
基于具身交互的听觉数字孪生及无人机作战应用
2024-01-04 04:31吴凤鹃郭子淳
兵器装备工程学报 2023年12期
靳 聪,吴凤鹃,李 波,郭子淳,王 晶
(1.中国传媒大学 信息与通信工程学院, 北京 100024; 2.西北工业大学 电子信息学院, 西安 710129; 3.北京化工大学 艺术与设计系, 北京 100029; 4.北京理工大学 信息与电子学院, 北京 100029)
0 引言
数字孪生是当前军事装备应用研究中的一项关键技术。通过建立设备运行数据库,掌握物理设备整个生命周期的所有数据和参数,提高设备配置的合理性。通过创建逼真的三维战场环境,数字孪生将支持战场态势感知和规划能力的战略转型等。
由于人类对环境中声音信息的接收不像对视觉信息的接收那样容易受到角度和方向的限制,通过声音可以获得的不可见的事件状态或实体行为信息,这无疑是对视觉信息的重要补充,尤其在战场上具有重要的意义。然而,在虚拟战场仿真中,听觉作为成员与环境之间的信息交互的重要来源却常常被忽视。成员、物理世界和虚拟环境(virtualenvironment,VE)之间的关系不仅应该激发自然的多模态界面的设计,而且应该被发现以使VR技术的中介作用更有意义。
从哲学角度,听觉数字孪生可以解释为将人或代理的空间位置赋予一种虚拟的数字化身,并以具身性的听觉感知完成映射。“具身性”这个理念最早来自于梅洛·庞蒂,其本意是关注身体如何影响人类的心智和行动,以及基于身体本质对其所处空间的探寻。它能有效地通过调节“外来感官刺激所产生的印象,而其方式是身体将它对当前位置或地点的感觉与它对过去某种东西的感觉相联系”[1]。
本文中设计了一个具有技术-数字性质的听觉元环境,它是监护者、仔细的观察者和每个行动者的对话和参与的生命线。从“以人为本”的角度来看,它围绕着听众形成,即对它有意义的真实世界。为什么是数字孪生?因为这个术语让人想起2个不同的和遥远的实体或人之间的深刻联系,通常以具身性为基础。这个框架从生态学的角度延伸到通过考虑VR内在的多感官性质,从生态学扩展到多感官领域。由于这些原因,本文中提出了一个音频优先的视角,采用了一种更易读的、不损失信息的合成表达,即听觉数字孪生。
一些面向军事模拟作战场景的虚拟仿真设计在虚拟现实方面倾向于视觉优先,将听觉信息限定为次要和辅助角色[2]。虽然声音是实现沉浸式效果的重要组成部分,但与视觉相比,针对听觉空间和环境的相关研究工作较少。如今,人们越来越多地开始关注空间听觉对于虚拟环境所起到的重要作用,也在VR模拟[3-5]中达成共识。空间音频渲染技术现在能够通过从现实生活中的录音[6]或历史档案中重建刺激来传达可信感知的模拟,如2019年火灾前后的巴黎圣母院[7],越来越接近于与自然现实无异的虚拟版本[8]。这是由高度个性化的用户形态建模和人体与室内声场产生的声学转换合成的,通过计算机结合房间声学模型,建立声场环境的数字孪生[9-10],如图1所示。
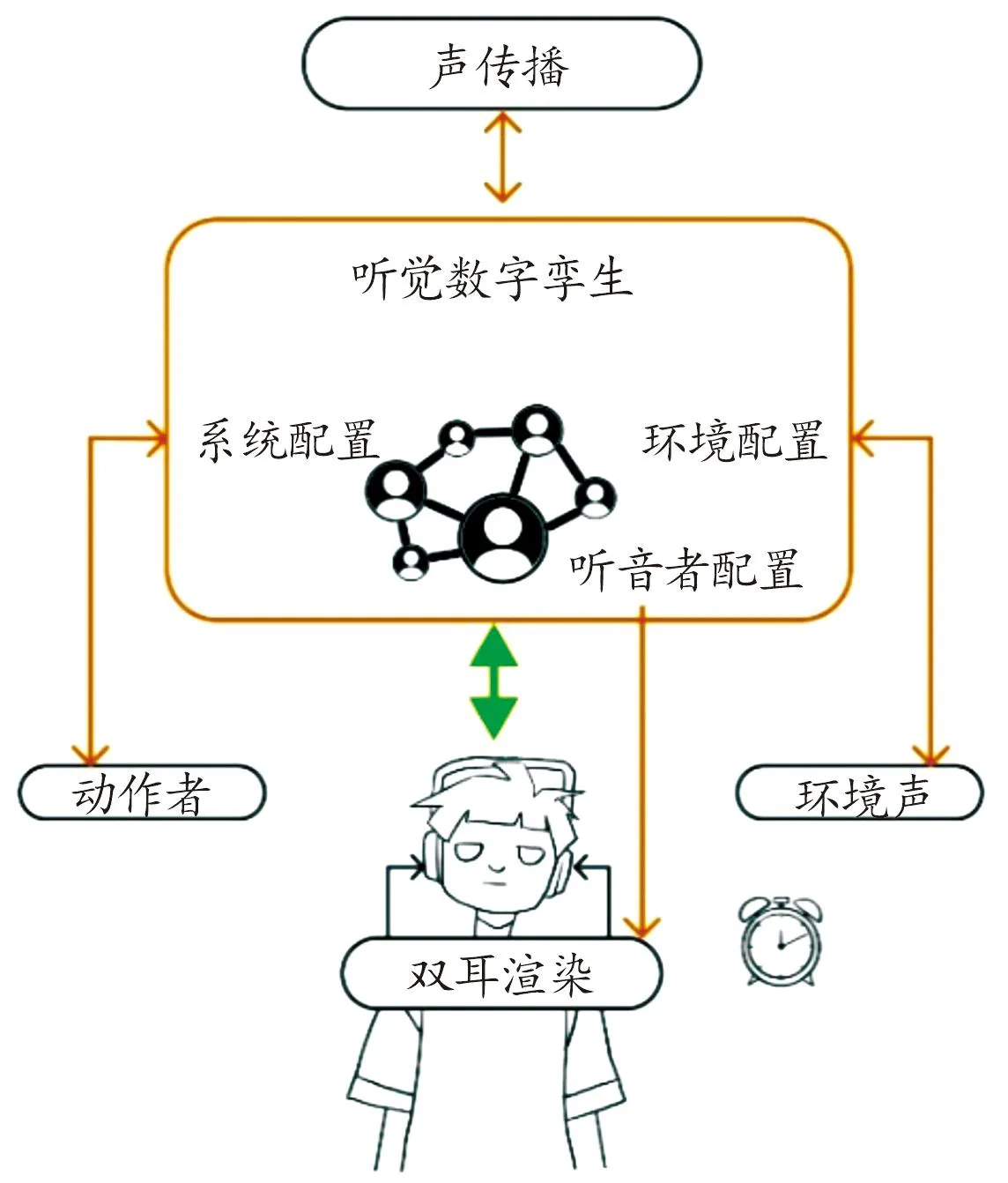
图1 听觉数字孪生系统图
哲学家莫里斯-梅洛-庞蒂在模糊性概念指出,所有的经验都是模糊的,不是由已定义的、可识别本质的东西组成,而是由开放灵活的风格或互动和发展模式组成[12-13]。从以自我为中心的沉浸式VR的空间角度出发,当听众的注意力被引导到外部的虚拟声音时,其学习和转化过程就会发生具身性的改变。因此,虚拟环境的听觉模拟,是由听者和数字孪生体过去的认知经验形成的,在建构主义的意义上,他们不清楚如何从物理或控制论世界中获得,由身体、头部和耳朵诱发或模拟的物理-声音印记,以及③由与技术共生诱发的主动和适应性的感知再学习过程[14-15]。正如Vindenes等[16]所指出的,经验是以听众的主观性为中介的,而听众的主观性是与VE的客观性联系在一起的。将物理世界和虚拟世界放在同一水平上,对于听众和它的数字孪生体来说,产生了相似性的具身表征,能够促进VR体验的变革作用,使人与现实的关系在接触后发生改变。
广泛使用的空间音频生成技术主要以传统的数字信号处理(DSP)为基础,通过DSP技术将双耳声音与空间信息作为一组线性时不变的声学组件,基于简化的几何模型实现模拟。由于精确的基于波形的室内脉冲响应模拟在计算上开销巨大,并且需要详细的几何和材料信息,因此实际中不常采用。头部相关的传递函数在电波暗室中进行测量[17],而高质量的空间化需要在近10k的不同空间位置进行双耳记录[18]。为了生成双耳音频,基于DSP的双耳渲染器通常会对分量脉冲响应进行一系列卷积。目前,神经网络的空间化研究进程已经开始。Gebru等[19]的研究表明:HRTF可通过训练原始波形,实现神经网络隐式学习。Manocha等[20]的一项工作致力于预测以视觉信息为条件的空间声音,但由于工作局限于一阶双声道,无法详尽地模拟双耳效应。与之相比,Yang和Zhou的一系列针对于2.5D视觉音效系统的论文[21-22]更为密切。在这一系列论文中,双耳音频是在视频帧嵌入的条件下生成的,因此可有效判断声音来源的位置。
本文中旨在将与虚拟环境中的声音交互(SIVE)有关的研究群岛转化为一个研究领域,提出听觉数字孪生的理论框架,对未来的挑战有一个包容性的看法。在一个采用了沉浸式音频技术的VE中,VR模拟的作用必须由人类和非人类代理(称为行动器)网络中的意识制造的参与性探索来发布。听觉数字孪生技术促进了人类和技术之间的内部互动,动态和流畅地重新定义所有那些对沉浸式和连贯性体验至关重要的配置。纠缠理论的想法在这里主要是在“以人为本”的空间视角中被拒绝,这与听者感知能力的知识有关。
本文中的核心是创建一个理想的听觉数字孪生系统,以一种音频视角来实现“以人为本”的模拟听众和其数字孪生体之间的具身映射关系。本文中的主要目标是通过一个听觉数字孪生体来描述听者和虚拟环境之间的交互行动,实现扩展现实(XR)体验下的空间音频孪生及多感官具身交互,并应用于军事虚拟仿真场景。
1 XR体验的空间音频渲染方法
空间音频,即从双耳收到的信号中解读空间信息的能力,通过向大脑提供相匹配的听觉与视觉输入来建立对空间的沉浸感、具身感,能够帮助我们实现在虚拟环境和真实环境之间映射的自我定位。目前,空间音频合成的大多数方法主要建立在传统的DSP技术的基础上,将每个组件——HRTF、环境噪声、房间声学等建模成线性时不变系统(LTI)。这些LTI能够被很好地理解,也较容易用数学建模,经过实验证明能在一定程度上产生接近于双耳音频的效果,因而至今仍得到广泛使用。但是,真实的声波传播为非线性波效应,故LTI无法对其进行适当建模,最终效果也不尽如人意。因此,数字信号处理技术虽然具备较好理解、相对简单的优势,但无法体现出动态场景的感知真实性,无法产生准确的度量结果,最终导致生成的波形与记录的双耳音频相似度较差,具身感知大大削弱。本文中通过理解、研究一种端到端的神经合成方法,可有效克服上述限制,合成精确的空间音频。端到端的神经合成方法能够自然地捕捉声波传播的线性和非线性效应,并且采用完全卷积的技术,在硬件上实现有效执行。这一神经合成方法优势主要体现在以下3点:超越现有技术水平的双声道模型;通过分析原始损耗的缺点以减轻这些损耗所带来的损失;在非消声环境中捕获真实的双声道数据集。
1.1 端到端网络的空间音频合成方法
空间音频合成系统的框架如图2所示。一个神经时间规整模块首先将单通道输入信号规整成双通道信号,时间规整补偿了粗略的时间效应,以及声源到听者双耳间的距离差造成的时间差效应。给定每个时间步长的声源和听者位置和方向,将单通道输入信号转换为双耳信号。神经时间规整模块在尊重物理特性(如单调性和因果性)的基础上,实现从源位置到听者左耳和右耳的精确规整;时间卷积神经网络模块模拟了细微的影响(如房间混响或与头部和耳朵形状相关的信号修改)对最终输出信号造成的差异。图2中的第2个方框代表一个N层的堆栈,每一层都是条件超卷积,然后是正弦激活,有研究证明这样有利于实现更高频率的建模[22]。按照WaveNet的设计,我们使用尺寸为2的卷积核,每一层的膨胀系数为2来增加感受野。这种时间卷积网络模拟了由房间混响、头部和耳朵的形状或头部方向的变化引起的细微影响。

图2 空间音频合成系统框架图
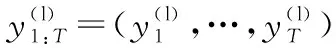
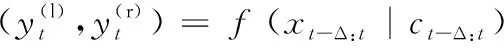
(1)
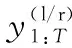
1.2 XR体验的音频渲染方法
XR体验的音频根据场景可分为动态音频和静态音频,动态音频是指音频内容不能提前制作,需要根据场景和环境实时渲染,例如直播、游戏等场景,一般使用游戏引擎制作。静态音频是可以提前制作的音频,例如音乐、影片等,常用的格式是ADM-BW64或已经渲染的双耳音频和扬声器音频,一般使用数字音频工作站(DAW)制作。其中ADM是三维空间音频的元数据定义框架,参考BS.2076-2,使用BW64格式的wav文件存储音频数据和ADM。静态音频有时可作为动态音频的输入以制作交互音频。
图3的制作流程包含以下功能:静态音频制作时,需要具备生成Object轨迹、录音、导入音频、回放、导出的功能。动态音频制作时,具备使用三维空间场景的能力,并且能够进行头部追踪、场景交互,同时具备静态音频的录音,回放功能。交互音频最终回放形式为双耳回放或扬声器回放。渲染器具备解析渲染包含ADM元数据和扩展元数据音频的能力。静态音频可作为动态音频的一部分输入。
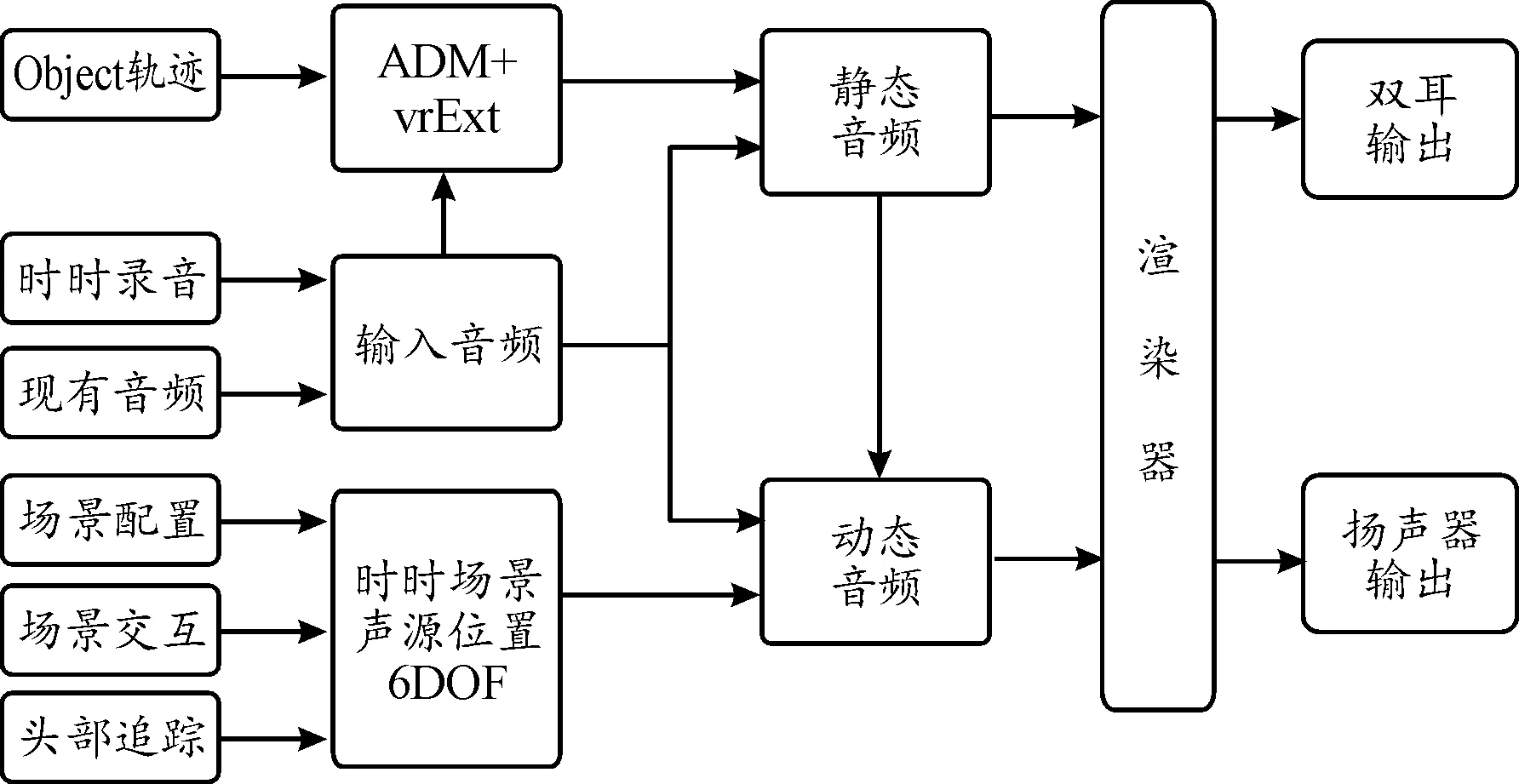
图3 空间音频渲染流程图
2 基于具身引擎的听觉数字孪生系统制作
基于具身引擎的听觉数字孪生系统主要有以下2种制作方法:第1种方法是在引擎中使用空间化插件模拟听众的具身环境,通过混响插件和基于函数计算的音频处理插件来处理音频,第2种方法是使用外部DAW制作空间音频并与模型中的虚拟扩声系统进行路由。
第1种方法是在引擎中使用空间化插件、混响插件和基于函数计算的插件来处理音频。空间化插件使用HRTF以双耳渲染直接处理声音,以准确模拟声源相对于听者的方向,用户可以清晰感知虚拟声源在三维空间中的绝对和相对位置(为达到听者所听内容差异性最小化的目的,需采集并对比大量用户的双耳以及头部相关物理数据,计算得出符合多数人耳听音条件的“头部相关函数(HRTF)”,在聆听房间中的各种滤波和反射声整合而成,此处的聆听房间声场大致接近于由麦克风阵列所录制声音合成的声床),还需测算出聆听房间的“双耳房间传递函数(BRIR)”。混响插件可以分析场景中房间和对象的大小、形状、布局和材质属性,使用这些信息通过模拟声音的物理特性来自动计算环境影响,使用混响插件时不必在整个场景中手动放置效果过滤器,也不必在各处手动调整过滤器,混响插件使用自动实时或基于预计算的过程,在整个场景中计算环境音频属性(使用物理原理),混响插件还可以计算卷积混响,这涉及在整个场景中的几个点计算脉冲响应,卷积混响会产生令人信服的环境,听起来比参数混响更逼真。基于函数计算的插件将众多混音与音频流处理工作中常用的效果器,如压缩器、限制器、EQ等,以及各种波形生成器,以引擎代表性的节点的形式,作为一个个单独的函数存放在插件中。使用者可以用类似着色器的形式,创造一条可视化的音频渲染管线。目前,在立体声场方面,这种基于函数计算的插件提供了至多8个声道的立体声混音器,用于在X/Y录音模式与M/S录音模式间转换的中-侧声道编解码器,以及可以模拟双耳时间差参数,以实现HRTF定位的双耳时间差的声像摆位器。
第2种方法是外部DAW中制作空间环绕声并将各个声道与模型中虚拟扩声系统进行路由。目前,主流DAW都已经拥有原生的3D Panner,部分DAW拥有内置的原生渲染器,除此之外,还可以使用我们自研发的渲染器结合开源程度较高的DAW制作。此方法采用多声道虚拟音频与引擎的交互,实现声音与舞台模型的结合。基于对象的环绕声制作不再受限于严格的重放制式,双耳渲染应用场景大幅增加。由于各个引擎可兼容和编辑的音频格式不同且有局限性,虚拟音频母版文件不便用于声音与模型的链接。在母版文件混音制作结束后,对照对象在空间中的位置信息和移动轨迹,在响度模拟软件中进行虚拟扩声系统设计(虚拟扩声系统在引擎中的信号路由参照真实扩声系统的搭建),水平、环绕、天空音箱以及超低的分布应保证各个音频对象运动于可用的重放范围内。现阶段音乐响度标准、影视响度标准和扩声响度标准各不相同,应在系统设计结束后严格对混音做出调整以达到最真实的现场听音效果。不同于在引擎中直接播放模板文件,根据对象的运动轨迹设计重放系统并直接将单独音频对象添加到引擎的播放系统中,可以最大程度还原空间信息,最大程度减小双耳重放造成的声场变化。对引擎中的扬声器模型加以动态效果,视觉上实现声音可视化,能进一步完善现场听音环境的还原。
2.1 虚拟声场的设计
以7.1.4环绕声系统设计为例,包括顶部左、右前置和后置扬声器4个、右后和左后扬声器2个、左右环绕声场扬声器2个、左、中和右扬声器3个和超低音音箱1个,如图4所示。其中,顶部左、右前置和后置扬声器使用相同的全音域设计,根据主聆听座位进行放置;右后扬声器和左后扬声器通过进一步定位音效来增加听感体验的强度,将它们布置在座位区的后面,与中心成135°~150°角;左环绕声场扬声器和右环绕声场扬声器,环绕声扬声器营造逼真的空间感,提供环境音效,将这2个布置于座位位置略靠后的区域并形成一定的角度,最好刚刚高于耳高;左、中和右扬声器有助于音乐随舞台灯光的变化而变化;超低音音箱可发出最强的低音,从而为音乐增加力量。
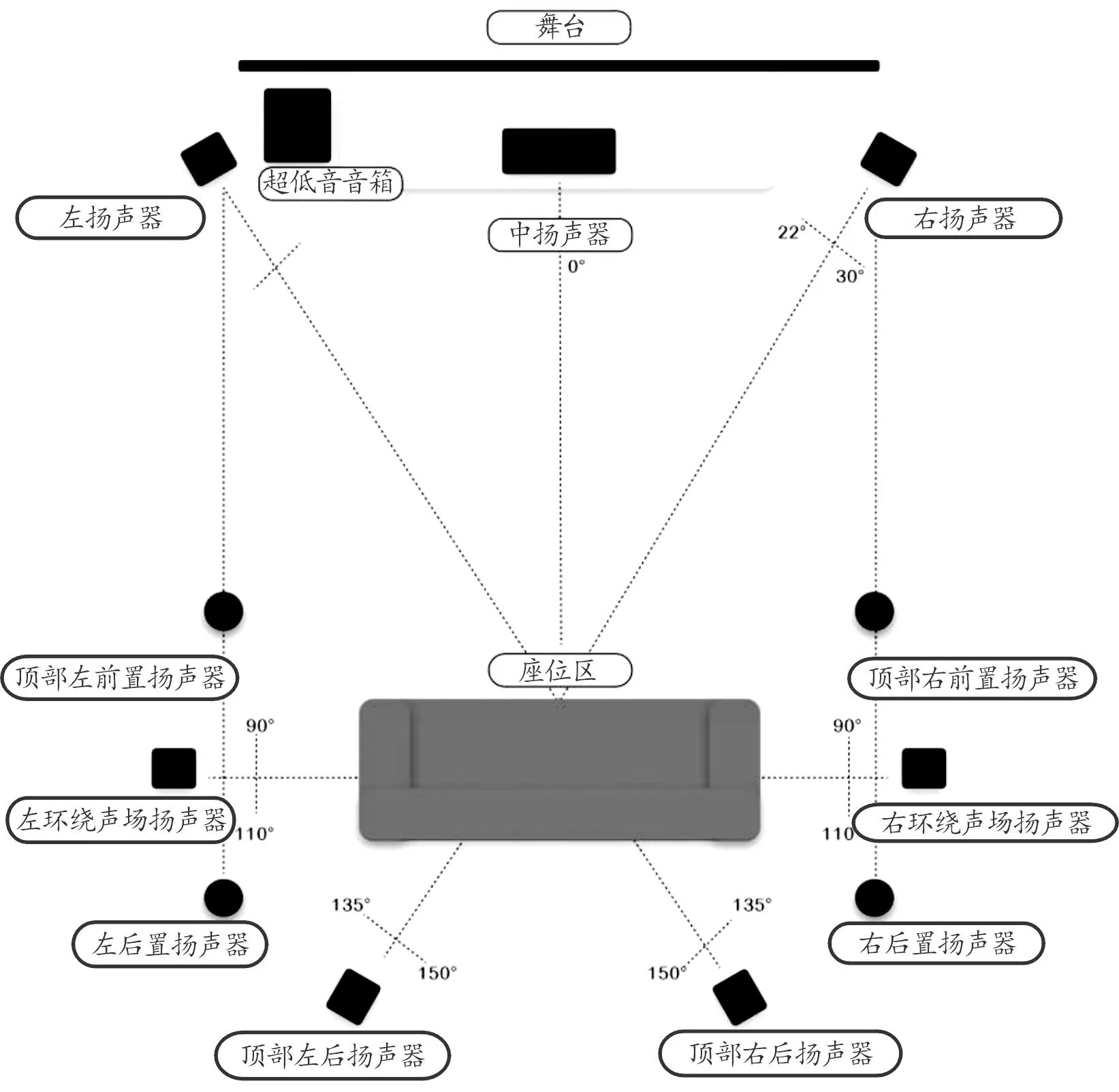
图4 扬声器摆放位置示意图
2.2 基于具身引擎的制作流程
1) 立体声声像平衡。利用“立体声声像摆位器”节点,同时输入音频信号与声像参数(以浮点数形式),即可分别输出调整声像后的不同声道音频,用于进一步渲染或是直接输出,并且可以更改声像工作法则预设,以在“自动平衡功率”与“仅进行线性叠加”2种模式间进行自由切换,以匹配不同的声场设计需要,如图5所示。
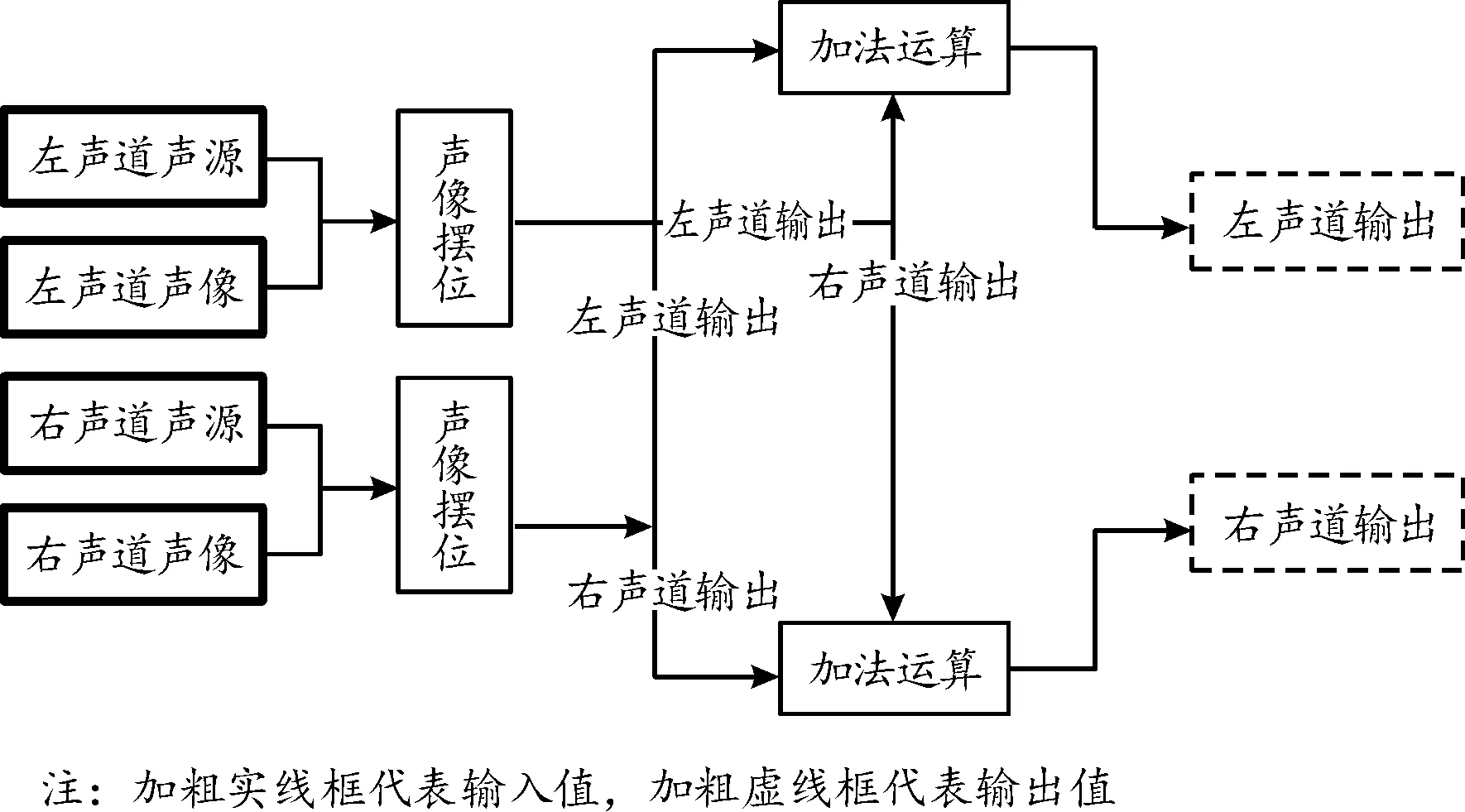
图5 立体声声像声场设计
2) 音频资产参数随机变化。通过随机生成节点,可以获得在某个范围内不断变化的随机数并接入声波播放器节点作为参数,以实现声音资产的随机变化,增强真实感,且同样可将双声道音频分别输出以用于双耳渲染。其中,音频资产可以是特定的某个wav文件,或者由自行设置的变量输入音频流,而此变量既可以是wav资产,也可以为一维音频数组(图6)。
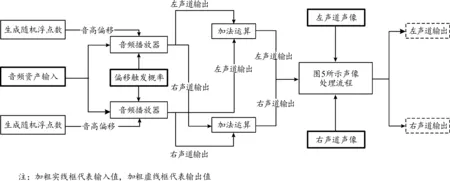
图6 音频资产参数随机变化
3) 多轨立体声处理。用UE5中Metasound插件构建一套最多可支持8个音轨输入,可同时处理并输出双声道音频的实时渲染、混音工具,其中每个音轨均可独立控制声像、响度增益、生效概率(该声轨在单个独立事件中被触发的概率),随机声像参数的变化范围等(图7)。
3 具身性听觉孪生系统与相关应用场景
3.1 基于具身引擎的听觉孪生系统
基于具身引擎所建构的听觉孪生系统,完成了人(虚拟人)、空间、听觉感知三者的具身关系,建构了主-客之间声音感知在空间位置中的包裹性,利用声像摆位将声音达到耳朵感知区域的那一刻,实现了具身性的包裹,主体被卷入“声音场”中心。在这种具身化的“声音场”中,声音的强弱、高低触动着人的听觉神经,并基于听觉完成外部空间的建构。例如,盲人对于现实世界的空间定位,就是来自于声音场所带来的具身感知,声音会随着盲人身体的运动变化完成衰减与增益,这种细微的变化为盲人的空间导航提供了保障。因此,基于具身引擎搭建的听觉数字孪生系统,可以有效适配每一个实战环境,完成真正意义上的虚拟战场仿真。
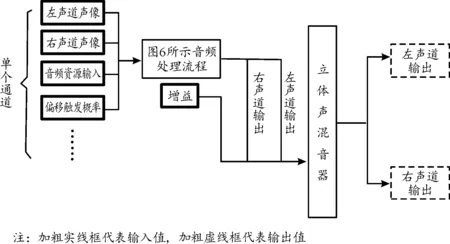
图7 多轨立体声处理过程
3.2 应用场景
以无人机作战为例,声音作为一种和作战活动有着密切联系的因素,无人机听觉系统在这个过程中产生出的“具身性”十分明显。这种关系从本质上离不开身音主体在听觉、空间二者之间的深层同构关系。
听觉装置需要识别炮弹爆炸声、车辆发动机在不同转速和负荷条件下发出的不同声音,对发声对象的类型、状态等特征做出准确判断,并通过具身算法与环境进行交互,快速做出躲避或攻击等一系列决策。与传统的无人机作战相比,基于具身引擎的无人机能够快速适应不同作战环境,展现出更高的作战效率。
此外,在资源保障作战等场景下,无人机的空中声学系统需要在人类叫声和环境噪音及其他非人类求救信号(如动物的叫声和风声等)之间进行破译,还可能需要识别求救人员试图引起救援队注意的踢腿、鼓掌或者其他响动,正确识别哪些声音是人类发出的,从而定位求救人员产生特定声音的准确位置,提高救援效率。由于无人机的红外探测器和雷达探测器的可探测距离易受某些因素限制,后续无人机在装备听觉孪生设备后,有望弥补现有探测传感器的不足,在灾害救援时增加识别概率和加快识别速度,避免更大的损失。
在无人机自主导航情形下,传统的无人机基于视觉或灯光系统提供指导,当视觉提供的信息不足时容易造成无人机自主导航系统失效。而基于具身感知的无人机引擎能够有效适应黑暗、雨雪等条件,从而保障无人机的安全性。
4 结论
1) 作为军事虚拟仿真的应用场景创造身临其境和交互式的扩展现实体验需要在严格的实时限制内鲁棒地模拟出真实的听觉孪生效果。
2) 为了满足上述要求,实时系统遵循模块化方法,本文中将问题分为空间音频合成、听觉孪生制作和具身交互3个部分,并通过HRTFs进行数学公式化,从而形成一个通用框架。
3) 针对具身性听觉孪生系统提出了在无人机作战方面的应用与展望,利用听觉数字孪生实现更具沉浸感、真实感的扩展现实(XR)体验,可以提高作战效率。
猜你喜欢
家庭科学·新健康(2023年9期)2023-10-01
青少年科技博览(中学版)(2022年9期)2022-11-01
家庭科学·新健康(2022年1期)2022-02-02
家庭影院技术(2021年7期)2021-08-14
紫禁城(2020年5期)2021-01-07
电子制作(2019年22期)2020-01-14
家庭影院技术(2019年8期)2019-08-27
软件(2016年6期)2017-02-06
家庭科学·新健康(2016年11期)2016-11-23
创新作文(小学版)(2016年11期)2016-11-11
