
一种考虑隐私保护的深度强化学习任务分配模型
2023-11-24 05:25杨明川朱敬华李元婧奚赫然
计算机研究与发展 2023年11期
杨明川 朱敬华,2 李元婧 奚赫然,2
1(黑龙江大学计算机科学与技术学院 哈尔滨 150006)
2(数据库与并行计算重点实验室(黑龙江大学)哈尔滨 150006)
(mrvincenty@163.com)
移动群智感知(mobile crowdsensing,MCS)是Ganti等人[1]提出的,是一种在用户或社区之间感知和共享数据的新方法.Guo 等人[2]给MCS 更为明确的定义:“MCS 是一种新的感知范式,使普通公民能够贡献从移动设备感知或生成的数据,聚合和融合云中的数据,用于人群智能提取和以人为中心的服务交付.”[3]随着高性能的便携式移动设备与高速智能网络的普及,移动群智感知技术快速发展并深入到智慧医疗、交通流量预测以及智慧城市等各个领域,需要采集处理的数据集也日渐庞大,MCS 系统需要大量用户的参与和贡献[4],如何在数量庞大的参与者中选择合适的参与者完成给定的感知计算任务,且最大化平台和用户的收益显得格外重要.任务分配系统主要由3 部分组成:平台(任务发布者)、工人(用户,携带移动智能设备负责采集感知数据)和任务(如收集某地区的空气质量数据、监测某路段的交通流量等).如图1 所示,任务由平台基于一定的收益计算机制分配给工人,然后工人利用移动智能设备到指定任务点进行相关感知数据的收集并上传到平台获取相应报酬.一方面,考虑到任务的时效性以及预算,任务应当被合理地分配给合适的工人,保证任务分配合理化的同时尽可能最大化平台总收益;另一方面,工人上传信息时通常无法避免暴露自身位置等隐私信息.因此,在MCS 系统中,合理的任务分配机制与工人信息的隐私保护问题尤为重要.传统的任务分配算法,如蚂蚁算法、贪婪算法,适合于小规模数据集,应用于工人与任务信息固定的静态系统,但实际问题中工人与任务的位置、状态信息会不断改变,因此,深度学习被越来越多的研究者引入到这样的动态系统中来解决相应的动态规划问题.
Fig.1 Diagram of MCS task assignment system图1 MCS 任务分配系统图示
深度强化学习(deep reinforcement learning,DRL)可以基于过去的经验,通过智能体选择动作与环境交互并获得相应的状态和回报[5],在每次进行决策的过程中,智能体的策略选择的概率分布不断调整,最终达到最优的全局策略.因此在动态的MCS 问题中,DRL 往往能发挥更好的性能.在DRL 的众多方法中,DQN(deep Q-network)[6]和 A3C(asynchronous advantage actor-critic)[7]可以表现出良好性能,但仅限在离散的动作空间中;DDPG(deep deterministic policy gradient)[8]是一种离线的、确定性的方法,相对不适合需要实时控制解决方案的动态场景;TRPO(trust region policy optimization)[9]采用信任区域方法,其性能优于许多随机在线策略梯度方法,更适合于需要更多探索的场景;PPO(proximal policy optimization)[10]是一种无模型的、基于策略的、基于梯度的强化学习方法,它在连续控制问题的表现极其优异,并具有TRPO 的相应优点且实现复杂性要低得多.本文的算法采用了PPO 框架,该框架可以更好地适配离散型和连续型的状态/动作集合,甚至在复合型的状态/动作集合的表现也较为良好,并且相对于其他的DRL方法,PPO 的表现也较为优异,具有更快的收敛性.
同时,考虑到工人在与平台进行数据交互时往往会暴露自己的移动轨迹信息,因而本文采用本地差分隐私在工人与平台的交互中进行隐私保护.差分隐私的概念最早由Dwork[11]提出,建立在严格的数学理论基础上,对隐私保护提供了量化的评估方法和严谨的数学证明.本文方法在平台与工人的信息交互中,利用本地差分隐私的方法,对其位置信息加入随机噪声,最大限度地保护工人的隐私信息.
本文是面向MCS 任务分配问题,使用DRL 与差分隐私方法在保护隐私的前提下获得优化的任务分配策略.将动态环境下的任务分配问题定义为一个基于离散型数据集来进行动态规划的优化问题,并使用基于DRL 的算法来解决动态环境下的任务分配问题.具体来说,在每次迭代开始时,该算法观察了之前迭代中平台的分配策略、平台收益、工人收益、现有任务信息以及工人信息.根据观察结果,由基于DRL 的算法来决定工人分配到的任务以及任务的顺序,在此过程中利用差分隐私来对工人相关隐私信息做了模糊化处理.本文的目标是最大化平台的总收益和工人收益,被定义为工人收益与平台总收益的联合约束问题,此外还考虑了隐私保护的相关问题.本文的主要贡献总结为4 个方面:
1)将MCS 动态场景下的任务分配问题建模为一个多目标优化问题,并证明为NP-hard 问题.充分考虑了在MCS 的任务分配问题中,工人与任务状态信息不断变化的动态系统,以及工人与平台进行数据交互的隐私保护的必要性.
2)提出基于DRL 的PPO 方法求解该优化问题.相比于传统方法,DRL 在中大型数据集的MCS 问题中表现性能良好、收敛性好,能更快达到最优解,同时考虑了真实的MCS 中工人和任务的动态性,利用DRL 方法更适用于解决此类动态的、非确定性的MCS 问题.
3)提出基于差分隐私的任务分配方法.在工人的智能移动设备与中央服务器交互中利用本地差分隐私的方法,对工人的位置信息加入随机噪声,模糊化工人位置信息,进而解决中央服务器收集工人信息时存在的隐私泄露问题.
4)通过实验评估本文方法的有效性和高性能.通过模拟数据集的实验,对比了传统方法与现有方法,验证了本文的模型具有稳定性能,且收敛效果较好;此外还进行了消融实验,证明了加入隐私保护方法的有效性.
1 相关工作
1.1 传统任务分配方法
Cheung 等人[12]研究了时间敏感和位置依赖的感知任务的分配问题.考虑到具有不同初始位置、移动成本和速度以及声誉级别的异构用户,提出了一种贪婪算法来计算该问题的近似解.该算法要求每个用户专注于自己的收益,并向用户提供一个异步的分布式算法来计算用户的移动性计划.该算法的设计目标是最大化用户收益,但无法适用于工人状态信息变化的动态系统.在文献[13]中,Li 等人提出了基于蚁群算法ACO(ant colony optimization)的启发式多任务调度算法来确定任务调度策略,对工人福利的计算模型进行理论分析,利用基于ACO 的启发式多任务调度算法来确定任务调度策略,以最大限度地提高工人的利益.但该方法同样仅适用于静态系统,对于动态系统,越来越多的研究者倾向于基于DRL 的算法[14-15].
1.2 基于DRL 的算法
2013 年谷歌的DeepMind 团队发表了利用强化学习玩Atari 游戏的文章[16],DRL 开始炙手可热,相关算法被更多的研究者引入到各个领域.Kim 等人[17]将DRL 的方法应用于无人机的任务分配问题上,用基于Q 值的深度强化学习算法 DQN 来实现快速策略收敛,从而有可能适用于更大规模的系统,进而解决难以量化的由随机环境引起的无人机移动性的随机性问题.Tao 等人[18]使用双深度Q 网络(double deep Q-network,DDQN)来解决任务分配问题,作为一个具有时间窗的路径规划问题,考虑了感知任务的位置依赖性和时间敏感性,以及工人在最大旅行距离方面的资源限制.在文献[19]中,Patel 等人针对联邦环境下计算资源分配问题,提出了一个旨在使系统总成本最小化的优化问题,并将其定义为训练时间和能量消耗的加权和.考虑到非线性约束的难度和网络质量的不稳定,该团队设计了一种基于DRL的经验驱动算法,该算法可以在不了解网络质量的情况下收敛到接近最优解.
1.3 差分隐私
在文献[11]中,差分隐私的概念被Dwork 首次提出,该文章通过严谨的数学证明,可以保证数据变化时用户隐私不受攻击者所知的背景知识的影响.之后Dwork 对原有差分隐私的概念进行改进,提出本地化差分隐私[20],将信息的隐私处理工作转移到用户端,对差分隐私进行量化,每个用户单独对敏感数据进行处理,使得隐私保护更为彻底.Chen 等人[21]将本地差分隐私应用于位置数据保护,通过对位置数据加入拉普拉斯噪声,实现对位置数据的隐私保护.Wang 等人[22]提出了一种基于差分隐私以及Hilbert曲线的位置保护方法,将位置映射到一维空间中,通过拉普拉斯噪声对位置信息进行扰动,将处理后的位置信息发送给平台来实现位置信息保护.
2 问题定义
假设在该系统中有n个携带智能移动设备的工人W={w1,w2,…,wn},m个任务V={v1,v2,…,vm}.进而工人的智能移动设备可用Dev={Dev1,Dev2,…,Devn}表示,并定义第i个工人由表示,第j个任务由表示,其中(xi,yi)和(xj,yj)表示坐标,Pwi是第i个工人该时刻所有任务的开销集合,是该工人当前被分配到的任务队列,表示第j个任务所需时间,表示该任务的奖励,表示完成该任务平台可获取的收益.该系统是动态的,即工人与任务状态位置信息不断改变,在不同时刻下工人完成已有任务后会有“闲置状态”,此时需要在每次迭代时将“闲置”的工人重新放入在“待分配”工人的队列里,同时每个工人可接受的任务也是有限的,这需要根据工人的报酬以及任务对于工人的收益进行约束,例如距离较远的任务的开销大于收益则不会分配给工人,进而间接限制了工人所接受任务的数量,这就避免了任务分配不均的问题.
工人完成任务是有时效性的,因此在每个工人与任务里加入了时间戳,记录工人完成任务的时间,并标注出每个任务的完成时间限制.此外,考虑到工人开销的差异性,即任务对于每个工人的开销应该是不一样的,因而加入了笛卡儿坐标系,为每个工人和任务设置了位置坐标,每个工人依据距离和自己未完成的任务量计算任务开销.例如对于第i个工人,计算第m个任务开销时,距离越远,任务开销越大,自身未完成任务量(加权后的任务数量)越多,任务开销越大,反之亦然.这里,定义第i个工人对于第j个任务的开销为:
其中θi表示该工人的完成任务所需总时间,ξ表示第i个工人到第j个任务点的欧氏距离权重,α为时间权重,这里体现出了每个工人的任务开销的差异性.
可定义第i个工人的收益以及平台总收益为
其中ri表示第i个工人的收益,Rp表示此时平台总收益,Vout表示此时所有被分配出去的任务集合.
最终,将这一个基于离散型数据集的动态策略优化问题定义为
其中式(5)代表最大化平台总收益同时也要最大化当前第i个工人的收益,λ1与λ2为两者的收益权重,在式(6)中的约束代表第i个工人完成第j个任务时的报酬要保证不小于最小值Pmin,且Pmin是一个大于0 的常量.
从式(3)(4)中可以看出平台总收益与工人的收益是负相关的,而在本文的问题中,更希望两者都能达到最大化,因此采用联合优化方式,通过调节权重值来平衡双方利益,实现双方的纳什均衡.
由上述的问题定义可证明MCS 的任务分配问题是一个NP-hard 问题.首先假设一个特殊情况,即只有一个工人,任务集合不变.然后,该工人有一个设定的最大旅行距离,且支付给工人的报酬设置为0.最后,平台的总利润等于该工人完成任务的报酬,这也映射到定向运动问题,且该问题已被证明为NP-hard问题[23],则可推论本文的问题同样是NP-hard 问题.
3 系统模型及算法
3.1 系统模型概述
本文的系统模型如图2 所示,任务发布者在模型中作为中央服务器,每个工人的智能移动设备可看作分布式的小型处理器.在整个系统中,中央服务器与各个工人的移动设备在隐私保护的环境中进行信息交互.首先,每个工人智能移动设备将相关信息经过差分隐私的处理后传至中央服务器.之后,中央服务器获取该时刻全局的工人与任务的状态信息,经过基于DRL 的动态策略优化算法,制定相应的分配策略,最终传给各工人智能移动设备.同时在交互过程中,中央服务器中采用PPO 的算法进行训练并决策,在每轮训练时考虑了系统的动态性与差异性问题,即不同工人对于相同的任务会受到距离以及未完成的任务量影响,进而每个任务对不同工人的开销应是不一样的,且在每轮迭代时可能会产生完成了当前任务的“空闲”工人,在模型定义中考虑了以上问题,在每轮迭代会动态更新全局信息,最终得到全局最优的策略.
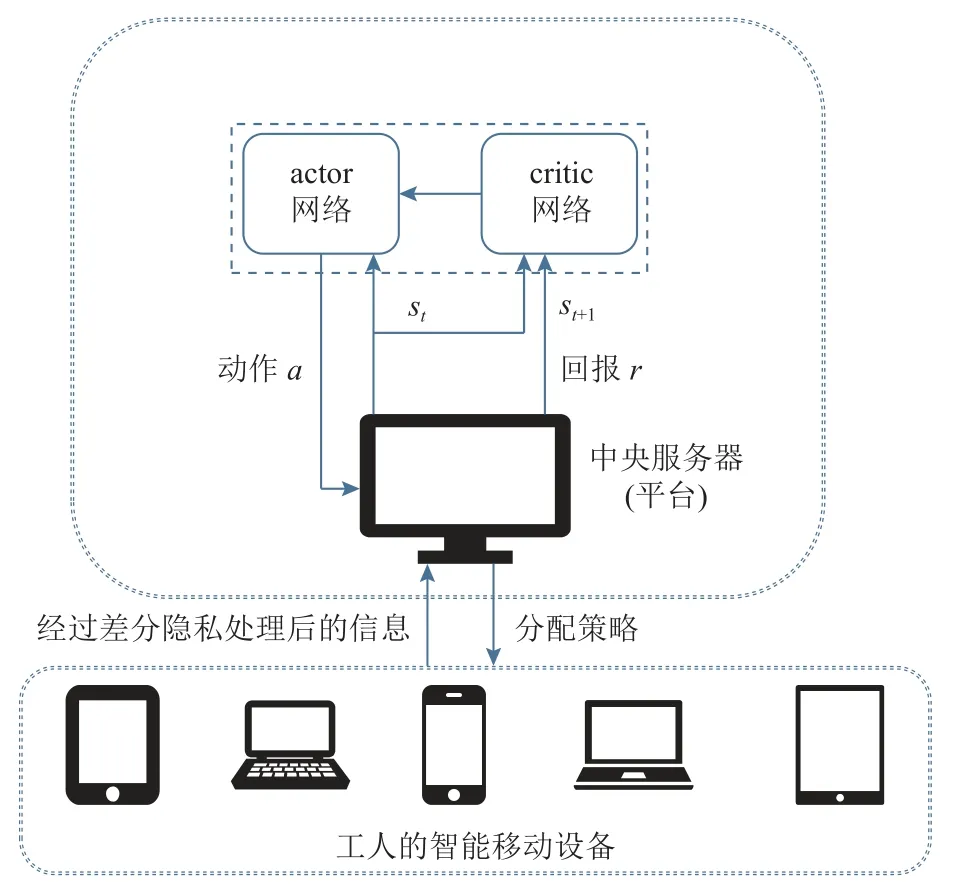
Fig.2 Illustration of the system model图2 系统模型图示
3.2 PPO 模型
中央服务器中应用了基于DRL 的动态策略优化算法PPO 进行决策推演.传统的PPO 算法源于A-C网络[24]的思想,如图3 所示,该算法由actor 网络和critic 网络构成,每一次迭代时,actor 网络会根据一定的动作决策概率分布进行动作选择,并与环境进行交互,获得该时刻的状态和相应的回报,此时critic 网络将根据动作、状态和回报的集合计算相应的收益函数(有时是TD-error,用于评价actor 网络的动作),并传给actor 网络和环境,actor 网络基于此调整动作的决策概率分布,并进行下一步动作选择,最终获得最优策略.
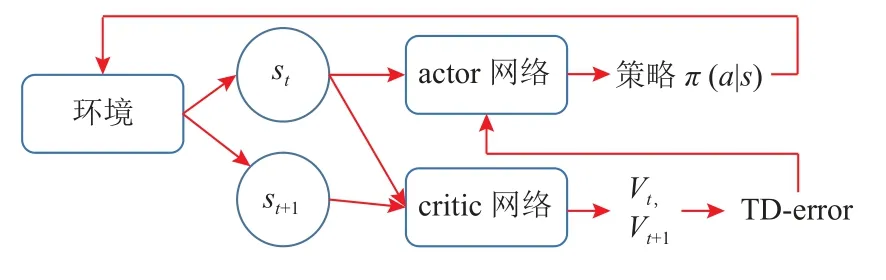
Fig.3 Block diagram of A-C network图3 A-C 网络的框架图
在本文的算法中,将传统PPO 框架做了调整,即在收益函数的定义上采用了双约束.动作空间、状态空间以及回报约束定义为:
1)动作空间.动作集中包含了工人与任务的匹配信息,并采用2 维向量表来表示,其中定义第i个工人在第k次迭代时被分配的任务集合为同时,每个工人设备中将存储任务分配记录以及任务完成顺序.每次迭代时由中央服务器决策进行分配,中央服务器依据上一轮交互所得到的全局信息(工人和任务数量、工人报酬、任务收益等),计算平台总收益,并进行匹配.其定义为
2)状态空间.状态集合中,记录了工人与任务的相关信息(工人的任务时序、各任务的收益、雇佣工人的开销、可用工人数量和剩余任务数量等),这里由第k个状态可用工人集合Wk与可用任务集合Vk来表示.每次迭代开始,每个工人根据中央服务器传递的数据,计算各个任务对于自己的开销与收益,并于中央服务器进行交互,更新此时的本地信息以及中央服务器的全局信息.综上所述,将状态集合定义为
3)回报约束.参照式(5)的联合约束,力求保证平台收益最大化的同时,尽可能增加工人的累积收益.将该问题视为平台与工人间非合作性竞争的纳什均衡问题.将平台总收益的计算定义为平台整体收益减去所有工人开销,而单个工人的收益定义为工人获得报酬减去完成任务的开销.回报约束中的平台总收益的优先级高于单个工人优先级,此处根据收益权重进行调整.这里回报约束定义为
其中Wout为已分配任务的工人集合,Wk为未分配的任务集合.
在PPO 模型的训练过程中,critic 网络根据回报rk以及动作/状态集合{a,s}计算其Value值以及优势函数Ak,进而对于下一次actor 网络中动作选择的策略π进行调整,相关定义为:
其中第k轮迭代时的价值函数为Valueπ(sk),γ为折扣率,为状态转换概率,Ak为此时的优势函数,λ为优势函数权重,最终损失函数可用Loss表示.
3.3 本地差分隐私
这里引入地理不可区分性的概念,即存在2 个位置点x和x′∈X,Z是X通过映射机制D的输出结果,若D满足地理不可区分性,则对所有欧几里得距离d(x,x′) ≤r,其中r为该映射机制保护的范围,报告位置点z∈Z,则有
式(14)(15)输入为x和x′ 时,根据该映射机制D的查询函数D(x)(z),将得到相同输出z的概率.位置信息中应用差分隐私是为了使真实位置点信息与其近似位置点信息拥有地理不可区分性,从而达到隐私保护的目的.
本文采用本地差分隐私的算法.首先,工人的移动设备定位当前位置信息(xreal,yreal).其次,根据当前位置坐标划定模糊位置范围,该范围是一个以R为模糊半径的圆形区域.在该范围内指定ε∈R2,根据机制D确定候选的位置坐标集合,并根据拉普拉斯机制随机噪声,敏感度设为Δf,该噪声服从(0,Δf/ε)的拉普拉斯分布.最后在候选坐标集合中随机选取模糊化后的位置坐标(x,y),并作为位置信息上传至平台.
3.4 基于PPO 的任务分配算法
基于A-C 网络的思想,利用PPO 模型训练并学习任务分配策略,该方法与本文的问题非常匹配,并已成功地应用于许多其他领域.在DRL 的众多策略优化方法中,PPO 在易于实现样本复杂性和易于调优之间取得了平衡,以最小化目标函数进行计算和更新,同时确保与以前策略的偏差相对较小.因此,在本文算法中的策略优化过程采用了PPO 算法.
在本文的模型里包括了一个历史策略缓冲区Cache、策略π、actor 网络与critic 网络,在算法1 中展示了该模型算法的伪代码.首先,初始化PPO 框架,随机赋予actor 网络与critic 网络的相关参数相应的初始值θa和θv,将θa作为初始的策略参数(行①).随后迭代开始,最大迭代次数为K(行②).在环境中获取当前的可用工人集合Wk以及可用任务集合Vk的信息,其中工人的位置信息根据本地差分隐私已做模糊化处理,最终得到第k次迭代的状态(行③~⑧).然后,基于状态sk根据当前策略在actor 网络中进行动作选择(行⑨),将此时的动作集合ak输入到环境中计算相应的回报rk以及下一轮的状态集合sk+1(行⑩).critic 网络中计算Ak以及Valuek,并将集合{sk+1,sk,ak,rk,Ak,Valuek}存储到历史策略缓冲区Cache中(行⑪~⑫).当Cache装满时计算偏导数,并基于根据梯度上升策略更新策略参数θa(行⑬~⑮).在从Cache中学习信息后,actor 网络的新参数θa分配给策略进行下一次采样.同时,历史策略缓冲区被清空(行⑯).
算法1.基于PPO 的动态策略优化算法.
4 实验
4.1 实验参数设置
本文选用Gowalla 和TaskMe 这2 个数据集进行模拟实验,从中提取部分数据的位置以及时间信息,并将添加在一定范围内随机生成的数据作为任务奖励等其他信息,最终生成拥有2 000 个任务和1 000个工人的模拟数据集合.其中,每个任务的奖励设置在8~20 的范围内并按照N~(12,4)的正态分布进行随机生成,任务的时间则设置在10~60 的范围内随机生成.最后,根据实验的不同要求,选用该数据集中部分任务以及工人的数据信息在一个200×200 的正方形传感区域空间内进行模拟实验.
首先,设置了不同的工人与任务数量下损失函数的对比实验,目的是验证工人与任务数量对损失函数的收敛性的影响.在一个200×200 的正方形传感区域空间内,分别测试了80 个任务和5 个工人、300个任务和15 个工人、800 个任务和30 个工人这3 种不同情境下的损失函数.其次,与现有的传统方法(贪婪算法、蚂蚁算法)以及其他DRL 方法(DDQN)针对收敛速度、最大收益以及任务覆盖率的对比实验.该部分将蚂蚁算法中蚂蚁数、迭代次数和随机选择的概率分别设置为10,30 000,0.1,对于基于DDQN的算法将其重播内存容量设为10 000 次,迭代次数设为30 000 次,随机选择的概率从0.9 开始,然后逐渐衰减到0.1.最后,通过消融实验来验证隐私保护的有效性.在该实验中将本文算法与DDQN 的算法以及去除掉差分隐私时的算法进行比较,实验设置参数与对比实验相同.
4.2 模型损失
本节进行了不同工人数量以及任务数量的模拟实验,图4(a)中迭代次数在100 次以内,大约在第70次时达到收敛;图4(b)中模型在迭代次数约120 次时达到收敛;图4(c)中在迭代280 次时达到收敛.可以看出,该算法收敛效果主要受到工人与任务的数量影响,随着其数量的增多,收敛速度将变慢.
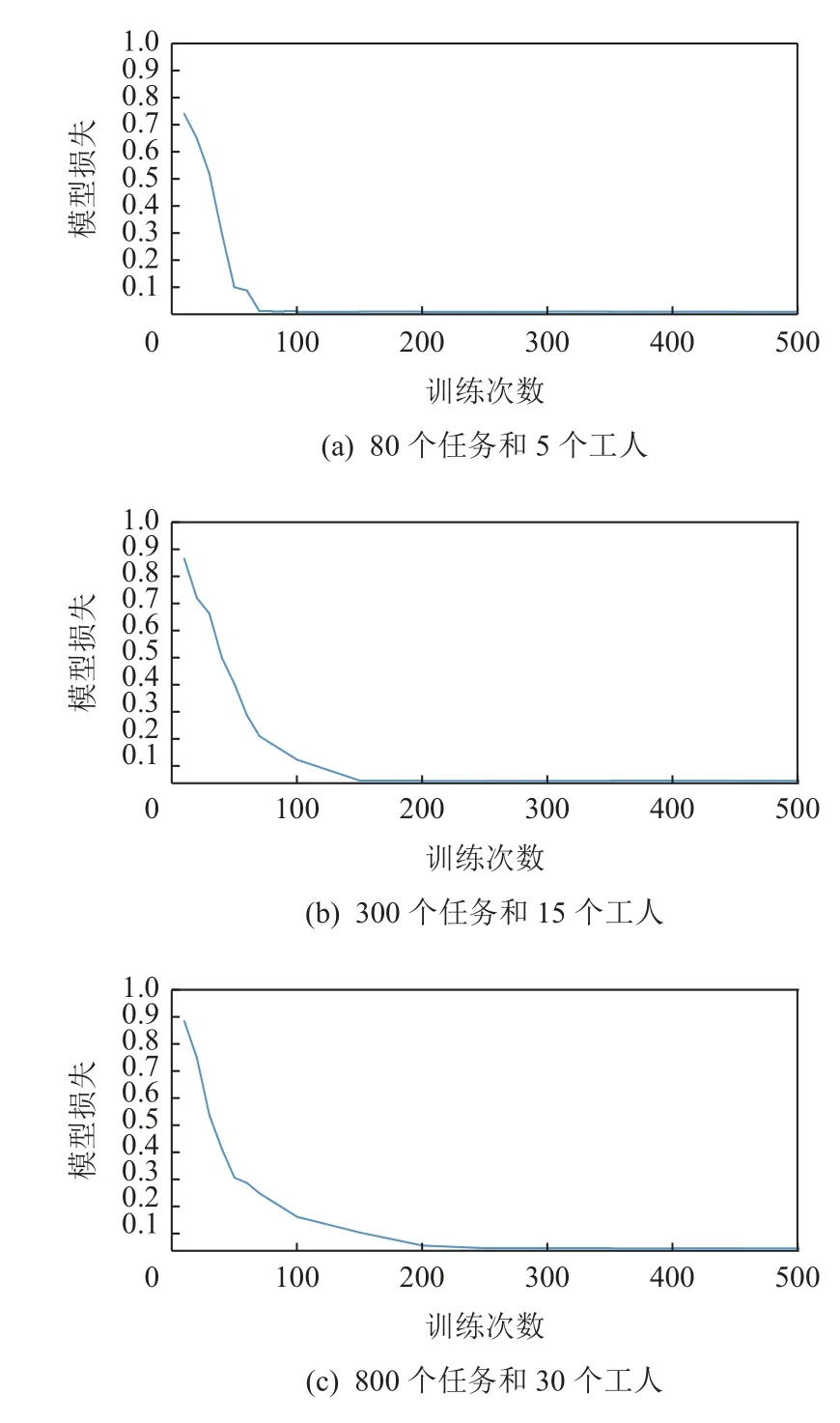
Fig.4 System loss for different numbers of tasks and workers图4 任务与工人不同数量下的系统损失
4.3 对比实验
本节实验不仅针对传统MCS 任务分配方法(即蚂蚁算法和贪婪算法的对比),而且加入了同为基于DRL 的任务分配算法(即基于DDQN 的算法),在任务覆盖率、性能、收敛性以及最大收益上做了相应对比实验.在图5 中,可以看到基于DDQN 以及基于PPO 的2 种DRL 算法在系统平均开销的收敛情况,结果表示基于DDQN 的算法虽然可以比本文算法能更快收敛,但本文算法可以达到更小的平均系统开销.图6 展示了4 种算法的平台收益情况,贪婪算法和蚁群算法由于是静态的算法,因而不需要多轮迭代,但其平台收益与基于DRL 的算法相比差距甚远;而基于DDQN 的算法同样有更快的收敛性,但本文的基于PPO 的算法可以最终达到最大收益.
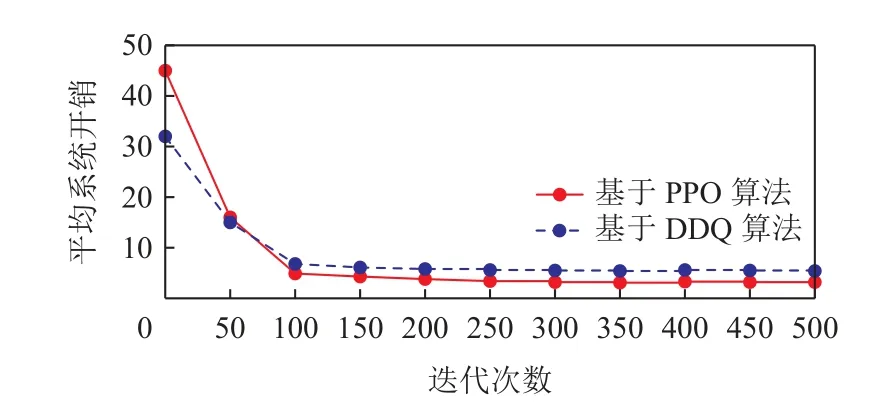
Fig.5 Comparison of average system costs图5 平均系统开销的比较
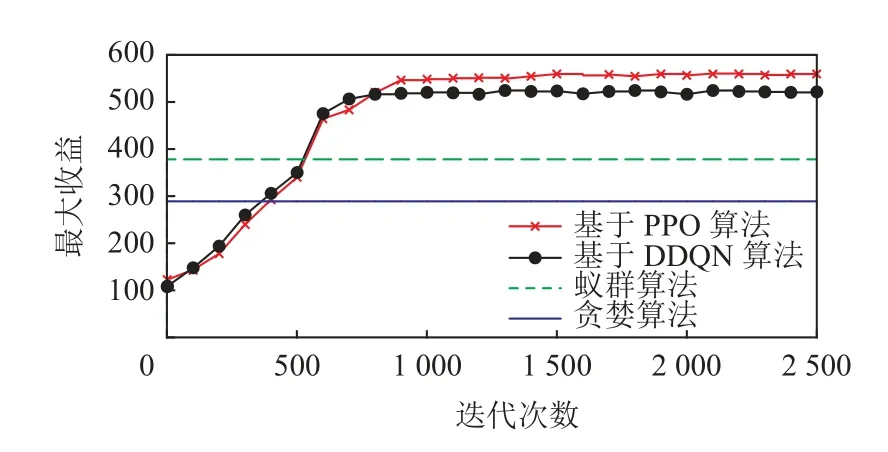
Fig.6 Comparison of maximum profits图6 最大收益的比较
首先引入任务覆盖率的概念:当一个任务在其可接受的时间范围内被分配出去且完成,则可称为该任务被覆盖.因此任务覆盖率可被定义为被分配掉的任务数与总任务数的比值.如表1 所示,在平台最大利润和任务覆盖率上,基于DDQN 和PPO 的2种DRL 算法均远高于贪婪算法和蚁群算法等传统方法,且基于PPO 算法比基于DDQN 的算法表现更为优异.图7~9 展示了4 种算法在平均开销、总开销以及工人平均收益上的对比,结果表明本文的基于PPO 算法均优于其他算法,而贪婪算法表现最差.

Table 1 Comparison of Maximum Profit and Coverage Ratio表1 最大利润与覆盖率的对比
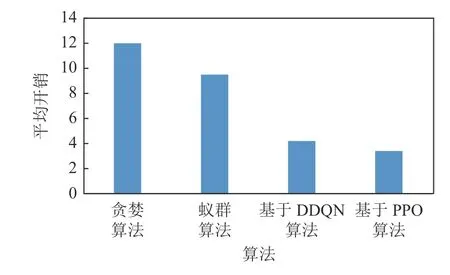
Fig.7 Comparison of average costs图7 平均开销的对比
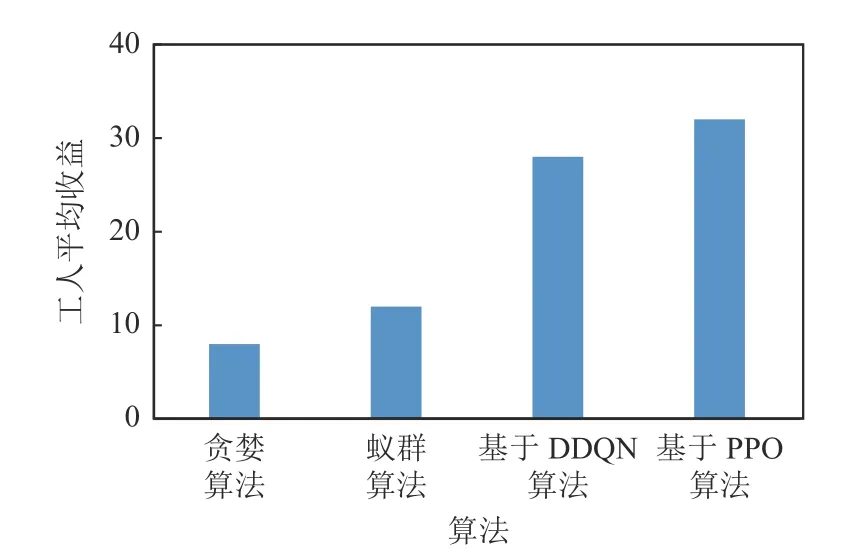
Fig.9 Comparison of average revenue of workers图9 工人平均收益的对比
4.4 消融实验
如图10 所示,本文针对差分隐私的有效性做了消融实验,实验中对比了有差分隐私的性能以及没有差分隐私的性能,并与基于DDQN 的算法模型进行对比.实验结果表明,去除差分隐私性能会有更好的效果,是因为模糊化的位置信息影响了模型的计算性能,但加入差分隐私的方法可以在不损失过多性能的前提下保护工人信息的隐私.此外,为了验证该算法的性能随差分隐私保护程度的变化,消融实验中加入了不同的隐私保护机制覆盖范围下的算法性能的对比实验,如图11 所示,其中r表示本文3.3节所提到的差分隐私机制的保护范围,当保护范围越大时,则需保证该范围的地理不可区分性,故保护程度越高.由此可见,随着保护范围的增加算法性能所受影响较大,需选择合适的保护强度,实现在保护隐私的前提下保证算法性能.
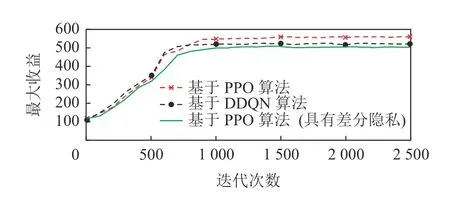
Fig.10 Ablation experiment图10 消融实验
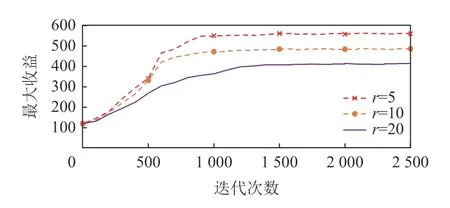
Fig.11 Comparison under different protection levels图11 不同保护程度下的对比
5 结论与展望
在本文中,针对MCS 的感知任务分配问题,在工人与任务的位置、状态信息不断改变的动态系统中,考虑了任务分配机制的合理性与工人信息的隐私保护等问题,将其定义为一个基于离散型数据集来进行动态规划的优化问题,并利用差分隐私和深度强化学习的相关算法及模型去解决该问题.将PPO 模型作为决策模型训练和学习,在每次迭代中,考虑当前状态下的每个工人开销的差异性以及完成任务的时序性等因素,利用联合约束,在保证平台收益最大化的同时,尽可能增加工人的累积收益,在这样的动态系统中不断优化分配策略.此外,还在工人的移动设备与中央服务器的交互中加入了差分隐私的方法来保证工人的隐私.实验结果也证明了本文方法的有效性.
在未来的工作中,将探索更多隐私保护的策略,并且在保证隐私的同时进一步提升模型的性能.此外,也考虑在该模型中加入数据预测的机制,在收集处理感知数据的同时,基于历史经验数据进行某一范围内的数据预测,提升模型整体效率.
作者贡献声明:杨明川负责实验及相关研究工作,并完成论文撰写;朱敬华提出算法思路,设计论文整体框架;李元婧负责数据分析并协助撰写论文;奚赫然提出修改意见并修改论文.
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28
今日农业(2020年20期)2020-12-15
海峡姐妹(2017年6期)2017-06-24
工会信息(2016年4期)2016-04-16
金色年华(2016年1期)2016-02-28
读写算(下)(2015年11期)2015-11-07
中国火炬(2015年11期)2015-07-31
信息安全研究(2015年3期)2015-02-28
中国火炬(2014年3期)2014-07-24
太空探索(2014年1期)2014-07-10
