基于LSTM-ES-RVM 的滚动轴承剩余寿命预测方法
2024-01-10 01:42周圣文郭顺生杜百岗
振动工程学报 2023年6期
周圣文,郭顺生,2,杜百岗,2
(1.武汉理工大学机电工程学院,湖北 武汉 430070;2.数字制造湖北省重点实验室,湖北 武汉 430070)
1 概述
滚动轴承作为旋转机械设备中的关键机械基础件之一,因其退化周期长且失效具有随机性,其安全性备受关注。相关统计数据表明,超过30%的旋转机械设备故障是由滚动轴承故障引起的[1]。
相比故障诊断,寿命预测可以提前预测设备未来的健康状况,具有更多的意义。设备RUL 预测主要包括获取状态信息、提取性能退化HI 曲线和HI 曲线趋势预测三大部分,其中提取性能退化HI曲线是一个重要的研究问题。基于此,许多学者提出了多种方法来提取HI 曲线,并取得了一定的研究成果。Lei 等[2]使用均方根(Root Mean Square,RMS)构建HI曲线。Antoni[3]使用峰度(kurtosis)时域指标构建HI 曲线。Rai 等[4]采用经验模式分解(Empirical Mode Decomposition,EMD)方法将每个信号分解成多个固有模态函数(Inherent Mode Functions,IMFs)成分,然后选择前两个IMFs 作为输入,进行奇异值分解(Singular Value Decomposition,SVD),生成HI 曲线。Zhang 等[5]利用短时傅里叶变换和非负矩阵分解模型,从时频分布中提取时频码(Time-Frequency Codes,TFCs),随后通过自组织特征映射(Self-Organizing Feature Map,SOM)神经网络来量化特征向量之间的相似性并生成HI 曲线。
然而,上述方法存在以下问题:(1)上述HI 曲线构建模型需要先验知识和人工经验,例如,选择至少一个或多个融合的时频域指标(RMS 和kurtosis 等)进行组合;(2)这些HI 构建模型需要通过几个不同的模型进行融合,过程比较繁琐。
LSTM 模型为多层网络结构,通过建立先前信息和当前环境之间的时间相关性,能有效地降低对专家经验的依赖性。基于此,众多学者采用LSTM网络来提取HI曲线。Cheng 等[6]提出了 一种基 于LSTM 的融合方法,该方法包括时频域指标、核谱聚类和LSTM 三大部分,以识别设备的退化趋势。申彦斌等[7]提出了一种基于双向长短时记忆(Bi-directional LSTM)网络的循环神经网络结构,提取轴承的HI 曲线。黄宇等[8]提出一种结合双向长短期记忆网络与注意力机制的神经网络模型构建HI曲线。
HI 曲线的单调性是影响设备RUL 预测结果的关键因素。虽然LSTM 在一定程度上已经应用于提取HI 曲线,然而通过LSTM 提取的HI 曲线中存剧烈振荡。如图1(b)所示,通过LSTM 构建的LSTM-HI 曲线在第250 个数据点之前具有明显的振荡,而从第250 个点附近开始微弱增长。因此,有必要找到一种合适的方法来处理图1(b)中的红色虚线矩形中的剧烈振荡区域并改善其单调性。
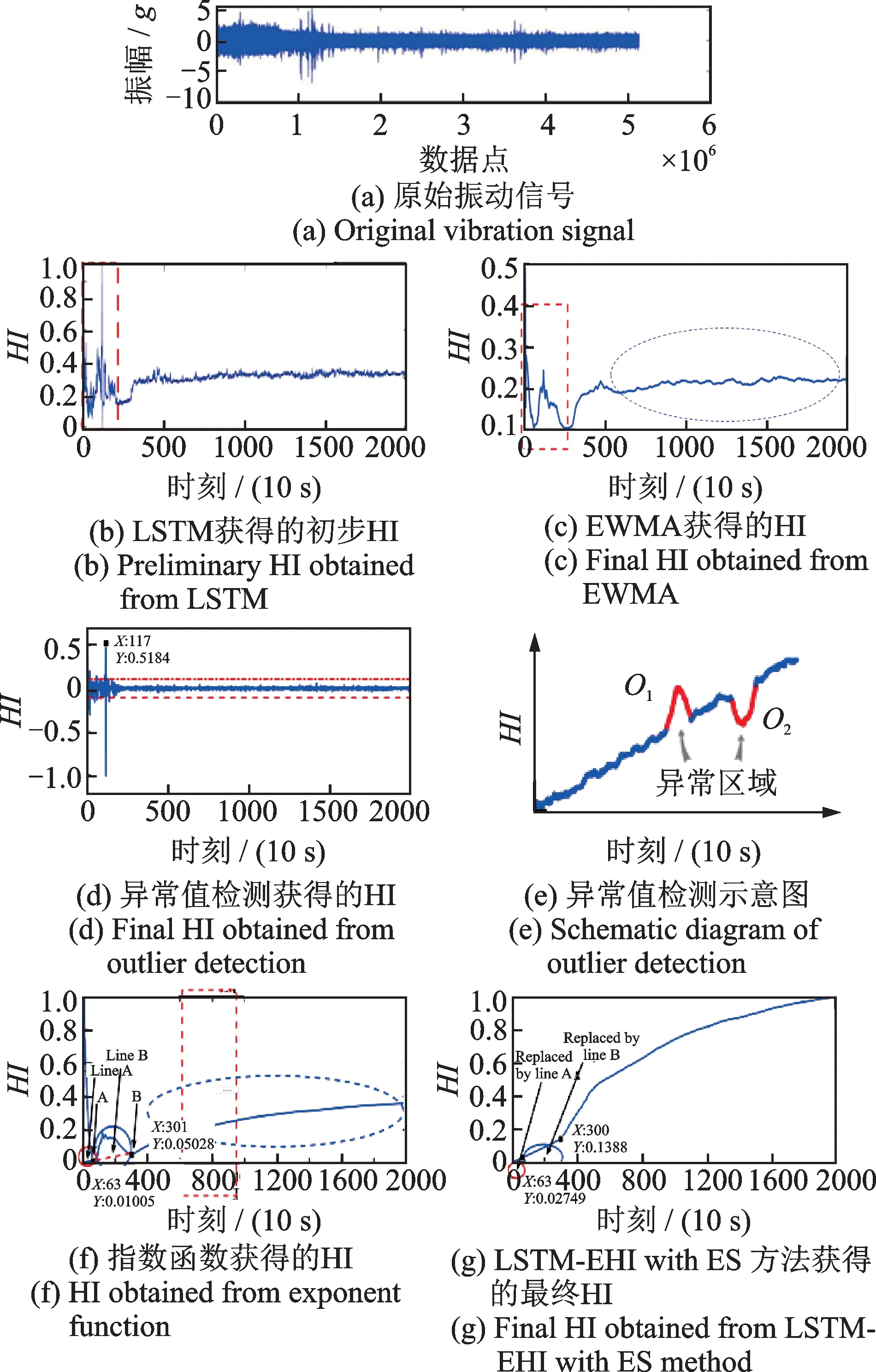
图1 使用不同方法处理LSTM-HI 曲线剧烈振荡区域并改善单调性对比图Fig.1 Different methods are used to deal with the violent oscillation region of LSTM-HI curve and to improve the monotony contrast graph
指数加权移动平均(Exponentially Weighted Moving-Average,EWMA)、异常检测(Outlier Detection)和基于均值指数函数(Exponent Function based on the Mean)是三种常用来处理HI 振荡的模型。其中,EWMA 模型通过对时间序列数据的加权平均来控制预测过程中的均值漂移,可有效平滑时间序列数据。Tse 等[9]使 用EWMA 模型平 滑提取油砂泵的HI 曲线,并取得了良好的结果。异常值检测模型则利用数据的差值和标准差来检测异常数据点,以帮助识别异常数据并剔除其影响。谢雨洁等[10]引入了基于多尺度局部核回归的异常值检测方法,提高了轴承退化阶段识别的准确性。基于均值指数函数则使用起始时间到当前时间期间数据点的平均值来减弱剧烈振荡,并利用指数函数本身的单调递增特性增强HI 曲线的单调性。Tse 等[11]利用均值指数函数对HI 曲线进行平滑处理,并获得了良好的效果。
为了消除LSTM-HI 曲线的剧烈振荡区域并改善其单调性,本文分别利用EWMA、异常值检测和基于均值指数函数对LSTM-HI 曲线的振荡区域进行平滑处理,如图1(c),(d),(f)所示。其中,基于均值指数函数提取的HI(LSTM-EHI)的计算公式如下:
式中HIi表示i时刻的 LSTM-HI 值 ;mean{HI1,HI2,…,HIi}为从HI1到HIi的平均值。
然而,上述方法存在以下问题:
(1)相较于图1(b),图1(c)通过EWMA 平滑方法所得到的曲线并没有明显改善HI 曲线的平滑度和单调性。尤其是在红色虚线矩形区域内,曲线仍然出现了剧烈振荡。此外,曲线在红色虚线区域内的削弱,使得整个缓慢增长趋势变得不明显,并且在蓝色虚线椭圆区域内的整体单调性也被削弱,这将导致预测RUL 的效果较差。此外,EWMA 方法需要具备先验知识才能设置指数系数和滑动窗口的数量。
(2)图1(d)中仅检测到一个异常点,因此无法生成异常点区域。而在图1(e)中,异常点区域需要一定数量的异常点来确定。然而在实际工程中,并不是所有的数据集都总是能够生成异常区域。此外,异常点检测只能提高局部异常点区域的单调性,而不能提高HI 曲线整体的平滑性和单调性。
(3)图1(f)为通过LSTM-EHI 方法提取的HI曲线,与图1(c)(EWMA)相比,LSTM-EHI 曲线更具平滑性和单调性。然而,红色虚线区域中的剧烈振荡曲线降低了整体的平滑性和单调性。出现这种情况的原因在于,轴承或设备在系统运行的开始阶段未达到稳定状态,从而导致振动信号的略微波动,进而导致红色虚线区域的HI值不稳定。因此,需要对这部分曲线进行处理和替换。
此外,近年来随着人工智能技术的发展,相关学者已经提出了多种趋势预测方法,主要包括误差反向传输(Back Propagation,BP)[12]神经网络、粒子群优化算法(Particle Swarm Optimization,PSO)[13]以及支持向量机(Support Vector Machine,SVM)[14]等。其中,SVM 利用支 持向量 样本集 决定预测结果,具有一定的鲁棒性,但存在计算复杂、耗时长、惩罚系数难确定、核函数受Mercer 条件限制等问 题。RVM[15]是一种 将Bayesian 理论与SVM 相结合的机器学习算法,相较于SVM,RVM具有良好的稀疏性和泛化能力,已在趋势预测领域得到一定的应用。
基于此,本文提出了基于LSTM-ES-RVM 的滚动轴承RUL 预测方法。首先,为了减少对先验知识和人工经验的依赖,提出了LSTM 模型,直接从频域上提取轴承的初步性能退化HI;其次,提出了ES 模型,以消除退化HI 曲线振荡并增强其整体单调性;最后,将提取的性能退化健康指标按时间维度拆分为训练集和测试集,利用RVM 模型对HI 曲线进行趋势预测,实现滚动轴承的RUL预测。
2 基于LSTM-ES-RVM 的滚动轴承RUL 预测框架
本文提出的基于LSTM-ES-RVM 的滚动轴承RUL 预测框架主要分为五个部分:数据采集、数据预处理、性能退化HI 曲线构建、健康阶段划分、RUL 预测,如图2 所示。
(1)数据采集:通过振动传感器实时采集滚动轴承的全寿命振动数据;
(2)数据预处理:通过快速傅里叶变换(Fast Fourier Transform,FFT)操作将原始振动信号从时域变换到频域;
(3)性能退化HI 曲线构建:先使用LSTM 模型提取初始HI 曲线,再通过ES 模型利用曲线的极小值数据点来替代HI 曲线局部剧烈振荡区域中的极值点,从而提高HI 曲线的单调性;
(4)健康阶段划分:在进行剩余寿命预测之前,可以根据设备退化HI 的变化趋势将设备的全生命周期划分为健康阶段、退化阶段和失效阶段;
(5)RUL 预测:采用RVM 模型对退化HI 曲线进行趋势预测,通过外推预测退化HI 曲线超过失效阈值的时间,间接获得设备剩余寿命的预测值。
2.1 基于LSTM-ES 的健康指标构建
为了获得图1(g)中的曲线,本文提出了ES 模型,以消除图1(f)的振荡区域并增强曲线的整体单调性。ES 模型的主要思想是在健康指标曲线中检测所有局部最小值数据点,并根据这些数据点的斜率按降序进行排序,通过将这些局部最小值点连接起来消除振荡区域,从而增强HI 曲线的整体单调性。算法流程如图3 所示,其中LSTM-EHI 作为ES模型的输入,经过ES 方法处理后的HI 曲线称为LSTM-EHI with ES 曲线。
具体的计算步骤如下所示:
步骤1:查找所有局部最小点(极小值点),并将其保存到相应极小值点数据序列MP。
步骤2:计算MP 中两个相邻极小值点的斜率,并得到斜率矩阵S,若斜率矩阵中的Sj为0(斜率为0 代表横坐标轴),则设置Sj=1。
步骤3:将Sj按照升序排列获得斜率数据集sorta 和相应的顺序下标集合sortb。
步骤4:使用临时变量Temp 保存当前选择的最小极值点P(xj,yj),该数据 点是根 据sorta 和sortb 获取的;xj表示相应数据点的下角标,yj为LSTM-EHI 数值,y1表示集合sorta 中最小斜率的点。Temp 变量的 第一个 数据点 为P(x1,y1),第 二个数据点为P(x2,y2),当数据点P(xj,yj)具有第二最小斜率时,选择局部极值点P(xj-1,yj-1) 和P(xj,yj),并使用这两点构建的直线替换HI 曲线单调性较差的区域。
步骤5:重复步骤4 直到满足当前数据点P(xj,yj)的斜率大于前面所有点的斜率时为止。
2.2 基于RVM 的剩余寿命预测模型构建
旋转机械的RUL 预测一直备受关注,剩余寿命预测是指确定当前检查时刻至失效阈值的时间间隔[16],通常用一个时间段来表示从当前时刻到机器失效的剩余寿命。定义如下:
式中Ti为当前检查时刻,由用户指定;Tf为预测退化HI 曲线首次穿过失效阈值所对应的时刻;RUL(Ti)为当前检查时刻Ti所预测的轴承剩余寿命。如图4 所示。
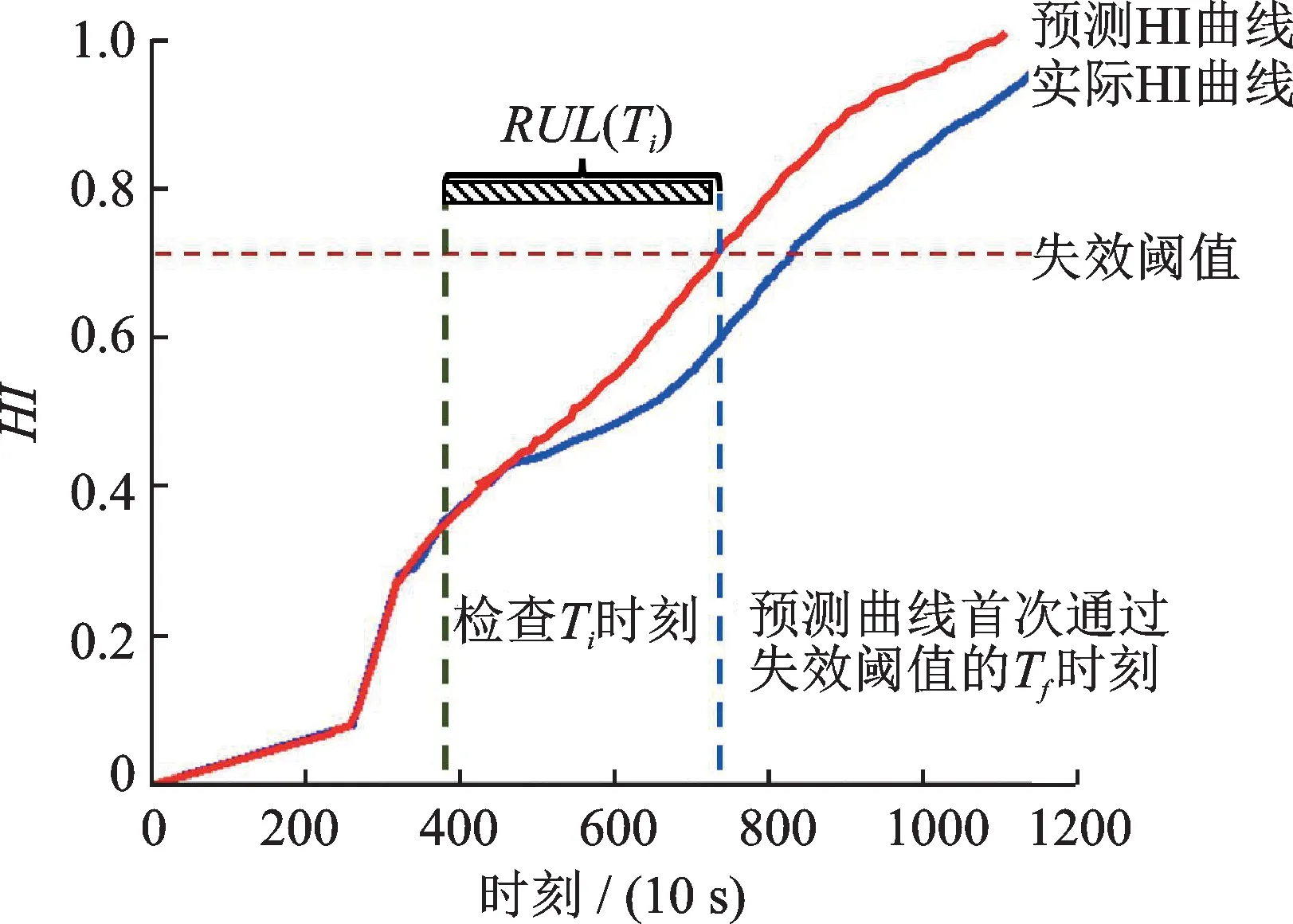
图4 剩余寿命预测示意图Fig.4 Schematic diagram of remaining useful life prediction
为了降低寿命预测模型的参数复杂度并提高训练速度,使用RVM 模型对HI 曲线进行趋势预测,从而实现了滚动轴承的RUL 预测。RVM 基本原理如下:
式中εi为零均值的高斯分布N(0,σ2)中各样本的高斯噪声误差,其中σ2为噪声误差的方差,是未知量。因此,容易得到p(ti|x)=N(ti|f(xi),σ2)服从高斯正态分布,其分布由ti,f(xi)及方差σ2所决定。
回归函数f(xi)的常见表达形式为:
式中k(x,xi)为核函数;w=[w1w2w3…wS]T为权重向量;w0为偏差。
由于高斯核(Gaussian kernel)函数具有局部性好、参数数量少、计算量小等优势,本文采用高斯核函 数k(x,xi)=exp {-‖x-xi‖2/(2τ2)},其 中τ为核宽度参数。
则最大似然概率可以定义为:
式中t=[t1t2t3…tS]T为训练样本的输出向量;ϕ=[φ(x1)…φ(xS)]T为S×(S+1)维的核函数矩阵,其中φ(xi)=[1k(xi,x1) …k(xi,xS)]T。
如果直接对上述似然函数关于w和σ2求极大似然,会导致“过拟合”的问题。Tipping[15]从贝叶斯定理的角度出发,认为权重向量w服从一定的先验分布,即:
式中αi为权重wi对应的超参数。
定义先验分布后,根据贝叶斯定理,未知参数的后验分布为:
根据贝叶斯定理,得到权重向量w的后验分布为:
其中,后验分布的协方差Q和均值μ分别为:
且A=diag(α)=diag(α1,α2,…,αS)。
此时,RVM 的训练学习过程转化为如何使超参数后 验分布p(α,σ2|t)∝p(t|α,σ2)p(α)p(σ2)最大化的问题。这一过程只需最大化边际分布p(t|α,σ2),通过对参数w进行边缘积分求得:
从而得到超参数α,σ2的边缘似然:
由于式(13)服从正态分布,因此有:
基于上述理论基础,本文提出了一种基于RVM 的剩余寿命预测模型。首先,将提取的性能退化健康指标按时间维度拆分为训练集和测试集,作为RVM 模型的输入;然后,拟合相关向量中未知的参数,从而获得相关向量;接着,设置预测过程中所需的检查时刻和失效阈值等参数;最后,通过外推拟合的退化HI 曲线超过失效阈值的时间,间接获取设备剩余寿命的预测值。
3 实验结果与对比分析
3.1 评估指标定义
3.1.1 单调性指标
使用单调性指标(Monotonicity,Mon)来评估构建的HI 曲线的单调性[17],Mon的计算公式如下:
如果Mon=0 表示HI 曲线平滑不具有单调性,即Number(dF>0)等 于Number(dF<0);Mon=1 表示HI 曲线持续平稳的单调上升或下降,即Number(dF>0)或Number(dF<0)为0。因此,Mon值越接近1,HI 曲线的单调性越好。
3.1.2 预测精度指标
为了定量评价预测模型的有效性和优越性,本文使用RE[18](Relative Error,相对误差)、RMSE[18](Root Mean Square Error,均方根误差)作为评价指标对轴承RUL 预测模型进行评估,其评估公式分别为:
式中n为数据总数;yi表示第i时刻的真实值表示第i时刻的预测值。
3.2 实验数据采集平台及数据预处理
本文采用IEEE PHM 2012 挑战数据集对所提出的方法进行有效性验证。该数据集来自PRONOSTIA 轴承退化试验平台(如图5 所示),共采集了17 个滚动轴承的数据,分为三个工况组,其中工况1 组和工况2 组各有7 个轴承,工况3 组有3 个轴承。实验平台每10 s 采集一个样本,每个样本长度为2560 个数据点,采样频率为25.6 kHz。表1 提供了有关数据集的详细信息[19]。
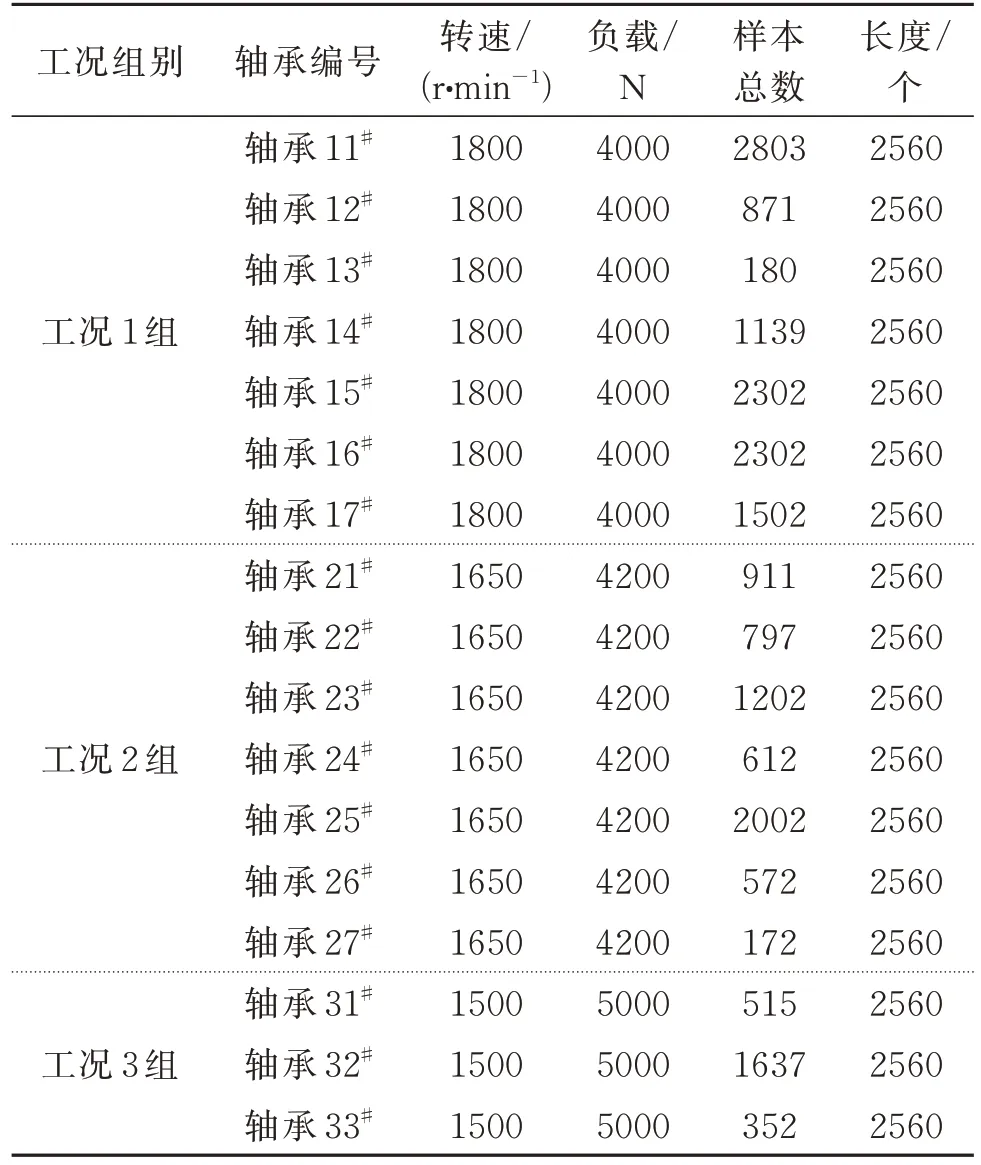
表1 不同工况下滚动轴承原始振动信号信息Tab.1 The roller bearing’s raw vibration signal information under different working conditions

图5 实验数据采集平台Fig.5 The experimental data acquisition platform
本文选取了轴承13#~15#、轴承23#~25#和轴承33#作为观察数据集。由于滚动轴承的振动信号具有非线性和随机的特性,从时域数据中很难提取到有用的信息,例如图6(c)中轴承15#的信号在曲线上就没有明显的变化。
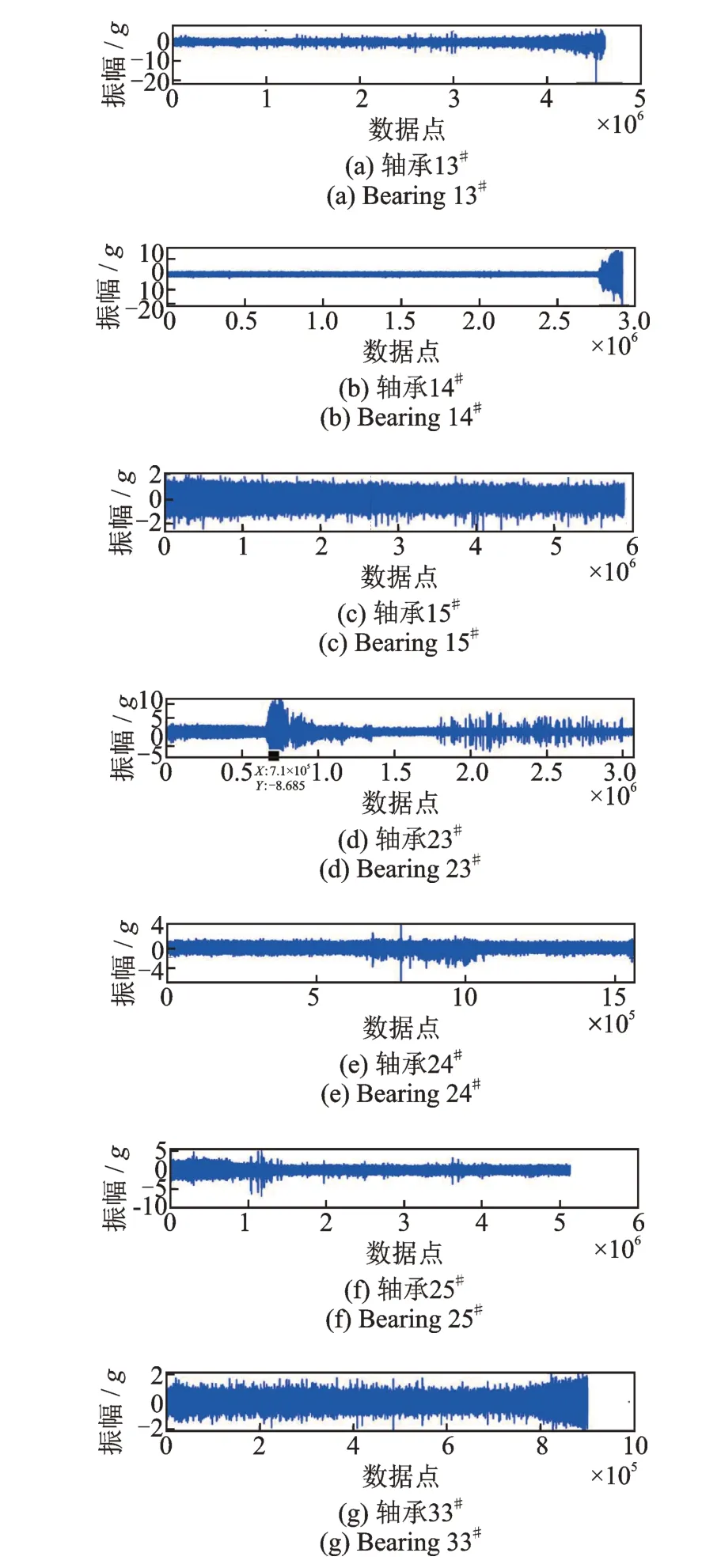
图6 不同轴承的原始时域信号Fig.6 The original time domain information of different bearings
本文采用FFT 方法将原始振动信号从时域变换到频域,以提取有用的信息。从图7 中观察到,大多数轴承的特征频率主要分布在103 kHz 左右,特别是轴承13#的特征频率为103 kHz,正好是系统工作频率(25.6 kHz)的4 倍,说明特征频率主要分布在工作频率的倍频。
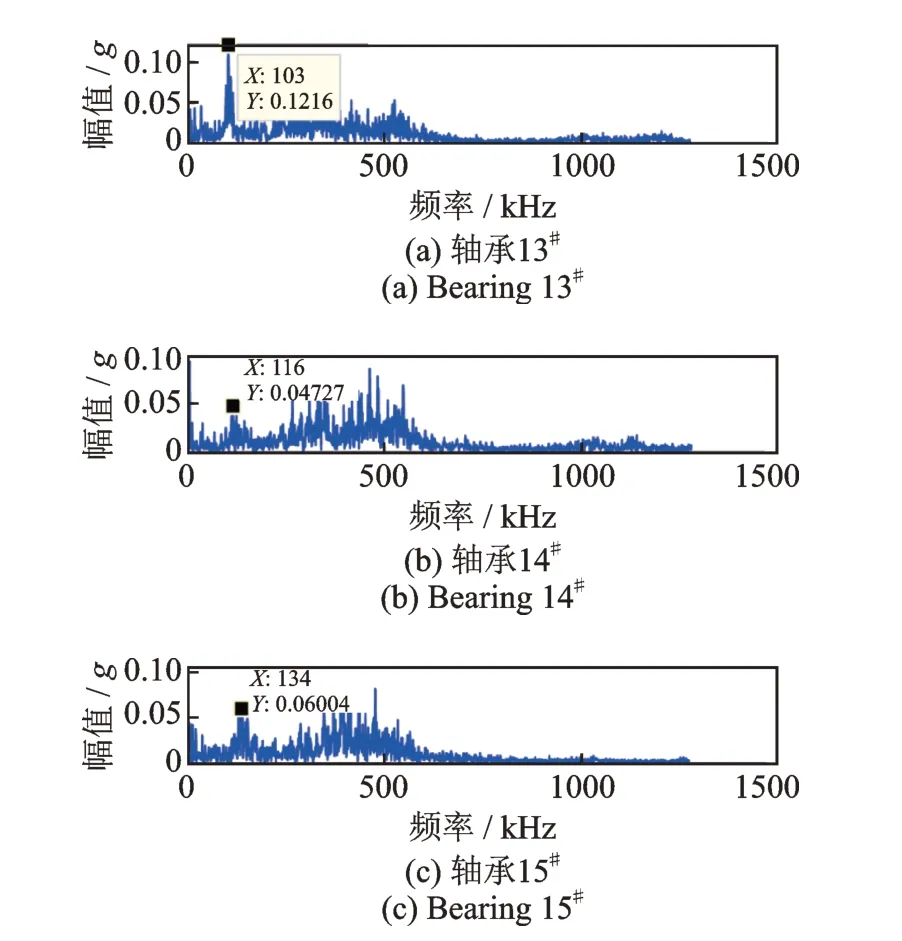
图7 通过FFT 方法转换的不同轴承的频域信号Fig.7 The frequency domain information of different bearings converted by FFT method
3.3 基于LSTM-ES 的健康指标实验结果与分析
3.3.1 基于LSTM-ES 的健康指标(HI)构建
在使用LSTM 算法提取LSTM-HI 曲线时,设定初始学习率为0.01,最大迭代次数为300。在训练过程中,采用均方根误差(RMSE)作为损失函数,自适应矩估计(Adam)作为优化器进行网络模型的参数优化更新。模型的输出值是第i个样本在t时刻的退化百分比,例如,若轴承24#的全生命周期样本总数为5120000 个且输出大小被设置为1,则第3072000 个样本点的目标退化百分比为0.6。
在利用LSTM 算法提取轴承的HI 曲线时,本文采用同工况组中的其他轴承作为LSTM 的训练数据集,比如,图8 中轴承13#的HI 曲线是以工况1组中的其他轴承作为训练数据集。

图8 LSTM-HI 曲线和LSTM-EHI 曲线Fig.8 The LSTM-HI curves and LSTM-EHI curves
(a)在图8(d)中,可以看 到轴承23#的LSTM-HI 曲线在第279 点之后急剧增加;与此同时,在图6(d)中,轴承23#的原始振动信号曲线在7.1×105个点的振幅也明显增加。这是因为一个原始振动信号样本包含2560个数据点,则图8(d)中轴承23#的279 点刚好 对应图6(d)中第7.1424×105(279×2560)个数据点。这说明LSTM 构建的HI 曲线(LSTM-HI)能很好地反映轴承振动信号的变化趋势。
(b)在图8 中,所有的LSTM-EHI 曲线总体上表现出比LSTM-HI 曲线更平滑的趋势,并且振荡显著减弱。特别在图8(d)的蓝色虚线矩形区域中,可以明显看出LSTM-HI值(0.6383)在第279 点有所增加。由于LSTM-EHI 曲线在计算过程中利用指数函数(式(1))对从开始时间到当前时间的平均值进行处理,因此其值(0.1409)明显小于LSTM-HI曲线的值(0.6386),振荡明显减弱。
(c)以轴承23#为例,使用式(1)中指数函数时,从开始时间到当前时间的HI 值的平均值作为指数函数的输入,如图9(a)所示。在图9(a)中,第279 点附近的值正在逐渐增加;相反,第263 点是图中的局部最小点,这是因为在图8(d)中,第263 点附近对应的LSTM-HI 值较小且第263 点附近点的值彼此接近。图9(a)中第263 点到第279 点的值也略有增长,这部分增长有效地缓冲了图8(d)中在第279 点之后曲线的增长,这表明基于平均值的指数函数可以有效消除局部振荡。为了进一步加强对指数函数优越性的解释,表明其可以有效地消除曲线的整体振荡,LSTM-HI 和LSTM-EHI 曲线的两个相邻点的差值如图9(b)所示。在图9(b)中,LSTM-HI 差值(蓝线)出现了明显的波动;相反,LSTM-EHI 差值(红线)非常稳定,接近于0。此外,图9(c)为LSTM-EHI 曲线的两个相邻点的差值放大扩展图。
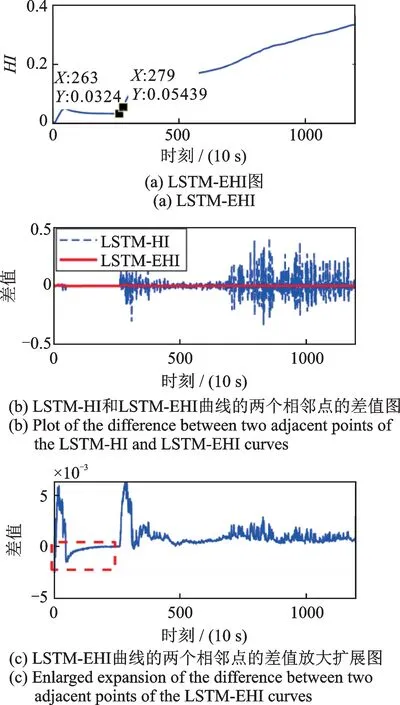
图9 使用公式(1)中指数函数时从开始时间到当前时间的平均值以及所有LSTM-EHI 的差值Fig.9 The mean value from starting time until the current time when the exponent function is used in formula(1)and the difference values for all LSTM-EHI
相较于其他轴承,轴承25#的LSTM-HI 和LSTM-EHI 曲线表现出较差的平滑度。在图8(f)中的蓝色虚线矩形区域(前300 个数据点之前),LSTM-HI 和LSTM-EHI 曲线都呈现出明显的波动。这些振荡曲线掩盖了曲线在300 个数据点之后逐渐增长的趋势,这种变化情况与图6(f)中轴承25#的原始振动信号一致。因此,需要删除并替换蓝色虚线区域中的LSTM-EHI 曲线,以保持曲线整体平稳的增长单调性。
为了改善LSTM-EHI 的单调性,并去除异常点和强烈振荡区域(如图8(f)中的蓝色虚线区域),本文采用ES 模型进行数据处理。图10 展示了不同轴承的LSTM-EHI with ES 曲线。
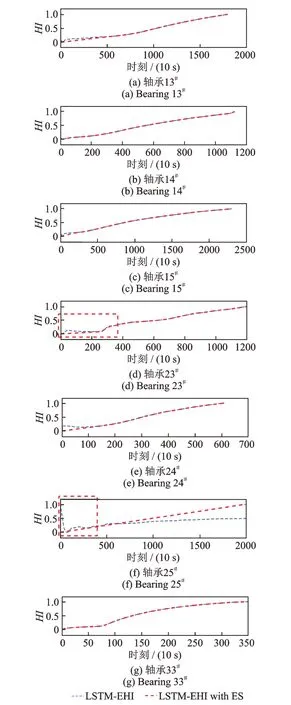
图10 LSTM-EHI 曲线和LSTM-EHI with ES曲线Fig.10 The LSTM-EHI curves and LSTM-EHI with ES curves
(a)在图10 中,轴承23#和25#的LSTM-EHI曲线中的振荡区域被ES 模型替换,且LSTM-EHI with ES 的两条红色虚线比LSTM-EHI 的两条蓝色虚线明显上升。特别是在轴承25#的红色虚线区域中,LSTM-EHI with ES 的单调性显著增强,在前500 个数据点之前,LSTM-EHI 曲线呈下降趋势,之后则急剧上升。这表明ES模型可以增强曲线的单调性。
(b)以轴承24#为例,用Mon的结果和比较分析来证明ES 模型可以增强曲线的单调性。将轴承24#的LSTM-EHI输入到ES 模型中,第一个局部最小斜率点编号为136(如图11 中点A),以坐标轴零点作为起始点和第136 个数据点作为终点所对应的直线斜率为K1=0.1691/136=0.00124(此处0.1691 为HI值);第二个局部最小斜率点编号为128 号所对应的直线的斜率为K2=0.1627/128=0.00127,K2>K1,因此编号为136 点的斜率为局部最小值。从第136 个数据点开始,所有后续点的斜率值都大于第136 点的斜率值,迭代结束。最后,图11 中蓝色矩形虚线区域中的红色虚线LSTM-EHI 曲线被黄色虚线曲线替换,从图中可以看出,ES 模型具有良好地增强LSTM-EHI曲线单调性的能力。
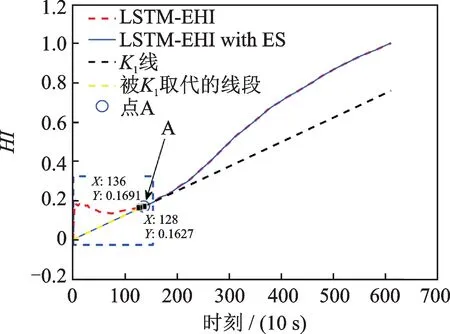
图11 轴承24#的LSTM-EHI with ES 曲线生成过程图Fig.11 The generation process figure of LSTM-EHI with ES curves of bearing 24#
3.3.2 与其他HI 构建模型的对比分析
为了证明ES模型具有良好的增强HI曲线单调性的能力,本文与文献中的其他模型进行比较,如RMS[2],kurtosis[2],EMD-SVD-k-means/k-medoids[11],频率指标(Time-frequency)[11],带指数 函数的SAE(SAE-EHI)[20],如图12所示。
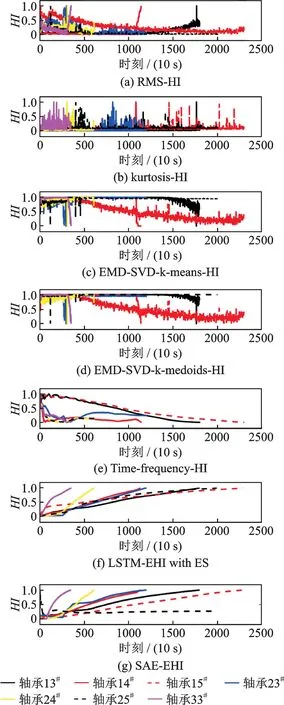
图12 不同轴承以不同模型构造HI 的对比图Fig.12 Comparison diagram of the constructed HI obtained from different models of different bearings
(a)所有轴承的HI 曲线通过RMS 和kurtosis 处理之后趋势都逐渐增加,但曲线中也存在一些噪声,这些噪声很容易导致整体单调性变差,如图12(a),(b)所示。经EMD-SVD-k-means/k-medoids 和Time-frequency 处理过的HI 曲线单调减小但趋势是平滑的,不会急剧下降或上升,如图12(c)~(e)所示。LSTM-EHI with ES 所有曲线明显倾向于单调增加,如图12(f)所示。
(b)图12(g)中轴承25#的SAE-EHI 曲线在开始阶段具有明显的振荡,但在图12(f)中,25#轴承的LSTM-EHI with ES 曲线的变化趋势更加稳定。
(c)本文对不同HI 构造模型的Mon值(式(17))进行了对比分析,如表2 所示,LSTM-EHI with ES的所有轴承HI 的Mon值均明显高于其他模型。
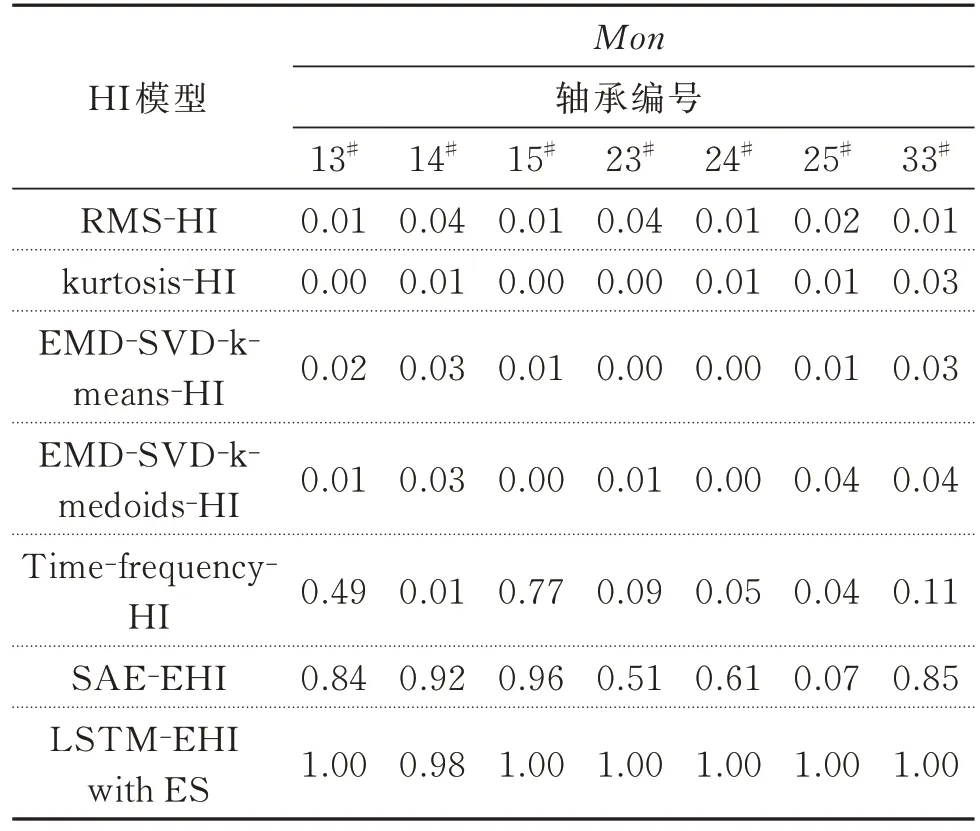
表2 使用各种模型时的Mon 对比结果Tab.2 The comparison results of Mon with various models
3.4 基于RVM 的剩余寿命预测模型结果分析
为了验证所提出的RVM 模型对寿命预测的有效性,本文选择IEEE PHM 2012 挑战数据集中工况2 组内的轴承23#的全生命周期数据作为实验对象,并选定检查时刻T(362,483,655)×10 s 对轴承进行剩余寿命预测。
3.4.1 模型参数设置
本文在进行剩余寿命预测时,采用RVM 模型,选择高斯核函数,最大迭代次数为2500,目标函数最小误差为10-3,失效阈值为819(10 s)时刻(轴承23#的初始故障点为8190 s)。
若高斯核宽度参数过小易导致过学习,过大易导致过平滑,因此,过大或过小会引起回归能力的下降。图13 显示了不同高斯核宽度的预测结果平均相对误差。从图13 中可以看出,高斯核宽度参数为0.1 时,对应的平均相对误差最小,故本文的高斯核宽度参数设置为0.1。

图13 不同高斯核宽度的预测结果平均相对误差Fig.13 Average relative error of prediction results with different Gaussian kernel widths
3.4.2 寿命预测结果
图14~16 显示了预测过程和相应的结果。表3给出了各检查时刻利用RVM 模型所得到的详细预测结果。从图14~16 和表3 中可以看出,随着更多的训练样本数据被提供,预测模型能够获得更好的预测结果。
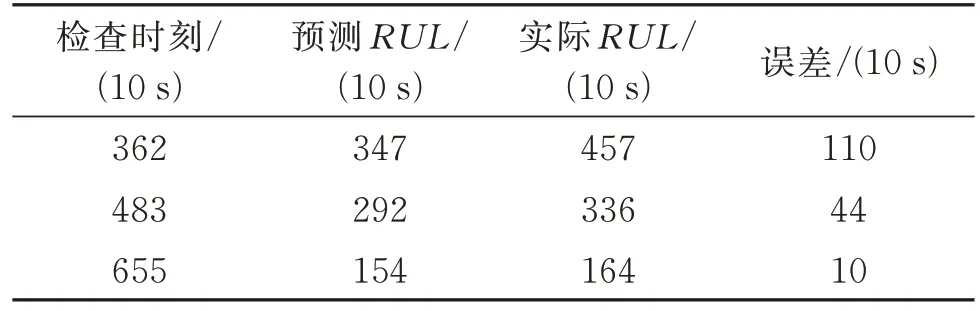
表3 轴承23#在不同检查时刻T 使用RVM 模型获得的详细结果Tab.3 Detailed results obtained by RVM model at different inspection time T of bearing 23#
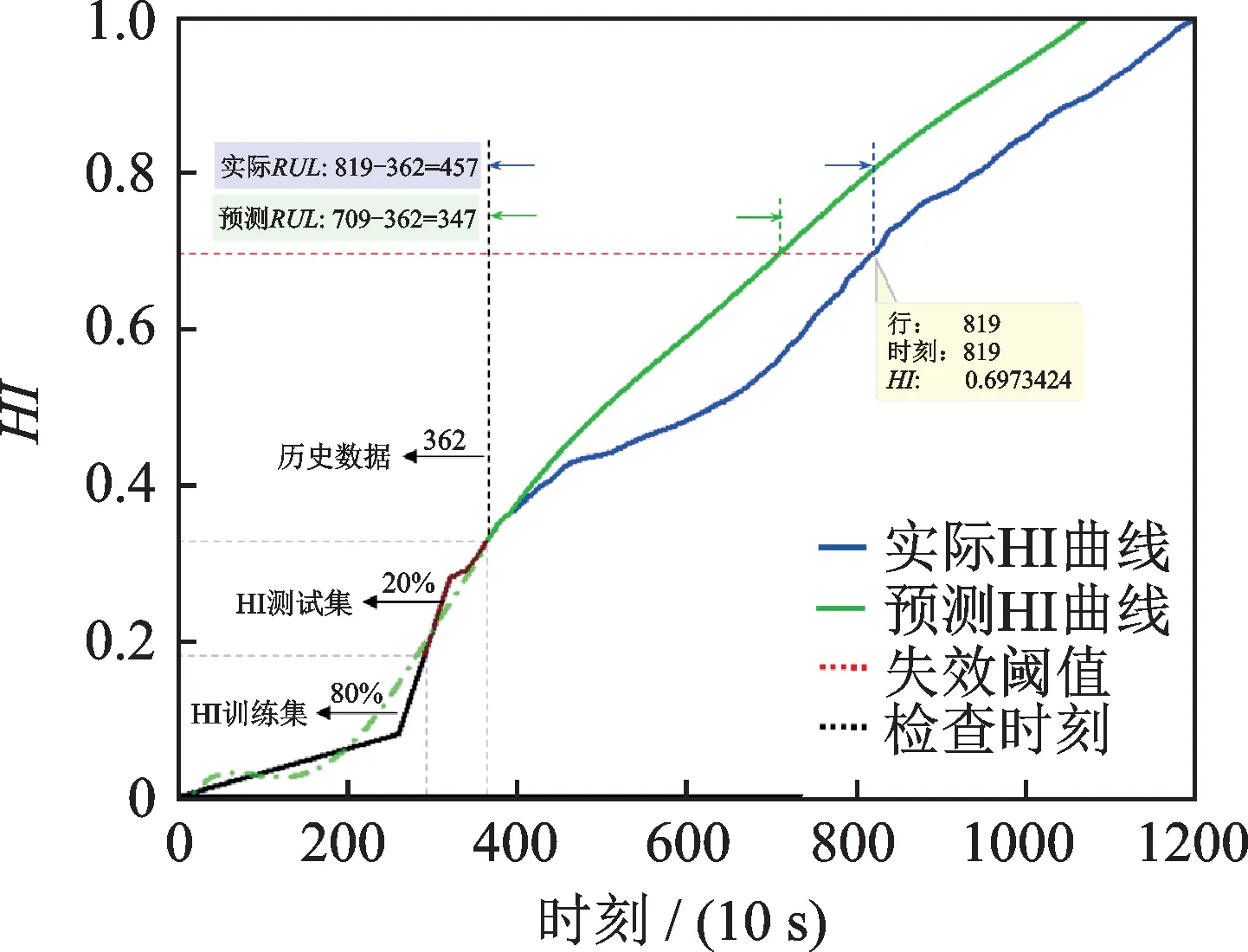
图14 轴承23#在检查时刻362使用RVM模型获得的预测结果Fig.14 Prediction results of bearing 23# at inspection time 362 with RVM model
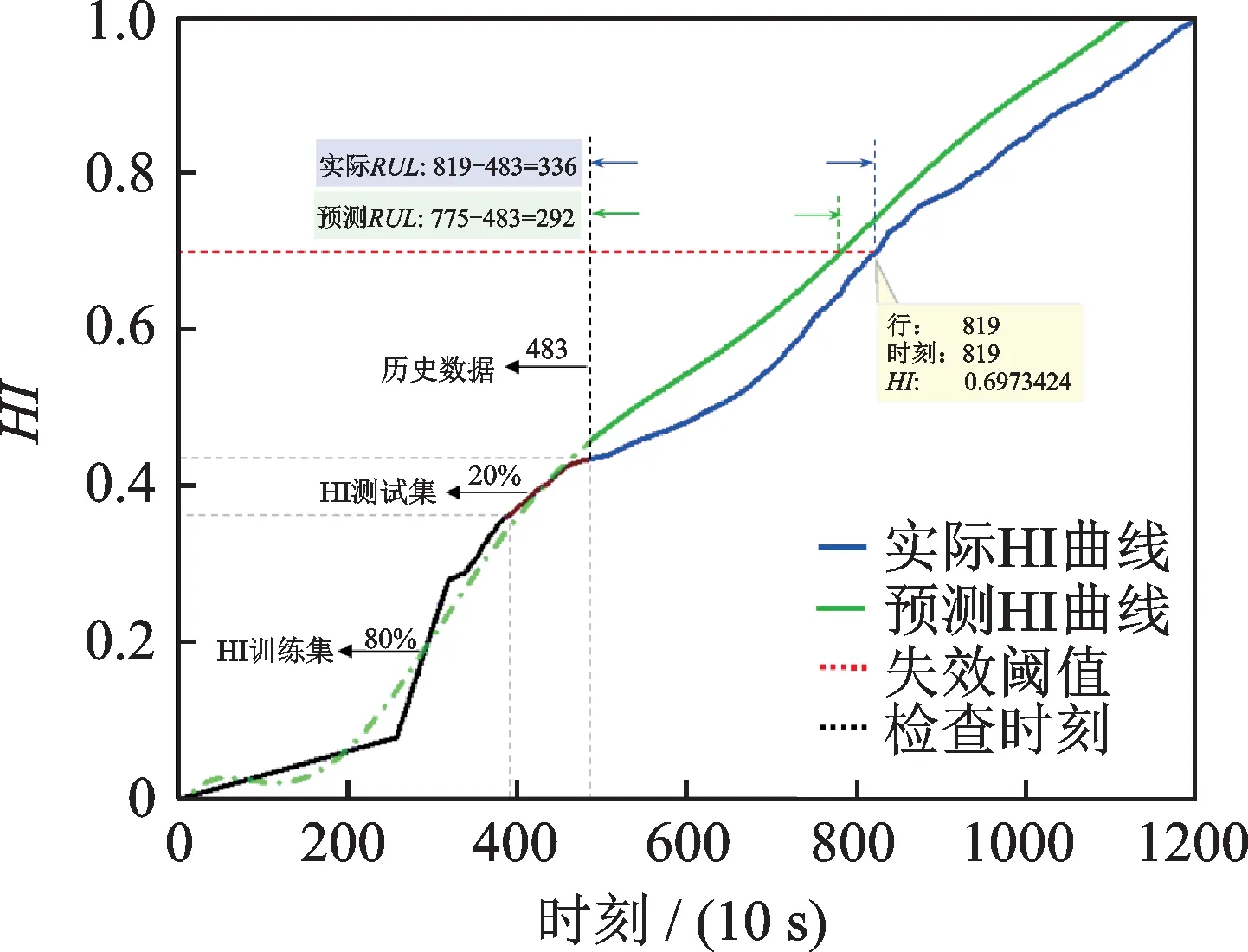
图15 轴承23#在检查时刻483 使用RVM 模型获得的预测结果Fig.15 Prediction results of bearing 23# at inspection time 483 with RVM model
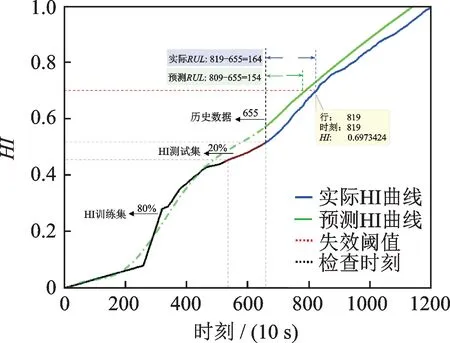
图16 轴承23#在检查时刻655 使用RVM 模型获得的预测结果Fig.16 Prediction results of bearing 23# at inspection time 655 with RVM model
3.4.3 RVM 模型的优越性
为了证明本文所提出的RVM 模型的优越性,以轴承23#的寿命 预测为 例,与SVM[14],BP[12]和PSO[13]等模型进行了对比。
在SVM 神经网络中,采用高斯核函数,将惩罚因子、核函数参数和不敏感系数分别设置为9,0.002和1;在BP 神经网络中,神经网络层数设置为3,神经元激励函数采用Sigmoid 函数,输入层、隐含层、输出层的各层神经元个数分别设置为10,14,1;在PSO 中,粒子数、惯性权重、学习因子等基本参数分别设置为50,0.5,1;对比模型的最大迭代次数、目标函数最小误差、失效阈值等参数均与RVM 模型一致。
分别对检查时刻T(326,483,655)(10 s)的预测结果进行计算,各模型的预测结果对比如图17~19和表4所示。
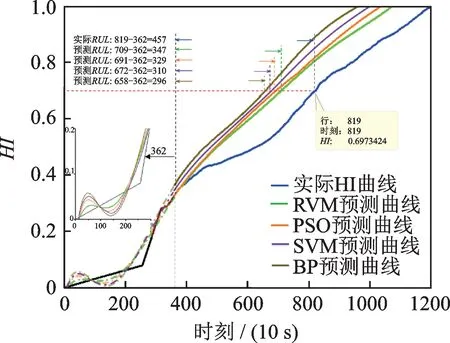
图17 轴承23#在检查时刻362 使用不同模型的预测对比图Fig.17 Comparison diagram of life prediction of bearing 23#using different models at inspection time 362
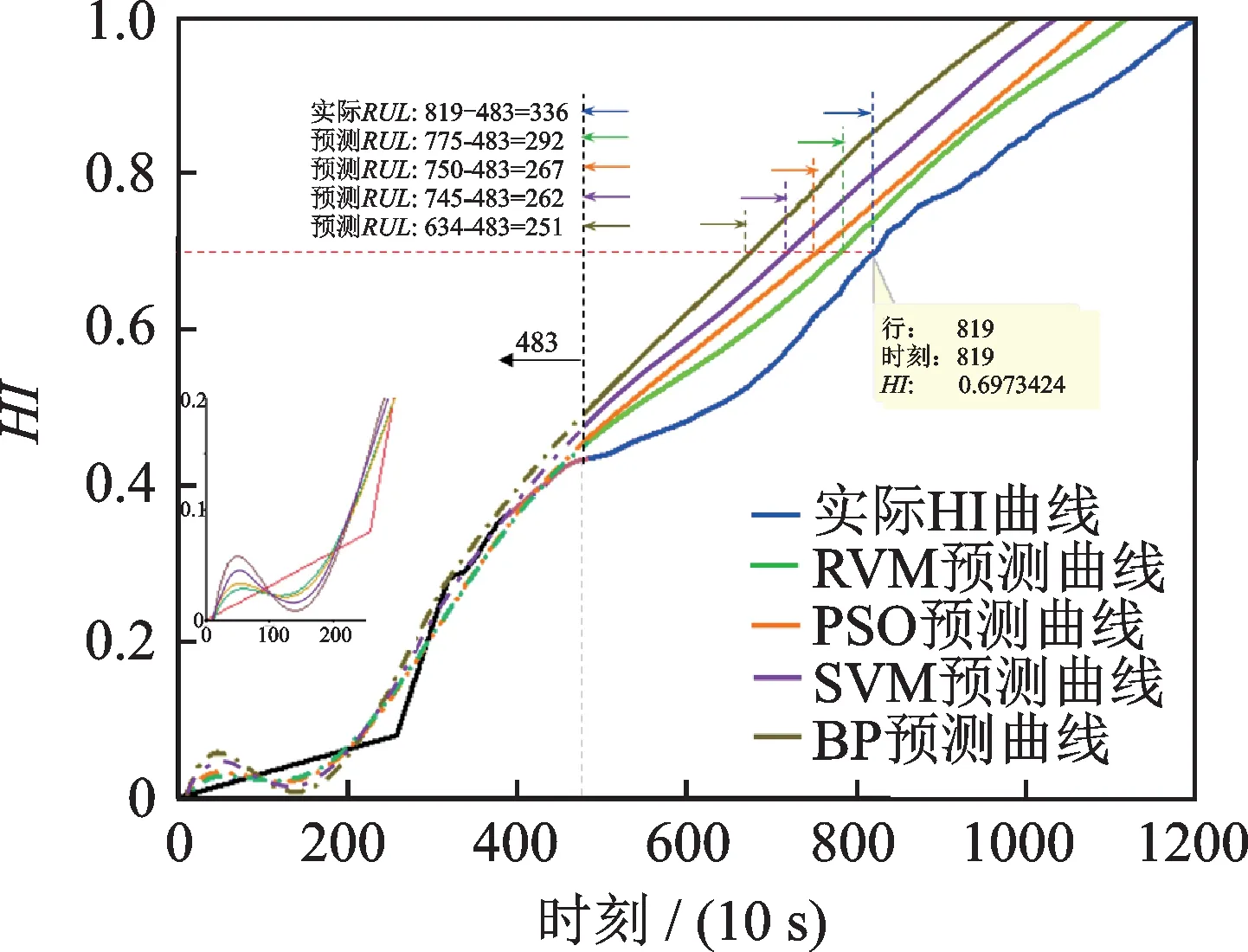
图18 轴承23#在检查时刻483 使用不同模型的预测对比图Fig.18 Comparison diagram of life prediction of bearing 23#using different models at inspection time 483
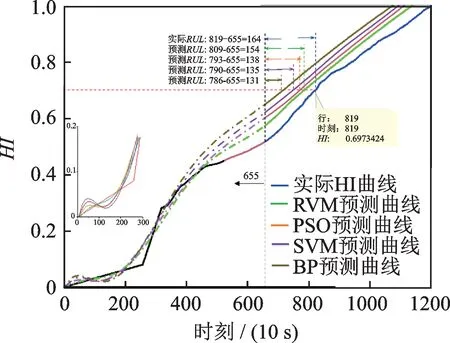
图19 轴承23#在检查时刻655 使用不同模型的预测对比图Fig.19 Comparison diagram of life prediction of bearing 23#using different models at inspection time 655
从图17~19 和表4 中可以看出,在所有对比模型中,RVM 取得了最好的性能。另外,在检查时刻T=6550 s 的情况下,PSO 方法也取得了不错的预测效果,这表明提高HI 的单调性有利于开展设备剩余寿命预测工作。
3.5 结果分析
为了证明本文所提出的LSTM-ES-RVM 方法的优越性,以轴承23#的全生命周期振动数据为例,与现有文献的方法进行了对比试验。其中,对比方法包括 CNN[21],LSTM[22],CNN-LSTM[23]和BD-LSTM[21]。本文分别计算了不同方法在运行时刻[655,819]之间的RUL 预测值,采用均方根误差(RMSE)指标进行评估,结果如表5 所示。从表5 的结果中可以看出,所提出的LSTM-ES-RVM 优于其他对比方法。

表5 轴承23#使用不同方法的均方根误差RMSE 比较结果Tab.5 The comparative result of root mean square error RMSE of bearing 23# using different methods
为了直观地分析各种方法的预测性能,本文绘制了各对比方法在运行时刻[655,819]之间的RUL 预测值的对比曲线和相对误差图,分别如图20 和21 所示。
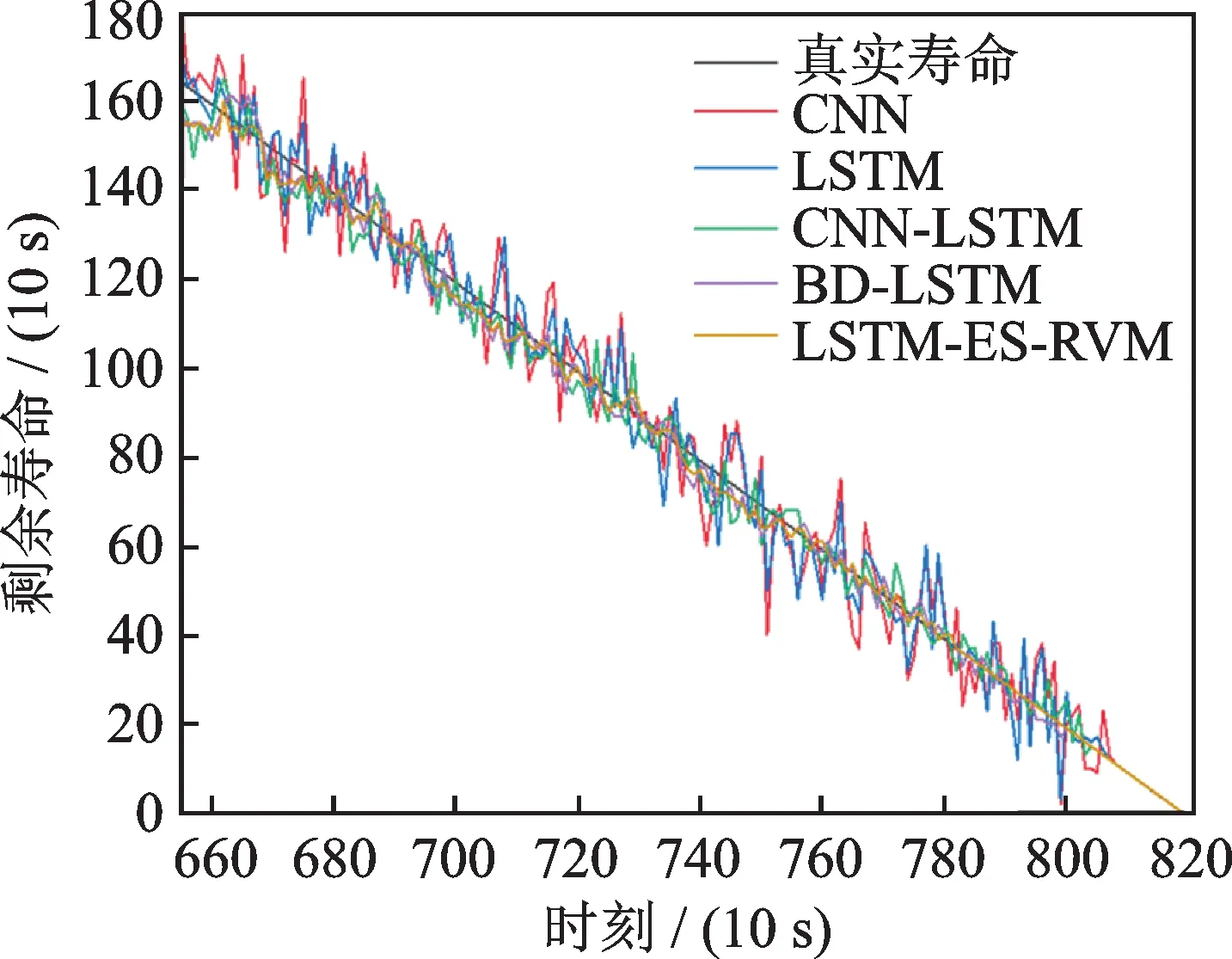
图20 轴承23#使用不同方法的预测结果Fig.20 Prediction results of using different methods of bearing 23#
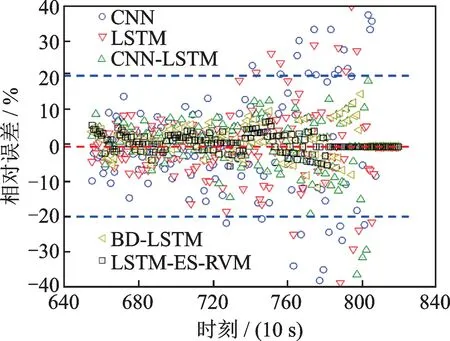
图21 轴承23#使用不同方法的预测结果相对误差Fig.21 Relative error of using different methods of bearing 23#
所有实验在Win10 操作系统环境下进行,硬件环境为Intel Core(TM)I7-7700 CPU-2.80 GHz 和16 GB 内存,表6 列出了轴承23#不同模型的计算时间。从表6 中可以看出,在单模型的运行时间中,CNN 的计算时间最短;而在多模型的运行时间中,本研究提出的方法计算时间最短。

表6 轴承23#不同模型的计算效率结果Tab.6 The calculation efficiency results of different models of bearing 23#
4 结论
本文提出了一种基于LSTM-ES-RVM 的滚动轴承剩余寿命预测方法。该方法减少了对人工经验和先验知识的依赖,改善了性能退化HI 曲线的整体单调性,提高了滚动轴承的RUL 预测精度。为验证本文所提方法,使用公开数据集(PHM2012)的实验数据进行验证,结果表明相较于文献中的其他方法,所提方法取得了最优的预测性能。
在未来的研究中,可以考虑找到一种有限数据集下自动识别失效阈值的方法,结合无监督深度学习的寿命预测模型,提高设备RUL 预测的自适应性。
猜你喜欢
新世纪智能(数学备考)(2021年11期)2021-03-08
新世纪智能(数学备考)(2020年11期)2021-01-04
物理之友(2020年12期)2020-07-16
幼儿画刊(2020年4期)2020-05-16
中学生数理化·高一版(2019年9期)2019-10-12
幼儿画刊(2019年2期)2019-04-08
福建中学数学(2016年7期)2016-12-03
光学精密工程(2016年1期)2016-11-07
小学阅读指南·低年级版(2016年4期)2016-05-14
电测与仪表(2016年6期)2016-04-11