
“地”字结构识别
2006-07-27 05:32钱小飞
现代语文 2006年5期
[摘要] “地”字结构是汉语中有标记的状语结构,“地”字结构的自动识别作为浅层句法分析的任务之一可以减少自动句法分析的歧义。本文在分析“地”字结构性质的基础上,利用规则与统计相结合的方法,基于分词文本对“地”字结构进行了对比性的识别研究。实验利用200万字的语料进行训练,将获取的数据用于自动识别,获得了较好的效果。
[关键词] “地”字结构 句法分析 规则 概率
汉语是一种缺乏形态变化的语言,传达了较少的形式化信息,增加了自然语言处理的歧义。在自动句法分析的过程中,汉语缺少可直接利用的形式信息,增加了分析的难度。
20世纪80年代末,国外开始了关于组块(Chunk)的研究,并提出了浅层句法分析的概念,希望通过语块的识别和语块之间依附关系的分析来实现对完全句法分析任务的分解。90年代以来,国内学者在汉语的浅层句法分析方面也做了很多工作。郭志立利用广义互信息研究了“的” 字短语的结构和边界。王立霞、吴云芳使用概率模型识别了介词短语的边界。赵军提出了基于转换的汉语基本名词短语(baseNP)识别模型。周强利用边界概率分布和内部结构组合对最长名词短语(MNP)进行了较为全面的识别分析。这些研究主要集中于对名词短语和介词短语的识别,为汉语的自动处理做出了有益的探索。
作为浅层句法分析的任务之一,“地”字结构的自动识别可以有效地减少句法分析的歧义。由于“地”字结构在句中处于状语的位置,对于一些简单的单句而言,该结构的自动识别常常可以帮助找到谓语中心,划定句子的基本结构,我们可以给出这样的形式化表示:
S=[SZ]+Subj+[SZ]+DS+P+[Obj]
其中,S表示单句,SZ表示句首或小句状语,DS表示“地”字结构,P表示谓语中心,Subj表示主语,Obj 表示宾语,[]表示可以出现也可以不出现,+表示语法分隔。
本文分为四个部分,第一部分对“地”字结构进行定义和分类,第二部分介绍统计与规则相结合的“地”字结构识别算法,第三部分分析实验结果,第四部分结语。
1.“地”字结构的定义及分类
1.1“地”字结构的定义
“地”字结构是以结构助词“地”为右边界标志,在句中动词前作状语,直接修饰动词或谓语中心语的一种句法结构。我们把“地”字结构定义为“修饰语+地”的形式。
1.2“地”字结构分类
“地”字结构内部存在多种句法关系,表现为修饰语部分可以是单个词语,也可以是句法组合,包括状中组合、并列组合、述宾组合、主谓组合等。根据“地”字结构内部的句法层次和句法关系对它进一步细分。
(1)简单“地”字结构:“单元状语+‘地”形式的结构。
(2)复杂“地”字结构:“多元状语+‘地”形式的结构。
简单“地”字结构的修饰语是单元的,即内部只有一个元素,不存在句法组合关系,如:
新 的 游客 【源源不断 地】 涌 来 。
复杂“地”字结构的修饰语有多个元素组合而成,这些元素之间满足一定的句法组合关系。根据这些关系,可以将复杂“地”字结构进一步细分为多元修饰型、多元并列型、多元主谓型以及多元述宾型等:
多元修饰型:修饰语为“状语+中心语”形式的“地”字结构,如“很 努力 地”。
多元并列型:修饰语为“并列成分+[连接成分]+并列成分+…”形式的“地”字结构,如“积极 主动 地”。
多元主谓型:修饰语为“主语+谓语”形式的“地”字结构,如“程度 不同 地”。
多元述宾型:修饰语为“述语+宾语”形式的“地”字结构,如“有 计划 地”。
2.统计与规则相结合的“地”字结构识别策略
2.1识别目标
“地”字结构识别的目标是准确地确定“地”字结构的左右边界。本研究以“【”作为“地”字结构左界标志,以“】”作为右界标志,对句中“地”字结构进行识别,识别结果格式如下:
中国认为 , 伊拉克应 【全面 、 切实 地】 履行 联合国 有关 决议。
2.2识别算法
根据“地”字结构的特点,在语料统计分析的基础上,我们确定采用规则匹配、概率加权选择和上下文调整相结合的策略进行识别。
2.2.1规则匹配
我们以人民日报1998年1月份的标记语料(记为9801.tag)作为训练语料,对其中的“地”字结构进行人工标注,并提取出每一个具体的“地”字结构的词性标记串及其出现概率,组成“地”字结构的标记串规则集,此规则集中包含了100条规则,其中任意一条规则的出现概率P(rule[i])的计算公式如下:
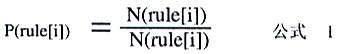
我们应用此标记串规则集的具体规则对每一个“地”字结构进行可能匹配:对于每一条标记串规则,获取相同长度的“地”字结构词串,并通过查词典的方式取得该词串所有的可能标记串,如果存在某条可能标记串与标记串规则匹配,则该标记串规则作为一条可能匹配规则;如此记录下所有的可能匹配规则,并统计其出现概率。
2.2.2概率加权选择
由于面对的是分词文本,规则的长度和词串所对应的标记串都是不确定的,在实际标注过程中有两种选择:一种选择是长规则优先匹配,规则长度相同时,高频规则优先匹配;另一种选择是通过规则的出现概率进行优选。实验表明,第一种选择不能体现语料中的自然比例关系,造成了短规则匹配概率低下,影响标注正确率;第二种方法具有更大的可行性和优越性。但是,通过统计得到的规则集还不能直接用于标注:
第一,用上文使用得最大似然估计法估计参数会造成严重的数据稀疏问题,低概率事件常常被忽略。
第二,规则的出现概率受到其长度的制约。实验发现,短规则出现概率通常高于长规则,但规则的出现概率高不等于该规则作为“地”字结构的概率高,甚至有相反的趋势。
我们使用一种简单的加权方法,并将权值转化为费用:
Feeweight[i] = P (rule[i])×Fee(rule[i]) ×(Len(rule[i])-1) 公式2
其中, Fee(rule[i])表示rule[i]的费用,Len(rule[i])表示规则rule[i]的长度。为解决数据稀疏的问题,采用了一阶马尔可夫过程计算规则费用:

trans[i][j]是指从“地”字结构内部获取的词性tagi到tagj的转移概率。
对于某一条具体的规则rule[i],Feeweight[i]值越大,它用于“地”字结构标注的概率越小。当某一个字符串能匹配多条规则时,优先选择费用最低的规则进行标注。
2.2.3上下文信息
对标记串的概率优选只利用了词性信息,一些词语上下文信息对识别也非常有帮助。我们制定了三张词表来进行概率标注后的微调。左界外词表记录常常仅作为DS左界外一词的词语,如“等”,左界内词表记录常常仅作为DS左界内一词的词语,如“很”,非DS左词词表记录常常只出现在名词“地”左邻,而不出现在助词“地”左邻的词语。
3.实验结果及分析
3.1 实验结果分析
我们应用9801.tag作训练语料,1月份和2月份的切分语料(分别记为9801.cut和9802.cut)作测试语料,进行了多次实验。
3.1.1 相异词表实验
考虑到词表对于“地”字结构标注的影响,分别应用从9801.tag的“地”字结构中提取的封闭的小词表(917词条),并使用开放的先验大词表(约155000词条)进行测试,其中开放测试语料为人民日报2月份上半个月的切分语料(记为9802p.cut)。令某DS左右边界都标注正确作为1次正确识别,否则为1次错误识别,如果Fc表示正确识别的DS个数,Fw表示错误识别的个数,Ff表示识别失败的个数,Fm表示多余识别的个数,Ft表示文本中DS总数,则正确率(Precision)、召回率(Recall)和调和平均值(F)可计算如下:

测试结果如表1和表2所示:

词表对于标注的影响非常明显。从“地”字结构中提取出的小词表减少了词语的词性选择维度,有利于提高精确率,但词语数量不够的问题,降低了召回率。先验的大词表基本能够保证词语数量的充足,有利于提高召回率,但加剧了词性标记的竞争,降低了正确率。另外,大词表中可能存在的错误,也会对识别产生影响。
综合正确率、召回率和调和平均值可以看出,使用大词表的开放测试取得了比较好的结果。
3.1.2相异规模实验
为考察算法的有效性和健壮性,我们使用先验的大词表对9802p.cut和9802.cut进行了对比性的开放测试,测试结果如表3和表4所示:
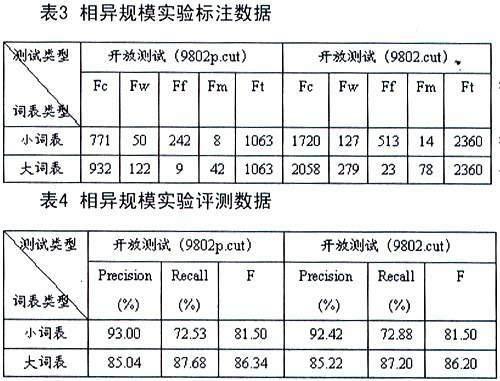
从测试结果可以看出,我们所采用的算法具有较好的健壮性,对于大词表开放测试,9802.cut的正确率甚至略优于9802p.cut的测试数据。
3.2 错误分析
大词表测试数据表明:实验中最主要的错误类型是错误识别(Fw)和多余识别(Fm)的问题。错误识别即因该识别的结构定界不准确而导致的错误,这些错误涉及到以上提到的各种语法结构,主要包含以下几种情况:
3.2.1状语存在语法功能歧义,如“又”,它既可以出现在DS中,也可以作谓语的修饰语:
a. 他 【又 生气 又 无奈 地】 瞅 着 我 。
b. *姐妹 俩 【又 亲热 地】 聊 了 起来 。
考虑到句a存在的可能性,我们没有将“又”列入左界外词表,带来了如句b的标注错误(用*号表示,下同)。事实上,在9802.cut中并没有出现a所示的情况。因此标志词词表如何制定还需要进一步考虑和完善。
3.2.2 标点分隔的并列结构作状语,以上算法缺乏识别能力,如:
c. *从而全面 、 【完整 、 准确 地】回答 了 什么是 社会主义 。
3.2.3语料问题,如分词问题。
d. *她 还 把 学 到 的 技术 毫无 【保留 地】 传教 给 别人 。
“毫无保留”作为一个词切分更合适,例d切分为两个词,造成了识别错误。
3.2.4固定结构,如“…般地”,“像…般地”。
e. *像 【洪流 般 地】向前 移动 。
多余识别,即名词“地”被作为助词处理,是另一个重要的错误来源,从识别算法可以看出,我们使用的统计方法对多余识别的错误缺乏辨别能力,因此名词“地”的排歧任务主要由非DS左词词表完成,虽然名词“地”前一词具有一定的特征,如量词“亩”,完全收录这部分词仍然困难,如:
f. *许多 “ 六朝 【繁华 地】 ” 成为荒漠中的遗址。
“地”字结构的自动识别可以减少句法分析的歧义,是浅层句法分析的任务之一。本文在分析语料的基础上,对切分语料中“地”字结构进行了识别,提出了基于规则匹配和概率选择的识别方法,取得了比较好的效果。在今后的研究中,我们将逐步进行改进和提高。
参考文献:
[1] 陈小荷:现代汉语自动分析——Visual C++实现.北京语言文化大学出版社,2000年。
[2] 郭志立:用统计方法研究“的”字短语的结构和边界.计算机时代的汉语和汉字研究,1997年。
[3] 王立霞:现代汉语介词短语边界识别研究.中文信息学报,2005年第3期。
[4] 吴云芳:汉语介词结构的自动标注.北京语言文化大学硕士论文,1998年。
[5] 赵军,黄昌宁:基于转换的汉语基本名词短语识别模型.中文信息学报,1999年第2期。
[6] 周强、孙茂松、黄昌宁:汉语最长名词短语的自动识别.软件学报,2000年。
(钱小飞,南京师范大学文学院)
猜你喜欢
电脑知识与技术(2019年23期)2019-11-03
风流一代·经典文摘(2017年11期)2018-02-21
安徽文学·下半月(2017年9期)2018-02-03
中学课程辅导·教师教育(中)(2017年3期)2017-04-14
科学与财富(2016年30期)2017-03-31
亚太教育(2016年34期)2016-12-26
读者·校园版(2015年12期)2015-05-14
时代英语·高三(2014年5期)2014-08-26
教学与管理(理论版)(2009年9期)2009-11-04
