
面向非独立同分布数据的联邦学习研究进展
2023-11-10 15:11郭桂娟皮慧娟贾维嘉彭绍亮
小型微型计算机系统 2023年11期
郭桂娟,田 晖,皮慧娟,贾维嘉,彭绍亮,王 田
1(华侨大学 计算机科学与技术学院,福建 厦门 361021)
2(北京师范大学 人工智能与未来网络研究院,广东 珠海 519000)
3(北京师范大学-香港浸会大学联合国际学院 人工智能与多模态数据处理广东省重点实验室,广东 珠海 519000)
4(湖南大学 信息科学与工程学院,长沙 410000)
5(湖南大学 国家超级计算长沙中心,长沙 410000)
1 引 言
近年来,随着云计算、边缘计算、联邦学习的快速发展,大数据在保证数据隐私保护的前提下得到了很好的利用.由于联邦学习具有很好的保护用户数据隐私的特性,联邦学习在近几年迅速崛起,得到了很多行业的青睐[1].联邦学习不仅在电信领域、医疗、金融风控等方面发挥着重要作用,并且还在人工智能、5G、联合数据分析中也有着举足轻重的地位.此外,联邦学习也因其自身的特点在边缘计算场景中得到广泛的应用,如边缘聚合、边缘缓存以及计算卸载等[2].
对于联邦学习来说,虽然最主要的数据部分放在本地上进行训练,很大程度上保证了数据的安全性和隐私性.但是由于non-IID数据的存在,联邦学习的效率、准确性和通信成本等都受到了很大的限制.其中,Zhao等人发现,由于并非所有的客户端数据都是独立同分布的,当客户端数据存在高度倾斜的non-IID数据时,联邦学习的训练精确度明显降低,最高可以达到约55%[3].此外,Zhu等人对联邦学习中的数据异构性做了详细的总结,并分析了数据异构性对参数模型、非参数模型在水平联邦学习和垂直联邦学习的影响[4].尽管联邦学习在数据独立分布的情况下有着良好的准确性和通信成本,然而Zhong等人通过实验证明了在存在non-IID数据的某些类型仅靠学习单个联邦模型往往不是最优的[5].
针对联邦学习中的non-IID数据所引起的一系列问题,很多学者都在这上面进行了大量的研究.如文献[6]针对联邦学习中non-IID数据所带来的偏差问题,提出一种趋于经验控制的框架来智能的选择客户端设备参与到每轮的联邦学习中去,从而平衡由non-IID数据引起的偏差问题并加速收敛速度.文献[7]更是提出稀疏三值压缩(STC)来最优化上下行通信,从而提高联邦学习中non-IID数据的鲁棒性.由于non-IID数据和IID数据分布特性并不相同,因而在non-IID数据下进行训练时可能会导致联邦学习无法描述甚至无法收敛的情况.因此对non-IID数据的研究显得十分困难.虽然non-IID数据会导致训练的模型有所偏差,但是拥有大量数据的客户群体之间的数据可能存在这个某种相关性.文献[8]从客户端之间的集群化出发并结合图卷积神经网络提出集群驱动的图联邦学习策略来解决统计异构性问题.联邦学习相对于传统的机器学习具有更好的数据隐私保护性,然而,没有哪种技术是完全安全的.针对联邦学习隐私保护的研究也比比皆是,但目前大多数学者都是针对IID数据来对联邦学习的隐私保护进行的研究,如文献[9]对联邦学习安全性和隐私性做了全面探讨.为此,文献[10]针对联邦学习non-IID数据中有关隐私保护进行了创新性的探索.
综上所述,虽然国内外专家和学者对联邦学习中的non-IID数据进行了一定的研究,但是对这方面缺乏系统的梳理和总结.本文系统地介绍了联邦学习中non-IID数据的相关研究,从几个方面对non-IID数据带来的影响及其目前的研究方案进行了阐述.最后详细的介绍了目前non-IID数据未来的研究方向,对联邦学习中non-IID数据未来的研究具有重要意义.
2 联邦学习与non-IID数据
本节详细介绍了联邦学习中non-IID数据的相关概念,并指出了衡量non-IID数据程度的评价方法及对non-IID数据的场景分类.
2.1 联邦学习
随着数字信息化时代的到来,许多行业都拥有大量的私有数据.但是由于行业竞争、隐私安全等问题,这些数据常常以孤岛的形式存在.针对数据孤岛和数据隐私等巨大难题,2017年谷歌公司提出了联邦学习算法框架[11].联邦学习打破了数据孤岛问题并极大保证了用户数据的隐私安全,终端设备仅仅需要上传本地模型即可共同训练一个目标模型.
根据联邦学习中数据集的贡献方式可以将联邦学习分为3类:横向联邦学习(Horizontal Federated Learning,HFL)、纵向联邦学习(Vertical Federated Learning,VFL)和联邦迁移学习(Federated Transfer Learning,FTL)[12].在图1~图3中,矩形的长度代表样本特征维度,宽度代表样本维度.
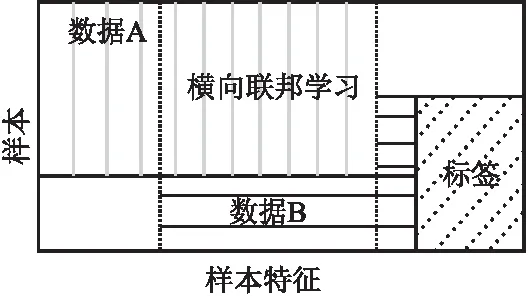
图1 横向联邦学习Fig.1 Horizontal federated learning
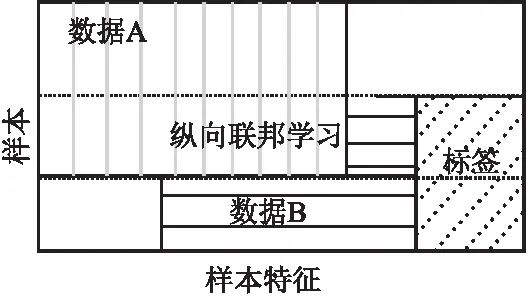
图2 纵向联邦学习Fig.2 Vertical federated learning
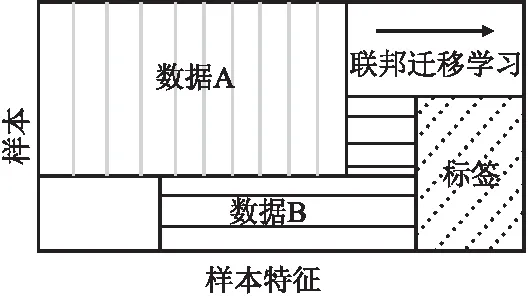
图3 联邦迁移学习Fig.3 Federated transfer learning
1)横向联邦学习HFL[13]指的是不同的参与方有较多的数据样本特征(横向)重叠而数据样本(纵向)重叠较少,即HFL适用于各数据持有方的用户特征维度重叠多而用户维度重叠少的情况.
2)纵向联邦学习VFL[14]指的是不同参与方有较多的数据样本重叠而数据样本特征重叠较少,即VFL适用于用户重叠较多而用户特征维度重叠较少的情况.
3)联邦迁移学习FTL[15]是对横向联邦学习和纵向联邦学习的补充,指的是不同参与方的数据样本以及数据样本特征的重叠都较少的情况,即FTL使用于用户及用户特征维度重叠较少的情况.
2.2 联邦学习中的non-IID数据
在概率论与统计学中,独立同分布(Independent and Identically Distributed,IID)是指一组随机变量中每个变量的概率分布相同并且每个变量之间相互独立.而非独立同分布(non-Independent and Identically Distributed,non-IID)是指随机变量之间非独立或者非同分布.在联邦学习中,non-IID是指数据独立但不同分布的情况,因为数据的分布一定是独立的,但是数据的采集不一定服从同一采样方法.比如全数据集中有上百类图片,某些设备中都是风景类图片,另一些设备中都是人物类图片,那么前者是一种数据分布,后者是另一种数据分布.反之,如果某个设备中的图片种类齐全即既有风景类也有人物类图片,并且其他设备中的图片也齐全,那么它们就是同分布的[11].
2.3 联邦学习中衡量non-IID数据程度的评价方法
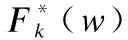
(1)
如果数据遵循IID分布或者non-IID数据程度很小,则每个设备中的分布则近似一样,那么本地目标函数最小值加权和等于全局目标函数最小值,即上述式子趋于零.如果数据遵循non-IID分布,那么上述式子值的大小则反映了数据分布的异构性程度.
2.4 联邦学习场景中对non-IID的分类
在实际的联邦学习环境中,参与者之间的数据具有高度异构性和数据量差距较大等特点[19].因此,在不同的环境下的参与者之间的数据有可能是完全不同,即是non-IID数据.假设数据样本为(x,y),其中x为输入属性或特征,y为标签.对于non-IID数据而言,假设终端设备k的本地数据分布为pk(x,y),即该设备的pk(x,y)与其他终端设备的不同.文献[16]根据数据偏离同分布的常见方式将non-IID数据分为以下5种类型:
1)特征分布倾斜(Feature distribution skew—covariate shift):同一特征,不同客户端表现形式不同.如相同的数字,不同的人写法不同(如笔画的宽度和倾斜度不同).
2)标签分布倾斜(Label distribution skew—prior probability shift):同一标签,其分布因客户端而定.如袋鼠只在澳大利亚或动物园;某些表情符号只被某一群人使用等等.
3)标签相同但特征不同(Same label,different features—concept drift):对于不同的客户端,相同的标签有不同的特征.如不同的地域,建筑物存在很大的差别;同样的衣服品牌在不同的时间会有很大的不同等等.
4)特征相同但标签不同(Same features,different label—concept shift):由于个人喜好,训练数据中相同的特征向量可以有不同的标签.如反映情绪或预测下一个词的标签因个人和地区不同而有所差异.
5)数据倾斜:不同的客户端可以保存大量不同的数据.
以上5类non-IID数据是该文献根据真实世界中联邦学习数据集可能涉及的偏离同分布的各个情景进行划分的结果.
3 联邦学习系统模式
在不同的应用场景中,联邦学习系统所对应的模式也有所不同.在不同的联邦学习系统模式中,处理non-IID数据所涉及的方式也不尽相同.根据应用场景的不同可将联邦学习系统模式分为客户-服务器模式和端对端对等模式.
3.1 客户-服务器(C/S)模式
在客户-服务器(Client/Server ,C/S)模式[20]中,中央服务器是一个可信的聚合服务器.如图4所示,在联邦学习过程中,中央服务器负责对全局模型参数的“发放”以及对局部模型参数的“聚合”.参与方只需要将自己训练好的本地模型发送给中央服务器即可,即参与方的原始数据始终保留在本地上.在C/S模式中,参与者需要借助第三方进行通信,因此第三方必须是可信的服务器.
前面第1章所述的方法都是基于中心化联邦学习的,也就是依赖于一个中心服务器,这需要所有的客户端均信任该中心服务器,并将本地模型上传到中心服务器来训练目标模型.在C/S模式中,可以结合一些前沿技术寻找解决non-IID数据的最佳方法,如数据增强技术.文献[21]提出一种新颖的联邦学习框架XorMixFL,该框架的核心思想是收集其他设备上仅能被该设备数据样本进行解码的编码数据样本,解码过程提供合成但又真实的数据样本,直至引导出IID数据集以用于模型训练.实验表明,该框架在MNIST数据集中的non-IID数据集下,XorMixFL Vanilla FL提高了17.6%的精确度.此外,为了缓解统计异质性,通过对未充分表示的数据采用零机会数据增强;并鼓励联邦网络中的客户端提高测试精确度和更加公平,文献[22]提出并研究了在客户机上使用零机会数据增强的联邦学习Fed-ZDAC以及在服务器上使用零机会数据增强的联邦学习Fed-ZDAS两种变体,并通过实验证明该方案的公平性和准确度.
3.2 端对端对等(P2P)模式
当中心服务器不可信或者没有中心服务器时,联邦学习通常采用是端对端对等(Peer to Peer ,P2P)模式也即去中心化.如图5所示,P2P模式由持有数据的终端设备组成,这种模式不需要第三方服务器,模型参数直接在参与方进行传送.参与训练的终端设备A直接将训练的本地模型参数发送给下一个(或多个)终端设备B,终端设备B接收到一个(或多个)模型参数后继续训练,直至收敛或达到阈值条件为止.虽然P2P模式下,各个参与方无需借助第三方中心设备便可直接通信,提高了系统的安全性,但是由于P2P模式需要对信息内容进行加密和解密等操作,这会导致额外的计算开销.
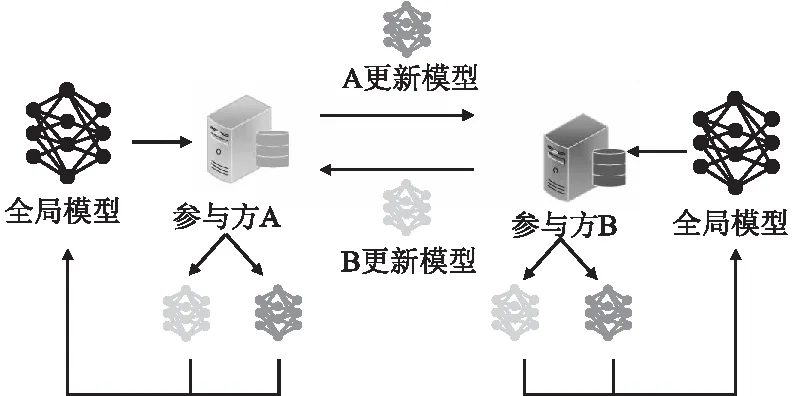
图5 端对端对等模式Fig 5 Peer to Peer
对于P2P这种前沿技术,有的专家和学者开始尝试利用联邦学习与P2P结合来寻求解决客户端中的non-IID问题.为解决物联网网络中的不平衡和non-IID数据问题,文献[23]考虑到端对端模式不需要中心服务器,并就此提出一种新型的点对点算法P2PK-SMOTE来训练non-IID场景下的有监督异常检测机器学习模型,通过自适应地应用于点对点联邦学习的数据再平衡方法,用于异常检测.通过实验结果证明在P2PK-SMOTE方法下查全率和查准率为100%,假阴性和假阳性率几乎为0%.文献[24]考虑到实际场景中客户端之间的数据分布通常是异构的,提出一种基于性能的邻近选择方法PENS来学本地数据分布的模型.当前P2P模式除了用来寻求解决non-IID数据问题外,还可用于联邦学习下的单向信任问题、模型保护问题等等[25].目前联邦学习与去中心化等技术结合的研究仍然处于起步阶段,也正逐渐成为研究热点,如何将技术融合助力共同发展,仍然值得不断探索.
4 联邦学习中non-IID数据涉及的各方面研究现状
4.1 性能优化
当客户端数据存在高度倾斜的non-IID数据时,联邦学习的性能(如:模型精确度、学习效率等)明显降低.针对由non-IID数据导致的效率下降问题,很多国内外专家和学者做出了不懈努力.
Li等人提出了一种联邦学习框架FedProx来解决联邦学习中的数据异构性问题.该方案认为客户端的参数更新虽然很微小但是对实验有很重要的影响,同时考虑到终端设备间数据的异构性,提出在每个本地目标函数中添加一个近端项,使算法对本地客户端之间的异构性更具鲁棒性.实验表明,提出的FedProx算法提高了联邦学习的性能[26].Karimireddy等人证明了当数据异构时会产生客户端漂移现象即更新偏移,导致不稳定性并减缓收敛速度.对此,文章中提出了一种算法SCAFFOLD来解决上述问题.该算法通过使用控制变量(方差减少)来纠正本地更新中的客户端漂移现象[27].此外,还有很多专家和学者进行了大量的研究和探讨.比如Huang等人提出一种方法FedAMP来促进具有相似数据的客户端之间成对协作[28].Ruan等人提出一种新型的联邦学习聚合方法,能允许更灵活的设备参与收敛[29].而Zhang等人也提出一种算法CSFedAvg来选择频率较高的模型以缓解因non-IID数据导致的精确度下降问题[30].
联邦学习的训练效率在很大程度上都和non-IID数据有关,如果从non-IID数据着手研究将对联邦学习效率的提升有很大的帮助.
4.2 算法优化
联邦平均算法FedAvg是联邦学习中使用最为广泛的算法之一.然而联邦平均算法通过采用权重更新来更新全局模型,即只考虑到客户端数据量的大小,并未考虑到客户端数据质量对整体模型的影响.因此提出一个能够适用于不同数据质量的算法是一个非常有意义且值得探索的方向.
针对独立同分布数据集,Wang等人通过观察局部更新的数目变化时收敛速度和误差下限间的关系提出一种自适应性通信策略,即在开始阶段先设计一个较大的τ,在模型接近收敛时逐渐减小τ.通过这种自适应性策略能够实现快速收敛和低错误下限[31].McMahan等人提出根据客户端本地数据集的大小对本地模型进行加权平均进行训练[32],但是仅仅针对数据集大小对模型进行加权平均会忽略了数据质量这一因素的影响.
虽然国内外专家和学者已经考虑到从算法上来处理数据的异构性问题,但是目前从这个方面着手的研究相对而言还是比较少.如何设计一个能考虑到异构性并能真实反映终端设备数据情况的算法仍然亟待解决.
4.3 模型优化
现有的关于non-IID数据的研究主要涉及性能优化、通信成本、隐私保护等方面,需要解决的不仅仅只有数据问题和算法问题,还包括模型优化问题.在联邦学习中,由于参数模型和非参数模型的训练方式不一致,因此non-IID数据对联邦学习的训练性能也存在较大影响.此外,由于联邦学习参与者的数量十分庞大,联邦服务器的通信成本和通信链路资源十分有限.因此,如何高效训练模型并保证模型的健壮性就显得非常重要了.
在现有的研究中,对于大量模型的一般解决方法就是将模型压缩(稀疏化).Shi等人从随机稀疏角度出发,将训练算法与本地计算、梯度稀疏结合起来提出一种柔性稀疏法,即对参与者提供误差补偿,允许参与方只上传小部分具显著特征的梯度,从而减少每一轮的通信负荷[33].此外,针对移动终端设备上数据分布的不平衡性,Duan等人提出一种自平衡框架Astraea,在该方案中,通过自适应数据扩增和下采样来缓解全局不平衡,同时根据客户端数据分布的相对熵(Kullback-Leibler Divergence,KLD)创建边缘层来重新安排客户训练以缓解因数据不平衡而导致的模型偏差[1].自2015年Hinton等人提出知识蒸馏法后,联邦蒸馏(Federated Disillation)也被提了出来,联邦蒸馏只是交换局部模型输出而非交换传统联邦学习采用的模型参数,因为这些输出的尺寸通常比模型尺寸小,因此可以减少通信消耗.如文献[34]提出的一种通信效率高且保护隐私的分布式深度强化学习框架——联邦强化蒸馏(Federated Reinforcement Distillation,FRD).
由于在联邦学习中,客户端的数量是庞大的,联邦学习环境可能由数百万参与者组成.因此如何高效训练模型并保证模型的健壮性显得十分重要.但是,显然目前已有的FedAvg不是最优的综合方案,目前许多研究就针对现有的模型更新和模型聚合做了改进,如何通过non-IID数据来提高模型的健壮性和有效性也是目前研究联邦学习的一大热点.对比现有的方法中比较优秀的有 Experimental Study[6],但是目前的研究是远远不够的,如是否能根据文献[35]提供的从模型的清洗、过滤角度着手,然后根据non-IID数据对模型的差异进行筛选,如过滤掉由IID数据和non-IID数据联合训练出来的性能比较差的模型[36];又或者通过激励方式来获取性能比较好的模型呢?
4.4 通信成本
联邦学习的通信问题主要是由客户端和中央服务器之间的网络连接和数据传输(模型、参数)所造成的.由于大量的用户设备都将本地模型、更新发送到服务器,而移动设备的数据通常有限,并且到中央服务器的网络连接速度很慢,因此减少通信开销至关重要[37].对于通信开销问题,很多国内外学者从以牺牲模型精确度为代价、在联邦学习的整体框架中只训练占用通信空间较小的低容量模型.在这个角度上,有Rothchild等人提出使用Count Sketch对客户端模型更新进行压缩的处理方法FedSGD[38]以及Reisizadeh等人提出的周期平均和量化的处理方法FedPAQ[39]等等,但是他们都很少注意到non-IID数据对通信成本的影响.对此,有的国内外学者从non-IID方面着手进行通信成本的缩减.其中影响因子比较大的方案有Sattler等人提出的稀疏三元压缩(Spare Ternary Compression,STC)[7].STC对联邦学习的设置采用文献[40]中描述的方法,并以tok-k稀疏化算法为起点来构建一个通过稀疏化、互化、纠错来压缩上行和下行通信的高效通信协议,主要解决3个方面问题:对权重更新的量化和无损编码进一步提高通信效率;设计下载的压缩通信;实现一个缓存机制,使得在客户端部分参与的情况下保持客户端同步.
Itahara等人提出了一种基于蒸馏的半监督联邦学习算法(DS-FL).在这种方法里,通信成本仅取决于模型的输出维度而不是根据模型的大小进行扩展.实验结果表明,DS-FL相对于FL基准降低了高达99%的通信成本[41].Chai等人提出一种基于non-IID数据的异步分层联邦学习方法FedAT,FedAT协同结合了同步层内训练和异步跨层训练.通过分层桥接同步和异步训练,最大限度地减少了掉队效应,提高了收敛速度和测试精度,同时使用一种基于折线编码的高效压缩算法来压缩上下链路通信,从而最大限度地降低通信成本.实验结果表明,与目前最新的FL方法相比,该方法预测性能提高了21.09%,通信成本降低了8.5倍[42].
综上,在通信成本方面,目前最多的是从模型角度出发,但是也有从维度出发来缩减成本.学者们提出的从non-IID着手缩减通信成本的方案均有很高的效果.
4.5 隐私保护
从传统的云计算、边缘计算发展到今天的联邦学习,联邦学习展现了强大的优势和发展潜力.尽管联邦学习很大程度上保证了终端设备的数据隐私问题.然而有学者发现在联邦学习环境中,就算终端设备只共享模型参数也会泄露隐私信息.当前对于联邦学习隐私保护的研究很少有人从non-IID数据方面着手,但是存在少量学者想以此为突破点而进行了相关研究.
Yang等人为了保证数据的隐私性、解决不同设备间数据不平衡、non-IID数据等问题,提出了一种全局模型聚合的联邦平均算法.该算法通过计算每个选定设备上局部模型的加权平均来实现[43].针对特征偏移non-IID问题,Li等人提出在平均模型之前使用局部批处理归一化来缓解特征偏移[44].Xiong等人从non-IID数据方面出发对联邦学习的隐私保护做了创新性的探索.首先,作者对FL中的隐私泄露问题进行深入分析,证明了隐私推理攻击的性能上界,并在此基础上设计了2DP-FL算法.该算法通过在训练局部模型和全局模型时加入噪声来实现差分隐私[10].
4.6 个性化联邦学习
在联邦学习中,由于客户端存在non-IID数据,统计异质性通常会导致各个用户端对模型性能的需求可能不一样.对于一些客户来说,仅仅基于私有数据进行训练的本地模型可能比全局模型效果更好,因此仅单个全局模型很难满足所有参与者的需求,此时可以采用个性化的研究方法使训练好的全局模型针对不同的用户进行优化.因此个性化联邦学习也是解决non-IID数据的一种研究方法.目前关于这方面进行全面调研的有文献[45].文献[46]提出一个可扩展的联邦多任务学习框架Ditto.Ditto可视为一个标准全局FL的轻量级个性化附加组件,通过以交替的方式求解全局模型和个性化模型以提供内在的公平性和鲁棒性.文献[47]强调了联邦学习个性化的必要性并对联邦学习个性化的最新研究做了相关总结.个性化全局模型的常见方法包括增加用户上下文、联邦迁移学习[48]、联邦多任务学习、联邦元学习、联邦知识蒸馏[49]、混合全局模型和局部模型等等.但是由于数据异构性,联邦学习很难训练出适合所有客户端的单一模型,通过个性化方法必然会增加额外的开销,因此,如何在联邦学习环境中为客户端建立个性化联邦学习和减少额外开销之间做出平衡,这仍然是十分有前景的研究方向,学者可以根据国内外学者现有的研究方案继续深入研究.
联邦学习中关于non-IID数据各方面的研究现状,表1做了详细的总结.通过调研分析可以看到,联邦学习中关于non-IID数据在各方面的研究现状中,性能优化、算法优化、模型优化等方面的研究比较集中.目前不少专家和学者注意到个性化联邦学习的优势,并开始从这个方面探索寻找一个适合不同参与者的个性化模型.个性化联邦学习是目前解决联邦学习中non-IID数据异构的一个重要方向.目前对于联邦学习个性化的研究方案也比较少,但是确实是值得深入研究的一个方向.
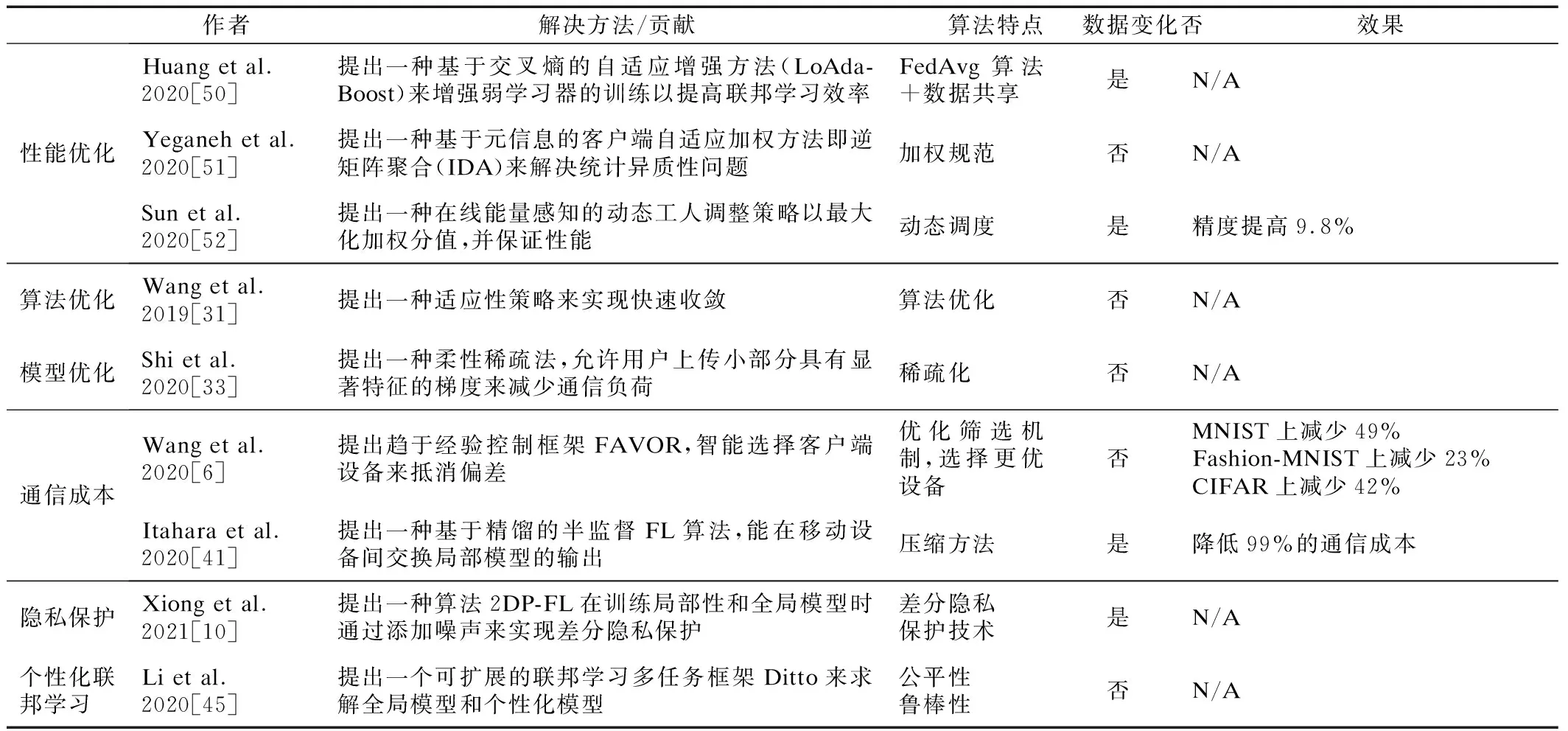
表1 non-IID数据在各方面的研究方案对比Table 1 Comparison of non-IID data on various aspects
5 未来研究方向
本节提出了联邦学习有关non-IID数据的几个重要研究方面.讨论了在不同研究方面中关于non-IID数据研究的可行性,探讨了联邦学习中关于non-IID数据的未来研究方向.
5.1 信任与激励机制
尽管联邦学习为不同机构、不同部门之间的数据联合提供了一个很好的平台,但数据融合仍然需要大量的用户参与到训练中去,如果没有高度的信任以及高效的激励机制便很难吸引到足够的数据量或者拥有良好数据的客户端参与其中,目标模型的质量也无法得到保证.针对上述问题,很多专家和学者开始探索如何制定信任机制以及如何设定激励机制来吸引优质客户端参与到联邦学习中.文献[53]总结了大量研究,指出联邦学习通过集成区块链保证模型的可信任性.同时基于区块链的激励机制作为一种经济回报能够根据构建模型时客户端的贡献给予相应的奖励,能够激励用户积极参与到数据训练当中去.
当前,移动边缘计算(Mobile Edge Computing,MEC)将移动终端的计算任务卸载到边缘服务器中,弥补了终端设备在资源存储、计算性能方面的不足.同时,要在保护数据隐私的前提下操作大数据,联邦学习发挥了巨大作用,因此,联邦学习和MEC的结合被认为是最有前景的研究之一.文献[54]认为在MEC中,边缘节点不愿意主动参与学习,并且在提供的资源方面也存在差异,这些都会影响到联邦学习的性能.因此文献提出一种具有K名中标者的多维拍卖联邦学习激励机制FMore.FMore通过采用K位赢家的多维采购拍卖方式来鼓励更多高质量、低成本的边缘节点参与联邦学习,从而提高联邦学习性能.实验表明,FMore算法可以将LSTM模型的训练次数减少近51.3%,准确率提高28%;在Linux HPC集群中,训练时间减少了38.4%,模型精度提高了44.9%.
在对联邦学习激励机制的研究过程中引入博弈论是一大研究热点.博弈论又称为对策论,主要考虑到在游戏过程中个体的预测行为和实际行为来研究其优化策略.考虑到多任务的边缘联邦学习激励机制问题尚未解决,文献[55]提出一种融合契约论和匹配博弈的激励机制.首先服务提供商利用契约论为多任务联邦学习制定多份合约,然后提出一个多对多匹配算法来匹配多份合约和多个终端设备.最后通过仿真实验证明了该激励机制的有效性.
虽然目前尚未有专家和学者在设计信任与激励机制时未考虑到non-IID数据相关问题,但是拥有non-IID数据的相关客户端与其他客户端相比较,其训练的模型与其他模型之间的异构性是比较明显的[1].当服务器端不可信时,用反演法反演异构数据也是比较容易的.因此是否可以从non-IID数据的角度设立可值得用户端信任的机制,并设定可信的激励机制鼓励大量优质客户参与到训练中去.此外,对于拥有异构数据,如果能在可靠的信任机制下用激励机制吸引客户端共享非私密数据以达到集成训练的效果也不失为一个办法,只是该信任机制如何值得客户端信任以及给予何种报酬才能吸引到用户贡献自己的数据,这是一个值得探索的问题.
5.2 用户关联模型
在联邦学习环境中,由于不同地区、不同环境下用户的数据分布情况并非是独立同分布的,因此用户的模型也是有差异的,如果直接视为同一类进行上传聚合,生成的模型与目标模型必定存在偏差.然而某些地区内的用户他们的数据是有一定的相关性的.文献[56]为了解决non-IID数据对联邦学习的影响,通过客户端之间的任务相关性来实现异构数据的有效聚合.在一轮聚合中,服务器为客户端提供一个可训练的编码器,将他们的数据压缩成潜在的表达形式,并将它们的数据签名传回服务器.然后,服务器通过流形学习来获取客户端之间的任务相关性,并执行联邦平均算法.当没有明确的客户端集群时,该方案可以灵活地处理通用客户端相关度图,并有效地将其分解为(不相交的)集群以进行集群联合学习.
通过用户之间的相关性来处理non-IID数据是一个较为新颖的方法.借助联邦学习对有关联的non-IID数据统一处理既可提高训练效率又不会忽略掉non-IID数据特性.然而,目前对于用户关联模型的研究仍然十分匮乏,值得继续探索.
5.3 感知情景
由于参与联邦学习的客户端来自不同的地区、部门以及客户端的上下文环境也不一样,如果直接将所有的局部模型不加区别统一进行训练,必然导致生成的模型有所偏差.而且以往对于数据的划分以及场景模拟十分刻板,为了模拟真实的non-IID场景,Li等人提出一种全面的数据划分策略来替代典型的non-IID数据策略,将真实数据集划分为多个较小的子集来合成分布式non-IID数据集,并通过数据分布不同(如标签分布偏差、特征分布偏差等等)分区策略不同来模拟不同的场景[57],该数据划分方法给其他研究提供了一个很好的思路,但是该方法基于分布式数据库上的机器学习的,不能始终优于其他方法.除了在对数据的划分进行探索之外,有的专家和学者开始从参与者的上下文感知方面考虑如何确保用户隐私的前提下提高模型训练的准确率以及计算卸载方案.文献[58]考虑到上下文信息对卸载策略有着重大影响,因此在所有卸载过程中使用自治管理循环收集上下文信息,提出一种基于联邦学习的卸载方法.实验结果表明,该方法在不考虑上下文感知算法的情况下,在能量消耗、执行成本、网络延迟和公平性等方面优于本地计算、卸载和FL算法.
尽管目前尚未有专家和学者在上下文场景中考虑到non-IID数据,然而上下文场景是一个值得探索的方向.或许在处理non-IID数据问题上可加入上下文场景,有针对性的为客户端进行推荐模型,对于拥有non-IID数据的客户端给其推荐互补的训练模型,对于其他用户则推荐一般目标模型进行训练即可.当然,该方法需要大量的研究及探索才能验证.
6 结束语
随着大数据时代的到来,用户对于隐私安全的保护意识越来越强烈,传统的机器学习已经不能满足人们对隐私安全保护的需求.联邦学习的出现打破了数据孤岛问题并极大程度地确保了隐私安全,因而得到了广泛的应用.然而Non-IID数据的存在不仅导致联邦学习效率降低、精确度下降等问题同时还给联邦学习的隐私保护带来了新的挑战,因此对于non-IID数据的研究仍是一个热点话题.本文将上述方案归纳整理,并系统的分析了相关研究.针对现有研究方案的不足,本文从信任与激励机制、用户关联模型和感知情景等方面提出了联邦学习未来的研究方向,为联邦学习中non-IID问题的进一步研究提供参考,从而为相关领域的研究人员提供考察和帮助.
猜你喜欢
家庭影院技术(2020年10期)2020-12-14
铁道通信信号(2019年9期)2019-11-25
家庭影院技术(2019年7期)2019-08-27
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
电子测试(2018年10期)2018-06-26
网络安全和信息化(2017年10期)2017-03-08
知识产权(2016年8期)2016-12-01
网络空间安全(2016年3期)2016-06-15
俄罗斯问题研究(2013年1期)2013-03-11
