
低跨云数据中心修复流量的纠删码的快速构造方法
2023-10-27 02:51王意洁
计算机研究与发展 2023年10期
包 涵 王意洁
(并行与分布计算全国重点实验室(国防科技大学) 长沙 410073)
(国防科技大学计算机学院 长沙 410073)
近年来,云数据中心故障频发,常导致其中数据长时间不可访问[1-6].同时,云际计算技术的逐渐成熟使得部署跨云数据中心存储系统更加便捷[7].因此,各机构纷纷采用跨云数据中心多副本技术来实现重要数据的容灾存储[8].
相较于跨云数据中心多副本技术,跨云数据中心纠删码技术具有更高的可靠性和更低的冗余度[9-12].然而,跨云数据中心纠删码技术要在生产系统中得到普遍运用,还需满足3 方面要求:
1)低跨云数据中心修复流量.纠删码技术在跨云数据中心存储系统中修复故障节点中的数据时,需跨云数据中心传输大量数据,即纠删码技术的跨云数据中心修复流量较大.由于云数据中心间带宽往往远低于云数据中心内带宽,所以纠删码技术在跨云数据中心存储系统中修复数据的时间较长[13-15].因此,亟需降低纠删码的跨云数据中心修复流量.
2)高编码参数适应性.在生产中,用户通常对存储节点数n、冗余度n/k、容错度d和容灾度D等纠删码编码参数具有多样化需求.因此,有必要提高跨云数据中心纠删码的编码参数适应性.编码参数为(n,k,d,D)的纠删码将每k个数据块编码为n个编码块,并将其分别存储在位于多个云数据中心的n个存储节点,且当任意d-1个存储节点或任意D个云数据中心故障时,其中存储的编码块可由其他编码块修复.
3)高纠删码构造效率.因为纠删码编解码数据的过程与存储系统的读写过程深度耦合,所以开发和部署存储系统前需先完成纠删码的构造,因而用户通常对纠删码构造用时较为敏感.因此,有必要提高跨云数据中心纠删码的构造效率.
现有工作提出的跨云数据中心纠删码[13-18]虽然能在一定程度上降低跨云数据中心修复流量,但普遍存在编码参数适应性较低的问题,无法在满足用户对编码参数的多样化需求的同时有效降低跨云数据中心修复流量.此外,有工作提出了面向跨云数据中心存储的自适应纠删码ACIoT[19],可求得不同编码参数(n,k,d)下的跨云数据中心修复流量下限,并构造能达到该下限的纠删码,即最优码.但是,ACIoT需要消耗较长时间来检验纠删码修复组分布方案与编码参数(n,k,d)的匹配性,故其纠删码构造效率较低.纠删码修复组分布方案E与指定编码参数P相匹配是指存在一个编码参数为P的纠删码的修复组分布方案为E.
综上,现有工作无法兼顾编码参数适应性、纠删码跨云数据中心修复流量和纠删码构造效率.本文提出一种低跨云数据中心修复流量的纠删码的快速构造方法(fast construction method of the erasure code with small cross-cloud data center repair traffic)FMEL,可在不同的编码参数下快速构造出具有较低跨云数据中心修复流量的纠删码.FMEL 的主要思想为:
首先,FMEL 将纠删码修复组分布方案及相应的编码参数(n,k,d,D)转换为定长特征向量,并将检验纠删码修复组分布方案与指定编码参数匹配性的问题转换为定长特征向量的二分类问题.其中,特征向量属于正类表示纠删码修复组分布方案与相应编码参数相匹配.然后,FMEL 采用具有较高分类效率的支持向量机(support vector machine,SVM)来对各个特征向量进行分类以实现其所对应纠删码修复组分布方案的快速检验.在检验的同时,FMEL 不断采集新的训练集对SVM 分类器进行增量更新,从而不断提高其分类准确率.随后,FMEL 采用一种并行搜索方法来快速地从所有可通过SVM 检验的纠删码修复组分布方案中选出跨云数据中心修复流量最小的一个方案.最后,FMEL 采用一种基于试错的纠删码修复组分布方案转换方法将搜索到的纠删码修复组分布方案转换为具有低跨云数据中心修复流量的纠删码的生成矩阵.
在跨云数据中心环境中的实验表明,FMEL 在大部分编码参数下可构造出能达到平均跨云数据中心修复流量下限的最优码,且其构造纠删码的时间仅为现有工作构造最优码时间的11%.
1 相关工作
1.1 单云数据中心纠删码
现有工作提出了2 类低修复流量纠删码——再生码和局部性码.再生码通过降低新生节点从各提供者节点里的编码块中读取的数据量来减少修复流量,局部性码通过降低各个编码块的提供者节点数量来减少修复流量.与再生码相比,局部性码更容易实现且灵活性更高,因而被广泛地应用于Amazon AWS[20],Microsoft WAS[21],Facebook HDFS-RAID[22]等生产系统中.特别地,Shahabinejad 等人[23]提出了一种可达到平均修复流量下限的纠删码ACAL.
虽然现有单云数据中心纠删码能够降低平均修复流量,但是跨云数据中心修复流量并不与修复流量正相关.因此,这些纠删码在跨云数据中心环境下不能充分降低跨云数据中心修复流量.
1.2 跨云数据中心纠删码
Yu 等人[13]提出了一种跨域容错纠删码DFC,其基本思想是在传统的RS 码的基础上引入局部校验块,首先使用RS 码将k个数据块编码为w个编码块并在N个云数据中心中各存储w/N(w/N≤w-k)个数据块.由于RS 码可以保证在这w个编码块中的任意w-k个编码块失效时重构原始数据,所以在任意一个云数据中心故障时,仍可以通过其他云数据中心里的w-w/N(w-w/N≥k)个编码块恢复出原始数据.然后,DFC 为每个机架存放的编码块生成局部校验块,使得在任意一个编码块失效时,可以使用机架内的编码块和局部校验块对其进行修复.因此,DFC 的跨云数据中心修复流量较小.但是,DFC 对编码参数具有严格的限制,要求n-k-d+1≥N.
Caneleo 等人[14]提出了一种多倍异或码MXOR,其基本思想是将数据块分为2 行k/2 列,而后通过异或计算分别求得各行各列的局部校验块,然后将所有编码块和局部校验块按行分散到各云数据中心.当单个编码块失效时,MXOR 可通过对云数据中心内部的其他编码块和局部校验块进行异或计算对其进行修复,因此MXOR 的跨云数据中心修复流量较小.但是,MXOR 对编码参数具有严格的限制,要求n/k≥2.4且d≤4.
Chen 等人[15-16]和Hu 等人[17]分别提出FMSR 码和DRC 码均能有效降低跨云数据中心修复流量.然而,FMSR 和DRC 均对编码参数有严格的限制,FMSR 要求n-k=2,而DRC 码要求n,k,N(云数据中心数)至少满足2 个条件中的1 个:1)n=3z,k=2z,N=3(z为正整数);2)N=n/(n-k).
虽然上述纠删码均能在一定程度上降低跨云数据中心修复流量,但它们普遍存在编码参数适应性较差的问题,无法在满足用户对编码参数的多样化需求的同时有效降低跨云数据中心修复流量.为此,有工作[19]提出了面向跨云数据中心存储的自适应纠删码ACIoT,可求得不同编码参数(n,k,d)下的最小跨云数据中心修复流量码,即最优码.具体而言,ACIoT 首先定义了纠删码的修复组分布方案,该方案决定了纠删码的跨云数据中心修复流量.然后,ACIoT可枚举指定编码参数(n,k)下的纠删码修复组分布方案,并检验它们是否与指定编码参数(n,k,d)相匹配.最后,ACIoT 可从所有与编码参数(n,k,d)相匹配的纠删码修复组分布方案中找出具有最小跨云数据中心修复流量的1 个并将其转换为最优码生成矩阵.然而,ACIoT 忽略了容灾度对跨云数据中心修复流量下限的影响.此外,因ACIoT 需要消耗较长时间来检验纠删码修复组分布方案与编码参数(n,k,d)的匹配性,故其纠删码构造用时较长.
综上,现有的跨云数据中心纠删码无法同时满足低跨云数据中心修复流量、高编码参数适应性和高纠删码构造效率,这严重限制了其在生产系统中的运用.
除以上聚焦于数据修复的工作外,Saeed 等人[24]还考虑到RS 码等纠删码技术在读取数据时具备多种读取方案,可以通过访问不同云数据中心的节点来重构用户数据.因此,他们提出了距离优先读取策略和负载均衡优先读取策略,分别用于对读取过程的网络开销和各存储节点的负载进行优化.同时,他们对用户读取数据时的网络开销和各节点的负载进行了综合建模,得到了一个综合考虑2 方面因素的开销模型,并基于此模型提出了跨数据中心纠删码数据读取节点选择算法Sandooq,能够有效降低数据读取的综合开销.此外,我们在之前的工作中提出了一种跨云数据中心纠删码增量写入方法[25]和一种基于生成矩阵变换的跨云数据中心纠删码写入方法[26],可分别通过提高编码并行度和降低跨云数据中心写入流量来提高写入效率.
2 重要定义及定理
定义1.生成矩阵.跨云数据中心纠删码技术将用户数据划分为若干数据块,并将每k个数据块(记为xt,t∈[1,k])编码为n个编码块(记为yi,i∈[1,n]),这n个编码块被称为一个条带,编码过程如式(1)所示,其中G为纠删码的生成矩阵.生成矩阵G的秩必须为k,否则GT(z1,…,zk)T=(y1,…,yn)T没有唯一解,即无法将一个条带中的n个编码块解码为原始数据块.
定义 2.校验矩阵. 如果为G[z1,…,zk]T=0的基础解系,那么H=为对应于生成矩阵G的校验矩阵.因为G的秩为k,所以H的秩为n-k.
定义3.修复组.由生成矩阵G与校验矩阵H的定义有,GHT=0,故(y1,…,yn)HT=(x1,…,xk)GHT=0.因此,每个编码块都可以通过对其他若干个编码块进行线性计算重构.如果编码块yi可以通过对yi,1,yi,2,…,yi,r进行线性计算重构,那么{yi,yi,1,yi,2,…,yi,r}为yi的一个修复组(用于修复yi的存储节点被称为新生节点,存储yi,1,yi,2…,yi,r的节点被称为提供者节点).一个编码块可能有多个修复组.此外,由于编码块之间的线性关系由生成矩阵G或校验矩阵H决定,所以编码块的修复组也是由生成矩阵G或校验矩阵H决定的.
定义4.编码块分布方案.一个条带中的编码块所在的云数据中心的编号组成的集合为该条带的编码块分布方案R={z1,z2,…,zn},其中zi表示该条带中第i个编码块位于第zi个云数据中心.
定义5.编码块修复组分布方案.设Ti,w为编码块yi的第w个修复组,如果Ti,w中的编码块分布于t个编号分别为z1,z2,…,zt的云数据中心中(这t个云数据中心分别记为,那么令Ri,w={z1,z2,…,zt}.设编码块yi共有Qi个修复组,记为Ti,1,Ti,2,…,Ti,Qi,且(q∈[1,Qi]),那么Ri,q为编码块yi的修复组分布方案.其中,表示Ri,w中含有的云数据中心编号个数.
定义6.纠删码修复组分布方案.如果C1,C2,…,Cn分别为编码块y1,y2,…,yn的修复组分布方案,那么{C1,C2,…,Cn}为条带{y1,y2,…,yn}的修复组分布方案.通常而言,纠删码的不同编码条带中的编码块在各个云数据中心间的分布相同.在此情况下,纠删码的各个条带的修复组分布方案相同,因而条带的修复组分布方案也被称为纠删码修复组分布方案.
为了降低跨云数据中心修复流量,在基于纠删码技术的跨云数据中心存储系统修复编码块时,含有提供者节点的云数据中心通常会先将其中的提供者节点的编码块合并为一个和各个编码块大小相同中间块,然后再将中间块发往新生节点.此外,为了保持系统的容灾度和负载均衡性不变,失效编码块的新生节点通常和该失效编码块位于同一云数据中心.在此情况下,如果编码块yi的修复组分布方案为Ci且编码块大小为m,那么在修复yi时需要向其新生节点发送中间块的云数据中心(含新生节点所在云数据中心)的个数为Ci中含有的云数据中心编号个数 |Ci|,因而修复yi的最小跨云数据中心传输量为m(|Ci|-1).所以,一个纠删码的修复组分布方案为E的纠删码的编码条带的平均跨云数据中心流量为其中,C为E中的编码块修复组分布方案,n为一个编码条带中的编码块数.因此,纠删码的平均跨云数据中心修复流量由其修复组分布方案决定.
定义7.纠删码Tanner 图[23].若一个编码参数为(n,k,d,D)的纠删码CO的校验矩阵为H,那么该纠删码的Tanner 图 T 为满足3 个条件的二分图:1) T的一个端点集包含n个变量端点(variable node,VN);2)T的另一个端点集包含n-k个校验端点(check node,CN);3)当且仅当H的第i行、第j列的元素不为0,T的第j个校验端点覆盖其第i个变量端点,即 T中有一条以第j个校验端点和第i个变量端点为端点的边.图1 举例说明了纠删码的Tanner 图与纠删码校验矩阵H间的关系.

Fig.1 Erasure code’s Tanner graph图1 纠删码Tanner 图
图2 举例说明了纠删码Tanner 图与编码块和修复组之间的关系.纠删码的一个编码条带中的6 个编码块y1,y2,…,y6分别对应着该纠删码Tanner 图的6 个变量端点VN1,VN2,…,VN6.覆盖纠删码Tanner 图中的第1,4,5,6 个变量端点VN1,VN4,VN5,VN6的校验端点CN1对应的修复组为{y1,y4,y5,y6},该修复组内各编码块之间的线性关系为y1+y4+y5+y6=0.同理,校验端点CN2对应的修复组为{y2,y4,y5,y6},该修复组内各编码块的线性关系为y2+y4+2y5+4y6=0;校验端点CN3对应的修复组为{y3,y4,y5,y6},该修复组内各编码块的线性关系为y3+y4+3y5+9y6=0.

Fig.2 The relationship between the erasure code’s Tanner graph,coded blocks,and the repair groups图2 纠删码Tanner 图与编码块和修复组之间的关系
本文涉及的常用符号及其含义如表1 所示:
定理2.假设H(n-k)×n为纠删码CO的校验矩阵.当且仅当由H的第z1~zc列组成的矩阵H1的秩为c,CO能够在其各条带中的第l1~lc个编码块同时失效时修复这些失效编码块.
证明.从纠删码的校验方程(y1,…,yn)HT=0中得到的以为未知数的方程组如式(2)所示:
因为式(2)中的最大线性无关方程数等于H1的秩,所以,当且仅当H1的秩为c时,式(2)有唯一解.因此,当且仅当H1的秩为c时,能够被同条带中的其他编码块修复.证毕.
定理3.假设纠删码的编码块分布方案R已确定,即任意条带中的n个编码块被分配给N个云数据中心,亦即纠删码Tanner 图 T的n个变量端点和相应的校验矩阵H的n个列被分配给了N个云数据中心(根据定义7,纠删码Tanner 图 T的n个变量端点分别对应于校验矩阵H的n个列和任意条带中的n个编码块).在此假设下,T 匹配于编码参数(n,k,d,D)的一个充要条件是:T有n-k个校验端点、n个变量端点(子条件1);T的任意 γ个校验端点至少覆盖γ+k个变量端点,其中,γ ∈[J,n-k]且J=n-k-d+2(子条件2);T的最大匹配数不小于n-k(子条件3);任意含有B(B≤n-k)个变量端点的D个云数据中心中的任意β(β∈[1,B])个变量端点至少覆盖个校验端点(子条件4).
证明.1)必要性证明.
①子条件1 的必要性.
根据定义7,若 T匹配于编码参数(n,k,d,D),那么其对应的纠删码的生成矩阵一定有k行n列.根据纠删码Tanner 图与纠删码的生成矩阵的关系,T一定有n-k个校验端点、n个变量端点,即 T一定满足子条件1.
② 子条件2 的必要性.
如果在 T中存在 γ个校验端点(不妨设为CN1,CN2,…,CNγ)仅覆盖了w个变量端点(不妨设为VN1,VN2,…,VNw)且w≤γ+k-1,那么根据定义7,对应于T的校验矩阵如式(3)所示.其中,0γ×(n-w)为全零矩阵.
(i)如果n-w≤d-1,从纠删码的校验方程(y1,…,yn)HT=0中只能得到以yw+1,yw+2,…,yn为未知数的线性方程组:
因为n-w≤d-1,所以n-w≥n-(γ+k-1)=n-kγ+1.所以,式(4)中的具有n-w个未知数和n-k-γ个方程的方程组无唯一解.因此,yw+1,yw+2,…,yn不能由同条带中的其他编码块修复.因此,T不匹配于编码参数d.
(ii)如果n-w>d-1,从纠删码的校验方程[y1,…,yn]HT=0中只能得到以yn-d+2,yn-d+3,…,yn为未知数的线性方程组:
因为γ∈[J,n-k]且J=n-k-d+2,所以n-k-γ≤nk-(n-k-d+2)=d-2.所以,式(5)中的具有d-1个未知数和n-k-γ个方程的方程组无唯一解.因此,yn-d+2,yn-d+3,…,yn不能由同条带的其他编码块修复.因此,T不匹配于编码参数d.
综上,如果 T匹配于编码参数(n,k,d,D),T的任意 γ个校验端点至少覆盖γ+k个变量端点,其中γ∈[J,n-k]且J=n-k-d+2.
③子条件3 的必要性证明.
假设 T的最大匹配数为b<n-k且H(含有n-k行、n列)为任意一个对应于 T的校验矩阵,那么由定理1 有,H的每个n-k行、n-k列的子矩阵均不满秩.因此,H的秩不为n-k.因此,根据校验矩阵的定义,H不可能是一个(n,k,d,D)纠删码的校验矩阵.因此,T不匹配于(n,k,d,D).因此,若 T匹配于编码参数(n,k,d,D),T 的最大匹配数不小于n-k.
④ 子条件4 的必要性证明.
如果存在D个云数据中心(不妨设为),其中的 β个变量端点(不妨设为VN1,VN2,…,VNβ)只覆盖了c≤β-1个校验端点(不妨设为CN1,CN2,…,CNc),那么根据定义7,对应于 T的校验矩阵H中只有c个行中的第1~ β列中存在非零元素.因此,从纠删码的校验方程(y1,…,yn)HT=0中只能得到以y1,y2,…,yβ为变量的线性方程组:
因为式(6)中的 β元方程组的最大线性无关方程数为c(c<β),所以该方程组没有唯一解.因此,对应于 T 的纠删码的任意编码条带{y1,y2,…,yn}中的y1,y2,…,yβ不能被同条带的其他编码块修复 (T对应的纠删码不能容忍同时失效).因此,T不匹配于编码参数(n,k,d,D).
综上,若 T匹配于编码参数(n,k,d,D),任意含有B(B≤n-k)个变量端点的D个云数据中心中的任意β(β∈[1,B])个变量端点至少覆盖 β个校验端点.
2)充分性证明.
证明.假设纠删码Tanner 图 T 符合定理3 中的充要条件,那么可按5 个步骤构造出一个纠删码Tanner 图为 T的匹配于编码参数(n,k,d,D)的纠删码的生成矩阵,即 T匹配于编码参数(n,k,d,D).
①求得 T 的最大匹配.因为 T 满足定理3 中的充要条件的子条件3,所以其最大匹配包含n-k个变量端点.如果 T 的最大匹配包含,那么令H1为由H的第l1,l2,…,ln-k列组成的矩阵.由于H1的行数和列数均为n-k,所以其为方阵.然后,我们将H1加入集合LS.
② 求得H的所有的包含n-k行、d-1 列的子矩阵的集合SM1以及H的所有的包含其对应于任意D个云数据中心的列的子矩阵组成的集合SM2.
③根据纠删码Tanner 图的定义,SM1和SM2中每个矩阵都对应于 T的一个子图.因此,我们求得对应于SM1和SM2中每个矩阵所对应的 T的子图的最大匹配.而后,对于SM1和SM2中的每个矩阵Z,如果其对应的 T的子图的最大匹配包含则将其第l1,l2,…,lc行组成的子矩阵加入集合LS.
可以证明,如果SM1或SM2中的某个矩阵有q列,那么其对应的 T的子图的最大匹配一定为q(即LS中的矩阵均为方阵),证明过程为:
首先,证明如果SM1中的某个矩阵有q列,那么它的最大匹配数一定为q.由于SM1的矩阵的列数恒为d-1,因此只需要证明SM1中的矩阵对应的 T的子图的最大匹配数恒为d-1.
(i)令∂=n-k-γ+1(因为γ∈[J,n-k]且J=n-kd+2,所以∂∈[1,d-1]),可以证明 T中任意 ∂个变量端点至少覆盖 ∂个校验端点:如果存在 ∂个变量端点仅仅覆盖u≤∂-1个校验端点,那么剩下的n-k-u≥γ个校验端点最多覆盖n-∂=k+γ-1个变量端点,这与定理3 中的充要条件的子条件2(任意 γ个校验端点至少覆盖γ+k个变量端点)相矛盾.因此,任意 ∂个变量端点至少覆盖 ∂个校验端点.
(ii)根据Hall 定理[27],在 T 的任意含有d-1 个变量端点、n-k个校验端点(d-1<n-k)的子图存在完全匹配的充要条件是该子图中任意 ∂个变量端点至少覆盖 ∂个校验端点(∂∈[1,d-1]).由(i)有,T中任意∂个变量端点至少覆盖 ∂个校验,所以 T的任意含有d-1 个变量端点、n-k个校验端点(d-1<n-k)的子图存在完全匹配,即 T中任意d-1 个变量端点可以一对一地覆盖d-1 个校验端点.
(iii)假设Z为SM1中的任意矩阵且Z包含H的第l1,l2,…,ld-1列.由(ii)有,一定一对一地覆盖d-1个校验端点(不妨设为CN1,CN2,…,CNd-1).因此,为对应于Z的 T的子图的最大匹配.因此SM1中任意矩阵对应的 T的子图的最大匹配数为d-1.
然后,证明如果SM2中的某个矩阵有B列,那么它的最大匹配数一定为B.
(i)不妨假设 T中对应于任意D个云数据中心的任意B个变量端点为VN1,VN2,…,VNB.根据Hall 定理[27],T的由其VN1,VN2,…,VNB和n-k个校验端点组成的子图存在完全匹配的充要条件是该子图中任意β个变量端点至少覆盖 β个校验端点(β∈[1,B]).因为T满足定理3 中的充要条件的子条件4,即任意含有B(B≤nk)个变量端点的D个云数据中心中的任意β(β∈[1,B])个变量端点至少覆盖 β个校验端点,所以T的由其VN1,…,VNB和n-k个校验端点组成的子图存在完全匹配,即 T中对应于任意D个云数据中心的任意B个变量端点一定可以一对一地覆盖B个校验端点.
定理4.纠删码修复组分布方案E匹配于编码参数(n,k,d,D)的一个必要条件为:设ST为E中所有编码块修复组分布方案的无重复集合,对于任意D个共含有B个编码块的云数据中心(不妨设这些云数据中心的编号为z1,z2,…,zD,即设这些云数据中心为),ST中仅含有不多于n-k-B个不包含这些云数据中心的编号集合{z1,z2,…,zD}中任意元素的编码块修复组分布方案.
证明.根据定义6,如果ST中含有超过n-k-B个不包含{z1,z2,…,zD}中任意元素的编码块修复组分布方案,那么相应的纠删码有超过n-k-B个不含有中编码块的修复组.因此,根据定义7,在任何对应于E的纠删码Tanner 图(不妨设为T)中,一定有超过n-k-B个校验端点没有覆盖对应于中编码块的变量端点.因此,在T中,对应于中编码块的变量端点(不妨设为)覆盖的校验端点少于B个.因此,根据定义7,任意对应于 T的校验矩阵H中的第l1,l2,…,lB列组成的矩阵H1最多只有B-1 个非零行.因此,H1的秩小于B.因此,根据定理2,校验矩阵为H的纠删码不能容忍任意编码条带中的第l1,l2,…,lB个编码块失效,即不能容忍同时失效.因此,纠删码修复组分布方案E不匹配于编码参数(n,k,d,D).证毕.
定理5.所有匹配于指定编码参数(n,k,d,D)的纠删码修复组分布方案的平均跨数据中心修复流量的最小值为编码参数(n,k,d,D)下的纠删码的平均跨数据中心修复流量下限.
证明.令所有匹配于指定编码参数(n,k,d,D)的纠删码修复组分布方案的平均跨数据中心修复流量的最小值为T.假设存在一个满足编码参数(n,k,d,D)且平均跨数据中心修复流量小于T的纠删码(不妨设为CO),那么CO的修复组分布方案的平均跨数据中心修复流量小于T.因为所有匹配于指定编码参数(n,k,d,D)的纠删码修复组分布方案的平均跨数据中心修复流量的最小值为T,所以不匹配于编码参数(n,k,d,D),因而不存在一个满足编码参数(n,k,d,D)的纠删码的修复组分布方案为,这与CO的修复组分布方案为相矛盾.因此,不存在一个匹配于编码参数(n,k,d,D)且平均跨数据中心修复流量小于T的纠删码,即T为编码参数(n,k,d,D)下的纠删码的平均跨数据中心修复流量下限.证毕.
3 低跨云数据中心修复流量的纠删码的快速构造方法FMEL
本节提出了一种低跨云数据中心修复流量的纠删码的快速构造方法FMEL(如图3 所示),可在不同编码参数下快速求得具有低跨云数据中心修复流量的纠删码.
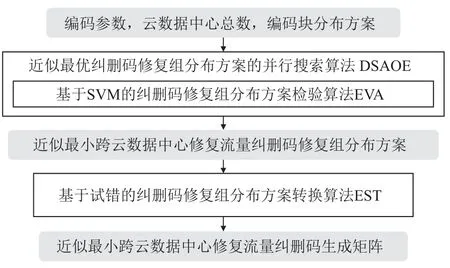
Fig.3 The structure of FMEL图3 FMEL 的结构
具体而言,基于第2 节推导出的相关定理,本节首先得出纠删码修复组分布方案匹配指定编码参数(n,k,d,D)的条件,并以此为依据提出了一种基于SVM 的纠删码修复组分布方案检验算法(erasure code repair group distribution scheme verification algorithm based on SVM)EVA,可对纠删码修复组分布方案与编码参数匹配性进行快速检验.
然后,本节提出了一种具有近似最小跨云数据中心修复流量的纠删码修复组分布方案的并行搜索算法(distributed search algorithm of the erasure code repair group distribution scheme with the approximate minimum cross-cloud data center repair traffic)DSAOE,可从所有通过EVA 检验的纠删码修复组分布方案中选出平均跨云数据中心修复流量较小的一个纠删码修复组分布方案.
最后,本节提出一种纠删码修复组分布方案转换算法(erasure code repair group distribution scheme transformation algorithm)EST,可将DSAOE 搜索到的修复组分布方案转换为具有低跨云数据中心修复流量的纠删码的生成矩阵.
3.1 纠删码修复组分布方案匹配于指定(n,k,d,D)的条件
1)纠删码修复组分布方案匹配于指定(n,k,d,D)的充要条件
纠删码修复组分布方案是由纠删码的编码块的修复组和位置决定.如果将一个纠删码Tanner 图的各个变量端点分配给不同的云数据中心,那么纠删码Tanner 图可以同时反映相应纠删码的编码块的修复组及位置.因此,每个纠删码Tanner 图对应一个纠删码修复组分布方案.因为多个纠删码Tanner 图可能对应同一个纠删码修复组分布方案,所以每个纠删码修复组分布方案通常对应多个纠删码Tanner 图.纠删码Tanner 图 T匹配于编码参数(n,k,d,D)是指存在一个Tanner 图为 T的纠删码的编码参数为(n,k,d,D).因此,若一个纠删码修复组分布方案所对应的纠删码Tanner 图中,有不少于一个纠删码Tanner 图匹配于编码参数(n,k,d,D),则该方案匹配于编码参数(n,k,d,D),反之则该方案不匹配于编码参数(n,k,d,D).即纠删码修复组分布方案匹配于编码参数(n,k,d,D)的充要条件是至少存在一个与之对应的Tanner 图满足定理3 中的子条件1~4.
2)纠删码修复组分布方案匹配于指定(n,k,d,D)的必要条件
纠删码修复组分布方案匹配于编码参数(n,k,d,D)的一个必要条件如定理4 所示.
3.2 EVA 算法
基于3.1 节得出的纠删码修复组分布方案匹配指定编码参数(n,k,d,D)的条件,首先,EVA 把纠删码修复组分布方案和对应的编码参数转换为便于分类算法高效处理的定长特征向量,转换过程能够保留判断纠删码修复组分布方案是否匹配于指定编码参数所需的全部信息,因而能够保证分类的准确性.此外,EVA 使用一个SVM 来对定长特征向量进行分类以达到快速检验纠删码修复组分布方案是否匹配于对应的编码参数的目的.在分类过程中,EVA 可以持续收集更多带标签定长特征向量,并使用这些定长特征向量对SVM 分类器进行增量更新,从而达到不断提高分类准确率的目的.EVA 使用3.1 节推导出的纠删码修复组分布方案匹配于指定编码参数(n,k,d,D)的条件为定长特征向量打标签,以得到SVM 分类器的初始训练数据集和增量更新数据集.
3.2.1 特征向量构造
基于SVM 的EVA 对纠删码修复组分布方案进行转换:
首先,由定义6 有,如果可用云数据中心的数目为N,那么编码块的修复组分布方案C一共有2N-1个可能的取值.因此,EVA 将把这 2N-1个可能的取值一一映射为1,2,…,2N-1,映射函数如式(9)所示.
然后,对于每个云数据中心,EVA 将统计出纠删码修复组分布方案中对应于该云数据中心中的编码块的修复组分布方案的映射值中1,2,…,2N-1出现的次数,从而得到了一个长度为N(2N-1)的定长特征向量X',该向量中的第a×b个元素的值为c表示第a个云数据中心中有c个编码块的修复组分布方案的映射值为b.例如,如图4 所示,如果纠删码修复组分布方案为{{1},{1,2},{1,2},{2,3},{1,2,3},{1,2,3}}、云数据中心总数为3、编码条带中的第1,2 个编码块位于第1个云数据中心、编码条带中的第3,4 个编码块位于第2 个云数据中心、编码条带中的第5,6 个编码块位于第3 个云数据中心,那么其中各个编码块修复组分布方案的映射值分别为1,3,3,6,7,7,因而相应的X'=(1,0,1,0,0,0,0,0,0,1,0,0,1,0,0,0,0,0,0,0,2).
因为X'中含有各个云数据中心中的对应于不同修复组分布方案的编码块数目,所以使用X'可以恢复出各个云数据中心中的编码块的修复组分布方案的无序集合.例如,从X'=(1,0,1,0,0,0,0,0,0,1,0,0,1,0,0,0,0,0,0,0,2)的第3× 7 个元素为2 可以推导出第3 个云数据中心中有2 个编码块的修复组分布方案的映射值为7,即它们的修复组分布方案为{1,2,3}.因此,和原始的纠删码修复组分布方案相比,X'中仅仅丢失了各个编码块在各云数据中心内的顺序信息.因为各个编码块在各云数据中心内的顺序并不影响纠删码的冗余度、容错度和容灾度,因此纠删码修复组分布方案转换过程没有丢失判断一个其是否匹配于编码参数(n,k,d,D)所需的有效信息.
在将纠删码修复组分布方案转换为一个数值型的定长特征向量X'后,EVA 将n,k,d,D追加到X'即可得到用于表示纠删码修复组分布方案及其对应编码参数(n,k,d,D)的特征向量X,其长度恒为N(2N-1)+4.
3.2.2 基于SVM 的特征向量分类
由于匹配于编码参数(n,k,d,D)的纠删码修复组分布方案之间以及不匹配于编码参数(n,k,d,D)的纠删码修复组分布方案之间均有一定的相似性,所以匹配于编码参数(n,k,d,D)的纠删码修复组分布方案对应的特征向量之间以及不匹配于编码参数(n,k,d,D)的纠删码修复组分布方案对应的特征向量之间存在一定的相似性.因此,可以采用有监督学习算法[28-29]来对纠删码修复组分布方案对应的特征向量进行分类:使用一些已知匹配于编码参数(n,k,d,D)的纠删码修复组分布方案对应的特征向量和已知不匹配于编码参数(n,k,d,D)的纠删码修复组分布方案对应的特征向量作为训练集来训练一个分类器.分类器会判断新的纠删码修复组分布方案对应的特征向量是否和已知匹配于编码参数(n,k,d,D)的纠删码修复组分布方案对应的特征向量相似,如果相似则判断其匹配于编码参数(n,k,d,D),反之则判断其不匹配于编码参数(n,k,d,D).由于SVM 具有分类速度快以及可对线性不可分的数据进行分类等优点[30-32],所以可以基于SVM 对纠删码修复组分布方案对应的特征向量进行分类,以达到快速检验纠删码修复组分布方案的目的.
EVA 的工作流程如算法1 所示.
算法1.EVA 算法.
1)初始训练集获取
EVA按4 步获取用于构造初始SVM 分类器的训练集:
①随机抽取部分编码参数下的部分纠删码修复组分布方案(不妨设纠删码修复组分布方案的集合为TE);
② 将TE中的纠删码修复组分布方案及其对应的编码参数转换为定长特征向量;
③对于TE中的任意一个纠删码修复组分布方案E,枚举其对应的纠删码Tanner 图,并使用纠删码Tanner 图匹配于指定编码参数(n,k,d,D)的充要条件来检验这些纠删码Tanner 图是否存在1 个匹配(n,k,d,D),从而判断E是否匹配于(n,k,d,D),即得到E对应定长特征向量的类别标签;
④ 将所有打上类别标签的特征向量组合为SVM 分类器的初始训练集(算法1 的行①~⑧),由于当云数据中心数N固定时,所有纠删码修复组分布方案的特征向量长度相同,所以同一套部署环境下只需要准备一份初始训练集.
2)分类器增量更新
SVM 的分类器的本质是一个能将高维空间一分为二的决策超平面,而其分类特征向量的本质则是判断被投射到高位空间后的特征向量位于决策超平面的哪一侧.在SVM 中,能够对决策超平面(分类器)的构造造成影响的特征向量为有效特征向量.当初始训练集中的有效特征向量的数目有限时,首次训练出的分类器很难反映真实的数据分布情况,使得其无法对特征向量进行准确分类.针对这个问题,基于SVM 的EVA 将在训练分类器时筛选出训练集中的有效特征向量,并在分类的同时持续收集新的已知确切类别的特征向量.然后,EVA 将挑选部分新收集的特征向量与旧训练集中的有效特征向量组成新的训练集,并使用新的训练集训练出一个新的分类器(算法1 的行 ㊻~㊽).因为新的训练集同时包含新收集的特征向量中的有效特征向量和旧训练集中有效特征向量,所以新的分类器的分类准确性更高.
增量学习的关键是如何从旧训练集中挑选出有效特征向量以及如何获取新的有效特征向量:
①旧的训练集的有效特征向量.EVA 会在训练分类器的同时获取一组支持向量,这些支持向量决定了决策超平面.也就是说,这些支持向量即为旧训练集中的有效特征向量.因此,EVA 直接将这些支持向量加入到新的训练集中.
② 新收集的特征向量中的有效特征向量.如果分类器对一个特征向量进行了误分类,那么意味着现有的分类器(决策超平面)缺少该特征向量的信息.因此,如果将该特征向量加入到新的训练集中,新的决策超平面将与旧的决策超平面有所不同.所以,新收集的特征向量中被旧分类器错误分类的部分即为有效特征向量.因此,EVA 将这些支持向量加入到新的训练集中.
具体而言,EVA 搜集新的有效特征向量以及检验纠删码修复组分布方案的具体过程如图5 所示.

Fig.5 Verification process of erasure code repair group distribution scheme图5 纠删码修复组分布方案检验过程
首先,EVA 分别用纠删码修复组分布方案匹配于指定编码参数的必要条件和分类器来检验输入的纠删码修复组分布方案.
如果分类器和纠删码修复组分布方案匹配于指定编码参数的必要条件的检验结果均为某个纠删码修复组分布方案E匹配于编码参数(n,k,d,D),EVA则使用纠删码Tanner 图匹配于指定编码参数的充要条件来检验E的纠删码Tanner 图.如果存在一个E的纠删码Tanner 图匹配于编码参数(n,k,d,D),则可确定E匹配于编码参数(n,k,d,D).反之,如果不存在任何一个E的纠删码Tanner 图匹配于编码参数(n,k,d,D),则可确定E不匹配于编码参数(n,k,d,D)且分类器对E对应的的特征向量进行了错误分类,此时E对应的特征向量将被加入新的训练集(算法1 的行⑭~㉗).
如果分类器的分类结果是某个纠删码修复组分布方案E不匹配于编码参数(n,k,d,D),EVA 将在较小的概率Po下使用纠删码Tanner 图匹配于指定编码参数的充要条件对E进行检验(以检验分类器的分类结果)——因为分类器误分类频率越小,检验它的分类结果的必要性越小,所以Po始终等于分类器的当前误分率.如果存在一个E的纠删码Tanner 图符合其匹配于指定编码参数的充要条件,可以确定E匹配于编码参数(n,k,d,D)且分类器对E进行了错误分类,此时E对应的特征向量将被加入新的训练集.如果EVA 没有使用纠删码Tanner 图匹配于指定编码参数的充要条件对E进行检验或者不存在一个对应于E的纠删码Tanner 图符合其匹配于指定编码参数的充要条件,那么EVA 将E视为不通过检验的纠删码修复组分布方案(算法1 的行㉘~㊷).
如果分类器的分类结果是某个纠删码修复组分布方案E匹配于编码参数(n,k,d,D)但E不符合其匹配于指定编码参数的必要条件,那么可以确定E不匹配于编码参数(n,k,d,D)且分类器对其进行了误分类,此时E对应的特征向量将被加入新的训练集(算法1 的行㊸~㊺).
3.3 近似最优纠删码修复组分布方案搜索算法
3.2 节提出EVA 可快速检验纠删码修复组分布方案是否匹配于指定编码参数(n,k,d,D).DSAOE 可从所有能通过EVA 检验的纠删码修复组分布方案中挑选出具有最小平均跨云数据中心修复流量的一个纠删码修复组分布方案.
根据定义6,当云数据中心数目N、编码参数n以及条带分布方案确定时,相应的所有纠删码修复组分布方案均可被枚举出来.此外,每个纠删码修复组分布方案对应一个平均跨云数据中心修复流量.
因此,DSAOE 的主要思想是:当云数据中心数N,编码块数n和编码块分布方案被指定后,枚举出所有与它们相对应的纠删码修复组分布方案,并将这些纠删码修复组分布方案按它们对应的平均跨云数据中心修复流量递增的顺序排序.然后,对纠删码修复组分布方案进行分组并采用多个计算节点对各组纠删码修复组分布方案进行并行检验——各个计算节点使用EVA 对其进行检验.各个计算节点中第一个通过EVA 检验的纠删码修复组分布方案即为局部最小跨云数据中心修复流量纠删码修复组分布方案.各个计算节点的局部最小跨云数据中心修复流量纠删码修复组分布方案中具有最小平均跨云数据中心修复流量的一个纠删码修复组分布方案即为DSAOE 的输出.
DSAOE 使用1 个协调者节点和多个工作节点来并行完成最优纠删码修复组分布方案的搜索,其具体分工为:
1)协调者节点
协调者节点的工作流程如算法2 所示.
算法2.DSAOE 的协调节点的工作流程.
输入:编码参数(n,k,d,D),云数据中心总数N,编码块分布方案R,Worker总数W;
输出:全局最优解GO(包括近似最小跨云数据中心修复流量修复组分布方案及其对应的最优纠删码Tanner 图和平均跨云数据中心修复流量).
当协调者节点接收到编码参数(n,k,d,D)、云数据中心总数N以及条带的编码块分布方案R后,协调者节点将枚举所有可能的纠删码修复组分布方案并计算出这些纠删码修复组分布方案的平均跨云数据中心修复流量(算法2 的行②)——根据定义6,纠删码的修复组分布方案E的平均跨云数据中心流量为(C为E中的编码块修复组分布方案、n为一个编码条带中的编码块数),所以协调者节点计算纠删码修复组分布方案的平均跨云数据中心修复流量的开销较低.
然后,协调者节点将这些纠删码修复组分布方案随机分成若干子集并分发到若干工作节点进行检验(算法2 的行③④).工作节点检验这些子集时,协调者节点负责维护临时全局近似最小跨云数据中心修复流量纠删码修复组分布方案及其对应的临时全局近似最小平均跨云数据中心修复流量(算法2 的行⑤~⑮).
2)工作节点
工作节点的工作流程如算法3 所示.
算法3.DSAOE 的工作节点的工作流程.
输入:编码参数(n,k,d,D),编码块分布方案R,纠删码修复组分布方案组subSet,云数据中心数N,分类器svm;
在接收到协调者节点发来的纠删码修复组分布方案的集合后,各个工作节点首先将这些纠删码修复组分布方案按平均跨云数据中心修复流量递增的顺序进行排列(算法3 的行①).然后,工作节点依次读取这些纠删码修复组分布方案.如果一个纠删码修复组分布方案的平均跨云数据中心修复流量小于临时全局近似最小平均跨云数据中心修复流量,那么工作节点将使用EVA 对其进行检验.第1 个通过EVA 的检验的即为局部最低跨云数据中心修复流量纠删码修复组分布方案,其对应的平均跨云数据中心修复流量即为局部近似最小平均跨云数据中心修复流量.一旦一个工作节点得到了局部最低跨云数据中心修复流量纠删码修复组分布方案和局部近似最小平均跨云数据中心修复流量,它便立即停止后续纠删码修复组分布方案的检验,并分别用它的局部最低跨云数据中心修复流量纠删码修复组分布方案和局部近似最小平均跨云数据中心修复流量来更新协调者节点中的临时全局最低跨云数据中心修复流量纠删码修复组分布方案和临时全局近似最小平均跨云数据中心修复流量(算法3 的行②~⑭).
当所有的工作者节点均停止检验纠删码修复组分布方案时,协调者节点中的临时全局近似最小跨云数据中心修复流量纠删码修复组分布方案和临时全局近似最小平均跨云数据中心修复流量即为DSAOE 得到的近似最小跨云数据中心修复流量纠删码修复组分布方案和平均跨云数据中心修复流量近似下限.
由于在EVA 的分类器将一个纠删码修复组分布方案分为正类后,EVA 还会使用纠删码Tanner 图匹配于指定编码参数的充要条件对其进行检验,因此DSAOE 得到的全局最优纠删码修复组分布方案一定匹配于编码参数(n,k,d,D).
如果EVA 的误报率为0,DAOSE 可获得所有通过EVA 检验的纠删码修复组分布方案中平均跨数据中心修复流量最小的一个.根据定理5,该纠删码修复组分布方案能达到相应编码参数下的平均跨数据中心修复流量下限,即该纠删码修复组分布方案为最优纠删码修复组分布方案.若EVA 的误报率P>0,且一共存在Q个最优纠删码修复组分布方案,那么DAOSE 错过所有最优纠删码修复组分布方案的概率不超过PQ.因此,FMEL 可以得到最优码的概率不低于1-PQ.
此外,因为DSAOE 使用EVA 来对大多数纠删码修复组分布方案进行快速检验,所以其效率较高.另外,DSAOE 的并行度高的特点可进一步保证其搜索效率.
3.4 基于试错的纠删码修复组分布方案转换算法
3.3 节提出了DSAOE 能搜索到近似最小跨云数据中心修复流量纠删码修复组分布方案.本节提出了一种基于试错的纠删码修复组分布方案转换算法EST,用于将近似最小跨云数据中心修复流量纠删码修复组分布方案转换为相应的纠删码生成矩阵.
EST 的工作流程如算法4 所示.
算法4.EST 算法.
输入:全局最优解GO(包括近似最小跨云数据中心修复流量纠删码修复组分布方案及其对应的最优纠删码Tanner 图和平均跨数据中心修复流量);
输出:近似最小跨云数据中心修复流量纠删码的生成矩阵G.
1)对于指定的纠删码修复组分布方案,DSAOE只有在找到一个与其相对应的匹配于编码参数(n,k,d,D)的纠删码Tanner 图时才会确认该纠删码修复组分布方案匹配于编码参数(n,k,d,D).因此,DSAOE 在搜索近似最小跨云数据中心修复流量纠删码修复组分布方案的同时也得到了与之相对应的近似最小跨云数据中心修复流量纠删码Tanner 图 T,如算法4 的行①所示.
2)令U为如式(10)所示的柯西矩阵,基于试错的纠删码修复组分布方案转换算法EST 将构造一个对应于 T 的校验矩阵H:如果 T的第j个校验端点覆盖其第i个变量端点,那么H的第j行i列的值等于U的第j行i列的值.如果 T的第j个校验端点不覆盖其第i个变量端点,那么hji的值为0,如算法4的行②所示.
3)EST 获取H的所有包含n-k行d-1 列的子矩阵的集合SM1以及H的所有包含其对应于任意D个云数据中心的列的子矩阵的集合SM2.根据定义7,SM1和SM2中的任意矩阵均对应于一个 T的子图,如算法4 的行③④所示.
4)EST 获取 T的最大匹配.因为 T符合其匹配于指定编码参数的充要条件的子条件3,其最大匹配中包含n-k个变量端点,不妨设 T 的最大匹配包含,随后,EST 求得由H的第l1,l2,…,ln-k列组成的子矩阵H1.显然,H1是一个方阵(n-k行、n-k列).同时,EST 将H1加入到集合LS中,如算法4的行⑤⑥所示.
5)基于试错的纠删码修复组分布方案转换算法EST 获取对应于SM1和SM2中各个矩阵 T的各个子图的最大匹配.对于SM1和SM2中的各个矩阵Z,如果它对应 T的子图的最大匹配中包含的所有校验端点为则将Z的第l1,l2,…,la行组成的子矩阵添加到集合LS中.根据定理3 中的纠删码Tanner 图匹配于指定编码参数的充要条件的充分性证明的步骤③,LS中的矩阵均为方阵,如算法4 的行⑦~⑩所示.
6)EST 通过初等行变换将LS中的各个矩阵转换为如式(11)所示的上三角矩阵(转换过程见定理3中的纠删码Tanner 图匹配于指定编码参数的充要条件的充分性证明的步骤④),并获得这些上三角矩阵的对角元素的集合NE=,其中,为不包含的线性多项式,如算法4 的行⑫所示.
7)EST 考察NE中的各个对角元素是否为0.如果NE中某个元素的值为0(不妨设),则进行操作:对进行加1 操作;更新H,LS;重新构造上三角矩阵并更新集合NE;重新考察NE中各个元素的值.直到NE中的各个元素的值均不为0,如算法4 的行⑬~⑱所示,根据定理3 中的纠删码Tanner 图匹配于指定编码参数的充要条件的证明过程,此时LS中的矩阵均满秩.其中,LS中的H1满秩意味着H满秩.此外,由定理2 可知,LS中的其他矩阵满秩意味着此时的H对应的纠删码CO能够容忍任意d-1 个编码块失效或任意D个云数据中心失效(即H为一个匹配于(n,k,d,D)的校验矩阵).事实上,在我们的多次实验中,初始NE中的各个元素的值全不为0.也就是说,在大多数情况下,不需要对NE、LS和H进行更新即可一次性得到最终的校验矩阵H.
8)EST 对H执行初等行变换以得到矩H′=然后,EST 构造G′=和.显然,G′(H′)T=0.因此GHT=G′·(ΔT)-1ΔT(H′)T=G′In×n(H′)T=0.因此,G为对应于H的生成矩阵,即对应于近似最小跨云数据中心修复流量纠删码修复组分布方案的生成矩阵,如算法4 的行⑲所示.
3.5 FMEL 方法描述
低跨云数据中心修复流量的纠删码的快速构造方法FMEL 的工作流程如算法5 所示.
算法5.算法FMEL.
输入:编码参数(n,k,d,D),云数据中心总数N,编码块分布方案R,Worker总数W,云数据中心数N;
输出:G.
①全局最优解GO←DSAOE(n,k,d,D,N,R,W,N);
②G←EST(GO);
③returnG.
首先,FMEL 通过DSAOE 从所有能通过基于SVM 的EVA 的检验的纠删码修复组分布方案中选出具有较小平均跨云数据中心修复流量的一个纠删码修复组分布方案,如算法5 的行①所示.挑选出的纠删码修复组分布方案即为近似最小跨云数据中心修复流量纠删码修复组分布方案.然后,FMEL 通过EST 将近似最小跨云数据中心修复流量纠删码修复组分布方案转换为相应编码参数下的近似最小跨云数据中心修复流量纠删码生成矩阵G,如算法5 的行②所示.
4 实验与结果
4.1 方法实现
为了评估FMEL 构造出的近似最小跨云数据中心修复流量纠删码的实际性能,我们基于OpenEC[33]和FastDFS[34]实现了FMEL 构造出的纠删码.其中,OpenEC 是一种用于在已有的分布式文件系统中实现不同的纠删码编码方法和修复方法的可定制框架,FastDFS 是一种轻量级的文件系统.
具体而言,我们首先在原始的FastDFS 上增加了对OpenEC 的支持.然后,我们在OpenEC 上实现了FMEL,用于构造近似最小跨云数据中心修复流量纠删码生成矩阵.最后,基于OpenEC 的编码方法和修复方法定制功能,实现了近似最小跨云数据中心修复流量纠删码的数据编码方法和数据修复方法.
4.2 实验环境与参数
实验部署于UCloud[35]的6 个云数据中心,其中2 个位于北京(记为PEK1 和PEK2)、1 个位于上海(记为SHA)、1 个位于洛杉矶(记为LOS)、1 个位于台北(记为TPE)、1 个位于广州(记为CAN).实验使用了每个云数据中心的10 个存储节点(云主机),每个节点配备4 核Intel Cascadelake 6248R 3.0 GHz 处理器,8 GB 内存和1 TB 磁盘,外网最大带宽为800 Mbps,内网最大带宽为25 Gbps.
为了评估FMEL 构造出的近似最小跨云数据中心修复流量纠删码的性能,我们将其与典型的纠删码进行了比较:最优码构造方法ACIoT 构造出的最优码(因为原始的ACIoT 只能构造出指定编码参数(n,k,d)下的最优码,我们对其进行了扩展,使其能够构造出指定编码参数(n,k,d,D)下的最优码)、一种能够达到平均局部性下限的纠删码ACL 码[23]、经典的RS 码[36]、一种典型的局部性码Xorbas 码[22]和一种典型的跨云数据中心纠删码DFC 码[13].
为了评估FMEL 构造出的近似最小跨云数据中心修复流量纠删码在不同环境中的性能,我们将UCloud 的6 个云数据中心分为了2 个实验环境.由于大多数的跨云数据中心存储系统均是部署在3 个云数据中心[1,14],所以我们的每个实验环境均包含3个云数据中心.具体而言,实验环境1 包含PEK1,PEK2,SHA,实验环境2 包含LOS,TPE,CAN.由于各个实验环境包含3 个云数据中心,因而容灾度D的合理取值范围为[1,2],所以实验中D∈[1,2].此外,在实际应用中,为了便于条带管理,单个条带内的编码块数n通常较小.因此,我们在实验中将n的范围限制在[6,11](常见的生产系统中的n均处于该范围内[37-39]).另外,实验中单个条带内的数据块数k的取值范围为[n/3,2n/3],因为当k属于此范围时D的取值范围为[1,2].最后,容错度d的取值范围为[2,n-k+1],即d的合理取值范围[1,12-18].
在本文实验中,各个编码条带的编码块被平均分配到各个云数据中心中,以获取较高的容灾度和负载均衡性.此外,新生节点与其相应的失效编码块位于同一云数据中心,以保持系统的容灾度和负载均衡性.实验中的编码块大小和HDFS 一致[35],为128 MB.
4.3 评价指标
我们用4 个指标来评价FMEL 的性能:
1)分类器误报率(false-negative rate,FN).假设被FMEL 中的SVM 分类器误分类为负类(不满足编参数(n,k,d,D)的类)的纠删码修复组分布方案的数目为f1,EVA 检验过的纠删码修复组分布方案中匹配于编码参数(n,k,d,D)的纠删码修复组分布方案数为f2,那么分类器误报率为f1/f2.
2)纠删码构建时间(construction time,CT).纠删码构造时间是指ACIoT 构造最优码的时间或FMEL构造近似最小跨云数据中心修复流量纠删码的时间.
3)平均跨云数据中心修复流量T.令某纠删码修复它的一个条带中的n个编码块产生的跨云数据中心修复流量分别为T1,T2,…,Tn且每个编码块的大小为m,那么该纠删码的平均跨云数据中心修复流量
4)平均修复用时t.令某纠删码在实验环境1 中修复它的一个条带中的n个编码块所消耗的时间分别为t1,1,t1,2,…,t1,n,在实验环境2 中修复它的一个条带中的n个编码块所消耗的时间分别为t2,1,t2,2,…,t2,n,每个编码块的大小为m.因为tj,i受到云数据中心的排列顺序的影响,令为tj,i在不同云数据中心的排列顺序下的平均值.那么,该纠删码的平均修复用时
4.4 分类器误报率
在FMEL 中,SVM 分类器将一个纠删码修复组分布方案分为正类后,还会使用纠删码Tanner 图匹配于指定编码参数的充要条件对其进行检验,因此FMEL 不会将不匹配于编码参数(n,k,d,D)纠删码修复组分布方案错误分为正类.此外,如果SVM 分类器将一个匹配于编码参数(n,k,d,D)的纠删码修复组分布方案错误分为负类,FMEL 可能会错过具有较小平均跨云数据中心修复流量且匹配于编码参数(n,k,d,D)的纠删码修复组分布方案.因此,我们主要关注分类器将纠删码修复组分布方案错误分为负类的概率,即误报率.
我们的测试数据包括所有编码参数下的所有纠删码修复组分布方案.在分类器初始化时,首先在各组编码参数下随机挑选了50 个纠删码修复组分布方案并将这些纠删码修复组分布方案转换为对应的特征向量.然后,使用纠删码修复组分布方案匹配于编码参数(n,k,d,D)的充要条件判断这些纠删码修复组分布方案是否满足各自的编码参数,并以此为依据为对应的特征向量打上标签.因此,我们可以得到这些纠删码修复组分布方案对应的带标签的特征向量,它们组成了分类器的初始训练集(10 次实验的平均初始训练集构造用时为1 711 s、平均初始分类器构造用时为192 s).然后,我们按编码参数n递增的顺序将其他的纠删码修复组分布方案输入到分类器中进行分类.与此同时,FMEL 不断搜集新的训练集对分类器进行增量更新.
分类器分类每组(n,k)对应的所有纠删码修复组分布方案的误报率如图6 所示.因为在分类过程中含有效信息的特征向量被逐渐加入到新的训练集中,并不断更新分类器,因此分类器的误报率随着n的增加而逐渐降低.

Fig.6 False-negative rate of SVM’s classifier图6 SVM 分类器的误报率
因为同一组编码参数下的最优码往往存在多个,所以最优纠删码修复组分布方案也往往存在多个.假设一共存在Q个最优纠删码修复组分布方案且分类器的误报率为P,那么FMEL 错过所有最优纠删码修复组分布方案的概率不超过PQ.因此,FMEL 可以得到最优码的概率不低于1-PQ.由图6 可知,P总是小于27%的.所以,如果Q>1,FMEL 有92.7%的概率得到最优码;如果Q>2,FMEL 则有98%的概率得到最优码.
4.5 纠删码构造时间
每组(n,k)对应多组(n,k,d,D),FMEL 和ACIoT在每组(n,k)对应的所有(n,k,d,D)下的纠删码构造时间如图7 所示(FMEL 的工作节点数和ACIoT的工作进程数均为5).在构造最优码或近似最小跨云数据中心修复流量纠删码时,ACIoT 和FMEL 均需要枚举和检验部分纠删码修复组分布方案的纠删码Tanner 图.由于编码参数(n,k,d,D)下的纠删码Tanner图的总数为2n(n-k),所以,通常而言,n(n-k)越大,ACIoT和FMEL 需要检验的纠删码Tanner 图越多.因此,ACIoT和FMEL 的纠删码构造时间均呈现出随着n(n-k)的减少而减少的趋势.

Fig.7 Erasure code construction time of ACIoT and FMEL图7 ACIoT 和FMEL 的纠删码构造时间
对于大部分的纠删码修复组分布方案,FMEL 仅需要用SVM 分类器对它们分类即可,无需枚举和检验它们对应的纠删码Tanner 图.因此,FMEL 的平均纠删码构造时间仅为ACIoT 的11%.特别地,当n(n-k)较小时,总的纠删码构造时间较短.所以,此时FMEL中更新分类器的时间占总的纠删码构造时间的比例较大.因此,此时FMEL 的纠删码构造时间比ACIoT 略长.
4.6 平均跨云数据中心修复流量
因为不同的纠删码适应的编码参数不同,我们首先在除RS 码外的所有纠删码都适应的编码参数下比较了各个纠删码的平均跨云数据中心修复流量(RS码使用和其他纠删码相近的编码参数),如图8 所示.在这些编码参数下,DFC 码和ACIoT 均可为每个云数据中心分配一个局部校验块,因此,DFC 和ACIoT 均能够在不跨云数据中心传输数据的情况下完成编码块的修复,因而它们的平均跨云数据中心修复流量为0.大多数情况下,FMEL 的平均跨云数据中心修复流量也为0,即FMEL 有较大概率得到最优码.

Fig.8 Average cross-cloud data center repair traffic of ACL,Xorbas,DFC,RS,ACIoT and FMEL图8 ACL 码、Xorbas 码、DFC 码、RS 码、ACIoT 和FMEL 的平均跨云数据中心修复流量
因为RS 码在修复任意一个编码块时均需要读取k个编码块,而在实验中使用的全部编码参数下各编码条带在同一个云数据中心的编码块数始终小于k(如果要使各编码条带在同一个云数据中心的编码块数始终不小于k,那么冗余度将十分大),所以RS码在修复任意一个编码块时均需要跨云数据中心传输数据.因此,RS 码跨云数据中心修复流量最大.
因为Xorbas 码和ACL 码具有较低的修复流量(其中ACL 码能够达到平均修复流量的下限),所以它们能在一定程度上降低平均跨云数据中心修复流量,进而使得它们的平均跨云数据中心修复流量相较于局部性为k-1 的RS 码更小.但是,由于修复流量不与跨云数据中心修复流量严格正相关,所以ACL码和Xorbas 码的平均跨云数据中心修复流量大于ACIoT,FMEL,DFC 码.
因为RS 码和DFC 码对编码参数的限制较为严格,我们在更多的编码参数下比较了其他纠删码.如图9 所示,在这些编码参数下,FMEL 的平均跨云数据中心修复流量比ACL 码和Xorbas 码分别低了24.0%和34.8%,这是因为FMEL 能在这些参数下达到平均跨云数据中心修复流量的近似下限.

Fig.9 Average cross-cloud data center repair traffic of ACL,Xorbas,ACIoT and FMEL图9 ACL 码、Xorbas 码、ACIoT 和FMEL 的平均跨云数据中心修复流量
平均而言,FMEL 的平均跨云数据中心修复流量比ACL 码、Xorbas 码和RS 码分别低了42.9%,51.1%,56.0%.此外,FMEL 的平均跨云数据中心修复流量与DFC 码相近,但DFC 码对编码参数限制严格.
另外,FMEL 的平均跨云数据中心修复流量是ACIoT的100%~133%,并且在实验采用的15 组编码参数中的13 组编码参数下,FMEL 的平均跨云数据中心修复流量与ACIoT 相同,即FMEL 构造出最优码的概率较高.
容错度d和FMEL 构造的近似最小跨云数据中心修复流量纠删码的平均跨云数据中心修复流量之间的关系如图10 所示,当d小于一个特定值d'后,近似最小跨云数据中心修复流量纠删码的平均跨云数据中心修复流量,即平均跨云数据中心修复流程近似下限.这是因为当d<d'时,的主要影响因素为容灾度D.基于这一发现,不仅能够得到编码参数(n,k,D)下的平均跨云数据中心修复流量的近似下限,还可以得到满足该近似下限时的d的上限,即图中的最优d.

Fig.10 Relationship between d and average cross-cloud data center repair traffic’s approximate lower bound under different n,k,D图10 不同n,k,D 下d 与平均跨云数据中心修复流量近似下限的关系
因为与最优d相对应的编码参数和近似最小跨云数据中心修复流量纠删码能够在冗余度()、容错度(d)、容灾度(D)和平均跨云数据中心修复流量()之间取得较好权衡,因此关于最优d的这一发现对于实际应用具有指导意义.比如说,基于这一发现,我们找到了2 个能够在冗余度、容错度、容灾度和平均跨数据修复流量之间取得较好权衡的纠删码——FMEL(n=6,k=2)和FMEL(n=9,k=5,其生成矩阵如式(12)和式(13)所示.
如表2 所示,FMEL(n=6,k=2)的d值比3 副本技术高66.7%,同时,FMEL(n=6,k=2)的D、和和3 副本技术相同.此外,FMEL(n=9,k=5)的D比2 副本技术高33.3%,同时FMEL(n=9,k=5)的和比2副本技术低10%和33%且二者D相同.

Table 2 Comparison Between FMEL and Replications表2 FMEL 与多副本的对比
4.7 平均修复用时
因为不同的纠删码适应的编码参数不同,我们首先在除RS 码外的所有纠删码都适应的编码参数下比较了各个纠删码的平均修复用时(RS 码使用和其他纠删码相近的编码参数),如图11 所示.

Fig.11 Average repair time of ACL,Xorbas,DFC,RS,ACIoT and FMEL图11 ACL 码、Xorbas 码、DFC 码、RS 码、ACIoT 和FMEL 的平均修复用时
由于FMEL 和ACIoT 的平均跨云数据中心修复流量小于对照组中的其他纠删码,其修复数据时跨云数据中心传输数据的时间较短,使得其平均修复用时也比其他纠删码少.具体地,FMEL 的平均修复用时比ACL 码、Xorbas 码和RS 码分别少了36.9%,46.1%,50.6%.此外,ACIoT 的平均修复用时与FMEL相近,但是ACIoT 的纠删码构造时间更长.
因为RS 码和DFC 码的编码参数适应性较差,我们在更多的编码参数下对除这2 种纠删码之外的纠删码进行了对比,如图12 所示.在这些编码参数下,FMEL 和ACIoT 的平均修复用时少于ACL 码和Xorbas码,这是因为基于FMEL 和ACIoT 的平均跨云数据中心修复流量较小.特别地,在编码参数为(8,3,5,1)时,FMEL 和ACIoT 的平均修复用时远低于其他纠删码,因为此时只有它们能够在不跨云数据中心传输数据的情况下完成数据修复.

Fig.12 Average repair time of ACL,Xorbas,ACIoT and FMEL图12 ACL 码、Xorbas 码、ACIoT 和FMEL 的平均修复用时
此外,如表2 所示,因为FMEL(n=9,k=5)的平均跨云数据中心修复流量低于2 副本技术,因此其平均修复用时也短于2 副本技术.特别地,虽然FMEL(n=6,k=2)的平均跨云数据中心修复流量与3副本技术相同,但其平均修复用时略长于3 副本技术,这是因为FMEL(n=6,k=2)在修复数据时的计算量大于3 副本技术.
5 总结
针对现有纠删码构造方法无法兼顾编码参数适应性、跨云数据中心修复流量和纠删码构造效率的问题,本文提出了一种低跨云数据中心修复流量的纠删码的快速构造方法FMEL,可在不同编码参数下快速求得低跨云数据中心修复流量纠删码.在真实跨云数据中心环境中的实验表明,相较于现有的可构造能达到平均跨云数据中心修复流量下限的最优码的方法,FMEL 构造纠删码的时间少了89%,且在大部分编码参数下二者构造的纠删码的平均跨云数据中心修复流量相同.此外,我们利用FMEL 评估了大量编码参数,并挑选出2 组编码参数.FMEL 在这2 组编码参数下构造的纠删码的平均修复流量低于已得到广泛使用的多副本技术,同时其容灾性、容错性和冗余度相较于多副本技术具有明显优势.
作者贡献声明:包涵提出了算法思路和实验方案,并负责完成实验和撰写论文;王意洁提出指导意见并修改论文.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
数学物理学报(2022年2期)2022-04-26
保定学院学报(2022年2期)2022-04-07
中学生数理化·教与学(2019年8期)2019-09-18
许昌学院学报(2018年4期)2018-05-02
中国铸造装备与技术(2017年6期)2018-01-22
中华建设(2017年1期)2017-06-07
数学物理学报(2017年1期)2017-06-05
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电测与仪表(2015年1期)2015-04-09
