
基于听觉特性和发声特性的语种识别
2023-08-20 05:30华英杰邵玉斌
云南大学学报(自然科学版) 2023年4期
华英杰,朵 琳,刘 晶,邵玉斌
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
语种识别(Language Identification,LID)是通过计算机判断某段未知语音的所属类别,是跨语言智能语音处理系统的前端[1],其被广泛应用于各种实际场景,如:国际会议、军事监听、出国旅游等.目前,语种识别技术在无噪环境和长语音上已经达到工业水准,但是在嘈杂环境、短语音和高度混淆语种等情况下,识别性能依然不佳.
传统的语种识别主要基于声学特征和音素层特征.底层声学特征主要包括感知线性预测系数(Perceptual Linear Predictive,PLP)[2]、梅尔频率倒谱系数(Mel-frequency Cepstral Coefficient,MFCC)[3]、伽玛通频率倒谱系数(Gammatone Frequency Cepstrum Coefficient,GFCC)[4]、对数Mel 尺度滤波器能量(Log Mel-Scale Filter Bank Energies,Fbank)[5]等.目前主流的语种识别模式主要是支持向量机(Support Vector Machines,SVM)[6]和混合高斯模型−全局背景模型(Gaussian Mixture Model-Universal Back-ground Model,GMM-UBM)[7]等.基于音素层特征主要解决的是不同语种的不同音素集合问题.其主流模型包括并行音素识别器后接语言模型(Parallel Phone Recognition followed by Language Modeling,PPRLM)[8]等.
由于神经网络的快速发展,越来越多的研究倾向于将神经网络模型应用于语种识别中,主要包括卷积神经网络、深度神经网络和循环神经网络等.与传统的语种识别模型相比,取得了更高的识别准确率.Montavon[9]将含有时域和频域信息的语谱图作为卷积神经网络的输入,获得高于声学特征的识别准确率.Jiang 等[10]通过深度神经网络较强的特征提取能力,在i-vector 语种识别方法上引入深瓶颈层特征方法,该特征在面对大量的语料信息时,尤其是对于实时性要求比较高的语种识别任务时,实用性较好.Lopez-Moreno 等[11]利用特征提取、特征变换以及分类器融合在一个神经网络模型中,提出一种端到端的语种识别模型.Geng 等[12]将注意力机制模型引入到语种识别的模型中,并取得了较大的性能提升.Watanabe 等[13]提出一种基于语种无关架构的端到端模型处理多语种识别的问题.Cai 等[14]利用底层声学特征直接学习语种类别信息,提出一种基于可学习的字典编码层的端对端系统,使得语种识别性能得到提升.Snyder等[15]提出了X-vector 方法,将不定长度的语音片段应用在时延神经网络映射到固定维度的embedding 中,这个embedding 便称作X-vector,相比基于I-vector 方法,在短时语音识别取得了更好的效果.Jin 等[16]提出了从网络中间层获取语种区分性的基本单元特征.Bhanja 等[17]利用色度特征与MFCC 特征融合,使得语种识别性能得到很大的提高,但计算量增大.Garain 等[18]利用底层声学特征将其转化为图像信息,放入到卷积神经网络中进行识别,此方法鲁棒性能较差,特征表现形式单一.在时延神经网络基础上,韩玉蓉等[19]利用多头自注意力双支流Xvector 网络,使用多头自注意力机制替换池化层,增大了有效特征权重,并针对样本数不均衡及难分类问题引入类别权重因子和调制因子,使得训练模型的损失函数得到了改进.但上述方法在复杂噪声环境下,语种识别正确率较低.
针对在低信噪比环境下语种识别性能不佳问题,本文提出了一种结合人的听觉特性和发声特性的语种识别方法,在很大程度上提高了低信噪比环境下识别准确率.首先根据人耳听觉感知具有的非线性特点,引入耳蜗滤波器模拟听觉特性,并提取耳蜗倒谱系数(Cochlear Filer Cepstral Coefficents,CFCC)特征;再根据人的发声特性提取声道冲激响应频谱参数(Spectral Parameters of Channel Impulse Response,SCIR)特征,减少说话人信息的影响,增强语种信息;最后融合听觉特性和发声特性得到融合特征CFCC+SCIR 特征.测试结果表明,该特征在噪声环境下识别性能较高,具有一定的抗干扰性.
1 模型搭建
1.1 构建带噪语音模型带噪语音信号定义为x(n)=s(n)+w(n),其中,s(n)为原语音,w(n)为高斯白噪声,其均值为0,平均信噪比(Signal Noise Ratio,SNR)定义为:
1.2 GMM-UBM 语种识别模型采用混合高斯模型−全局背景模型(Gaussian Mixture Model-Universal Back-ground Model,GMM-UBM)作为语种识别后端,能够准确识别判断出不同语言在共同背景环境之间的区别,具有较高的鲁棒性,并且在训练集数据量少的环境下能够得到高混合度的模型.基于GMM-UBM 的语种识别模型框架如图2 所示.该模型先对输入的M种语种背景语音分别进行听觉特征提取和发声特征提取,将两种特征进行融合,输入到UBM 模型进行训练;再对目标语音也分别提取听觉特征和发声特征后进行特征融合;然后输入到GMM 模型进行训练.训练完后将UBM 训练得到的公共模型与GMM 训练得到的语种模型通过模型自适应得到K种语种模型,根据测试语种与语种模型对比结果判定语种.

图2 GMM-UBM 语种识别模型框架Fig.2 The model framework of GMM-UBM language recognition
2 语种特征提取及融合
特征提取是语种识别中非常关键的步骤之一,特征的鲁棒性高低与否以及能否高效区分语种都对后期语种识别性能有着关键的影响.本文提出的基于听觉特性和发声特性的融合特征提取流程如下:首先提取耳蜗倒谱系数特征,再提取声道冲激响应频谱参数特征,最后从帧级别的角度进行特征融合,得到融合特征集.具体流程如图3 所示.
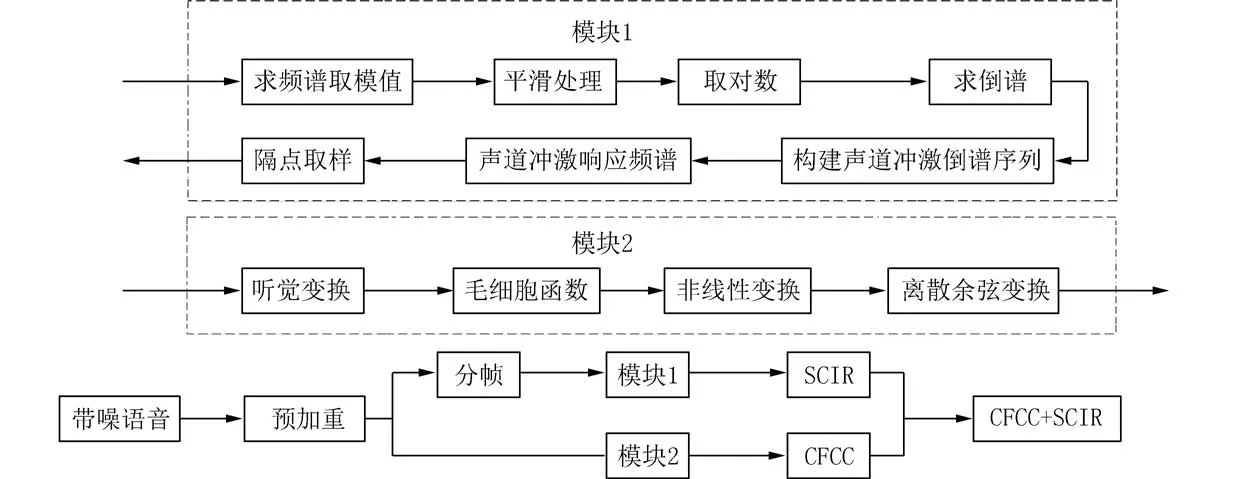
图3 特征提取流程图Fig.3 The flowchart of feature extraction
2.1 基于听觉特性的语种特征提取人耳对声音的敏感度主要受声音的方位、响度、音调及音色等因素的影响.对于细微的声音,只增加响度,人耳便可以感受到,但当响度增大到某一值后,再增大响度人耳听觉却没有明显的变化.因此将人耳受响度因素影响的这一听觉特性定义为“非线性”特性.CFCC 可以很好地模拟了人耳听觉这一特性.CFCC 特征参数提取过程主要包括听觉变换、毛细胞函数、非线性变换和离散余弦变换[20].听觉变换是利用小波变换实现滤波的,能够很好地实现人耳窝听觉感知的非线性结构.首先定义一个耳蜗滤波函数 ξ(n)∈L2(R),要求 ξ(n)满足下面4 个公式.

图1 不同信噪比下的语音局部波形图Fig.1 Partial waveforms of speech under different signal-to-noise ratios
式中:ξ(n)为定义的耳蜗滤波函数,C为任意正数.并假设z(n)为任意一个平方可积的语音信号函数,经过听觉变换输出为:
式中:ξa,b(n)为耳蜗滤波函数,其表达式见公式(7).
式中:α>0,β>0,α和 β的取值决定了耳蜗滤波函数的频域形状和宽度,这里取经验值 α=3,β=0.2.u(n) 为单位步进函数,b为随时间可变的实数,a为尺度变量,θ为初始相位.在一般情况下,a可由滤波器组的中心频率fC和最低中心频率fL决定,即:
将式(7)代入(6)即可得到z(n)经听觉变换的输出T(a,b).毛细胞函数可以将耳蜗的内毛细胞经听觉变换输出后的语音信号转变为人脑可分析的电信号,其模拟过程表达式为:
式中:d=max{3.5τi,20 ms},d是第i频带毛细胞函数的窗长;τi是第i个滤波器中心频带中心频率的时间长度,τi=1/fC;L为帧移,一般情况下,取L=d/2;j是窗的个数.
将式(10)的输出S(i,j)再次进行响度函数的尺度变换.文献[20]采用非线性幂函数变换,利用
进行模拟.非线性幂函数可粗略近似为听觉神经元发放率−强度曲线,且非线性幂函数的特性与人耳听觉相符,即输出的动态特性不完全取决于输入量的幅度.最终利用离散余弦变换对y(i,j)进行去相关性得到 15×j维的特征矩阵Y,得出CFCC 特征参数.
2.2 基于发声特性的语种特征提取在整个发声系统中主要包含两种参数模型,即声门激励脉冲频谱(激励模型)和声道冲激响应频谱(声道模型)[21].声道是由声道的气管控制的,属于分布参数系统,可以看作是谐振腔,包含很多谐振频率.谐振频率是由每一瞬间的声道外形决定的,这些谐振频率称为共振频率,是声道的重要声学特性.SCIR 特征还包含元音和发声方式等语种信息,因此可以将其作为语种特征.SCIR 特征参数提取过程具体步骤如下:
步骤 1对x(n)进行预加重处理,提升信号的高频部分,得到z(n).
步骤 2对z(n) 进行分帧处理,帧长 ∂=256,帧移 ε=128,对于分帧后得到j帧信号,第i帧的信号为zi(n).
步骤 3对每一帧信号zi(n)进行离散傅里叶变换得到zi(k),并对zi(k)每个数据取模得到ui(k).
步骤 4根据Savitzky-Golay 滤波器原理,利用每个窗口上拟合的二次多项式对数据进行平滑处理,使之减少语音噪声以及频谱突变的影响.在最大限度地保留语音特征的条件下对噪声进行抑制,平滑处理后的信号为:
式中:h(η)为平滑滤波器的抽样响应;M为平滑处理窗口长度的一半,由实验结果证实,当M=5时,效果较好.
步骤 5对yi(k)取对数,更好地描述听觉系统:
步骤 6对si(k)进行逆离散傅里叶变换处理,即取倒谱,目的是将声门激励脉冲和声道冲激响应更好有效分离,求倒谱后得到ci(n).
步骤 7因为倒谱具有对称性的特点,所以将倒谱中的第30 条谱线为界进行划分.因此1~30和227~256 区间构成声道冲激响应倒谱序列:
式中:gi(n)为声道冲激响应倒谱序列,其构建的长度为256.
步骤 8对gi(n)进行离散傅里叶变换,然后取实数部分.由于两边是对称性的,因此可以只取前半部分,得到声道冲激响应频谱ri(k).
步骤 9对ri(k)取样,由实验可得间隔点个数C=6,为了使训练的数据量少且大量语种信息不被破坏,故加快训练速度和识别速度,得到 22×1的第i帧取样后的SCIR 特征向量,将每帧特征向量融合得到该段语音的 22×j维的特征矩阵G:
式中:D为最后一个取样点对应ri(k)中的位置.
2.3 基于听觉和发声特性的语种特征融合CFCC 特征只模拟了听觉特性,并没有进行说话人信息的抑制,说话人信息属于干扰信息,而SCIR特征可以有效地抑制说话人信息的干扰,但是无法很好地反映人耳听觉特性及语音信息.因此为了得到抗干扰性能更佳的语种特征集,本文提出将包含听觉特性的特征CFCC 和包含发声特性的特征SCIR 融合得到新的特征集CFCC+SCIR.在提取CFCC 特征的基础上,加入反映不同语种的发声方式和声道形态上存在差异的SICR 特征.融合特征既模拟了人耳的听觉特性又包含了不同语种的发声特性,还在一定程度上抑制了说话人信息和噪声信息的干扰,可以更好地表示不同语种的本质特征,具有更好的鲁棒性.
本文从帧级别的角度进行特征融合,将15 维的CFCC 特征矩阵G和22 维的SCIR 特征矩阵Y特征进行融合,融合公式如下:
式中:R为 37×j维的融合特征矩阵CFCC+SCIR.
3 实验结果与分析
本研究采用的数据集来自中国国际广播电台的广播音频语料库,音频经过人工处理,剔除了干扰因素,为采样率f=8 000 Hz、时长t=10 s的单通道的语音段.包括汉语、藏语、维吾尔语、英语、哈萨克斯坦语等5 种语种.训练集采用的语种数目K=5,每种语种300 条,其中50 条为纯净语音,其他250 条分别与白噪声构建 SNR=[5 ∼25]dB的带噪语音.测试集每种语种171 条,分别与白噪声构建形成 SNR=[−5,0,5,10]dB的4 种带噪测试语料库.UBM 自适应模型采用的语种数目随机,只要该数据为广播数据即可,选取1 675 条随机广播音频.采用识别正确率作为评价指标,计算公式如下:
式中:Ah、Az、Aw、Ay、As为每种语种识别正确数,N为总识别数,R为平均识别正确率.
3.1 GMM-UBM 模型混合度实验本文选用13维静态CFCC 特征参数,分别对16、32、64、128等4 种不同混合度进行训练测试.不同混合度的GMM-UBM 模型的识别正确率如表1 所示.

表1 不同混合度的GMM-UBM 模型识别正确率Tab.1 Recognition accuracy of GMM-UBM models with different mixture degrees %
从表1 可知,在−5 dB 和0 dB 下识别性能没有太大的差别,识别性能都不佳.在5 dB 和10 dB 下混合度在64 时识别性能最佳,但是只比混合度为32 时分别提高0.6 和0.3 个百分点,然而训练识别时间却多出1 倍.因此,综合考虑本文的模型混合度设为32.
3.2 基于听觉特性的语种识别实验本文设计4组实验,实验1~3 为对比实验,实验4 为本文提出基于听觉特性的识别方法.在背景噪声为白噪声的环境下,分别验证不同信噪比下所提出的语种识别方法的有效性及性能,并分析其优劣的原因.实验1~4 分别提取64 维对数Mel 尺度滤波器能量(Fbank)[5]、13 维静态MFCC[3]、13 维静态GFCC[4]、15 维CFCC 特征作为语种特征,实验结果如表2 所示.
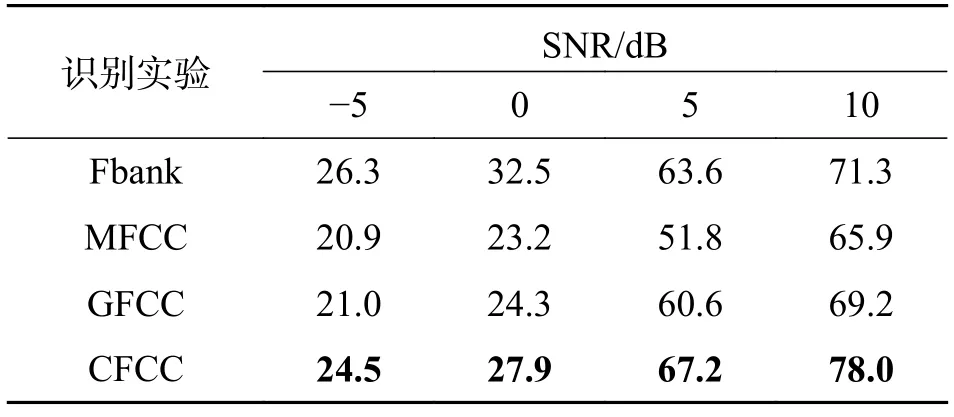
表2 基于听觉特性的语种识别正确率Tab.2 Correct rate of language recognition based on auditory characteristics %
从表2 可以看出,与常见的MFCC 特征和GFCC 特征相比,本文提出的CFCC 特征在识别性能上具有明显的优势.相对于GFCC 特征,4 种信噪比下分别提升了3.5、3.6、6.6 和8.8 个百分点.由于CFCC 特征采用的是非线性幂函数,可以更好地模拟听觉神经元发放率,而且CFCC 特征是基于耳蜗滤波器的听觉变换特征,更好地模拟了人的听觉特性.与Fbank 特征相比,CFCC 特征在5 dB 和10 dB 下识别性能更好,在−5 dB 和0 dB 下识别性能有所下降.由于Fbank 特征采用的是残差神经网络模型进行训练识别,对噪声具有一定的抑制作用,但是在高信噪比下,CFCC 特征的优势就更加明显,在5 dB 和10 dB 下分别提升了3.6 和6.7 个百分点.
3.3 基于听觉特性和发声特性的语种识别实验从表2 可知本文提出的CFCC 特征具有在高信噪比下具有明显优势,在低信噪比下依然性能不佳.因此本文基于人的听觉特性和发声特性出发,提出了融合两种特性的融合特征集(CFCC+SCIR).下面设计的4 组实验,实验1~3 为对比实验,实验4为本文提出的融合特征实验.分别验证不同信噪比下,本文提出的基于听觉特性和发声特性的语种识别方法的有效性及其优劣的原因.实验1~4 分别提取64 维Fbank、13 维S-GFCC+PCA[22]、22 维SCIR[21]、37 维CFCC+SCIR 特征作为语种特征,实验结果如表3 所示.

表3 基于听觉特性和发声特性的语种识别正确率Tab.3 Correct rate of language recognition based on auditory and vocal characteristics %
从表3 可以看出,本文提出CFCC+SCIR 特征具有明显优势.相对于采用深度学习的Fbank 特征,在4 种信噪比下分别提升了12.3、26.6、14.1 和11.2 个百分点.由于CFCC+SCIR 特征从人的发声和听觉进行出发,具有一定的抗干扰能力.与SCIR 特征相比,也在性能上具有一定的提升,由于SCIR 特征只研究了人的发声特性,而CFCC+SCIR 特征还结合了人的听觉特性.与S-GFCC+PCA 特征相比,CFCC+SCIR 特征在0 dB 和5 dB上提升明显,分别提升了9.8 和8.1 个百分点.
3.4 不同语种识别方法的平均识别正确率从平均识别正确率对比本文方法的优势,不同方法的平均识别正确率如图4 所示.平均识别正确率的定义如下:

图4 不同方法的平均识别正确率Fig.4 Average recognition accuracy of different methods
式中:R−5dB、R0dB、R5dB、R10dB分别是不同信噪比下的识别正确率,Ra是4 种信噪比下的平均识别正确率.
从图4 可以看出,4 种信噪比下,MFCC 特征识别性能最差,CFCC+SCIR 特征识别性能最佳.相对于Fbank 特征、MFCC 特征、GFCC 特征、SGFCC+PCA 特征、SCIR 特征分别提升了16.1、24、20.7、7.3 和9.8 个百分点.本文提出的方法很好地结合了人的听觉特性和发声特性,从而增强了特征的抗干扰能力.
4 总结
针对低信噪比环境下语种识别性能不佳,提出一种基于人耳的听觉特性和人的发声特性的语种识别方法.首先利用人的发声特性提取SCIR 特征,再模拟人耳的听觉特性提取CFCC 特征,从而得到最终的CFCC+SCIR 特征.从理论分析和仿真实验结果可以看出,本文提出的CFCC+SCIR 特征具有一定的抗噪性能,在4 种信噪比下明显优于其他方法.后续针对该方法在极低信噪比下识别性能不佳继续进行研究,并针对真实的噪声环境展开研究.
猜你喜欢
时代邮刊(2021年8期)2021-07-21
中华养生保健(2020年7期)2020-11-16
北京航空航天大学学报(2019年9期)2019-10-26
电子测试(2018年11期)2018-06-26
雷达学报(2017年3期)2018-01-19
疯狂英语(双语世界)(2017年3期)2018-01-19
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
西南石油大学学报(自然科学版)(2015年5期)2015-04-16
