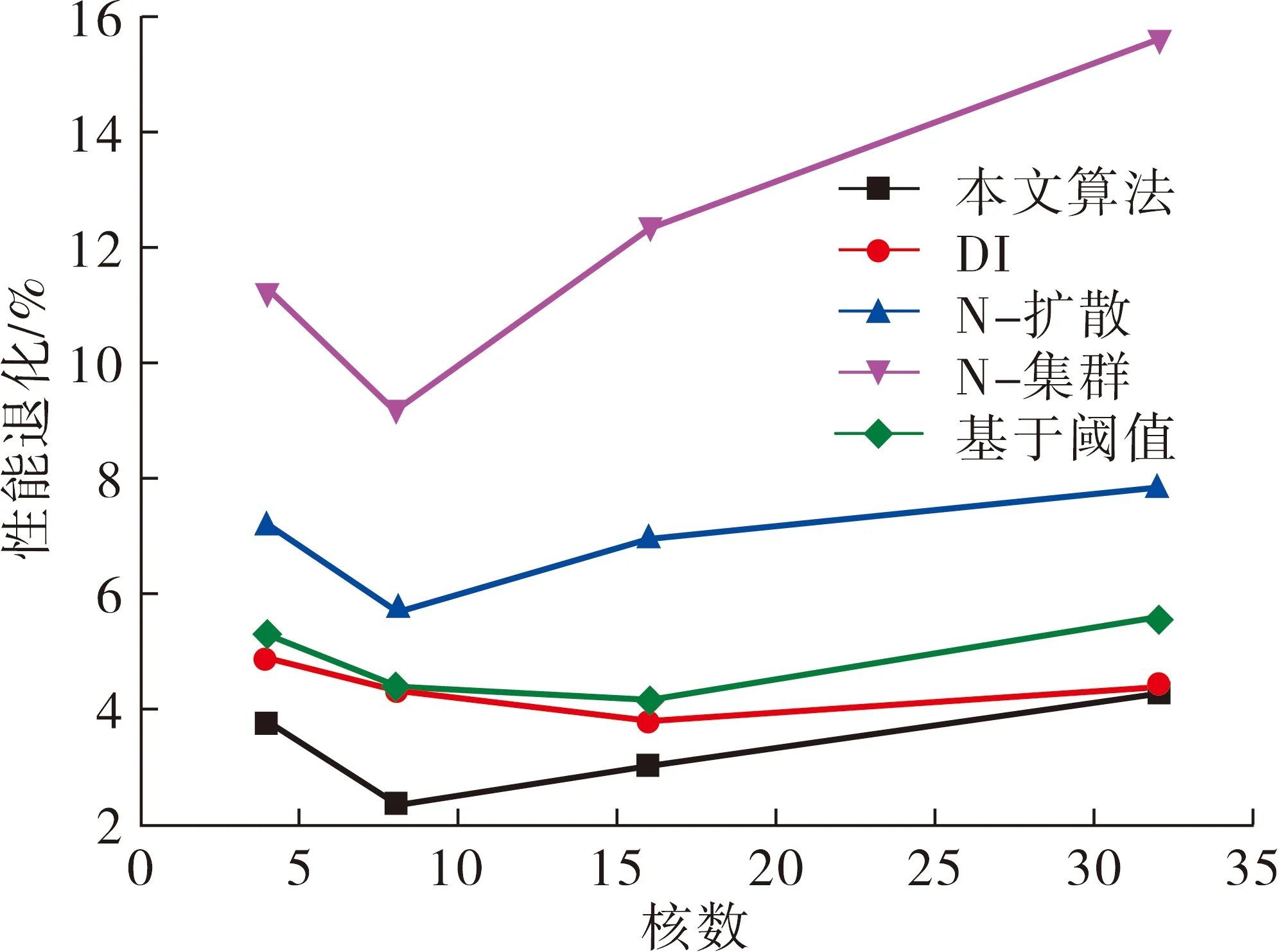
状态S2:在这种未充分利用状态下,至少有一个域的平均IPC低于预期的IPC,即∃i,使得满足条件:IPCi 状态S3:在这种未充分利用状态下,至少有一个域的平均IPC低于预期的IPC,即∃i,使得满足条件:IPCi 该算法的目标是保持域的平均IPC尽可能高。因此,该算法试图在最大和最小平均IPC之间保持最小可能的差异。在这种状态下,线程将基于Naive扩散算法[3]分配到核心。 在S1状态下,算法反复检查所有运行域的平均IPCs,分别找到运行域Di和Dj的平均IPCs最小值和最大值。检查域Di的平均IPC,如果大于或等于预期的IPC阈值,ThIPC,算法保持S1状态。否则,算法将根据Max(IPC)和Min(IPC)的差值移动到S2或S3状态。算法2展示了算法的虚拟代码,以及它在上述状态下是如何工作的。输入是线程和一个指定的采样周期P。输出是映射的线程。根据该算法,当最大IPC和最小IPC差值小于阈值时,即Max(IPC)-Min(IPC) 算法2: Input: Threads,P Output: Mapped threads Function Thread Mapping Algorithm(): forAllthreadsthatarereadytorundo Schedule each thread with Naive spread algorithm; repeat Calculate averageIPCfor all domains; Di← domain with the minimumIPC; Dj← domain with the maximumIPC; if(IPC(Di) if(IPC(Dj)-IPC(Di) Freeze a random number of threads inDifor100K cycles; else Swap threadT1∈Diwith threadT2∈Dj; if(thisisthefifthmigrationofDi/Dj)then Terminate the threadDi/Dj; end end Wait forP; end untilallthreadsarefinished end End Function 该算法试图在竞争线程之间创建一个时间间隔,从而解决缓存竞争问题。线程在冻结期结束后再次被激活,并继续运行。该算法在冻结期间不执行任何其他竞争,保持状态S2,并在100K循环后返回状态S1。另一方面,Di域和Dj域的IPCs 存在较大差异,即Max(IPC)-Min(IPC)≥Thδ,说明线程映射不合适。在这种情况下,提出的算法基于Naive扩散,改变最初的线程映射。域Di中IPC最低的线程将被域Dj中IPC最大的线程所取代。 该算法还跟踪已迁移的线程,以检查它们是否可能参与连续的迁移。对于给定线程,连续三次迁移将该线程放入警报列表,第五次迁移后,该线程将被终止。线程迁移完成后,算法返回状态S1,继续检查所有域的平均IPCs。所提出的算法很简单,且不需要硬件辅助,可以很好地提高基准测试的性能,这将在下一节中得到展示。 该算法使多级高速缓存系统在保持高性能的同时,对引入的攻击具有鲁棒性。为了进一步研究这一问题,将本文提出的线程映射算法与SPEC CPU 2006基准测试包中不同任务集下的分布式强度(DI)[11]、基于阈值(threshold-based)[11]、Naive集群(Naive-cluster)[3]和Naive分散(Naive-spread)[3]线程映射算法进行了比较。 使用Akula模拟器[3]进行仿真,在仿真中考虑了不同的情况,研究了本文所提算法的优缺点。所有情况都选择SPEC CPU 2006基准套件中的线程。在SPEC CPU 2006基准测试套件中,线程可以细分为以下2类:高内存需求(HI-MD);低内存需求(LO-MD)。HI-MD和LO-MD线程的各种组合被用来形成线程集,以覆盖自然和攻击情况。为了研究内存需求强度对性能的影响,定义了线程集以显示4种不同级别的内存需求: 级别1:该线程集由6个HI-MD线程和2个LO-MD线程组成,作为内存需求最高的集合。 级别2:这个集合由5个HI-MD和3个LO-MD线程组成。 级别3:这个集合由4个HI-MD和4个LO-MD线程组成。 级别4:这个集合由3个HI-MD和5个LO-MD线程组成,作为内存需求最低的集合。 对于每个模拟实验,从SPEC CPU 2006基准测试套件中选择10个不同的线程来满足上述内存需求。进行了10次模拟,从Akula模拟器得到结果后,记录最差和平均情况下的性能。结果需要计算算术平均值。 根据平均和最差情况下的性能退化(APD)这2个指标,对上述线程集的DI、基于阈值、Naive集群、Navie分散和本文提出的算法的性能进行评估。性能退化因子指的是,与在单核芯片上运行而不共享缓存相比,在多级共享缓存平台上运行的给定线程的性能退化情况。这里说的退化是由缓存竞争造成的。第i个线程的性能退化因子由式(1)计算。 (1) 用式(2)计算APD,即 (2) 式中:n是线程在芯片上运行的核数。 最坏情况下的性能下降是运行在n个核上的线程的最大性能下降,用式(3)计算得 (3) 改善平均情况下性能退化有利于整个系统,系统可提前关机,节省功耗。改善最坏情况下的退化有利于服务质量(QoS),因为竞争感知调度程序提供了稳定的执行时间,以保证更好的应用服务质量(QoS)。 为了评估所提算法的广泛性,对表1中介绍的配置执行了所有步骤。表2描述了在不同的内存需求水平下,与其他4种映射算法相比,本文提出的算法在最差情况和平均情况下性能改善的百分比。由表2可以看出,本文提出的算法能够很好地减少线程之间的竞争,提高性能,特别是在性能退化最差的情况下。所提出的映射算法比Navier集群算法平均高出78.2%,而相比DI算法,改善值低于10%。平均情况下,平均性能改进(即退化减少)的趋势与最差情况几乎相同,所提出的算法比DI提高了31%。在一些罕见的情况下,所提出的映射并不是最佳解决方案,例如,在3级内存需求中,DI的性能损失最低,在最差和平均情况下比本文所提算法的要好28%和7%。表2中分别对4种算法性能提高的平均值再进行求平均,可以得出,在最差情况和平均情况下,系统整体性能分别提高了46.4%和55.9%。 表1 模拟中的核和域的数量 表2 所提线程映射算法性能的提高 % 图4~5分别显示了所有5种算法在不同处理器中不同线程在最差和平均情况下的性能退化,表明本文所提的算法有了明显的改进。如图6所示,评估了完成1个线程集所需的线程迁移数量。所提的算法所需的迁移梳理比DI算法少得多。在DI算法中,当核数增加时,迁移会呈指数增长,而本文所提算法改善了这种情况。 图4 最差情况下的性能退化 图5 平均性能退化 图6 DI和所提算法所需的线程迁移数量 假设数据缓存的总大小是n块,受害线程占用了缓存的m个指令块。当受害线程执行其目标数据访问(读和写)时,攻击线程的行为是随机的,使竞争最大化。攻击线程在无限循环中不断地运行,试图将随机块引入共享数据缓存。虽然受害线程对数据缓存进行了有针对性的访问,但攻击线程试图通过发出随机访问来指向同一个块。 受害线程运行m个指令块所需的平均时间为 (4) 式中:m是受害线程在指令缓存中准备由本地核心执行的指令块的数量;¯Tblock是执行一个指令块所需的平均时间。 将¯Tblock用式(5)表示为 (5) (6) 对于特定的i=j,受害者访问第i块数据缓存的概率为1,否则为0,即 (7) 由于攻击随机且一致地访问所有数据缓存块,因此访问受害者已经访问过的同一个数据缓存块的概率为 (8) 计算所有数据缓存块在同一时间访问的概率如式(9)所示。 (9) 式中:P(Att(Bi))、P(Vic(Bi))分别为攻击和受害线程访问数据缓存第i块的概率。 (10) (11) 因此,受害线程中故意缺失的概率为 (12) 式中:P(Att(Bi))和P(Vic(Bi))是2个独立的概率。 将它们相乘,得到受害线程新的命中概率,即 (13) 在这种情况下,攻击线程将有更多的机会将故意缺失注入到受害线程,实现成功攻击的机会更高。 使用Intel Pin工具进行实验,运行了2个正常的程序,并计算了每个基本块的指令数(跳跃指令作为最后一条指令的一系列指令)。图7描述了5个不同程序中基本块的数量和每个基本块的平均指令数。虽然每个程序的基本块的数量不同,但每个基本块的平均指令数量都低于5条。几乎有15%的指令需要访问内存,通过相同的测量工具计算,攻击程序的这个百分比为30%。 图7 不同程序下基本块数量和基本块平均指令数 1)为了延长特定线程的执行时间,引入了一种新的攻击方法,该方法独立于访问私有数据空间。这种攻击可以将正常程序的执行延迟5倍。 2)提出了一种基于软件的竞争感知线程映射算法来缓解缓存竞争,该算法根据IPC参数检测同一域上的竞线程,定期检查系统状态。与其他算法相比,它需要的线程迁移数量更少。 3)平均和最坏情况下,系统整体性能分别提高了46.4%和55.9%,证实了所提的线程映射算法通过减少缓存竞争而显著地节省了性能。并且,仅仅依靠任务迁移来减少竞争并不是一个有效的解决方案。 4)通过阐述提出的缓存攻击对受害线程性能的影响,对提出的攻击进行了全面的安全性分析。发现每个程序的基本块的数量不同,但每个基本块的平均指令数量都低于5条。3 算法评估
3.1 在模拟中使用线程集
3.2 实验结果和分析
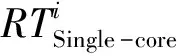



4 安全分析


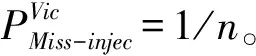

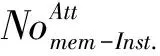

5 结论
猜你喜欢
山西电子技术(2021年3期)2021-06-28网络安全技术与应用(2020年1期)2020-01-07当代陕西(2019年13期)2019-08-20测控技术(2018年5期)2018-12-09环球市场(2017年36期)2017-03-09电信科学(2016年10期)2016-11-23电脑爱好者(2015年21期)2015-09-10科技传播(2015年20期)2015-03-25西安航空学院学报(2014年5期)2014-07-13测绘科学与工程(2014年5期)2014-02-27
