
基于图像增强与深度学习的安全带目标检测
2023-02-21 12:53李雷孝
计算机工程与设计 2023年2期
李雷孝,孟 闯+,林 浩,高 静,王 慧
(1.内蒙古工业大学 数据科学与应用学院,内蒙古 呼和浩特 010080;2.内蒙古自治区科学技术厅内蒙古自治区基于大数据的软件服务工程技术研究中心,内蒙古 呼和浩特 010080; 3.天津理工大学 计算机科学与工程学院,天津 300384;4.内蒙古农业大学计算机与信息工程学院,内蒙古 呼和浩特 010011)
0 引 言
目前机动车辆驾驶员检测方法主要分为传感器检测与计算机视觉检测两种方法。基于传感器的安全带检测方法[1,2]是在安全带卡座或者驾驶员座位中安装压力传感器,通过判别压力传感器数值大小判断驾驶员是否佩戴安全带。此方法存在弊端,当驾驶员事先将安全带卡扣扣好再坐到座椅上时,会错误判别驾驶员已佩戴安全带。对于未安装传感器的车辆不能进行安全带检测,不具有普遍适用性。基于计算机视觉的检测方法可划分为传统图像处理检测方法与基于机器学习、深度学习[3,4]的检测方法。传统的图像处理方法一般通过灰度积分投影法、霍夫直线检测法等,利用安全带长直线特点或者安全带反光等特性检测驾驶员是否佩戴安全带。近些年随着机器学习、深度学习的兴起与快速发展,基于机器学习、深度学习的驾驶员安全带检测方法已成为主流。如何提高检测准确率、适应复杂的使用场景已成为如今研究的重点。
1 相关研究
传统安全带检测方法中[5,6],使用灰度积分投影法进行安全带检测。利用安全带反光的特性,通过对二值化后的图像进行灰度积分投影得到安全带特征点的位置坐标,判别驾驶员是否佩戴安全带。这种方法受光照强度影响较大,驾驶员衣领与头发也会对实验结果造成影响,鲁棒性不高。有学者利用安全带边缘具有两条长直线的特点,利用霍夫直线检测与边缘检测相结合的方法识别安全带区域。这种方法易受图像清晰度等影响,当驾驶员衣服图案中有类似长直线时,会对实验结果造成干扰,实际检测中准确率不高。
基于机器学习、深度学习的目标检测领域中,田坤等[7]设计了一种基于YOLO(you only look once)网络和极限学习机(extreme learning machines,ELM)相结合的安全带检测模型。通过ELM训练了一个安全带二元分类器,但要求分类的图像需要具有明显的分类特征,在对模糊的驾驶员图片检测中并不能得到较高的准确率。吴天舒等[8]提出了一种YOLO网络与语义分割网络相结合的安全带检测方法。首先通过YOLO网络快速定位主驾驶区域,后利用语义分割网络得到安全带的连通区域,判断连通域面积大小从而判别驾驶员是否佩戴安全带。这种方法驾驶员衣服图案会对实验结果造成干扰。霍星等[9]提出了一种自定义的深度卷积神经网络检测安全带的方法。首先通过SVM(support vector machine)分类器确定车牌位置进而确定车窗位置,再通过Alexnet深度神经网络训练了一个二元分类器完成对安全带的检测工作。这种方法步骤繁琐,检测效率较低。詹益俊等[10]提出了一种基于卷积神经网络的安全带检测方法。通过改进网络架构,减轻级联网络框架,减小网络计算量,满足实时性检测驾驶员安全带的需求。基于机器学习、深度学习的检测方法相比于传统的图像处理检测方法,容错率更高,准确率也相应提升。
针对目前车窗检测步骤繁琐、驾驶员区域不能精细化截取、安全带检测易受光照、图片清晰度等方面影响的缺点,本文提出了一种基于YOLO v3[11,12]和Faster R-CNN[13]的安全带单类别目标检测模型。首先基于YOLO v3网络设计了车窗检测模型与车窗-驾驶员检测模型,可准确定位驾驶员区域。再通过图像增强操作,有效解决了图片清晰度或者光照强度对安全带检测的影响。最后通过基于Faster R-CNN的安全带单类别目标检测模型进行安全带检测。在实际测试中,本模型安全带检测准确率可达到96.0%,同时检测速率较高。
2 模型设计
基于YOLO v3和Faster R-CNN的安全带单类别目标检测模型主要分为驾驶员区域检测模型与安全带检测模型两部分。模型总体设计流程如图1所示。
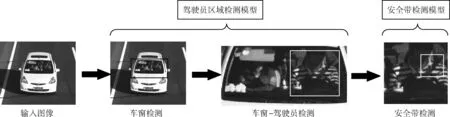
图1 模型总体设计流程
对于驾驶员区域检测模型,将其细分为车窗检测模型与车窗-驾驶员检测模型。为了简化驾驶员的定位过程,模型不定位车辆,而是直接定位车窗。因车辆前挡风玻璃类似于长方形,特征较为明显,直接训练车窗检测模型便可以得到较高的准确率。
在对驾驶员的检测及定位过程中,首先截取上一步通过车窗检测模型检测出的车窗图片作为训练集图片。在车窗图片中标注驾驶员区域,训练车窗-驾驶员检测模型。相比于通过几何关系裁取车窗图片截取驾驶员区域的方法,本方法可减少外界多余的干扰信息,例如可减少车窗边框等冗余信息对后续安全带检测所造成的影响,容错率更高,适应性更强。
最后通过车窗-驾驶员检测模型检测到驾驶员图片,并送入到安全带检测模型中检测安全带,完成对驾驶员安全带的检测工作。
2.1 驾驶员区域检测模型
本文基于YOLO v3网络实现了对驾驶员区域的检测与精细化定位过程。模型采用单步回归的方式进行目标检测,训练和检测过程都是端到端的,整个网络仅使用一个CNN网络直接预测目标的类别和位置。检测过程对整张图片做卷积,使检测目标具有更大的视野,且不容易对背景造成误判。
主干特征提取网络采用Darknet-53的网络架构,包含53个卷积层。借鉴残差网络,在一些层之间设置了快捷链路。模型预测过程中,利用多尺度特征进行对象检测。首先将图片调整成416*416*3的格式大小输入到CNN卷积层。经过一些列卷积操作,分别通过32倍下采样、16倍下采样、8倍下采样得到不同尺度大小的卷积核进行预测。经过32倍下采样的特征图大小为13*13,特征图感受野大,适合检测图像中尺寸较大的对象。经过16倍下采样后的特征图具有中等尺度的感受野,适合检测尺寸中等的对象。经过8倍下采样的特征图感受野最小,适合检测小尺寸的对象。高层级特征图语义丰富,精度低。低层级特征图语义不丰富,精度高。通过跨层连接,输出特征图既有较高的精度,又具有较丰富的语义含义。对于3种不同的下采样尺度设定3种先验框,通过K-means聚类得到先验框的尺寸,总共聚类出9种尺寸的先验框。驾驶员区域检测模型网络架构图如图2所示。
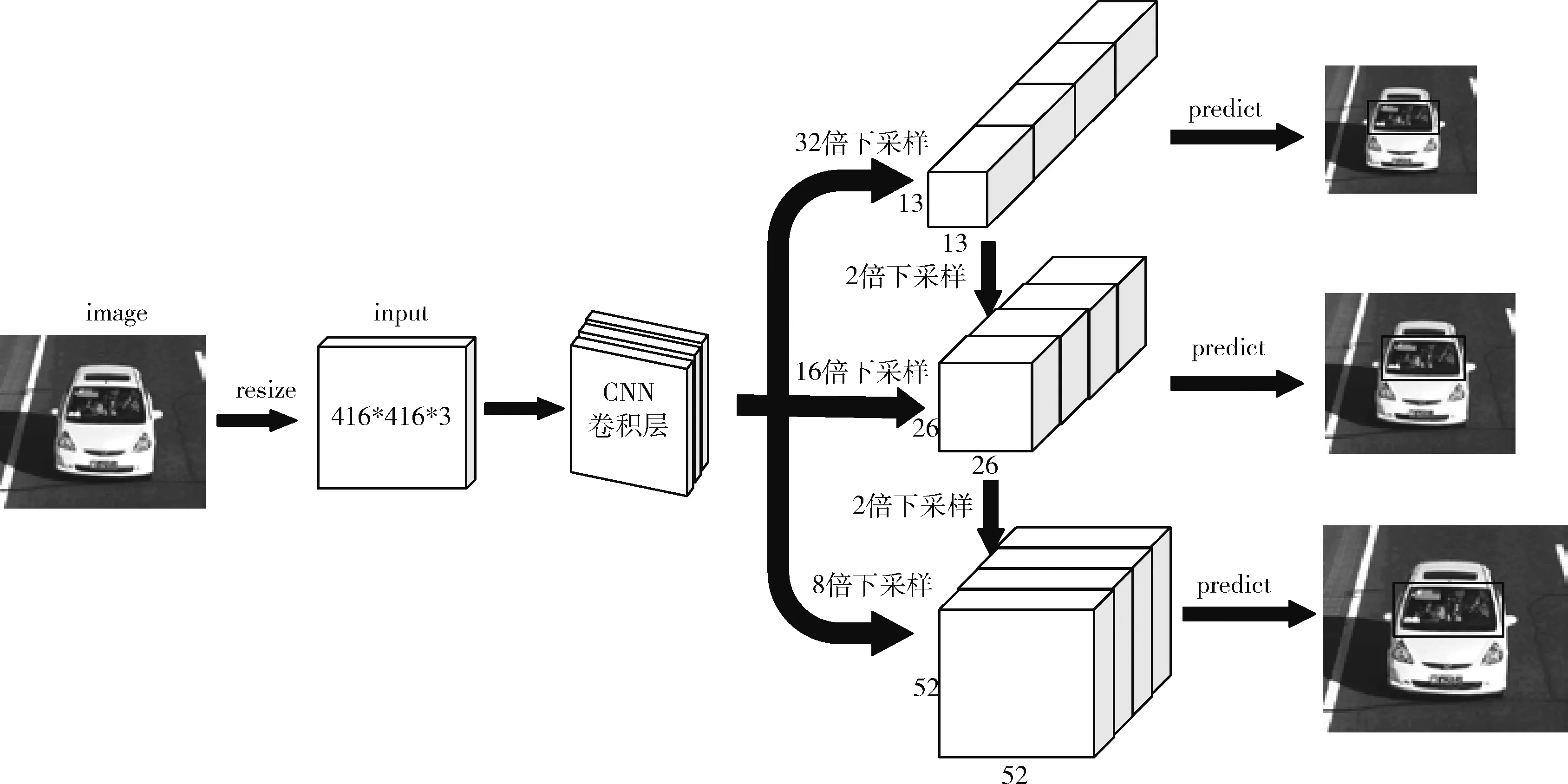
图2 驾驶员区域检测模型网络架构
模型损失函数误差来源于3部分,分别为定位损失误差、置信度损失误差与分类损失误差。模型预测过程中将整张图片划分成s*s个网格,每个网格产生B个候选框anchor box。对于第i个网格中第j个anchor box,需要对这个anchor box产生的bounding box求出中心坐标误差、宽高误差、置信度误差、分类误差。
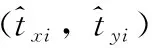
(1)
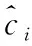
(2)
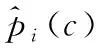
(3)
2.2 安全带单类别目标检测模型
2.2.1 图像增强处理
交通摄像头抓取到的图片中驾驶员区域相对较小,分辨率低,且易受光照强弱等外界因素干扰,驾驶员区域往往不清晰。为提高安全带区域的对比度,首先对驾驶员区域进行图像增强[14]操作。
截取的驾驶员区域图像中,当光照强时图像整体亮度偏高,光照条件不足时图像整体亮度偏暗。过强与过弱的光照条件会使图像中某些像素点色深相近,安全带区域与周围区域对比度并不高。直方图均衡化[15]使用累积分布函数,原始图像根据概率密度转化成相应的灰度级图像。通过对图像进行非线性拉伸,将像素值映射到0到255之间,可将图像中的像素值均匀分布,使一定范围内像素值的数量大致相等。此方法可显著提高驾驶员安全带与周围区域的对比度。映射方法如式(4)所示
(4)
其中,nj表示图像中灰度级为j像素点的个数,n为像素点总个数,k为灰度级等级总数。
经过灰度化、直方图均衡化处理后的图像,受图片分辨率大小的影响,小分辨率图像存在较多噪点。本文采用高斯滤波器进行去噪处理,选用3*3的高斯核对图片进行卷积操作,平滑处理降低噪声,减少图像中噪点。因处理二维图像,故采用二维高斯分布函数式定义卷积核数值大小。 (x,y) 表示以中心点为原点的位置坐标,σ为方差,计算公式如式(5)所示
(5)
假设卷积核的大小为 (2k+1)*(2k+1), 则卷积核各个元素值计算如式(6)所示
(6)
图像增强处理过程如图3所示。

图3 图像增强处理过程
2.2.2 安全带单类别目标检测
Faster R-CNN双阶段网络相比于YOLO等单阶段的目标检测网络,检测目标更加精准。安全带类别属于小目标,Faster R-CNN在小目标检测上具有良好的表现,因此基于Faster R-CNN网络进行安全带的目标检测工作。Faster R-CNN是由何凯明等于2015年提出的目标检测算法。Faster R-CNN网络分为两部分,一是Region Proposal Network(RPN)区域生成网络,二是Fast R-CNN网络。其中RPN网络包括proposals和conv layers层,Fast R-CNN包括卷积层、ROI pooling及全连接层等部分。
检测过程中,图片被调整成800*800*3的格式大小。首先将整张图片输入到卷积层进行卷积操作,提取图片的Feature maps。将Feature maps输入到RPN建议网络得到候选框的特征信息。最后将目标框和图片的特征向量输入到ROI pooling层。为了满足对不同大小图片的检测,ROI pooling层将截取到的不同的小的特征层区域调整到一样大小,再通过分类与回归网络判断截取到的图片中是否包含目标,并对建议框进行调整,完成目标检测的任务。基于Faster-RCNN的安全带检测流程如图4所示。
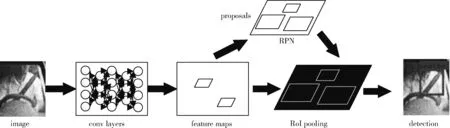
图4 基于Faster R-CNN的安全带检测流程
传统的基于深度学习的安全带检测模型的检测类别为双类别,类别有安全带和无安全带两种。在制作数据集时,需同时制作有安全带与无安全带两种数据集,工作量较大。对于驾驶员未佩戴安全带的图片,因驾驶员身体无安全带区域并没有明显特征,实际检测效果较差。
本文设计了一种基于Faster-RCNN的安全带单类别目标检测模型。模型训练中采用有安全带图片作为数据集进行训练,将安全带双类别分类问题转换为单类别目标检测问题处理。在实际检测过程中,相比于双类别分类模型,检测速率更高,准确率也相应提升。安全带单类别目标检测流程如图5所示。
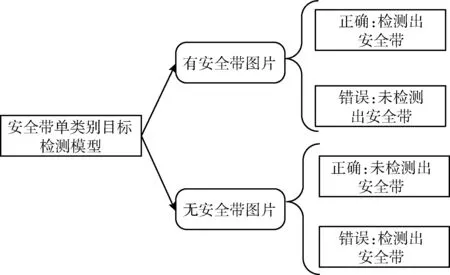
图5 安全带单类别目标检测流程
对于驾驶员佩戴安全带的图片,模型正确检测出安全带作为正确检出结果。对于驾驶员未佩戴安全带的图片中,模型未检测出安全带作为正确检出结果。
3 实验设计与结果分析
实验中训练模型及测试所使用的图片为道路交通监控摄像头所拍摄的车辆图片,数据集来源于北京理工大学的BIT-Vechicle Dataset数据集。在模型的训练过程中,采用LabelImg软件进行人工图像标注。
实验采用Intel Core i7-9700处理器*8,16 G内存,NVIDA GeForce RTX2060显卡,CUDA10.1,CUDNN7.5深度神经网络加速库,Windows 10操作系统,TensorFLow2.1深度学习框架。
3.1 评价指标
本模型使用了几个评价指标衡量模型效果的好坏,分别为准确率(AC)、平均置信度(AVC)与检测速率(DR)。AC反应模型检测准确率的高低。AVC表示检测出的所有目标的平均置信度,反应模型可信度的高低。DR反应模型检测速度的快慢,衡量标准为帧(s-1)。
AVC的计算公式如式(7)所示,即求取所检测样本的平均置信度,n表示检测样本总数量,xi表示样本i的置信度
(7)
文中定义TN、FN、TP、FP。TN(true number)为正样本的总数量,FN(false number)为负样本的总数量,TP(true postitve)为正样本中预测为正样本的数量,FP(false postitve)为负样本中预测为正样本的数量。
对于驾驶员区域检测模型,检测样本只有正样本。AC为正确检测出的图片数量占检测图片总数量的比例,如式(8)所示
(8)
对于安全带检测模型,检测样本分为正样本与负样本。本安全带检测模型为单类别目标检测模型,检测类别为单一类别,对于正样本,计算正确检出安全带的样本数量。对于负样本,计算错误检出安全带的样本数量与负样本数量的差值作为正确检出结果。并计算正确检出结果的样本数量占总样本数量的比例当作准确率。AC(positive)为在正样本集中检测的准确率,AC(negative)为在负样本集中检测的准确率,AC表示总体准确率。计算公式如式(9)、式(10)、式(11)所示
(9)
(10)
(11)
3.2 主驾驶区域检测模型实验
3.2.1 驾驶员直接检测模型实验
为了简化检测流程,本文最先设计了驾驶员直接检测模型,尝试直接从交通探头所拍摄的图片中检测驾驶员区域。实验验证模型不同迭代次数对检测准确率的影响,以寻求最优迭代模型。驾驶员检测模型准确率随模型迭代次数的变化如图6所示。
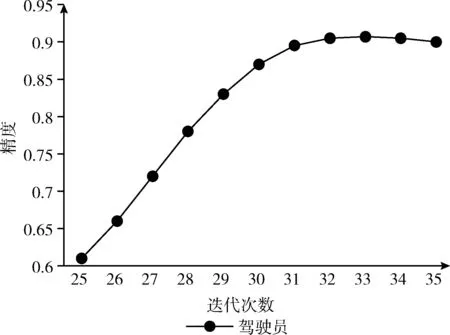
图6 驾驶员检测模型准确率
基于2482张图片测试中,当模型迭代次数达到33次时,模型检测准确率不再上升并趋于稳定,模型准确率大约为91%。驾驶员直接检测模型检测示例图如图7所示。

图7 驾驶员区域检测
3.2.2 驾驶员区域检测模型实验
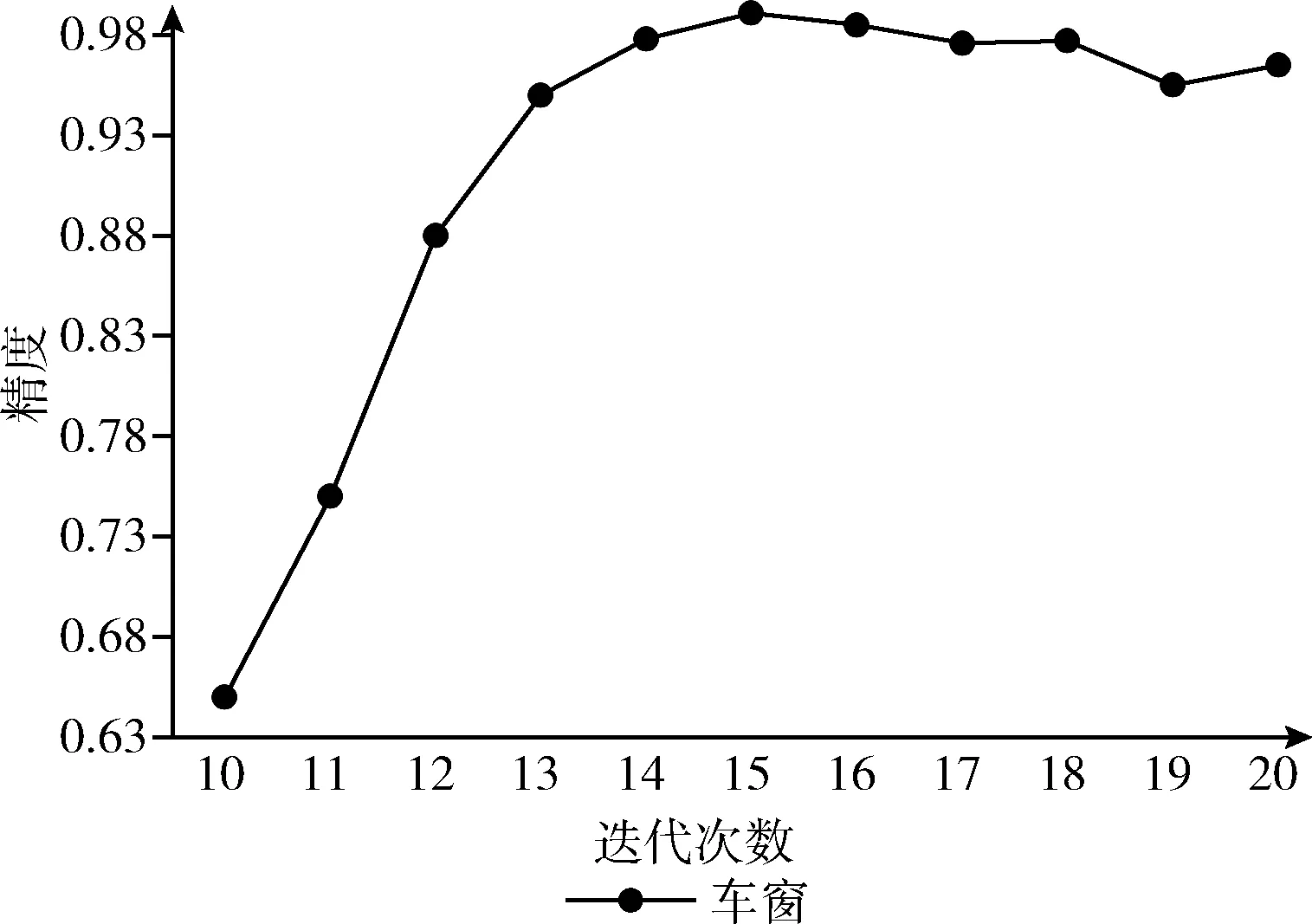
图8 车窗检测模型准确率
本文采用相同的训练集与测试集,进行对比实验,对比了基于Faster R-CNN的车窗检测模型与基于SSD(single shot multibox detector, SSD)[16]网络的车窗检测模型,测试这几种模型在相同测试集下的准确率(AC)、平均置信度(AVC)及检测速率(DR),实验结果见表1,图9为车窗检测。

图9 车窗检测
由表1得出,基于2484张测试集图片测试中,本文方法测得准确率为99.9%,平均置信度约为98.1%。因车窗特征相对明显,在基于Faster R-CNN的车窗检测模型与基于SSD网络的车窗检测模型中,也可得到较高的准确率与平均置信度,本文方法准确率略高于其它两种方法。检测速率上,本文基于YOLO v3的车窗检测模型可达到233 帧/s,相比于Faster R-CNN网络与SSD网络,检测速率更快。实验结果得出,所设计的车窗检测模型具有较高的准确率与检测效率,可满足实时性目标检测的需求。
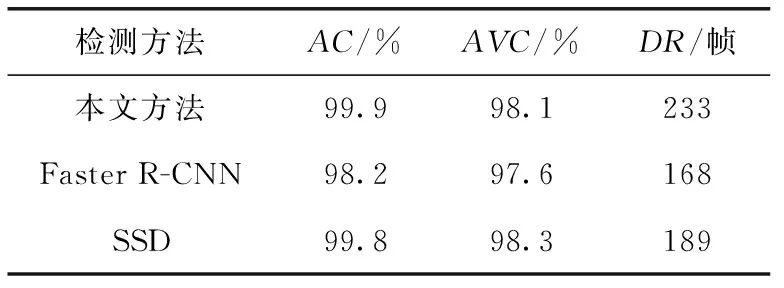
表1 车窗检测模型对比
同样为了验证模型迭代次数对车窗-驾驶员检测模型准确率的影响,记录不同迭代次数与准确率的映射关系。采用与车窗检测模型相同的网络架构,训练了车窗-驾驶员检测模型。训练集图片与测试集图片均来自上一步车窗检测模型中所检测出的车窗图片。当模型迭代到27次,LOSS值已降低到0.6且不再收敛。车窗-驾驶员检测模型准确率随迭代次数变化如图10所示。
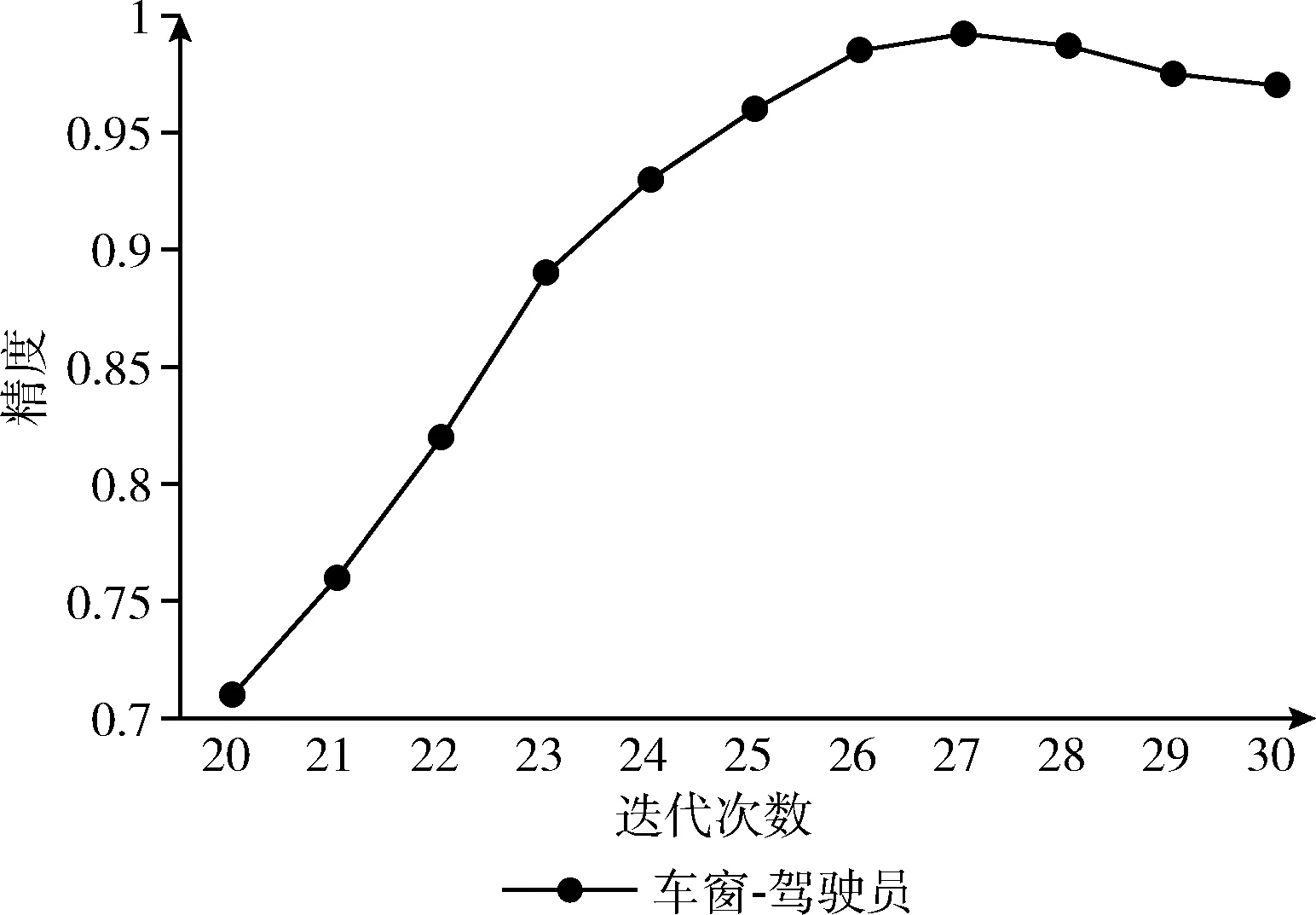
图10 车窗-驾驶员检测模型准确率
进行了相同的对比实验,实验结果见表2,图11为车窗-驾驶员检测。

图11 车窗-驾驶员检测
从表2可以看出,基于1805张图片测试中,本文方法测得车窗-驾驶员模型准确率为99.2%,平均置信度为98.6%,检测速率可达到208帧/s。通过车窗-驾驶员检测模型,可实现对驾驶员区域的精细化定位,减少冗余区域对后续安全带检测造成的影响。相比于传统的通过几何法裁取驾驶员图片,本方法容错率更高,适应性更强。
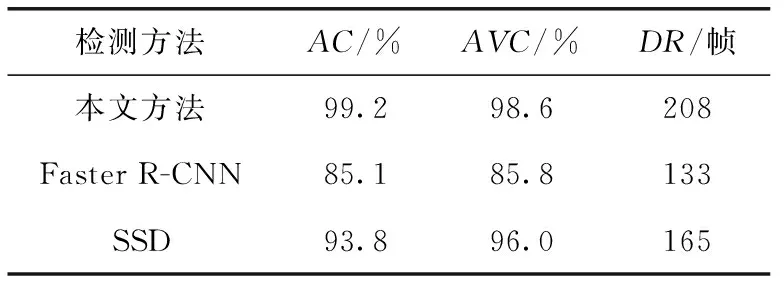
表2 车窗-驾驶员区域检测模型对比
将车窗检测模型与车窗-驾驶员检测模型相结合,测试驾驶员区域检测模型总体准确率,实验结果见表3。

表3 驾驶员区域检测模型对比
因受图片分辨率以及检测目标大小的影响,驾驶员直接检测模型检测准确率并不高,并不能直接检测驾驶员。本文所设计的车窗检测模型+车窗-驾驶员检测模型总体准确率约为99.1%,可满足对驾驶员区域的目标检测工作。
3.3 安全带检测模型实验
3.3.1 图像增强处理实验
基于Faster R-CNN的安全带单类别目标检测模型一共分为两部分:图像增强处理与安全带检测两个步骤。通过图像增强处理后,增强了安全带区域的对比度,如图12所示。
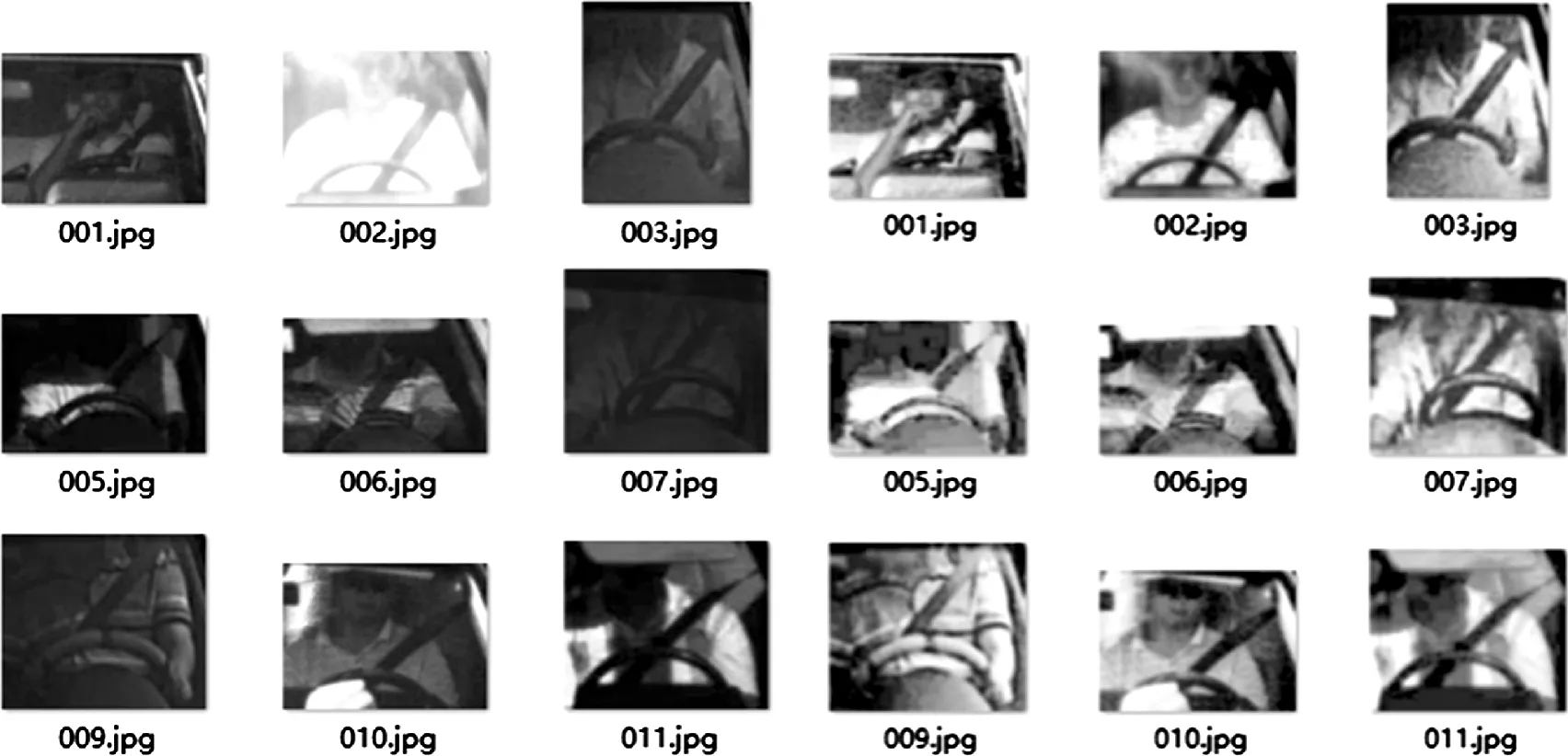
图12 原图(左)-图像增强处理图(右)
3.3.2 安全带目标检测实验
将处理后的图片送入到Faster R-CNN模型进行训练。本实验制作训练集图片932张。选取测试集3422张。测试集中,包括正样本集1716张,负样本集1706张,模型一共迭代100次。实验验证不同的置信度(confidence)阈值大小验证对模型检测准确率的影响,分别测试在正样本集、负样本集下的准确率以及总体准确率。其中,AC(positive)为正样本集中的准确率,AC(negative)为负样本集下的准确率,AC为总体准确率。实验结果如图13所示。
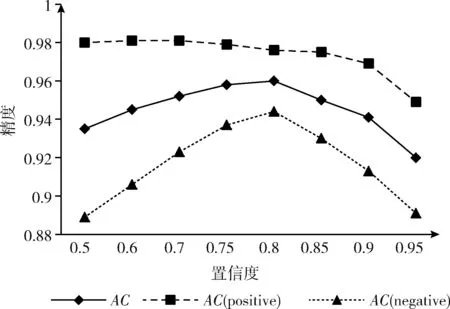
图13 安全带检测模型准确率
由图13可以看出,本文所提出的安全带检测模型在正样本集中准确率整体高于负样本集中的准确率。设定较小的置信度阈值会对负样本集造成更多的误判,设定较大的阈值会过滤掉部分正样本集图片。当设置confidence=0.8时,模型检测准确率达到最优状态。
模型最终设定置信度大于0.8、交并比(intersection over union,IOU)高于0.6时作为正确检出结果。为验证图像增强处理对模型检测准确率的影响,分别实验检测未经过图像增强处理与经过图像增强处理步骤后的两种基于Faster R-CNN的安全带单类别目标检测模型准确率,并对比了其它文献中安全带检测准确率,实验结果见表4,图14为安全带检测。
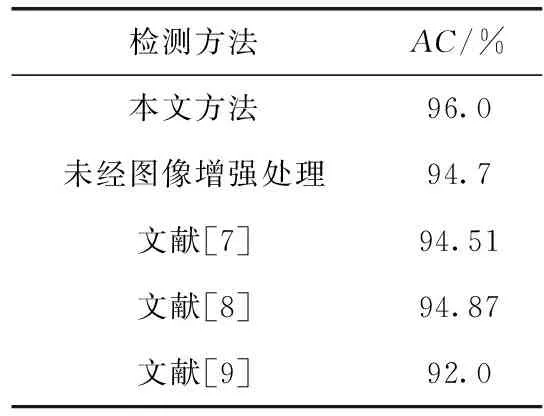
表4 安全带检测模型对比

图14 安全带检测
通过表4可以得出,本文设计的基于Faster R-CNN的安全带单类别目标检测模型在未经图像增强处理时,准确率约为94.7%。通过图像增强处理后,准确率提高到96.0%,准确率有所提升。相比与其它文献中的方法,准确率较高。因本模型首先经过图像增强处理,增强了安全带区域对比度,因此本模型不易受光照强度、图片清晰度等因素影响,实际应用过程中鲁棒性更强,适用范围更广。
4 结束语
本文提出了一种图像处理与深度学习相结合的驾驶员安全带单类别目标检测模型。①为了快速定位主驾驶员区域,简化检测步骤。利用YOLO算法目标检测速率快的特点,训练了车窗检测模型与车窗-驾驶员检测模型,实现了对驾驶员区域的快速与精细化定位。②为了适应光照条件、图片清晰度不良的图片,本文首先对驾驶员图像进行图像增强处理,提高安全带的对比度。③为了提高检测准确率,训练了基于Faster R-CNN的安全带单类别目标检测模型,将传统的二分类问题转化为单目标检测问题处理。相比于传统的基于深度学习的安全带检测模型,本方法适用性更强,准确率也相应提升。目前,模型只检测主驾驶员区域,我们也将改进模型,同时检测主、副驾驶员区域并判断是否佩戴安全带。安全带单类别目标检测模型在正样本集上的准确率较高,在负样本集上准确率稍低,也将进一步通过优化模型网络架构,提升模型的准确率。
猜你喜欢
燃气涡轮试验与研究(2021年6期)2021-08-01
海洋信息技术与应用(2020年4期)2021-01-18
中国生物医学工程学报(2019年5期)2019-07-16
中学生数理化·八年级物理人教版(2019年3期)2019-04-25
北京航空航天大学学报(2017年3期)2017-11-23
女士(2017年10期)2017-11-01
疯狂英语·新读写(2017年1期)2017-04-06
小学生作文(低年级适用)(2017年12期)2017-02-06
发明与创新·小学生(2016年8期)2016-08-17
汽车文摘(2015年11期)2015-12-02
