
基于fasttext 实现船舶工况点分类系统研究
2023-01-24 12:51陈浩天刘晓东
电子设计工程 2023年2期
陈浩天,刘晓东,2
(1.武汉邮电科学研究院,湖北武汉 430070;2.武汉虹旭信息技术有限责任公司,湖北 武汉 430070)
截止到2021 年上半年,船舶领域的语料库基本缺失,无法在互联网、图书馆等公共资源区域有效获得船舶领域的相关语料,也就无法实现船舶工况点自动匹配。
现有的文本自动匹配方法研究如传统的知识工程分类[4],对时间维度消耗大,不满足最后的自动化处理需求;基于深度学习进行分类处理[8]的算法在处理时对语料要求很大,模型的效果很大程度取决于语料的好坏,人们常用的Logistic算法以及SVM算法[11]都是如此。随着词向量的提出,深度学习算法逐渐进入人们的视野,CBOW 模型[12]以及Skip-Gram 模型都能很好地对分布式词向量模型进行分类。
为了验证改进C-fattext 算法在实验中可以提升效率,文中针对改进C-fasttext 算法和在分类中常用的朴素贝叶斯算法、支持向量机算法和原始fasttext算法进行对比,力求达到实验预期指标。
1 分类算法相关原理
1.1 传统分类步骤
传统分类步骤大致可以分为四步,即文本获取、文本预处理、特征词提取、分类器选择。
1.1.1 文本获取
在船舶领域,目前,互联网、图书馆等场所无法获取有效的船舶资源,这为获取语料造成了极大的影响,文中通过网络爬虫获取大量船舶网站的新闻数据以及试验数据,加上公司内部船舶资料、船长提供的手册资料等,将这些资料结合成为一个庞大的语料库,进而转换为纯文本语料库。
1.1.2 文本预处理
在文本获取中得到大量文本数据后,不能直接使用原始数据进行后续实验,原始文本数据中包含了大量垃圾信息与噪声,这些垃圾信息与噪声对后续需要进行的分类工作没有任何帮助,甚至在一定程度会起到相反的作用,对分类的速度、准确率造成不同程度的干扰,导致试验分类结果不佳。因此,使用分词、去停用词、同义词转换等方法处理文本信息。
1.2 特征词提取
一个工况点的主要内容可以由其特征词汇决定,通过这些特征词汇完成工况点分类。目前特征提取算法已经呈现多元化发展,例如TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文本频率指数)算法、TextRank 算法(基于图的用于关键词抽取和文档摘要的排序算法)、互信息算法、信息熵算法等,这些算法都能满足特征提取需求。文中选用TF-IDF 算法实现工况点分类任务的特征词提取。
1.3 分类器选择
文中使用fasttext 分类器,fasttext 分类器采用分层softmax 提高训练速度,在大量文本中取得更好的评分效果,其因速度快、准确率高而被广泛应用在文本分类领域。
2 分类算法改进
2.1 TF-IDF算法
词频TF 表示文本某个词在前文本中出现的次数或者频率,计算公式为:
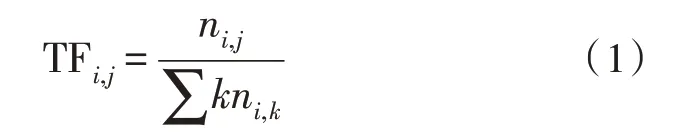
逆文档频率IDF 代表一个词在词库中出现的词条的频率:
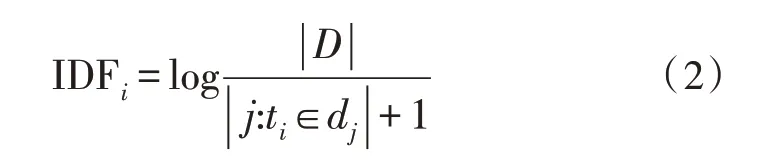
TF-IDF 算法的核心思路为词频和逆文档频率的乘积:
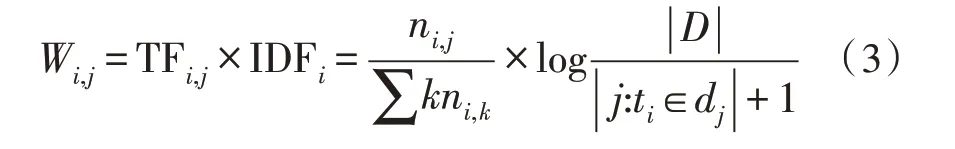
2.2 TF-IDF算法改进
为了避免因为使用IDF 逆文档频率直接表示文本外部特征带来的负面影响,可以在分词之后,将处于设备部分,并且出现可以直接代表分类结果的词汇,直接匹配上分类结果。例如,在分类“主机”类别时,形如“No.1 主机转速”在分词之后会出现“主机”词汇,可以直接将此工况点分类至“主机”类别中;在后续通过模型训练出类别后,可以使用此规则得到的结果直接覆盖,提升因为模型误差、参数设计不合理等因素造成的分类失误。
在传统的TF-IDF 算法中,增加一个能够表示船舶的特定工况点库,如果待对比工况点数据出现在此特定工况点库中,则记录系数ci,表示工况点中是否出现了符合特定工况的情况。如果出现在特定工况点库中,则按照工况点中记录的ci系数同式(3)中的Wi,j相乘,同时需要考虑到特征词在同一类别,但不同文章之间的分布情况。在传统的TFIDF 算法中,如果一个词汇在某类别的文章中和另外一个词汇出现在此类别的文章中的次数是相同的,则这两个词汇会获得相同的TF-IDF 系数。然而,可能前面的词汇在同种文章中的分布是均匀的,后者却在小部分文章中大量出现,那么前者词汇的系数应当大于后者的系数。为了解决上述可能出现的情形,同步对对式(3)进行更新,新增类内系数aci,计算如下:
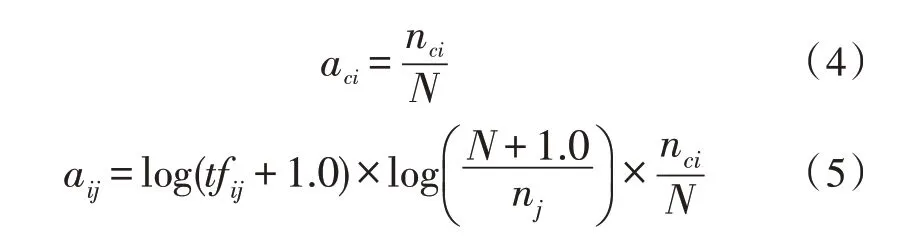
式中,tfij表示词j在文档i中的频率,N表示文档总数目,nj表示词j出现的总文档数,nci表示词j在类别c文档中出现的文档数目。通过对输入文本的每个词都进行更改后的TF-IDF 算法计算,将其命名为C-TF-IDF 算法。
另外,单纯添加一个系数仍然无法避免低频词条删除问题,因为在压缩文档时,低频向量词条可能会被删除,这样就可能会忽略掉出现频率不高,但是代表性、专业性很强的词汇,使得改进的C-TF-IDF算法性能在某些情况下大打折扣。
为使得对权重的处理更加合理,使用归一化处理,以达到简化计算的目的。使用归一化作用于每个词向量,标准化高频词汇和低频词汇权重,避免出现某词汇出现次数过多或者过少而产生分布失衡的现象,同时也避免出现词频相差过大而影响分类效果。如此更改对权重的处理将更加有意义,再结合fasttext 算法,将C-fasttext 算法进行更新。
C-fasttext 算法的计算步骤如下:
1)规则索引;
2)语料库的收集以及文本预处理;
3)在原始词序列中增加N-gram 特征;
4)使用创新后的C-TF-IDF 算法计算单个工况点结果aij;
5)根据得到的结果aij对目标工况点权重进行更新迭代计算;
6)进行模型运算。
2.3 fasttext算法
fasttext 算法原理从word2vec 顺延而来,它们都拥有CBOW 模型类似的结构,即分为三层:①输入层,主要为文本词向量的输入、特征的输入等;②隐藏层,进行相关参数计算、迭代;③输出层,与word2cev不同的是,fasttext 算法是通过上下文预测类别,其输出的是最终判断的类别可能性。
2.4 fasttext算法改进
fasttext 算法可以理解为带监督的分类模型,输入的数据可以认为是带有参数系数的词向量信息,在输入之前加入一层凭借层,此层的主要作用是将得到的信息整合,删除无用信息,保证数据的完整性与可靠程度。凭借层网络拓扑图如图1 所示。
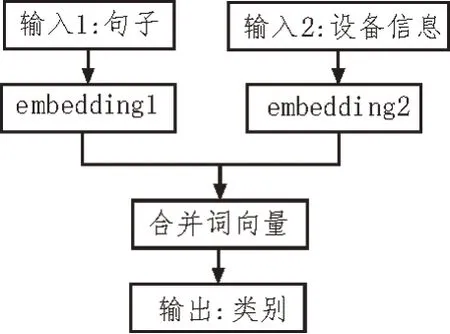
图1 凭借层网络拓扑图
由于文中的应用领域为船舶领域,结合前文对于算法的改进,最终选择的损失函数是交叉熵损失函数:

一个批次中的损失函数计算公式如式(7)所示:
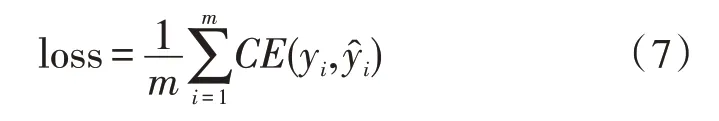
式中,yi表示实际类别的标记,表示模型预测的类别标记。
可以得出改进后fasttext 算法实现流程如图2所示。
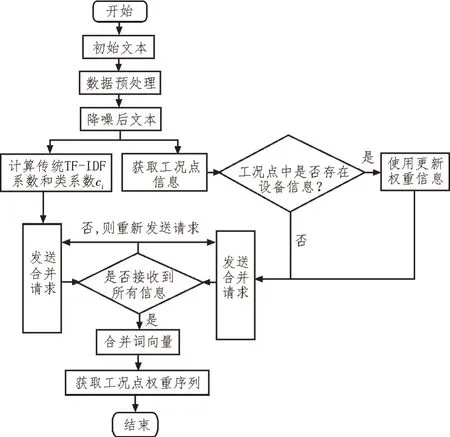
图2 改进后fasttext算法实现流程图
3 实验及分析
3.1 实验环境
文中试验环境为本地Windows10 家庭版操作系统,Intel Core i5 处理器,使用的语言为Python3.7,实验采用的评判指标为文本分类准确率、召回率、F值,用于对比显示结果。
3.2 实验数据
实验使用数据集为船舶领域数据库中已经拥有的2 123 条工况点数据,验证数据集为新船中选取的1 000 条工况点,训练集中数据格式如图3 所示。

图3 训练集数据格式
3.3 评价方法
在自然语言领域,通常使用三种评估指标,分别为准确率、召回率和F 值。
准确率:准确率表示模型预测为正样本且实际为正样本的比例,计算公式为:

召回率:召回率表示模型准确预测为正样本的数量占所有正样本数量的比例,计算公式为:

F 值:可以理解为P和R的加权调和平均,计算公式为:
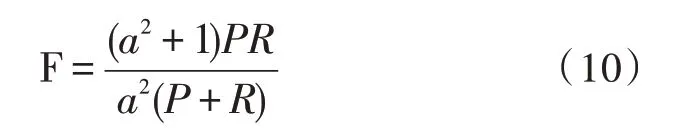
3.4 实验结果分析
为验证改进的C-fasttext算法的分类能力,使用实验数据进行测试,同时选择朴素贝叶斯算法、SVM 算法、传统fasttext算法同改进的C-fasttext算法进行对比。
为了数据能够更加直观显示,使用折线图表示不同类别工况点数目,如图4 所示。
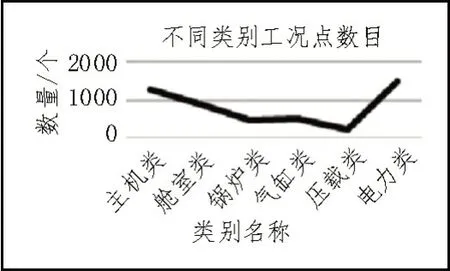
图4 不同类别工况点数目
图4 表明,在船舶领域中,六大主要类别出现概率差距不大,没有出现某种类别过多或者过少的情况,其中压载类工况点数目少是因为压载类一般出现在其他类别的辅助类中,原始数据中单独出现压载类的情况并不多。在数据集中,每个类别占有总数据的比例为:主机类26.45%,舱室类18.14%,锅炉类9.85%,气缸类10.40%,压载类5.03%,电力类30.12%。在分类判决中,实际还有一个其他类,其他类拥有出现极少或者特殊情况的工况点,在分类阶段暂时剔除,以免对分类结果产生影响。
图5 给出了改进C-fasttext 算法在船舶领域六大类中的分类结果。
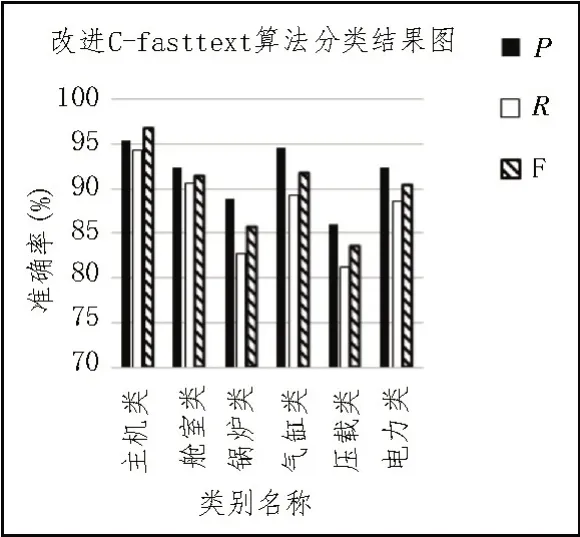
图5 改进C-fasttext算法分类结果图
四种分类方法准确率结果如图6 所示。
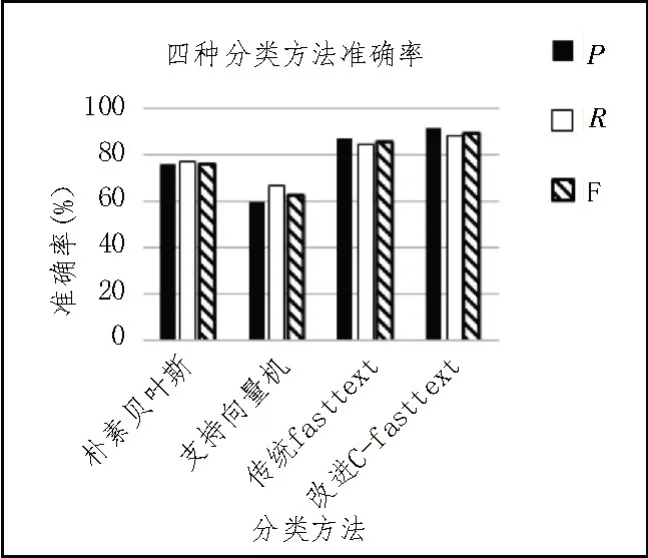
图6 四种分类方法准确率结果图
由图6 可知,文中提出的改进C-fasttext 算法准确率最高,高达91.59%;传统的fasttext 分类算法的平均准确率也处于领先地位,为88.27%;支持向量机算法处在较低水平,准确率只有59.98%;朴素贝叶斯方法在准确率上达到76.19%。可以看出,对比朴素贝叶斯算法、支持向量机算法和原始fasttext 算法,改进C-fasttext 算法在二分类任务中获得了较好的评分,说明改进是成功的。
在错误控制方面,随机抽取100 条数据,查看分类结果,发现误报率为3%,语料覆盖率为97%,满足最初控制误报率不超过5%、语料库覆盖率超过95%的需求,得出基于fasttext 的船舶工况点分类研究算法满足项目要求结论。
4 结论
为解决船舶领域工况点对比分类问题,提出基于fasttext 的改进C-fasttext 算法,对特征提取方法中的TF-IDF 算法做出改进,使其在权重设置上更加符合工况点分类要求;对fasttext 算法在输入层做出创新,指出其在应用于工况点分类中的不足之处,提出的C-fasttext 算法在原有基础之上进行了改进,从而节省大量人力资源,匹配准确率为91.59%,语料覆盖率为97%,提出的C-fasttext 算法能够完善对工况点的分类效果,满足需求。
猜你喜欢
客联(2022年3期)2022-05-31
通信技术(2021年12期)2022-01-25
中国新闻周刊(2021年26期)2021-07-27
民族古籍研究(2018年1期)2018-05-21
信息安全研究(2016年4期)2016-12-01
西夏学(2016年2期)2016-10-26
浙江大学学报(工学版)(2015年1期)2015-03-01
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
