
结合GIS与FNN-SGD的雷波县泥石流易发性评价
2023-01-02 12:06董艾嘉邬春学
软件导刊 2022年11期
董艾嘉,邬春学
(上海理工大学光电信息与计算机工程学院,上海 200093)
0 引言
雷波县位于四川省西南部,地质灾害对雷波县可持续发展的制约日益显著[1-2]。自然灾害从本质上来说是多面性与不可预测的[3],泥石流易发性分析是评估危害和风险的第一步,其显示了一个地区发生泥石流的可能性与其地貌特征有关[4]。泥石流灾害的发生会给当地居民带来很大的安全隐患,因此对雷波县泥石流易发性进行评价是非常必要的[5]。
泥石流易发性评价结果会影响对雷波县泥石流易发地的预测,因此找出精度较高的模型是实现泥石流易发性评价的重要前提[6]。随着GIS 技术的发展,传统的多元统计方法可分为概率和确定性预测,已广泛应用于灾害预测与评估中[7]。随着科技的进一步发展,机器学习技术在地质灾害预测中也得到了广泛应用,从神经网络到前馈神经网络(Feedforward Neural Network,FNN),由单层感知器到多层感知器,克服了感知器不能对线性不可分数据进行识别的弱点。文献[8]通过神经网络模型,可较好地处理区域内灾害易发性与影响因子的非线性关系,对评价因子的权重计算更准确。逻辑回归(Logistic Regression,LR)通过建立多元线性回归方程,可明确表示因变量与一个或多个自变量之间的多元回归关系,从而预测泥石流的易发地。文献[9]采用逻辑回归模型对干热河谷区进行泥石流易发性评价,可为该地区泥石流预测和防治提供参考依据。随机森林(Random Forest,RF)可处理具有高维特征的输入样本,且不需要降维,能够评估各个评价因子在分类问题上的重要性。文献[10]将随机森林模型应用于泥石流敏感性分析,无需提前设置因子权重,即可对评价因子进行重要性分析,便于分析各评价因子对泥石流发育的影响。随机梯度下降(Stochastic Gradient Descent,SGD)可将特征缩放及均值归一化,以保证特征取值在合适的范围内。文献[11]采用随机梯度下降法选取合适的学习速率,使得模型以较快速度收敛到最优解,因为每次选取一个样本计算随机梯度,从而大大减小了每次更新所用时间。
考虑到雷波县泥石流样本数量的有限性,虽然随机过采样通过简单复制样本的策略增加少数类样本可实现样本均衡,但是容易造成模型过拟合,从而导致模型学习到的信息过于特别而不够泛化,因此本文采用改进的随机过采样算法(Synthetic Minority Oversampling Technique,SMOTE)。泥石流灾害点共有39 个,潜在泥石流灾害点有114 个,将其视为正样本(153 个),通过合成少数类过采样技术,将少数类样本合成新样本添加到数据集中。最终使得泥石流负样本与正样本数量相同,得到新的均衡的负样本(153 个),从而使正负样本比例均衡。随机选择70%的正样本(153个)和负样本(153个)作为训练样本,剩余30%的数据作为测试样本。
评价因子的选择也是保证评价模型准确、合理的关键前提。在分析雷波县地质条件和社会活动的基础上,结合雷波县地质灾害分布情况,利用研究区域资料、地理资源网站、遥感影像提取了14 个对泥石流有影响的因子,每个评价因子相互独立,并分析各个因子之间的联系,采用频率比(Frequency Ratio,FR)对评价因子进行辅助分析[12]。其中10 个因子影响显著,包括降水量、高程、坡度、坡向、岩性、剖面曲率、归一化植被指数、到河流距离、土地利用情况、到公路距离与雷波县泥石流发生之间存在明显关联,可作为雷波县泥石流易发性评价体系中的评价因子。
泥石流易发性分布图可为地质灾害的防治管理提供依据[13]。利用FNN-SGD 模型对雷波县泥石流的易发性进行评价,并与前馈神经网络、逻辑回归、随机森林3 种模型的结果进行分析比较,将雷波县泥石流易发性划分为5 个等级,利用GIS 绘制易发性分布图,并使用ROC 曲线验证模型的准确率,得出前馈神经网络、逻辑回归、随机森林、FNN-SGD 的准确率分别为97.6%、93.1%、95.4%、98%,预测成功率分别为96.3%、90.9%、93.6%、97.1%。准确率与预测成功率之间的差值可体现模型的稳定性,按照由大到小排序分别为逻辑回归(2.2%)、随机森林(1.8%)、前馈神经网络(1.3%)、FNN-SGD(0.9%)。由此可知,FNN-SGD模型比较稳定、可靠,具有良好的泛化能力。
本文在上述研究基础上,创新地提出一种前馈神经网络结合随机梯度下降(Feedforward Neural Network and Stochastic Gradient Descent,FNN-SGD)模型,并与前人研究的单模型进行比较,验证该模型的准确率和稳定性。结果表明,前馈神经网络相比随机森林对于评价因子权重的计算更为准确;逻辑回归模型在建模过程中受到的主观干扰较大;FNN-SGD 模型相比其他模型的准确率更高、效果更好,可提高雷波县泥石流易发性区域划定精度,更适用于雷波县泥石流易发性评价。
1 相关技术
1.1 优化随机过采样
对于特定的研究区域,泥石流作用下的面积总是小于总面积,使得样本数据不平衡。对于某一不平衡数据集,分类越不平衡,准确度越低。当数据相对平衡时,分类效果最好。数据平衡是通过改变数据分布来实现的,其中最常见的策略是过度采样和采样不足[14]。
本研究的主要目的是预测雷波县的泥石流易发性分布。由于雷波县的泥石流样本数量有限,而且不同研究区域引发泥石流的外部因素与地形条件存在较大差异,因此采用研究区域以外的泥石流灾害样本数据进行平衡的方法是不可取的[15]。
在实际应用中,泥石流数据很难满足多元正态分布及变量之间的相互独立。本文将泥石流灾害点视为正样本,非泥石流灾害点视为负样本,若正负样本不均衡将会对算法的学习过程造成很大干扰,较少的正样本有可能会被预测为数量较多的负样本。为解决正负样本不平衡的问题,本研究采用SMOTE 算法,其是一种优化的随机过采样算法。泥石流灾害点共有39 个,潜在泥石流灾害点有114个,将其视为正样本(153 个),通过合成少数类过采样技术,将少数类样本合成新样本添加到数据集中。
随机选取一个少数类样本,以欧式距离为标准计算出其到所有样本的距离,得出k 近邻。根据样本不均衡比例,设定一个采样比例来确定采样倍数n。对任意一个少数类样本x,从其k 近邻中随机选若干样本。对于任意一个随机选出的近邻,挑选[0,1]之间的随机数乘以随机近邻与x特征向量的差,然后再加x,如公式:
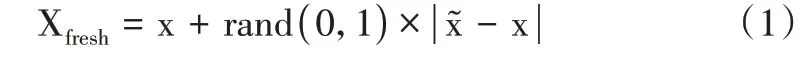
最终,使得泥石流负样本与正样本数量相同,得到新的均衡的负样本(153个),使得正负样本比例均衡。
泥石流易发性预测统计模型是通过训练样本建立自变量与因变量之间的关系,然后通过检验样本验证其关系。因此,机器学习模型需要用两个单独的数据样本进行训练与检验。为识别与区分训练集和验证集,可使用不同策略,采用最适用的一次性随机选择方法[16]。本文研究区域分为306 个单元,其中39 个单位是历史灾难点,114 个单位是潜在的泥石流灾难点,将其视为正样本,剩余的153个单元视为负样本。在构建模型前,随机选择70%的正样本(153 个)和负样本(153 个)作为训练样本,剩余30%的数据作为测试样本。
1.2 前馈神经网络
前馈神经网络(Feedforward Neural Network,FNN)的研究从20 世纪60 年代开始,其是目前应用最广泛、发展最迅速的神经网络之一[17]。前馈神经网络采用一种单向多层结构,其中每一层包含若干个神经元[18]。在神经网络中,各神经元可接收前一层神经元的信号,并将输出结果输入到下一层。本研究是将降雨量、高程、坡度、坡向、岩性、剖面曲率、NDVI、到河流距离、土地利用情况、到公路距离共10 个特征量作为输入层,两层隐藏层先计算输入层的特征量,再进行数据分析,将是否发生泥石流作为输出结果,最后转换成外界能够识别的信息。从评价因子作为输入层到是否发生泥石流作为输出层单向传播,多层前馈神经网络结构如图1所示。
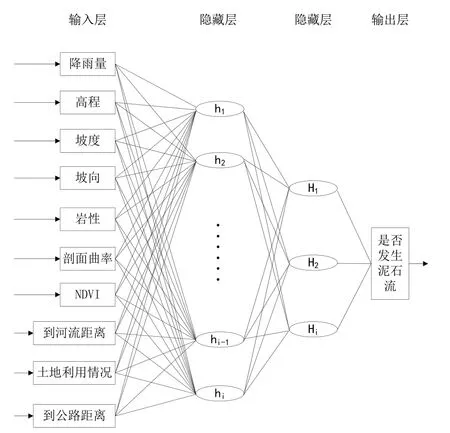
Fig.1 Structure of feedforward neural network图1 多层前馈神经网络结构
在多层前馈神经网络中,每一层相当于一个单层的前馈神经网络,采用生长法更符合认识事物的规律。输入与输出之间的变换关系为:
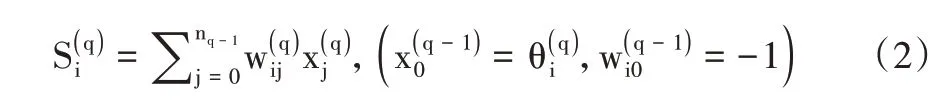
式中,对于第q 层,x 是输入的特征向量,即评价因子;wij是xi到的连接权是按照不同特征的分类结果:
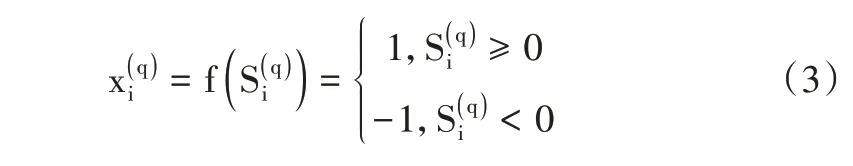
式中,i=1,2,…,nq;j=1,2,…,nq-1;q=1,2,…,Q。对于第q 层,会形成一个nq-1维的超平面。函数表示对于输入x 的分类结果,类别1 表示正例,类别0 表示负例。
1.3 逻辑回归
逻辑回归模型(Logistic Regression,LR)可以明确因变量与一个或多个自变量之间的多元回归关系。将泥石流事件认为是二分类问题,不直接预测标签是0 或1 分别表示泥石流事件的负或正,而是预测输出数值是0 或1 的概率,因此逻辑回归模型根据所选的因变量计算目标事件的发生概率。

式中,P 表示泥石流事件发生的概率,Y 表示泥石流事件,由以下公式进行计算:

式中,θ0为方程的常数值或截距,θ1,θ2,…,θn为最佳参数,X0,X1,…,Xn 为训练数据的向量。本研究的预测函数为:
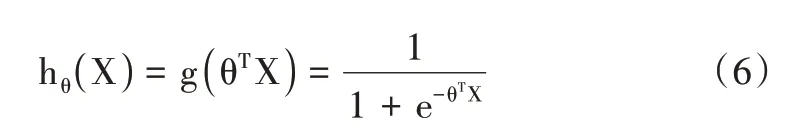
式中,hθ(X)表示对于X 的分类结果,θT表示训练过的一组权值,X 表示需要预测的向量。分类结果为类别1(事件正例)和类别0(事件负例)的概率分别为:
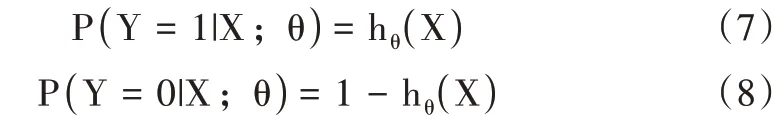
1.4 随机森林
随机森林(Random Forest,RF)是多个决策树的组合,一般决策树的数量越多,泛化结果越好。多个决策树对数据进行分类时,可给出自变量的相对重要性占比,评价自变量对泥石流造成的影响。针对泥石流易发性评价的研究采用一种基于统计学习理论的机器学习算法,通过集成多棵决策树,然后采用投票方式选出分类结果。在数据预处理阶段,对于不平衡的分类数据集,随机森林模型可平衡误差;在评价指标选取阶段,随机森林模型处理多维度和大量数据集的速度快,比决策树的非线性拟合能力强;在易发性评价阶段,随机森林模型可分析出评价指标的重要性,模型的可解释性强。
在本研究中,树的数量(k)和用于分割节点的预测变量数量(m)是形成随机森林所需定义的参数。为保证算法的收敛性和良好的预测结果,采用CART 决策树通过基尼指数进行特征选择,使用基尼指数最小的特征对子节点进行划分。将树的数量k固定为500,选取预测变量m 为3。
假设有M 个特征X1,X2,…,Xm,基尼指数的公式为:
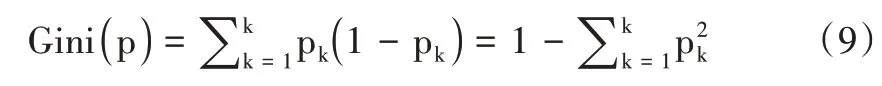
式中,k表示类别数量,pk表示类别k所占比例。
对于处理好的数据集,采用70%的样本构建随机森林模型进行计算,剩余30%的样本对训练集进行验证。从训练数据N 中有放回地随机抽取k个样本,然后通过n 次随机采样得到n 个训练集。对于n 个训练集,分别训练n 个决策树模型。根据训练数据的特征M,随机选取m 个特征作为该节点的分裂特征集。
1.5 FNN-SGD
前馈神经网络结合随机梯度下降(Feedforward Neural Network and Stochastic Gradient Descent,FNN-SGD)模型是一个有单个输出节点的前馈神经网络,当此节点输出越接近1(泥石流发生的正例),越可能符合泥石流发生的条件,越接近0(泥石流发生的负例)则越不可能发生泥石流。本研究通过交叉熵判断两个概率分布之间的距离。设p 为泥石流发生的概率,q为泥石流未发生的概率:
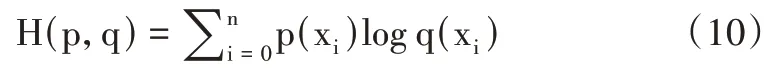
H(p,q)表示泥石流发生的正、负概率分布之间的距离。前馈神经网络的输出不一定是一个概率分布,雷波县泥石流事件总数是有限的,概率分布函数需满足:
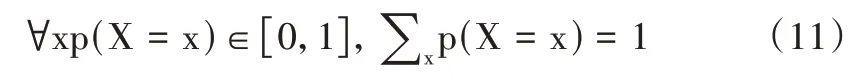
式中,x 表示任意事件,任意事件的发生概率都在[0,1]范围内。通过上述方式将非线性单元进行映射,接下来对样本进行分类,然后识别出相应类别。随机梯度下降可用于求解非线性的最小二乘问题,在前馈神经网络求解过程中,沿梯度下降方向求解极小值,沿梯度上升方向求解极大值。
在机器学习中,为拟合输入样本,建立了目标函数h(θ)。目标函数计算公式如下:

式中,j 表示参数个数,为评估模型拟合质量,用损失函数度量拟合程度。l(θ)损失函数计算公式如下:
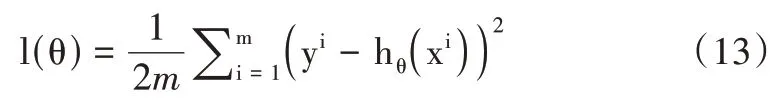
式中,m表示总迭代次数,这里的1/2 是为了方便求导,l(θ)函数的收敛曲线表示模型拟合程度,对应的模型参数为最优参数。θ计算公式如下:

式中,θ表示初始化参数,∇θ表示梯度,η 表示下降系数,即梯度下降的步长。首先计算出损失函数的梯度,然后沿梯度方向使损失值逐渐减小,得出最小的函数损失值,从而得到最优解。
虽然机器学习模型如前馈神经网络、逻辑回归、随机森林等单个的机器学习模型在地质灾害评价体系中应用广泛,但是基于多模型组合的应用较少。本文将FNNSGD 应用于泥石流易发性评价中,并与单模型进行对比分析,以验证该模型应用于泥石流易发性评价中的准确率和稳定性。
1.6 模型评估
采用频率比法(Frequency Ratio,FR)定量分析泥石流发生的影响因素与泥石流发生的关系。本文的FR 是在分析影响因子和泥石流灾害点的基础上,计算影响因子与泥石流灾害点之间的关系。FR 值计算公式如下:

式中,下标i 为所考虑的每个变量的第i 类,Di为控制因子第i 类所包含的泥石流灾害点数,D 为研究区域泥石流灾害点总数,Ui为控制因子第i 类所包含的泥石流灾害单元总数,U 为研究区域单元总数。当FR 大于1 时,表示该评价因子与事件的相关性更强;反之,表示相关性更弱。因此,以频率比为参考,验证模型对评价因子的选择与评价是否合理。
如果没有适当的评估或验证,模型及获得地图的科学价值较低。因此,对模型结果进行评价与验证是泥石流易发性评价不可或缺的任务。近年来,人们采用多种方法来评估模型的不确定性和预测能力,如准确率曲线和预测成功率曲线、列联表、ROC(Receiver Operating Characteristic)曲线和AUC(Area Under Curve)曲线等。AUC 是衡量地质敏感性评价效果的标准指标。本研究采用FR 对评价因子进行分析,通过ROC 曲线和AUC 曲线对FNN、LR、RF、FNN-SGD 建立的模型进行评价与验证(见图2)。
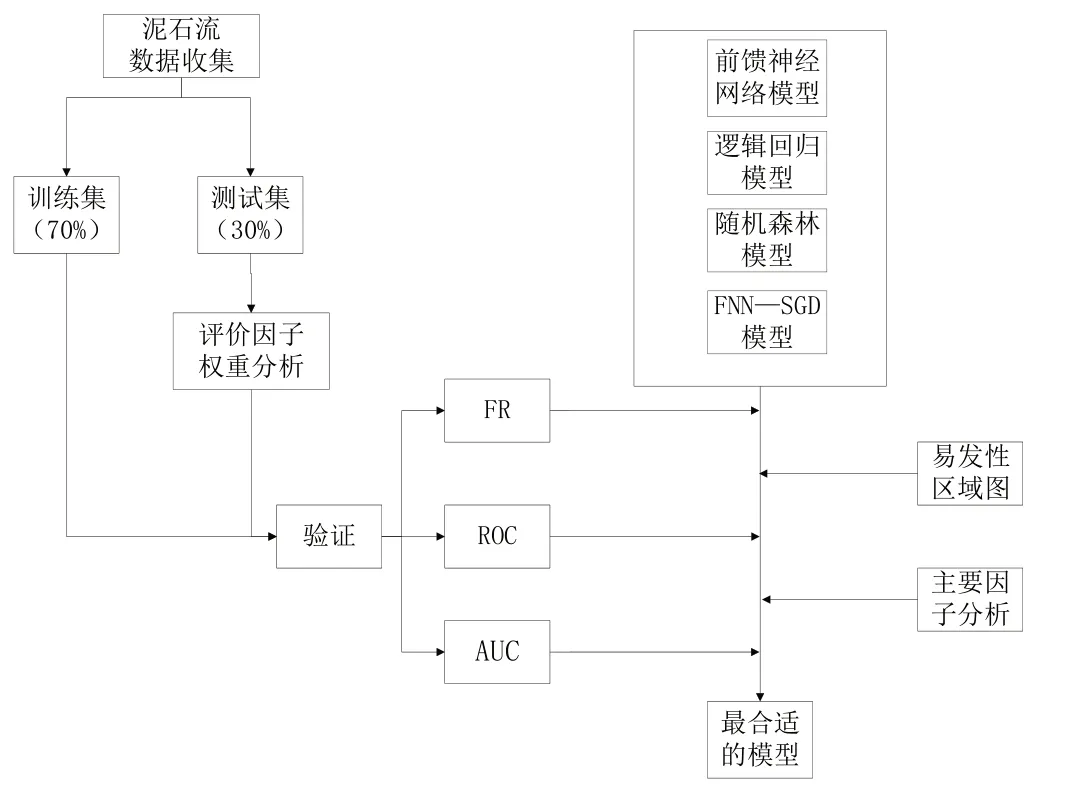
Fig.2 Research flow图2 研究流程
2 实验与分析
2.1 研究区域
研究区域雷波县位于四川省西南边缘、凉山彝族自治州东部、金沙江下游北岸,是历史上泥石流地质灾害较为频繁的地区。其地处北纬27°49'-28°36',东经103°10'-52'之间,面积2 932km2;海拔高度为380~4076m,相对差近3 700m;地质构造复杂,地貌种类多,有大江大湖、高山峡谷、瀑布溶洞、森林草原等;属于亚热带山地立体气候,年均降雨量900ms,属于多雨地区,日照1 250h,气温13℃,常年空气湿度保持在70%左右。
雷波县曾发生过多次泥石流,分别在2002 年8 月9 日(碉楼沟)、2007 年5 月20 日(莫红沟)、2015 年5 月7 日(部分乡镇),给当地造成了巨大的经济损失和人员伤亡。因此,能否快速、有效地根据泥石流发生的历史数据,分析与判断泥石流的易发生区域,对预防泥石流地质灾害、减少当地人民的生命和财产损失具有极其重要的意义。本文针对此问题进行研究,基于GIS 和FNN-SGD 对泥石流易发性区域进行分析,并给出对泥石流易发性区域情况的分析和判断。
雷波县以山地地貌为主,构造活动强烈,地质环境复杂。雷波县现存由国土资源部门负责防治的地质灾害隐患点150 处,其中滑坡66 处,崩塌34 处,泥石流35 处,不稳定斜坡15 处,共威胁4 121 户19 393 人。最后,确定本研究所选的区域位置,如图3 所示(彩图扫OSID 码可见,下同)。
一份完整、准确的泥石流清单地图对于模型训练与验证是必不可少的,因为建模方法是基于过去和现在对未来的假设。在本研究中,数据分别来自中国气象科学数据共享服务网的全国降雨量数据、地理空间数据云的DEM 数字高程数据(GDEMV2 30M 分辨率数字高程数据)、LANDSAT 系列数据(Landsat 8 OLI_TIRS 卫星数字产品)、Globe-Land30 的2020 版30m 全球地表覆盖数据与OpenStreetMap的路网数据。评价因子数据来源如表1所示。
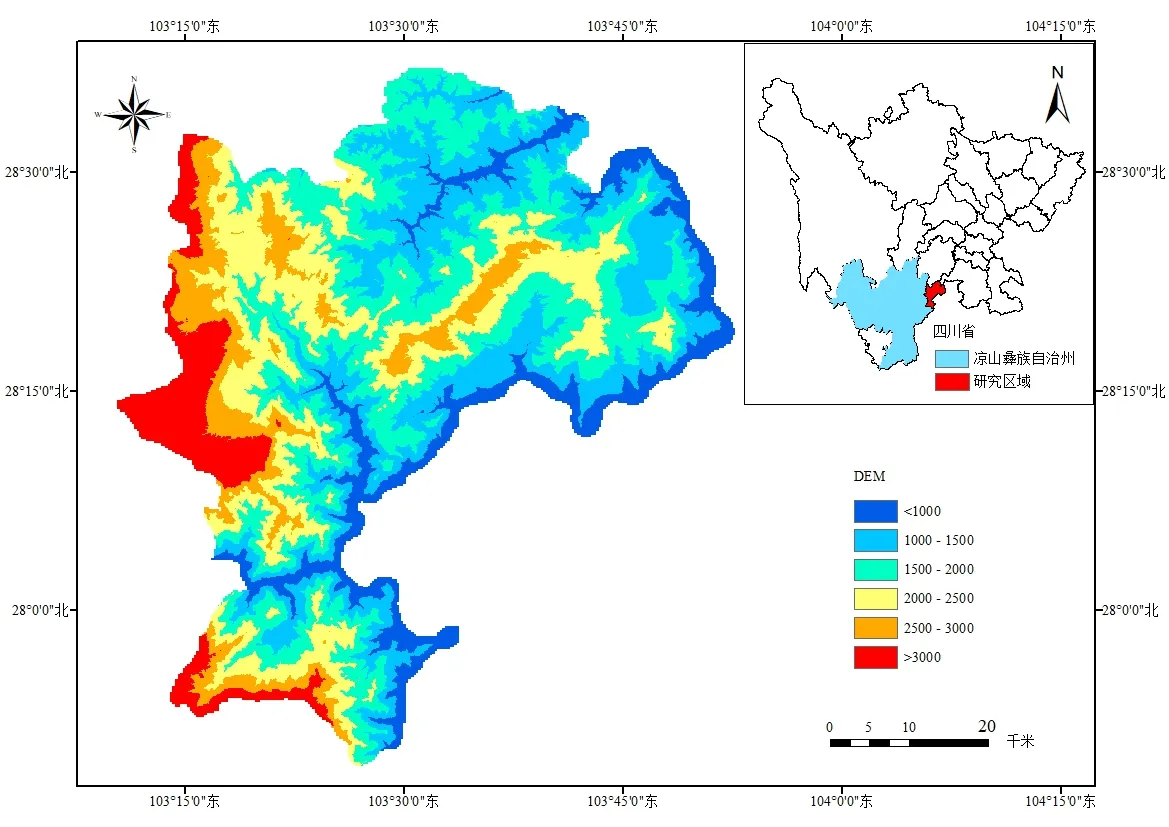
Fig.3 Location of the study area in Sichuan图3 研究区域在中国四川省的位置
选取真正影响模型结果的评价因子作为输入参数是开展泥石流易发性评价的关键。地形、地质和气候因素对泥石流的分布与活动起着至关重要的作用。因此,数据的可用性、可靠性和实用性也被考虑在内。本研究的控制因素包括:①降雨条件;②地形条件(高程、坡度、坡向、等高线、剖面曲率);③地质条件(岩性);④植被条件;⑤河流分布(河网密度、到河流距离);⑥人类活动条件(土地利用情况、路网密度、到公路距离)。
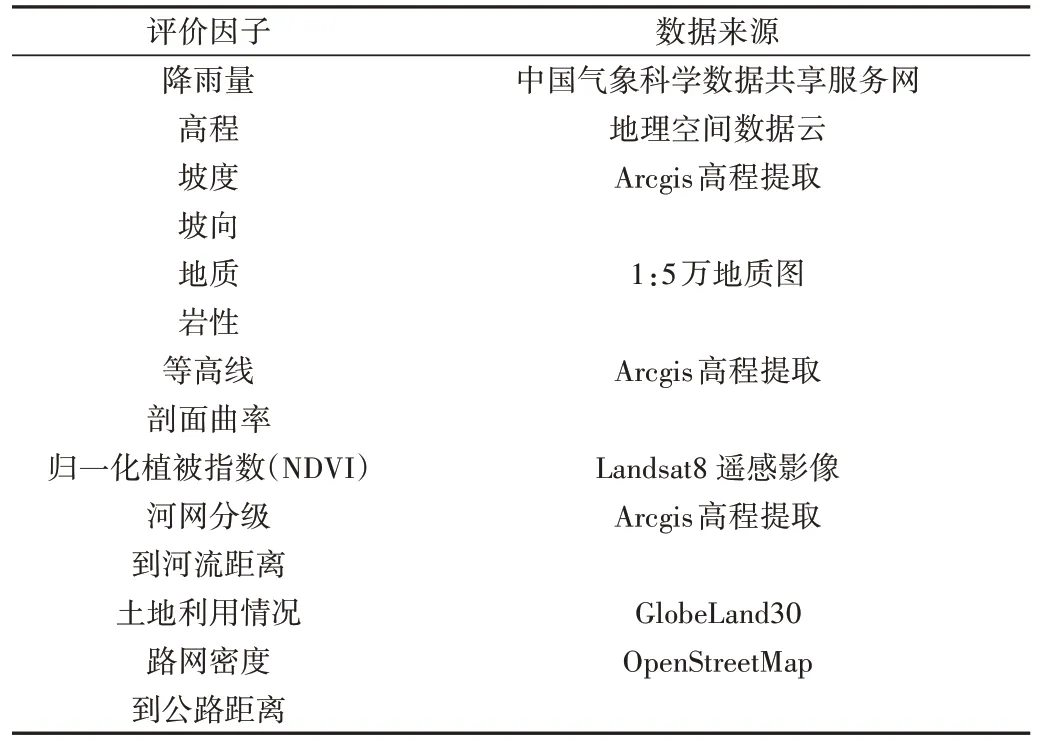
Table1 Data sources of evaluation factors表1 评价因子数据来源
按照雷波县泥石流灾害分布特点将每个评价因子的子类划分为4~9 类,使每个间隔单元尽可能服从正态分布。得到该研究区域的降雨量、高程、坡度、坡向、剖面曲率、等高线、地质、岩性、NDVI、河网分级、到河流距离、土地利用情况、路网密度、到公路距离共14 个评价因子图(见图4)。
2.2 降雨条件
四川省凉山彝族自治州雷波县流域内的季节性降雨引起一段时间内水位上涨,有可能引起泥石流。本研究将雷波县2009-2019 年6-9 月降雨量(累计)用自然间断点法分 为5 类:601~640mm,640~666mm,666~688mm,688~710mm,710~743mm,如图4(a)所示。
降雨是诱发泥石流灾害最重要的外部因素之一,可能会催化边坡失稳。以研究区域雷波县(站点编号:56 485,位置:28.27N、103.58E,海拔:1 255.8m)的逐月、逐日降雨量数据为参考,本研究选取2009-2019 年的月平均降雨量作为灾害爆发的诱导因子,如图5所示。
2.3 地形条件
与地貌相关的因子来自于数字高程模型(Digital Elevation Model,DEM),从地理空间数据云获得30m 分辨率的DEM,可用ArcGIS 中的Data Management Tools、Spatial Analyst Tools、3D Analyst Tools 等工具得出坡度、坡向等相关信息。
海拔是另一个常用的调节因子,其不仅影响降雨和植被状况,而且有助于泥石流的发生。利用ArcGIS 中的工具,首先将DEM 数据进行拼接,然后按照凉山彝族自治州雷波县的行政区提取拼接的DEM 数据,最后通过投影栅格得到高程。本研究区域的高程以500m 为间隔,分为6类:0~400m,400~600m,600~800m,800~1 000m,1 000~1 500m,>1 500m,如图4(b)所示。
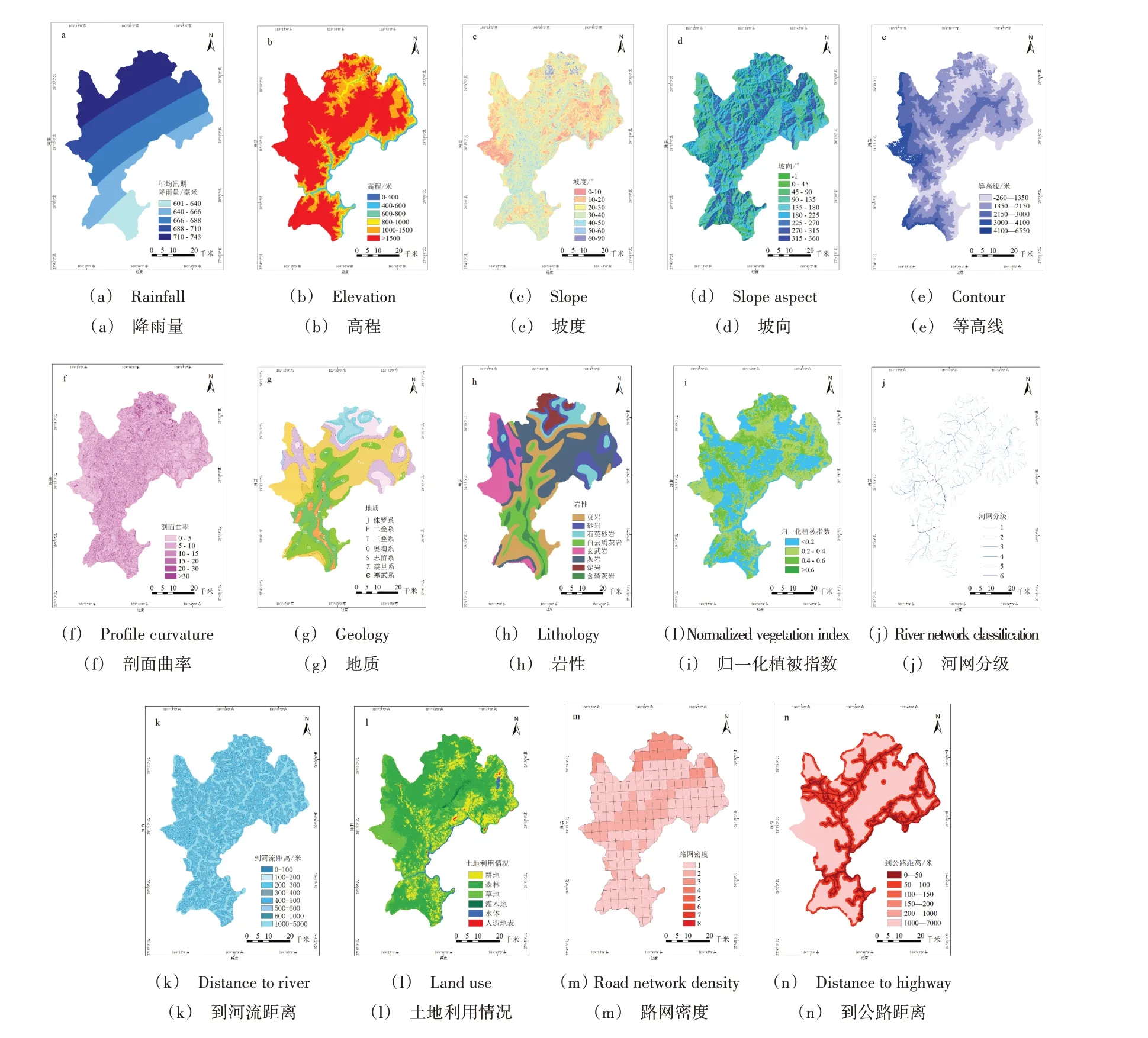
Fig.4 Classification map of evaluation factors in Leibo County图4 雷波县评价因子分类图

Fig.5 Average monthly precipitation(cumulative)in Leibo county from 2009 to 2019图5 2009-2019年雷波县每月降水量(累计)平均值
坡度通常被认为是影响边坡稳定性最重要的因素之一,其不仅能引起边坡重力变形,而且能控制应力分布。利用ArcGIS 中的工具从上述高程数据中获取坡度,本研究区域的坡度图分为7 类:0°~10°,10°~20°,20°~30°,30°~40°,40°~50°,50°~60°,60°~90°。坡度图显示斜角在0°~90°之间,以10°为间隔,如图4(c)所示。
坡向表示单元格所在位置面对的指南针方向,此因素可通过影响太阳辐射暴露,从而调节斜坡上的土地覆盖和水分蒸发情况。利用ArcGIS 中的工具从上述高程数据中得到坡向,本研究区域将坡向数据分为9 个基本方向:-1,0°~45°,45°~90°,90°~135°,135°~180°,180°~225°,225°~270°,270°~315°,315°~360°,以45°为间隔,其中-1 是当单元格没有下坡方向(即平坦区域)时给出的值,如图4(d)所示。
等高线是地形图上高程相等且相邻的各点所连成的闭合曲线。等高线每上升1 000m,温度降低6℃。一般来说,等高线稀疏,坡度平缓;等高线密集,坡度陡峭。本研究用自然间断点的分级方法将等高线划分为5 类:-260~1 350m,1 350~2 150m,2 150~3 000m,3 000~4 100m,4 100~6 550m,如图4(e)所示。
剖面曲率代表地形表面的起伏程度,对泥石流的形成有一定辅助作用。剖面曲率值>0时,地形表面会朝下凹;相反,曲率值<0时地形会朝上凸;曲率值为0 时,地面为水平。本研究将剖面曲率划分为6 类:0~5,5~10,10~15,15~20,20~30,>30,如图4(f)所示。
2.4 地质条件
雷波县位于“川滇南北向构造带”与“盆地新华夏系沉降带”交接地带,县域西部以南北向构造带为主,中部和东部则以北东向构造带为主,东部有少量南北向构造。本研究将地质情况分为7 类,分别为:侏罗系、二叠系、三叠系、奥陶系、志留系、震旦系、寒武系,如图4(g)所示。
泥石流在不同岩性中的发育程度不同,当岩石层遭到破坏,碎屑为泥石流的形成提供了充足的物质。雷波县的岩性可分为8 类,分别为:白云岩、泥岩、砂岩、石英砂、页岩、灰岩、含磷岩、玄武岩。雷波县岩性分布图如图5(h)所示。
2.5 植被条件
从地理空间数据云的Landsat 8 系列获取植被覆盖图像,接下来利用ArcGIS 提取雷波县行政界限的图像,再使用栅格计算器计算归一化植被指数。归一化植被指数(NDVI)计算公式如下:
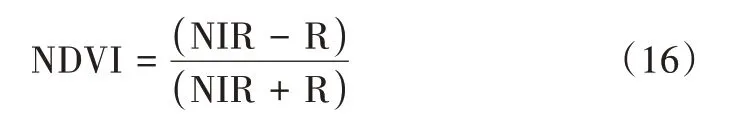
式中,NIR、R 分别为近红外波段和红外波段处的反射率值。由此公式计算出本研究区域的归一化植被指数(NDVI),再将植被覆盖度的范围设置为0~1,共分为4 类:0~0.2、0.2~0.4、0.4~0.6、0.6~1,如图4(i)所示。
2.6 河网条件
河网是滑坡的重要制约因素,其可以通过切割、软化、侵蚀等方式长期改变河岸边坡的地质条件。根据上述获取的DEM 数据,利用ArcGIS 中的工具,首先填充DEM 洼地,然后通过水文分析得出本研究区域的河流流向、流量,可看出水流脉络,接下来利用栅格计算器,使用con 函数得出对河网的分析结果,可看到精细的河网结构,再使用Strahler方法将不同等级的溪流用不同颜色表示出来,最后将栅格河网矢量化。本研究将河流密度划分为6 个等级,如图4(j)所示。
针对到河流距离,本文使用欧氏距离进行分析,将到河流距离根据泥石流灾害分布特点重新划分为8 类:0~100m,100~200m,200~300m,300~400m,400~500m,500~600m,600~1 000m,1 000~5 000m,如图4(k)所示。
2.7 人类活动条件
从变化的地质条件来看,土地利用情况也可被认为是人类活动的指标,如耕地、森林和人造地表等。从Globe-Land30 2020 版16m 分辨率高分一号(GF-1)多光谱影像中获取凉山彝族自治州雷波县的地表覆盖数据,本研究利用ArcGIS 中的工具按照行政边界提取雷波县的地表数据后,从这些特征中提取属性信息,包括耕地、森林、草地、灌木地、水体与人造地表。本研究区域的土地利用情况分为6类,如图4(l)所示。
公路建设在山区发展过程中起着重要作用,但开挖活动往往会影响边坡的稳定性。因此,路网密度可作为另一个外部变量。从OpenStreetMap 中获取凉山彝族自治州雷波县的路网数据,利用ArcGIS 中的工具创建渔网,再将渔网与路网相交,通过栅格计算器计算路网密度,对道路(铁路、公路、水路)长度总和与每个单元格面积之比进行计算,生成地形图(单位:km/km2)。本研究将路网密度分为8类,如图4(m)所示。
一般来说,泥石流灾害点与主干道路越接近,泥石流发生后路人面临的危险性越大。考虑到划分缓冲距离的合理性,本研究将到公路距离分为6 类:0~50m,50~100m,100~150m,150~200m,200~1 000m,1 000~7 000m,如图4(n)所示。
3 实验结果及分析
3.1 评价因子分析
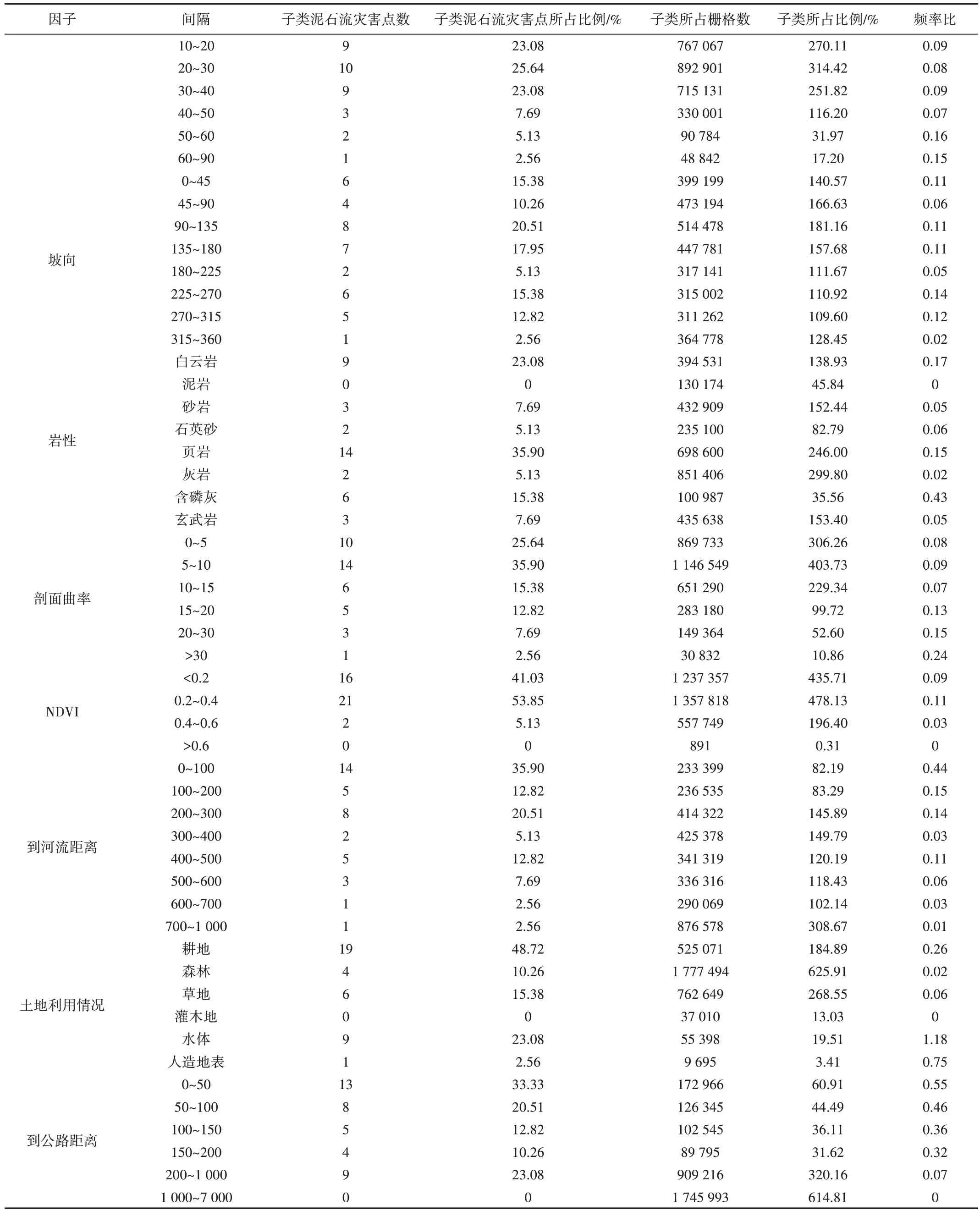
与频率比法(Frequency Ratio,FR)相比,4 种模型对评价因子的分析存在显著差异。基于频率比法,可更详细地探索各评价因子与泥石流之间的潜在关系。雷波县泥石流易发性频率比值如表2所示。
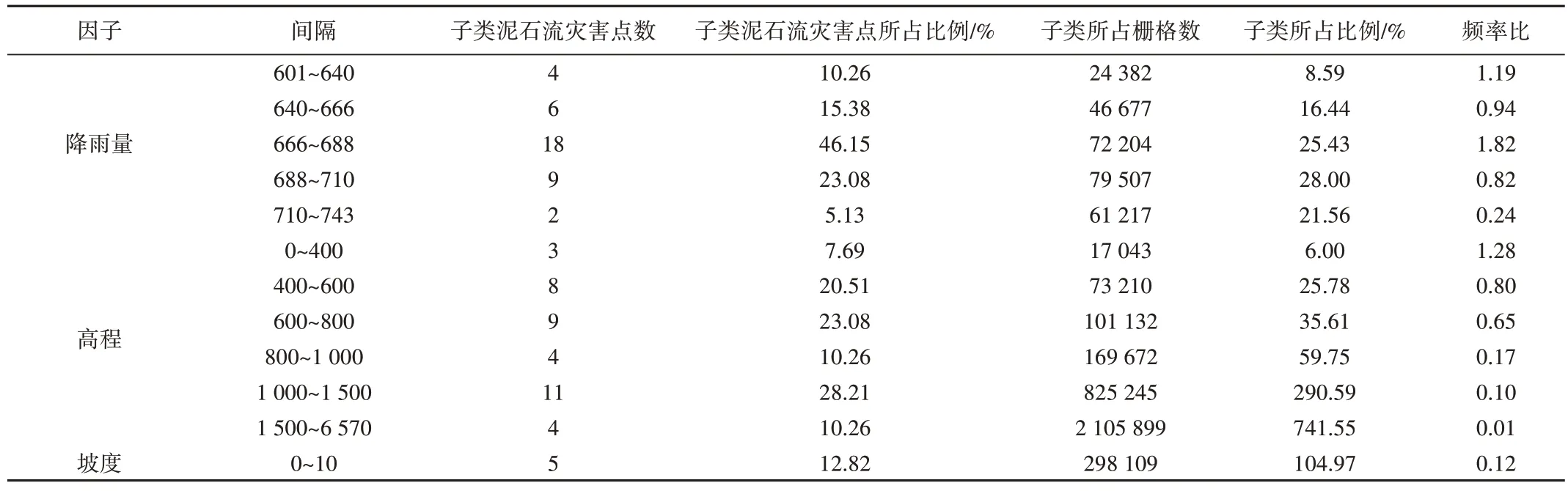
Table 2 Frequency vatio of debris flow susceptibility表2 泥石流易发性频率比值
续表
由表2 可知,降雨量、高程和土地利用情况对泥石流灾害的敏感度更高。以降雨量为例,降雨量的子类666~688mm 相较于降雨量的其他子类对泥石流灾害更敏感。通过上述例子依次判断剩余评价因子的子类敏感度,得到高程的子类0~400m、坡度的子类50°~60°、坡向的子类225°~270°、剖面曲率的子类>30、岩性的子类含磷灰、归一化植被指数的子类0.2~0.4、到河流距离的子类0~100m、土地利用情况的子类水体、到公路距离的子类0~50m 对泥石流灾害更敏感。
3.2 模型结果
本研究将四川省凉山彝族自治州雷波县的泥石流易发性分为5 类:极低易发性区域、低易发性区域、中易发性区域、高易发性区域、极高易发性区域,得到雷波县的泥石流易发性分布图,如图6所示。

Fig.6 Distribution map of debris flow susceptibility in Leibo county图6 雷波县泥石流易发性分布图
3.2.1 前馈神经网络
前馈神经网络模型将10 个评价因子作为输入进行学习与训练得出训练结果,再利用ArcGIS 软件得到泥石流地质灾害易发性分布图(见图6(a))。根据自然间断点方法将易发性评价结果分为:极高、高、中、低、极低,面积占比分别为:9.8%、15.42%、21.79%、26.49%、26.5%,各分区所对应的灾害点数量分别为:18、12、8、1、0,位于高易发区域及以上的灾害点数量占总灾害点数量的76.92%。
前馈神经网络得到评价因子相对重要性占比如图7所示,分析结果表明:降雨量、到公路距离、高程是影响泥石流灾害形成最重要的3 个因子,占全部因子重要性的63%;岩性、土地利用情况、坡度、剖面曲率也对泥石流灾害的形成影响较大;坡向、NDVI、到河流距离对泥石流灾害的形成影响较小,重要性仅占9%。
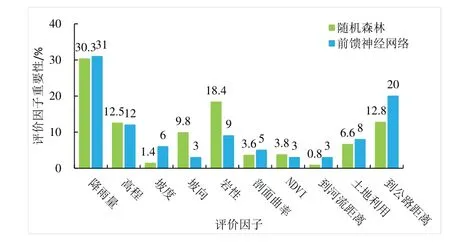
Fig.7 Relative importance ratio of evaluation factors图7 评价因子相对重要性占比
3.2.2 逻辑回归
逻辑回归模型采用主效应方法对10 个评价因子进行学习与训练,再利用ArcGIS 软件得到泥石流地质灾害易发性分布图(见图6(b))。根据自然间断点方法将易发性评价结果分为:极高、高、中、低、极低,面积占比分别为:5.8%、14.23%、17.73%、23.99%、38.25%,各分区所对应的灾害点数量分别为:10、14、4、8、3,位于高易发区域及以上的灾害点数量占总灾害点数量的61.54%。
逻辑回归模型因其具有拟合模型的简单性和拟合系数的可解释性而被广泛应用于各个领域,并被多次应用于泥石流易发性评价。根据模型中系数的正负符号,可直接判断各自变量与因变量之间的关系,广义线性模型系数也可用来评估评价因子的相对重要性。然而,逻辑回归模型一般采用逐步回归的方法对变量进行过滤,只留下少数统计上显著的变量,这会导致对默认值有显著影响的部分变量信息丢失。泥石流易发性评价过程涉及多个评价因子,逻辑回归模型无法自主克服自变量之间的多重共线性对结果的影响。因此,该模型难以很好地分析泥石流的诱发因子,有时甚至会得出与以往经验相反的结论。
3.2.3 随机森林
随机森林模型通过对数据的学习与训练,得出了10个评价因子的重要性占比,再利用ArcGIS 软件得到泥石流地质灾害易发性分布图(见图6(c))。根据自然间断点方法将易发性评价结果分为:极高、高、中、低、极低,面积占比分别为:6.91%、11.14%、17.43%、24.23%、40.3%,各分区所对应的灾害点数量分别为:14、12、10、3、0,位于高易发区域及以上的灾害点数量占总灾害点数量的66.67%。
随机森林得到评价因子相对重要性占比如图7 所示,分析结果表明:降雨量、岩性、到公路距离、高程是影响泥石流灾害形成最重要的4 个因子,占全部因子重要性的73.94%;土地利用情况、坡向也对泥石流灾害的形成影响较大;坡度、剖面曲率、NDVI、到河流距离对泥石流灾害的形成影响较小,重要性仅占9.61%。
随机森林模型具有处理高维、小样本和不平衡数据的能力,对模型依赖性没有预先的假设,并且可以处理分类数据和连续数据。随机森林模型的应用较好地保留了原始的控制信息,这些评价因子有助于更好地了解地质灾害。所得结果的值越大,对泥石流发生的贡献越大。然而,其结果并不像逻辑回归模型那样积极或消极。本文仅对每个评价因子的重要性进行排序,即每个因子默认都会促进泥石流的发生,但其效果是不同的。
3.2.4 FNN-SGD
FNN-SGD 模型首先通过前馈神经网络模型训练样本,然后计算出损失函数的最小值,再通过随机梯度下降的方向让损失值逐步减小,从而得到最优解。利用ArcGIS软件得到泥石流地质灾害易发性分布图(见图6(d)),根据自然间断点方法将易发性评价结果分为:极高、高、中、低、极低,面积占比分别为:9.19%、18.16%、25.18%、29.49%、17.98%,各分区所对应的灾害点数量分别为:23、9、6、1、0,位于高易发区域及以上的灾害点数量占总灾害点数量的 82.05 %。
FNN-SGD 模型利用最初的数据集进行训练,作为FNN 模型的第一层学习器,将FNN 模型输出的结果作为特征带入SGD 模型中进行二次学习,最后输出结果。通过对多个模型的输出结果进行泛化,可提升泥石流易发性预测精度。
在FNN-SGD 模型构建的易发性分区中,高和极高易发性区域主要分布于雷波县东南部,中易发性区域分布于雷波县西南部,低和极低易发性区域分布于雷波县西北部和东北部。
本文将四川省凉山彝族自治州雷波县的泥石流易发性分为5 类:极高、高、中、低、极低,通过4 个模型预测5 类易发性区域面积占雷波县总面积的比值,以及各区域泥石流灾害点分布情况,分别如表3、表4所示。
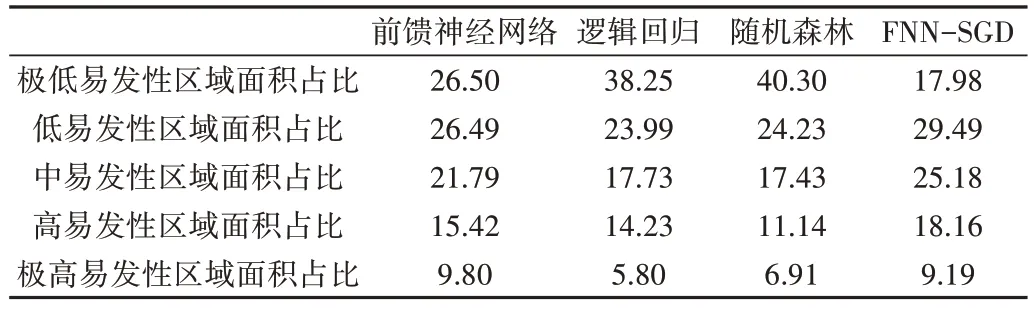
Table 3 Partition area proportion of the four models表3 4种模型所对应的分区面积占比情况 %
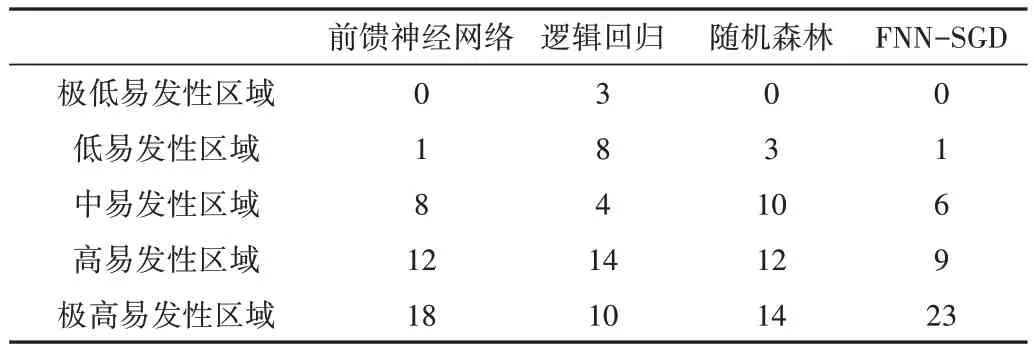
Table 4 Distribution of debris flow disaster points corresponding to the four models表4 4种模型所对应的分区泥石流灾害点分布情况
3.3 模型结果验证
验证是雷波县泥石流易发性评价中不可或缺的一部分,某种程度上决定了模型制图质量。为更好地评估模型精度,使用ROC 曲线进行验证。训练集4 种模型的准确率ROC 曲线如图8 所示,验证集4 种模型的预测成功率ROC曲线如图9所示。
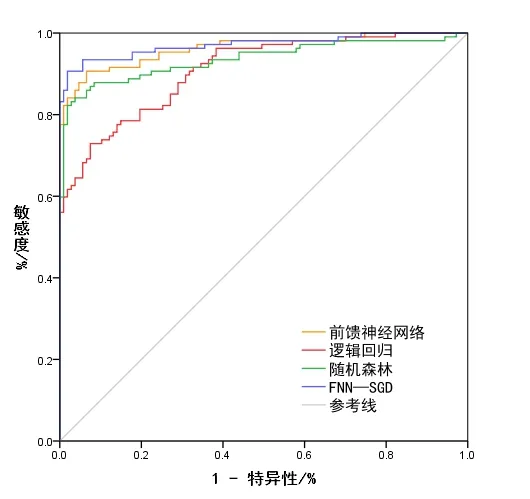
Fig.8 Accuracy ROC curve图8 准确率ROC曲线
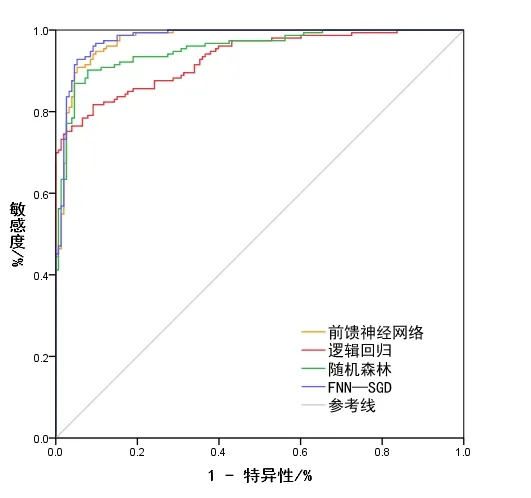
Fig.9 ROC curve for predicting success rate图9 预测成功率ROC曲线
4 种模型的准确率及预测成功率如表5 所示。成功率与预测率之间的差值可体现模型的稳定性,按照差值由大到小排序,分别为逻辑回归(2.2%)、随机森林(1.8%)、前馈神经网络(1.3%)、FNN-SGD(0.9%)。由此可知,FNN-SGD模型稳定性强、可靠,具有良好的泛化能力。
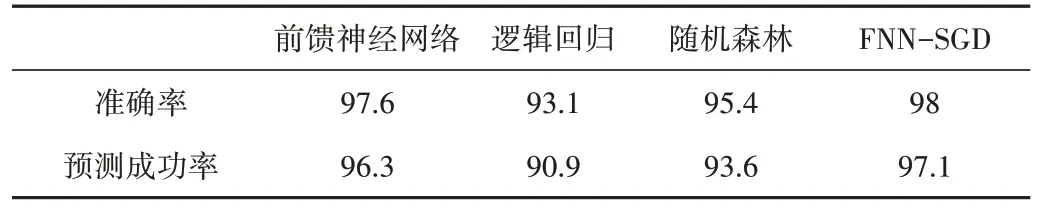
Table 5 Accuracy rate and prediction success rate of four models表5 4种模型准确率及预测成功率 %
因此,通过综合考虑ROC 曲线验证及泥石流在实际情况中易发性的对比分析,FNN-SGD 模型的准确率和预测成功率相比其他3 个单模型的效果更好,更适用于雷波县泥石流易发性评价。根据FNN-SGD 模型的雷波县泥石流易发性评价结果和区域重要程度两方面进行分析,得出雷波县的泥石流易发性区域。
4 结语
本文通过ROC 曲线对4 种模型的性能进行验证,实验结果表明,FNN-SGD 模型与前馈神经网络、逻辑回归和随机森林相比,FNN-SGD 模型的准确率更高、稳定性更强。根据FNN-SGD 模型结果绘制雷波县泥石流易发性分布图,高和极高易发性区域主要分布于雷波县东南部,中易发性区域主要分布于雷波县东北部,低和极低易发性区域主要分布于雷波县西北部。雷波县泥石流易发性区域的具体分布情况为:高和极高易发性区域主要分布于雷波县的巴姑乡、宝山镇、渡口镇、卡哈洛乡、马颈子镇、莫红乡、千万贯乡、上田坝镇、永盛镇;中易发性区域主要分布于雷波县的桂花乡、黄琅镇、箐口乡、山棱岗乡、瓦岗镇、汶水镇;低和极低易发性区域主要分布于雷波县的柑子乡、谷堆乡、金沙镇、锦城镇、拉咪乡、西宁镇。
因此,相比于与其他3 种模型,FNN-SGD 模型得到的泥石流易发性分布图具有更强的适应性与合理性。未来泥石流易发性评价研究还有待进一步深入,本研究的结论对于降低雷波县区域性的泥石流风险及制定土地利用规划具有一定借鉴意义。
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
今日农业(2021年10期)2021-11-27
今日农业(2021年1期)2021-03-19
农家科技下旬刊(2018年1期)2018-05-05
艺术评鉴(2017年20期)2017-11-30
魅力中国(2017年32期)2017-08-17
海峡姐妹(2017年6期)2017-06-24
环球时报(2017-06-14)2017-06-14
绿色科技(2009年6期)2009-09-29
