
基于生存分析理论的电子资源用户流失预测研究
2023-07-10 07:18刁羽薛红
新世纪图书馆 2023年5期
刁羽?薛红


摘 要 基于电子资源校外访问系统用户行为数据,运用生存分析理论中的Kaplan-Meier、COX比例风险模型研究用户整体流失概率变化规律、用户个体访问行为与其流失概率之间的发展变化规律及相关关系,并在预测用户流失临界点的基础上建立用户流失预警机制,从而为进一步采取用户流失干预措施提前布局。本研究能反映出用户访问行为与用户流失概率之间的变化情况,具有较高的应用价值和推广价值。
关键词 用户流失;流失预警;生存分析;校外访问系统;电子资源行为数据
分类号 G252.62
DOI 10.16810/j.cnki.1672-514X.2023.05.009
Research on Electronic Resource User Churn Prediction: Taking Off-campus Access System of Electronic Resource as Example
Diao Yu, Xue Hong
Abstract Based on the user behavior data of the off-campus access system of electronic resources, the Kaplan-Meier and COX proportional risk models in the survival analysis theory were used to study the change law of the overall probability of user churn, the law of development change and the correlation between the individual user access behavior and the churn probability, and a user churn warning mechanism based on predicting the critical point of user churn was established. Therefore, the further implementation of user churn intervention measures in advance layout. This study can reflect the change between user access behavior and user churn probability, and has high application value and promotion value.
Keywords User churn. Churn prediction. Survival analysis. Off-campus access system. Electronic re-source behavior data.
0 引言
随着数字化新技术的迅猛发展,传统科学研究范式已悄然发生变革,电子资源已成为各种不同层次的用户获取信息的主要类型[1]。目前,各高校图书馆的电子资源购置费所占馆藏的经费比例过半,自2006年以来均值与比例基本上呈抬升趋势,虽然在2019年發生下滑,但2020年随即恢复上升[2]。尽管各种类型电子资源在图书馆中不断得到补充,较大地满足了用户需求,但即便如此,仍存在不少用户在访问电子资源过程中由积极使用转向消极使用甚至彻底放弃的现象,这已成为高校图书馆电子资源服务运营面临的挑战和难题,对此采取用户流失干预措施,满足用户需求,提升老用户访问资源行为是关键。通常情况下,拓展新用户与挽留老用户相比,无论在花费的成本上,还是在为企业或系统平台带来的价值上,后者皆优于前者[3]。因此,为最大程度挽留老用户,有效预测濒临流失用户的关键临界点显得尤为重要。为此,本文基于生存分析理论[4]重点研究用户访问行为与用户流失概率之间的发展变化规律及相关关系,来预测用户流失的临界点,并在此基础上形成用户预警分析,从而为图书馆分析流失原因、挽留濒临流失用户夯实基础。
1 研究综述
用户流失最早由Keaveney和Parthasarathy于2010年针对在线服务提出[5],流失类型主要分为两种,一是用户中断在线服务,即在使用一段时间后停止使用该服务;二是用户“服务切换”,即改变所使用服务的提供商或运营商。对于流失用户的定义依行业或访问方式的不同而不同,移动设备App领域以用户一定时期内不再登录、卸载软件及二次安装或选择其他同类替代为界定标准[6]。
近年来,业界关于用户流失的研究主要是以S-O-R理论、扎根理论等为基础,利用访谈设计、问卷调查等方式来统计分析研究不同类型平台用户流失的重要因素。对于用户流失预测研究也有一些学者利用用户访问系统时留下的客观行为数据进行分析,如贺芳以“新浪微博”为例,在用户细分的基础上采用典型判别分析法构建用户流失预测模型, 并通过交叉验证法判别预测精度[7]。王若佳,严承希,郭凤英等使用LDA抽取用户关注主题的文本向量,使用SMOTE算法对模型进行修正,以解正数据集中流失与非流失用户比例失衡的问题,并使用C4.5决策树等6个算法对比研究预测用户流失情况的优劣,对比显示Gradient Boosting和ExtraTrees模型效果较好[8]。在图书馆领域,有些学者基于生存分析理论对文献采购、引文分析、关键词等方面展开分析研究,如:Jiang Z、 Fitzgerald S R、Walker K W等学者使用生存分析法分析出版者、出版时间、价格、美国国会图书馆分类法等与图书馆文献采购的相关关系[9]。朱世琴,蒋辛未等利用生存分析的Cox回归研究CSSCI来源期刊中2000-2014年9个学科的论文被引频度的年代分布,以确定文献的老化风险率[10]。刘智锋,李信通过生存分析方法对作者关键词进行分析,以反映作者关键词生存情况[11]。孙佳佳,李雅静通过客户价值细分RFM模型对CSSCI收录的图情档文献的作者关键词建模,在此基础上利用Kaplan-Meier曲线挖掘热点主题[12]。也有学者将生存分析应用于信息系统用户流失的研究,但总体数量较少。赖院根等为反映国家科技图书文献中心(NSTL)的总体运行状况,对NSTL在2003-2008年间的用户进行了用户流失分析,并使用寿命表方法揭示了NSTL用户的生存时间分布[13];赖院根,刘砺利在通过利用SPSS生存分析模块中的寿命表分析了NSTL用户生存时间的基础上,使用Kaplan-Meier模块对赠卡用户和无赠卡用户进行了生存时间比较,并使用COX模块分析了流失用户的影响因素[14]。
2 用户访问电子资源行为数据分析的相关性理论和分析模型
在大数据时代,如何通过电子资源行为数据有效揭示其与用户流失概率的相关性,如何发掘濒临流失的用户并建立预警信号,不仅是进一步分析用户流失原因并精准施策的基础,也是提高电子资源服务效能的根本。基于这样的考虑,那么能够真实反映用户对校外访问系统黏性的用户访问电子资源行为数据即成为研究用户检索行为和科研方向的重要信息源。高质量的电子资源行为数据不仅是用户获取电子文献资源时与平台自然产生的最为客观的数据,也是新数据范式下快捷高效地发现事物间的内在关联,明确用户的使用规律和关注焦点,对此相关性的研究分析可为图书馆预防电子资源用户流失提供科学依据。
目前,在业界相关研究中,数据驱动的科学研究第四范式开始注重分析数据间的相关关系,即某数据的发生与其他數据变化规律间的关系[15],而非拘泥于揭示现实的“实体性的物与发生性的事”之间的因果关系[16]。目前,数据相关分析已然有效地应用于推荐系统、商业分析、公共管理、医疗诊断等领域,通过时序分析、空间分析等方法进行数据分析[17]。故此,本研究基于生存分析理论利用用户访问系统时留下的客观行为数据进行的分析,不是探究用户访问电子资源各行为特征变量与造成用户流失之间的直接因果关系,而是基于大数据思维,分析用户行为数据特征值随着时间变化与其流失概率之间的发展变化情况及相关关系,以期为下一步找出造成用户流失的关键性原因打下坚实基础。
基于电子资源校外访问系统(以下简称校外访问系统)用户流失概率及流失临界点的计算,本文运用生存分析理论中的Kaplan-Meier和COX比例风险模型来研究用户整体随时间推移流失概率的变化规律,解析用户个体访问行为与其流失概率之间发展变化情况及相关关系,以及预测用户流失临界点,并最终形成用户流失预警分析。
首先定义用户的生存变化规律,用生存函数(survival function)来表示。将用户定义为r;将用户使用校外访问系统的时间长度定义为T,即用户生存时长;将t定义为计算r生存概率的随机时间。生存函数值反映T≥指定时间t时,用户继续使用校外访问系统的概率,其公式[4]如下:
从公式一可以看出,生存函数是t的单调下降函数,代表用户流失的风险随着时间的增加而增加。函数下降快慢,反映了用户使用校外访问系统流失速率的总体情况。
在本研究中,由于用户开始使用校外访问系统的时间以及在观察期间处于流失或删失的状态各有差异,单纯地使用生存函数或危险率函数对含有删失数据的样本数据评估校外访问系统用户的流失规律显然偏差较大。为此,针对存在删失数据的生存分析,可使用1958年由卡普兰和梅尔联合提出的一种基于不完全样本估计总体生存函数的非参数估计量(Kaplan-Meier estimator)进行计算,公式[4]如下:
其中i=(1,2,…,n)为用户集合,y(1)≤y(2)≤…≤y(n)是y1,y2,…,yn的顺序量,y为出现用户流失事件的时间点,δ(1),δ(2),…,δ(n)是与之相对应的y1,y2,…,yn的δ值。从公式二可以看出,Kaplan-Meier的每个时间节点的生存概率都是以上一个时间节点为基础并剔除删失数据进行计算的,因此能较好地解决删失问题。
虽然使用Kaplan-Meier可以预估用户在指定时间节点流失的概率,但没有考虑相关变量在其中的作用,因此还需采用COX比例风险模型(cox proportional-hazards model,以下简称COX模型)。COX模型是一种半参数回归模型,考虑了一种或多种因素对用户生存时长的影响。设与用户生存的相关的因素:X=(X1,X2,…,Xm),则根据COX模型,可以建立以h(t,X)为因变量的指数回归方程[18]:
其中1,…,m为导致用户死亡的因素X1,…,Xm的回归系数,h(t,X)为风险率函数,计算当用户在时间t时仍然在使用校外访问系统,那么计算其在t至?t(?t无限趋近于0)之间流失的概率,公式如下[19]:
本研究的重要目的是预测用户流失的临界点,其原理是在扩展公式一的基础上计算用户在时间s的生存概率。因此在预测生存时间的计算上,设s为用户已经存活的时长,可利用公式五计算该用户已经存活到s时间的条件下,还能存活到t时的概率,其中因在s前用户尚未流失,所以在计算概率时需将s前用户的生存概率设置为1.0[20]:
3 数据来源与数据结构
本研究所采集、利用用户特征数据与用户访问电子资源的行为数据(以下简称行为数据),是指用户在利用校外访问系统过程中登录、检索、浏览、下载等随着时间变化的历次会话的集合。这些数据是用户对校外访问系统用户黏性的真实体现,它们中每个特征值的变化情况,皆可体现校外访问系统对用户的吸引力,即校外访问系统价值[21]。之所以选取校外访问系统行为数据作为数据来源之一,首先在于该系统具备广泛的使用率,能确保采集的样本数据的多样性及准确性,且只涉及用户访问电子资源的行为数据,提取容易;其次该系统详细、全面记录了用户每次访问的不同维度的行为数据,能客观、真实地反映出用户利用校外访问系统情况;第三在技术保障方面,笔者在前期研究成果中已经提出并实现了基于电子资源校外访问系统的数据采集关键技术和实施方案[22]。
3.1 图书馆集成管理系统数据结构
图书馆集成管理系统(以下简称LIS)中的“读者库”表存储了用户基本人口统计学特征数据。而校外访问系统的登录名为用户在LIS中的“借书证号”,因此,可方便地将登录名与LIS的借书证号进行关联,并从LIS中获取本研究所需要的数据。根据学校的实际情况,本研究提取了借书证号、姓名、读者类别字段作为数据来源。
3.2 行为数据来源及其数据结构
本馆购置的校外访问系统用户行为日志数据以JSON格式存储,每条JSON数据代表用户与校外系统的一次会话,JSON数据的文件名为用户的登录名,同一天所有用户的日志数据存储在以当天日期命名的文件夹中。单条JSON日志数据结构如图1所示。
在校外访问系统中,本研究涉及的主要数据有:(1)文件夹名,用于提取用户的访问时间;(2)JSON日志名,用于提取用户的登录名;(3)日志文件的RES元素,通过其SEARCH、DOWNLOAD、VIEW4个子元素获取每次会话用户检索、下载、浏览的次数。
3.3 数据融合
因为校外访问系统的登录名与LIS的借书证号完全一致,故将借书证号作为主键,登录名作外键进行连接,从而可以融合上述两个系统中的数据并存储在以“SurvivalDataset”命名的数据库中。该数据库各表及表间关系如图2所示。
SurvivalDataset数据库涉及的表及其中字段含义如表1所示:
4 校外访问系统用户数据相关性流失分析
本文根据校外访问系统的实际使用情况,将用户在6个月内不再使用校外访问系统定义为“流失”,其余情况则被定义为“删失”。此外,本研究由于学生在校时间有一定时间限制,必然出现自然流失的现象,故本文仅选择以本校教职工为研究对象。其分析思路如图3所示。
首先,使用Kaplan-Meier分析用户整体行为数据在不同时期其生存概率的变化情况,并以此揭示出用户整体流失风险变化趋势;其次,通过使用COX比例风险模型,分析用户各行为数据特征值与用户流失概率之间发展变化规律及相关关系。当特征值的变化与用户流失概率呈正相关时,则可以将之视为用户濒临流失的重要信号;第三,通过公式五预测用户流失临界点(日期),为预防用户濒临流失提前布局;第四,以python 3.8.3+lifelines 0.26.3为工具进行上述生存分析。
4.1 基于Kaplan-Meier的用户整体流失风险分析
通过LIS读者库的用户级别字段筛选出1165名教职工的行为数据,研究时间范围为2017年3月14日至2021年8月31日。根据前文公式二,从SurvivalDataset中提取以下數据并以xlsx格式保存。为了对不同时间阶段校外访问系统的运行态势进行对比,本环节将数据分割为2017年3月14日至2020年8月31日、2018年3月14日至2021年8月31日两组数据。数据结构见表2。
通过Kaplan-Meier分析,并利用python的lifelines库进行对比,形成不同时间段用户生存曲线对比图(图4)。图4中“At_risk”表示生存时长与横坐标不一致的用户数;“Censored”表示删失用户数;“Events”表示在此及以前的累积流失用户数。
以图4中2018—2021年生存期为10个月的数据为例,在前0~10月期间,校外访问系统累积流失人数为287人,有178名用户的使用时长正好为10个月,因没有后续统计数据揭示用户体整体是否趋于流失,故这些标记为删失数据,另有522名用户的使用时长超过10个月。在此基础上,调用Kaplan-Meier的logrank_test函数对上述两组时间段的用户(按时间划分的两组数据)的生存曲线做Log-rank 检验,p值均等于0.21,表明这两条生命曲线没有统计学意义上的差异。从图4的生存对比还可以看出,虽用户整体生存概率在2018年至2021年间的略高于2017年至2020年间,但总体来看,两个时间段用户生存概率走势几乎一致,表明校外访问系统运行状态稳定且在2018—2021年期间用户流失风险还略有降低。总之,结果表明:通过对比不用时期校外访问系统用户整体的生存概率,可从宏观层面上有效监测系统各时期其流失风险变化情况;当各时期校外访问系统用户整体生存概率趋于平稳时,则可将濒临流失的用户个体作为重点监测目标。以下将利用COX模型解析用户访问行为与其流失概率之间发展变化规律及相关关系。
4.2 基于COX模型的用户流失概率相关特征分析
本研究从最能反映用户粘性的访问频率、有效访问行为,以及用户对系统掌握的熟练度等角度出发,根据经验提取了登录频繁度等7个指标作为可能反映用户流失概率变化的相关特征值,再融合用户名等基础数据生成进行COX分析所使用数据。数据结构见表3。
通过分析计算,其结果如表4所示。表4中,coef栏为COX回归方程中各自变量的回归系数。exp(coef)代表风险比(HR,hazard ratio),coef栏的值为此栏的自然对数。当HR=1时,coef的值为0,则变量对用户流失概率没有影响;当HR>1时,coef的值为正,表示变量值越大,则用户流失风险也越大;当HR<1时,coef的值为负,表示变量越大用户流失风险越小。se(coef)为系数的标准误差。表中后面4列分别代表coef和exp(coef)在95%置信区间的上限与下限。
从表4中可得出以下结论:用户活跃度为用户流失概率的不良相关因素,即每次登录后进行大量检索操作的用户更具有流失风险。其余为良性相关因素,即它们所代表的用户访问行为指标越活跃,流失风险越低,其中登录频繁度尤为突出。
为评估COX模型的精准度,本研究通过一致性指数(Concordance Index,C-index)进行评价。其值在0.5到1之间,数值越大,模型的准确性越高。当为0.5时,表示模型的预测完全随机,无任何意义;当等于1时,则表示模型与实际情况完全符合。其原理为将样本数据随机进行两两配对,并比较他们的协变量与其生存时长的关系是否相符,即协变量显示生存时间更短的用户实际生存时长也更短,则为相符,反之,为不相符[23]。最后计算相符的结果在所有情况中的比例。经过计算,本研究的C-index值等于0.82,准确度良好。
5 预测用户流失临界点(critical point)及预警分析
利用lifelines可以计算留存用户在最后一次登录时间(d)后每一天的生存概率,在此基础上即可简捷地预测用户流失临界点(以p表示)。首先,根据公式五计算用户生存概率刚刚小于0.5时距离d的时长(即剩余生存时间),以t_s表示;其次,计算用户流失临界点的公式为:p=d+t_s。在该日期,用户的生存概率刚刚小于0.5,用户留存概率刚好低于用户流失概率。需要注意的是,lifelines默认最多计算1640天的生存概率,如果用户在1640天时的生存概率仍然未小于0.5,则它不再计算t值,而是将用户的生存时长标记为无穷大。在这种情况下就无法预测流失临界点,故予以剔除。本环节使用的数据与基于COX模型的用户流失概率计算使用的数据一致,具体结果如下:
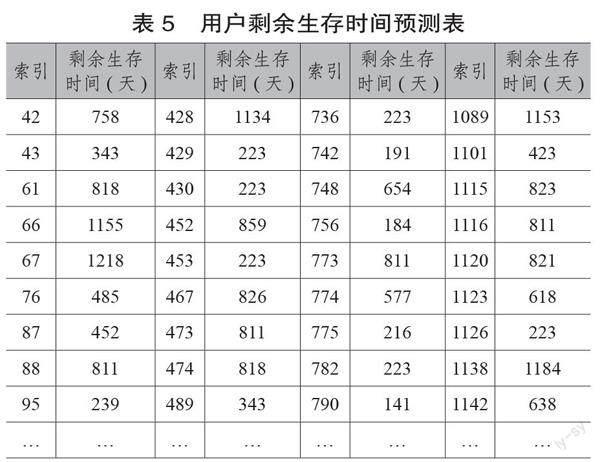
第一步,通過调用CoxPHFitter对象的predict_survival_function函数预测用户剩余生存时间。结果显示可预测160名用户的剩余生存时间,其中最长时间为1308天,最短为56天,平均剩余时间约为568天。预测部分结果见表5。
第二步,计算用户流失临界点。表5中的索引栏为用户在导出数据的excel文件中的行号(以0开始),可用于定位具体用户并获得该用户的最后一次登录时间(d)。以790号用户为例,其d值为2021年4月26日,t_s值为141,则可以计算出其流失临界点为p=t_s+d,即2021年9月14日。
当用户流失临界点计算值出来后,即可进行预警。用户流失预警分析是指通过建立操作性强、可实现的流失识别指标体系,衡量流失迹象是否存在以及存在的边界状态[24]。主要涉及以下三个方面。
(1)监测用户整体的生存概率变化情况。通过Kaplan-Meier对比不同时期用户整体生存概率的变化情况。当近期用户组生存曲线下降幅度增加,同时与前期对照组用户生存曲线作Log-rank检验时且p值<0.05,则表示用户整体生存概率总体趋于恶化,校外访问系统的用户粘性降低,这时就需发出用户整体的流失预警信号;反之,除此之外,还可将濒临流失的用户个体作为重点监测目标。
(2)监测反映用户个体流失概率的相关特征值变化。通过COX定时监测行为数据中反映用户个体流失概率变化的相关特征值的变化情况,有助于及时发现濒临流失的用户个体。当用户流失概率的良性相关因素在一定时间内持续走低时,或不良因素持续升高的情况下,可以认定该用户正处于疲惫瓶颈期,且具有较高的流失风险,需及时发出预警信号。
(3)预测用户流失预警日期。根据用户流失临界点(p)确定用户流失预警日期(churn warning date,以w表示)。当用户位于流失临界点时,其留存的概率刚刚小于流失的概率。此时,可认定该用户已处于濒临流失的状态。但如前文所述,判断用户流失的标准是在提取用户行为数据的截止日期前推6个月内未登录,会出现用户流失临界点早于完成数据分析的时间(以ad表示),如790号用户的p值为9月14日,而本次实证的分析完成之日为9月20日),为精准统计,这部分用户也需要纳入预警范围。另外,因本研究只能发现用户可能流失的相应征兆,而不能明确造成用户流失的具体原因,为真正实现在相对精确的时期介入干预避免用户流失,需耗费一定时间做量的用户调研、数据分析工作,故需在p日前置某个时间段(pd)进行提前预警。该时间可以根据实际情况自定,本研究拟设置为7(天),则计算用户流失预警日期(w)的公式如下:
当p-ad- pd ≤0时:
w= ad
如790号用户的流失预警期为数据分析完成之日,即9月20日。
当p-ad- pd >0时:
w=p- pd
如279号用户的最后登录时间为2021年8月9日,剩余生存时间为272天,则p等于2022年5月8日,流失预警之日为2022年5月1日。
6 结语
本研究采用Kaplan-Meier、COX对用户整体流失风险变化趋势、用户访问行为与用户流失概率之间的变化情况,揭示了电子资源用户流失变化规律, 可及时发现用户对校外访问系统电子资源黏性降低时的行为表征,并在此基础上显现濒临流失用户,不仅在生存函数的基础上进一步拓展了关于预测用户流失的研究,填补了该研究领域的空白,具有较好的可行性及普及推广价值,还能从用户整体和个体两个层面有效发现电子资源用户濒临流失的预兆,为及时改进与完善图书馆电子资源服务工作提供参考依据。然而,本研究还存在诸多不足:其一,实证研究的对象较为单一,方法可能存在缺陷,在今后的研究中应根据具体情况适当的扩大研究范围。其二,在本研究的基础上,尚需过滤出濒临流失用户,进一步挖掘出导致其可能流失的真正原因。其三,在判断用户濒临流失的标准方面,尚未经过实践反复复检验,后期需采集用户主观数据并结合经验来进行多角度的综合分析及判断。这些探索点将是笔者后续努力研究的方向。
参考文献
孔青青.科研人员电子资源需求调查分析[J].图书情报工作,2016,60(10):47-54.
吴汉华,王波.文献2020年中国高校图书馆基本统计数据报告[J]. 大学图书馆学报,2021,39(4):5-7.
零客户流失:服务业的质量革命[EB/OL].[2021-10-04].https://wenku.baidu.com/view/38f0e71275232f60ddccda38376baf1ffc4fe38d.html.
《数学辞海》编辑委员会.数据辞海:第四卷[M].太原:山西教育出版社,2002.8.
KEAVENEY S M,PARTHASARATHY M.Journal of the Academy of Marketing Science [J].2001,29(4):374-390.
陈静,余建波,李艳冰.基于随机森林的用户流失预警研究[J].精密制造与自动化,2021(2):21-24,51.
贺芳.基于用户细分的微博社区用户流失预测研究[J].情报探索,2018(12):21-27.
王若佳,严承希,郭凤英,等.基于用户画像的在线健康社区用户流失预测研究[J].数据分析与知识发现, 2022(Z1):1-16.
JIANG Z, FITZGERALD S R, WALKER K W. Modeling time-to-trigger in library demand-driven acquisitions via survival analysis[J]. Library & Information Science Research, 2019, 41(3): 100968.
朱世琴,蒋辛未.基于CSSCI的人文社科期刊文献老化风险率研究[J].情报学报,2017,36(10):1031-1037.
刘智锋,李信.作者关键词生存分析:以国内图情领域为例[J].图书馆杂志,2020,39(7):48-57.
孙佳佳,李雅静.基于关键词价值细分的高价值热点主题识别方法研究[J].情报学报,2022,41(2):118-129.
赖院根,刘敏健,王星.网络环境下的信息用户流失分析[J].情报科学,2011,29(11):1736-1741.
赖院根,刘砺利.基于生存分析的信息用户流失研究与实证[J].情报杂志,2011,30(4):129-132,171.
程学旗,梅宏,赵伟,等.数据科学与计算智能:内涵、范式与机遇[J].中国科学院院刊,2020,35(12):1470-1481.
陈志伟.大数据方法论的新特征及其哲学反思[J].湖南师范大学社会科学学报,2020,49(1):24-31.
数据相关性[EB/OL].[2022-04-04].https://baike.so.com/doc/26482622-27741494.html.
Cox回归生存分析[EB/OL].[2021-09-01].https://www.jianshu.com/p/e80eb4168043.
刘桂琴,许新华.基于机器学习的图书馆用户流失影响因素研讨[J].新世纪图书馆,2020(1):9-13.
Prediction on censored subjects[EB/OL].[2021-09-01].https://lifelines.readthedocs.io/en/latest/Survival%20Regression.html#prediction-on-censored-subjects.
刁羽,薛红.高校图书馆用户校外访问系统电子资源满意度画像研究:基于小数据的视角[J].图书馆工作与研究,2021(9):76-83.
刁羽,贺意林.用户访问电子资源行为数据的获取研究:基于创文图书馆电子资源综合管理与利用系统[J].图书馆学研究,2020(3):40-47.
How the concordance index is calculated in Cox model if the actual event times are not predicted? [EB/OL].[2021-09-01].https://stats.stackexchange.com/questions/478294/how-the-concordance-index-is-calculated-in-cox-model-if-the-actual-event-times-a/478305#478305.
董堅峰. 经济不发达地区公共图书馆用户稳定机制研究[J]. 现代情报,2012,32(5):25-29.
