
基于改进半监督生成对抗网络的少量标签轴承智能诊断方法
2022-12-01 09:26邢晓松
振动与冲击 2022年22期
邢晓松,郭 伟
(电子科技大学 机械与电气工程学院,成都 611731)
近年来,为了确保大型装备的安全可靠运行,在线监测系统采集了海量的装备数据,推动装备的故障预测与健康管理进入了“大数据”时代。在各类大型装备的旋转机械和传动系统中,滚动轴承是其中的关键基础件,也是最易损坏的部件之一。已有研究[1-2]表明,电机故障中有40%~50%是由轴承故障引起的,其故障可能会造成整个设备故障,甚至是停机和事故。因此,有必要利用动态监测与大数据分析掌握运行轴承的健康状态,进而对整个装备开展故障预测与健康管理。
机械监测数据的大容量、低密度、多样性和时效性[3]的特点推动了智能故障诊断的研究与应用。现有方法可以分类两大类:一类是基于人工特征提取和机器学习方法的智能诊断方法,常用人工特征包括时频域统计指标、小波参数、熵参数[4]、复合指标[5-6]等;另一类是通过深度学习,从海量数据中自主学习获得抽象特征,并实现故障分类。相比传统的机器学习方法,深度学习算法利用海量数据的训练来挖掘其中隐含的信息,所得的深层次模型具有更好的分类或预测性能。
但在应用过程中,基于深度学习的智能故障诊断方法面临标签数据不足的问题,仅有少量数据可确定设备的健康状态,这使得依赖标签数据监督学习的智能诊断难以达到预期效果。为解决这一问题,学者们将迁移学习、非监督学习、半监督学习等引入深度网络中。
雷亚国等[7]采用非监督学习对去噪自动编码机进行预训练,然后使用误差反向传播算法作为微调阶段的监督算法,实现了多工况、多故障的智能状态识别。陈仁祥等[8]提出基于深度置信网络迁移学习的行星齿轮箱故障诊断方法,利用少量的目标域有标签样本微调深度置信网络的权重和偏置值,以适应新的目标样本识别,最终提高了目标域样本故障识别准确率。Shao等[9]使用预训练的深度卷积网络来解决训练中只有少量标记数据的问题,结合微调策略提高模型准确性。
除基于预训练的微调算法外,域适应的方法也可用于轴承的迁移学习。Wen等[10]提出了基于迁移学习的深层自编码器,使用最大平均差(maximum mean discrepancy,MMD)来减少源域和目标域的分布差异。王肖雨等[11]采用自适应噪声完整经验模态分解对不同工况下滚动轴承振动信号进行分解,然后利用源域数据和目标域数据训练分类模型,最小化域间特征分布差异,最终提高了滚动轴承状态识别的准确率。Lu等[12]提出了一种基于深度神经网络的迁移学习方法,并将MMD用于滚动轴承故障诊断。Zhu等[13]通过多层适应多核MMD将卷积神经网络(convolutional neural network,CNN)用于迁移学习和诊断。Han等[14]将对抗性学习引入卷积神经网络,以达到不同工作负载下故障诊断的迁移学习。由于对抗性学习中的域分类器不考虑特定任务的决策边界,因此在决策边界附近生成的特征可能模棱两可。为了解决这个问题,Jiao等[15]提出了基于分类器差异的无监督对抗域适应网络,通过对抗性学习使得源域和目标域的分布接近。Chai等[16]提出了一种细粒度的对抗性网络,通过与多个域鉴别器竞争来学习可迁移特征,实现了两个域的全局对齐和跨域的每个故障类别的细粒度对齐。
自2014年Goodfellow等[17]提出生成对抗网络(generative adversarial network,GAN)以来,已在图像、计算机视觉等领域样本不足的情况中得以发展与应用。Liu等[18]使用生成器模拟数据,扩展了训练分类器所需的次要数据集。马波等[19]提出基于生成对抗网络样本生成技术的智能诊断方法,通过在健康数据中加入故障特征得到故障样本,达到了较好的变工况迁移能力。Ding等[20]训练多个GAN用以排除异常情况,以半监督的方式加强了小样本故障诊断的性能。Zhang等[21]将半监督学习与生成对抗网络相结合,提出了基于原型学习网络的深度对抗半监督(deep adversarial semi-supervised,DASS)网络,利用少量标注样本进行对抗训练,提升了分类器的识别能力和鲁棒性。Zhang等[22]提出了主动半监督学习GAN网络(ASSL-GAN),通过交替更新的方式最小化损失函数,获得了较高的准确率。Guo等[23]提出了深度卷积迁移学习网络,包含域适应与状态识别,前者通过最大化域识别误差和最小化域概率分布距离来提取域不变特征,用以识别新监测对象的健康状态。Li等[24]通过梯度反转层优化特征提取器,最大化鉴别器损耗,使域鉴别器无法区分两个域的数据。邵海东等[25]采用可缩放指数型线性单元和非负约束提升深度自动编码器的性能,结合目标域中的单个训练样本来微调分类模型,实现了不同轴承的迁移诊断。Zhuang等[26]和Lu等[27]分别对迁移学习和少样本学习的相关研究进行了综述。
上述研究表明了深度迁移学习在有限标签样本学习与诊断知识应用的可行性和有效性,但是生成对抗网络在训练早期会因判别器迅速收敛而导致梯度消失[28],而微调要求迁移学习中源域与目标域具有相似的特征空间。因此,本文提出一种增强特征匹配的半监督生成对抗网络,并将其用于较为复杂的轴承迁移学习任务。该方法在半监督生成对抗网络的基础上,针对生成器和判别器模型的中间层分别进行特征匹配,使网络可以充分获取故障数据的特征,同时加快损失函数的收敛速度。最后,使用四组轴承数据的迁移学习对所提网络进行验证和分析。
1 生成对抗网络的基本原理
生成对抗网络主要由两个部分组成:生成器G(Generator)和判别器D(Discriminator),如图1所示。随机噪声输入生成器G获得生成数据,标记为G(z);然后判别器辨识输入数据是来源于真实数据x,还是生成数据G(z)。训练过程中,生成器G和判别器D交替训练,通过二者的对抗学习,最终使判别器无法分辨数据的来源,定义目标函数为
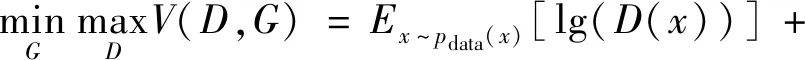
(1)
式中:D(x)为判别器的输出属于真实数据的概率;Pdata和Pz分别为真实数据和生成数据的分布。

图1 生成对抗网络框架示意图Fig.1 Illustration of GAN framework
训练过程的每一次迭代,先固定生成器G,通过训练判别器D使其能够区分输入数据的来源,由此获得一个二分类的分类器。然后,固定判别器D,训练生成器G,使生成数据接近真实数据;交替迭代使得对方的错误最大化,通过博弈使得生成器能够估测出真实数据的分布,从而弥补真实数据不足的问题。
2 改进半监督生成对抗网络
将生成对抗网络用于轴承智能诊断时,可用一个分类器C(Classifier)替换上述框架中的判别器D,即用多分类的分类器替代二分类的判别器,将判别器输出的真假改为输出数据类别,包含真实数据x的K类和生成数据G(z)对应的第K+1类。基于此框架,本文提出了改进半监督生成对抗网络,其结构如图2所示,用于提高仅有少量标签数据时轴承故障诊断的准确性。
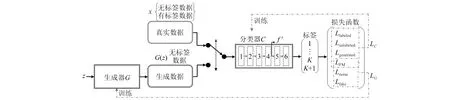
图2 改进半监督生成对抗网络结构图Fig.2 Structure of an improved semi-supervised learning-based generative adversarial network (ISSL-GAN)
2.1 生成器网络的结构
本文的生成器网络是基于反卷积网络来设计的。如图3所示,生成器的输入为一组随机生成的噪声,网络由4层反卷积神经网络构成,通过逐步缩小卷积核的大小,最终获得大小为32×32的二维数据。为了减少过拟合的发生,网络的前三层加入了Dropout层。网络中激活函数使用了Leaky_ReLU,其表达式为
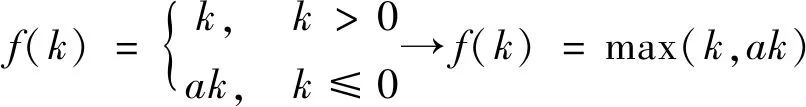
(2)
式中,a为(1,+∞)区间内的固定参数。

图3 生成器网络的结构图Fig.3 Structure diagram of the generator network
2.2 分类器网络的结构
分类器在训练过程中提取数据的抽象特征,实现对输入数据的分类,前K个类别对应真实数据的类别,第K+1个类别对应生成数据,其结构如图4所示。本文的判别器网络由5个卷积块和一个全连接层组成。前3层采用了4×4的卷积核,步长设置为2,后2层卷积核大小设为3×3,步长为1,最后一层是全连接层(Dense层),通过Softmax函数输出分类结果。

图4 分类器网络的结构图Fig.4 Structure diagram of classifier network
2.3 生成器和分类器损失函数定义
损失函数是用于衡量网络生成数据与输入真实数据之间的差距,通过迭代训练过程来最小化损失函数。半监督生成对抗网络的损失函数是由生成器G的损失函数和分类器C的损失函数构成。
(1) 生成器损失函数
生成器G的损失函数LG定义为
LG=λLfake+Lnoise
(3)
Lfake=Ez~noiselg[1-C(G(z))]
(4)
(5)
式中:Lfake为生成器的真假损失,将生成数据人为设置为“真”标签,并与分类器输出的标签相比,计算二者的差值,最小化该损失函数最终使生成器获得的生成数据接近真实数据,使分类器判定该数据为真;Lnoise为生成器的数据损失,使生成数据和真实数据的特征更加接近;Lfake和Lnoise的不同之处在于,前者是在优化生成器,使生成数据更接近真实数据,而后者则是优化生成数据的分布,缩小二者差距,使其更加接近真实数据的概率分布;λ为平衡系数,用于在两部分损失之间取得平衡,使训练效果更好;C(x)为x通过分类器识别出其真实标签的概率,C(G(z))为生成数据通过分类器后识别出其为真实数据的概率。
(2) 分类器损失函数
网络训练数据由大量的无标签数据和少量有标签数据组成,因此采用半监督学习算法。对于有标签数据,损失函数定义为网络预测标签与真实标签之间的偏差
Llabeled=-Ex,y~pdata(x,y)lgpmodel(y|x,y≤K)
(6)
式中,y为分类器预测的数据类别标签。
无标签的数据包含真实的无标签数据和生成器生成的无标签数据。因其无标签,无法用分类器判断其类别,因此只判别其数据源,即真实数据判别为“真”,而生成数据判别为“假”,真实无标签数据损失函数Lunlabeled和生成的无标签数据损失函数Lgenerated定义为
Lunlabeled=-Ex,y~pdata(x,y)lgpmodel(y≤K|x)
(7)
Lgenerated=-Ez~Glgpmodel(yz=K+1|z)
(8)
上述损失函数的定义是以提高分类器性能为目标进行优化,但是在处理大规模数据集时训练时间较长,而且对迁移学习难以达到预期效果,因此本文提出了增强特征匹配算法,用以优化网络训练过程。
2.4 增强特征匹配
在数据量大的情况下,只依靠生成器和判别器输出结果进行损失值计算,训练的收敛速度会变慢。为提高网络的学习效率,本文提出了一种增强特征匹配的损失值计算方法。其主要思想是:考虑到少量的卷积层对数据特征提取尚不充分,本文使用较深的卷积层获得的抽象数据特征。在保证准确率的前提下,提取出网络深层的计算结果,对其进行真实数据和生成数据的特征匹配,以获取样本数据深层特征信息。如图4所示,在分类器中提取出第4个卷积块的输出结果,计算真实数据和生成数据的输出之间的损失值偏差,即
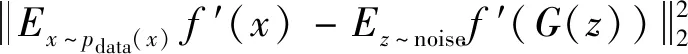
(9)
式中,f′为分类器第4个卷积块的输出结果。此损失函数的目标是通过增加真实数据和生成数据之间的差距来提高分类器性能,进而加速网络的收敛。
因此,分类器的总损失函数定义为
(10)
类似地,为了增强生成器的学习能力和收敛速度,将式(9)也引入生成器的损失计算中,不同的是,在生成器中这一部分损失的目标是减小生成数据和真实数据的差距。因此,生成器的总损失函数更新为
LG=Lnoise+λLfake+μLFM
(11)
式中,λ和μ为对应损失函数的系数。
2.5 算法流程
本文将增强特征匹配算法与基于半监督学习的生成对抗网络相结合,构建了改进的半监督生成对抗网络(improved semi-supervised learning-GAN,ISSL-GAN),算法流程描述如下:
步骤1生成数据——将随机噪声输入生成器,获得与真实数据相同维度的生成数据;
步骤2计算分类器损失——将真实数据和生成数据输入到分类器,采用式(10)计算分类器的损失值;
步骤3计算生成器损失——根据分类器结果,采用式(11)计算生成器的损失值;
步骤4网络参数优化——采用自适应矩估计法(Adaptive moment estimation,Adam)优化网络参数;
步骤5停止条件判断——判断是否达到预设分类器准确率或达到最大循环次数。如果满足停止条件,结束训练,选取分类准确率最高的模型参数作为输出结果;若不满足,返回步骤1。
3 试验结果与比较
本文使用两种类型的轴承数据进行方法验证,并与卷积神经网络CNN和半监督生成对抗网络(semi-supervised learning-GAN,SSL-GAN)进行对比,通过分析网络的分类准确率、算法收敛等分析网路性能差异。
3.1 试验数据说明
本文试验种使用了两种类型的轴承,进行了四组试验。试验1~试验3的轴承数据来源于德国帕德博恩大学公开的滚动轴承试验数据[29],试验4的数据来源于北京交通大学的轮对轴承试验数据。下面对所用的试验数据进行简要的说明,试验中训练集与测试集的轴承和工况设置如表1所示。
(1) 德国帕德博恩大学的滚动轴承试验数据
该数据集中故障生成方式包括人工注入的模拟故障和加速寿命试验产生的故障,加速寿命试验通过对轴承施加更高的径向力和使用低黏度的润滑油来加速疲劳损伤的出现,经过长时间的旋转,从而获得损坏的轴承,根据损伤情况进一步量化了损伤程度。数据采集时,将不同健康状态的轴承放置在轴承试验台上可获得轴承的振动信号。轴承试验台由电机、扭矩测量轴、滚动轴承、飞轮和负载马达5个部分组成,在轴承箱顶端安装了加速计,设置采样频率为64 kHz,每次采集时长为4 s。如表1所示,分析轴承的状态包括健康(K001、K003、K005)、外圈故障(KA04,KA05,KA07,KA08,KA22)和内圈故障(KI03,KI05,KI08,KI18,KI21)。为了测试所提深度网络的分类性能,训练集和测试集数据来源于不同轴承(故障生成方式、损伤程度)和工况(转速、载荷和扭矩)。
(2) 轮对轴承试验数据
轮对轴承试验台如图5所示,轴承上施加了垂向和横向载荷,加速计固定在轴承座的9点和12点方向,采样频率为12.8 kHz,采集时长为25 s。试验轴承的故障类型包括外圈故障、内圈故障、滚动体故障和保持架故障。试验中选取了同一转速下不同载荷的轴承振动数据,用以分析不同载荷下的轴承故障诊断准确性。
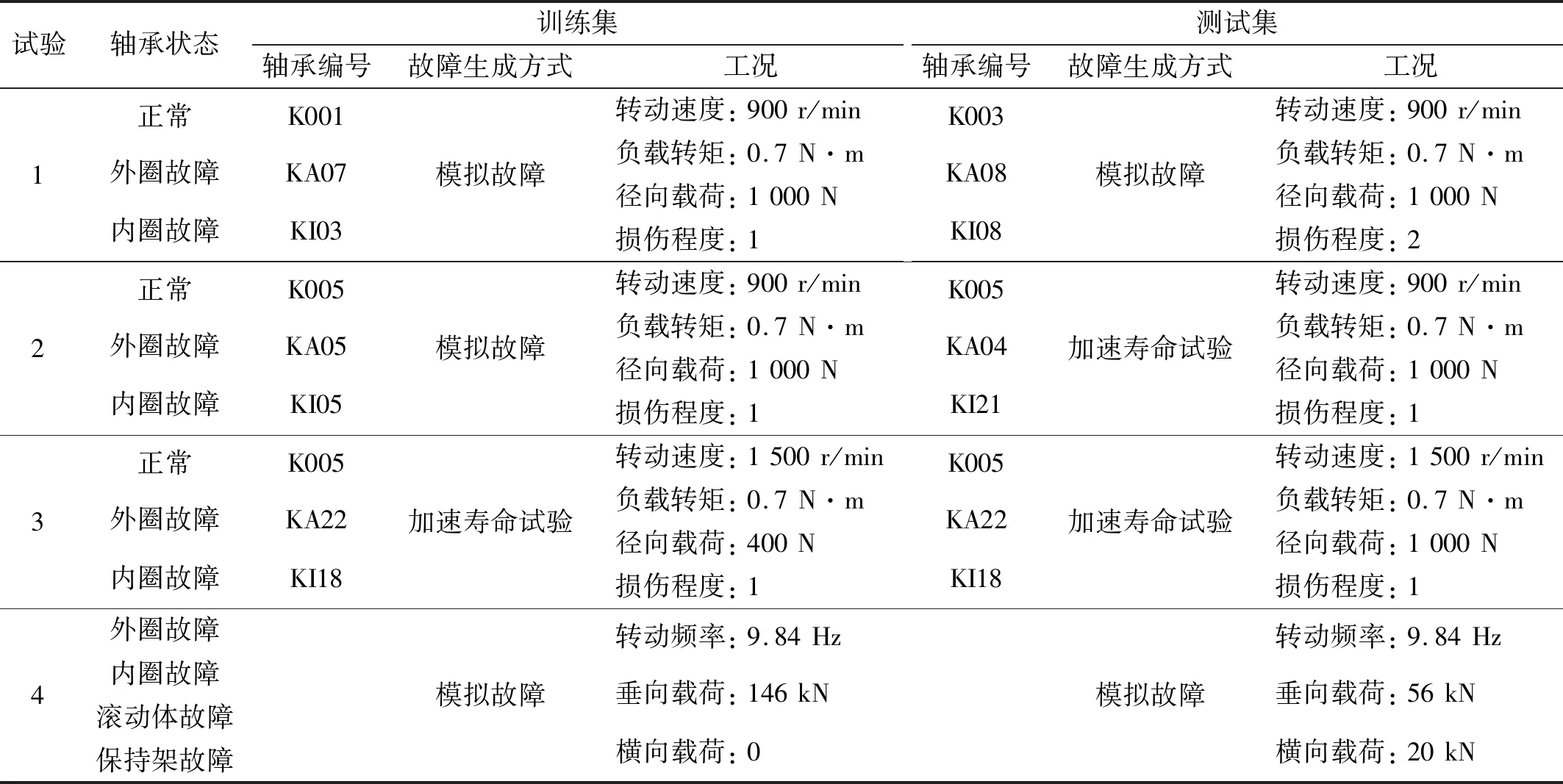
表1 4个轴承试验的训练集和测试集设置Tab.1 Training and test sample settings of four bearing experiments

图5 轮对轴承试验台Fig.5 Test rig for wheel set bearings
3.2 试验样本设置
为了获得足够的数据,对采集到振动数据进行分割。对表1中列出的试验1~试验3,将每个数据文件(时长4 s,共256 000个数据点)分割成等长的2 000个样本,每个样本包含1 024个数据点,相邻样本之间有一定的重叠,如图6所示。在每个试验中,三种轴承状态共计可获得6 000个训练样本。对每种轴承状态的训练样本,随机选取其中的1 600个样本(该类样本数的80%),人为将其标签去除,用作无标签样本,剩余样本仍保留其状态标签,即训练样本中总计有4 800个样本无标签,其余样本标注了其健康状态(标签)。采用类似的方法,从不同轴承/工况/故障程度的轴承数据可以获得300个测试样本,用以检验网络的性能。
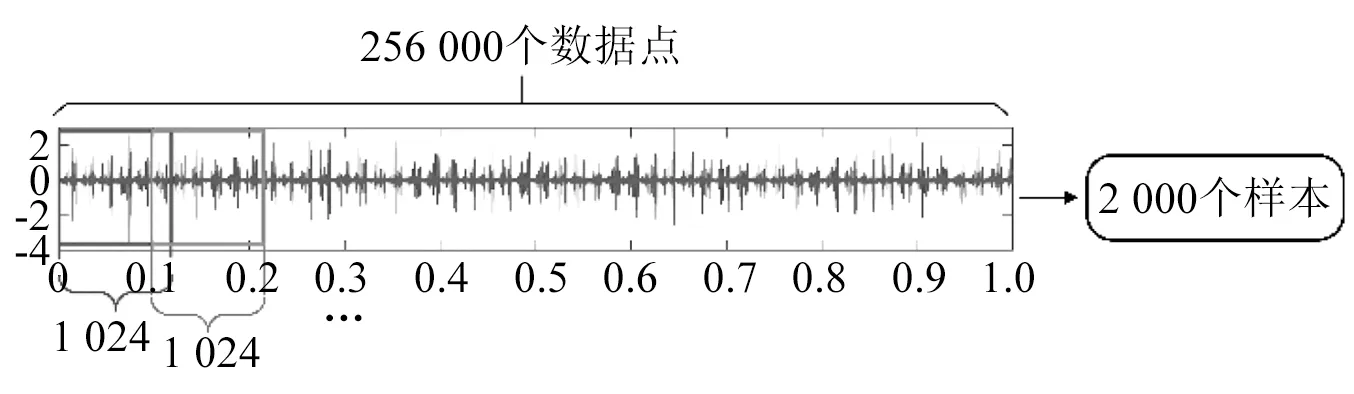
图6 试验1轴承数据分割示意图Fig.6 Illustration of bearing data segmentation in experiment 1
表1中列出的试验4,由于采样频率较低,设定每个样本包含4 096个数据点,其余样本设置方法同前,最终获得8 000个训练样本和400个测试样本,其中数据标签分别为外圈、内圈、滚动体和保持架故障,随机选取80%的训练样本去除其标签,其余样本标签仍保留。
根据表1设置:试验1分析相同工况和故障形式下,不同轴承和损伤程度的故障诊断性能;试验2针对同一类型的轴承,采用相同的工况和损伤程度,设置不同故障生成方式,即训练数据源于模拟故障,而测试轴承故障是加速寿命试验获得的;试验3中轴承故障均源于加速寿命试验,分析工况变化对迁移学习的影响;试验4则是轮对轴承不同载荷的迁移学习。
3.3 试验结果
为了分析本文提出的ISSL-GAN网络性能,选取了两种不同的网络进行对比。第一种方法为卷积神经网络,该网络由卷积层和全链接层组成,为了便于比较设定其结构与图4中分类器的结构相同。第二种对比方法采用半监督生成对抗网络,简写为SSL-GAN,设定该网络和本文提出的ISSL-GAN结构相同,但是没有加入增强特征匹配的算法。
本文提出的 ISSL-GAN网络中引入了增强特征匹配,在式(11)中需设定损失函数Lfake和LFM相应的系数λ和μ。考虑目前尚无合适的优化算法,本文采用少量数据预训练,对比不同系数设置所得的分类准确率,通过数值比较确定系数设置。以试验1数据为例,表2显示了设置不同系数预训练的部分结果,根据此表的结果设定系数为λ=0.5,μ=1。
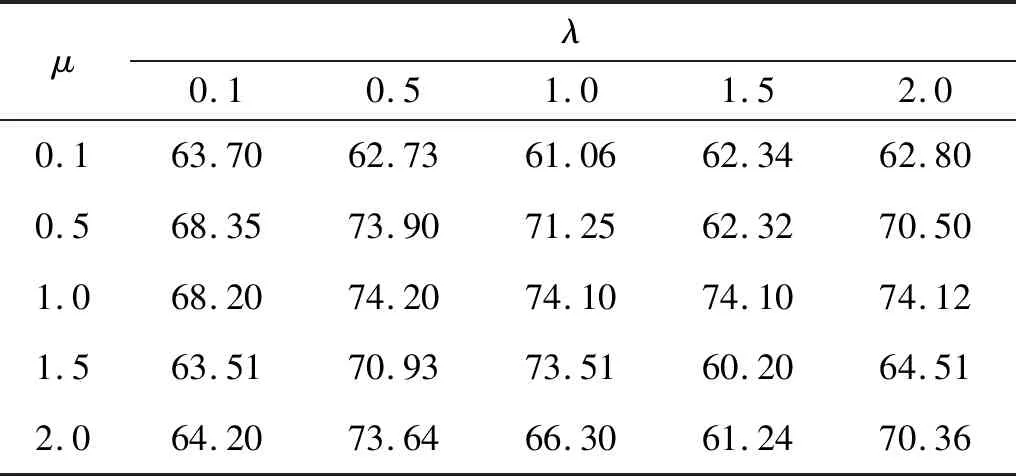
表2 设置不同损失函数系数所得网络的分类准确率对比Tab.2 Comparison of classification accuracies of networks obtained by setting different coefficients for the loss function %
试验中设置网络最大迭代次数设为100。三种网络的四组试验结果如表3所示。从表3中可以看出:试验1、试验2和试验4中本文的ISSL-GAN的分类准确率明显高于另外两种深度网络;试验3中三种深度网络的诊断结果相近。总体而言,本文所提的ISSL-GAN在四组试验中具有更高的诊断准确性。
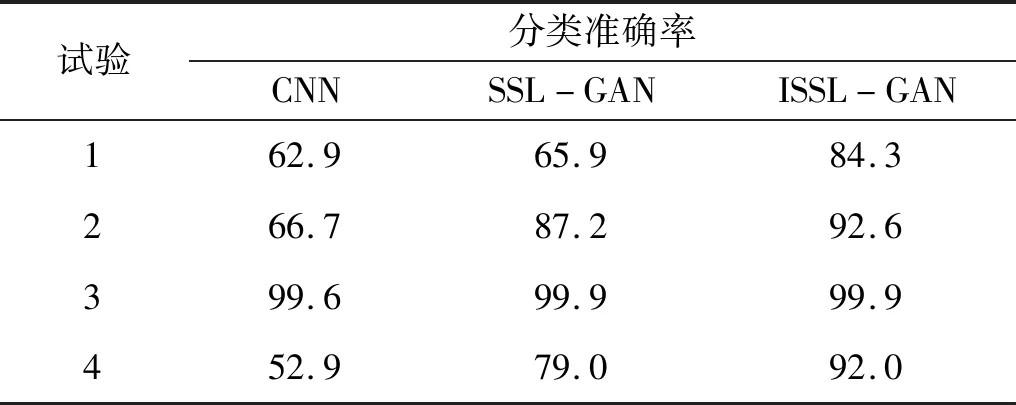
表3 三种深度网络的分类准确率结果Tab.3 Classification accuracies of three deep networks %
分析试验数据的设置可以发现,试验3中仅改变了载荷设定,其他设定均相同,因此训练数据和测试数据分布相近,因此三种深度网络的诊断性能相近。而对于训练集和测试集相差较大的另外三组试验,CNN因本身不含有对抗学习结构,其迁移学习效果较差;SSL-GAN得益于半监督学习的优势,其迁移学习的准确率相较于CNN有明显提升,试验2和试验4的分类准确率明显高于CNN。
考虑到试验1和试验4分析了不同类型的轴承,下面以这两组试验为例,进一步分析本文方法对每种轴承状态的识别性能。图7显示了试验1数据的诊断结果混淆矩阵,列出了每种状态具体的识别结果。
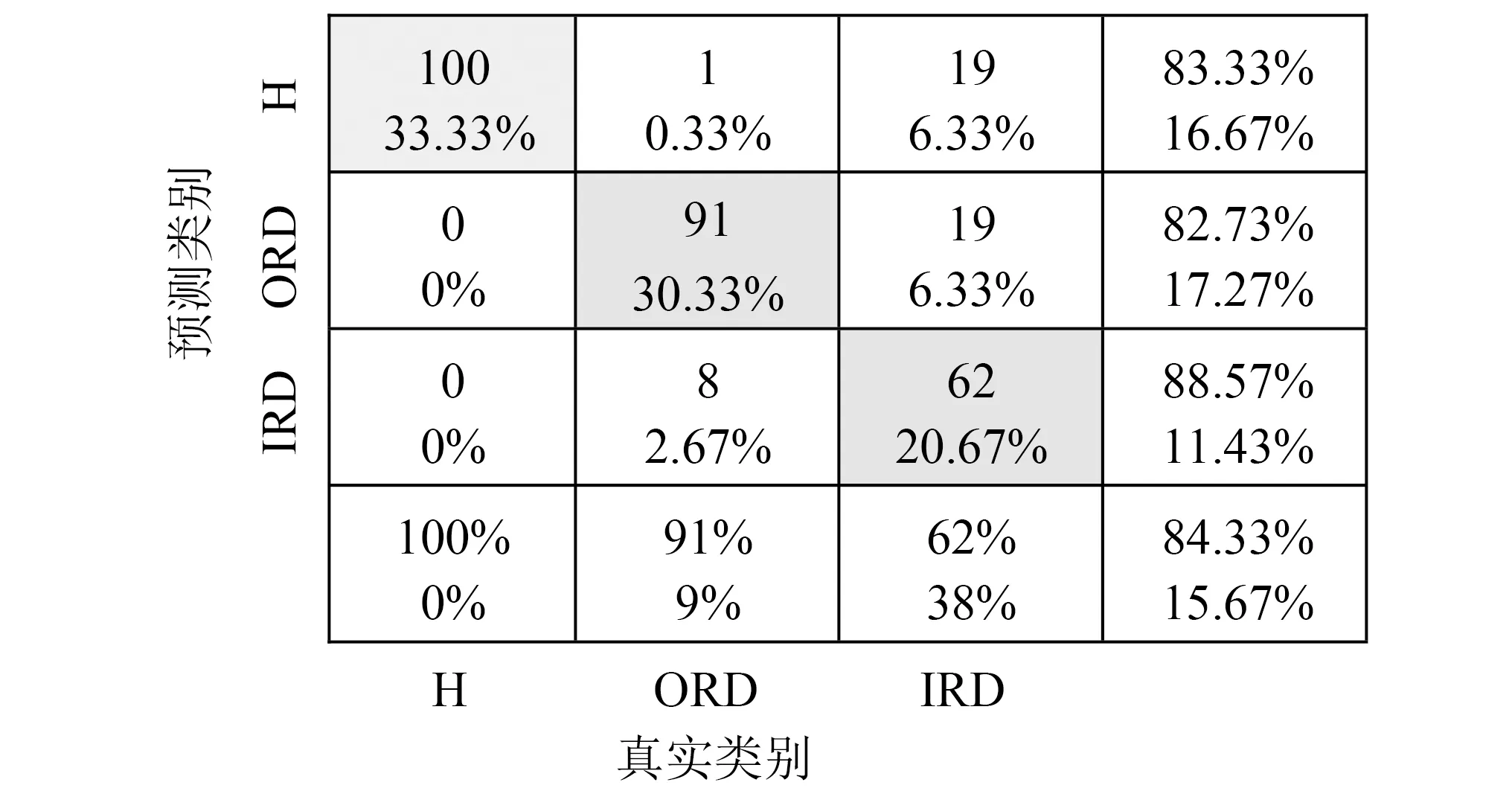
注:H (Health)为健康;ORD (Outer Race Defect)为外圈故障;IRD (Inner Race Defect)为内圈故障。图7 试验1轴承的ISSL-GAN混淆矩阵结果Fig.7 Confusion matrix obtained by applying the ISSL-GAN to bearing data in experiment 1
如图7所示,测试数据中100个健康轴承样本均被准确识别。100个外圈故障样本中有91个样本正确分类,在整个测试集中其准确率为(91/300)×100 = 30.33%;有一个样本被错分为健康样本,占整个测试集的(1/300)×100 = 0.33%,8个样本被错分为内圈故障,占整个测试集的(8/300)×100 = 2.67%。100个内圈样本中62个样本被正确分类,占整个测试集的20.67%。因此,采用本文方法的整体分类准确率为(253/300)×100 = 84.33%。根据此结果可以看出,所提网络能够准确区分故障和非故障样本,但部分内圈样本未能准确识别。
图8显示了试验4数据的诊断结果混淆矩阵。该试验中不包含健康轴承数据,所分析轴承均含有不同类型的故障。根据混淆矩阵的结果,本文方法对外圈故障样本能够准确识别,但对其他类型的故障有少量的错分,相比而言内圈和保持架故障识别效果略低,有少量错分为另一种故障,而滚动体故障识别效果较低,与传感器位置与振动幅度有关。整体分类准确率为92%,明显优于另外两种深度网络。
本文采用t-SNE(t-distributed stochastic neighbor embedding)算法展示训练前后训练样本和测试样本的类别分布变化。t-SNE 是一种非线性降维算法,可将高维数据降到2维或3维,便于分类结果可视化。为了清楚展示训练的效果,此处仅选取部分样本进行可视化,试验1和试验4的结果如图9和图10所示。
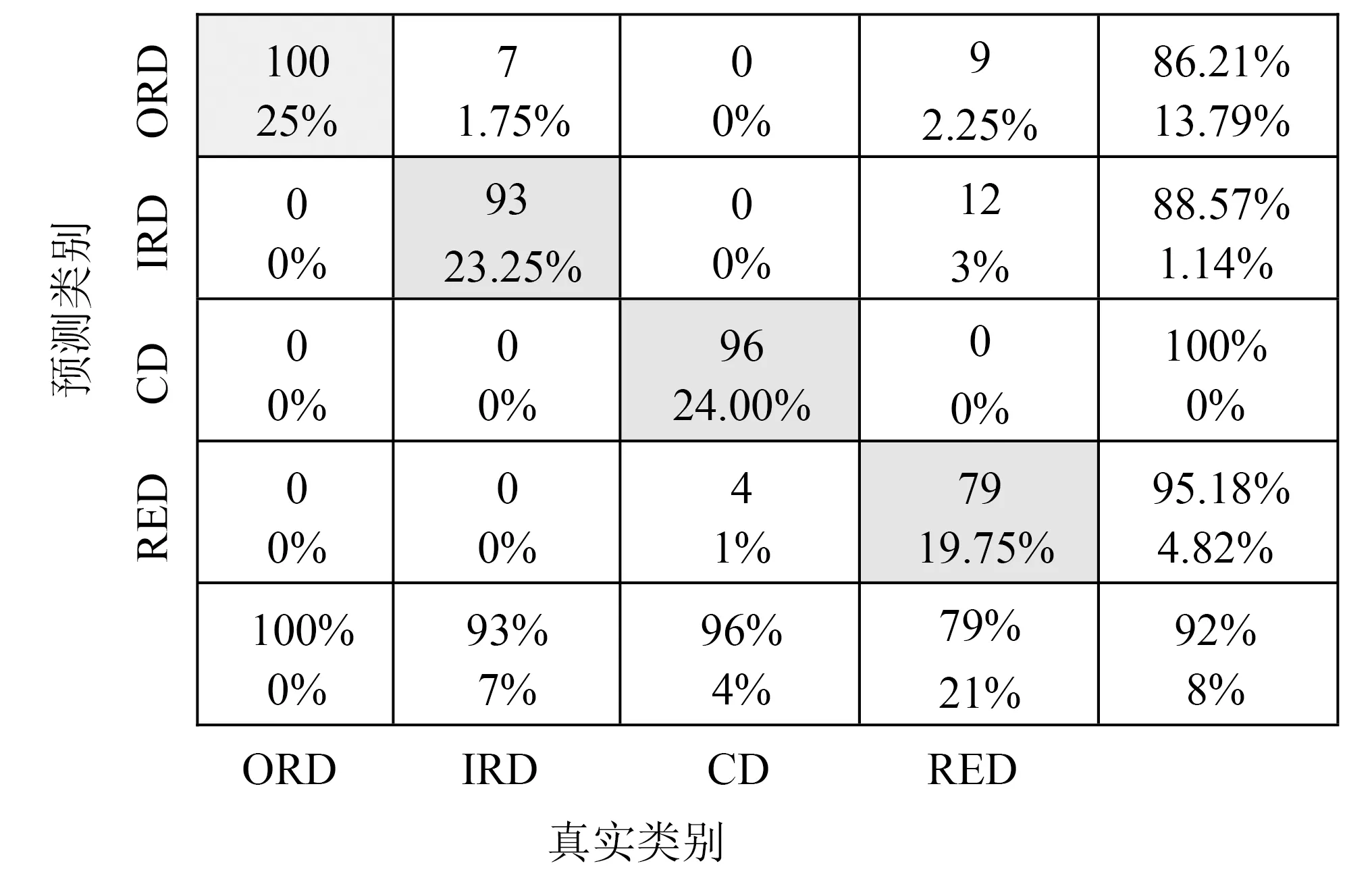
注:ORD (Outer Race Defect)为外圈故障;IRD (Inner Race Defect)为内圈故障;CD (Cage Defect)为保持架故障;RED (Rolling Element Defect)为滚动体故障。图8 试验4轴承的ISSL-GAN混淆矩阵结果Fig.8 Confusion matrix obtained by applying the ISSL-GAN to bearing data in experiment 4

图9 试验1:用ISSL-GAN训练前后的训练样本和测试样本的t-SNE类别示意图Fig.9 Experiment 1:t-SNE results of training and test samples before and after training the ISSL-GAN
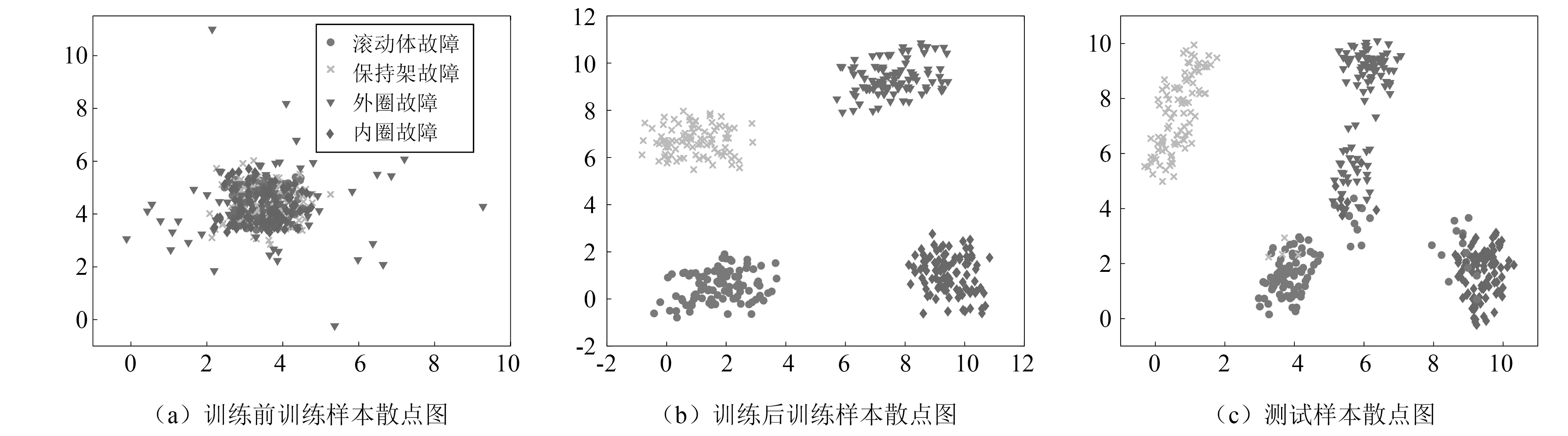
图10 试验4:用ISSL-GAN训练前后的训练样本和测试样本的t-SNE类别示意图Fig.10 Experiment 4:t-SNE results of training and test samples before and after training the ISSL-GAN
图9(a)和图9(b)为训练前后训练样本的类别分布,从图中可以看出,训练之前三种状态混杂在一起,而训练后三种状态可以完全区分开来。将训练好的网络用于测试数据分析,结果如图9(c)所示,类别之间的距离减小,相应的可区分性降低,因此整体分类准确率对比图9(b)下降。类似地,图10展示了训练前后训练样本和测试样本分类的可视化结果。结果表明,本文所提方法可以极大地改善不同类别数据的分布,减小同类数据的间距,增加不同类别之间的距离,使得类别差异更易辨识,对新的测试数据亦可获得较好的诊断结果。
图11对比了四组试验中不同网络随迭代次数增加时分类器损失值和测试样本分类准确率的变化。从图中可以看出ISSL-GAN方法在不同试验数据的训练过程中均具有较快的收敛速度;随着训练次数的增加,测试数据的分类准确率逐步升高。对比SSL-GAN和CNN,CNN收敛较慢,准确率较低。试验1、试验2和试验4结果的共同点在于:CNN在训练终止时测试数据的分类准确性较低,这与表2的结果一致;SSL-GAN的测试数据分类准确性波动较大,而本文ISSL-GAN仅用较少的训练次数就可以达到较高的分类准确性。上述试验结果表明,本文所提的ISSL-GAN对不同的迁移任务均具有更好的分类性能和效率,利用少量标签数据即可实现准确的轴承智能诊断。
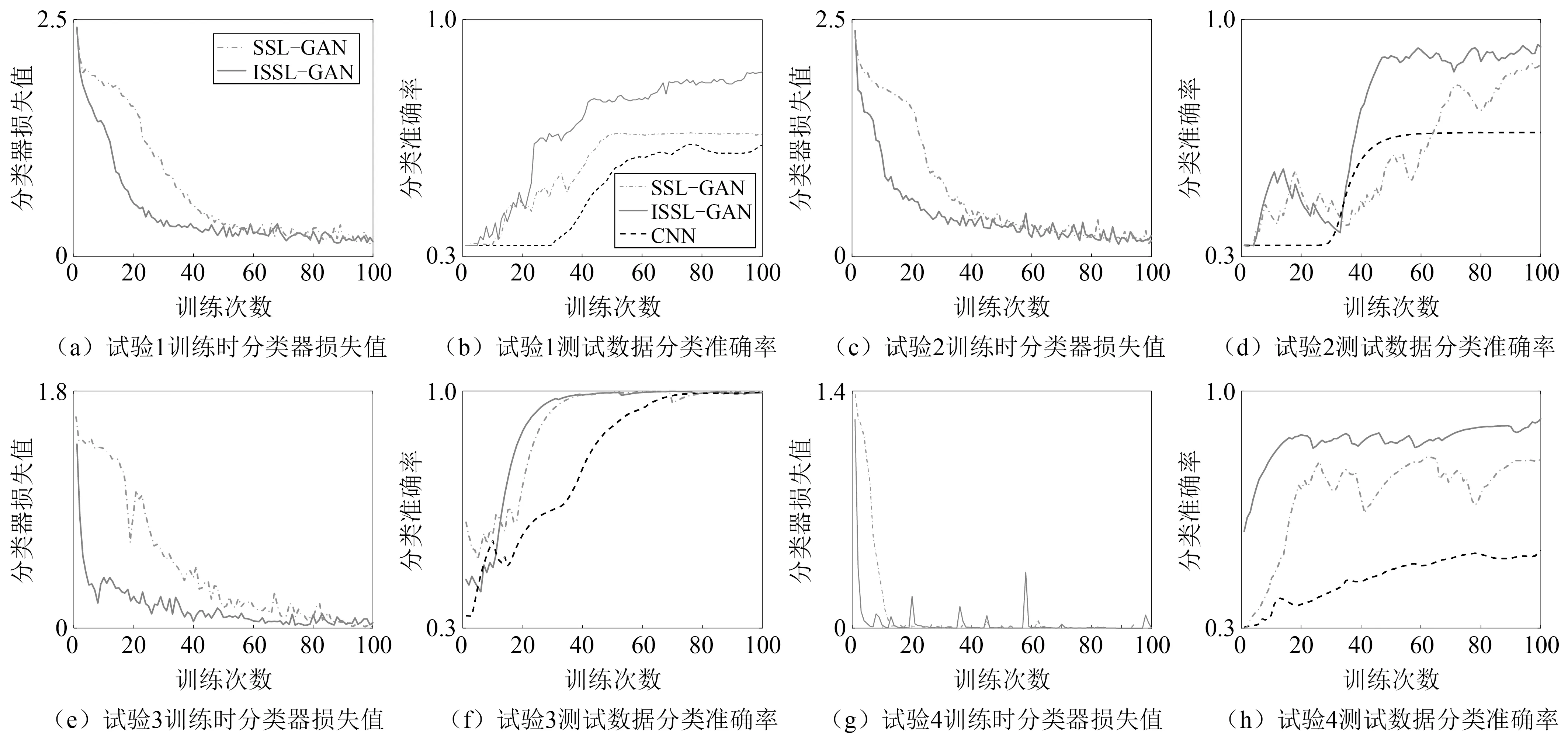
图11 三种深度网络的训练和测试阶段性能对比Fig.11 Performance comparisons of three deep networks during the training and test processes
4 结 论
本文针对滚动轴承智能诊断面临的少量有标签数据引发的诊断问题,运用深度迁移学习和半监督学习的优势,提出了一种改进半监督生成对抗网络,用以提高少量标签轴承数据的准确故障诊断。
本文所提方法在常规生成对抗网络框架基础上,用多分类的分类器替代其二分类判别器,通过网络中生成器与分类器的对抗学习来提高分类器对轴承数据中不同类别的隐含特征的提取能力;结合半监督学习,利用有标签数据提升分类器的类别辨识能力,避免了无监督学习效率低的问题。同时,考虑到模型的复杂性,提出了增强特征匹配算法,利用中间层的深度特征来提高对抗训练的收敛速度。
对两组不同类型的轴承设定了四组迁移任务,试验结果表明,本文所提ISSL-GAN的分类准确性和快速性优于CNN和基于半监督学习的GAN网络。在深度迁移学习过程中,若训练集与测试集数据分布相似,则三种深度网络均可获得较高的分类准确率;若二者相差较大(试验1——变轴承、变故障程度;试验2——变故障生成模式,试验4——轮对轴承变载荷),则三种方法的迁移学习能力和效率相差较大,本文所提方法在训练过程中分类器损失值下降和测试样本分类准确性方面均呈现出更好的结果。最终,本文所提方法利用少量的有标签数据实现了不同轴承的准确智能故障诊断。
猜你喜欢
防爆电机(2022年4期)2022-08-17
电子产品世界(2022年4期)2022-04-21
防爆电机(2021年5期)2021-11-04
防爆电机(2021年3期)2021-07-21
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
Coco薇(2015年11期)2015-11-09
科技视界(2015年24期)2015-08-22
