
基于强化学习的个性化学习路径推荐算法研究
2023-12-14 14:20陈耀东
科技风 2023年34期
陈耀东
长沙师范学院 湖南长沙 410100;湖南省教育科学研究院 湖南长沙 410100
“构建网络化、数字化、个性化、终身化的教育体系”是实现建设学习型社会的重要条件。在移动互联网、大数据、人工智能、云计算等众多新技术的支持下,教育模式、教学方法、学习方式等均在发生深刻变革,促使我国教育向着智慧化、智能化的方向迈进,其中“关注学习者的个体差异”“为每个学习者提供适合的教育”这些理念在社会上逐渐共识,个性化教育与个性化学习成为解决我国当前社会教育供需矛盾的主要途径。以自媒体为代表的新媒体环境下,学习资源极大丰富,如何利用智能技术为学习者提供定制化的学习路径是当前个性化学习研究领域的一个热点。个性化学习路径推荐问题可以定义为,基于学习者学习能力、知识背景、学习兴趣、达成目标等方面的差异,通过智能技术为学习者定制一条符合教育规律且能达到学标的学习路径,同时实现学习者学习状态检测[1]。
一、概述
学习路径推荐的主要研究范畴有三个方面。一是学习者建模,涉及学习者能力水平、心理状态、风格兴趣[4]等的特征化问题和提取方法;二是学习对象建模,涉及发掘学习推荐对象与学习者个性化参数的关联信息;三是推荐算法设计,涉及学习者与对象之间策略选择与最优匹配问题。根据相关研究[2-3],个性化学习路径推荐问题的数学描述形式如下。给定学习目标g,学习目标相关的知识点kp,学习资源r=(kp1,kp2,…,tp,s),s.t.kpi+1=f(kpi),r是由知识点kp组成的有序向量,这里tp∈{文本,图片,视频}代表r的类型,s∈{课程,章节,知识单元,知识点}代表与目标g的层次相关的r的粒度,f(·)是一个转换函数,表示知识点kpi为kpi+1的先修学习资源。一般采用向量e描述每个学习者的先验特征,特征向量一般作为各类推荐算法的初始输入值。学习路径表示为pn,且有pnt={et,rt},其中e和r分别表示t时间对应的学习者状态特征和学习资源集合。因此,学习路径Lp是一条由pn结点组成的、以g为目标的、与指定学习者相关的有序序列,Lp={pn0,pn1,…pnt,…,pnm|pnt=f(pnt+1),g=f(Lp)}。
个性化学习的主流学习框架包括基于机器学习的,基于进化计算的,基于知识图谱的三种。机器学习框架将路径推荐转换为预测问题,分为监督和无监督两种。进化计算一般采用遗传算法、蚁群算法等解决路径搜索问题,目前群体计算和群体智能是其重点研究方向[5]。知识图谱是基于知识工程和本体论方法,在构建领域图谱的基础上运用带约束条件的路径搜索方法找出最佳推荐路径。随着AlphaGo在2016年战胜围棋世界冠军,强化学习成为当前机器学习的一个研究热点并逐渐演化成一个热门分支,其后的升级版本AlphaGo zero,基于深度强化学习框架,在世界围棋大赛和游戏竞技大赛中继续完胜人类选手。强化学习特别适于解决序列决策优化问题,在个性化学习路径推荐方面能取得较好效果[6-7]。
二、模型描述
强化学习是将学习者作为智能体,通过不断“试错”引导其自主化学习。经典的学习模型基于马尔可夫决策过程,学习者不断学习新的知识点,然后利用获得的奖赏来指导学习行为是否适合,从而最大化累计奖赏以实现特定目标。这一过程可用5元组(S,A,P,R,γ)进行简单描述,其中S为有限的状态集,A为有限的动作集,P为状态转移概率,R为回报函数,γ为用来计算累计回报的折扣因子。策略π是状态S到动作A的映射,策略π为每个状态s指定一个动作概率π(a|s)=p(At=a|St=s)。强化学习的目标就是为学习者发现一个最优策略π*,使得学习者获得的期望折扣奖励之和最大化,也即:
Vπ(s)=∑aπ(s,a)[R(s,a)+γ∑s′Pr(s′|s,a)Vπ(s′)]
(1)
公式1当中R(s,a)+γ∑s′Pr(s′|s,a)Vπ(s′)代表在当前s状态下提供每一个可能决策的累计未来奖励。学习者在当前状态下通过“试错”的方式选择动作,按照这种状态→动作→回报的顺序循环,最后达到学习者指定目标收益最大化。
用户反馈。对于一个学习者,假定某个时刻t模型根据前序状态选取当前转换的状态为s,用户可对此状态给予一个正面和负面的标签l+,l-,则对于所有状态序列S,有:
(2)
进一步对公式1和公式2进行整合,形成基于用户反馈的参数化策略最优框架:
Gη(C,V)=η·T(θ,V)-(1-η)·L(θ,C)
(3)
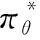
(4)
其中Rl表示学习者l计算到的某次学习路径。
(5)
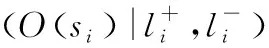
三、实验分析
(一)数据来源
本文面向计算机专业课程学生学习的过程数据和考核数据进行测试。《移动应用开发》面向计算机和物联网工程本科学生讲授基于Android的程序开发,课程已在2014年开始在超星数据平台(www.chaoxing.com)开设线上教学,至今近10年,形成了内容丰富、形式多样、组织科学的教学资源库(参见表1),累积了近1000名学生线上线下学生情况。由于本专业的学生来源有第一志愿高考录用、其他非工科专业调剂,专升本等情况,因此学生的学习能力与兴趣差异较大。为此,本课程很早开展了人才培养方案的改革创新,将培养目标设定为中阶和高阶两个设定为多目标要求,中阶目标的核心要求是能够自主设计移动APP的界面并实现交互,高阶目标则要求能面向特定场景需要独立设计和开发具有完整功能的移动APP。课程PPT、视频、试题集等均按此分成两类,即每一类具有闭环的知识学习与能力评估体系。

表1 实验所用数据来源
为确保有效性,本实验从线上空间筛选抽取活跃度强、互动性高的学生,根据中阶和高阶不同目标等级分别设置两组学生集。目标测试数来源于期末试卷库,每套试卷对应1个目标测试数。课程自主录制教学短视频集,其中中阶的74个涵盖87个知识点,高阶的132个涵盖144个知识点,为辅助学生更好地理解知识点,从互联网收集知识点相关的学习资料,其中中阶32个,高阶51个,每个学习资料对应一个PDF文档。每位学生在测试过程中对选取的知识点进行正反评价,因此反馈标签数=学生数×知识点×2。
(二)实验测试集
考虑学生在知识学习与测试考核的不可重复性,实际测试的每个数据集进一步分离成测试数据集。以表1当中的中阶1为例,145名学生经自愿后随机分成三个类,分别包含25名、60名、60名学生,同时衍生出M-1-Normal、M-1-NoTagged、M-1-Tagged共3个测试集,M-1-Normal表示对第一类25名学生按教师预设的学习路径进行学习,即未采用强化学习进行个性化学习路径推荐;M-1-NoTagged表示对第二类60名学生,采用本文强化学习框架在不整合反馈标签条件下进行路径选择计算;M-1-Tagged表示对第三类60名学生,采用本文强化学习框架在不整合反馈标签条件下进行路径选择计算。按同样的方式,实验对其他5个数据集进行分类测试。实验分别以学生平时作业和期末考核的分数作为评价标准。
(三)结果与分析
表2展示了4×3共12个测试集的结果。

表2 中阶目标测试结果
(四)结果分析
表2的测试结果说明,强化学习能明显增强学习路径推荐的有效性,通过强化学习后,学习者的平均成绩和期末考核均有显著提升,在整合反馈标签后,学习路径推荐的效果进一步得到提升,测试集1分别提升平时成绩分别提升3.3分和5.9分,期末考核分别提升4.2分和4.7分。测试集2在三个算法上的表现与测试集1类似。表3展示了高阶目标测试结果情况。表3当中的3个算法的结果与表2类似,同时注意到,表3中基于反馈的强化学习路径推荐算法的效果约为8~9分,高于测试集1的提升效果6分和3.5分,效果相差很大,这说明强化学习在高阶目标环境下效果更强,分析认为,高阶目标具有更多的知识点和补充学习资料,同样的,基于标签反馈的算法给出大量学习者评价标签,用于指导策略函数找到折扣奖励最大的路径,由此证明了本算法的有效性。

表3 高阶目标测试结果
结语
强化学习模仿智能体反复“试错”的学习方式达到自主学习目的,特别适于解决序列优化问题,本文基于强化学习框架提出了一种基于标签反馈的策略优化算法,在策略寻优过程中加入学习者对当前状态转换的标签评价,指导和提高强化学习参数优化性能。实验采集计算机专业课程线上教学与考核数据,对比非强化学习、强化学习和本文提出的算法,实验结果证明了本文算法的有效性,下一步将标签反馈运用到其他强化学习优化策略。
猜你喜欢
数学物理学报(2021年1期)2021-03-29
数学物理学报(2020年6期)2021-01-14
哈尔滨轴承(2020年1期)2020-11-03
文苑(2020年4期)2020-05-30
数学物理学报(2018年5期)2018-11-16
新闻传播(2018年12期)2018-09-19
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
汽车与新动力(2016年6期)2017-01-04
公民与法治(2016年10期)2016-05-17
