
基于机器学习算法的上市企业内部控制缺陷预测研究
2024-04-26 12:35袁涛黄寰
财会月刊·上半月 2024年4期
袁涛 黄寰


【摘要】上市企业内部控制缺陷信息是企业利益相关者进行决策的重要参考, 人为操纵内部控制缺陷认定以及错误披露内部控制缺陷信息会引发企业未来的经营风险。基于机器学习算法构建的预测模型能够对企业的内部控制缺陷进行有效预测, 有助于企业对潜在风险进行预警。实证研究表明: 与判别分析、 逻辑回归、 支持向量机、 决策树等利用机器学习算法预测企业内部控制缺陷的模型相比, 随机森林模型在预测的准确率、 精准率、 召回率、 F1-score和AUC值方面综合表现更好。在使用随机森林模型预测企业内部控制缺陷的过程中, 审計费用、 机构投资者持股比例和总资产增长率等特征变量起到了重要预测作用。进一步采用SHAP方法对特征变量进行贡献分布可视化分析, 深度挖掘特征变量对企业内部控制缺陷出现的影响机理。
【关键词】机器学习;内部控制缺陷;随机森林模型;准确率;精准率
【中图分类号】F279.23 【文献标识码】A 【文章编号】1004-0994(2024)07-0030-6
一、 引言
内部控制作为企业经营管理的重要手段, 在防范风险和保障企业可持续发展方面发挥着关键作用(刘启亮等,2012)。我国自2006年颁布《上市公司内部控制指引》开始, 就要求企业每年对内部控制详细情况发布内部控制评价报告(刘瑾和赵纳晖,2022)。2008年, 财政部联合五部委颁布了《企业内部控制基本规范》, 要求企业不仅要出具内部控制评价报告, 还要聘请有资质的中介机构对报告进行鉴证。2010年, 为了配合基本规范的执行, 财政部又联合五部委颁布了《企业内部控制配套指引》等文件, 规定了企业在内部控制评价报告中应当披露的详细内容。至此, 我国企业内部控制体系初步形成(喻彪和杨刚,2022)。
上市公司对内部控制的有效性进行自我评价, 有助于其发现隐藏的内部控制缺陷, 并通过制定整改和纠正措施, 规避和减少内部控制缺陷给企业带来的风险(曾庆超和许诺,2022)。但是, 上市公司对内部控制信息的披露容易受到诸多因素的影响。一方面, 企业管理层为了避免披露内部控制缺陷信息对企业声誉造成不利影响, 会减少对内部控制缺陷信息的披露, 甚至可能会人为篡改内部控制缺陷评价报告。另一方面, 企业投资者对于企业披露的内部控制缺陷信息十分关注, 如果企业向外界传达了企业内部控制有效性欠缺等内控缺陷信息, 势必影响投资者的投资选择, 从而增加企业投融资的压力, 给企业带来不良的经济后果(黄志刚等,2020)。为了规避上述风险, 企业存在选择性披露和隐藏内部控制缺陷信息的动机(蒋盛益等,2010)。
但是, 如果企业不能够及时准确地披露内部控制缺陷信息也同样会面临风险。一方面, 这会对企业的信誉造成一定程度的损害; 另一方面, 内部控制缺陷如果不能及时披露和整改, 必然会增加企业在未来的经营风险(倪静洁和吴秋生,2020)。另外, 错误的内部控制缺陷信息披露也会误导和欺骗企业的利益相关者, 提高利益相关者遭受损失的可能性。因此, 通过开展企业内部控制缺陷研究, 对可能存在的企业内部控制缺陷进行预测, 并将预测结果提供给企业的利益相关者, 对于完善企业内部控制体系具有重要的现实意义。
现有文献对于企业内部控制缺陷的研究主要以理论研究为主, 而利用大数据和信息技术手段对企业内部控制缺陷进行预测研究的文献较少。因此, 本文以机器学习算法为基础, 构建了逻辑回归、 判别分析、 支持向量机、 决策树和随机森林模型, 利用我国上市企业的财务信息和非财务信息作为特征变量来预测企业的内部控制缺陷。这为企业内部控制缺陷的研究提供了新的思路, 丰富了企业内部控制缺陷研究的内容, 也为机器学习技术运用于企业内部控制缺陷预测研究提供了可能。
二、 研究设计
(一) 样本选择和数据处理
本文以2012 ~ 2021年我国A股上市企业为研究对象。根据《企业内部控制基本规范》和《内部控制——整合框架》等文件以及现有文献的做法, 内部控制缺陷可以按照缺陷严重程度或缺陷成因等进行分类。考虑到本文主要研究不同严重程度的内部控制缺陷, 故只按照缺陷严重程度对内部控制缺陷进行划分, 将企业内部控制缺陷按照严重程度分为重大缺陷、 重要缺陷和一般缺陷。其中, 将内部控制存在重大缺陷的样本企业标记为正样本, 将不存在重大缺陷的样本企业标记为负样本。另外, 选取相对应上市企业的财务状况、 企业治理和审计监管信息作为预测数据。
为了保证样本数据的规范性和完整性, 本研究剔除了130多家金融类上市企业, 并对数据不全或缺失的样本进行了剔除。通过筛选整理, 最终获得26230个样本。其中: 企业内部控制存在重大缺陷的正样本7856个, 占全样本的比例为30%; 不存在重大缺陷的负样本18374个, 占全样本的比例为70%。正负样本比例约为1∶2, 两组样本的数量趋向平衡, 不存在类别不平衡的问题, 因此, 本研究的数据集不需要通过欠采样或者过采样等方法来缓解类别不平衡的问题。另外, 为了防止预测模型出现过拟合问题, 本研究在预测模型中加入正则化项或罚项来缓解预测模型的过拟合问题。为了更好地评估机器学习算法对企业内部控制缺陷的预测性能, 本文按照7∶3的比例将正负样本划分成模型的训练集和测试集, 训练集的样本数据用来拟合训练模型, 测试集的样本数据用来进行模型预测和性能评估。所有样本数据均来源于CSMAR数据库和企业年报。
(二) 特征选择
1. 财务状况与企业内部控制缺陷。财务状况信息能够反映企业内部控制情况。通常来说, 财务绩效和经营状况越差的企业, 其内部控制有效性越低, 内部控制质量也越差(叶康涛等,2015;Askari和Anwar,2020)。已有研究表明, 企业在进行投资、 融资等生产经营活动时, 内部控制缺陷出现的概率最高, 相应企业的财务绩效水平也处于行业平均水准以下(刘启亮等,2013)。基于上述分析, 本文选取部分财务指标来对企业的财务状况进行衡量, 具体包括: 以利息保障倍数、 流动比率和资产负债率来衡量企业的偿债能力; 以总资产增长率、 净利润增长率、 营业收入增长率和营业成本增长率来衡量企业的发展能力; 以应收账款周转率、 应付账款周转率和固定资产周转率来衡量企业的营运能力; 以总资产净利率、 净资产收益率和营业净利率来衡量企业的盈利能力。另外, 存在内部控制缺陷的企业, 抵抗风险能力普遍较弱, 因此还选取经营杠杆和财务杠杆指标来衡量企业的风险水平。
2. 公司治理与企业内部控制缺陷。公司治理与内部控制之间存在着相辅相成、 相互促进的关系, 二者具有高度的相关性(李万福等,2011;Tan等,2020)。已有研究表明, 健全的内部控制机制要有完善的公司治理结构作为支撑, 而内部控制的创新和深化也将促进公司治理结构的完善。健全的公司治理是内部控制有效运行的基础和保障。在完善的公司治理结构环境下, 股东大会、 董事会、 监事会和管理层各司其职、 相互制衡, 以此保证内部控制制度的建立和实施, 有利于企业内部控制系统的良好有序运行, 从而达到提高企业经营效率与加强企业信息披露的目的。反之, 如果公司治理结构不完善, 无论多么有效的内部控制制度设计也会流于形式(Kim和Arun,2014;Du,2014)。因此, 本文选取实际控制人两权分离率、 股权制衡度、 机构投资者持股比例、 是否两职合一、 董事会规模、 独立董事比例等指标衡量公司治理。
3. 审计监管与企业内部控制缺陷。相关研究显示, 超过70%的内部控制缺陷是在对企业进行审计的过程中发现的。而设置审计委员会、 聘请会计师事务所对企业财务报告进行外部审计, 体现了企业管理层对内部控制的重视程度。变更会计师事务所则体现了企业的审计监管是否连续, 已有研究表明, 频繁进行会计师事务所变更的企业, 发生内部控制缺陷的比例通常更高。而是否披露内部控制审计报告和披露审计意见类型则反映了企业独立审计的客观性。一般而言, 对于内部控制质量差、 经营状况不佳以及风险较高的企业, 会计师事务所会投入更多的人力和资源来开展审计工作, 因此会收取比内部控制
(五) 特征变量的数据处理
1. 数据归一化。为了缩小数据间的差异, 提高预测模型的算法效率, 需要对特征变量的数据进行归一化处理。公式如下:
x?=(x-μ)/σ。其中, μ为样本均值, σ为样本标准差。归一化操作之后数据的均值为0, 标准差为1。
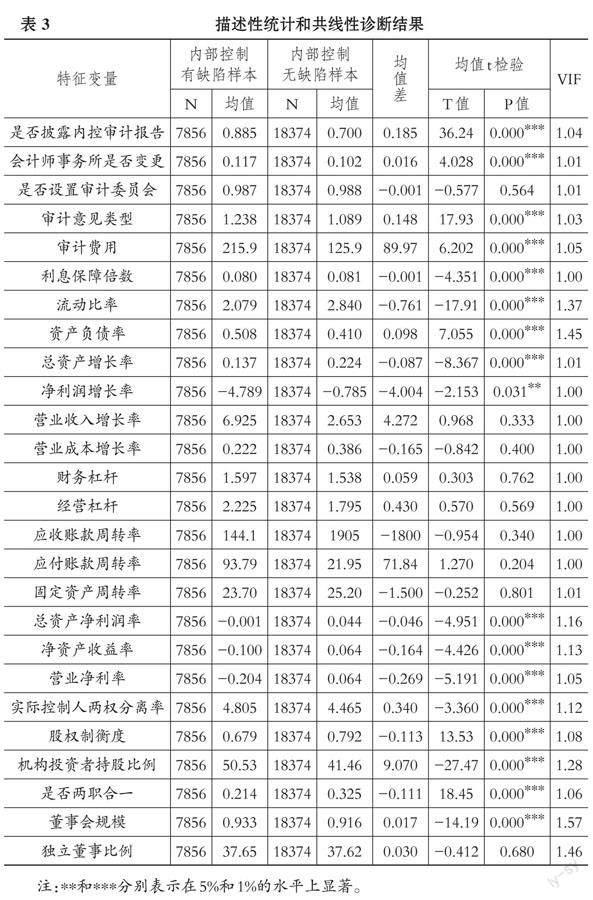
2. 多重共线性检验。为了防止特征变量之间因存在多重共线性, 而对之后的预测模型产生误差影响, 本文需要先对相关指标进行共线性检验。本研究使用方差扩大因子方法对选用的特征变量进行共线性检验, 检验的结果通过得到的VIF值来判断, 如果0 三、 机器学习模型预测结果 (一) 描述性统计 表3是本研究所选特征变量的描述性统计结果。根据结果显示, 内部控制存在缺陷的样本和内部控制不存在缺陷的样本在财务状况、 公司治理和审计监管等特征变量上存在显著差异。 在财务状况方面, 内部控制存在缺陷样本的偿债能力明显弱于内部控制不存在缺陷的样本, 具体表现为前者的利息保障倍数、 流动比率的均值都小于后者且均值差在1%的水平上显著。资产负债率前者明显高于后者且在1%的水平上显著。除此以外, 内部控制存在缺陷样本的发展能力和盈利能力也弱于内部控制不存在缺陷的样本。具体表现为前者的总资产增长率、 净利润增长率、 总资产净利润率、 净资产收益率和营业净利率的均值都小于后者且均值差在5%或1%的水平上显著。而对企业风险水平和运营能力的特征进行比较发现, 虽然上述特征变量的均值差不显著, 但是内部控制存在缺陷样本的经营杠杆、 财务杠杆和应付账款周转率的均值都明显高于内部控制不存在缺陷的样本。应收账款周转率和固定资产周转率也都明显低于内部控制不存在缺陷的样本, 这说明内部控制存在缺陷的样本企业面临的经营财务风险更大, 发生坏账损失的可能性更大, 其运营能力更低。 在公司治理方面, 内部控制存在缺陷的样本在实际控制人两权分离率和机构投资者持股比例方面高于内部控制不存在缺陷的样本。同时, 内部控制存在缺陷样本的股权制衡度和是否两职合一的比例低于内部控制不存在缺陷的样本。另外, 在董事会规模和独立董事比例方面, 内部控制存在缺陷的样本与内部控制不存在缺陷的样本的差异不太明显。这说明相对于内部控制不存在缺陷的样本, 内部控制存在缺陷的样本具有实际控制权较为集中、 股权制衡度不高、 管理职权分散等特点。 在审计监管方面, 内部控制存在缺陷样本在披露内控审计报告中的比例高于内部控制不存在缺陷样本; 负责审计的会计师事务所的变更前者也更频繁; 审计意见类型前者对审计结果的看法和所持的态度也比后者更消极; 在审计费用的支出上, 前者也明显高于后者。上述特征变量的样本均值差都在1%的水平上显著。综上所述, 内部控制存在缺陷的企业在财务状况、 公司治理和审计监管方面与内部控制不存在缺陷的企业存在差异, 且前者弱于后者。 (二) 机器学习模型的预测结果 本研究使用判别分析、 支持向量机、 逻辑回归、 决策树和随机森林等机器学习算法, 构建了企业内部控制缺陷预测模型。各模型的预测结果见表4。 在预测模型的准确率方面: 首先, 随机森林的准确率最高, 为71%; 其次为支持向量机Linear核函数模型的70%; 然后是Rbf核函数、 判别分析、 逻辑回归、 Sigmoid核函数和决策树模型, 均为69%; 最后是Poly核函数模型, 为68%。准确率反映了模型对企业内部控制存在缺陷和不存在缺陷预测的预测正确情况。对于预测模型的精准率, 最高的是随机森林、 决策树和支持向量机Rbf核函数模型, 为63%; 其他模型的精准率均位于56% ~ 61%之间。精准率衡量的是模型出现误判的概率。对于预测模型的召回率, 最高的是随机森林, 然后是判别分析和决策树模型, 最低的是支持向量机的Sigmoid核函数和Linear核函数模型, 所有模型的召回率均在50%以上。召回率反映的是模型对企业内部控制缺陷识别的漏检率, 召回率越高, 漏检的概率就越小。对于预测模型的F1-Score值, 随机森林的F1-score最高, 为58%; 最低的是支持向量机的Linear核函数和Sigmoid核函数模型。F1-score值越大, 说明模型的质量越高。除上述可以评估模型預测性能的指标以外, 本文也会使用ROC曲线和AUC值来对模型进行评价, ROC曲线是根据混淆矩阵以FPR为横坐标、 以TPR为纵坐标所绘制的曲线。而 ROC 曲线围成的面积就是AUC 值, 一般AUC值越大, 模型预测效果就越好。根据表4, 所有模型的AUC值都大于0.5, 表明机器学习模型具有预测价值。其中AUC值最大的模型是随机森林, 达到了0.77。这说明相对于其他模型, 随机森林的预测效果最好。上述结果表明, 根据机器学习算法建立的模型能够对企业内部控制是否存在缺陷进行预测, 并且通过准确率、 精准率、 召回率、 F1-score以及ROC曲线和AUC值对各个模型进行评价后发现, 随机森林模型的预测效果最好。 (三) 特征变量重要性和可视化分析 本研究还需确认对预测企业内部控制缺陷贡献度最高的特征变量。特征变量重要性的计算方式是通过构建树类模型, 并使用Feature_Importances方法获得在树模型中每个特征变量的特征分裂次数以及利用该特征分裂后的增益来计算特征变量的重要性。根据上述各机器学习模型的预测性能, 最终选择了表现较好的随机森林模型来计算特征的重要性。为了便于观察, 按照特征变量的贡献度, 从大到小进行了排列, 根据图1特征变量的重要性可以发现, 每个特征都对模型的学习效果产生了影响。其中, 影响力排名前三的特征变量分别是审计费用、 机构投资者持股比例和总资产增长率, 其特征贡献度分别为5.57%、 3.24%和2.21%。这说明审计费用、 机构投资者持股比例和总资产增长率对企业内部控制缺陷的预测起到了重要作用。 为了进一步挖掘特征变量影响企业内部控制缺陷发生的重要因素和影响方式, 本研究采用SHAP方法对企业内部控制缺陷预测模型的运作过程和贡献分布进行可视化分析。Shapley值常用于研究合作博弈中各参与方的价值, 后被用于解释复杂模型中特征的价值。SHAP方法的工作原理是将每个特征值的贡献分配到不同的特征变量中, 然后计算每个特征变量的Shapley值, 最后将计算得到的Shapley值与特征值相乘得到该特征变量对于预测结果的贡献。SHAP方法有助于理解机器学习模型的预测结果, 识别预测模型不足之处并加以改进, 进而提高模型的预测能力。 在图2中, 左侧显示各个特征变量的名称, 右侧对应的是各特征变量映射SHAP value(SHAP值)后的取值范围和大小。图2中Feature value(特征值)的颜色由浅色到深色, 表示特征取值由小到大。当横坐标SHAP value的值大于0时, 代表该特征正向提升了预测模型的贡献值;当SHAP value的值小于0时, 代表该特征降低了预测值, 起反向作用。根据图2可知, 审计费用对预测模型的贡献度最高, 且审计费用深色样本的SHAP value均小于0, 这说明审计费用降低了企业内部控制缺陷出现的概率, 审计费用有助于企业内部控制目标的完成。机构投资者持股比例的深色样本也基本落在SHAP value小于0的一侧, 这说明外部投资也能够抑制企业内部控制缺陷出现的概率。总资产增长率的深色样本绝大多数落在SHAP value大于0的一侧, 这说明企业资产经营规模扩张的速度越快, 公司内部控制缺陷出现的概率就越高。具有类似性质的还有是否两职合一、 流动负债比率和实际控制人两权分离率等。 四、 研究结论 本研究以2012 ~ 2021年在我国A股上市的企业为研究对象, 通过选取衡量企业财务状况、 公司治理和审计监管的26个特征变量的26230个数据为样本, 构建了判别分析、 逻辑回归、 支持向量机、 决策树和随机森林等利用机器学习算法预测企业内部控制缺陷的模型, 并对各个模型的预测性能进行了评价。评价的结果显示, 随机森林模型的预测性能优于其他预测模型, 可运用于企业内部控制缺陷的预测。研究还发现, 在使用随机森林模型预测企业内部控制缺陷的过程中, 审计费用、 机构投资者持股比例和总资产增长率等变量的特征贡献度最高, 对企业内部控制缺陷的预测起到了重要作用。最后, 采用SHAP方法对特征变量进行贡献分布可视化分析, 深度挖掘了特征变量影响企业内部控制缺陷出现的影响机理。 保障企业生产经营活动正常运行、 控制和防范各类风险是企业实施内部控制的目的。而企業实施内部控制的关键是准确识别内部控制缺陷。因此, 研究利用机器学习算法预测企业内部控制缺陷, 有助于企业管理层识别潜在的风险, 完善企业的内部控制体系, 减少各类风险给企业带来的经济损失, 并为企业的投资、 融资以及经营管理等重大决策提供参考。 【 主 要 参 考 文 献 】 黄志刚,刘佳进,林朝颖.基于机器学习的上市公司财报舞弊识别前沿方法比较研究[ J].系统科学与数学,2020(10):1882 ~ 1900. 蒋盛益,汪珊,蔡余冲.基于机器学习的上市公司财务预警模型的构建[ J].统计与决策,2010(9):166 ~ 167. 李万福,林斌,宋璐.内部控制在公司投资中的角色:效率促进还是抑制?[ J].管理世界,2011(2):81 ~ 99+188. 刘瑾,赵纳晖.基于机器学习的企业内部控制重大缺陷预测[ J].财会月刊,2022(3):123 ~ 131. 刘启亮,罗乐,何威风等.产权性质、制度环境与内部控制[ J].会计研究,2012(3):52 ~ 61+95. 刘启亮,罗乐,张雅曼等.高管集权、内部控制与会计信息质量[ J].南开管理评论,2013(1):15 ~ 23. 倪静洁,吴秋生.内部控制有效性与企业创新投入——来自上市公司内部控制缺陷披露的证据[ J].山西财经大学学报,2020(9):70 ~ 84. 叶康涛,曹丰,王化成.内部控制信息披露能够降低股价崩盘风险吗?[ J].金融研究,2015(2):192 ~ 206. 喻彪,杨刚.内部控制重大缺陷与企业劳动投资效率[ J].财会月刊,2022(13):32 ~ 40. 曾庆超,许诺.机器学习对上市公司年报错报的识别研究——财务重述预测的视角[ J].中国注册会计师,2022(2):43 ~ 48. Askari Sikdar., Anwar Hussain. IFDTC4.5:Intuitionistic Fuzzy Logic Based Decision Tree Fore-transcational Fraud Detection[ J].Journal of Information Security and Applications,2020(52):1 ~ 13. Du X.. Does Religion Mitigate Tunneling? Evidence from Chinese Budd-hism[ J].Journal of Business Ethics,2014(2):299 ~ 327. Kim Soo Y., Arun Upneja. Predicting Restaurant Financial Distress Using Decision Tree and Ada-Boosted Decision Tree Models[ J].Economic Modelling,2014(36):354 ~ 362. Tan Duojiao, Bilal,Simon Gao, Bushra Komal. Impact of Carbon Emission Trading System Participation and Level of Internal Control on Quality of Carbon Emission Disclosures: Insights from Chinese State-Owned Electricity Companies[ J].Sustainability,2020(5):1788. (责任编辑·校对: 李小艳 黄艳晶) 【基金项目】四川省科协科技智库调研课题(项目编号:sckxkjzk2024-2);西南科技大学博士基金资助成果(项目编号:23sx7111);成都市哲学社会科学规划重点项目(项目编号:2023CS119);成都理工大学研究生质量工程研究项目(项目编号:2023YJG107) 【作者单位】1.西南科技大学经济管理学院, 四川绵阳 621010;2.成都理工大学学术期刊中心, 成都 610059;3.成都理工大学商学院, 成都 610059。 黄寰为通讯作者
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
中国经贸(2016年20期)2016-12-20
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
商业会计(2016年18期)2016-11-10
科学与财富(2016年28期)2016-10-14
商业会计(2016年12期)2016-10-08
