
引入通道注意力机制的目标检测算法
2023-12-25 03:25许维义
电脑知识与技术 2023年31期
关键词:目标检测
许维义



摘要:针对目标检测模型在提高检测精度的同时会带来更高模型复杂度这一不足,该文提出了一种改进的YOLOv4模型。该模型将通道注意力机制ECA模块加入特征提取网络之中,构建了一个新的YOLOv4模型。通过在PASCAL VOC数据集上的实验表明:该算法在不增加模型大小的前提下提高了检测精度,相比YOLOv4算法在PASCAL VOC 2007测试集上的平均精确度均值@0.5提升了最高3.56mAP,达到了最高83.42mAP,能够解决目标检测性能和模型复杂度之间的矛盾,并提高了检测精度。
关键词:目标检测;YOLOv4算法;通道注意力机制;解耦头
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)31-0048-03
开放科学(资源服务)标识码(OSID)
目标检测作为计算机视觉领域的重要分支,在实时监控、信息检索、交通物流等领域都发挥着重要的作用,一直受到众多学者的关注和研究。目标检测任务作为图像处理领域的经典任务之一,由目标定位和目标分类两部分组成。其中目标定位任务主要输出目标在图片上的位置,输出的数据形式一般为目标中心及目标区域的长宽或目标在图片上的四个端点的坐标信息;而目标分类负责判断图片中是否有需要检测的目标出现,其输出数据的形式包括类别的编码以及目标属于该类别的概率。目标检测任务的应用范围非常广泛,如人脸检测、智能交通、安全系统检测和医疗方面检测。
从像素级分析的传统目标检测时代到特征级分析的深度学习型目标检测时代,目标检测技术在无数研究人员的努力下得到了长足发展,并逐渐走向成熟。但由于应用领域的不同、应用场景的不同、目标大小和目标类别的不同、任务类型的不同和样本数目的不同,目标检测仍然面对着提高应用灵活性和任务适应性等挑战。
如Girshick R等人[1]将区域提议与CNN相结合,提出的R-CNN揭示了丰富的图像特征层次结构,提高了检测的精度。Girshick R等人[2]提出的Fast R-CNN是在R-CNN的基础上引入SPPnets,在对整个图像进行归一化后,候选区域的特征不再是在卷积层中进行提取,而是通过在尾部的池化层中加入需要检测区域的坐标位置来提取所需要的特征。Liu W等人[3]介绍了SSD,SSD的创新是对目标的检测加入了多尺度特征图,能够提高检测的精确度。Ren S等人[4]通过让RPN和Fast R-CNN共同使用卷积特征来整合成一个网络,能够有效地提高检测速度和综合性能。Rashwan A等人[5]介绍了矩阵网(xNet) ,一个尺度和纵横比感知架构的目标检测,能够增强基于关键点的对象检测,且使用一半参数的同时降低训练时间到原来的1/3。针对上述问题,本文提出了一种改进的YOLOv4模型[6],能够在不增加模型大小的前提下,提高模型的检测精度。该算法将有效通道注意力模块ECA引入特征提取网络中,通过分析插入位置的不同而导致的模型性能的差异来选取最优插入区域,并对YOLOv4原模型的SPP[7]进行不同尺度的对比优化。为解决YOLOv4检测头部耦合问题,使用解耦检测头代替了原本的耦合检测头,进而提升检测的效果。
1 背景知识
1.1 YOLOv4模型
YOLO[8-10]作为一系列的目标检测模型,已广泛应用于各个行业,如交通违章检测、行人检测、商品检测等领域。其中,YOLOv4作为一种单阶段目标检测算法,首先是通过骨干网络进行目标的关键信息提取,再经过颈部网络对骨干网络提取的信息进行融合,最后使用检测头部对融合的信息进行分类和回归。YOLOv4借鉴CSPNet结构并融入Darknet53中,使骨干网络性能得到大幅提升。颈部网络也称加强特征提取网络,YOLOv4采用了SPP模块和PANet网络作为颈部网络,增强了对特征图的提取能力。YOLOv4的头部结构与YOLOv3相同,依旧采用三尺度输出,用于对不同尺寸大小的目标进行检测。
自2018年YOLOv3年提出的两年后,在Redmon声明放弃更新YOLO算法后,Alexey等人扛起了YOLO系列更新的大旗,在2020年4月提出了YOLOv4版本。YOLOv4在YOLOv3的模型基础上使用了空间金字塔池化和路径聚合网络组合的特征融合方式,并将原骨干网络Darknet53换成了CSPDarknet53,CSPDarknet53是在Darknet53的基础上加了CSPNet。CSPNet的特点是充分利用跨层信息,使用CSPaNet結构将输入特征图分成两个部分,然后通过跨层连接来结合这两部分的信息,这样可以在减少计算复杂度的同时提高网络的感受野和特征表达能力。
2020年11月,CSPNet的作者Chien-Yao Wang与Alexey等人在YOLO系列继续扩展,从影响模型扩展的几个不同因素出发,基于CSP方法的YOLOv4对象检测神经网络,可向上和向下扩展,适用于小型和大型网络,同时保持最佳速度和精度。Scaled-YOLOv4是一种Network Scaling网络扩展方法,它不仅针对深度、宽度、分辨率进行调整,同时可以调整网络结果,并提出了两种分别适合于高端GPU的YOLOv4-large和低端GPU的YOLOv4-tiny。
YOLOv4-large是为云GPU设计的,主要目的是实现高精度的目标检测,是一种完全csp化的模型YOLOv4-P5,并将其扩展到YOLOv4-P6和YOLOv4-P7。
1.2 注意力机制
通道注意力机制是指在多个通道中,通过调节每个通道的权重来实现注意力分配。例如,在图像识别任务中,每个通道对应的是不同的颜色、纹理、形状等特征,通过调节每个通道的权重,可以更好地捕捉重要的特征,从而提高识别准确率,因此对提高目标检测网络模型的性能方面有着重要的作用。但是,现在大多数方法为了提高模型的检测性能,往往采用十分复杂的注意力模块,这使得模型的复杂性大大增加,而本文使用的有效通道注意力模块ECA在提升模型检测精度的同时并没有增加模型的大小。
挤压和激发模块验证了通过建模可以重新预测各个通道,使获取的通道信息更加关键,但是遗漏了位置的信息。卷积注意模块虽然添加了空间注意力模块,但是通過卷积来获取位置信息,而卷积只能捕获局部位置关系,不能够对长范围关系进行卷积。协调注意力模块捕获了跨通道的方向感知和位置感知的信息,可以让模型对目标区域的定位更加精准,但使用的参数太多。
本文使用的有效通道注意力模块与提高检测精度的同时会带来更高模型复杂度的模块不同,ECA模块在提高检测精度的同时参数量并没有太大变化。ECA模块通过避免渠道维度缩减,同时以极其轻量级的方式捕捉跨渠道互动,用来学习有效的渠道注意力,可以使模型对通道内信息的提取更敏感、更关键。
2 改进的YOLOv4算法
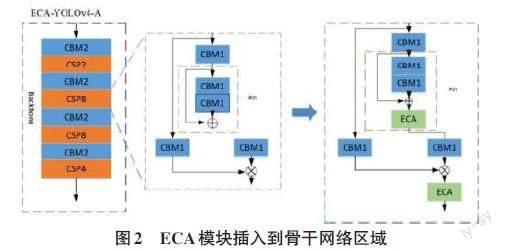
作为一种即插即用的注意力模块,ECA可以添加到YOLOv4网络中的任何地方,但不同的插入位置也会导致模型预测性能的差异。本文对在YOLOv4网络模型中的不同位置插入ECA模块所带来的差异进行研究。根据 YOLOv4 网络模型的结构,可分别在 YOLOv4的Backbone骨干网络、Neck颈部和Head检测头部3个部分插入ECA注意力模块。由于ECA模块是加强对不同通道中的特征信息提取,所以可以在上述3部分中的每个特征融合区域中插入ECA模块,ECA模块的具体插入位置如图2所示。
根据YOLOv4 网络模型的结构,可在YOLOv4的Backbone骨干网络部分插入ECA注意力模块。由于ECA模块是加强对不同通道中的特征信息提取,所以可以在特征融合区域中插入ECA模块。
3 实验与结果分析
3.1 数据集和训练参数
本实验采用VOC2007+2012公共数据集,该数据集的主要层级结构为4个大类,共包含20个小类,共有27088张图片。训练集、验证集和测试集的比例为7∶2∶1。其中,训练集图片有18 962张,验证集有5 418张,测试集有2 708张。训练过程的初始学习率为0.001,每25次迭代后学习率下降到原来的0.1倍,动量为0.9,衰减系数为0.000 5,Batchsize设为4,设置训练的Epochs为180次。
实验将VOC2007数据集中的图像标签修改为YOLO模型所需的pascalvoc标签,训练集是voc07train+val和 VOC12的train+val,验证集/测试集是voc2007test。由于显存较低的原因,本实验将原图片608×608尺寸调整为416×416大小。
3.2 对比试验及结果分析
为了验证所提出的网络模型在检测精度上的有效性,从不同方面将笔者的方法与现有方法进行了对比和分析。
为了突出YOLOv4-ours模型在检测性能上的优势,本文选用三个注意力机制模块分别插入YOLOv4网络中,分别是SE模块、CBAM模块、CA模块,再加上原本的YOLOv4网络与改进后的YOLOv4-ours模型进行对比。ECA模块是在SE模块的基础上,把SE中使用全连接层FC学习通道注意信息,改为1×1卷积学习通道注意信息。与FC相比,1×1卷积只有较小的参数量,这样可以避免在学习通道注意力信息时通道维度减缩,且降低了参数量。而CBAM模块虽然也是轻量级的注意力模块,但它将通道与空间注意力机制进行结合,不可避免地增加了模型大小。与EC模块相比,CBAM在特征提取后加了一个并行的最大池化层,虽然提取到的高层特征更加丰富,但池化而导致信息的丢失也更多。并且在通道注意力机制之后,CBAM模块添加了一个多层感知机来提高识别率和分类速度,但训练速度较低,尤其是对于目标检测这类巨大量的训练集。
为了突出YOLOv4-ours模型在精度上的优势,本文使用YOLO-V3、improved-YOLO-V3、YOLOv4、Fast-R-CNN4种模型在PASCAL VOC 2007上对比我们的模型。笔者使用文中提出的性能评价指标来评估这些方法的性能。从结果可以看出,在阈值为0.5即mAP@0.5时,YOLOv4-ours在目标检测精度上相较YOLOv4算法表现更好,相较其他算法模型在PASCAL VOC 2007数据集上也表现出了最高的检测精度83.42%,证明了该网络模型具有较好的目标检测性能。
4 结论
针对目标检测模型在提高检测精度的同时会带来更高模型复杂度这一不足,本文提出了一种改进的YOLOv4模型,该算法将有效通道注意力模块ECA引入特征提取网络中,进而构建一个新的YOLOv4模型,在不增加模型大小的前提下,提高了模型的检测精度。根据实验表明,相比YOLOv4算法在PASCAL VOC 2007测试集上的mAP@0.5提升了最高3.56mAP,在PASCAL VOC 2007测试集上达到了最高83.42mAP@0.5,且较其他算法模型也表现出了最高的性能,证明了模型在解决目标检测性能和模型复杂度之间矛盾的优越性。
参考文献:
[1] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.ACM,2014:580-587.
[2] GIRSHICK R.Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV).Santiago,Chile.IEEE,2015:1440-1448.
[3] LIU W,ANGUELOV D,ERHAN D,et al.SSD:single shot MultiBox detector[J].Computer Vision – ECCV 2016,2016.
[4] REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[5] RASHWAN A,KALRA A,POUPART P.Matrix nets:a new deep architecture for object detection[C]//2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW).Seoul,Korea (South).IEEE,2019:2025-2028.
[6] BOCHKOVSKIY A,WANG C Y,LIAO H Y M.YOLOv4:optimal speed and accuracy of object detection[EB/OL].[2022-10-22].2020:arXiv:2004.10934.https://arxiv.org/abs/2004.10934.pdf.
[7] HE K M,ZHANG X Y,REN S Q,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].Computer Vision-ECCV 2014,2014.
[8] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas,NV,USA.IEEE,2016:779-788.
[9] REDMON J,FARHADI A.YOLO9000:better,faster,stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu,HI,USA.IEEE,2017:6517-6525.
[10] REDMON J,FARHADI A.YOLOv3:an incremental improvement[EB/OL].2018:arXiv:1804.02767.https://arxiv.org/abs/1804.02767.pdf.
【通聯编辑:代影】
猜你喜欢
科技创新与应用(2016年36期)2017-02-21
科学与财富(2016年28期)2016-10-14
哈尔滨理工大学学报(2015年5期)2016-01-19
湖南大学学报·自然科学版(2015年10期)2015-11-30
现代电子技术(2015年20期)2015-10-26
现代电子技术(2015年14期)2015-07-22
