
基于全局与局部感知网络的超高清图像去雾方法
2024-04-09 01:41郑卓然魏绎汶贾修一
智能系统学报 2024年1期
郑卓然,魏绎汶,贾修一
(南京理工大学 计算机科学与工程学院, 江苏 南京 210094)
带有雾霾的图像具有低对比度和模糊的特性,这会严重影响下游图像处理模型的表现,例如行人检测、图像分割等。对此,大量的单幅图像去雾方法被开发出来,它们的目的在于把输入的带有雾霾的图像转换成一张清晰图像。然而,伴随着移动设备和边缘设备对分辨率为4 k图像处理方法的需求的不断增长,现存的图像去雾的方法很少能高效地处理一张带雾的超高清图像[1]。
对于传统算法来说,大量的研究人员专注于雾霾和环境的物理性质,他们采用各种清晰的图像先验来规范解空间,但这些方法通常需要复杂的迭代优化方案才能找到最佳解。而且,这些手工制作的图像先验知识的复杂性远远不能满足实际应用的要求。例如Tan[2]开创了在没有任何额外信息的情况下在单图像实现去雾的可能性。He等[3]使用暗通道先验(dark channel prior, DCP)借助统计学来估计图像的雾霾以实现图像去雾。Zhu等[4]提出了颜色衰减先验,通过估计场景深度来消除雾霾。Berman等[5]观察到,无雾图像的颜色可以很好地近似为RGB空间中形成紧密簇的数百种不同颜色,然后基于这一先验知识提出了一种去雾算法。Chen等[6]提出了一种改进的评价彩色图像去雾效果的方法。该方法考虑了对图像边缘信息的评估以及对颜色失真的评估。
最近,基于CNN的方法已被应用于图像去雾,并且与传统方法相比取得了显著的性能改进。早期的算法[7-9]使用可学习的参数代替传统框架中的某些模块或步骤(例如估计透射图或大气光),并使用外部数据来学习参数。从那时起,更多的研究使用端到端的数据驱动的方法来消除图像雾化[10-14]。例如,Cai等[7]提出了DehazeNet来生成端到端的传输图。Zhang等[15]将大气散射模型嵌入到网络中,允许CNNs同时输出传输图、大气光和去雾图像。GandelSman等[11]借助于图像先验知识提出了一种无监督的图像去雾方法。Chen等[16]在合成数据集中预先训练了去雾模型,之后使用无监督学习方法使用各种物理先验微调网络参数,以提高其在真实雾霾图像上的去雾性能。还有一系列研究放弃了传统的物理模型,并使用直接的端到端方法来生成去雾图像。Li等[8]设计了一个AOD网络,通过重新制定的大气散射模型直接生成去雾图像。Qu等[14]将去雾任务转换为图像到图像的转换任务,并增强了网络以进一步生成更逼真的无雾图像。尽管基于CNN的方法已经取得了最先进的结果,但它们通常需要堆叠更多的卷积层才能获得更好的性能,从而导致在资源受限的设备上计算成本过高。
除此之外,基于MLP的方法已被应用于图像增强任务,例如图像超分辨率[17-18]、图像去噪[19]和图像去雨[20-21]。与CNN相比,这些方法在低运算量的基础上取得了更好的视觉效果。不幸的是,目前基于MLP的方法有2个主要限制。首先,上述方法将图像划分为多个块,以捕获图像上的全局感受野,导致图像像素之间的空间拓扑信息丢失;其次,图像去雾是一个高度不适定的问题,因此需要大量的MLP层或一些注意力机制来重建更好的高频细节。为此,这些结构和模块的大量堆叠会严重增加计算负担。例如,Uformer结构[22]只能使用24 GB RAM处理一张360×360分辨率的图像。
针对上述存在的问题,本文提出了一种不带有图像补丁的全局和局部感知网络。其中,全局感知网络基于MLP-Mixer的设计原则,在多尺度框架中捕获图像的全局特征。此外,局部信息的抽取使用U-Net来捕捉图像的局部特征以弥补全局信息建模的不足。最后,通过融合全局和局部特征图生成一个高质量的系数张量,它用于输入图像的仿射变换。值得注意的是系数张量可以看作是一种注意力机制,它表示了带雾图像的局部区域应该有相似的变换。经过大量的实验分析表明,所提出的用于UHD图像去雾任务的全局感知网络具有两个优点:1)该模型能够有效地建模出图像的全局特性,同时保留了图像上的元素之间空间拓扑信息。2)全局特征和局部特征相辅相成,协同产生一张高质量的超高清去雾图像。本文算法有能力在单个24 GB RAM的RTX 3 090上以110 f/s的速度处理一张4 k分辨率的图像,并实现最佳性能。值得注意的是该模型在4KID数据集中的峰值信噪比指标达到了26.99 dB。
1 全局和局部感知网络的结构
图1给出了4 k分辨率图像去雾网络的架构,该网络主要由两个分支网络组成,一个全局信息提取网络和另一个是局部信息提取网络。

图1 全局和局部感知网络框架Fig.1 Framework of global and local aware network
1.1 全局信息提取
传统的基于MLP的图像重构模型需要将图像分割成若干个块再进行特征抽取,这无疑会丢失图像的空间拓扑信息。灵感来自于MLP-Mixer的设计原则,本文设计了一个空间MLP混合器(spatial-MLP-mixer,SMM)。具体来说,SMM将完整的特征图X作为输入,其中特征图X的长度域,宽度域和通道域分别为H、W和C,X∈R(C×H×W)。然后分别使用相同的投影矩阵和激活函数以“滚动的方式”对一张图像的宽度域、长度域和通道域进行非线性的投影。混合器块由尺寸相等的多层MLP组成,每层由3个MLP块组成。第1个块是图像的宽度混合MLP,它作用于X的行,映射RWRW,并在所有行之间共享。第2个块是图像的长度混合MLP,它作用于X的列(即它应用于转置的输入XT),映射RHRH,并在所有列之间共享。第3个块是图像的通道混合MLP:它作用于X的通道维度,映射RCRC,并在所有通道之间共享。每个MLP块包含两个完全连接层和一个独立应用于输入数据张量每个维度的非线性层。具体如下:
其中:L表示层归一化,S是 Sigmoid函数,ω表示全连接层参数。该结构的整体复杂性在图像中的像素数上是线性的,这与ViT (vision transformer)不同,ViT的复杂性是二次的。SMM可以通过“滚动”提取图像的空间域信息进行长范围依赖建模以更好地恢复图像的颜色与纹理信息。
除此之外,多尺度特性也被考虑。多尺度特性是空间MLP学习高分辨率(high resolution,HR)图像的高质量特征的关键。为了实现更多的跨分辨率特征交互,在SMM开始时以不同的尺度插入交叉分辨率特征信息。为了帮助低分辨率(low resolution, LR)特征保持更多图像细节和准确的位置信息,该算法把低分辨率特征与高分辨率特征融合。HR路径在LR路径中增加了更多的图像信息以减少信息损失,并增强了反向传播过程中的梯度流,以促进LR变换模块的训练。另一方面,将LR特征合并到HR路径中,以帮助模型获得具有更大感受野的抽象层次的特征。具体来说,该网络有3种规模(256、128和64)的多尺度SMM,框架与HRNet相同。它始终保持高分辨率表示,以获得空间准确的全局特征图。通过迭代融合由HR和LR子网络生成的特征来合成可靠的高分辨率特征。所有的图像下采样和上采样的方式都使用了双线性插值。
1.2 局部信息提取
为了进一步增强模型生成一张清晰的超高清去雾图像的能力,该模型引入了图像的局部信息提取网络。该网络首先将4 k分辨率带雾输入降低到256×256的固定分辨率(双线性插值的方法),然后由U-Net获取其局部特征图。U-Net添加了一个3×3卷积层,将解码器最后一层的通道数从64映射到3。局部提取模块通过堆叠卷积层和池化层,可以更好地关注图像中的局部信息关系以消除冗余的特征信息。
此外,图像局部信息的抽取可以用于恢复清晰的边缘特征,这些特征可以通过依赖图像的短距离依赖进行恢复。如图2(b)所示,本地信息提取模块的输出图像具有更清晰的边缘。相比之下,图像的色彩信息不能仅根据该像素及其附近像素的色彩信息进行恢复,还需要考虑全局的长距离依赖才能正确恢复图像颜色。因此,通过SMM来提取图像的长距离依赖色彩空间信息,以更好地恢复图像颜色。如图2(a)所示,全局信息提取模块更侧重于图像的颜色特征。

图2 全局和局部分支归一化特征结果Fig.2 Results of normalized output feature maps of the global and the local branches
2 实验与结果分析
在本节中,通过对合成数据集和真实世界图像进行实验来评估所提出的方法。将所有结果与9种先进的去雾方法进行比较:AOD[17]、PSD[16]、DCP[3]、CAP[4]、NL[5]、GCANet[23]、MGBL[1]、FDMHN[24]和PFFNet[25]。此外,还进行消融研究,以表明该网络在图像去雾任务上每个模块的有效性。
2.1 评价指标
为定量的评估去雾算法的表现,本文使用了峰值信噪比P和结构相似性H作为评估指标,其中K表示最大值,E表示方差。
H表示干净图像与噪音图像之间的均方差。
2.2 数据集
训练数据集总共包含13 136张雾化/真实图像。它包括来自4KID的12 861张包含建筑物、人物、车辆、道路等的图像和来自I-HAZE的25张室内场景图像和来自O-HAZE的40张室外场景图像进一步扩充了数据的多样性。相应地,实验对来自4Kdehaze的200张图像,来自I-HAZE的5张图像和来自O-HAZE的5张图像进行测试。
2.3 实验细节
该模型是使用PyTorch 1.7实现的,网络是使用AdamW优化器训练的。在这种情况下,一张分辨率为512×512的图像作为输入(输入到模型后会借助双线性插值被强行下采样到256×256的分辨率),并使用8的批量大小来训练网络。初始学习率设置为0.001。整个模型的使用了50轮次的训练。
对于DCP,将窗口大小设置为60×60用于测试。对于去雾模型PSD,GCANet和FDMHN,它们分别在4KID、I-HAZE和O-HAZE数据集上进行微调。网络使用AdmaW优化器进行训练,学习率为0.000 1。特别是对于PSD,本文使用作者提供的PSD-MSDBN模型系数进行微调。此外,对于AOD、PFFNet和MGBL,应用Adam优化器并将学习率设置为0.001以训练网络。对于去雾算法NL,灰度系数γ设置为1进行测试。
2.4 实验结果
所有方法都在3个数据集上进行评估,即4KID、O-HAZE和I-HAZE数据集。图3和图4中给出了在4KID数据集中的一张分辨率为4 k的图像和I-HAZE数据集中的一张图像的对比结果。可以观察到,传统的基于物理的方法(NL、DCP、CAP)倾向于过度增强结果,导致颜色失真。最近的深度模型(GCANet、FDMHN、AOD、PFFNet、MGBL)由于缺乏全局建模能力,结果中仍然存在一些模糊。虽然PSD的结构相似性优于本文算法,但局部与全局感知网络可以更快地处理分辨率为4 k的图像并获得更好的色彩结果。图3(k)、4(k)中局部与全局感知网络法生成的去雾结果接近图3(l)、4(l)中的真实无雾图像。表1表明了本文方法的有效性。同时,在同一台具有NVIDIA 24GB RAM RTX 3 090 GPU的机器上评估所有深度模型。运行时只是GPU的处理时间,不考虑I/O操作。4KID、I-HAZE和OHAZE数据集的平均运行时间如表1所示。传统方法(NL、DCP、CAP)需要解决复杂的函数,这不可避免地增加了计算成本。虽然一些轻量级网络(FDMHN、AOD、PFFNet、MGBL)可以实时消除分辨率为4 k的图像的雾霾,但它们的性能不如本文模型。此外,虽然一些大型网络(GCANet、PSD)实现了更好的性能,但它们无法实时去除单个分辨率为4 k的图像的雾霾。
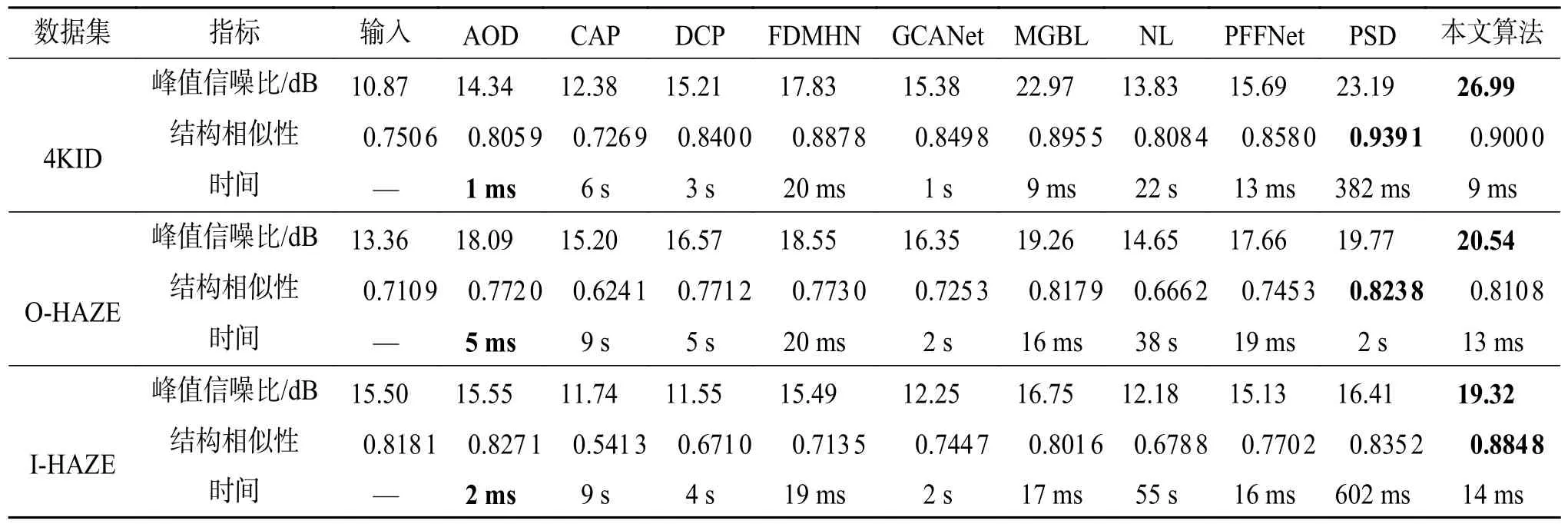
表1 4KID、I-HAZE和O-HAZE数据集上的定量评估Table 1 Quantitative evaluation of the 4KID, I-HAZE and O-HAZE datasets

图4 在I-HAZE数据集上的测试结果Fig.4 Dehazed results on the I-HAZE dataset
然后,在真实世界的带雾图像上评估所提出的算法。首先,在真实捕获的4 k分辨率带雾图像上与不同的先进方法进行比较。图5给出了两张具有挑战性的真实世界图像的结果的定性比较。如图所示,DCP使去雾结果中的某些区域变暗,CAP和PSD遭受颜色失真,而AOD、GCANet、MGBL、FDMHN和PFFNet生成的结果有一些残留的雾霾。相比之下,本文算法能够生成逼真的颜色,同时更好地消除雾霾,如图5(j)所示。

图5 在真实4 k分辨率图像上的去雾结果Fig.5 Dehazed results on real-world 4 k resolution images
除了4 k分辨率图像,在其他公共数据库下载的几个低分辨率带雾图像上评估了超高清去雾算法与其他的对比方法。去雾结果如图6所示。可以看出,除本文之外的所有型号都存在颜色失真。相反,本文方法可以更好地消除雾霾并有效地产生逼真的色彩。

图6 在低分辨率图像上的去雾结果Fig.6 Dehazed results on low-resolution hazy images of real-world
为了检验SMM的有效性,全局与局部网络还与SwinIR[19]和MLP-Mixer[26]进行了比较。所有3个模型应用大致相同数量的参数。SwinIR和MLP-Mixer都需要将图像分割成块,导致空间拓扑信息的丢失和模型的图像增强能力的降低。此外,SwinIR对Transformer的使用增加了其计算能力但减慢了模型的速度。如图7所示,MLP混合器产生了模糊的结果,图像中存在可见的斑块,而SwinIR的输出不能完全消除雾霾,并且存在颜色失真。但是,本文提出的SMM能够更好恢复纹理和颜色。值得注意的是,对于大致相同数量的参数,SMM是最快的,而SwinIR是最慢的。

图7 空间MLP混合器、MLP混合器以及SwinIR效果对比Fig.7 The results of spatial MLP-mixer, MLP-mixer and SwinIR
2.5 消融实验
为了表明所提出的网络中引入的每个模块的有效性,进行了一项消融研究,涉及以下3个实验:全局分支的有效性,该模型移除了全局特征提取分支并直接回归图像以获得最终输出;局部分支的有效性,该模型移除UNet,直接将图像回归到多尺度空间MLP混合器中,以获得最终结果;多尺度的有效性,比较了分别使用单一尺度和两个尺度的效果,同时保持相同数量的参数。
如表2和图8所示,局部分支依靠图像的局部特征,在两个指标上取得了较好的结果,但其颜色恢复能力仍然不足。仅使用全局分支并不能给出令人满意的结果,但其更好地提取全局信息的能力可以增强局部分支对图像颜色的恢复。值得注意的是,对不同尺度的SMM进行消融实验时,该模型为单尺度和双尺度SMM堆叠了更多的MLP层,以达到与多尺度SMM相似数量的参数。显然,出色的多尺度性能是由于多分辨率图像提供的丰富细节。
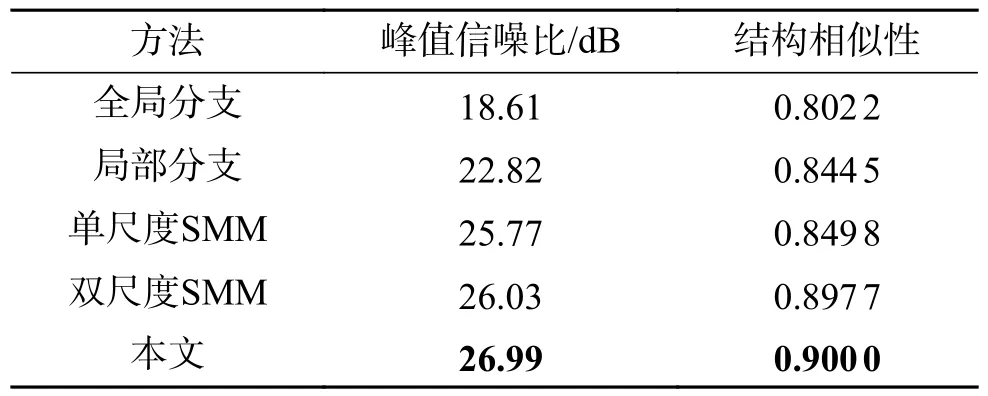
表2 全局分支、局部分支以及多尺度的消融实验Table 2 Ablation studies of global branch, local branch and multi-scale

图8 在低分辨率图像上的消融结果Fig.8 Dehazed results on low-resolution hazy images
3 结束语
本文提出了一种具有全局和局部感知的超高清分辨率图像去雾的新模型。该模型的关键是使用全局特征提取分支的空间MLP混合器。空间MLP混合器可以帮助模型从超高清分辨率的 (4 k)图像中恢复颜色特征。使用局部特征分支来恢复高质量的细节特征,为图像去雾提供丰富的纹理信息。定量和定性结果表明,该网络在准确性和推理速度方面与先进的去雾方法相比更好,并在真实世界的4 k雾霾图像上产生了视觉上令人满意的结果。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
金桥(2018年4期)2018-09-26
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
太空探索(2016年5期)2016-07-12
中国卫生(2014年5期)2014-11-10
