
面向文书的情报关键信息抽取算法
2023-03-11 08:21张锦文
火力与指挥控制 2023年1期
陈 勇,邢 欣,张锦文
(1.中国科学技术大学,合肥 230026;2.北方自动控制技术研究所,太原 030006)
0 引言
作战文书是部队实施指挥控制时传递信息的重要载体,由作战人员根据战场情况,简明扼要、准确无误地编写敌我情况、战斗部署、行动计划、指挥命令等内容,便于阅读且具有法律效应。但作战文书本质上是面向作战人员使用的信息承载方式,其非结构化的自然语言数据,不便于指挥信息系统直接用于分析、计算等操作,使得作战人员被迫充当了文书和指挥信息系统之间的信息“编码器/解码器”,给作战人员带来较大且繁琐的工作,间接降低了作战指挥的效率。
如图1 所示,作战人员A 从集团军的指挥信息系统、情报侦察系统或指挥员意图等多个来源获取信息,按照要求编写相应的作战文书。利用通信链路,传输至作战人员B 阅读后,在合成旅指挥信息系统中开展相应操作。其中步骤(2)文书编写和步骤(4)文书阅读,即是以作战人员为主的文书编码/解码过程。该过程繁琐、效率低,且作战人员在紧张的作战情景下容易出错,给作战指挥带来不可预估的负面影响。

图1 文书流转示例Fig.1 Example of operation document transfer
针对这一问题,本文聚焦于文书中敌情、战场环境、气象环境等情报类内容,提出了一种基于BERT+BiLSTM+CRF 的情报信息抽取算法,抓取其中的要素、时间、地域、动作、属性等关键信息,并转换成相应的格式化数据,既能够减轻参谋人员“解码”的事务性工作量,同时可为指挥信息系统态势标绘、兵力统计、战斗力对比、关联推荐等下游业务提供基础数据支撑。
1 相关工作
文书信息抽取是实体识别在作战指挥控制领域的具体应用,抽取方法随着实体识别算法发展而快速发展,逐步由规则算法向统计算法、深度学习算法演变。规则算法方面,文献[3]利用有穷自动机结合递归型组块规则,自动识别部队番号。文献[12]则利用句法分析规则,识别文书中的地名。该类规则化方法的基础在于识别规则的梳理,对不同内容的识别需要建立不同的识别规则,可扩展性不足。文献[4]基于预定义的本体信息,对文书中番号、时间、方位、地点等感兴趣的内容进行抽取。该方法的信息抽取能力受限于本体定义(Ontology 定义)规则,对文书的适应性不高。文献[5]通过分词和语义分析两个主要步骤,抽取文书中的实体元素,并用于后续自动标图业务。但该方法给定了有限的语义角色,没有覆盖数量、属性等信息。规则类抽取算法覆盖范围窄,精度一般,因而逐步向统计方法转变。统计算法方面,文献[6]使用条件随机场方法,识别装备、地名、机构、设施等实体信息,并利用词典和规则修正识别结果,识别进度有明显提高。但随着深度学习算法的快速发展,文献[7-11]均引入了BiLSTM 深度神经网络作为特征提取器进行实体识别,文献[7-11]还采用了CRF 方法,相比之前的算法明显提升了识别的精度。但现有的深度学习算法还存在两个问题,一方面所识别的对象仍局限于传统的实体识别领域,针对文书中的情报信息提取的覆盖面不广泛;另一方面,现有深度学习算法对自然语言处理特征的表征能力不足,整体识别能力还有提高的空间。
本文使用深度学习算法抽取情报文书中的关键信息,进一步扩展了作战文书中的实体范围,将属性作为要素、地域等实体的附带信息一并识别,同时使用BERT 作为自然语言特征表征器,提高了抽取结果在军事应用场景中的完备性、准确性和可用性。
2 情报关键信息
2.1 作战文书及内容
作战文书类型主要包含敌情通报、预先号令、作战方案、处置命令等类型,用于筹划准备、作战执行等阶段。每类作战文书均规定了必填的章节模块,如在预先号令中,主要章节为敌情、任务概要、准备工作、完成时限等,由作战人员依据各类信息源手动编写。
本文以作战文书中涉及到情报信息的章节内容为研究对象,将自然语言描述的情报文本转换为格式化的情报要点数据。由于作战文书在描述敌情时,一般会明确地指出敌部队在何时何地执行何种动作,以及该部队属性如何,这类信息对作战人员理解战场情况、指挥作战至关重要,因此,从作战文书中抽取要素(object)、时间(time)、地域(location)、动作(action)、属性(property)5 类关键信息。相比传统的实体识别[1-2,13]研究有所不同,一方面将人名、机构名统一归为要素当中,作为战场中客观事物的集合进行抽取;另一方面扩展了动作、属性两项识别内容,作为客观事物的附属关联信息进行抽取。对这两类信息的抽取,能够较好地描述情报文本中每一要素的具体情况,为指挥信息系统下游业务提供信息支撑。
2.2 情报关键信息分类
情报文本是战场情况的映射,是综合多种情报源基础上对战场实际的理解和描述,编写时具有一定的自由度。结合军语、互联网资料、演习实际文书等材料,对要素、时间、地域、动作、属性5 类关键信息进行细分,以便算法能够较好识别相关内容。
1)要素(Object)
要素是传统实体识别中的人物、机构[13]等具有现实对照物的名称,在军事领域,需要对其进行扩展,至少还应包含番号、装备、设施等名称。
2)时间(Time)
本文所指时间与传统实体识别中所提时间基本一致,某些情况下可能会区别作战时间和天文时间,但时间表述格式无差别。
3)地域(Location)
本文所指地域是传统实体识别中的地点。较为不同的是,作战文书中的地点可能会使用“地名+坐标”的方式进行精确表述,对于一些无名地点会使用高程加以区分。此外,还会使用地域范围来表述地域信息,用于描述部队的行动空间。
4)动作(Action)
动作是传统实体识别中未涉及的内容。在军事领域中,主要指装备、部队的运动、防御、侦察等作战行为。本文将要素的动作进行抽取,用于描述要素的行为信息。
5)属性(Property)
传统实体识别中会抽取数量信息,本文所抽取的属性同样是要素的数量属性,如侦察范围、机动速度、有效火力等。
图2 展示了军事情报5 类要点与传统实体识别之间的对应关系。可以看出,本文所抽取的信息是对传统实体识别的扩展,因此,应选用泛化能力强、识别效果好的算法,以便能够适应多类关键信息的抽取。

图2 军事情报关键信息与传统实体识别Fig.2 Key information and traditional entity recognition for military intelligence
3 情报关键信息抽取
情报文本的编写讲究简明扼要原则,每一句话需要交代明确的要素及关联的位置、时间、动作等信息,较少出现大段落内容,以免文书编写、阅读过程中出现混淆。此外,情报文书专为描述各类情况而编制,其中使用的词语集合比开放领域的集合稳定。这为情报关键信息抽取提供了较好的基础。结合自然语言研究最近研究成果,BERT 预训练模型在多项自然语言任务上取得优异成绩[14],能够广泛适应中文实体识别任务[15]。因此,本文使用BERT模型作为后端基础模型,在此基础上利用BiLSTM和CRF 的算法校正识别效果,应用多个与军事相关的数据集进行训练,获得较好的识别率。
3.1 算法架构
情报关键信息抽取算法由数据源及输入、数据处理、模型训练及预测、结果输出4 个阶段组成,如图3 所示。

图3 情报关键信息抽取算法架构Fig.3 Architecture of key information extraction algorithm of intelligence
数据源包括军语文本数据、公开军事报道数据、演训文书数据。其中军语以《中国人民解放军军语》2011 版为基础,选取作战(综合)、战斗战术、侦察情报等类目中的词条解释作为训练文本(约1 500 个词条),通过手动方式标出词条解释中的5 类关键信息。由于军语不涉及具体的作战背景,仅能提供通用的实体数据,因此,还需要利用公网数据补充特殊武器装备、地址地名等实体数据;公开报道为军事门户网站文本数据,本文主要从环球网、新浪网、搜狐网等门户网站的军事频道中摘取实时军事文本,其中国内军事动态共200 篇,国际共400篇。每篇数据去除段落及特殊字符,并手动标注关键信息;演训文书主要以某部队演习过程中产生的真实文书为主,包含预先号令、敌情通报、作战计划等各类文书共38 份。实验中从每份文书中摘取“敌我情、综合情况”等段落内容数据,通过清洗、拆分进行预处理,而后通过等价替换方式进行脱密处理(时间以外的阿拉伯数据按照1-9 的顺序替换,地点从国内县级以上地名中随机选取替换)。处理后的样例数据如表1 所示。

表1 演训文书样例数据Table 1 Sample data of operation documents for demonstration and training
3 类数据集中,军语和公开军事报道均作为训练数据。演训文书数据中,按照0.7、0.2、0.1 的比例随机划分为训练、验证、测试集。
2)数据处理
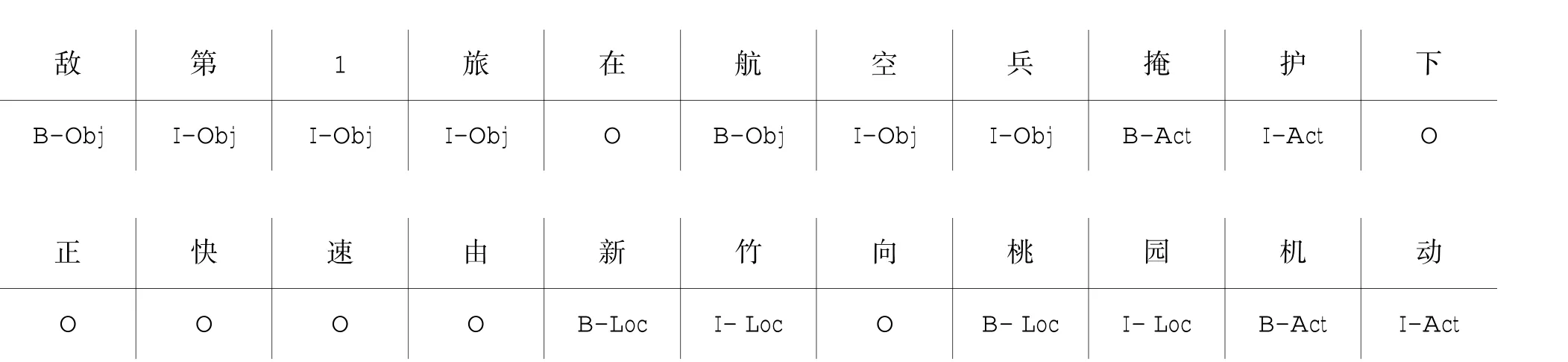
数据处理包含预处理和标注。预处理主要针对数据源进行清理、过滤,并自动标注非实体内容,如标点符号、助词、非法字符等内容。标注使用BIO 方式,例如“敌第1 旅在航空兵掩护下,正快速由新竹向桃园机动”,标注结果为:
3)模型训练及预测
分词算法由BERT(bidirectional en) coder representations from transformers)[14]+BiLSTM(bi-direction al long short-term memory)+CRF(conditional random field)组成,通过BERT 中文预训练模型[15]获取输入的字符级特征向量,然后利用BiLSTM 得到输入的最大概率标签,最后利用CRF 对输出进行优化,得到全局最优标记。
(2)2017年,铁路总公司发布了最新的施工图审核考核办法,对咨询单位的工作质量提出了新的要求,承担施工图审核工作的咨询单位,内部管理需要进行适应性改善。
4)结果输出
根据算法得出的标签序列,转换成对应的标签内容,完成结果输出。
3.2 BERT+BiLSTM+CRF 算法
分词算法自底向上主要由BERT、BiLSTM、CRF组成,如图4 所示。BERT 是由Google 在2018 年提出的语言预训练模型框架,使用遮蔽方式在大量的语料库上进行训练,能够更好地表征一词多义,成为众多NLP 任务中的基础模型。再结合BiLSTM 的双向记忆能力,组成性能更优的实体识别算法。
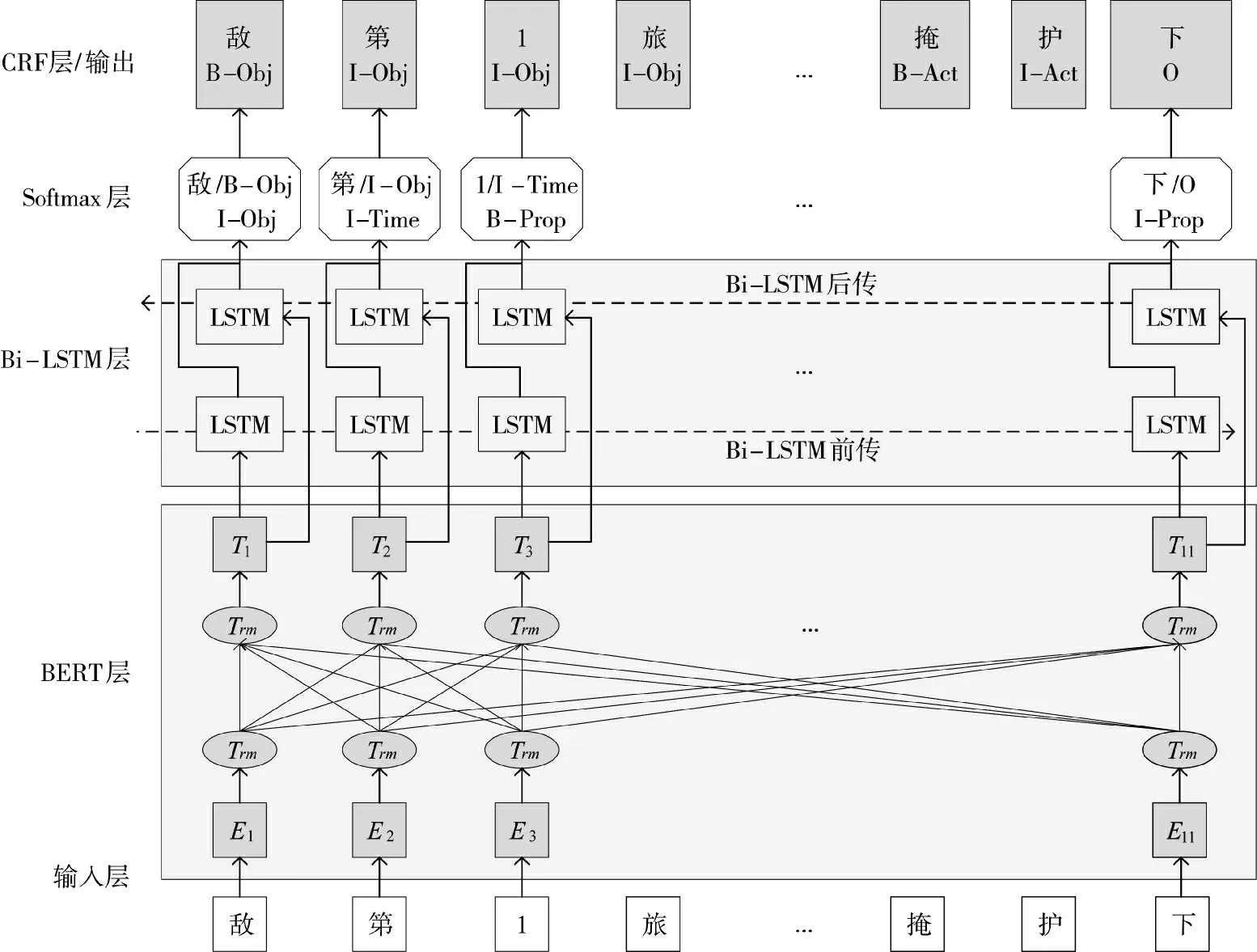
图4 BERT+BiLSTM+CRF 算法结构Fig.4 Algorithm structure of BERT+BiLSTM+CRF
1)BERT 层
BERT 是以双向Transformer 编码器单元为主的词向量表征模型,可以更好地了解上下文语意信息和特征。其中,self-attention 机制是Transformer 编码器的核心组成,通过调整关联权重寻找词之间的关联程度,如图5 所示。

图5 Transformer 结构Fig.5 Structure of Transformer

其中,(query)、K(key)、V(Value)是输入的字符向量,dk是输入向量的维度。Self-attention 机制可以通俗理解为在给定查询(query)的情况下,从字符集的编码K(key)中寻找与查询(query)相似的向量,得到的值V(Value)便是字符之间的相似度。该机制能够长文本条件下,对所关注部分的关系进行捕获,同时也能够对层次结构的信息进行表达。
训练时,BERT 将字符级(词嵌入)、句子级、位置信息拼接作为输入,利用遮蔽方式随机扣掉中间字符,使用前后字符对遮蔽字符进行预测,使BERT模型能够充分掌握上下文信息。
2)BiLSTM 层
BiLSTM 模型是RNN(recurrent neural network)和LSTM 模型的变种,通过多个记忆单元解决了RNN 训练过程中的长期依赖不强以及梯度消失/爆炸问题,利用正/反向传播同时捕获前后文信息,得输出序列标签。
BiLSTM 的核心单元包含遗忘门、输入门、输出门,如下页图6 所示。遗忘门主要负责舍弃前一时刻ht-1中不相关信息量,输入门负责根据xt向量向LSTM 单元中添加新的信息,输出门则用于确定输入xt以及前一时刻ht-1中哪些信息可以输出。

图6 LSTM 单元Fig.6 LSTM unit
BiLSTM 的输出通过softmax 层后,得到字符对应的最大概率标签,作为CRF 层的输入。
3)CRF 层
BiLSTM 的输出只针对字符级别,不考虑前序标签与当前标签之间的关系,有一定概率造成结果不准确、不合理。如图4 的Softmax 层输出的第3 个字符“1”的标签是“I-Time”,根据前序标签“第/I-Obj”判断,字符“1”的标签是不合理的。CRF 算法则能够考虑相邻标签之间的关系,获得全局最优的标签序列,对不合理的输出进行“矫正”。
CRF 是给定观测条件下的马尔可夫随机场,即X,Y 是随机变量,P(Y|X)是给定X 时Y 的条件概率,若Y 是马尔可夫随机场(Y 的条件概率仅与相邻状态有关),则P(Y|X)便是CRF。在本算法中CRF定义了标签转移分数,设X={x1,x2,…,xn}是输入的字符序列,Outn,m是BiLSTM 的输出矩阵,Y={y1,y2,…,yn} 是预测序列,T 为标签i 转移为标签j 的概率矩阵,则其标签分数函数为:

将式(4)作为损失函数,利用梯度下降法求得最小损失,即为P(Y|X)最大值,得到在Outn,m输出条件下,Y 的全局最优标签序列。
4 实验分析
4.1 实验环境
本文采用中文预训练的BERT 模型[15]作为骨干网络,并在高性能GPU 服务器上进行其他网络层(BiLSTM)的训练,实验环境配置如表2 所示。

表2 实验环境配置Table 2 Experiment environment configuration
实验中,使用CRF 模型[6]、BiLSTM 模型[10]、BiLSTM+CRF 模型[7-8]、BERT+BiLSTM+CRF 模型进行试验对比,神经网络参数如表3 所示。

表3 神经网络参数Table 3 Neural network parameters
在训练过程中,使用Adam 优化器对网络参数进行优化。采用动态学习率(learning rate)调整策略,每5 个epoch 步减少0.002 的步长,最小减少到0.001 为止。当网络损失(total loss)在1 个epoch 内的下降值连续小于0.01 时自动结束训练,并选择训练过程中在验证集上损失最低的模型参数作为训练结果。
4.2 结果分析
本文共对5 组模型进行训练,实验结果如下页表4所示。

表4 实验结果Table 4 Experiment results
从表4 可以看出,单独使用CRF 作为识别器能够达到一定的识别效果,适合在终端环境或者没有GPU 资源的硬件环境中使用。随着深度学习算法的加入,识别的准确率和召回率都有明显提升。但BiLSTM 网络层数的增加,没有为识别效果带来显著提升。基于这一点考虑,BERT+BiLSTM+CRF 算法也使用2 层BiLSTM 进行构建,在识别效果显著提升的情况下又能够平衡训练成本。从以上实验结果可以看出,使用BERT 预训练模型,能够有效提升情报文本中关键信息的抽取能力。
5 结论
本文针对现有文书信息抽取类目范围窄、抽取精度低的问题,提出了基于BERT+BiLSTM+CRF 模型的情报文书关键信息抽取方法。借助BERT 强大的语义表征能力,在原有实体识别类目基础上,增加了要素、动作和属性3 类信息的抽取,在扩充抽取类目的同时,保持了抽取精度不下降,既能够降低作战人员读取各类文书、填充各类表框时的工作量,又能够直接为指挥信息系统下游业务提供数据来源,为提升指挥信息系统自动化的业务流程、增加作战指挥效率提供原型支撑。
猜你喜欢
现代装饰(2022年5期)2022-10-13
邯郸学院学报(2022年2期)2022-07-05
现代装饰(2022年3期)2022-07-05
现代装饰(2022年2期)2022-05-23
安徽警官职业学院学报(2020年6期)2020-07-21
中国外汇(2019年18期)2019-11-25
西夏学(2019年1期)2019-02-10
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
