
基于异常特征模式的心电数据标签清洗方法
2023-11-24 05:25韩京宇
计算机研究与发展 2023年11期
韩京宇 陈 伟 赵 静 郎 杭 毛 毅
(南京邮电大学计算机学院 南京 210023)
(江苏省大数据安全与智能处理重点实验室(南京邮电大学)南京 210023)
(jyhan@njupt.edu.cn)
根据世界卫生组织的报告,心血管疾病(cardiovascular diseases,CVDs)是人类健康的头号杀手[1].心电图(electrocardiogram,ECG)作为一种无创的心脏健康检测技术在临床上广泛应用,因而心电图异常的自动识别备受关注[2].由于每个样本通常会有多种心电异常,例如完全性左束支阻滞经常和前间壁心肌梗死共同出现,房性期前收缩经常和窦性心动过缓并发[3],其自动检测在机器学习中是一个典型的多标签分类问题.训练有效的分类器,通常需要大量具有完整且准确标签的样本,然而在实际中,人工标注心电异常不仅需要专业人员,而且费时费力.
众所周知,丰富且标记正确的样本对于训练有效的分类器至关重要,尤其是训练深度学习模型,样本的数量直接影响分类器的精度和泛化性.现实中,经常有一些心电的弱标签数据集(weakly labelled dataset,WD)不能被有效利用[4-5].这些样本有异常标签,但标签不一定完整和正确,如何有效地去除错误标签、填补缺失标签,提供更丰富的训练数据集,意义重大[6].我们注意到,获取少量的有完整、正确标签的示例数据集(example dataset,ED)是完全可行的.根据这个认识,弱标签心电数据集的清洗任务具体化为,给定一个WD和一个ED,对WD中的异常标签进行清洗,获得干净数据集(clean dataset,CD),其每个样本有全部正确的异常标签.
目前关于弱标签心电图样本清洗的研究[7-10]可以分为2 类:依赖于分类器的方法和独立于分类器的方法.前者直接在弱标签数据集上训练一组分类器,并根据它们的判断来识别错误标记的样本[7,9-10];后者旨在无需训练分类器的情况下,开发识别弱标签的专用算法[8],本文提出的方法就属于后者.另外,机器学习中利用弱标签数据和未标记数据训练通用分类器的方法也受到广泛关注.前者根据每个样本的部分相关标签进行学习[11-15],后者基于小部分正样本和大量未标记样本来训练分类器[16-17].但这些方法不能用于创建具有干净标签的数据,也不适用于心电图数据:首先,心电图异常标签多达几十个,而通常的方法只关注少量标签;其次,心电图数据的异常标签和特征间有复杂的相关性,即一个异常呈现不同的特征模式,而且类似的特征模式可能指示不同的异常[3,5].
本文提出一种基于异常特征模式(abnormalityfeature pattern,AFP)清洗弱标签心电数据的方法(后文简称:AFP 方法),生成可重复使用的、具有完整且准确标签的干净数据集,为心电数据的有监督学习提供更丰富的训练样本.具体地,基于心电数据的异常特征模式,在ED的支持下去除错误标签并填补缺失标签,AFP 包括2 个阶段,即清洗规则构建和迭代清洗异常标签.在第1 阶段,提取由ED和WD共享的异常特征模式,识别ED和WD共享的异常标签,即锚标签;然后,提取异常发现规则、异常排除规则和1 组二分类器.在第2 阶段,首先根据标签发现和排除规则识别初始相关异常;然后,根据二分类器迭代判断其他的弱标签是否属于对应样本.迭代终止时,生成对应WD的CD.方法中ED的支持是不可或缺的,它不仅是发现共享异常特征模式的基础,也是挖掘清洗规则的源泉.
本文主要贡献在于提出了一种通用的心电数据标签清洗方法,具体包括3 个方面:
1)提出利用异常特征模式识别以高置信度属于实例的锚标签.既利用了人类知识,又提取了弱标签中的可靠信息,保证清洗方法的有效性和鲁棒性.
2)提出挖掘异常发现和排除规则的具体算法,这些规则是标签清洗的基础.
3)开发了一个迭代式的异常清洗框架,通过逐步缩小不确定区间来清洗异常标签,精准地去除错误标签和添加缺失标签,避免方法性能的波动.
1 相关工作
1.1 弱标签心电图数据学习
大多数心电图分类工作假设样本的标签完整且准确,但实际中很难满足.在心电异常分类中,如何利用被错误标记的样本备受关注.文献[7]中利用5 种不同的分类器,支持向量机(support vector machine,SVM)、K 近邻(K-nearest neighbor,KNN)、朴素贝叶斯(naive Bayesian,NB)、线性判别分析(linear discriminant analysis,LDA)和决策树(decision tree,DT),将所有训练样本随机分成10 份,1 份作为验证集,其余9 份作为训练集,然后将训练集输入到这5 种分类器,确定标签是否被错误标记.文献[8]中自动删除具有潜在错误标签的训练样本,协助用户进行心电图病症标记.所提出的方法基于遗传优化过程,其中每个染色体代表一个候选解决方案,用于确认无效的训练样本.文献[9]中提出,用分类性能最好的前k个算法独立进行投票,如果k个算法对是否有某个标签持不同观点,则将该标签视为潜在错误标签.
另一项密切相关的工作是如何利用弱标签数据训练通用分类器[11-14,18-21],该工作分成2 类:
一类是直接对弱标签进行修正.文献[12]中提出通过10 折交叉验证来识别错误标记的数据,在第i轮中的第i组作为验证集,其余9 组作为训练集.在验证集上预测的每个标签,如果训练出来的分类器不一致,则被认为是不正确的标签.文献[13]用一个矩阵建模图像和标签的相似性,通过矩阵补齐技术来补齐图像的标签,也是一种修补标签的方法.文献[18]中提出了半监督弱标签(semi-supervised weak-label,SSWL)方法,解决基于部分标签甚至无标签数据进行的学习问题,它根据实例相似性和标签相似性来补充缺失标签.
另外一类是直接利用弱标签数据训练分类器.文献[20]提出的随机梯度下降树(random gradient descent tree,RGD-tree),在有错误标签的数据集上训练支持向量机,保证超平面的可分性.文献[21]提出采用缩放铰链损失函数(rescaled hinge loss function),提高支持向量机对噪声标签的鲁棒性.
本文不同于上述2 类方法在于:1)标签被清洗后,数据集可以被复用于各种计算任务,不仅可以用于训练分类器,而且可以用于各种数据挖掘、数据分析任务,拓宽数据的可用性;2)弱标记数据进行学习通常只能在符合方法特点的数据集上进行有效学习,方法对数据集敏感,有一定的适用局限性.
1.2 PU 学习
另一个相关工作是正样本和未标记样本(positive and unlabeled,PU)学习[22],它根据正样本和未标记样本来训练分类器,主要分为2 步法(two-step methods)和有偏学习(biased learning).
2 步法的第1 步识别出一些可靠的负样本;第2步将此样本与正样本结合用于训练分类器,对未识别的样本进行分类.文献[23]基于正样本构建概率生成模型,把相对正例密度最低区域的样本认为是负样本,基于此构建分类模型.文献[24]设计了最小平方支持向量机对未标记样本进行分类.
有偏学习训练分类器时将无标签样本当成负样本.文献[15]提出采用多个合成器、过滤器和确认器标记无标签的样本.文献[16]中将所有未标记的样本标记为负样本,并使用线性函数从噪声实例中学习,从而将问题转化为噪声学习问题.文献[17]中引入了一种生成PU 学习模型,在没有完全随机选择(selected completely at random,SCAR)假设的情况下,生成一组虚拟PU 示例来训练分类器.文献[25]将未标记的数据集视为负类,对负类标签进行建模,转化为使错误的负标签风险最小的问题.
1.3 多标签分类
因为分类器的输出空间大小与类标签数量成指数关系,所以多标签分类任务具有挑战性.一般多标签分类可以通过2 类方法来解决,即问题转换和算法适应[26-27].前者将多标签分类问题转化为其他成熟的学习场景,而后者采用流行的学习技术来处理多标签分类问题.
问题转换方法可以分为3 类:二分类、标签排序和多类分类.代表性的二分类有二元相关法[28]和分类器链法[29],前者将多标签分类问题分解为1 组独立的二分类问题,后者将多标签分类问题转化为二分类问题链,链中的后续二分类器建立在前面分类器的预测之上.标签排序的代表是校准标签排名(calibrated label ranking,CLR),它将多标签分类问题转化为标签排序问题,其中标签之间的排序通过成对比较来实现[30].诸如Random K-Labelset[31]之类的多类方法将多标签分类问题转换为多类分类问题的集合,其中每个组件分类器都针对标签的随机子集.
算法适应方法对已存算法进行改造实现多标签分类.例如,文献[32]中的多标签K 近邻(multi-label Knearest neighbor,MLKNN)方法采用K 近邻技术来处理多标签数据,使用最大后验(maximum a posteriori,MAP)规则进行预测.多标签决策树(multi-label decision tree,ML-DT)采用决策树技术来处理多标签数据,基于多标签熵的信息增益标准递归地构建决策树[33].文献[34]提出的排序支持向量机(ranking support vector machine,Rank-SVM)采用最大边距策略进行多标签分类,优化了一组线性分类器以最小化经验排序损失.文献[35]提出基于粒化特征加权的K 近邻算法实现多标签学习.
1.4 噪声标签清洗
目前噪声标签清洗方法主要分成2 类:一类对噪声鲁棒性进行建模,文献[36]提出对噪声的代理损失函数(surrogate loss function)和噪声率进行建模,文献[37]提出均匀标签噪声模型(uniform label noise model),通过风险最小化,创建鲁棒性强的多标签分类模型.另外一类基于模型过滤进行噪声标签清洗,如文献[38]提出基于数据分布过滤(data distribution filtering,DDF)的标签噪声过滤方法.对于数据集中的每一个样本,根据其近邻内样本的分布,将其邻域样本形成的区域划分为高密度区域和低密度区域,然后针对不同的区域采用不同的噪声过滤规则进行过滤.
2 问题和方法概述
令U={l1,…,lk,…,lu}为所有异常标签,表1 列出了一些常见的心电异常标签.ED={ob1,…,obi,…,obN}是具有正确标签的示例数据集,每个obi由特征ft(obi)和相关异常标签集rl(obi)⊆U组成.ft(obi)是一个d维向量 (f1,…,fk,…,fd),每个fk代表一个数值型特征,采用截断多元正态分布来描述该d维向量的分布.本文中,对每个样本的心电数据经过波形去噪、波形(QRS 波、P 波、T 波)识别、特征提取和归一化,在12 个导联上提取横向间隔、纵向幅度、电轴倾斜和波形高度4 类特征[39],构成d维向量 (f1,…,fk,…,fd).给定一个待清洗的大型弱标签数据集WD={ob1,…,obi,…,obM},每个obi带有弱标签集cl(obi),cl(obi)中的一些标签属于相关标签集rl(obi),而其余的则是错误标签,即不相关标签.另外,obi的有些相关标签缺失.清洗的目的是从WD生成一个CD.下文除特殊说明,异常和标签指示同一概念.表2 中列出了本文中使用的主要符号.
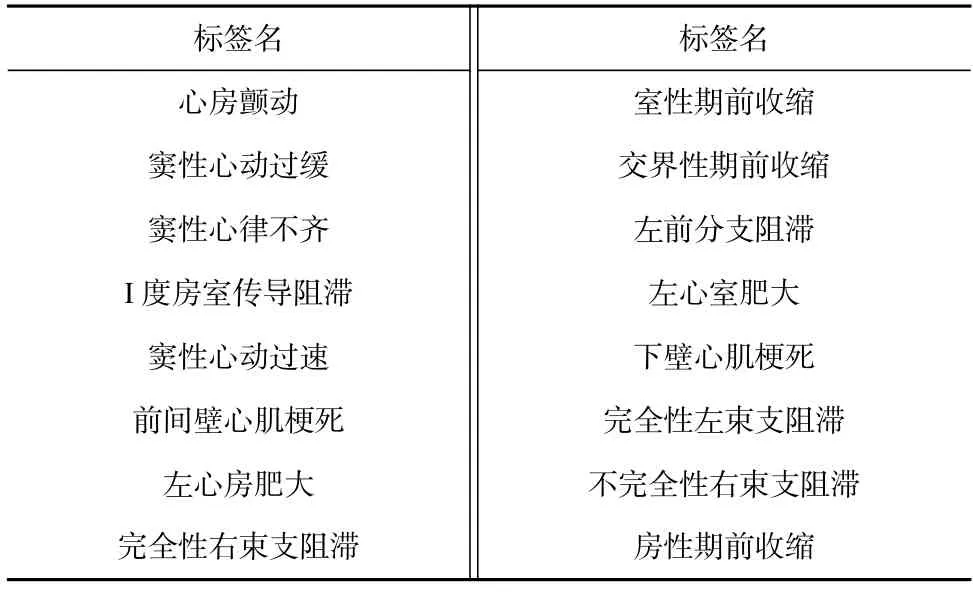
Table 1 Abnormality Labels in CHE and CHW Datasets表1 CHE 和CHW 实验数据集中的异常标签

Table 2 Meanings of Key Notations in Our Paper表2 本文中主要符号含义
定义1.异常特征模式.给定l的一个类簇Ci(l),它的异常特征模式fpi(l)对应一个截断多元正态分布NM(μi(l),Σi(l)),其中μi(l)是特征均值,Σi(l)是特征协方差.
给定2 个特征模式fp1=NM(μ1,Σ1)和fp2=NM(μ2,Σ2),衡量f p1和f p2的相异性Wasserstein 距离为:
其中 ||μ1-μ2||2是L2 范数距离.
AFP 方法分成2 个阶段:基于聚类的清洗规则构造和基于迭代的标签清洗,如图1 所示.在基于聚类的清洗器构造时,首先在ED和WD上进行聚类寻找锚模式.
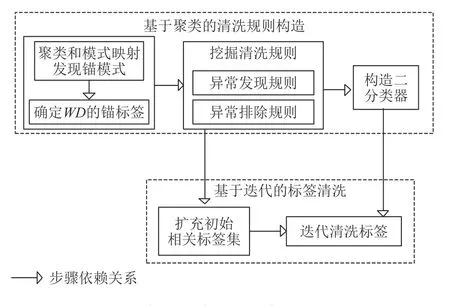
Fig.1 The steps of AFP图1 AFP 方法的步骤
定义2.锚模式.给定一个异常特征模式fpi(l),如果它被ED和WD共享,它就是一个锚模式.
定义3.锚异常集.给定一个实例ob∈WD,其锚异常集al(ob)⊆rl(ob)是根据锚模式识别的相关异常集.
锚异常集是根据共享的锚模式识别出的WD上的高置信度标签,它既是WD相关标签的一部分,又用来扩充规则挖掘依赖的样本.
挖掘标签发现规则和标签排除规则,分别用来表征2 个异常特征模式的正相关性和负相关性,在后续的标签清洗中分别用于填补缺失标签和去除错误标签.最后,为每个异常构造二分类器,以支持后续的标签迭代清洗.
标签迭代清洗前,在ED和WD组成的TD上构建隔离森林iForest(isolation forest)[40],根据样本在隔离森林中的路径长度决定参与迭代清洗的次数.清洗时,首先根据标签发现和排除规则,包含或排除弱标签,包含的标签确定为相关标签,排除的标签视为不相关标签,从而扩充初始相关标签集,缩小了弱标签集的大小;然后根据二分器,迭代清洗弱标签集,逐步缩小不确定的标签集合.迭代清洗时,通过不断地逼近标签和类簇特征间的关联,识别出其他相关标签.
后文除特别说明,使用Jensen-Shannon 距离来衡量2 个分布的差异,记为JSD.
定义4.JSD.给定2 个分布P(X)和Q(X),其中X表示域值,其JSD定义为
3 标签清洗规则的构造
对于每个异常l,在其正样本和负样本上分别识别一组类簇,进而构建l对应的1 组特征模式.虽然每个样本表征为高维数据,但本文没有对数据进行降维处理,因为有些心电病症的区别主要集中在若干特征上[3],如果进行降维,会剔除或淹没这些关键信息,降低异常识别精度.对样本进行聚类时,没有采用常见的方法如k-均值(k-Means)进行聚类,避免根据经验指定类簇数量,而是采用狄利克雷过程混合模型(Dirichlet process mixture model,DPMM)进行聚类,它能够自适应地根据数据分布特点发现最合适的类簇[41].DPMM 中每个实例obi产生于中国餐馆过程CRP(Chinese restaurant process)[42]表达的狄利克雷过程:
该生成模型中,实例由多元正态分布MN产生,类簇分配由中国餐馆过程CRP(γ)决定,其中 γ是聚焦参数,Zi是实例obi对应的类簇;作为狄利克雷过程的基分布,逆威沙特分布NIW(normal-inverse-Wishart)是多元正态分布MN的共轭先验分布:μ0是N维向量,代表最初平均值;k0用作平滑因子,控制Y0中各个元素的放缩比例;v0是自由度,初始化为原始特征数目;Y0是成对偏差积,初始化为N×N的常数矩阵.
为了找到实例obi所属合适类簇,算法1 用吉布斯采样获得类簇分配.
算法1.clusterAssignment.
类簇分配不停迭代,直到不再改变.迭代时,每个实例的类簇分配概率根据式(6)更新:
其中Z-i是除obi之外的所有实例的类簇分配.
证明.
由于P(ob-i|Zi=m,Z-i)=P(ob-i|Z-i)和
可得
证毕.
式(6)第2 行的第1 项是给定obi之外的所有实例的类簇分配条件下obi的类簇分配,根据式(7)的中国餐馆过程来确定:
其中nm,-i是簇m中除obi外的实例数.
式(6)第2 行的第2 项是给定当前所有类簇分配条件下obi的概率,根据多元正态分布确定:
其中μm,-i和Σm,-i是类簇m不包括obi时的均值和协方差.
3.1 基于异常特征模式识别锚异常
如果ED和WD共享某个锚模式,则在2 个数据集上对应的模式表达不仅应该相似,而且对应的2个类簇上应有尽可能多的具有相同标签集ls∈2U的样本.因此,2 个模式集合的最优一对一映射
要满足2 个条件:
1)配对的异常特征模式的平均Wasserstein 距离
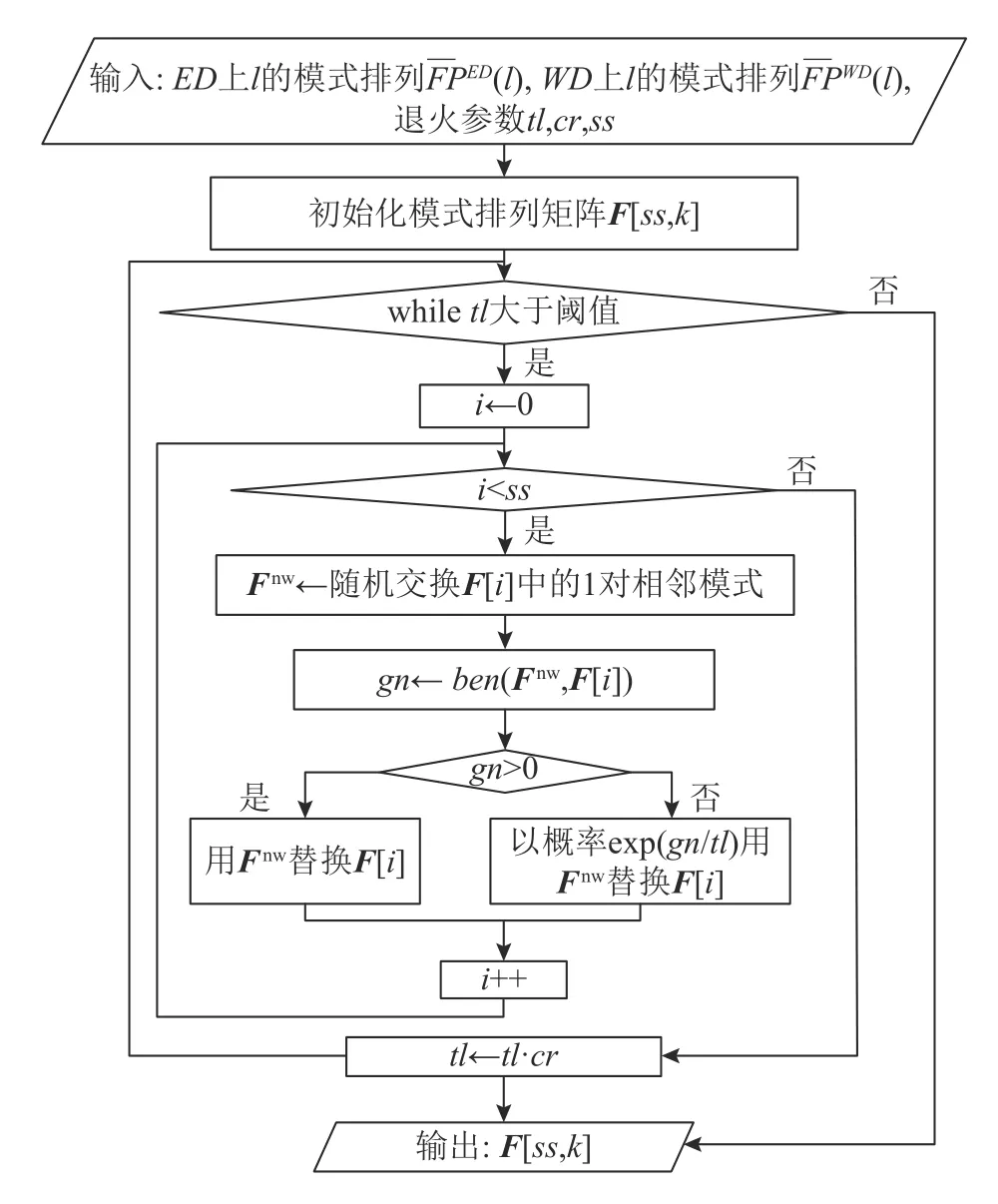
Fig.2 Flow chart of algorithm for pattern ordering on WD图2 WD 上模式排序算法流程图
式(12)的直观含义:如果新排列优于原排列,则返回1,否则返回-|dtAWD+dtAJSD|.当迭代结束时,有ss个候选解,从候选解中选择一个最优解或非劣解.模式排列算法的运行时间主要由嵌套循环决定,其时间复杂度为O(ss·logcrtl).
最后,模式排列算法返回的每个候选解,对应1组AWD和AJSD,计算这ss个候选解的平均值作为阈值.然后,将平均值低于该阈值的候选解作为锚模式.一旦确定了标签的锚模式,给定一个实例ob∈WD,锚模式对应的异常标签称为ob的锚标签,同时是该实例的相关标签.然后,将ED和WD的锚标签样本结合,形成一个训练数据集TD,在TD上挖掘标签发现、排除规则并构建二分类器.
3.2 挖掘标签发现和排除规则
3.2.1 在TD上挖掘标签发现规则
在心电数据中,一个异常经常表现出若干特征模式.标签发现规则用来指示频繁共同出现的异常特征模式.给定2 个异常特征模式fpi(ls)和fpj(lt),标签发现规则fpi(ls)=>fpj(lt)表明:若某个实例同时落入fpi和fpj的特征模式,并且该实例有异常标签ls,则该实例有异常标签lt.
例1.设有2 个异常标签A和B,A是前壁心肌梗死,B是左后分支传导阻滞.假设某个标签发现规则是fpi(A)=>fpj(B),其中
令fq(fpi(ls) )和fq(fpj(lt) )分别代表Ci(ls)和Cj(lt)中呈现fpi(ls)和fpj(lt)模式的样本个数,则标签发现规则的支持度和置信度定义为式(13)(14):
其中fq(fpi(ls)∪fpj(lt))是同时呈现fpi(ls)和fpj(lt)模式的样本个数.
模式的正相关性根据Kulczynski(记为Kulc)度量:
直观地,如果cort=0.5,则fpi(ls)和fpj(lt)相互独立;如果cort接近1,则fpi(ls)和fpj(lt)正相关;如果cort接近0,则fpi(ls)和fpj(lt)呈负相关.
综上所述,给定支持度阈值st、置信度阈值ct和正相关阈值rt,一个标签发现规则fpi(ls)=>fpj(lt)必须满足3 个条件:1)supp(fpi(ls)=>fpj(lt))≥st;2)conf(fpi(ls)=>fpj(lt))≥ct;3)cort(fpi(ls)=>fpj(lt))≥rt.
本文通过2 个步骤挖掘标签发现规则.首先,根据支持度阈值st和置信度阈值ct,挖掘两两标签间的关联规则[44].每个关联规则ls→lt表明,如果ls出现,则lt就会出现.进一步,根据算法2 将关联规则提炼为标签发现规则.
算法2.generateInclusionRule.
输入:标签间的关联规则LR,异常特征模式AFP,支持度阈值st,置信度阈值ct,正相关阈值rt;
输出:标签发现规则.
算法2 的时间复杂度为O(|LR|·q2),其中|LR|是标签间的关联规则数量,q是一个异常对应的特征模式数量的上界.
3.2.2 在TD上挖掘标签排除规则
定义5.标签排除规则.给定2 个异常标签ls和lt,如果
则认为ls和lt是强负相关的,记ls⇎lt,其中fq(ls∪lt)是同时有标签ls和lt的样本个数.
为了度量强负相关性,引入阈值ε(0 <ε≪ 1),如果
则认为fp(ls)和fp(lt)是强负相关的.直观含义是,如果ls在某个实例上呈现,则lt不会在该实例呈现,反之亦然.采用算法3 实现标签排除规则的挖掘.
算法3.generateExclusionRule.
输入:频繁标签对集合FS,负相关阈值ε;
输出:标签排除规则.
算法3 的时间复杂度为O(|FS|),其中|FS|是频繁标签对的数量.
3.3 构造二分类器
这里θl是分割阈值,介于0~1 之间,ρl是模糊间隔长度.如果hasLabel返回1,l是ob的相关标签;如果返回-1,l是ob的无关标签;否则,无法确定l是否属于ob,需要在下一轮迭代判断.因为dr的值介于0~1 之间,所以符合Beta 分布:
其中α,β是确定密度函数形状的参数.则平均值 μ*和标准差 δ分别是
因此,设置 θl=μ*,ρl=δ.
4 迭代清洗WD 中的弱标签
WD中的异常标签通过2 个步骤进行清洗,即弱标签预处理和迭代清洗.
4.1 弱标签预处理
给定一个实例ob∈WD,其锚标签集合al(ob)属于相关标签集合rl(ob).cl(ob)代表弱标签集合,其中的标签可能属于rl(ob),也可能不属于rl(ob).对弱标签预处理时,确认弱标签是相关或不相关标签,从而缩小弱标签集合.具体过程如算法4 所示,给定一个实例ob,如果它落入一个标签发现规则两侧的异常特征模式,并具有该规则的左侧标签,则右侧标签属于其相关异常rl(ob).具体地,给定实例ob和异常特征模式NM(μ,Σ),如果ob落入(μ-3·Σ,μ+3·Σ)区间,则ob∈NM.对不相关标签排除时,如果标签排除规则一侧的标签属于给定实例,则丢弃另一侧的标签,将该标签从弱标签集合cl(ob)中删除.
算法4.reduceWeakLabelSet.
输入:样本ob,标签发现规则IR,标签排除规则ER;
输出:ob的相关标签和缩减后的弱标签集合.
算法4 的运行时间取决于一个实例的标签数和针对一个标签的规则数,所以它的时间复杂度是O(u·Mr),其中u是U的大小,Mr是单个异常的标签发现或排除规则的最大数目.实际中,算法4 运行时间远小于O(u·Mr),因为一个实例的标签数目通常远小于u.
4.2 迭代清洗弱标签
标签清洗时,二分类器BD迭代地对剩余的弱标签进行区分,扩展相关标签集合或从cl(ob)中清除不相关标签,同时更新二分类器BD.为避免ob无休止地参与迭代,须设定其生存指数lf(ob).为此,在ED∪WD上构建隔离森林iForest[40].实例在隔离森林中的平均路径长度apl(ob)作为ob的生存指数分量.每轮迭代中,ob的生存指数lf(ob)修改为:
其中x是控制变化率的因子.式(25)的合理性在于,apl(ob)越大,ob越可能被经常出现的特征模式覆盖,因此需要的迭代次数越少;|cl(ob)|越大,需要越多的迭代来区分其中的相关标签和非相关标签.
迭代清洗的算法流程如图3 所示,迭代直到所有弱标签被分类为相关标签或不相关标签,或生存指数小于等于0.在ob到期后,如果仍无法确定标签l是否属于ob,将这项任务留给人工识别.每轮循环时,一方面确定相关和不相关标签,另一方面调用update-Discriminator更新异常特征模式参数和所有标签的二分类器.迭代清洗算法的时间复杂度是O(N·ul·l fm),其中N是WD的大小,ul是一个实例的弱标签数目的上界,l fm是实例的生命周期的上界.
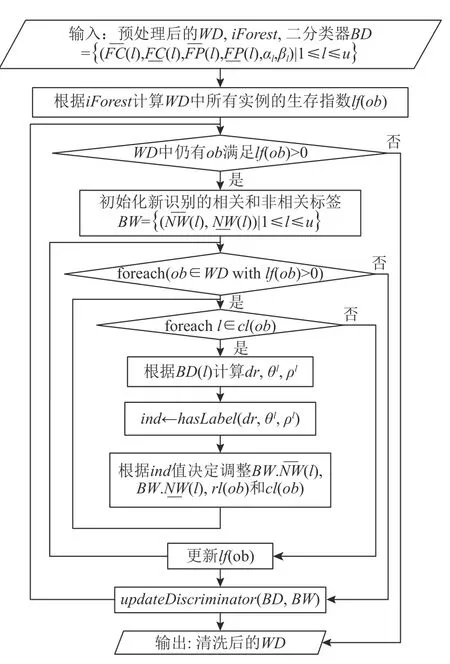
Fig.3 Flow chart of iterative cleaning algorithm图3 迭代清洗算法流程图
图3 中的标签迭代清洗调用updateDiscriminator实现二分类器更新,二分类器更新的算法流程如图4所示.首先,将新识别的实例和标签分配给相应的正、负类簇,并调整Beta 分布,进而根据类簇样本调整异常特征模式参数.这是为每个异常标签l调整分割阈值 θl和模糊区间 ρl的基础.
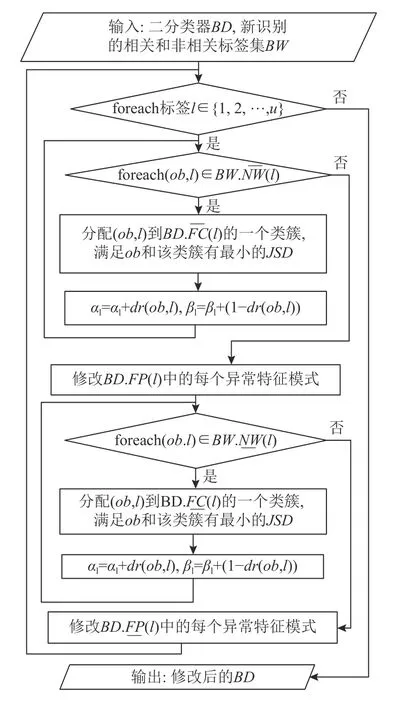
Fig.4 Flow chart of updateDiscriminator图4 二分类器更新算法流程图
5 实验评估
实验在配备AMD CPU(8 核@2.90 GHz)和16 GB内存的计算机上运行,原型系统用Python 实现,
实验共采用了3 个心电数据集,前2 个是从社区医疗中心收集的真实数据集,每个样本是12 导联、10 s 的记录,采样频率为500 Hz.异常标签共有16 个,如表1 所示.一个数据集CHE 包含3 919 个样本,心电异常标签由专业医生标记和确认,标签是完整和正确的.另一个数据集CHW 包含12 385 个样本,部分标签缺失或不正确.第3 个是MIT-BIH 的公共数据集[45],记为MIT.MIT 收集了其中40 个包含II 和VI 导联、30 min 的心电记录,取样频率是360 Hz,将每个心电记录分成等长的180 个长度是10 s 的样本,将每个样本心跳对应的标签合并,作为该样本的多标签.由于个别标签的样本非常稀疏,实验时采用了包含表3 所示的8 个异常标签的7 166 个样本.心电波去噪,基线漂移消除,QRS 波、P 波和T 波的识别和特征提取按文献[39]所述实现,每个样本取100 个特征.

Table 3 Abnormality Labels in MIT-BIH Dataset表3 MIT-BIH 数据集中的异常标签
为了度量标签清洗的效果,采用3 个指标,即precision,recall,F1,它们根据表4 所示的3 个指标定义.

Table 4 Meanings of TP,FP and FN表4 TP,FP,FN 的含义
给定一个标签l,其precision,recall,F1 定义为
汇报的度量根据标签的权重计算平均值.例如,测试集TS上precision的计算为
一方面,在真实的示例数据集CHE 和弱数据集CHW 按照如下步骤验证方法效果.CHW 作为弱数据集WD,由于难以确定WD上的准确标签,根据训练的分类器效果间接度量标签的清洗效果.首先,将CHE 分为2 部分:1/3 的CHE 作为测试集TS,其余作为示例数据集ED,对WD的清洗效果按照3 个步骤计算:
1)在WD上为每个异常训练1 组二分类器.然后,在TS上计算precision,recall,F1,分别记为precisionorg,racallorg,F1org.
2)在WD的清洗数据集上为每个异常训练1 组二分类器,进而在TS上计算precision,recall,F1,分别表示为precisioncln,recallcln,F1cln.
3)上述2 次测量值的差作为性能指标.例如,对于d f1=F1cln-F1org作为性能指标.
另一方面,分别在CHE 和MIT 上模拟噪声标签,形成2 个模拟数据集SCHE 和SMIT 来评估方法效果[7],即将各类标签按照一定的比率替换为不属于样本的随机标签,形成噪声标签.具体地,从CHE 中选择1/3 的样本作为ED,另外的2/3 的样本生成2 份拷贝.一份作为正确标签参照,另一份引入不同级别(5%,10%,20%,30%,40%)的噪声标签作为WD.在MIT 上也同样操作.然后,对WD进行清洗,清洗后的样本与参照相对比,从而计算precision,recall,F1.为避免实验结果的随机性,使用6 折交叉验证计算各个度量.根据采样效果,设置阈值st=10.
5.1 影响标签发现规则和排除规则的因素
给定一个规则,其准确率(acc)是正确识别的正(或负)标签占识别出的正(或负)标签的比例.下面分析在不同噪声水平下2 种标签规则的影响因素.除特别说明,本节汇报的是在SCHE 上的结果,其他数据集上的结果呈现相同趋势,不再赘述.
5.1.1 影响标签发现规则的因素
图5 和图6 分别显示了在噪声水平为10%和30%时,固定其他参数,置信度阈值ct从0.1 增加到0.6 时,准确率acc的变化.可以看出,随着ct的增加,准确率先增大,然后趋于平稳.在其他噪声水平下,呈现类似的趋势.这是因为ct越大,规则的置信度越高,规则的约束性更强,被包含的标签的准确度更高.
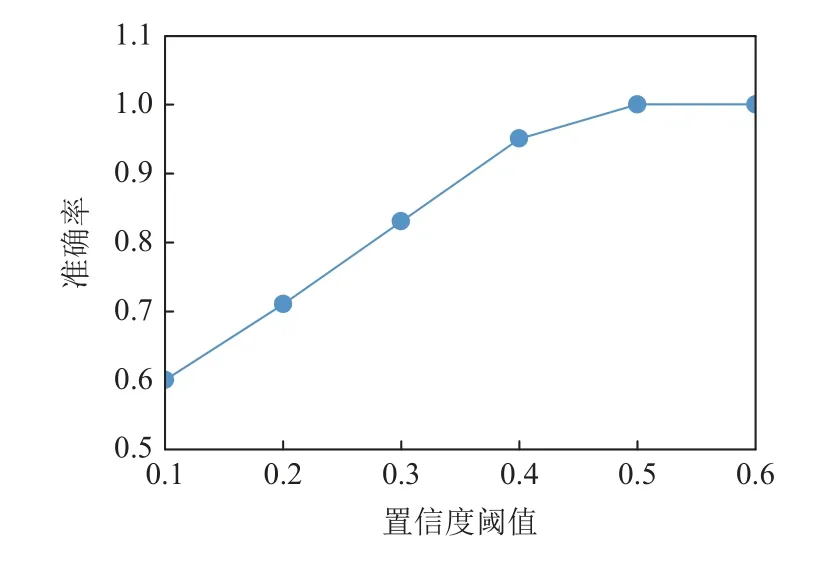
Fig.5 acc changing with ct at noise level 10%图5 噪音水平10%时准确率随置信度阈值的变化
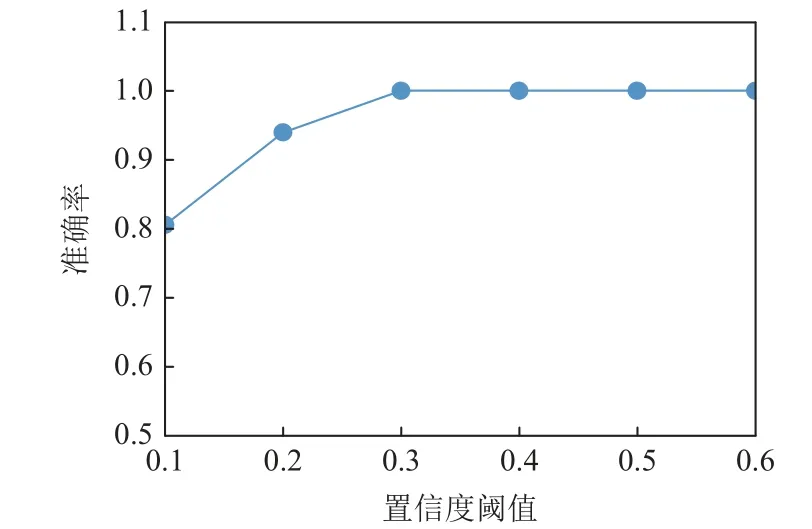
Fig.6 acc changing with ct at noise level 30%图6 噪音水平30%时准确率随置信度阈值的变化
图7 和图8 分别显示了在噪声水平为10%和30%时,固定其他参数,正相关阈值rt从0.1 增加到0.6 时,准确率的变化.可以看出,随着rt的增加,准确率先增大然后趋于平稳.在其他噪声水平下,呈现类似的趋势.这是因为正相关性越高,对2 个标签共现频率的约束越高.实验中,在模拟数据集上,对不同噪音水平采用不同的ct和rt.在真实数据集上,根据采样估计ct和rt.
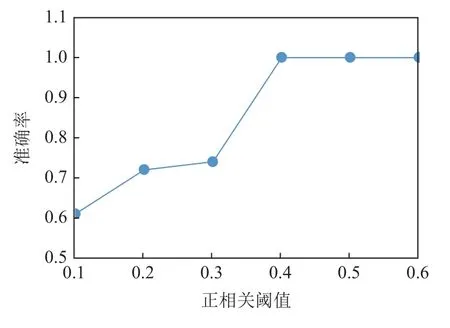
Fig.7 acc changing with rt at noise level 10%图7 噪音水平10%时准确率随正相关阈值的变化
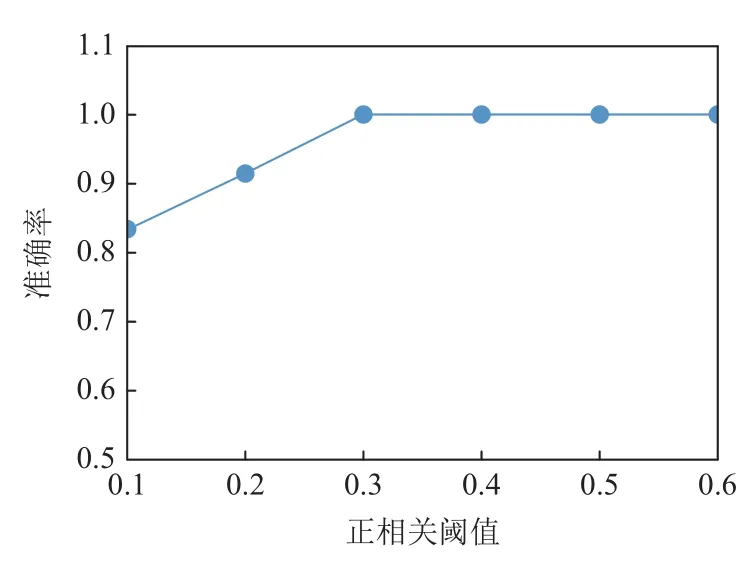
Fig.8 acc changing with rt at noise level 30%图8 噪音水平30%时准确率随正相关阈值的变化
5.1.2 影响标签排除规则的因素
图9 和图10 分别显示了在噪音水平为10%和30%时,acc随阈值ε的变化.随着ε的增加,准确率先升高,然后降低.这是因为,若ε太小,约束过于严格,会约束一些有效的标签排除规则,导致准确率受错误识别标签的影响;而随着ε变大,可以有效地发现更多排除规则,使得准确率趋于稳定;但ε进一步变大,也会导致排除规则准确率降低.在其他噪音水平,呈现类似的效果.
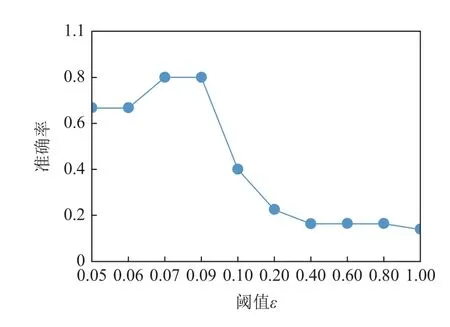
Fig.9 acc changing with threshold ε at noise level 10%图9 噪音水平10%时准确率随阈值ε 的变化

Fig.10 acc changing with threshold ε at noise level 30%图10 噪音水平30%时准确率随阈值ε 的变化
5.2 消融实验
AFP 方法的标签清洗包含3 个关键环节:第1 步(ph1),在ED和WD上寻找共享异常特征模式,进而识别WD上的锚标签(是初始标签的一部分);第2 步(ph2),挖掘标签发现和排除规则,然后扩充WD上样本的初始相关标签集;第3 步(ph3),利用二分类器进行弱标签的迭代清洗.为了验证各个环节的作用,AFP 方法分别消除ph1,ph2,ph3,记为AFP-ph1,AFPph2,AFP-ph3 后,汇报综合性能指标F1 的变化情况.
图11~15 汇报了噪声水平分别为5%,10%,20%,30%,40%时2 个模拟数据集SCHE 和SMIT 上的消融实验结果.图16 汇报了在真实数据集CHE 和CHW 上的消融实验结果.模拟和真实数据集上的结果表明:
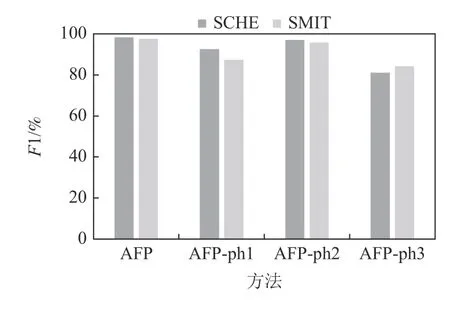
Fig.11 Ablation experiment at noise level 5%图11 噪声5%的消融实验

Fig.12 Ablation experiment at noise level 10%图12 噪声10%的消融实验
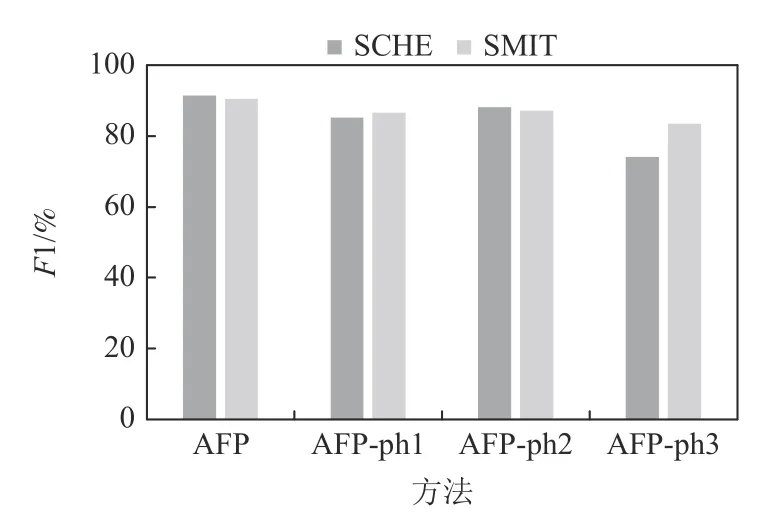
Fig.13 Ablation experiment at noise level 20%图13 噪声20%的消融实验
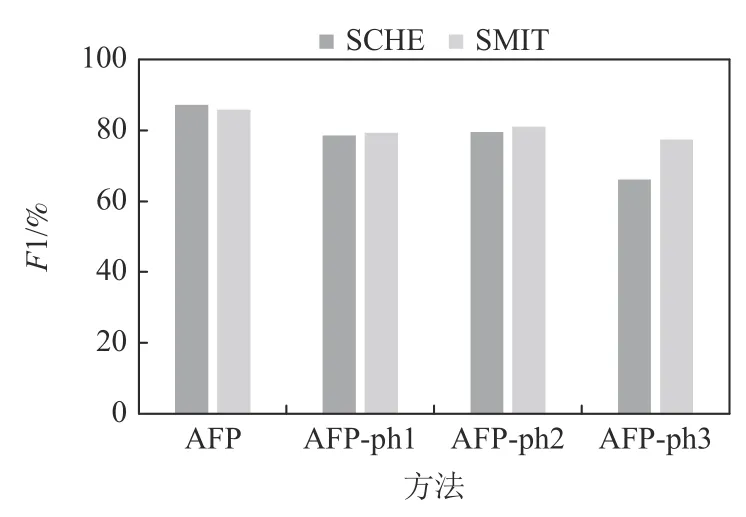
Fig.14 Ablation experiment at noise level 30%图14 噪声30%的消融实验
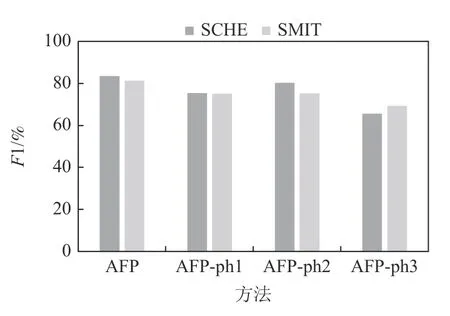
Fig.15 Ablation experiment at noise level 40%图15 噪声40%的消融实验
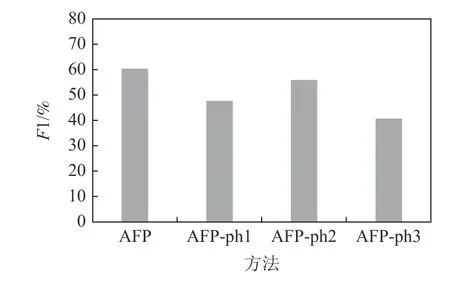
Fig.16 Ablation experiment on real dataset图16 真实数据集上的消融实验
1)在不同的噪声水平下去除步骤ph1 后,在模拟数据集SCHE 上,F1 指标降低了5.8~7.99 个百分点,SMIT 上降低了6.21~10.17 个百分点,在真实数据集上,F1 降低了12.68 个百分点.这是因为如果没有ph1,不仅不能确定WD的锚标签,而且不能利用含锚标签的WD样本来扩充规则挖掘的可用样本.
2)在不同的噪声水平下去除步骤ph2 后,SCHE上的F1 指标降低了1.37~7.63 个百分点,SMIT 上降低了1.75~6.12 个百分点,真实数据集上降低了4.43个百分点.这是因为,步骤ph2 根据挖掘的规则确定属于样本的异常标签,在扩充初始相关标签集的同时,尽量避免引入错误标签.
3)在不同的噪声水平下去除步骤ph3 后,模拟数据集SCHE 上的F1 指标降低了16.89~20.93 个百分点,在SMIT 上F1 降低了7.07~13.25 个百分点,真实数据集上的F1 指标降低了19.71 个百分点.这是因为二分类器在清洗中不断自调整,有效地识别单次清洗中无法识别的、处于分布边缘的标签.可见,步骤ph3 居于AFP 的主体地位.
5.3 比较研究
在模拟和真实数据集上,AFP 方法与交叉验证(cross validation,CV)方法[7]和基于DDF 的标签噪声过滤方法[38]进行了比较.CV 方法利用SVM,KNN,NB,LDA 和DT 这5 种分类器,协同识别标记错误的样本.CV 方法为每个标签训练5 个分类器,如果5 个分类器对一个实例的标签持不同认知,则认为该标签被错误标记.根据3 个标准S1,S2,S3 确定样本是否被错误标记.对于S1,如果5 个分类器都认为异常不属于实例,则该异常是错误标签.对于S2,如果4个或更多分类器认为异常不属于实例,则认为该异常标记错误.对于S3,如果3 个或更多分类器认为异常不属于该实例,则认为该异常标记错误.DDF 方法将每个样本的邻域样本划分为高密度和低密度区域,然后针对不同的区域采用不同的噪声过滤规则进行过滤.由于DDF 能够识别出噪声标签,但不能自动修补,因此在模拟数据集上对每个标签计算precision时,用DDF 排除掉噪声标签后的该类标签数目作为识别出的该类标签数目.
图17~21 汇报了AFP,CV,DDF 方法在SCHE 上的precision,recall,F1 值.可见,当数据噪声级别为5%时,AFP 方法的F1 指标比CV-S1 高5.15 个百分点,比CV-S3 高 23.42 个百分点,比DDF 高18.73 个百分点.当噪声水平为10%时,AFP 方法的F1 指标比CV-S1 高 3.35 个百分点,比CV-S3 高21.53 个百分点,比DDF 高17.13 个百分点.当噪声水平为20%时,AFP 方法的F1 指标比CV-S1 高0.7 个分点,比CVS2 指标高8.17 个百分点,比CV-S3 高17.75 个百分点,比DDF 高14.25 个百分点.当噪声水平为30%时,AFP 方法的F1 指标比CV-S1 低1.63 个百分点,但比CV-S2 和CV-S3 分别高5.16 和14.44 个百分点,比DDF 高12.1 个百分点.当噪声水平为40%时,AFP 方法的F1 指标比CV-S1 低3.93 个百分点,比CV-S2 和CV-S3 分别高1.86 和 11.18 个百分点,比DDF 高9.84个百分点.实验结果表明,AFP 在SCHE 的噪声不是很高的情况下,清洗效果优于CV 方法;在数据噪声很高的情况下,AFP 方法略低于CV-S1 方法,仍优于CV-S2 和CV-S3;同时,AFP 稳定地优于DDF 方法.
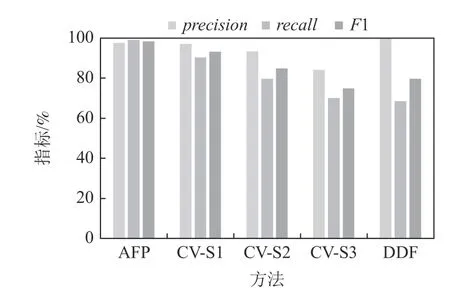
Fig.17 Performance comparison over SCHE at noise level 5%图17 在SCHE 上噪声5%时的性能比较
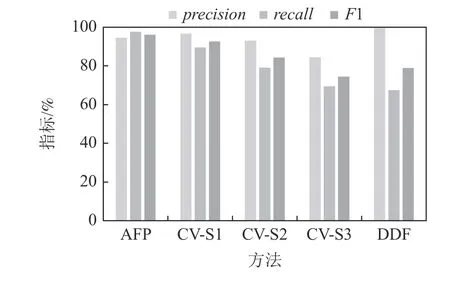
Fig.18 Performance comparison over SCHE at noise level 10%图18 SCHE 上噪声10%时的性能对比
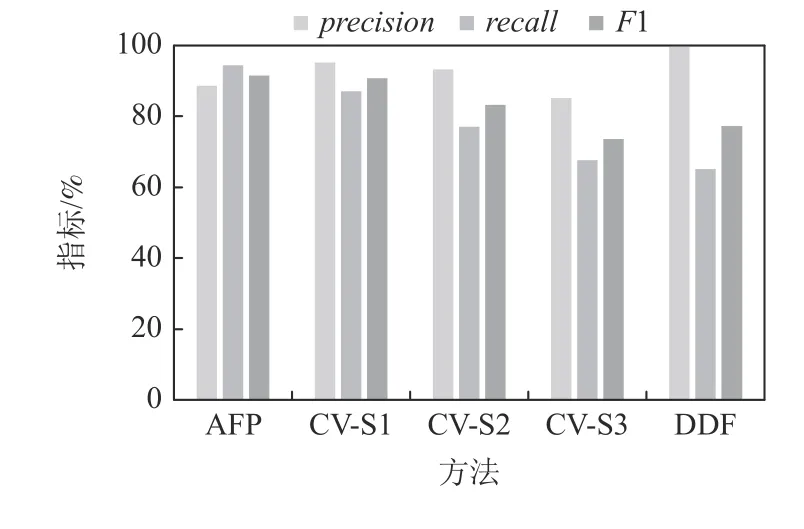
Fig.19 Performance comparison over SCHE at noise level 20%图19 SCHE 上噪声20%时的性能对比
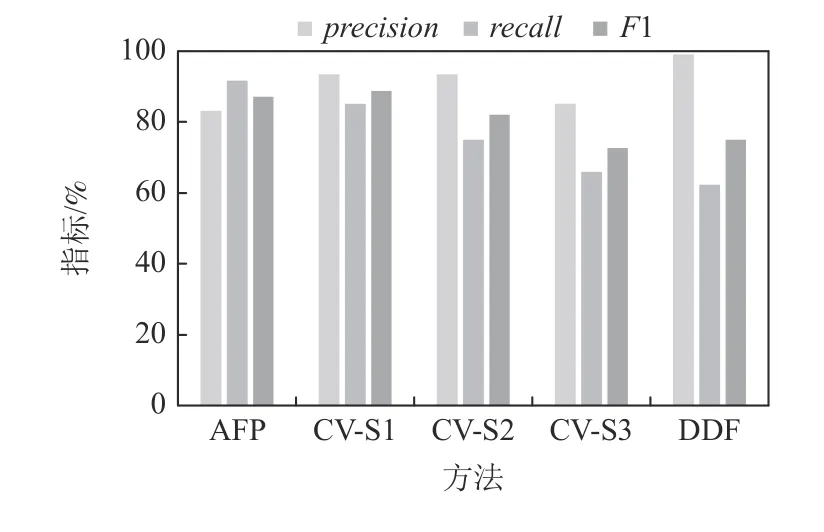
Fig.20 Performance comparison over SCHE at noise level 30%图20 SCHE 上噪声30%时的性能对比
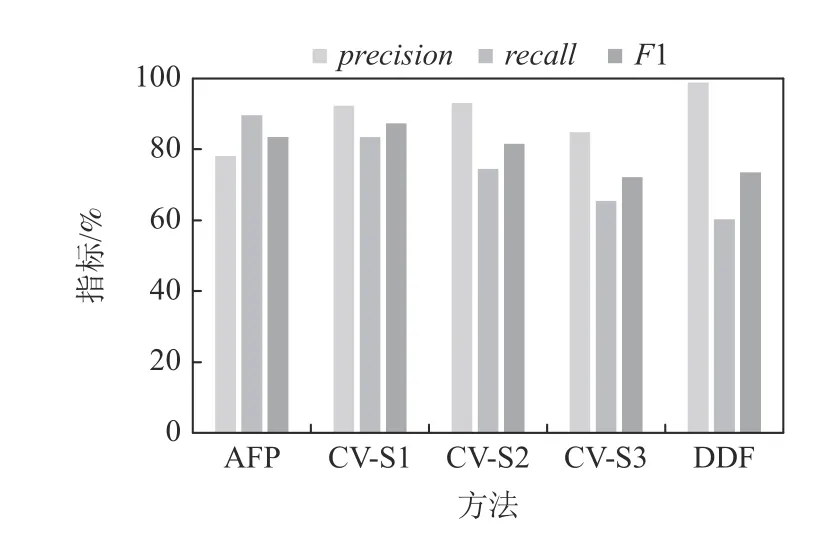
Fig.21 Performance comparison over SCHE at noise level 40%图21 SCHE 上噪声40%时的性能对比
图22~24 汇报了SMIT 上噪声为5%,20%,40%时的实验结果.当噪声级别为5%时,AFP 方法的F1指标比CV-S1 高3.25 个百分点,比CV-S2 高 4.6 个百分点,比CV-S3 高 11.33 个百分点,比DDF 高8.16 个百分点.当噪声水平为20%时,AFP 方法的F1 指标比CV-S1 高1.26 个分点,比CV-S2 高 0.11 个百分点,比CV-S3 高6.09 个百分点,比DDF 高4.28 个百分点.当噪声水平为40%时,AFP 方法的F1 指标比CV-S1高0.64 个百分点,比CV-S2 低1.66 个百分点,比CVS3 高 2.33 个百分点,比DDF 高2.88 个百分点.其他噪声水平下呈现类似趋势,不再赘述.实验结果表明,在噪声不是很高的情况下,AFP 方法在SMIT 上稳定地优于CV 方法;在噪声很高的情况下,AFP 方法仍优于CV-S1 和CV-S3 方法;另外,AFP 稳定地优于DDF 方法.
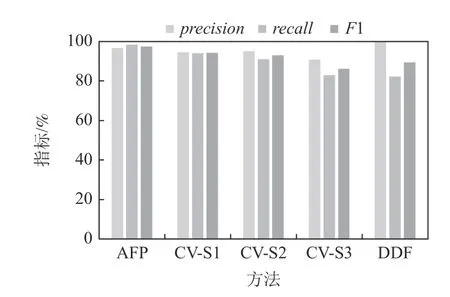
Fig.22 Performance comparison over SMIT at noise level 5%图22 SMIT 上噪声5%时的性能对比
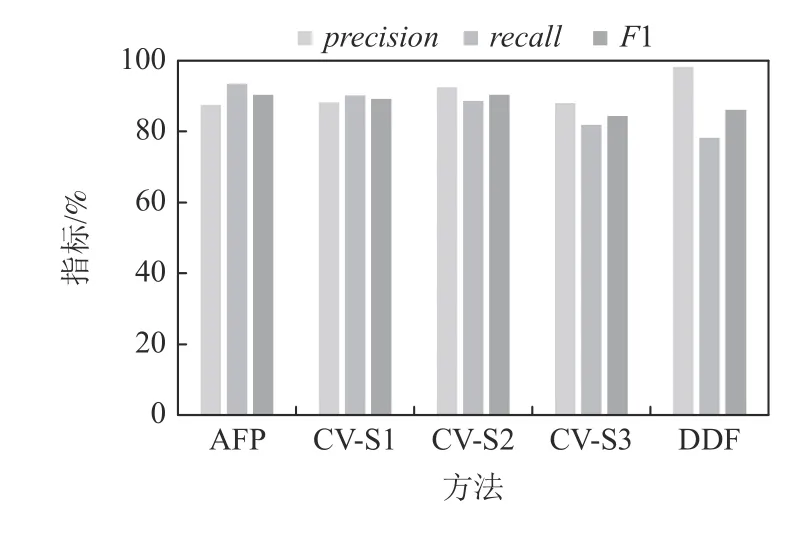
Fig.23 Performance comparison over SMIT at noise level 20%图23 SMIT 上噪声20%时的性能对比
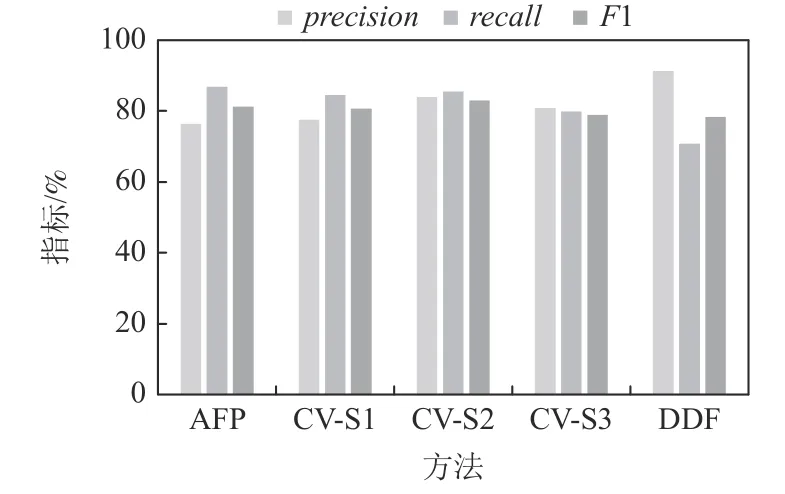
Fig.24 Performance comparison over SMIT at noise level 40%图24 SMIT 上噪声40%时的性能对比
同时,在真实数据集CHE 和CHW 上进行了比较.首先,在原始数据集CHW 上训练分类模型,然后分别用AFP,CV,DDF 方法对数据集进行清洗,比较在清洗前和清洗后的数据上训练分类器的性能指标.表5 显示了在真实数据集上的比较结果.AFP 方法的平均F1 指标提高5.19 个百分点,CV-S1 和CV-S2 分别提高1.06 和0.22 个百分点,DDF 提高3.13 个百分点.AFP 方法性能的优越主要因为2 个原因:首先,AFP 方法根据类簇在示例数据集和弱标签数据集上的一致性来识别锚异常,充分利用了人工标注的知识,也利用了弱标签数据集的可用信息.其次,采用迭代框架,逐步缩小模糊区间来推断异常标签,保证了清洗效果的可靠和稳步提升.
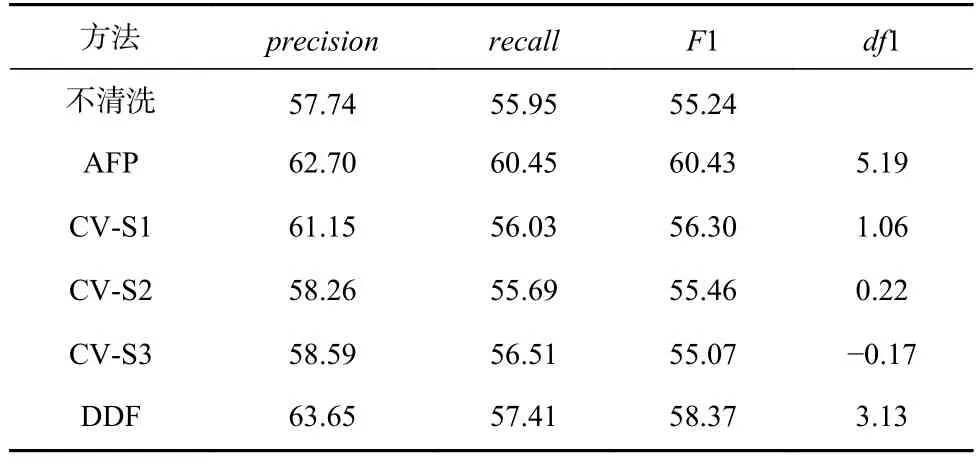
Table 5 Comparison of AFP,CV and DDF on Real Dataset表5 真实数据集上AFP,CV,DDF 方法的对比 %
6 结论
根据心电图(ECG)判断心脏异常是临床广泛应用的心脏健康检测技术.目前,自动异常检测主要采用有监督学习技术来实现.由于生物电信号的多样性和相关性,一个好的分类器通常需要依赖大量的高质量标签样本,才能保证分类器的精度和泛化性.这点对于当前流行的深度学习技术尤为重要.然而,高质量的心电标注不仅需要专业的心电知识,而且要耗费大量的时间和精力.实际中,经常会有一些标注缺失或错误的心电数据集,如何对这些弱标签的心电数据进行清洗,提高标注质量,使其变得可用,是一个很有价值的问题.
设有一个包含所有正确标签的示例数据集,可大可小,这在实际中完全可行.问题转化为在示例数据集的辅助下,对弱标记数据集进行标签清洗,将其转化为一个干净数据集.由于一个心电异常通常表现出不同的特征模式,提出了一种基于标签特征模式的标签清洗方法.该方法首先确定高置信度属于实例的锚标签,它们是相关标签集的子集.然后,以迭代方式清洗其他弱标签.本文总结为3 个方面:1)根据示例数据和弱标签数据的一致性来识别锚特征模式,充分结合了人工知识和数据的统计特性来提高标签区分能力.2)提出了挖掘标签发现和排除规则的具体方法.前者用于包含相关标签,而后者用于删除无关标签.3)采用迭代框架逐步清洗标签,保证清洗效果的可靠和稳定.在真实和模拟数据集上的实验结果证明了方法的有效性.未来将研究根据病症的因果关系提高清洗效果.
作者贡献声明:韩京宇负责论文思路、实验方案、论文撰写和修改;陈伟和赵静负责实验和数据整理;郎杭负责相关文献查阅和方法改进;毛毅提供实验平台和专业知识指导.
猜你喜欢
昆明医科大学学报(2021年4期)2021-07-23
电子制作(2019年19期)2019-11-23
中国生物医学工程学报(2019年6期)2019-07-16
心电与循环(2019年2期)2019-02-19
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
电测与仪表(2014年15期)2014-04-04
