
机器学习在量子通信资源优化配置中的应用*
2022-12-05 11:12陈以鹏刘靖阳朱佳莉方伟王琴
物理学报 2022年22期
陈以鹏 刘靖阳 朱佳莉 方伟 王琴†
1)(南京邮电大学,量子信息技术研究所,南京 210003)
2)(南京邮电大学,宽带无线通信与传感网教育部重点实验室,南京 210003)
在未来量子通信网络的大规模应用中,如何根据当前用户实际情况实现资源优化配置,比如选择最优量子密钥分发协议(quantum key distribution,QKD)和最优系统参数等,是实现网络应用的一个重要考察指标.传统的QKD 最优协议选择以及参数优化配置方法,大多是通过局部搜索算法来实现.该方法需要花费大量的计算资源和时间.为此,本文提出了将机器学习算法应用到QKD 资源优化配置之中,通过回归机器学习的方式来同时进行不同情境下的最优协议选择以及最优协议的参数优化配置.此外,将包括随机森林(random forest,RF)、最近邻(k-nearest neighbor,KNN)、逻辑回归(logistic regression)等在内的多种回归机器学习模型进行对比分析.数据仿真结果显示,基于机器学习的新方案与基于局部搜索算法的传统方案相比,在资源损耗方面实现了质的跨越,而且RF 在多个回归评估指标上都取得了最佳的效果.此外,通过残差分析,发现以RF 回归模型为代表的机器学习方案在最优协议选择以及参数优化配置方面具有很好的环境鲁棒性.因此,本工作将对未来量子通信网络实际应用起到重要的推进作用.
1 引言
量子密钥分发(quantum key distribution,QKD)是量子保密通信的核心,其安全性基于物理学基本原理,原则上能够为远距离通信的双方(Alice和Bob)提供无条件安全的信息保障.第一个QKD 协议由Bennett和Brassard[1]于1984 年提出,此后简称BB84 协议,其安全性已经得到严格的数学证明[2,3],也是目前应用最为广泛的一种QKD 协议.原始的BB84 协议需要采用理想的单光子源,但是在实际应用中,大多采用弱相干光源(weak coherent source,WCS),该类光源中的多光子成分使得窃听方(eve)实施光子数分离攻击(PNS)成为可能.为了解决PNS 攻击,科学家提出了诱骗态方法[4−6].此外,探测端的测信道漏洞也是Eve 攻击的对象[7−10].为了关闭探测器端的诸多侧信道漏洞,加拿大Lo等[11]和英国Braunstein等[12]于2012 年各自独立地提出了测量设备无关量子密钥分发(measurement-device-independent,MDI)协议.MDI-QKD 结合诱骗态方案可以免疫所有针对探测段的攻击手段,因此提出之后受到了广泛的关注[13−18].在实际应用中,MDI-QKD的安全密钥率和传输距离受统计起伏效应影响严重.在此背景下,双场量子密钥分发协议(twin-field quantum key distribution,TF-QKD)于2018年被Lucamarini等[19]提出.TF-QKD 保留了MDIQKD的测量设备无关特性,并打破了无中继量子信道码率-距离限制(PLOB 界)[20,21],进一步提高了量子通信的实用性能,这也使其成为目前关注度最高的QKD 协议之一[22−24].
在实际执行量子密钥分发之前,首先需要根据用户实际情况选择合适的密钥分发协议[25,26],同时对选定的量子密钥分发协议进行相关参数的优化配置[27],从而确保通信双方之间能够实现最优的安全密钥共享,本文将这个过程称之为最优协议选择以及最优参数配置.传统的解决方案可以使用遍历收索方法或维度下降局域收索(LSA)优化算法[28].但是以上方法在实际应用时需要消耗大量的计算资源和计算时间,无法满足实时量子通信的需求.另一方面,由于机器学习在数据处理方面的优势,其常被用于协助解决量子信息中的部分问题[29,30].鉴于此,本文考虑使用机器学习方案替代上述传统方案,即通过机器学习实现回归模型来建模传统方案.仿真结果表明,相较于传统方案,机器学习方案大幅减少了时间资源消耗,因而显示出在实时量子通信应用中的巨大应用前景.
2 机器学习方案
监督机器学习过程可以简单解释为通过特征数据到标签数据的映射,去学习一个具有指定数据预测功能的机器学习模型,即基于某种机器学习算法F(x)通过X →Y的映射过程去学习获取具有数据预测功能的ML 模型f(x).以几种主流的量子密钥分发协议:BB84-,MDI-以及TF-QKD为问题背景,并主要从数据的获取和机器学习模型的构建两方面来介绍本文工作.
2.1 ML 标签数据与特征数据的获取
为简单起见,本文在评价最优QKD 协议时暂不考虑系统安全等级等因素,仅把安全密钥速率(R)作为评定特定情境下最优QKD 协议的关键指标.在实际QKD 过程中,R值与下面几种系统因素紧密相关:探测器的暗记数率(Y0)、探测效率(η)、本底误码(ed),通信发送方发送的光脉冲数(N),通信双方间的通信距离(L).将系统参数组合成5 维向量X=[Y0,ed,η,N,L],并将其作为ML的特征数据格式.
在讨论ML 所需标签数据格式之前,首先对获取仿真数据过程中所涉及到的3 种主流QKD 协议及其诱骗态方法进行简要论述.对于BB84 协议,使用的是三强度诱骗态方法[5].在该方案中,参数优化过程所涉及到的主要配置参数包括:信号态强度µ、诱骗态强度ν、发送信号态脉冲的概率Pµ、发送诱骗态脉冲的概率Pν、信号态制备在Z 基的概率Pzµ、诱骗态制备在X 基的概率Pxν.对于MDI 协议,使用的是四强度诱骗态方法[31],参数优化涉及到的配置参数主要包括:信号态强度µ、诱骗态强度ν和ω、发送信号态µ的概率Pµ、发送诱骗态ν的概率Pν、发送诱骗态ω的概率Pω.对于TF 协议,使用的是四强度诱骗态方法[32],对应系统参数包括:信号态强度µ、诱骗态强度ν,ω及其对应选择概率Pµ,Pν,Pω,以及失败概率ϵ等.
为了在ML 标签数据格式中表征所选的最优协议,本工作将3 种协议对应编号1,2,3,并将其作为标签向量的一个维度.则不同协议的标签格式有:YBB84=[µ,ν,Pµ,Pν,Pzµ,Pxν,1],YMDI=[µ,ν,ω,Pµ,Pν,Pω,2],YTF=[µ,ν,ω,Pµ,Pν,Pω,ϵ,3].研 究发现BB84 协议和MDI 协议的标签向量格式均为6维,而TF 协议的标签向量格式为7 维.为了构建统一格式的标签向量,采用占位法来抹平上述差异,即YBB84=[µ,ν,Pµ,Pν,Pzµ,Pxν,NUM,1],YMDI=[µ,ν,ω,Pµ,Pν,Pω,NUM,2].进一步地,得益于占位方式的使用,不同协议能够很好的保证参数维度的一致性,这更有利于本工作推广到其他多种不同的QKD 协议.
在标签数据格式和特征数据格式构建完成之后,需要获取通用的特征数据和标签数据.根据实际经验,本文将特征数据格式中的5 个系统参数限制到表1 所示的特征范围中.本工作在5 个系统参数的特征范围内进行等间隔的取值,以间隔n为例,则可以生成n5特征数据.这里需要注意一点,对于本底误码的取值而言,TF 协议是其他两个协议的4 倍.随后利用不同QKD 协议的密钥生成公式,并结合LSA 算法优化不同协议的配置参数,以获取3 份数据量大小为n5的标签数据.接着通过比较不同协议的密钥率大小,将3 个协议关联起来,即直接根据密钥率R将无效数据剔除后的YBB84,YMDI和YTF,这3 份标签数据合并为一份标签数据Y.至此,便得到了ML 所需的特征数据X和标签数据Y.

表1 系统参数的特征范围Table 1.Characteristic range of system parameters.
2.2 数据集划分及回归模型构建
特征数据和标签数据统称为ML 数据集,经过上述的相关操作整个数据集的大小在10 万量级.随后本工作采用归一化(normalization)操作来加速ML 模型对数据集的学习拟合,表示为núm=(num– min)/(max– num).从数据集中随机划分出80%用于ML 模型训练的训练集和20%用于ML 模型性能评估的测试集.后续,在训练集上先后进行随机森林、最近邻、逻辑回归等ML 模型的学习训练.鉴于RF 模型取得了最佳的预测效果,接下来仅以RF为例,介绍其构建的主要过程.
随机森林(random forests,RF)[33]是基于Bagging(bootstrap aggregation)集成算法的典型范例,其基本单元是决策树(decision tree)[34][35],直观理解就是众多决策树构成一片随机森林.在机器学习任务中,随机森林既可以用于分类任务又可以用于回归任务,本文主要是利用RF 算法训练一个回归模型.RF 回归模型,是由众多回归决策树集成而来的.回归树在训练时,每确定一个节点,就会将特征数据对应的特征空间进行一次划分,划分形成的单元会以该单元内的均值作为其输出值.RF 中除了森林这一重要概念之外,还有随机的概念.随机主要有两种含义:其一,从训练集中随机有放回的拿取样本数据用于决策树的学习,有放回的随机抽取就是Bagging 算法的直观体现;其二,随机选取特征向量中的特征用于决策树的学习.随机的样本数据、随机的特征选择,导致RF 中的决策树各不相同,而RF 最终输出的结果则取决于不同决策树回归输出的均值.图1 展示了本工作中RF 回归模型的算法框架.
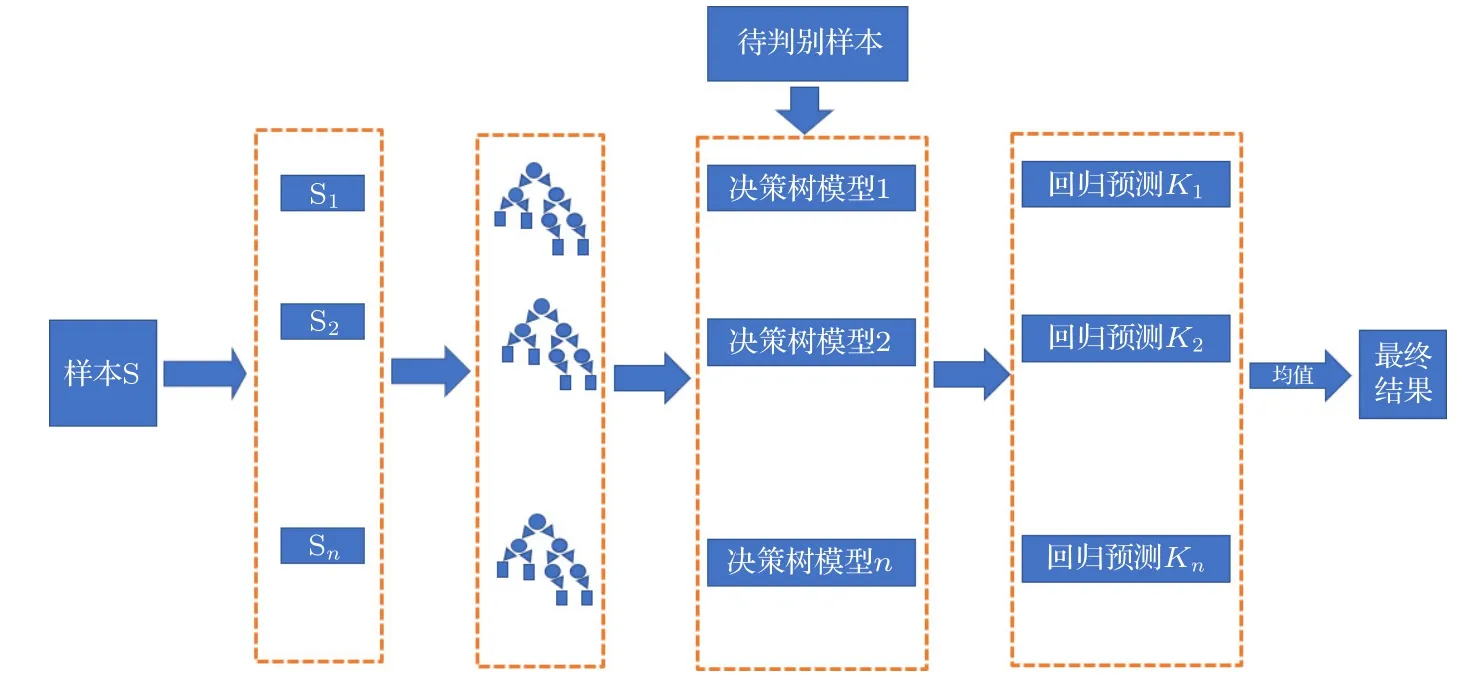
图1 随机森林回归模型的算法框架.Fig.1.The algorithm framework of random forest regression model.
RF 在训练集上进行学习拟合时,需要对其算法的一些参数进行调优,才能获取预测效果最好的回归模型.这里主要使用网格搜索(GridSearch)和交叉验证(CV)的方法来对Sklearn 中的随机森林Regressor 模型进行调参.GridSearch 可以理解为在指定参数范围内按照一定步长将候选参数所有可能的取值进行排列组合,即生成“网格”.而交叉验证则是将训练集进一步切分,以常见的K折交叉验证法为例,训练集中的K-1 份使用网格参数进行训练,训练集中剩余的1 份则用于评估,重复K次并选出K次平均评分最高时的网格参数,进而完成参数调优.本工作中RF 回归模型的最终调参结果是:n_estimators为90、max_depth为56,min_samples_split为1.其中,第1 个参数用于指定RF 原始训练集有放回随机抽取样本数据所生成的子数据集个数;第2 个参数用于指定生成决策树的最大深度;第3 个参数用于指定决策树节点可分的最小样本数.在完成RF 回归模型的构建后,对特征数据X中5 个系统参数的重要性进行评估.结果表明:距离L对RF 模型的影响最大;其他几个系统参数的重要性相对较小,具体的重要性比重如图2 所示.

图2 系统参数对随机森林回归模型的重要性.Fig.2.Importance of system parameters to RF regression model.
3 方案评估与讨论
在测试集上对已获ML 模型进行性能评估时,需要注意标签数据Y中包含了协议标号和该协议对应的配置参数.不同于分类模型直接获取协议标号,本工作的回归模型需要对回归预测的协议标号进行取整操作才能正确的实现协议分类.下面简要介绍3 种常用回归模型的性能评估指标,并对本文的RF,KNN,LR 模型进行比较分析.
平均绝对误差(mean absolute error,MAE),用于评估回归模型预测结果和真实结果差异的平均值,其值越小说明ML 模型对数据的拟合效果就越好,可以表示为:均方误差(mean squared error,MSE),用于计算预测结果和真实结果对应样本点误差平方和的均值,其值越小说明ML 模型在数据预测方面的性能就越好,可以表示为:决定系数(coefficient of determinationRsquared,Rsquared),一般被认为是衡量线性回归相对较好的指标,其取值范围在0—1 之间,越靠近1 说明ML 模型对数据的拟合效果就越好,可以表示为:上述表达式中的N为测试集数据量、yi为测试集中的真实结果、yi为ML 模型使用测试集预测出来的结果、这里将回归模型的评估指标以及预测准确率如表2 所示.
由表2 可知,基于相同训练集获取的RF 回归模型相较于KNN和LR 模型,在MAE,MSE,R2预测准确率等性能指标上都取得了最好的表现,这也说明RF 适用于最优协议选择和参数优化配置的任务.此外,将ML 方案和传统方案在个人电脑上的具体耗时情况如表3 所示.个人电脑的硬件配置为:Intel(R)Core(TM)i1-9750H CPU @2.60GHz;NVIDIA GeForce GTX 1650;16 GB DDR42667 MHZ.具体的时间资源损耗统计过程,本工作在指定某一用户需求下,先后使用两种不同方案进行时间统计.机器学习方案:在获取训练完成的模型后,将需求数据输入模型,模型可以在短短数秒之内给出协议选择以及参数配置.传统方案:根据提供的用户需求数据,采用LSA 优化并获取3 个协议的安全码率,之后对3 个协议的码率大小进行比对,将成码率最大的协议作为最优协议.该过程的时间损耗主要集中在采用LSA 对协议参数进行优化获取最佳码率这个过程,耗时超过24 h.从表3 结果来看,两种方案选择的协议相同且协议配置参数的残差在0.025 以内,但是两者的耗时却存在着巨大的差异,这进一步表明机器学习在很大程度上满足了简化并加速量子通信资源配置的目的.
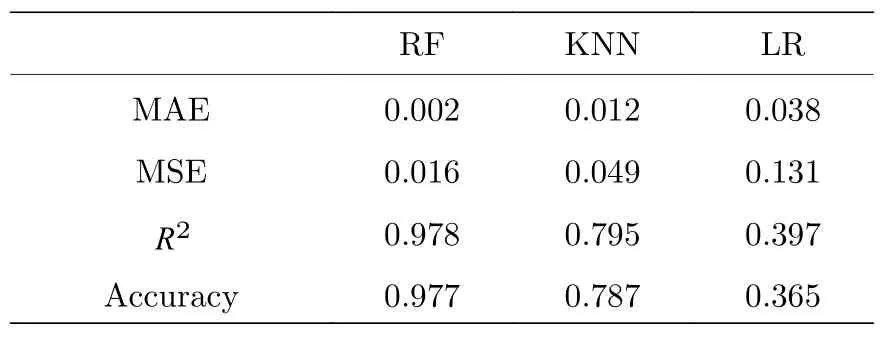
表2 不同回归模型的评估对比Table 2.Evaluation and comparison of different regression models.

表3 时间资源损耗记录表Table 3.Time resource wastage table.
为了更加直观地展示RF 方案的可行性,接下来就RF的残差和混淆矩阵进行可视化分析.图3为RF 回归模型在训练集和测试集上的残差图,这里的残差分析针对的是协议的配置参数,即标签数据Y向量中处于第一维的配置参数.图3 中的蓝色点为训练集上的残差情况,绿色点为测试集上的残差情况.经统计,多数偏差都低于0.025,这表明RF 机器学习方案具有相对较好的鲁棒性.图4展示了协议选择的混淆矩阵,主对角线的协议选择为正确的选择情况.从图4 可以看出,RF 模型在不同情境下都能以较大的概率做出正确的协议选择.通过对混淆矩阵可视化数据的相关计算,可以求得RF 回归模型的预测准确率在98%左右,这也与表2 中通过函数接口计算的准确率基本相当.

图3 随机森林回归模型的残差图Fig.3.Residual diagram of RF regression model.
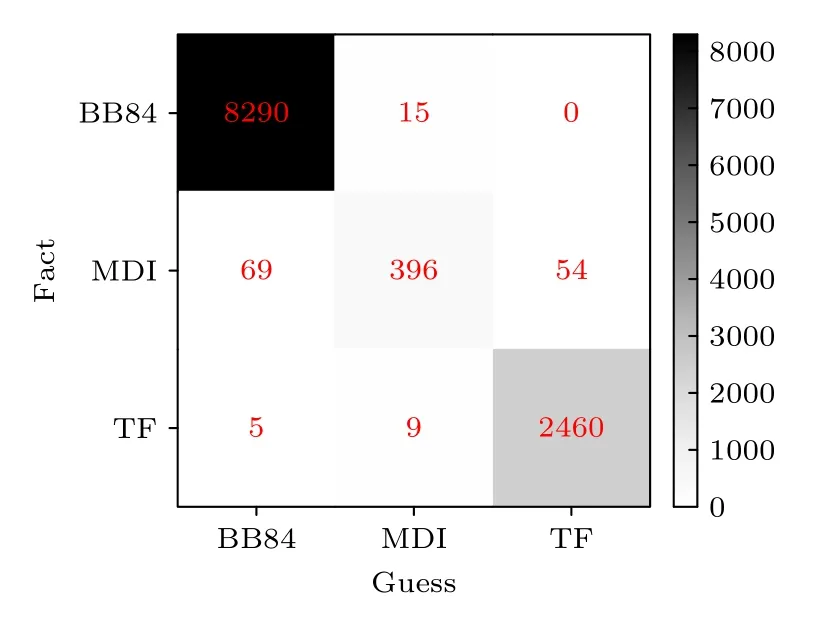
图4 随机森林回归模型的混淆矩阵Fig.4.Residual diagram of RF regression model.
4 总结与展望
本文提出了基于机器学习的最优协议选择以及优化参数配置的新方案,相较于传统方案而言,新方案大幅度地减少了时间资源损耗,通过残差分析证明机器学习方案具有较好的鲁棒性.此外,本文详细地介绍了机器学习方案的流程,主要是通过监督学习去实现满足协议选择以及参数配置功能的回归模型.在构建的多个回归模型中,RF 模型取得了最佳的表现:均方误差为0.002、平均绝对误差为0.016、R2为0.978.综上,本工作的研究对未来即时量子通信网络的大规模应用以及多协议高速QKD的发展都有很好的参考价值.
感谢南京邮电大学通信与信息工程学院张春辉老师和周星宇老师的帮助与讨论.
猜你喜欢
量子电子学报(2022年2期)2022-04-16
量子电子学报(2022年1期)2022-02-25
故事作文·低年级(2022年2期)2022-02-23
故事作文·低年级(2022年1期)2022-02-03
北京电子科技学院学报(2020年2期)2020-11-20
网络安全和信息化(2019年1期)2019-12-22
科学大众(中学)(2019年2期)2019-04-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
太空探索(2016年10期)2016-07-10
