
基于深度学习的指针式仪表的读数检测方法
2023-07-29 11:00陈凯迪
自动化与仪表 2023年7期
虞 健,陈凯迪,施 展,孔 明
(1.中国计量大学 计量测试工程学院,杭州 310000;2.芋头科技(杭州)有限公司,杭州 310000)
已有的指针式仪表的读数检测方法一般是先通过仪表的结构化特征,使用特征提取及匹配的方式进行仪表检测和定位[1],例如包括使用Hough圆形检测[2]、模板匹配[3]、特征点匹配[4]等方法来检测图像中的仪表位置,随后通过旋转角度法[5]、Hough直线检测[6]、帧差剪影法[7]等方法检测仪表中的指针位置,最后通过角度法或距离法[8],计算指针在两个已知刻度位置之间的角度之比或距离之比来获得指针式仪表的读数。这些方法中,通常需要对图像进行预处理,例如需要考虑待测仪表的倾斜角度[5]进行透视变换。如果通过深度学习模型获得替换上述的步骤[9-11],由于指针式仪表结构不标准,对于训练模型所需的数据量要求较高。另外,通过角度法或距离法计算指针式仪表的读数是通过仪表图像中的角度或距离信息来计算读数,会受到仪表图像拍摄角度而引起的圆形仪表盘变形以及因为指针投影到表盘上的位置差异而导致的读数偏差。
因此,本文提出了一种新的算法框架,通过将指针式仪表读数检测拆分为仪表检测、语义分割、读数回归3 个基于深度学习的步骤,利用小规模的标注数据量,快速、准确地实现对不同拍摄角度下对指针式仪表图像进行读数检测。
1 仪表读数的算法框架
本文算法框架的流程如图1 所示。首先对仪表的图像进行目标检测,并对检测后的图像进行语义分割,从而得到仅包含刻度和指针信息的分割图像,最后基于分割图像进行指针读数的回归,得到仪表读数。在仪表检测和语义分割过程中,采用YOLOv5-s 网络模型和Unet 网络模型对实验数据进行训练。

图1 算法流程Fig.1 Flow chart of algorithm
对于读数回归模型结构根据指针式仪表识别任务的特点进行了优化。具体地,由于需要输出范围为0~100 之间的仪表读数,因此读数回归过程中,基于仪表读数回归任务对标准的Resnet18 模型进行了调整。在输出层上,将标准的Resnet18 最后的全连接层的输出结果修改为一维数据,并采用Sigmoid 函数将输出的数据的值范围约束在0~100 之间,以对应仪表读数的区间。在模型训练使用的损失函数上,将用于多分类任务的CrossEntropyLoss 修改为MSELoss,以适应仪表读数的线性输出结果;使用Adam 优化器,以动态调整训练过程中的学习率。在本文中,将调整后的Resnet18 称为Resnet18-CNN 模型。
2 实验过程和结果讨论
2.1 实验平台和所用设备
训练神经网络的服务器的硬件配置包括Intel(R)Xeon(R)Gold 6342 处理器、内存256 GB、Nvidia A100 显卡,操作系统为Ubuntu 18.04,深度学习框架为Pytorch 1.12。
实验用的指针式仪表主要选择敞梦仪表有限公司生产的0~100 ℃的指针式的温度计仪表,可以通过温度控制方便的获得不同指针位置的仪表图像。
实验用的图像数据使用红米K30 Pro 5G 手机的摄像模式拍摄,视频分辨率为1920×1080。采用帧提取的方式从视频图像中提取图像。
2.2 数据准备
2.2.1 仪表检测数据集
仪表检测的训练数据集采用百度飞浆的开源项目提供的数据集(以下简称数据集1),其中共有标记好的训练集仪表图片725 张,验证集仪表图片58 张,其中包括单仪表、多仪表以及无仪表的干扰图像场景。将其标注方式转换为适合YOLOv5 模型的数据结构。
2.2.2 仪表语义分割数据集
通过控制温度计仪表下端探头的接触温度,手工采集了不同指针位置的仪表图像,其中包括每间隔1 单位、0~100 单位范围的101 张原始数据,并使用数据增强的方式扩大到2424 张(以下简称数据集2)。数据增强的方法使用了Python 的第三方库imgaug 提供的方法,包括:像素点丢失(Dropout)、缩放、仿射变换、对比度调整、锐化、扭曲平滑方式中的随机一种或多种。如图2 所示,在对数据的标签进行标注时,将整个指针作为一个类别进行标注,将所有刻度条所围成了的环状区域作为一个类别标注。

图2 仪表语义分割数据集示例Fig.2 Examples of data for meter segmentation
2.2.3 仪表读数回归数据集
仪表读数回归数据集采用的是将数据集2 中的原始数据通过语义分割模型生成的灰度的分割图像作为回归数据集里面的图像数据,并将图像所对应的实际读数作为数据标签,并处理为Pytorch框架中Dataset 数据类型。
由于读数回归是从仪表的结构特征中获取指针式仪表的读数值,为了避免对数据预处理过程中的分辨率调整导致仪表图像产生畸变,影响最终结果,在对数据集的预处理中,加入了对图像数据进行了Padding(填充)处理以获得正方形的图片,随后再对Padding 后的正方形图像进行缩放,以得到适合神经网络处理的图片尺寸大小。在本文使用的Resnet18-CNN 模型中,采用224×224 分辨率的图片作为模型的输入。
2.3 使用YOLOv5s 进行仪表检测
训练过程中,将Batch Size(批数量)设定为4,Epoch(迭代次数)设定为50,图像的分辨率设定为640。在判断网络的训练结果的时候,采用mAP 对模型进行评估,mAP 为平均精度的简称,其主要代表是在不同的IOU(交叠率)阈值下,物体检测的准确率。例如mAP_0.5-0.95 指在IOU 从0.5~0.95 之间的平均精度;如果mAP_0.5-0.95 越大,则代表该模型训练结果的准确率越高。
基于数据集1 的训练结果如图3 所示,可以看到训练集的训练损失函数随着Epoch 增加而不断下降,证明模型成功收敛。同时mAP_0.5:0.95 随着训练的Epoch 增加也提升,证明模型的识别准确率不断提升。而mAP_0.5:0.95 则在40 个Epoch 时候稳定在0.995,说明40 个Epoch 之后模型已经达到最优状态。
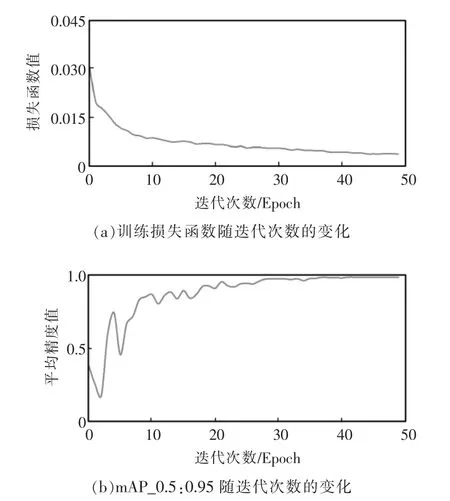
图3 YOLOv5 训练结果Fig.3 Training result of YOLOv5
2.4 使用Unet 进行仪表的语义分割
在进行Unet 模型的训练过程中,将Batch Size设置为1,Epoch 设定为20。在判断Unet 网络的训练结果的时候,采用Validation Dice(验证骰)对模型进行评估,Validation Dice 是用来评价语义分割任务的常用参数,其意义是分割区域和真值区域之间重合面积的2 倍和这两个区域的面积之和的比值,如果Validation Dice 越大,则模型对图像的语义分割的准确性约高,当Validation Dice 为1 的时候,则表示是分割后的图像和真值完全重合。
针对数据集2 的训练结果如图4 所示,从图4(a)可以看到,当训练开始之后,Validation Dice 迅速上升,当第5 个Epoch 后,整个模型的Validation Dice 数值为0.97,已经接近1;从图4(b)训练的损失函数也可以看到在第5 个Epoch 后,Loss 已经接近于0,证明模型已经收敛且分割的效果较好。

图4 Unet 训练结果Fig.4 Training result of Unet
2.5 使用Resnet18-CNN 进行仪表读数检测
在使用Resnet18-CNN 进行训练的时候,将Batch Size 设定为8,Epoch 设定为100,将数据集的80%作为训练集,20%作为测试集。在每个Epoch 结束之后对测试集进行一次推理计算,并将测试集中所有图像数据的推理结果和真值之间差做平均,得到均值偏差。以均值偏差来判断模型的识别准确率,即均值偏差越低,认为模型的准确性越高。
训练集的训练结果如图5 所示。从图5(a)可以看到随着Epoch 增加,损失函数呈现出下降的趋势,在达到80 个Epoch 时,损失函数的波动趋于稳定,并在1 附近跳动,证明模型已经收敛;从图5(b)可以看到均值偏差也随着训练的过程逐渐降低,尽管在训练初期,均值偏差偶尔有较大的波动,但是在80 个Epoch 之后,其主要在0.6 左右波动,选取了均值偏差最低的点0.48 作为最佳模型参数,来进行结果验证。

图5 Resnet18-CNN 模型的训练结果Fig.5 Training result of Resnet18-CNN model
3 实验研究
另行拍摄了不同角度的仪表的数据对上述方法训练的模型进行验证。如图6 所示,其中包括通过YOLOv5 模型检测出来的指针式仪表的正面拍摄图片、左侧拍摄图片和右侧拍摄图片。将通过YOLOv5 模型检测到的仪表图像送入训练好的Unet模型之后,获得仪表的分割图像如图6 第2 行所示,可以看到正面拍摄图片的分割结果基本完美,指针和刻度都得到了准确的分割,而左侧拍摄图片和右侧拍摄图片的指针中心位置有一些信息丢失,但是刻度线基本做到了准确的分割。将分割后的图片送入ResNet18-CNN 模型后,即可得到相应的仪表读数。

图6 对于Unet 的验证结果Fig.6 Demonstration result of Unet
作为对比,在使用Unet 分割后的图像的基础上,模拟了文献[11]上的距离法来获得仪表读数,使用指针附近的2 个已知标记刻度的位置和使用Hough 直线法检测出来的指针位置,使用2 个刻度点到指针直线的距离之比来计算读数。选取了2 个读数值在不同角度拍摄的7 个仪表图像样本,将Resnet18-CNN 模型输出结果、距离法输出的结果和肉眼人工读数结果进行比较,如表1 所示。可以看出,由于图片拍摄角度的不同,因为指针投影在刻度平面上的位置产生偏差,导致人工读数会产生约1 个刻度左右的读数偏差。相比于人工读数和距离法读数的结果,通过本文的ResNet18-CNN 回归模型的读数结果的读数偏差更小。

表1 本方法读数和距离法读数、人工读数的结果比较Tab.1 Comparison of results of this method with the distance method reading and manual reading
由于分割后的图形仅保留了指针读数相关的结构特征,使用深度神经网络从分割好的仪表图像中直接进行读数回归,因此相比于直接从原始图像回归出读数[9-10],本方法读数回归模型训练的模型复杂度降低、且训练所需要的人工标注的数据量可以大大减少。由于摄像机拍摄角度、指针式仪表安装位置的影响,采集到的表盘图像通常具有一定的倾斜角度,这会影响读数的精确度,因此传统的方法需要对图像中的表盘先进行旋转校正,以提高读数的精确度。通过本方法的Resnet18-CNN 模型,无需对于图像进行预先旋转矫正,即可以得到比较准确的结果。对此,认为可能的原因是在Resnet18-CNN 的训练过程中,对训练数据的数据增强包括随机的仿射变换,因此模型在训练过程中已经对于不同仿射变换的图像进行了学习。
4 结语
本文设计了一种基于深度学习的指针式仪表识别方法。该方法的优势在于,图像无需额外预处理的情况下,可以在较少数据量的情况下,通过3个神经网络处理步骤可以获得准确的指针式仪表读数结果,特别是针对语义分割和读数回归的模块,仅使用了101 张人工标注的数据。针对测试数据,通过本方法得到的指针仪表读数结果和人工读数以及距离法读数相比,对于不同角度拍摄的仪表独享的读数偏差更低。进一步,由于本方法通过语义分割后的仪表图像进行读数回归,而无需具体检测仪表中的指针位置和刻度信息,如果在模型训练中增加不同的仪表数据,本方法将可适用于不同种类仪表的读数检测。
猜你喜欢
青海草业(2022年2期)2022-07-23
计算机应用(2021年4期)2021-04-20
中国公路(2017年19期)2018-01-23
中国公路(2017年15期)2017-10-16
广东第二课堂·小学(2017年9期)2017-09-28
中国公路(2017年9期)2017-07-25
中国公路(2017年7期)2017-07-24
电测与仪表(2015年5期)2015-04-09
黑龙江科学(2015年11期)2015-03-27
电测与仪表(2014年18期)2014-04-04
