
近三年档案资源语义化开发研究热点与前沿探测
2023-09-04 01:25宋雪雁张祥青张伟民
档案管理 2023年4期
宋雪雁 张祥青 张伟民

摘 要:本文对近三年国内外档案资源语义化开发研究热点与前沿进行了探测,通过高频关键词共现分析总结了国内外近三年档案资源语义化开发研究的相关主题,其中国内总结为档案保管与智慧建设、档案社会记忆建构与知识服务、档案语义转换与语义重组等6个研究主题,国外总结为基于本体的语义化开发等3个研究主题,同时基于高频关键词主题加权演进分析探测了研究热点与前沿。此外,本文对该领域相关平台项目实践研究进行了梳理,并基于以上研究,对国内外档案资源语义化开发的对象、目标、技术方法等内容进行了归纳总结。
关键词:档案资源;语义;本体;知识图谱;知识组织
Abstract: This article explores the hot spots and frontiers of research on the semantic development of archival resources both at home and abroad in the past three years. Through high-frequency keyword co-occurrence analysis, it summarizes the relevant topics of research on the semantic development of archival resources both at home and abroad in the past three years, including six research topics summarized domestically, including archival custody and intelligence construction, archival social memory construction and knowledge services, archival semantic transformation and semantic reorganization. There are three research topics summarized abroad, including ontology based semantic development. And through weighted evolution analysis based on high-frequency keyword topics this paper also studies research hotspots and frontiers. In addition, this article reviews the practical research on relevant platform projects in this field, and based on the above research, summarizes the objects, objectives, technical methods, and other contents of semantic development of archive resources at home and abroad.
Keywords: Archival resource; Semantic; Ontology; Knowledge map; Knowledge organization
要对档案资源语义化开发研究有整体的理解与掌握,首先需要理解档案语义的含义与概念。冯惠玲等[1]指出档案语义是指所有档案本身的数据和描述档案的数据含义,包括档案内容数据、背景数据以及结构数据的含义,与传统文本内容以及元数据的含义不同,档案的语义使用形式化的语言表达,含义明确且机器可理解。伴随技术的快速发展与更迭,大数据、深度学习等技术被广泛应用于档案资源语义化开发研究中,这促进了学者对该领域研究的逐渐深化。为发现与总结档案资源语义化开发中热点与前沿性内容,本文对近三年国内外档案资源语义化开发研究成果进行梳理,对该领域主要研究主题进行总结分析,发现该领域重点研究内容,以期为相关研究提供参考。
1 国内相关研究梳理
本研究以主题=“档案 AND 语义”或者篇关摘=“档案 AND 语义”为检索方式在中国知网、万方、维普数据库进行检索,检索时间限制在2019年8月31日—2022年8月31日,共获得近三年相关文献201篇。经过人工校对清理,将与主题不相符合的文献加以剔除,最终保留114篇相关文献进行分析。
1.1 中文文献关键词数据分析。中文文献关键词数据分析将從关键词词频统计、时间分布、高频关键词共现分析方面进行总结。
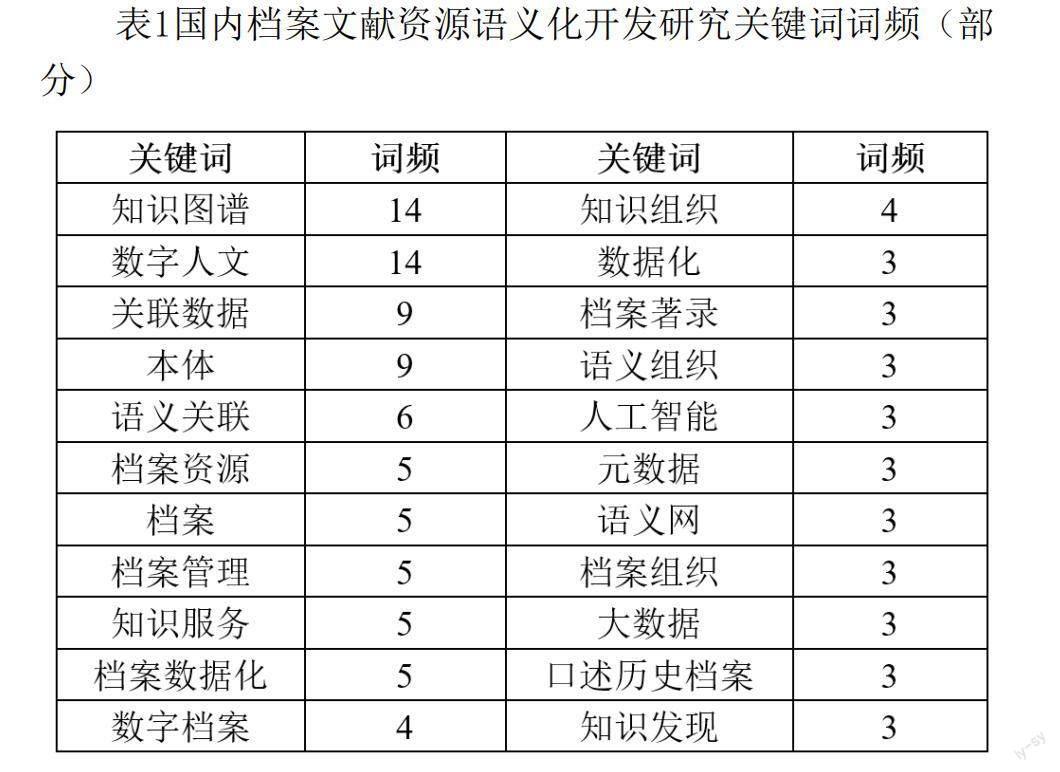
(1)中文关键词词频统计。对相关文献进行词频分析,其中出现频次≥2的关键词有52个,出现频次≥3的关键词有23个,现对部分关键词词频进行表格整理(表1),除了表1整理的数据,关键词清代在相关文献中出现的频次也为3。绘制的关键词词云图如图1所示。
由表1和图1可以看出,在档案资源语义化开发研究中,相较于其他关键词,知识图谱、数字人文、关联数据、本体、语义关联、档案数据化在文献中出现次数较多,说明知识图谱、关联数据以及本体等技术在档案资源语义化开发中得到了较多应用,并且学者对数字人文视域下档案资源语义化开发进行了较多研究,实现了档案资源的语义挖掘、关联与发现,推动了档案资源的智慧建设。
(2)中文关键词时间分布。本文对关键词进行分时段统计,每时段拟选取10个有代表性的关键词进行分析,选取依据首先为选取频次高的关键词,在频次相同的情况下,选择与该时段高频关键词密切相关联的关键词,以期对档案资源语义化开发研究有一个整体的了解与分析,统计如图2所示。
由图2可以看出,在2019年8月31日—2019年12月31日这一时段间,元数据、关联数据为高频关键词,频次为2,其余关键词频次皆为1。数字档案资源、档案信息资源等档案资源的语义化开发需要运用元数据、关联数据技术,实现档案资源的关联与共享,推动档案信息化进程,编码档案信息描述需要建构档案元数据体系。
此外,本体与元数据、关联数据紧密关联,运用这些技术方法可助力档案资源的语义转换,实现语义互操作,除了图谱显示的关键词,在该时段内,本文认为语义网也是与高频关键词关联数据相关联的关键词,语义网的构建需要以关联数据技术为基础,实现档案资源的语义互联。通过展示的关键词,可以看出学者在这一时段的研究有运用元数据、关联数据等技术方法对数字档案资源语义关联、语义转换探索,元数据、关联数据等技术方法的应用是这个时期的关注点。
在2020年相关文献中,知识图谱、档案管理、数字人文等8个关键词出现频次≥2,其余关键词出现1次。机器学习、大数据等技术方法可助力实现档案资源的智能管理。此外,在数字人文研究背景下,国内外部分高校开展了以档案为中心的数字人文项目研究,这推动了档案资源的语义化开发研究。因此,除了高频关键词,本文在剩余频次为1的关键词中选择“智能管理”“数字人文项目”作为这一时段的代表性关键词,如图2所示,可以看出这一年的研究成果中关于档案知识图谱的研究最多。知识图谱以图结构揭示语义信息,[2]以知识图谱的方式揭示档案语义信息是较为可行的方法。
另外,语义化开发视角下的档案管理、档案组织、电子文件管理研究也较多,学者基于数字人文理念,将机器学习、本体以及大数据等技术方法运用到档案领域语义知识挖掘与知识发现中。在2021年相关文献中,关联数据、数字人文、知识图谱、知识服务、本体、语义关联、知识组织7个关键词出现频次≥4,档案、数字档案、档案资源3个关键词出现3次,其余关键词频次小于3。通过图谱可以看出,前两个阶段的相关研究在这一年得到了延续和加强,学者的关注点也为基于数字人文视角,运用知识图谱、关联数据、本体等技术方法对档案知识组织进行研究,以期为用户提供更好的知识服务。
在2022年1月1日—2022年8月31日期间,知识图谱、数字人文关键词频次为4,口述历史档案、数字管护、档案数据化、清代、可视化、本体、档案资源、知识发现8个关键词出现2次,其余关键词频次为1。通过图谱可以看出,这一时段学者运用知识图谱、本体、可视化等技术方法对数字人文视域下的档案资源语义挖掘、揭示与知识发现进行了相关研究。
基于以上每时段关键词条形图可以看出,“本体”在统计的各个时段都有出现,体现了本体知识建模是档案资源语义化开发研究中必要且基础的技术,是档案学者掌握且能够成熟运用到档案资源语义化开发中的技术方法;“数字人文”“知识图谱”从2020年开始至统计时段结束都有出现,其中知识图谱技术受到学界较多关注与使用;元数据、关联数据也是学界较为关注的档案资源语义挖掘与组织技术,这呈现出档案学与计算机科学、信息哲学、历史学、语义学等多学科的交叉融合态势。
(3)中文关键词共现矩阵。由以上分析可知频次≥2的关键词有49个,频次≥3的关键词有23个,现对频次≥2的关键词进行了共现矩阵计算,并对频次≥3的23个关键词绘制了共现矩阵图(图3)。
其中,本体与关联数据共现3次,数字人文2次。关联数据与档案、知识组织、元数据、语义网共现2次。共现频次越高,说明关键词之间关联关系越突出,便于发现档案资源语义化开发相关研究文献中档案领域与其他理论、技术方法等内容具有交叉价值的知识点。除了以上列举的关键词数字人文、知识图谱、本体、关联数据与其他关键词的共现关系,其他关键词之间也有共现关系。
1.2 基于高频关键词共现的中文文献主题聚类分析。经过对频次≥2的49个关键词共现矩阵计算,可以发现关键词之间的共现关系。将共现矩阵导入VOSviewer软件,布局格式设置为Fractionalization,吸引力(Attraction)设置为5,排斥力(Repulsion)设置为0,最小聚类中关键词个数(Min. cluster size)设置为5,共得到7个聚类结果。根据关键词的共现关系回顾文献,发现聚类6下的关键词档案数据化、资源描述框架,聚类7下的记录因子、数据化、档案数据与档案数据化研究主题相关,聚类6下的关键词本体工程、电子文件管理、人工智能与聚类7下的领域本体、视频档案与档案领域本体构建研究主题相关,因此,根据关键词表达的主题与语义含义,本文将聚类6与聚类7合并为一个聚类进行主题概括与分析,最终聚类结果整理如表2所示。
基于表2的聚类结果,可以归纳近三年国内档案资源语义化开发研究中的主题方向。
(1)档案保管与智慧建设研究。聚类结果1包含智慧数据、档案保护、资源建设、语义增强、数字人文等10个关键词。对于档案保管方面,钱毅[3]总结了档案保护、保存、管护的目标分别为维系延续实体老化的物理空间、构建防范技术老化的数字空间、营造适应文化老化的语义空间,基于学者对档案保管体系理念演变的讨论与分析,可以帮助人们应对未知的档案管护问题。
牛力等[4]指出,在档案工作新形势下,构建从保管导向到价值导向的智慧档案2.0体系会成为未来趋势,由此可以发现,档案保管是推动档案智慧建设的重要基础。在档案智慧建设方面,郝伟斌等[5]指出应用语义网技术进行档案文化数据资源语义组织能构建知识本体之间的语义关系,实现档案资源智慧数据建设。曾蕾等[6]也认为语义技术使图博档数据纳入到智慧数据中,语义增强是一种使数据形成语义网的显著有效方法。
在档案资源知识语义开发中,本体作为一种语义技术得到了广泛应用,赵雪芹等[7]以芭蕉茶厂1973年第三件档案为例,使用Protégé軟件进行了可视化的构建,揭示类与类之间错综复杂的语义关联,此研究在一定程度上促进了数字人文领域下万里茶道档案资源智慧建设的研究。
(2)档案社会记忆建构与知识服务研究。聚类结果2包含语义分析、档案著录、口述历史档案、社会记忆建构、知识服务、知识发现等9个关键词。
对于档案社会记忆构建相关研究,房小可从档案编研和档案著录两个视角切入进行了相关论述。在档案编研方面,房小可[8]对档案学科视角下社会记忆构建框架进行了研究,指出语义分析、机器学习等技术能够提取拟订编研主题的子主题,帮助实现档案资源主题挖掘。在档案著录方面,房小可[9]指出在著录工具基础上加入语义分析等技术,能够获取档案社会记忆逻辑要素及其语义关系,实现记忆重构及再现。牛力等[10]对名人档案价值挖掘的理论及技术支持进行了研究,指出知识服务层次的实现为名人档案数据的记忆呈现。从已有研究可以发现,档案社会记忆建构能帮助实现更好的档案知识服务,帮助人文学者深入利用档案资源,挖掘档案资源中的记忆价值。对于档案知识服务相关的研究,周娟娟等[11]指出运用语义分析、知识图谱等技术,能够增强数据之间关联,促进人事档案知识服务研究发展。档案知识服务的发展与档案资源开发与利用、档案资源知识发现研究紧密关联。高淞等[12]指出利用RDF框架、语义网等数字技术进行资源开发,能够构建新的数字人文视域下的口述历史档案资源开发模式。邓君等[13]对口述历史档案资源知识图谱与多维知识发现进行了研究,实现了资源细粒度关联、语义化查询、个性化服务。
(3)档案语义转换与语义重组研究。聚类结果3包含关联数据、本体、互操作、大数据、知识组织、语义网、元数据7个关键词。通过关键词之间的共现关系回顾文献,发现学者在语义转换和语义重组方面进行了相关研究。在档案语义转换方面郭学敏等[14]指出关联数据在档案知识组织中发挥了重要作用,元数据元素集、值词汇表、数据集是语义转换的源数据,语义转换能加强语义融合与不同语义工具间的互操作,通过本体构建和语义匹配,档案数据可转换为关联数据。在档案语义重组方面,夏天等[15]认为面向知识服务进行档案语义化重组具有重要意义,指出语义网与关联数据在档案组织与档案数据语义重组方面的应用需要深化研究。从已有相关研究可以发现档案语义转换、档案数据关联、档案语义重组与档案知识服务之间存在着紧密的逻辑关联,其中档案语义转换将档案数据转换成关联数据,档案关联数据的应用实现了档案数据语义重组,档案语义重组有助于档案资源实现更优的知识服务。
(4)档案知识图谱构建与智慧转型研究。聚类结果4包含知识图谱、智慧化、档案服务、档案资源、机器学习、科研档案本体、清代7个关键词,其中知识图谱与档案服务、档案资源、机器学习、科研档案本体都有共现,将这些关键词的研究归纳为档案知识图谱构建研究,档案资源与智慧化共现,回顾文献,发现学者在档案智慧转型方面进行了相关研究。在档案知识图谱相关研究方面,宋雪雁等[16]基于《钦定大清会典图》和《皇朝礼器图式》构建清代祭祀礼器知识图谱,此研究在一定程度上促进了清代档案文献的数字化进程。向梦宇[17]探索了基于知识图谱的军工研究所档案知识服务实现方式和流程,通过信息抽取、知识融合、知识加工及知识更新,实现了档案资源结构化、网络化知识体系的构建。雷洁等[18]构建了计算机可识别、具有较强操作以及富含语义关系的科研档案知识图谱模型,实现了科研档案资源的揭示、组织和关联,促进了科研档案资源的集成、共享与利用。雷洁等[19]指出利用知识图谱、机器学习等语义技术对科研档案资源进行知识组织和表示,能够推动科研档案智能管理。在档案智慧转型研究方面,祁天娇等[20]指出档案资源的智慧化转型基本路径为“数字化—数据化—语义化—智慧化”,数字化过程包括扫描加工、案卷著录等工作,数据化过程包括OCR识别、内容级标签等工作,语义化过程包括语义识别、揭示、表达等工作,智慧化过程包括检索与可视化等。邓君等[21]指出知识图谱技术实现了口述历史档案资源关联聚合,完成了“数字化—数据化—智慧化”过渡。基于已有研究可以发现,档案知识图谱构建是档案智慧化转型的重要环节,帮助实现档案资源的可视化呈现与语义检索。
(5)档案语义关联与语义发现研究。聚类结果5包含档案、语义、语义组织、语义关联、档案馆、档案信息6个关键词。通过回顾文献,其中关键词档案、档案信息、语义、语义组织表示基于档案语义组织的档案发现研究,语义关联、档案馆共现,表示档案语义关联研究。档案语义关联与语义发现与档案组织密切相关。在档案语义组织方面,冯惠玲等[22]指出档案语义组织旨在从档案资源的内容、背景与结构数据中实现语义关联与语义发现。张斌等[23]指出以本体、关联数据和知识图谱为代表的知识组织与推理技术能够实现档案知识对象间的语义关联。周媛媛[24]构建了档案语义关联模型,指出语义关联可推动档案馆构建异构分散的馆藏资源语义关联关系,构建的语义关联模块主要功能是语义分析与提取、语义关联挖掘、跨媒体本体构建及跨媒体检索技术。
(6)档案数据化与领域本体相关研究。经过合并,聚类结果6包含档案数据化、本体工程、电子文件管理等10个关键词。档案数据化、数据化、档案数据都表示档案领域数据化研究,记录因子是档案数据研究中提出的概念。本体工程、领域本体表示档案领域本体研究,视频档案共现领域本体表示视频档案本体相关研究,档案领域本体的构建也有利于电子文件管理。在档案数据化、记录因子方面,赵生辉等学者研究较多。赵生辉等[25]提出了体现档案学特色的记录因子理论,指出记录因子可以划分为时间类、空间类、人物类等类型,“档案数据化”意味着档案管理的基本单元由粗粒度的文档转变为细粒度的记录因子,并指出档案数据化的主线实践模式是“档案领域本体建模”。赵生辉等[26]指出数据本质上是记录因子的结构化集合,记录因子是描述社会系统实体、属性、关系的通用框架,开展记录因子攻关,对推动国家层面档案数据资源中心协作网络规划建设具有建设性意义。在档案领域本体相关研究方面,吕元智[27]指出视频档案语义标准的任务是将各类视频档案知识资源在语义标注领域本体的作用下,转化为含有语义信息的、规范化的视频档案知识资源进行存储。赵生辉等[28]在分析电子文件管理中“文档态电子文件”管理技术瓶颈的基础上,提出了“档案领域數据本体”概念,是用来模拟和反映社会历史领域各类实体属性之间的语义关系及其运动变化过程的大规模关联数据集,这推动了人工智能时代档案信息服务智能化发展。
以上通过高频关键词聚类与关键词共现关系回顾文献发现学者对档案保管与智慧建设、档案社会记忆建构与知识服务等主题进行了相关研究,每个主题内部有着其内在的逻辑关联。以上主题是近三年档案语义化开发领域关注的重点与热点内容,档案保管是档案资源语义化开发的基础,语义化开发从最小粒度的知识单元——记录因子着手,学者通过知识图谱、领域本体的构建以及相关语义转换技术,对档案资源进行语义重组、语义关联与语义发现,重构档案社会记忆,最终实现档案资源的智慧建设、智慧转型,更好地为用户提供知识服务。
通过以上主题的梳理与分析,可以发现学者在该领域的研究呈现出技术牵引、具体对象实践、理论升华特征。对于技术环境的牵引与指导,可以发现在以上的主题研究中本体、关联数据、语义网等语义技术在实现档案资源的智慧建设、社会记忆建构、知识服务、语义关联、语义发现、语义重组中发挥着重要作用。在具体对象实践方面,学者们以万里茶道档案资源、清代祭祀礼器、口述历史档案资源、科研档案为研究对象,进行了可视化、知识图谱构建相关研究,这种对具体对象的实践研究证明了语义技术的应用可实现档案资源语义的关联、揭示、发现、组织与表示,助力档案智能化管理,实现档案资源的智慧化应用和服务。在理论升华方面,该领域学者对档案保管体系理念的演变进行了探讨与分析,提出了档案知识组织的、记录因子“档案领域数据本体”的概念,进行档案智慧转型路径的探索,这些概念的提出,理念的探讨以及路径的探索会助力当下学者反思档案资源语义化开发的内涵与外延,实现多维度、结构化、空间化的档案资源语义化开发。
1.3 档案资源语义化开发平台与项目实践研究
在平台开发、项目实践的相关研究中,夏翠娟老师团队以红色文献资源为例,展开了较多研究。刘倩倩、夏翠娟等[29]指出,上图红色文献平台建设采用基于知识本体的方法,将多种红色文献资源和语义知识图谱融合,应用关联数据、GIS、数据可视化等多种技术进行了相关平台建设,已经建成的一系列相关联的知识服务平台有中国家谱知识服务平台、中文古籍联合目录及循证平台、人名规范库等,这些平台取得了较好的服务效果。铁钟、夏翠娟等[30]指出,“上海记忆——红色旅游”项目利用语义网、关联数据、知识图谱等技术将不可移动的历史文化建筑与文化记忆资源深度整合,形成多角度、多层次、可操控、便于传输和展示的数据,直观再现了上海的历史变迁与人文建筑信息。张春景、夏翠娟[31]指出,开放数据竞赛启发并验证了基于语义网和知识图谱技术的多源数据融合以及利用微信小程序、GIS、3D建模、VR等技术的文旅融合服务,为红色文化信息资源的开发和利用提供了新的模式和路径。
1.4 中文研究热点与前沿发现——高频关键词主题加权演进分析。对国内档案资源语义化开发研究进行研究热点与前沿探测,为使绘制的主题加权演进图谱表达清晰,易于直观发现研究热点与前沿,综合考虑关键词数量及其频次,选择对频次≥3的23个高频关键词进行主题加权演进分析,经过计算,基于关键词的主题加权结果如图4所示。横轴表示关键词平均出现的年份,纵轴表示关键词在相应年份出现的频次。对于横轴而言,关键词出现的年份越靠近2022年,说明其与该领域最新研究相关,代表档案资源语义化开发研究的前沿;对于纵轴而言,关键词出现的频次越高,说明近三年一直受到学者关注,代表档案资源语义化开发研究的热点。
可以看出,在档案资源语义化开发中,知识图谱、数字人文、关联数据、本体在近三年时间内出现的次数较多,时间较为平均,体现了档案知识图谱构建、档案数字人文、档案关联数据、档案本体构建一直是该领域的研究热点。档案数据化、知识发现、语义组织、人工智能出现的频次相对较低,但相比其他关键词时间接近2022年,说明档案数据化、档案知识发现、档案语义组织以及人工智能技术是档案资源语义化开发研究的前沿内容。
2 国外文献梳理
本文以所有字段=“Archival semantics” 或者 所有字段=“File semantics”為检索方式在Web of Science、ScienceDirect 等数据库中进行检索,时间限定在2019年8月31日—2022年8月31日,共检索到论文192篇。依据中文文献梳理可知,档案资源语义化开发研究中涉及具体对象除档案外,还有文件、文本以及记录等与档案息息相关的内容,因此对英文文献篇名、摘要进行梳理与筛查,筛查方式为篇名或摘要部分含有“Archives、Semantic”或者“File、Semantic” 或者 “Record、Semantic” 或者“Documents、Semantic”或者“Text、Semantic”等特征词,经过整理与校对,最终保留与研究主题相符合的外文文献31篇。
2.1 外文文献关键词数据分析。外文文献关键词数据分析将从关键词词频统计、每年关键词分布分析、高频关键词共现矩阵分析方面进行总结。
(1)外文关键词词频统计。本研究对外文关键词进行了频次统计,频次≥2的关键词共有7个,其余关键词在31篇文献中出现频次只有1次,说明外文文献研究的主题关键词相对中文而言较为分散,因为此领域研究外文成果相对较少,高频关键词以及其共现相对应也较少。经过以上统计,本研究绘制了外文文献档案资源语义化开发研究关键词词云图(图5),并将频次≥2的关键词进行了表格统计(表3)。
可以看出,在外文文献中,频次≥2的关键词为Semantics(语义)、Ontologies(本体)、Semantic Web(语义网)、Metadata(元数据)、Deep Learning(深度学习)、Linked Data(关联数据)、Feature Extraction(特征抽取)。以上关键词表示语义描述、语义抽取、语义组织、语义关联的技术支撑。除以上高频关键词外,剩余技术相关关键词有Image Segmentation(图像分割)、Character Recognition(字符识别)、Deep Semantic Feature(深层语义特征)、Convolutional Neural Network(卷积神经网络)、Deep Neural Network(深层神经网络)、Machine Learning(机器学习)等。本体、元数据、语义网、关联数据、深度学习、机器学习等技术方法的应用实现了语义关联、特征抽取,图像分割以及深层语义特征分析,技术方法的创新与更迭推进了档案资源语义化深度开发。
(2)外文关键词时间分布。本文按2019年8月31日—12月31日、2020年、2021年、2022年1月1日—8月31日四个时段对外文文献关键词进行了部分统计,如图6所示。
在2019年8月31日—12月31日时段内,文献中出现的关键词有Web Ontology Language(网络本体语言)、Unified Modelling Language(统一建模语言)、Information Model(信息模型)、Geographic Information Systems(地理信息系统)、Big Data(大数据)等,说明在这个时段学者对本体语言、模型构建、地理信息系统应用、大数据分析在档案资源语义化开发中的应用进行了相关研究。本体、信息模型的研究实现了该领域相关概念及语义关系的规范化、统一化表述,地理信息系统的应用对档案资源中的空间信息进行了精准、可视化的呈现,大数据思维与技术的应用实现了海量档案数据的语义挖掘与分析。在2020年时段内,文献中出现的关键词有Semantics(语义)、Feature Extraction(特征抽取)、Deep Learning(深度学习)、Resource Description Framework(RDF资源描述框架)、Linked Data(关联数据)、Semantic Web(语义网)等,在这个时段内学者对深度学习、RDF资源描述框架、关联数据等对语义深度挖掘的技术方法应用进行了相关研究,深度学习技术在档案资源实体识别、关系抽取方面得到了应用并取得较好结果,关联数据的应用可助力檔案资源的集成与共享,RDF三元组描述框架对档案资源的统一形式化表示具有重要意义,便利学者标注、抽取与获得档案资源中的实体语义关系。在2021年时段内,文献中出现的关键词有Semantics(语义)、Ontologies(本体)、Document Analysis And Recognition(文档分析和识别)、Character Recognition(特征识别)、Text Recognition(文本识别)、Text Analysis(文本分析)等,这个时段内研究包括对档案资源内容进行语义方面的特征识别、文本分析等,文本分析是档案资源文本挖掘的主要手段,基于计算机对档案资源文本理解与分析的基础上,从档案资源文本数据中抽取文本的特征与信息。档案资源的特征识别与生物特征识别紧密关联,智能机器通过获取和分析人脸、声纹、笔迹等生物特征,可助力档案资源中声像档案资源的语义化开发。在2022年1月1日—8月31日时段内,文献中出现的关键词有Convolutional Neural Network(卷积神经网络)、Deep Semantic Feature(深度语义特征)、Computational Semantics(计算语义学)、Data Curation(数据保管)、RDF Triples(RDF三元组)等,在这个时段学者对卷积神经网络数据处理、深度语义特征抽取、计算语义学等进行了相关研究,卷积神经网络技术的进步与发展实现了档案资源深度语义特征抽取,在计算语义学理论的指导下,学者可对档案资源词汇、句子、文本所蕴含的意义进行形式化描述,设计一套计算机可理解的语义语言,对档案资源进行语义解释,可以揭示档案资源不同词汇、句子及文本间的各类语义关联。
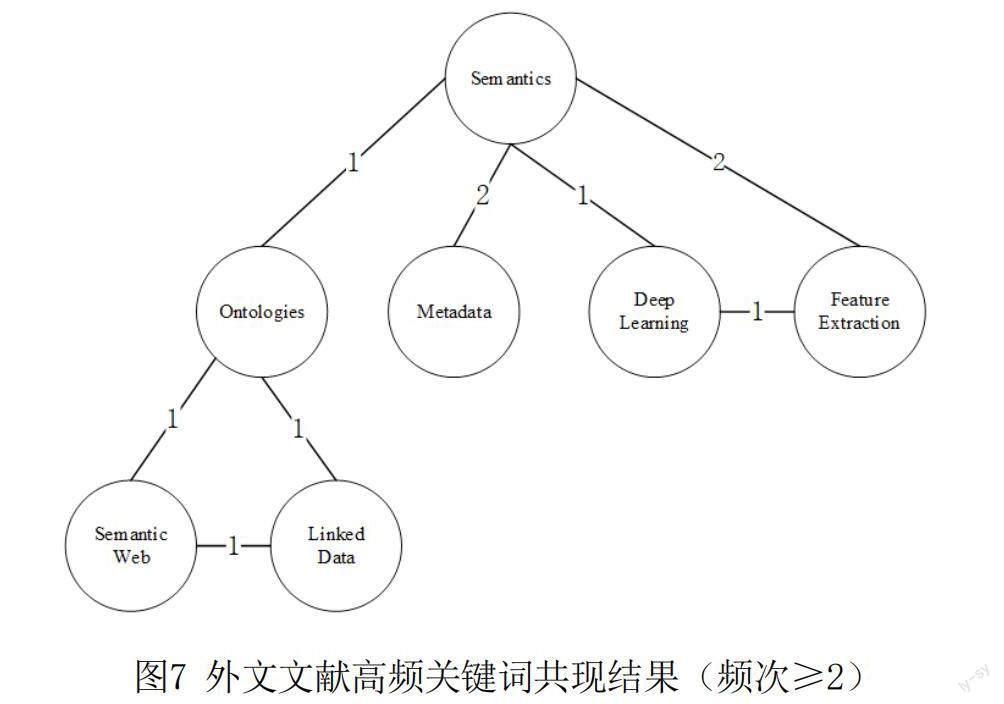
(3)基于高频关键词的外文文献共现分析。在相关外文文献中,频次≥2的关键词共有7个,本文对这7个关键词进行了共现分析(图7)。
其中,Semantics(语义)与Ontologies(本体)共现1次,与Metadata(元数据)共现2次,与Deep Learning(深度学习)共现1次,与Feature Extraction(特征抽取)共现2次;Ontologies(本体)与Semantic Web(语义网)共现1次,与Linked Data(关联数据)共现1次;Semantic Web(语义网)与Linked Data(关联数据)共现1次;Deep Learning(深度学习)与Feature Extraction(特征抽取)共现1次。基于共现结果,可以发现Semantics(语义)与其他关键词共现较多,语义、本体、语义网、关联数据之间的共现形成了闭环,说明学者以本体构建为基础,结合语义网、关联数据等技术实现档案资源的语义化开发研究。语义、深度学习、特征抽取之间的共现体现了学者在对档案资源语义化开发研究中,将深度学习等技术应用于资源内容的特征抽取,实现了档案资源的特征识别与分析。此外,语义与元数据共现2次,说明档案资源的语义化开发需要构建规范化的元数据体系,这对实现档案资源的语义发现和语义分析具有重要意义。
2.2 基于高频关键词共现的外文文献主题聚类分析。本文将国外档案资源语义化开发研究主题归纳为3个方面,分别是基于本体的语义化开发研究、基于元数据的语义化开发研究和基于深度学习与特征抽取的语义化开发研究,现将每个主题进行相关文献的梳理与总结。
(1)基于本体构建的语义化开发研究。Wang等[32]基于语义网和语义本体,总结了政府档案相关领域知识,构建了中国政府档案本体模型,进一步推动了档案学在数字化领域的研究和实践。Viry 等[33]提出一种基于语义Web技术从应用程序数据模型中展示地理可视化的方法,实现了以本体论推导知识自动创建地理可视化的目标。Stork等[34]提出了一个自然历史集合本体论NHC-Ontology(Natural History Collection Ontology)语义模型,用于构建自然历史档案馆藏中的命名实体,并且设计了一个注释工具,对1820年至1850年间自然历史委员会收集的8 000页书籍页面的图像进行了专家语义注释,实现了NHC-Ontology语义模型与语义注释数据的结合,此研究解释了本体在语义建模方面的价值。
(2)基于元数据规范化的语义化开发研究。Neal等[35]在生物网络计算建模(COMBINE)共识指导下,开发了一个规范、用于开放建模和交换(OMEX)格式的档案编码注释,OMEX元数据有助于注释档案中各种模型和数据表示格式的规范化。Gennari等[36]详细介绍了规范的 OMEX 元数据1.2 版本,其是支持语义模型注释的软件工具的技术指南,在模型重用、语义发现和语义分析方面具有重要意义。
(3)基于深度学习与特征抽取的语义化开发研究。Ren等[37]提出了基于深度学习框架——动态卷积神经网络(DCNN)的电子设备配置数据集的自动映射方法,使用Word2vec词模型对词及其语义关系进行向量化,实现了语义规律挖掘和智能记录仪的数据集自动映射,此研究对语义映射、语义特征提取具有重要意义。Wang等[38]指出深度信念网络模型使用多级神经网络从训练数据中学习表示,该表示可以重建训练数据的语义和内容,使用深度信念网络从源代码中提取的标记向量中自动学习语义特征,并利用这些特征来构建和训练缺陷预测模型,对文件级预测具有显著作用。
通过上述国外相关主题梳理可以发现,本体帮助实现档案领域知识总结,借助本体可以对档案资源内容进行知识表示和知识推理,帮助构建命名实体识别,对档案资源语义建模具有较大价值。元数据有助于规范档案资源中的模型和数据表示格式,实现档案资源的语义发现和语义分析。深度学习实现档案资源语义特征的提取,对文件级缺陷预测具有显著作用。以上技术方法的综合应用能够实现多层次、空间化的档案资源语义化开发,有助于档案资源智慧价值的挖掘,辅助人文学者构筑以语义发现与语义关联为纽带的档案资源知识记忆体系。
2.3 国外档案资源语义化开发平台与项目实践研究。在国外档案资源语义化开发实践研究中,Bartalesi等[39]芬兰文化遗产开发项目中的遗产资源来自22个博物馆、档案馆和图书馆,包含绘画、雕塑、漫画、人物传记等不同類型对象,其中关于传记桑波开发的系统使用CIDOC CRM模型对传记词典进行叙事概念表示,基于该系统构建了数字图书馆,包含13 000多位历史人物传记,通过使用知识提取技术将文本传记转换为关联开放数据,通过内部与外部数据源链接进行推理来丰富数据,并且丰富了数据分析和数据可视化的工具,助力学者进行数字人文研究。Koho等[40]指出基于桑波传记的另一个项目是关于手稿研究的数字图书馆开发,旨在将不同数据库来源的手稿数据集集成到共享平台中进行研究和发现,此项目统一并发布了手稿元数据作为开放关联数据,创建了语义门户和开放关联数据服务,便于进行搜索和发现,支持使用推理引擎进行知识发现,为用户提供更好的知识服务。Felipe等,[41]指出拉丁美洲漫画档案馆(LACA)对拉丁美洲漫画进行了数字化和编码,在漫画档案上为学者和学生提供了助力人文学科研究的数字标记和注释等数字技术工具,方便学生和研究人员能够合作定义要注释的关键术语语义,帮助学者和学生进行语义主题研究等学术探索。
2.4 外文研究热点与前沿发现——主题加权演进分析。与基于中文关键词进行主题加权演进来发现研究热点和前沿相同,对频次≥2的外文关键词进行主题加权演,以2020年为时间间隔点,可以发现在外文文献高频关键词中,特征抽取、深度学习、本体、元数据是近3年档案语义领域相关研究的热点,语义网关键词时间相比最靠前,说明其在外文文献档案语义相关研究中既是热点也是前沿。
3 国内外档案资源语义化开发研究总结分析
本文利用Co-Occurrence13.2(COOC13.2)软件,[42]对国内外档案资源语义化开发研究进行了关键词词频统计、条形图绘制、共现矩阵计算、主题聚类分析以及主题加权演进分析,通过以上分析,可以发现国内外学者对档案资源语义化开发在一些方面也达成一致意见:(1)档案资源语义化开发的对象是多源多构的,档案资源来源于档案馆、档案网站、档案数据库、档案微信公众号以及包含档案资源的图书馆、博物馆等组织或平台,数数据结构包括结构化数据、半结构化数据与非结构化数据;(2)档案资源语义化开发的主要目标是通过方法与技术实现档案资源语义内容的揭示与互联,以求解档案资源语义知识挖掘与关联问题或者满足知识服务需求,国内外都对档案资源语义化开发的技术应用较为重视,文献中提到包括本体、元数据、关联数据、语义网、知识图谱、GIS、机器学习、深度学习等主要语义开发技术与方法;(3)档案资源语义化开发涉及了多学科的理论与方法,主要涉及档案学、图书情报学、计算机科学、语义学、数学等不同学科的理论和方法,这映射了档案学与其他学科的合作共生关系,档案资源语义化开发也是多学科交叉融合的关键体现;(4)档案资源语义化开发的结果是提供用户所需的知识,或对于现有知识体系而言的新知识,助力学者与学生进行数字人文研究,实现档案资源智慧价值的挖掘。
通过对档案文献资源语义化开发平台与项目的相关实践研究分析,可以发现国内外学者大多基于辅助学者进行数字人文研究视角,构建相关的数据库、语义门户、数字图书馆等服务平台以实现档案资源的语义化开发,国内涉及的实践项目有上海图书馆发布的中国家谱知识服务平台、中国古籍联合目录及循证平台、人名规范库等,国外涉及的实践实现包括基于桑波传记开发的数字图书馆、关于手稿研究的语义门户以及拉丁美洲漫画档案馆项目等。这些实践研究应用了本体、元数据、关联数据、语义网、知识图谱、GIS等技术,实现了档案资源语义的深度挖掘与关联,为学者和学生进行数字人文研究提供了助力。
4 结语
本文对近三年国内外档案资源语义化开发研究进行了系统梳理,重点内容为通过高频关键词的共现分析与回顾文献总结了国内外档案资源语义化开发中的研究主题,剖析了各主题之间的逻辑关联以及各主题与档案资源语义化开发的关系。同时,对高频关键词进行主题加权统计分析,进而发现在高频关键词中近三年国内外档案资源语义化开发研究热点与前沿,助力学者快速掌握此领域的热点与前沿。此外,本文对国内外档案资源语义化开发平台、项目实践进行了梳理概括,通过梳理可以发现,相关档案资源服务平台为学者和用户提供了良好的知识服务,助力学者进行数字人文视域下档案资源语义化开发研究。最后,本文对国内外该领域研究进行了分析,发现了国内外档案资源语义化开发之间的共性,基于此,总结了档案资源语义化开发的对象、目标、多学科视角、结果实现以及相关应用技术等内容。
基于本文的梳理与总结可以发现,技术的更新、多学科的交叉融合创新了档案资源语义化开发模式,推动了档案资源从数据价值到信息价值到知识价值再到智慧价值的凝练与挖掘,随着用户对档案资源语义知识服务的需求不断变化,这种需求反过来也会推动档案资源语义化开发技术及理论层面的研究深度拓展。在未来,计算机科学、信息哲学、数字人文学、语义学将与档案学深度交融,在档案资源语义化开发中发挥更大的作用,而关于档案资源多模态语义融合与语义发现将是未来一段时间内档案资源语义化开发研究的重点内容。
*本文系国家社会科学基金项目“数据驱动的档案文献资源知识构建与知识服务研究”(项目号:21BTQ109)的研究成果之一。
参考文献:
[1][22]祁天娇,冯惠玲.档案数据化过程中语义组织的内涵、特点与原理解析[J].图书情报工作,2021,65(09):3-15.DOI:10.
[2][13][21]邓君,王阮.口述历史档案资源知识图谱与多维知识发现研究[J].图书情报工作,2022,66(07):4-16.
[3]钱毅.从保护到管护:对象变迁视角下的档案保管思想演变[J].档案学通讯,2022(02):82-88.
[4]牛力,黎安润泽,刘慧琳,等.从物理到数据:智慧档案2.0体系构建研究[J].档案学研究,2022(03):84-90.
[5]郝伟斌,王君仪,段燕鸽.档案文化智慧数据资源建设——河南省档案馆馆藏中福公司档案整理开发研究之二[J].档案管理,2022(01):114-116.
[6]曾蕾,谭旭.数据的语义增强——解读图档博支持数字人文的新动向[J].数字人文研究,2021,1(01):65-86.
[7]赵雪芹,李天娥.面向数字人文的档案领域本体构建研究——以万里茶道档案资料为例[J].情报理论与实践,2022,45(08):154-161.
[8]房小可.档案学科视角下社会记忆构建框架研究[J].档案学研究,2021(03):18-23.
[9]房小可,王巧玲.档案著录?知识关联与社会记忆重构[J].档案学通讯,2021(03):27-33.
[10]牛力,高晨翔,刘力超,等.层次与空间:数字记忆视角下名人档案的价值挖掘研究[J].档案学研究,2021(05):138-144.
[11]周娟娟,李泽锋,刘竟一.基于知识图谱的干部人事档案知识化服务研究[J].档案管理,2021(06):87-89.
[12]高淞,王向女.數字人文视域下口述历史档案资源开发利用研究[J].山西档案,2021(03):61-70.
[14]郭学敏,Ryan Shaw.基于关联数据的档案语义转换实践分析[J].档案学通讯,2019(05):50-57.
[15]夏天,钱毅.面向知识服务的档案数据语义化重组[J].档案学研究,2021(02):36-44.
[16]宋雪雁,张伟民,张祥青.基于档案文献的清代祭祀礼器知识图谱构建研究[J].图书情报工作,2022,66(03):140-151.
[17]向梦宇.基于知识图谱的军工研究所档案知识服务模式研究[J].机电兵船档案,2022(01):21-23.
[18]雷洁,赵瑞雪,李思经,等.科研档案管理知识图谱构建研究[J].科技管理研究,2020,40(11):162-169.
[19]雷洁,赵瑞雪,李思经,等.知识图谱驱动的科研档案大数据管理系统构建研究[J].数字图书馆论坛,2020(02):19-27.
[20]祁天娇,曹宇,傅晓丹,等.“十四五”时期档案资源智慧化转型研究[J].档案学通讯,2021(06):96-98.
[23]张斌,高晨翔,牛力.对象?结构与价值:档案知识工程的基础问题探究[J].档案学通讯,2021(03):18-26.
[24]周媛媛.综合性档案馆基于特征提取与数据分析的档案语义关联模型应用研究与实践[J].兰台世界,2022(06):59-61.
[25]赵生辉,胡莹.“档案数据化”底层逻辑的解析与启示[J].档案学通讯,2021(04):20-27.
[26]赵生辉,胡莹,黄依涵.数据?档案及其共生演化的微观机理解析[J].档案学通讯,2022(02):4-12.
[27]吕元智.视频档案资源多层级语义标注框架构建研究[J].数字图书馆论坛,2021(11):13-20.
[28]赵生辉,胡莹.拥有整体性记忆:档案领域数据本体管理论纲[J].山西档案,2020(06):17-27.
[29]刘倩倩,夏翠娟,朱武信.红色文化传承视域下的红色文献服务平台建设实践与思考[J].信息资源管理学报,2021,11(04):17-24+32+16.
[30]铁钟,夏翠娟,黄薇.文旅融合视域下红色文化信息资源数据化创新设计与实践[J].信息资源管理学报,2021,11(04):33-39+59.
[31]张春景,夏翠娟.开放数据竞赛在红色文化信息资源开发利用中的价值贡献研究——以上海图书馆开放数据竞赛为例[J].信息资源管理学报,2021,11(04):25-32.
[32]Wang Z Y,Song Z P,Yu G,et al.An Ontology for Chinese Government Archives Knowledge Representation and Reasoning[J].IEEE Access,2021,9:130199-130211.
[33]Viry M,Villanova-Oliver M.How to Derive a Geovisualization from an Application Data Model:An Approach Based on Semantic Web Technologie[J].International Journal of Digital Earth,2021,14(07):874-898.
[34]Stork L,Weber A,Miracle E G,et al.Semantic annotation of natural history collections[J].Journal of Web Semantics,2019,59:100462.
[35]Neal M L,Gennari J H,Waltemath D,et al.Open modeling and exchange(OMEX) metadata specification version 1.0[J].Journal of Integrative Bioinformatics,2020,17(2-3):20200020.
[36]Gennari J H,K?nig M,Misirli G,et al.OMEX metadata specification(version 1.2)[J].Journal of Integrative Bioinformatics,2021,18(03):20210020.
[37]Ren J B,Li T C,Gen S B,et al.An Automatic Mapping Method of Intelligent Recorder Configuration Datasets Based on Chinese Semantic Deep Learning[J].IEEE Access,2020,8:168186-168195.
[38]Wang S,Liu T Y,Jaechang N,et al.Deep Semantic Feature Learning for Software Defect Prediction[J].IEEE Transactions on Software Engineering,2020,46(12):1267-1293.
[39]Bartalesi V,Pratelli N,Lenzi P.linking different scientific digital libraries in Digital Humanities:the IMAGO case study[J].International Journal on Digital Libraries:2022,23:303-317.
[40]Koho M,Burrows K,Hyv?nen E,et al.Harmonizing and publishing heterogeneous premodern manuscript metadata as Linked Open Data[J].JASIST,2022,73(02):240-257.
[41]Felipe G ,Scott W ,Rikk M ,et al.The Latin American Comics Archive(LACA)an online platform housing digitized Spanish-language comics as a tool to enhance literacy,research,and teaching through scholar/ student collaboration[J].Cuadernos del Centro de Estudios en Dise?o y Comunicación.Ensayos,2020,89:47-67.
[42]學术点滴,文献计量. COOC一款用于文献计量和知识图谱绘制的软件[CP/OL].[2022-10-13].https://gitee.com/academic_2088904822/academic-drip.
(作者单位:吉林大学商学与管理学院 宋雪雁,教授,博士生导师;张祥青,博士研究生;张伟民,博士研究生 来稿日期:2023-04-19)
猜你喜欢
哲学分析(2023年4期)2023-12-21
新世纪智能(数学备考)(2021年9期)2021-11-24
少先队活动(2020年12期)2021-01-14
中国音乐学(2020年4期)2020-12-25
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
中成药(2017年3期)2017-05-17
读者(2017年5期)2017-02-15
文学教育(2016年27期)2016-02-28
卷宗(2013年6期)2013-10-21
