
期刊论文支撑数据FAIR原则的应用评估与案例分析
2024-02-18 14:07刘桂锋王清炫韩牧哲
现代情报 2024年2期
刘桂锋 王清炫 韩牧哲










关键词:FAIR原则;期刊论文;支撑数据;数据管理;数据科学;应用评估;案例分析
随着大数据时代的到来,科学研究模式也发生改变,除了传统的实验科学、理论科学和计算科学,现在还出现了被称为“数据密集型科学”的第4种科学发现模式。海量的科学数据对多个学科领域的科研活动产生了深远的影响和显著的推动作用。随着科技创新的不断发展,系统化、可靠性高的科学数据支持变得越来越关键。如何对这些数据进行高效地管理和利用,成为促进各研究领域向好发展的重要因素。随着开放科学运动向纵深发展,科学数据逐渐占据与学术论文同等甚至更为重要的位置。科学数据是科研成果的重要产出,支撑学术论文的科学数据在科学研究活动中的地位越来越重要。
支撑论文结论的研究数据(Supporting Data,论文支撑数据或称为论文关联数据),是论文研究不可或缺的部分,是论文结论的验证基础,只有通过开放共享,才能保证论文结论得到客观检验、重复验证和可靠应用的保障。国务院办公厅印发《科学数据管理办法》、中国科学院的《科学数据管理与开放共享办法》等倡议作者将论文支撑数据开放共享。国外,许多期刊强烈鼓励或要求作者把论文支撑数据提交到公共平台共享。如SpringNature、Elsevier、Wiley等国际大型学术期刊出版商均推荐符合FAIR原则的存储平台,根据数据出版流程提出相应政策。期刊论文支撑数据的开放,必将对推动科学数据共享重用、数据引用和科研评价具有重要作用,也是治理学术环境和学术评价机制的重要策略。中国科学院文献情报中心主办的中文核心期刊《数据分析与知识发现》是我国图书情报学乃至社会科学领域实现研究论文支撑数据开放共享的先行者,该期刊出台了《论文支撑数据公共保存与共享暂行办法》,保障论文支撑数据的可靠检验、严谨和高质量,规范科研人员提交和引用数据的行为。通过初步调研发现,《数据分析与知识发现》期刊的支撑数据公共保存与共享策略与国际通用的促进科学数据共享和重用的FAIR原则有高度的领域契合性。因此,本文尝试结合FAIR原则构建指标体系,以《数据分析与知识发现》期刊的论文支撑数据为样例,对相关科学数据的开放共享模式进行分析和评价,并为社科类中文学术期刊的科学数据的共享和重用前景提出合理化建议与优化策略。
1相关研究现状
1.1FAIR原则研究概述
随着数据密集型时代的到来,开放共享和管理科学数据逐渐成为开放科学建设的核心。为解决科研数据领域的数据发现、访问、集成分析等问题,FAIR原则于2014年在荷兰莱顿的洛伦兹研讨会上被首次提出,并于2016年由FORCE11小组正式发布。此后,FAIR原则逐渐受到科研领域,尤其是科学数据开放共享和管理领域的关注。FAIR原则作为一套促进和确保科学数据可发现(Findable)、可访问(Accessible)、可互操作(Interoperable)和可重用(Reusable)的原则,推进其实施,对保障科学数据充分共享与重用,以及最大限度地发挥科学数据的价值具有重要意义。FAIR原则自被提出以来就成为国内外研究的热点,当前可将FAIR原则的相关研究归为FAIR原则理论研究和实践应用两个方面。
理论上,国内外主要对FAIR原则内容进行分析解析。邢文明等对FAIR原则进行解读,提出背景、内容、实施路径以及相关案例分析。邱春艳对欧盟推动FAIR原则的内容、实践路径进行调查。Boeckhout M等对FAIR原则在数据管理实践中面临的问题进行了阐述。Juty N等单独对FAIR原则中的F(可发现性)原则进行了详细分析。陈书贤等对国内外FAIR原则研究成果及应用现状进行了梳理。
实践应用上,我国FAIR原则的应用已拓展到科学数据管理平台、资源及领域数据库中。在现状调研方面,李楠楠等、李骐安等分别调研了国内外科学数据中心和科学数据资源的FAIR应用情况。戚筠等、李春秋等分别调研了生物信息学领域和医学领域数据平台的FAIR应用情况。在基于FAIR原则的出版控制方面,国内成果较少,目前仅见雷雪、孔丽华等在FAIR原则背景下分别对科技期刊数据出版现状、政策所做的分析。国际上FAIR原则的实践应用则更加广泛,目前,国外已有相关组织构建了FAIR数据评估的模型和方法,如FAIR Metrics Group制定14条指标评估FAIR化程度;研究数据联盟(RDA)设置FAIR成熟度模型,也制定一套通用的FAIR评估指标。同时,FAIR原则已充分应用到医学、生物科学、农业等多个学科领域并成立基于FAIR原则的数据管理项目,如Arefolov A等为临床实验生物标志物数据FAIR化开发数据管理方法:RDA在生物科学、农业领域分别成立专门的BDIIG和IGAD数据研究小组,促进生物、农业领域数据共享管理,确保数据可访问和可重用;Lannom L等将FAIR原则应用到生物科学和地球科学中,数字化处理生物/地球标本数据,实现无缝统一访问。
1.2FAIR原则评估框架现状
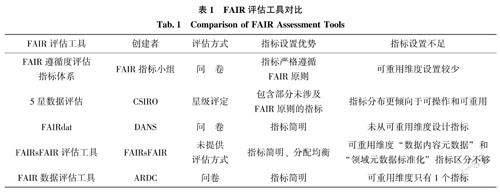
FAIR提供了通用的原则和指导,以确保数据达到最佳的发现和重用状态。在数据建设和管理过程中,要不断了解数据与FAIR原则的符合度,以便明确需要改进的方向。因此,建立明確、可识别、可测量且有通用性的评估指标非常关键。目前,国外已有研究机构开发出了FAIR指标评估体系,其中较具代表性的为:由FAIR原则的提出者等自主成立的FAIR指标小组在2018年提出的FAIR遵循度评估指标体系:澳大利亚研究数据共享组织(ARDC)提出的FAIR数据评估工具,从FAIR 4个维度进行了问题设计:荷兰数据存档与网络服务(The Dutch Data Archiving and Networked Services,DANS)于2017年发布FAIRdat评估工具,从可发现性、可访问性、可操作性3个维度设置指标;由澳大利亚联邦科学与工业研究组织(Common-wealth Scientific and Industrial Research Organisation,CSIRO)基于数据评级系统开发的5星数据评估工具,在所有问题完成后,会给出FAIR 4个维度的星级表示:基于成熟度理论的评估工具以研究数据联盟的FAIR数据成熟度模型(FAIR Data Ma-turity Model)为代表,并在此基础上衍生出FAIRs-FAIR数据对象评估指标。目前,我国尚无被广泛应用的成熟的FAIR指标评价体系。
综上所述,国内外对于FAIR原则的解读研究充分,在不同领域的实践也进行积极探索。随着FAIR原则不断推广,国内外期刊出版商发布论文支撑数据开放共享政策来促进数据FAIR化,期刊论文支撑数据是FAIR原则应用的重要领域,但相关研究不足,因此,为进一步掌握社科类中文学术期刊论文支撑数据的开放重用水平,本文以在实践领域有代表性的《数据分析与知识发现》期刊为例,结合已有的代表性FAIR评估模型,针对中文期刊论文支撑数据的独特属性,提出了针对中文期刊论文支撑数据开放性评估的FAIR指标评价体系。
2中文期刊论文支撑数据FAIR指标评价体系的构建
FAIR由可发现(Findable)、可访问(Accessi-ble)、可互操作(Interoperable)和可重用(Reusable)4个维度和15条具体细则构成,各细则相互独立、相互关联。经过预调研,发现期刊论文支撑数据集具有独特的属性。因此,需要根据数据集的特征,从FAIR的4个维度完善相关细则,设计新的评估指标体系。已有的代表性FAIR评估模型对于构建期刊论文支撑数据的FAIR指标评价体系有一定的借鉴作用。本文通过对FAIR遵循度评估指标体系、5星数据评估、FAIRdat、FAIRsFAIR评估指标和FAIR数据评估工具进行对比分析,综合考虑各评估工具的优势和指标设计特点。同时,针对《数据分析与知识发现》已公开的期刊论文支撑数据的相关特征以及自身对指标的理解,从各评估工具中选取部分指标,并对指标进行增加和调整,以确保指标的科学性和适用性,构建一个面向中文期刊论文支撑数据开放性评估的FAIR指标评价体系。
2.1FAIR原则评估框架对比
通过比较发现,除FAIRdat外,其余评估模型均从FAIR原则的4个维度设计了详细的评价指标:各工具没有对指标分配具体的权重,而是对FAIR原则进行了细化,主要差异是指标设计和评估方法。不同工具所提出的指标及评估方法各具特色,且有一定的互补性,如表1所示。虽然5个评估工具都提出了各自的FAIR指标评价方法,但是它们仅仅是评估模板,而不是固定标准。实施FAIR评估既要根据学科领域的发展情况、研究对象的特征,也要根据评估实施者对指标的理解来确定。为了更准确地评估期刊论文相关数据的FAIR应用情况,应根据自身对FAIR指标的理解以及数据特征,结合各评估工具的优势和特点,综合考虑评估方法、指标数量和分布等因素,构建一个新的评估指标体系。
2.2中文期刊论文支撑数据FAIR评价指标设计
在综合已有的FAIR指标评估框架的优势和特征的基础上,本文结合前期的案例调研,针对中文学术期刊论文支撑数据的相关特征,构建了期刊论文支撑数据FAIR指标评价体系,如表2所示。该体系以FAIR原则的四大维度延展,为提高可操作性将其细化至三级,设计过程中充分考虑了指标设计的规范性、适用性等要求。结合前期对中文期刊论文支撑数据的调研状况,对指标体系持续调整和完善,最终在可发现、可访问、可互操作、可重用4个一级指标下设计了10个二级指标和18个三级指标的多层次、多维度指标群。其中,从实际需求出发,在二级指标“标识符”下创设了三级指标“标识符能否正常解析”条目,在一级指标“可访问性”下创设了二级指标“访问时限”及其延展的三级指标“访问是否有时间限制”条目,使其在吻合FAIR原则的前提下,能够满足对中文学术期刊论文支撑数据的特色性评价需求。其余二级指标根据样本数据的特征,从已有的FAIR指标框架中进行抽取。而部分三级指标是在不影响原有含义的基础上,对指标进行微调或修改,把需要调研的内容更加贴合期刊论文支撑数据集的特征。比如将合规引用下的三级指标调整为关联到期刊论文和关联到相关数据集。表2列出了该评价体系对5个评估框架的借鉴情况,借鉴与否的决策主要基于对数据集调研结果和FAIR实施情况的综合考虑。
3数据来源与存储方式概况
3.1数据来源
从2022年3月20日起,《数据分析与知识发现》期刊要求所有被录用论文的论文支撑数据在稿件被录用后进行公共保存,并鼓励在此前被录用的作者参照《论文支撑数据公共保存与共享暂行办法》执行。目前,该刊是社会科学领域唯一对论文支撑数据开放明确要求且有一定数据储备的中文核心期刊,本文所研究的论文支撑数据样本就从该刊2022-2023年发表的论文中获取。
在本研究中,采用描述性和详细研究的方法,人工审查每一篇论文及其相关的数据集。发现该刊从2022年至今共发表195篇论文,其中16篇(8%)没有提供支撑数据;127篇(65%)论文将数据存储在私人空间中,并提供了作者邮箱:53篇(27%)论文公开保存了支撑数据。本文分析的样本即为这53篇执行了支撑数据开放共享的论文。
3.2期刊论文支撑数据的存储方式
经调研发现,在53篇论文中,5篇论文的支撑数据为公开的专业数据集:两个由明尼苏达大学Grouplens小组公开的影评数据集、1个为TREC临床決策支持跟踪数据集、1个由斯坦福大学公开收录的亚马逊数据集、1个是由清华大学公开的THUCNews新闻文本数据。4篇论文直接将支撑数据附录在论文最后。其余44篇论文将数据集存储在不同的数据共享平台中(有4篇论文涉及多个支撑数据集,其中3篇论文将部分数据集存储在科学数据银行,其余部分上传至Github,而另1篇论文则将其中一个数据集存储于Github,另一个数据集存储于百度网盘中,因此,表4中的以单条支撑数据统计的论文总数将超过44篇)。如表4所示,用于存储论文支撑数据的平台可分为4类,分别为科学数据存储平台(如科学数据银行),代码托管平台(如Github、Gitee),具有数据托管功能的社交网络平台(如CSDN),云存储平台(如百度网盘)。该期刊选择的数据存储平台应当满足数据长期保存、开放获取、规范管理利益相关者权益以及系统安全运行等要求,并遵循认证的国内国际规范,得到国家教育科研权威机构或国家科研与教育管理部门认可的国内公共保存平台,这些标准与FAIR原则的可发现性、可访问性、可操作性和可重用性相对应,如表3所示。然而,一些科研人员没有严格执行期刊要求,未将其论文支撑数据存储在符合期刊要求的平台中。
4期刊论文支撑数据FAIR原则应用现状分析
4.1可发现性
数据的可发现性是影响数据发挥其价值的重要因素,数据只有被用户发现,才有被使用、分析、组织的可能。支撑数据可发现性的两个重要指标特征包括唯一永久性标识符和元数据丰富程度。
4.1.1标识符
为数据(元数据)分配全球唯一永久性标识符是FAIR原则的重要部分。数字对象标识符(DOI)能够永久访问且有利于数据集的定位。如表5所示,科学数据银行采用了全球永久、唯一标识符标识数据集,其余平台均没有为数据集分配唯一永久性标识符,只提供URL,其中存储在Github的5个数据集已无法访问,用户点击URL却无法找到数据集所在的位置。
标识符能否正常解析也影响着数据的可发现性。由表5可知,科学数据银行中的DOI不能正常解析。通过DOI只能跳转到平台首页,却无法直接到达数据集的位置,需要在平台检索框內输人数据集名称、作者等元数据才可以找到该数据集。其余平台的URL在不失效的前提下可以正常解析。
4.1.2元数据丰富度
从表5中可以发现,5个存储平台中,只有1个(科学数据银行)自定义元数据元素且元数据较丰富,从标题、摘要、关键词、作者、学科、许可、关联出版论文等多个方面描述数据集.1个平台(CSDN)提供的元数据元素较少,主要从作者、标题、数据内容等方面描述数据集,Gitee平台为数据集提供数据贡献者、数据集名称、数据集简介等描述性元数据,Github平台上的数据集主要包含作者和标题两个元数据。Github和Gitee作为代码托管平台,所存储的数据集通常包含Readme说明文件,给数据集提供详细的介绍。而百度网盘主要用于个人存储和备份,无需提供丰富的元数据。
由此可见,科学数据银行作为专业的科学数据存储平台,赋予唯一持久性标识符(DOI),科研人员也为数据集提供丰富的元数据。相比之下,Github、Gitee和CSDN都是面向广泛的开发者、研发团队和企业的平台,主要用于版本控制、协作开发和代码共享等方面。尽管这些平台也支持数据集的存储和共享,但其定位并不是专门的科学数据存储平台,缺乏标识符申请的意识和动力。此外,数据集的元数据需要经过规范化和标准化处理,而这些平台的用户缺乏专业的数据管理知识和经验,因此在元数据描述方面有一定局限性。
4.2可访问性
当用户需要获取数据时,他们会考虑如何访问这些数据。为了保证数据的可访问性,需要在遵守访问协议的前提下,确保用户能够轻松地获取(元)数据。值得注意的是,可访问性并不意味着所有数据都必须公开,而是根据数据的性质确定公开的内容和时间。
由于存储在期刊网络版的科学数据、公共标准数据集和云存储平台(百度网盘)中的数据集可以直接访问,没有访问权限设置,因此,只对科学数据银行、Github.Gitee、CSDN 4个平台进行分析。
4.2.1访问协议
3类平台均支持HTTP协议访问和数据下载,如表6所示。HTTP是TCP/IP协议栈中的一种应用层协议,所有WWW文件都必须遵守其标准,而且各种技术信息都是公开且免费的。从这个方面来说,FAIR所要求的标准化访问协议环境已经得到了满足。此外,为了让用户更加方便地下载大数据文件,科学数据银行还提供了FTP协议服务。
4.2.2访问权限
访问权限既包括平台对用户的审核,也包括上传者对用户的审核。如表7所示,CSDN未提供用户审核机制,但需要用户注册账号并申请会员才可访问下载,对于营利性平台,其商业模式可能会对数据访问产生一定的影响,这可能会导致数据的访问受到限制或者需要付费,从而影响数据的开放访问。其余3个平台均提供用户注册审核机制,其中Github平台提供数据集的开放访问,用户无需注册即可免费访问数据集,科学数据银行声明用户注册账号后才能使用全部服务。而Gitee平台需要用户注册才能访问、下载数据集。除平台对用户的审核外,上传者可自定义获取条件并自行决定是否授予用户数据访问权限。对于存储在科学数据银行上的数据,用户若想下载此类数据文件须先填写《数据访问申请表》,作者通过该申请后,才可以访问下载数据文件。Github和Gitee平台具有访问权限设置,可以帮助用户控制代码和仓库的访问权限,数据上传者自行决定数据集是否允许其他用户访问。
4.2.3访问时限
科学数据银行为每个数据集分配了DOI标识符,旨在确保对科研数据的永久访问。但是,存储在科学数据银行中的6个数据集处于保护期,在此期间,数据集无法对外公开,只有在保护期结束后,用户才能访问该数据集。相比之下,其他平台和数据提交者并没有为数据集设置这种保护期。
4.2.4元数据的保存
随着时间的推移,数据集往往会消失或失去利用价值,即使数据不可再用,元数据也可以访问,因此元数据应保存到可靠、稳定且专业的存储平台中,并且提供元数据保存声明。目前有将近一半的数据保存在非专业的科学数据存储平台中,存储在代码托管平台中的数据最多,因此,下文分析科研人员将数据存储在代码托管平台和科学数据存储库中的原因及元数据保存声明,如表8所示。
3个平台都没有提供(元)数据保存声明。结合调研数据的内容及各类存储平台的服务特点发现,53篇论文中,有14篇论文的支撑数据含有代码,Github和Gitee是专门的代码托管平台,能够保证代码的安全,同时可以将代码和数据一起存储在同一个仓库中,并且可以与他人协作开发代码,而科学数据银行虽声明可以存放代码类型的数据,但在代码迭代、协作开发上有一定局限性。代码托管平台中有丰富的项目和技术支持,可提供给开发人员(包括科研人员)更多的资源和工具。此外,将代码或其他类型的数据存储到该类平台中有提升个人影响力的机会,数据点赞数/下载数越多,个人影响力越高。
4.3可操作性
可操作性指讓机器在访问、关联、集成不同来源的数据时,能够更加准确、顺畅地理解,从而为用户方便获取数据奠定基础。此外,可操作性还强调人类和机器对数据的交互与理解,以便更好地实现数据的利用和重用。
4.3.1合规引用
数据引用旨在建立数据与数据之间以及数据与文献之间的关联,进而促进数据的广泛交互。如表9所示,Github、Gitee、CSDN平台都没有提供明确的数据引用方式,只要求用户在遵守相应服务条款的前提下使用或引用数据,在一定情况下,经上传者同意后才能使用数据集。科学数据银行支持多种数据引用标准(如GB/T 7714-2015),用户可自行选择,并且提供了比较完整的引用信息,包括数据贡献者、数据集名称、上传时间、DOI等丰富的元数据信息。此外,公开标准数据集也提供引用方式,如明尼苏达大学Grouplens小组声明,在出版物中使用该数据集时,应当引用指定的论文。
在数据关联方面,科学数据银行以超链接方式将数据集关联至相关数据,包括数据集推荐阅读、数据参考资源,平台还将数据关联至外部数据,如关联出版论文。CSDN网站上存储的数据也具有数据集相关推荐。在Github和Gitee平台中,部分数据集中的Readme或txt说明文件含有相关数据集的URL。其中,Github、Gitee和CSDN平台并未将数据集关联至期刊论文,可能的原因是这些平台主要面向的是国内外的开发人员,而非专业的科研人员或科研组织,受众群体不仅限于科研领域,还包括其他行业领域人员。
4.3.2格式
文件格式会影响当前和未来软件“导人”数据集的能力,进而影响数据集的解释和理解。论文支撑数据基本存储于科学数据存储库和代码托管平台中,因此下文主要对科学数据银行、Github和Gitee平台上的数据进行分析。如表10所示,科学数据银行有明确的数据文件格式声明,为用户提供了一个表格,其中包括任何文件类型的“首选格式”,即用于长期保存数据的最佳文件格式及非首选格式。数据集以纯文本(txt)、数据表(CSV、xlsx)、文本文档(pdf、docx)、图片(jpg、png)和程序文件json等为主,txt、csv、json、xlsx文件中的数据多为用于计算分析生成论文直接结果的数据、用于结果分析的样本数据和原始数据,其中,一些xlsx文件中含有描述性统计分析后的结果数据和参数数据,pdf文件主要内容是统计分析后的结果数据,docx主要为说明文件。此外,1个支撑数据集包括原始图片类型数据集和经处理后的pickle文件,而pickle是Python中的序列文件,只能在Python中调用。根据数据文件格式推荐,docx并不是首选格式,pickle文件也不是开放数据格式,作者并没有完全按照“优先推荐格式”上传数据。
代码托管平台的本质是存储代码,而代码文件的格式通常是标准的格式,数据文件格式多种多样,因此,该类平台可能为了方便用户上传数据,未对数据格式有具体限制,论文支撑数据主要包括数据文件(纯文本(txt)、数据表(csv、xlsx)和图片(png))、Python语言的代码文件。其中,部分txt文件为说明文件。由此可见,不同类型的平台,即使所存储的数据格式相同,内容上却有所不同。
4.4可重用性
可重用是FAIR原则的目标,为了实现这一目标,需要充分描述数据,并在重用过程中明确知识产权,确保数据的可重用性。
4.4.1许可
如果数据使用规定不够明确,将会限制组织和个人对数据进行再利用。由表11可知,4个平台均提供数据使用许可。科学数据银行和Github均提供标准许可协议和自定义文本许可,Gitee和CS-DN主要为文本自定义许可,两种使用许可各有其特点。科学数据银行目前提供多种标准数据许可协议,包括CC(Creative Commons)通用许可协议、ODbl(Open Database License)等两种数据库许可协议,MIT(Massachusetts Institute of Technology)等12种软件许可协议,27个论文支撑数据集主要使用了CC通用许可协议。这类许可协议的特点在于,其条款内容严谨、清晰、应用范围广泛,既可用于整体数据的使用说明,也可应用到每个独立数据集上。该平台还自定义限制性获取许可协议,作者自定义数据获取条件。
Github提供MIT等标准软件许可协议,主要用于开源软件的管理,平台也自定义服务条款、免责声明、个人信息保护等使用条款,声明数据提交者可根据条款授予用户相关内容许可。相比之下,Gitee和CSDN是提供自定义免责声明、个人信息保护等使用条款,Gitee要求对于本站数据的任何使用请遵守数据集内容所附带的授权协议,以确保数据的合法使用。对于公开获取的数据集,如明尼苏达大学Grouplens小组也是自定义数据许可条款。自定义文本许可的优点是能根据平台、数据和数据提交者的需求制定具体内容。
值得注意的是,对于存储在代码托管平台上的论文支撑数据,作者将仓库公开后并未提供或申请使用许可,但通过浏览平台上的其他数据,发现大部分开发人员会为所提交的数据声明使用许可或申请标准许可协议,以维护数据产权。这种情况出现的原因可能有两个方面:首先,代码托管平台并非专业的科学数据存储平台,科研人员并未充分查看平台上的使用许可条款及内容;其次,科研人员对于软件等其他类型的标准许可协议可能不够清楚,而开发人员则可能会更加熟悉这些协议。
在限制声明方面,科学数据银行指出,数据提交者可自定义数据获取条件并自行决定是否授予用户数据获取权限,存储于科学数据银行的5个数据集处于保护期,并说明保护期限,但未提供具体的限制原因。Github和Gitee平台声明限制原因(将机密数据存储于私有仓储库中),平台允许数据上传者设置数据集为限制状态。可见样本平台对数据使用限制的声明一般是由数据提交者或平台限定。
4.4.2數据溯源
数据溯源为数据质量的评估提供了解决思路,数据溯源信息主要来自于数据上传者所发布的元数据。数据溯源信息一般包括数据发布和更新时间、数据提交者和联系信息,以及数据集访问地址、版本、元数据标准等。根据调研结果,科学数据银行为样本提供发布和更新日寸间、版本信息、作者和联系信息、访问地址,已具备了较完善的溯源信息。其余平台或网站仅提供数据提交时间和数据上传者及其联系信息。此外,平台均未声明使用标准溯源格式。由此可见,溯源信息和标准溯源格式未得到充分应用。
5中文期刊论文支撑数据FAIR原则推广策略
通过上述分析发现,FAIR原则在中文期刊论文支撑数据的应用仍需进一步完善,科研人员的数据共享意识及对于FAIR原则的认知度还远远不够。因此,本文从宏观和微观两个层面提出相应的对策与建议,旨在推进数据FAIR化,促进数据共享与重用。
5.1宏观层面的FAIR推进策略
基于本调研结果,有65%的支撑数据存储在个人空间。在27%的公开数据中,作者并未完全按照政策要求上传数据,可见科研人员对FAIR认知度不够,也不愿花时间根据FAIR原则描述数据。FAIR原则需要被推广、认可、接受和应用。因此,从宏观层面提出以下4点FAIR推进策略。
5.1.1宣传推广FAIR原则
虽然欧美国家(地区)的许多研究机构对FAIR原则进行了宣传和应用,但迄今为止,大多数科研人员对该原则并没有清晰的认识。一项由洛桑联邦理工学院研究团队于2019年进行的调查显示,受访的学术界人士中,有62%的人表示对于FAIR数据的期望程度不确定或不了解。应充分利用社交媒体、举办主题讲座或研讨会等多种形式进行宣传,针对不同群体制定不同的推广策略,如对于科研人员,重点宣传FAIR原则理念及如何遵循该理念管理提交数据等,可以邀请研究FAIR原则的知名学者通过线上或线下的方式开展培训课程和研讨会议,科研人员要积极参与,学习如何处理、存储、共享、规范使用数据,从而提高其在科研数据管理、发布、共享和重用方面的能力和素养。
5.1.2建立激励机制
我国的《科学数据管理办法》中明确提出“谁开放,谁受益”的理念,政策制定者应该建立激励机制,鼓励研究人员将数据存储在符合FAIR标准的受信任的专业存储库中,并使用现有的符合FAIR标准的数据资源。此外,FAIR数据也应该被视为核心研究成果,将其纳入职业发展评估和研究贡献中。这将有助于提高科学数据共享的意识和重要性,进一步推动科学研究的可持续性发展。为了支持FAIR数据,提供基础设施和服务的机构与人员也应该得到认可和奖励。
5.1.3FAIR原则融人数据政策
目前,我国已开始高度重视科学数据管理与共享领域的政策的制定和完善,但仍缺乏国家层面对于FAIR原则开展的政策支持。我国政策制定者应根据当前数据资源的发展态势,适当增加FAIR原则的相关内容,培养用户将数据FAIR化的意识和素养。宏观上,可将FAIR原则增加至《科学数据管理办法》等国家层面的政策,将其贯穿数据政策的全流程,强制要求科学数据在提交、存储、开放过程中保证可发现、可访问、可操作和可重用。微观上,期刊出版机构等利益相关者可以制定FAIR数据政策,以确保数据共享和重用,也可以根据FAIR原则的各个要素以及机构的发展规划来制定并及时调整数据政策,以促进数据的管理、共享、标准化、可视化和溯源。
5.1.4凝聚FAIR利益相关者
FAIRsharing是一个由社区驱动的数据资源平台,聚集了众多的利益相关者群体。该平台为不同的利益相关者群体制定了不同的FAIR原则实施策略。在国内尚未出现类似的平台,相关社会组织应积极联系利益相关者,一方面为数据消费者提供指导,帮助其发现、选择和使用所需的资源;另一方面,帮助数据生产者使其资源易于被发现并得到广泛使用。
5.2微观层面的FAIR应用建议
5.2.1可发现维度的建议
1)制定标准元数据框架
根据调研结果,科学数据银行的元数据丰富度较高,大大提升了数据被发现效率,因此与我国科技期刊合作的数据存储平台应继续丰富元数据元素,如数据采集目的、数据分析处理说明、数据提交者、创建过程等,提供从数据格式等基本信息到描述信息、关联期刊论文信息、溯源信息等元数据,促进数据发现,辅助数据使用者理解数据集的背景及数据集的创建过程。元数据元素应基于标准元数据框架并结合学科和数据集特点设计,并以RDF格式来标识元数据。对于非专业存储平台,虽然不以存储数据为主,但也支持数据集的储存和共享,平台可以面向用户和管理人员增设数据管理知识培训板块,便于用户提交丰富的元数据。
2)确保数据标识符可正常解析
拥有DOI标识符并不能保证顺利找到数据集,只有在成功解析DOI后才能够找到数据集所在的位置。基于本调研结果,科学数据银行存储平台中的DOI不能正常解析,因此,存储论文相关数据集的平台应确保用户能动态解析数据标识符,从而获取数据集的URL,减少数据集无法找到的可能。为了保证标识符的可靠性与准确性,应定期对DOI进行更新与维护。此外,即使是非专业的数据存储平台,也可以加强其DOI的申请意识,确保数据可永久发现。
5.2.2可访问维度的建议
1)将数据提交于专业的存储平台
存储方式影响(元)数据的长期访问。基于调研结果,将近一半的数据存储于非专业的平台。建议研究人员将数据存储于符合FAIR标准并经过认证的通用数据存储库或特定领域的数据存储库中,避免将数据上传于非专业存储平台。科学数据银行(www.scidb.cn)已进行了很好的实践,通过国际认可并提供了优质的数据共享平台。期刊出版商也可以采取奖惩措施,例如,对于正确上传数据的作者,期刊可以提供额外的奖励,优先发表或者优秀论文评比将优先考虑。这样的做法可以激发作者上传于专业平台的积极性,同时也可以提高数据共享的质量和访问效率。
2)制定元数据保存政策和实施方案
数据平台能够长期稳定发展的重要因素是数据长期保存政策的发布与实施,这意味着已经建立了较为完善的数据保存体系。科学数据银行仅简单说明数据可长期保存,并未提供(元)数据保存政策与声明。相比之下,国外数据存储库更倾向于发布更为清晰明确的数据长期保存政策。因此,建议未来期刊和科学数据存储库均制定更明确的(元)数据保存政策和施方案,借鉴国外的数据保存政策条款,优化数据保存体系。
3)完善平台服务功能
基于调研结果发现,用户的学科领域、专业技能、行为习惯是影响选取数据存储平台的可能原因。因此,数据存储平台可针对不同领域的用户进行细分,从而提高针对性的数据服务,比如科学数据银行可为计算机领域的科研人员设置代码协作开发功能,也可以提供相关的技术支持与指导,或增添第三方链接,将其关联至代码托管平台,以满足用户协作开发代码的需求。
5.2.3可操作维度的建议
1)规范数据生产使用行为
目前,科研人员并没有完全按照平台中的“优先推荐格式”上传数据,而非专业存储平台只要求用户遵守相应服务条款并在某些情况下获得上传者的同意来使用数据集。科研人员既是论文支撑数据的生产者,亦是数据的消费者。因此,研究人员应规范数据管理流程,明确并使用相关的数据标准和学科标准。在数据生产提交过程中,要按照相关标准提交相应数据,无论在哪个存储平台使用他人研究数据集,都要注意引用的规范。当涉及隐私或机密数据时,应及时与相关人员联系,征询许可。期刊可以优化作者投稿的数据准则,发布数据可用性声明提高数据的透明度,使科研人员更易遵守数据管理要求。
2)使用开放数据格式
数据平台应当采用国际认可的可靠数据文件开放格式,以支持集成异构数据集的需求。相比于专有格式数据文件,开放格式文件具有更好的用戶支持、可读性和兼容性,能够更好地支持机器互操作和数据集成。根据本调研结果,上传于科学数据银行中的数据格式并非都是开放数据格式,并且对于不同类型的平台,即使所存储的数据格式相同,但内容上却有所不同。因此,平台应继续完善开放数据格式的设置,并加强用户上传数据的限制,对上传数据格式进行验证,以提高数据的质量和可用性,也可以考虑提供数据文件格式转换的功能,此外,其余平台可借鉴科学数据银行中的数据文件预览功能,方便用户快速查看数据文件的格式和内容。不同类型或领域的平台应根据自身特点提供合适的开放数据格式推荐表。
3)开发关联技术和FAIR基础设施
基于本研究调研结果,科学数据银行的数据关联能力较强。为了更好地实现科学数据的被理解和使用,我国专业的科学数据存储平台应加强关联技术的开发与应用,通过使用关联数据发布元数据来促进互操作性。为了促进数据的语义化表达和提升机器可处理能力,平台应以开放的、机器可理解的方式发布数据,例如考虑应用RDF词表来发布关联数据。存储平台、社会组织也可以邀请技术方面专家和其他利益相关者进行指导,积极参与FAIR基础设施的开发,如开发出符合FAIR原则的规范数据管理软件,增强数据的可理解性。
5.2.4可重用维度的建议
1)明确数据许可声明
若数据集的访问和重用声明不明确,将会限制用户合理使用该平台的数据集,从而阻碍数据的重用。因此,为了方便机器和用户的理解和解释,使用标准的、机器可读的许可证非常重要。科学数据银行为数据提交者提供多种类型的标准许可协议,以确保数据的合法使用和重用。基于本调研结果,数据平台需高度重视参考标准的、机器可读的重用许可声明,在元数据中包含使用适当元数据元素表示的许可信息,在必要时设置保护期限并说明原因,对数据进行分级分类,明确不同数据的使用权限,并做出详细说明,帮助用户更好地理解数据使用的权利和义务,减少因数据权导致的数据重用纠纷。
2)采用机器可读的溯源格式
根据调研结果显示,数据存储平台的标准溯源格式和溯源信息未得到充分应用。溯源信息对于评估数据集在特定应用情境中的适用性具有重要作用。提供准确、丰富且机器可读的溯源信息可以为科研人员或机器评估数据集提供必要的凭证和支持。科学数据存储平台应提供机器可读的溯源信息,使用标准的溯源格式,进一步丰富数据集的工作流程、数据处理说明、数据生成设备等信息。非专业存储平台也应该完善数据溯源信息,以帮助不同类型的用户了解各类数据集的特征,从而更好地理解和使用数据。
6结语与展望
本文在国外FAIR原则评估模型的基础上,结合《数据分析与知识发现》期刊论文相关的科学数据特征,构建FAIR原则评估指标体系,基于该体系从4个维度分析调研结果,最后从宏观和微观两个层面提出FAIR原则应用建议。本研究局限于调研样本数量,调研结果对于反映中文社科类期刊论文支撑数据FAIR应用的总体情况有一定局限。但是本研究构建的中文期刊论文支撑数据FAIR指标评价体系及基于该调研结果提出的FAIR应用建议对我国期刊论文支撑数据的共享重用有一定借鉴意义。未来,关于FAIR原则的应用需针对FAIR实施中存在的问题提出具体措施。此外,我国期刊论文支撑数据FAIR应用需结合数据生命周期进行管理,继续完善相关政策制度和标准体系,进一步推动数据FAIR化。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年5期)2022-04-02
海洋信息技术与应用(2021年2期)2021-11-02
铁道通信信号(2020年4期)2020-09-21
科教导刊(2016年27期)2016-11-15
科技资讯(2016年18期)2016-11-15
语文教学之友(2016年9期)2016-10-08
中国科技期刊研究(2016年11期)2016-04-17
图书馆理论与实践(2015年7期)2016-01-19
重庆开放大学学报(2015年4期)2015-12-23
