
基于词性标注规则的马铃薯文献信息抽取方法
2023-10-12 09:45王腾阳赵小丹胡林
科学技术与工程 2023年27期
王腾阳,赵小丹,胡林
(中国农业科学院,农业信息研究所,北京 100081)
马铃薯是中国第四大粮食作物,除了能够兼做粮食、蔬菜和饲料,还有很多加工用途,产业链较长,有很大的潜力增产增收[1]。马铃薯育种研究人员育成新品种后会以论文的形式发布研究成果,内容通常包括马铃薯新品种的选育过程、特征特性、抗病性、品质分析等[2]。由于论文采用自然语言编写,缺少结构化的表述信息,积累了大量的非结构化文本数据,因此大规模的育种文献给人工整理品种数据带来了极大的挑战[3]。因此,亟需利用自然语言处理等技术自动分析马铃薯育种文献文本,抽取文本中的品种名、亲本、株高株型、抗病性等属性。这些信息可以用来搭建马铃薯遗传育种数据库,为马铃薯智能育种决策提供基础服务。
信息抽取指的是从自然语言文本中抽取指定类型的实体、属性等信息,并形成结构化数据的文本处理技术[4]。张萌等[5]对城市轨道交通安全事件案例的自由文本制定知识元属性、构建词库,并对文本进行分词,利用正则表达式抽取事件信息,但因其抽取规则制定不完善,部分知识元抽取效果不理想。谭永滨等[6]研究提取交通微博文本信息的方法,提出基于线性参照方法构建位置表达模式库,并将模式库表达为Trie树,利用有限状态机匹配微博文本中位置表达模式,识别并提取微博文本中的位置信息,其错误结果主要来自未登录地名与模式不确定性。刘时翔[7]研究半结构化金融文本信息抽取,用正则表达式抽取电话号码等简单项信息,利用行文格式、分隔符号等特点,用隐含马尔柯夫模型(hidden Markov model,HMM)模型抽取复杂项信息,造成抽取结果错误的因素有文本块的边界难以划分,大量过渡数据使文本块数据连续性较差,合同结构随意性较大等。Feng等[8]提出基于主题识别和命名实体识别的信息抽取方法,提取新冠疫情通报文本信息的风险区域和疫情轨迹信息。Martin[9]研究使用深度学习的方法识别企业发票的结构化文本,为企业节约人工提取成本。
虽然马铃薯育种文献文本描述形式多样,但论文作者对马铃薯特征特性的描述有规律可循,如“株高50 cm左右”“干物质含量15.4%”“皮色淡黄”“肉色白色”等,目标词可以归类为某一具体词性,并且相对于实体间的关系,任务更专注于提取实体的属性值,所以可使用自然语言处理的方法,将待处理文本进行分词,对分词结果进行词性标注,根据语句中的词性获取目标词。因此,现面向马铃薯种质资源领域,基于文本处理的分词和词性标注结果,编写规则库,根据规则对符合词性的目标词实现快速匹配,据此提出基于词性标注和规则库的马铃薯育种文献信息抽取模型,以期实现马铃薯育种文献中的种质资源信息结构化。
1 文献信息抽取
1.1 实验环境
本实验编程语言使用Python 3.8。自然语言处理技术使用HanLP[10],包括中文分词、词性标注等。具体实验流程如下文所述。
1.2 数据预处理
PDF文档分为两类,一类是文字内容可以完整读取的正常文档;另一类是文字读取与预期不符的文档。文字读取与预期不符的情况包括但不限于数字被符号代替、段落的行顺序错乱等。虽然光学字符识别(optical character recognition,OCR)可以实现该类文档的文本化,但由于期刊论文正文存在左右排版方式,使用OCR自上而下地识别会造成文字顺序混乱。因此需要先分割文档图像的各个文本块,将分割出的图片按阅读顺序排序,通过OCR获取图片内的文字并进行汇总。
首先将待处理的PDF文档页面转化为文字为白色、背景为黑色的反二值图像,使用游程平滑算法将文字连通,形成连通图。游程平滑算法[11]可以应用于文档图像分割处理,该算法对一行(列)上的两个黑色像素点间的距离进行判断,如果两个相邻黑色像素点间空白像素的个数小于设定的阈值时,就将这两点之间的空白像素点全部填黑。当算法的水平阈值Thor=3、垂直阈值Tver=3时,运行效果如图1所示。

图1 游程平滑算法示意图
通过开源计算机视觉库(OpenCV)中的相关方法,检测经过游程平滑算法处理后的图像中各个连通图的矩形边框,获得其边缘坐标。根据得到的坐标,截取源PDF文档页面图像中的对应位置,按照从左到右、从上到下的顺序,依次命名保存文字图像,作为OCR文字识别的输入源。处理流程如图2所示,最终得到的文本块分割结果,用矩形边框标注。

图2 处理文献过程图
由于直接提取PDF文档或通过OCR文字识别提取文档均存在全角字符、语句中存在多余换行符以及文字间存在多余空格等问题,因此需要先将文本内容按顺序进行如下处理:①全角字符转化为半角字符;②去除文字之间多余空格;③删除文字内换行符。
1.3 基于词性标注和规则库的信息抽取方法设计
规则库使用Json格式保存在文件。每一对键值对中,键表示抽取项的名称,值表示抽取项的规则。规则的设计包含下面五类:①关键词;②按照词性标注的抽取规则;③目标词中的屏蔽词;④抽取关键词所在关键句中不允许出现的词;⑤提供预设词进行匹配(以键值对表示,键表示匹配原始文本中的词,值表示抽取结果中展示的词)。
使用关键词结合正则表达式,获取目标抽取项所在语句,在获取的所有语句列表中,删除包含不允许出现的词的语句,随后对语句进行分词、词性标注,通过抽取规则定位关键词位置和目标抽取项位置。对于一些表述不规律、不能使用分词和词性标注方法获取的,例如,抗病性只有抗、不抗、高抗等几种表述,但由于其表述时有多种疾病混在一起,很难通过分词的方法来获取,这种情况使用匹配预设词并结合判断目标项与预设词的距离之间的距离的方法获取目标项。信息抽取流程图如图3所示。

图3 信息抽取流程图
1.3.1 关键词规则设计
关键词用于在待抽取文本中提取目标项所在语句,根据关键词的位置,在语句中使用基于词性标注规则和预设词的方法实现抽取目标项。用户建立关键词库,需要根据提取项,在待提取文本中找到相关表述。用户在人工校对提取结果时若发现抽取项的新关键词,可以将其添加至关键词库,从而优化提取效果。使用正则表达式获取关键词所在语句,具体方法为从关键词开始向前(后)直到达到20个文字或者遇到标点符号为止。本文使用关键词定位抽取项所在文本句,对于关键词规则的设计,考虑如下几种情况:①关键词之间是“或”的关系;②关键词之间是“与”的关系;③关键词之间是互斥的关系;④关键词之间是上述几种关系结合的关系。
关键词规则如“A(BC,D,^E)/F/G”,表示提取的文本句需要符合包含A或F或G;在包含A的情况下,需要满足同时包含B或C,以及包含D,但不能包含E。目标提取项所在句可能涉及多个不同的关键词,在上述示例规则中,A、F、G称为主关键词,每一个主关键词后面允许加括号,括号内的词称为次关键词,与主关键词的关系和“逻辑与”相同,表示提取语句需要同时包含主关键词和所有的次关键词。主关键词之间以 “/”分割,次关键词之间以 “”分割,与“逻辑或”相同。用“^”符号表示不允许提取语句中包含的关键词。
1.3.2 分词与词性标注
分词与词性标注使用HanLP自然语言处理工具包。首先将提取的关键词语句进行分词。在进行词性标注前,对分词结果进行预处理有利于后续的信息抽取过程。
对分词结果的预处理主要为合并部分分词内容。例如,中国马铃薯品种的命名方式大多为“X薯X号”,在分词时通常会将品种名中的“X薯”和“X号”分开,在进行信息抽取前将其合并会提高抽取的准确率。同理,对单引号、双引号等内部无需分词的内容统一进行合并,可以有效改善抽取效果。另外,需要添加关键词到自定义词典,防止关键词被分词影响后续抽取过程。
词性标注使用CTB(chinese treebank)标注集(表1)[12],结合自定义词库对分词结果进行词性标注。
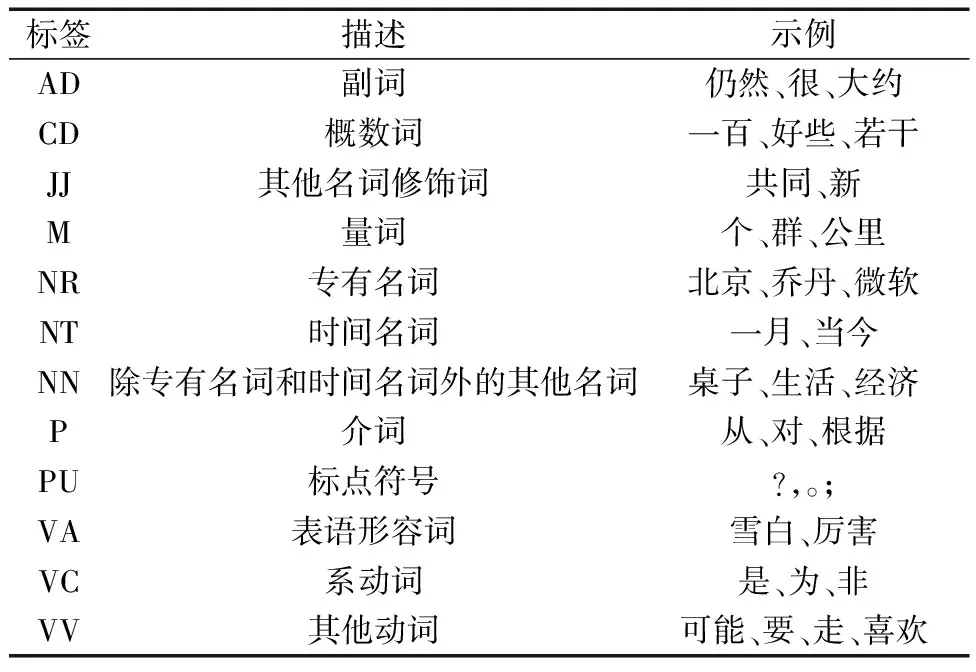
表1 部分CTB词性标注集
1.3.3 基于词性标注的规则库设计
规则基于分词和词性标注结果制定,在规则中,每一个匹配项使用CTB词性标注集中的标签代替。每一条规则都要包含作为提取依据的关键词和需要提取的目标词。关键词使用“KEYWORD”代替,目标词使用“TARGET”代替,用“ANY”代替两个标签间任意数量、任意词性的标签。抽取规则允许在同一位置有多种词性标签,标签间用“/”分割,因为目标词有可能被分词,采用的解决方法是在规则中使用多个“TARGET”标签,在抽取完成后将抽取的多个“TARGET”进行合并得到抽取结果。“TARGET”标签设计为可以指定特定的词性标签或不允许为某个特定词性标签。语法同关键词的设计类似,指定特定的标签间用“/”分割;在标签前加“^”符号表示不允许抽取某个特定标签。
抽取过程如下:①定位在规则中关键词和目标词的所在位置;②定位关键词在分词结果中的位置;③迭代检查词性标注结果是否符合规则;④合并、返回抽取结果。
设关键词在分词结果的位置为Pt,在规则中的位置为Pr,以规则中包含的元素个数N作为迭代次数,用i表示,即i=0,1,2,…,N-1。
词性标注结果中迭代索引映射为
Index=Pt-Pr+i
(1)
每次迭代都要判断词性标注结果是否符合规则,具体的判断依据有:①索引是否位于有效范围内;②词性标注结果是否在规则内;③索引是否为特殊情况(例如:索引为关键词位置时,不要求②成立)。当不满足上述条件时,跳出迭代并返回空字符串。抽取数据文本样式如图4所示(关键词以加粗斜体表示)。
部分抽取语句示例如表2所示,在“原语句”列中,关键词为加粗字体。
1.3.4 基于预设词的抽取规则设计
在马铃薯育种文献中,对于如抗病性的表述方法比较多样,使用词性标注的抽取方法不能满足需求,但需要提取的目标词的表述较为统一。例如“抗晚疫病、PVX、PVY”,单纯使用词性标注的方法虽然可以获得该品种对晚疫病的抗性结果,但对PVX和PVY的抗性难以制定规则获得相关表述;又如“植株抗晚疫病、感轻花叶和重花叶病毒病”和“晚疫病:高抗”两种表述中,若只根据第二种表述制定规则“关键词(KEYWORD),标点符号(PU),目标词(TARGET)”,则在第一句明显会匹配错误的结果,对于此类使用词性标注规则方法难以提取,且需要提取的目标词表述较为统一的语句,使用基于预设词的抽取方法。
预设词使用键值对保存,键用于保存关键词语句中的匹配词,值用于保存给用户输出结果的词。
抽取过程如下:①获取关键词、预设词在句中位置;②在语句中所有的预设词里,寻找距离关键词最近的一个,添加进结果集。
1.3.5 抽取结果的汇总与清洗
完成通过基于词性标注和基于预设词的两种抽取方法后,将两种抽取结果添加进一个集合中进行汇总。通过词性标注的抽取方法可能将不相关的词也统计入抽取结果,因此需要将汇总后的抽取结果匹配规则库中的违禁词进行筛选,从而得到更加准确的抽取结果。
2 实验结果及分析
2.1 数据来源与评价标准
测试集为马铃薯育种文献115篇,文献为PDF格式,通过人工标注抽取项和正确的抽取结果,针对每篇文献内容包含的马铃薯品种名称、亲本、株型株高、皮色肉色、抗病性等共20个数据项进行信息抽取实验。由于部分文献中不包含全部抽取项,因此抽取项数目总计1 490项。由于文献来自不同的年代,作者对马铃薯性状描述的侧重点不同,大部分文献不包含全部的20个抽取项。测试集文献的抽取项数目分布如图5所示。
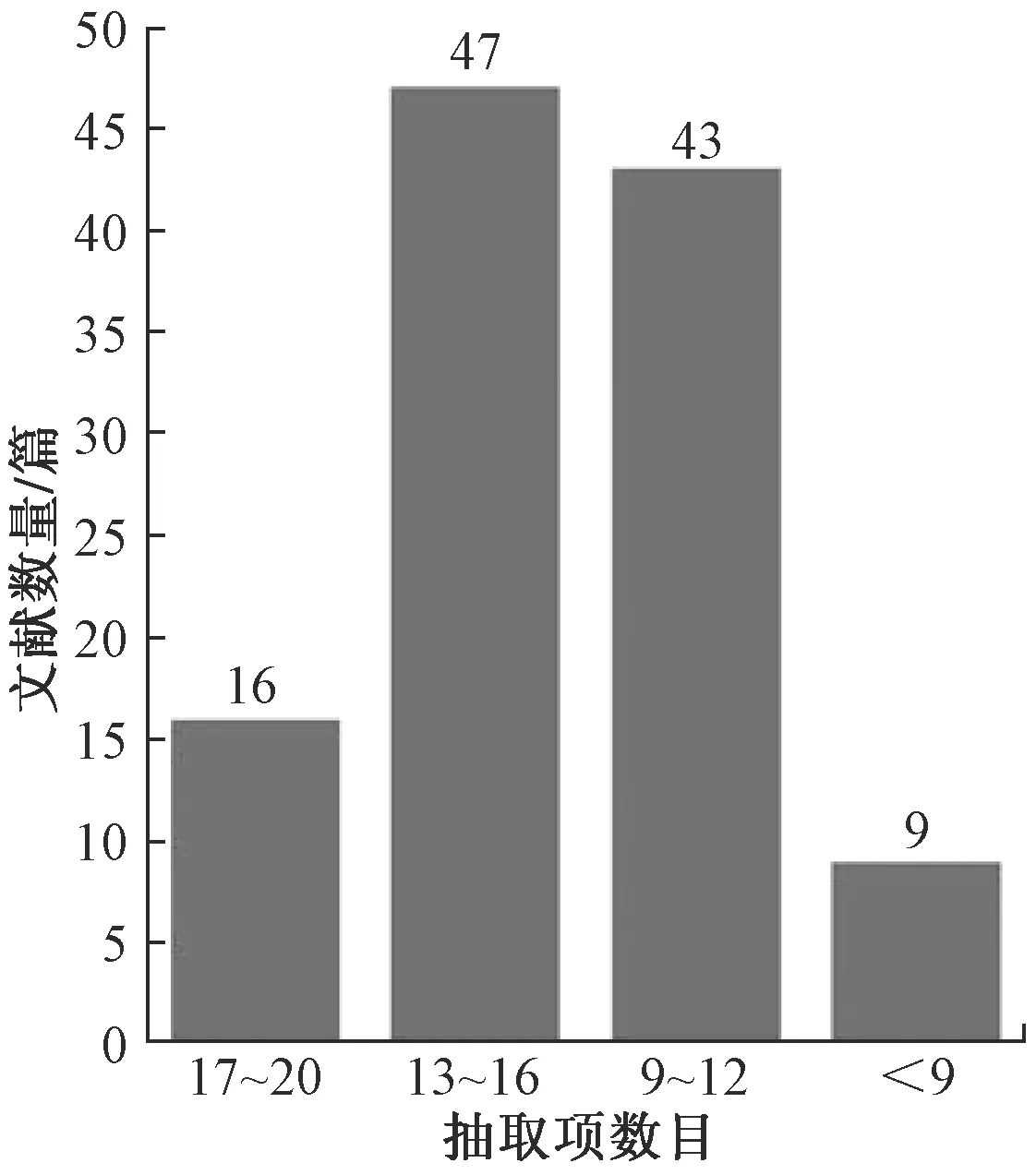
图5 测试集抽取项数目分布
文本信息抽取总共分为四种情况:TP表示文本中有数据,并且成功抽取到数据;FP表示文本中缺失数据,但抽取到了数据;TN表示文本中缺失数据,也没有抽取到数据;FN表示文本中有数据,但没有抽取到数据。以精确率P、召回率R和F作为性能评价标准,计算公式[13]为
(2)
(3)
(4)
2.2 方法结果对比
为了进一步验证本文方法的有效性,使用了传统信息抽取方法作为对比。作为对比的基于普通规则的传统信息抽取方法与本文基于词性标注和预设词信息抽取方法的文本预处理、关键词与规则库的处理方式相同,主要区别在于信息抽取部分。传统信息抽取方法使用正则表达式定位关键词,以某个指定字符作为边界,截取关键词到指定字符范围之间的内容作为抽取结果。各方法的抽取结果统计见表3。

表3 抽取结果统计
在普通规则方法中,抽取成功的比率达87.38%,能够有效抽取信息,但其准确率仅为53.89%,表明该方法提取有近一半不需要的干扰信息。基于词性标注规则中,抽取成功的。普通规则的抽取方法使用正则表达式提取目标信息,该方法的局限性在于注重于语句的字数、结构是否合规,缺少对文本内容的判断,导致提取到过多的无效信息。本文使用的基于词性标注规则弥补了普通规则的缺陷,使用词性标注判断文本内容是否有效,达到去除无效信息的效果。
本文抽取结果评价如图6所示,由图6可知,不论是基于词性标注规则还是基于预设词的抽取方法,召回率接近甚至达到100%,但准确率在基于词性标注规则中为82%,在基于预设词中为84%,本文所使用的基于词性标注规则的方法能够有效提取马铃薯育种文献中所需信息,但提取出不需要的结果的数量远远超过提取失败结果的数量。

图6 信息抽取结果评价
通过分析提取结果得知,提取失败的原因主要有以下几种。
(1)分词结果不准确;在分词时,有时会存在目标词被分词和不被分词两种情况,在制定规则时会针对两种情况分别制定,例如,在处理品种名“晋薯1号”时,会将其分词为“晋”“薯”和“1号”三个部分;但在处理“威芋3号”时,会将其分为“威芋”和“3号”两个部分,导致在规则的制定和分词结果的预处理上难以进行处理从而无法准确提取品种名。
(2)文献中涉及的品种不止一个,还涉及对其亲本的描述;在有些文献中提到其亲本信息,例如在“天薯13号[14]”的描述文献中,不仅有对“天薯13号”的特征描述,还存在对其母本和父本的株型、高度、淀粉含量和皮色肉色等特征的描述,模型会将其特征描述全部提取作为结果,对正确的结果造成干扰,因此造成召回率不变,准确率降低。
(3)部分文献所属的期刊在排版中,存在有其他文章的页面,导致提取到其他文章中的内容。
(4)部分年代较为久远的育种文献,文档信息化程度较差,不论是直接提取PDF文档文字,还是使用OCR对其内容进行文字识别,文字提取效果均不理想,造成文献信息提取效果较差。
3 结论
以马铃薯育种文献为对象,提出一种基于词性标注和规则库的信息抽取模型,结果表明,总体正确率达82.97%,召回率达99.73%,F值为90.58%,因为抽取结果需要人工进行校对再输入进育种数据库,所以希望模型在具有较高的准确率的同时,拥有更高的召回率,从而能减轻人工录入的工作量,因此本文使用的抽取模型能够有效提取文献内信息。该模型的重点在于分析分词与词性标注结果,因此该抽取模型具有通用性,只需编写所需规则库,就能应用到其他领域的抽取任务。该模型不仅能完成文本内容的信息抽取,而且还实现了文本图片的文本块分割,根据页面阅读顺序进行排序,使用OCR文本识别提取文字内容完成信息抽取。通过分析抽取结果,得出造成抽取错误的原因主要有以下几种。
(1)分词结果不准确。
(2)论文中涉及的品种不止一个,作者也对其亲本品种有所描述,造成抽取结果中有其他品种的属性信息。
(3)期刊将其他文章与待抽取文章排版到同一页面,抽取到其他文章的信息。
(4)提取PDF文件内文字与预期不符等。
未来将实现通过识别抽取属性与主体间的关系,抽取论文内所有主体的属性信息,提高抽取准确率的同时,获得更多品种的种质资源数据;针对农业领域训练或微调分词和词性标注模型,改善语句分词效果,进而提高信息抽取的准确性。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
校园英语·月末(2021年13期)2021-03-15
新世纪智能(语文备考)(2020年4期)2020-07-25
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
Coco薇(2017年11期)2018-01-03
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
语文知识(2014年4期)2014-02-28
外语学刊(2011年3期)2011-01-22
