
DF-RED:一种基于动态公平性的RED算法
2010-07-09 11:30余冠玮鲁东明
制造业自动化 2010年9期
余冠玮,邢 卫,鲁东明
(浙江大学 计算机科学与技术学院,杭州 310027)
0 引言
随着互联网应用的不断普及和发展,网络带宽资源的竞争也愈发激烈,而网络拥塞的发生往往又进一步导致网络性能的下降。其中的一个解决方案就是引入主动队列管理AQM(Active Queue Management)算法。
相比传统的基于尾部丢包队列(Drop-tail Queue)的TCP拥塞控制的路由机制,AQM可以有效的解决:对突然暴涨的数据流丢包过大(bias against bursty traffic)和容易产生全局同步现象(global synchronization)等问题。[1]其中,随机早期检测RED(Random Early Detection)就是最著名、最常用的主动队列管理算法,获得了大量网络路由器的支持。
RED通过计算平均队列长度,来尽可能早预测网络拥塞,并以一定概率丢弃部分数据包。然而,由于该算法对所有的分组采取相同的丢包率进行丢弃,它并不能保证适应流(Adaptive Flow)与非适应流(Non-adaptive Flow)并存时时,这些流对网络带宽资源的公平共享 ,也就是说,非适应流往往会抢占更多的带宽占用,而导致适应流的带宽资源不足,在最坏情况下,适应流甚至会被“饿死”。
为了增加主动队列管理算法的公平性改进:其中, CHOKe[3]算法是当一分组进入队列时,它首先从当前缓存中取出其中一个分组与该分组进行对比,若属于相同流,则丢弃这两分组,反之放回队列按传统RED进行丢弃。其不足之处在于,队列中的分组比例随着流数目的增加而减少,通过一次比较来识别高带宽流的办法会大大受限;CSFQ[4]算法是通过将一些流状态信息插入分组头部来辅助路由器进行丢弃概率计算,缺点则是其实现需网络中所有的路由进行协同;AFD[5]则与CSFQ比较相似,其最大贡献在于引入了分组采样机制进行辅助,虽然它大大降低了路由所需要维持的大量信息,但其存在的不足也与CFSQ类似;FRED算法[2]主要是通过考察某个流的当前队列缓存占用量来决定该相应的分组丢弃概率,但其缺点在于,由于需要对整个缓存队列中的活跃流进行记录并维护其相应的流状态,因而导致当流数量很大时,流状态表将变得过大,大大占用了路由器的存储和计算资源。高文宇[6]等人在对FRED,CHOKe,CSFQ和AFD进行综合对比研究后表明,FRED算法在公平性方面是在这几个主动队列管理算法中表现最好。
针对上述问题,本文主要通过周期性地分析链路分组构成,并对不同分组所在的流分配动态优先级,使得基于RED算法改进后的DF-RED(Dynamic Fairness Random Early Detection)算法可以有效顾及业务流之间的公平性问题,即在保持低资源开销的同时高低带宽流的吞吐量、降低丢包率,进而增强公平性。此外,本文还试图了对业务流之间公平性失衡进行定义,即只有当某个流占用带宽超过一定限度时,才被认为出现流之间出现了公平性失衡。
下面主要分为以下几部分内容:第一节,我们简要介绍了传统RED的实现机理;第二节,我们为了更为有效的解决网络公平性问题,提出了一种新的基于动态公平性的DF-RED算法;第三节,通过详尽的NS2仿真实验数据,得出DF-RED在非拥塞网络与拥塞网络,相比传统RED和基于流公平的FRED,在吞吐量和丢包率等方面都有较好的表现;最后是本文的总结。
1 RED算法
RED算法[7]是基于当前计算的平均队列长度,求得当前分组的丢弃概率,从而实现早期检测和发现拥塞的目的,其具体实现步骤如下:
首先,通过设置低通变量wq,并根据上一时刻的平均队列长度avgn-1以及当前队列长度q,利用以下策略计算当前的平均队列长度avgn,
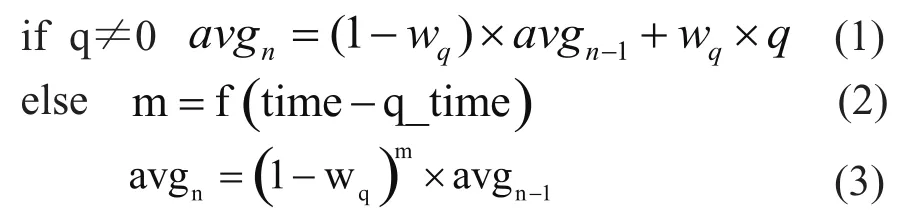
其次,预先设定平均队列长度的上、下限maxth和minth值,以及所允许的最大丢包率maxp。这样,当每个分组流入路由器时,通过检测当前平均队列长度avgn值,就可以计算出最终丢弃概率pa',如下所述:

从公式(5)中可以看出,临时丢弃概率pb是由当前平均队列长度avgn所决定的重要基准丢弃概率,随着avgn从minth到maxth的变化,它也线性从0递增到maxp。公式(6)则是使得临时丢弃概pb率能够随着上次标记丢包后所接收到的分组数目count增加而缓慢增加。
2 DF-RED算法
2.1 DF-RED分析
本文的主要是在传统RED的框架下,首先通过周期性对网络进行有限个数的分组采样;然后,根据其采样分组对应业务流的构成进行计数和统计;其次,通过计算最高带宽流与最低带宽流的情况,对网络公平性本身进行一个评估,并根据评估结果决定是否启动DF-RED算法;最后,当每个分组进入队列之时,算法要对分组进行识别,使得带宽占用率低的业务流对应的分组优先级较高,从而在原有丢弃概率上,进一步动态调低其丢弃概率;反之,对于带宽占用率高的业务流,则对其分组分配低优先级,从而动态增大其丢弃概率,使其更为接近已定义的最大丢弃概率,最终导致其更可能被优先丢弃。这样,就可以为传统RED算法提供业务流之间公平性保证。
该算法的主要特征在于:1)算法首先对网络业务流公平性本身进行了预判,只有当被认为发生公平性失衡时,才启动DF-RED算法,否则保留原来的传统RED算法;2)算法不需要对业务流进行事先的优先级定义也不需要对分组进行任何修改,进而保障了对客户端或者接入路由器的最低要求,提高兼容性与有效性;3)算法主要基于单缓冲队列实现,不需要复杂的多个优先级队列管理;4)由于算法是基于预定分组进行的采样分析,进而增加的存储资源是有限的,且算法是基于采样分组所表现出的有限业务流进行识别,因此,它的空间和时间复杂度都是,它并不随着流个数的增加而增加。
2.2 参数引入
为了实现RED算法的公平性改进,DF-RED算法需要引入如下三个参数:
sample:采样周期,周期性采样分析的数据包个数;
fairness_thresh:公平性阈值,最大带宽占用率流的分组比例与最小带宽占用率流的分组比例差的门限值,只有当实际计算的比例差大于该值时,网络业务流之间才被判定为公平性失衡,进而启动DF-RED算法进行调节;
α:介变因子,将被用于判定公平性严重失衡。当某个业务流比例值大于该值时,它的丢弃概率将以更大的速率增加,从而更为有效的降低此种类型的异常流。
2.3 算法描述
本节主要阐述了DF-RED算法的具体实现。由于DF-RED算法的基本框架仍是传统的RED机制,所以,下文所述的所有RED本身参数与第1章所述相同。
当每个数据分组流入路由器时,DF-RED算法主要由“预处理”分析阶段和早期丢包计算处理”阶段两部分组成。
其中,“预处理”分析阶段除了传统RED算法本身所需要的平均队列长度等计算之外,其主要任务还有:1、对各个业务流的识别;2、周期性计算各业务流分组所占比例,判定是否产生了“不公平”;3、对不同业务流分配相应的优先级prio,并将其传给“早期丢包计算处理”阶段。
而在“早期丢包计算处理”阶段,路由器则会首先根据此时评估出来的平均队列长度,并结合公式(5)计算出当前的的中间丢弃概率。其次,算法通过对之前求得的最大带宽占用率流的分组比例与最小带宽占用率流的分组比例的差进行分析,如果其大于thresh,则被认为是当前网络出现公平性失衡,进而启动改进后的RED算法对进行调节并求得新的临时丢弃概率,从而使得高带宽占用流更可能被丢弃,而低带宽流尽可能地进行有限服务;反之,若求的最大带宽占用率流的分组比例与最小带宽占用率流的分组比例的差不大于thresh时,此时的网络仍旧各业务流所占比例也相对公平,因而保持原有的RED算法。最后,利用公式(6)对进行处理,进而求得分组丢弃率,最终实现业务流之间的动态公平性控制。其具体丢弃概率的计算实现如下:




图1 的变化曲线图
图1显示了pc随着prio变化的一个曲线图。在图中可以看出,当业务流的prio在0~α时,该业务流的pc将在0~Pb之间进行缓慢变化,且变化速率随着业务流占用带宽的增加而增大,但还是低于原来的pb,减少非高带宽流的丢弃率;另一方面,当某个业务流的prio超过α时,丢弃概率Pc的增加将呈线性迅速增长,以保证高带宽占用的流将更有可能被丢弃。
3 仿真实验
在这一章中,我们主要在NS2[8]网络仿真平台上进行模拟实验,其中采用的FRED算法是由伯克利提供的NS-2功能模块。[9]由于公平性本质上说,就是在有限带宽资源情况下,不同业务流所占带宽的公平共享问题。为此,本实验主要通过分析DF-RED、FRED以及传统RED对不同流并时在非拥塞和拥塞网络环境中所作出的公平性反应,另外,我们还分析了高带宽流和其他低带宽流在端到端吞吐量,以及丢包率的变化。
为了衡量公平性,我们引入了Jain等人[10]提出的公平性指数(Fairness Index)。该指数标准由于简单适用,且适合单瓶颈上的资源分配公平性研究,故而被众多学者所采用,其具体定义如下:

其中,xi分配变量,在本章试验中,我们取值为成功发送的数据包数量;n是参与分配的用户数。可见,公平性指数取值介于0和1之间;网络公平性越好,其取值越接近于1,当完全公平时,FI等于1。
此外,本章的所有网络仿真拓扑如图2所示。其中,源节点S1~S4的带宽均为10Mbps,其到路由器R1的传输延时为1ms;路由器R1到目的节点(路由)R2的带宽为1Mbps,传输延时为20ms。节点R1的队列长度为500个报文。
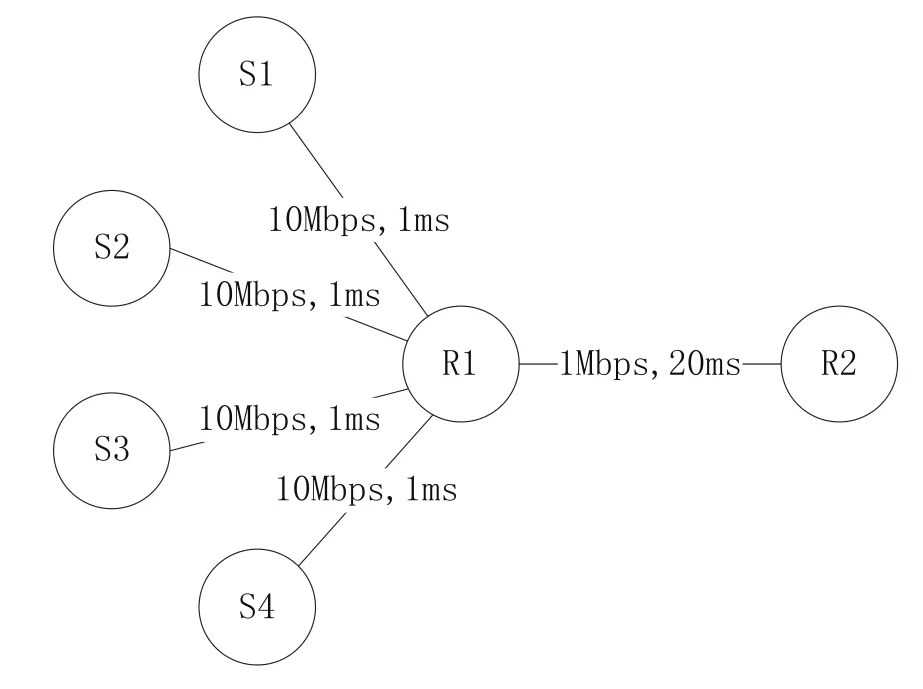
图2 网络仿真拓扑
仿真过程中,S1~S4节点主要使用了4个业务流,分别取名为FLOW_1、FLOW_2、FLOW_3、FLOW_4,前两者是基于TCP的业务流,而后两者则是基于UDP的业务流。其中TCP业务流采取Reno版本,它主要增加了“快速重传”与“快速恢复”算法,避免了网络拥塞不严重时采用“慢启动”算法而造成过大的减小发送窗口尺寸的现象。
模拟仿真总共进行100s,四个业务流实现的仿真场景如下所述:1、S1的FLOW_1业务流自0s启动至100s结束;2、S2的FLOW_2业务流自20s启动至80s结束;3、S3的FLOW_3业务流自0s启动自40s结束;4、S4的FLOW_4业务流自60s启动至100s结束。具体如图3所示。这主要是为了使得在每20s内网络业务流会出现不同的组成变化。本章所进行的所有仿真也都基于此场景。此外,通过实验表明,在20s间隔内网络大都可以趋于稳定。

图3 NS-2仿真场景
3.1 参数设定
通过多组实验综合分析比较,以及结合文献[2,7]对参数的设置建议,我们最终选择将其wq,minth,maxth,maxp分别设置为0.002,30,300,0.8,其中的将minth,maxth的计数单位分别统一为报文个数。
对于DF-RED的特有参数,通过实验我们发现将sample设置为队列长度的一半,即250;fairnessthresh, α分别设置为0.2,0.8是较为合适的。其物理意义为,当最大带宽流占用率与最小带宽占用率差为20%时,网络被认为有失公平性;而一旦某个业务流占用率突然超过整个网络业务流的80%时,则认为其已经对网络造成了严重影响。
3.2 非拥塞网络下实验对比
本仿真实验中,FLOW_1和FLOW_2都承载TCP应用,其TCP窗口大小为300,初始窗口为50,分组大小设置为500B;FLOW_3承载UDP应用,其分组大小为500B,发送速率恒定为0.7Mbps;FLOW_4也承载UDP应用,其分组大小为500B,发送速率恒定为0.2Mbps。因此,我们可以发现,在每20s的时间间隔内,虽然网络负载随着流的不同而变化,其中,除了在0s-40s时存在突发的大带宽占用FLOW_3流外,其余时刻始终仍能保障足够带宽来进行网络服务。
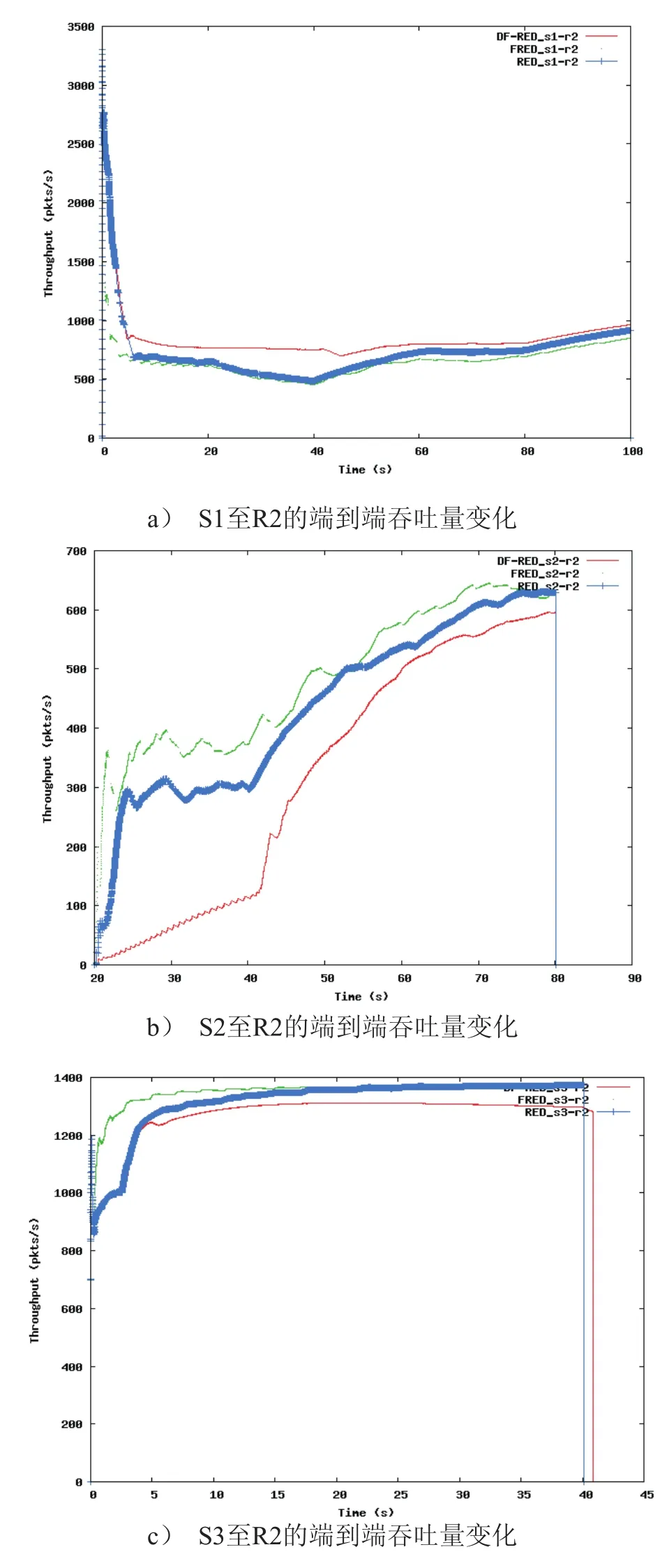
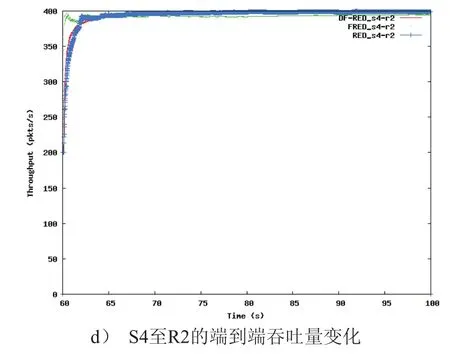
图4 DF-RED、FRED、RED的吞吐量对比
图4显示了在整个仿真过程中,各个时间段内,节点端到端的吞吐量变化。在0s-20s的时间段中,我们可以发现,在FLOW_1流与FLOW_3流并存,且FLOW_3占用了大量带宽的情况下,DFRED对此反应最为迅速,且保证了低带宽占用率的FLOW_1流有更高的吞吐量,同时,FLOW_3流吞吐量受到抑制,如图4a,4c所示。而在20s-40s阶段,链路中出现新的FLOW_2流,我们从图4b中可以发现,此时利用DF-RED算法的S2吞吐量上升速率最快,同时保持了非高带宽流FLOW_1的吞吐量(如图4a所示),同时继续抑制高带宽FLOW_3流的吞吐量,如图4c所示。在40s-60s,网络中只有FLOW_1和FLOW_2流,由于它们是完全相同的TCP流,并未丧失公平性,只有利用DF-RED可以使S2的吞吐量上升最快,而FLOW_1的吞吐量保持恒定,如图4a,4b所示。在之后的60s-80s中由于新的FLOW_4低带宽流出现,其吞吐量增加仍快于传统RED,如图4d。最后的80s-100s中,我们发现带宽完全满足时,利用DF-RED仍可保持网络吞吐量略高,如图4a,4d所示。
表1中显示的各个时间段对应的节点丢包率,从中我们可以看出,利用DF-RED算法可以对FLOW_3高带宽突发流起到更好的抑制,并更为有效的保护其他业务流,此外,我们还可以看出,在有足够带宽保证的40s-100s时间段上,DF-RED相比FRED和传统RED,在总体网络丢包率上都有大幅度降低。
而在公平性指数方面,DF-RED在0s-40s时间段上明显高于FRED和RED,可见它应对突发流时的表现较后两者都好,而在带宽充足的40s-100s时间段上,它们公平性相差不大。如表2所示。

表1 DF-RED、FRED、RED的各时间段丢包率对比
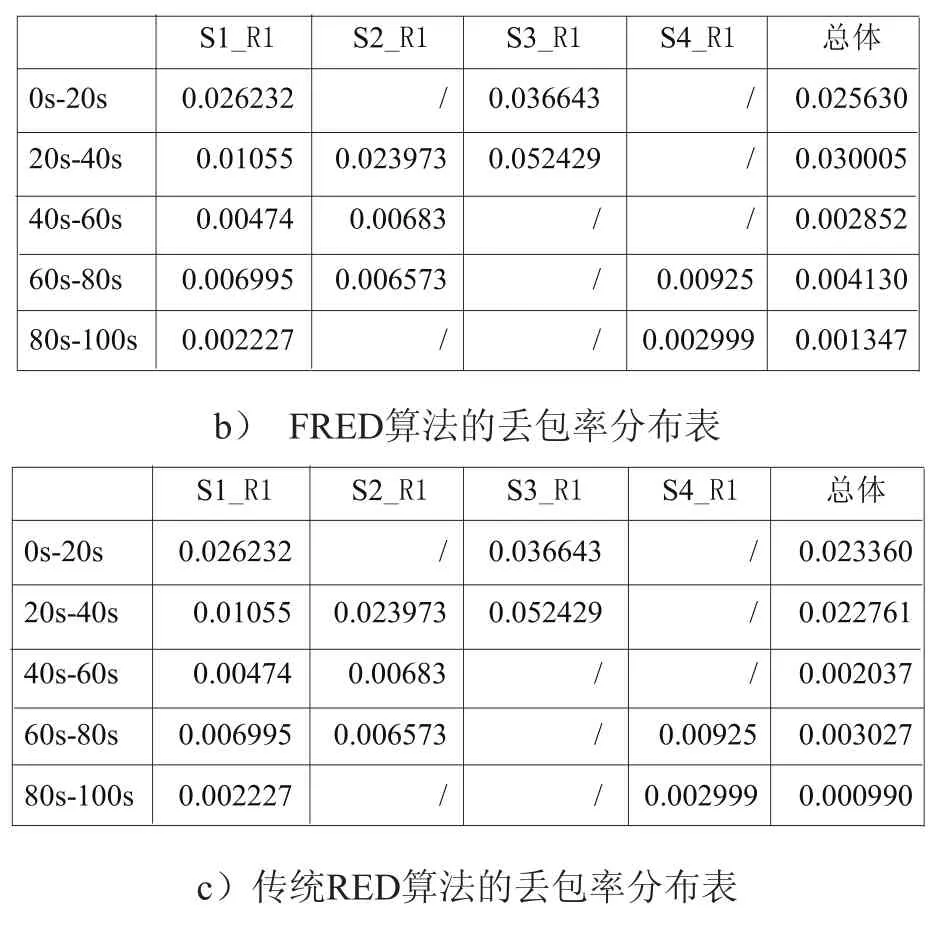
b) FRED算法的丢包率分布表c)传统RED算法的丢包率分布表
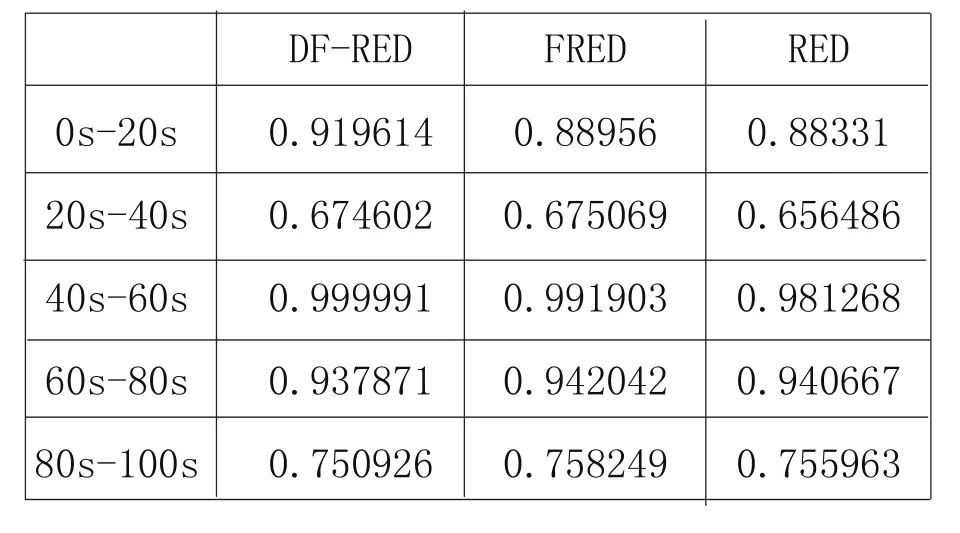
表2 DF-RED、FRED、RED的各时间段公平性指数对比
图5则显示了应用传统RED与DF-RED时的队列长度变化。其中我们可以看到,在存在突发流FLOW_3的情况下,DF-RED的缓冲利用率相比传统RED将更高,但也为此带来了一些不足:因队列长度增加而带来的网络延时变大。但是,如图5中40s之后曲线所示,一旦这类高带宽突发流消失之后,DF-RED算法也将使得队列长度迅速趋于平滑。


图5 传统RED与DF-RED时的队列长度变化比较
3.3 拥塞网络下实验对比
在本仿真实验中,我们同样是基于不同时间段的不同流构成变化进行分析,但与3.2不同的是,我们此次实验加大了所有流的带宽,试图在拥塞的网络环境下对DF-RED、FRED以及RED进行吞吐量和丢包率的对比。其中的FLOW_1承载TCP应用,其TCP窗口大小为1000,初始窗口为100,分组大小设置为500B;FLOW_2承载TCP应用,其TCP窗口大小为1000,初始窗口为100,分组大小设置为1000B;FLOW_3承载UDP应用,其分组大小为500B,发送速率恒定为0.5Mbps;FLOW_4承载UDP应用,其分组大小为500B,发送速率恒定为0.8Mbps。
图6显示了在DF-RED、FRED以及RED作用下的各个节点不同时间段的端到端吞吐量情况。其中,值得注意的是,在20s-40s时,由于FLOW_2流的出现,原来的网络变得更加拥挤,因此,虽然根据表2可以看出S1的丢包率有所下降,但其吞吐量也同样有所下降。但换来的是S2吞吐量的显著提升,如图6b所示。此外,通过图6d所示,我们可以看出,当FLOW_4流占用了大量网络带宽(0.8Mbps,500B)后,DF-RED算法相比RED和FRED有更好的抑制作用,从而保证整个网络中各个业务流的公平性。
另外,从网络丢包的情况看,我们可以发现,在TCP业务的FLOW_1和UDP业务的FLOW_2共存的0s-20s,DF-RED在保持平滑的平均队列同时(如图7所示),仍可以保证两个流更高的吞吐量和更低的丢包率。这主要得益于在DF-RED机制中,当公平性问题并不明显时,它将进一步降低包被丢弃的可能性,同时它也不区分UDP还TCP流。此外,从总体上说,即便是网络负载较大,DF-RED算法仍可保持较低的总体丢包率,如表3中所示。而在80s-100s这种存在高负载网络下的高带宽流情况下,DF-RED公平性指数明显高于FRED和RED,如表4所示。

图6 传统RED与DF-RED时的队列长度变化比较

表3 DF-RED、FRED、RED的各时间段丢包率对比

表4 DF-RED、FRED、RED的各时间段公平性指数对比
4 结束语
在本文中,我们通过对传统的RED 算法进行动态公平性的改进,相比FRED以及传统RED而言,它可以在保持有限时空开销同时,使其不论在拥塞还是相对宽松的网络情况下,都能更为有效的解决各个业务流之间的公平性问题,同时,还它还提高了网络吞吐量,并更低的节点丢包率。
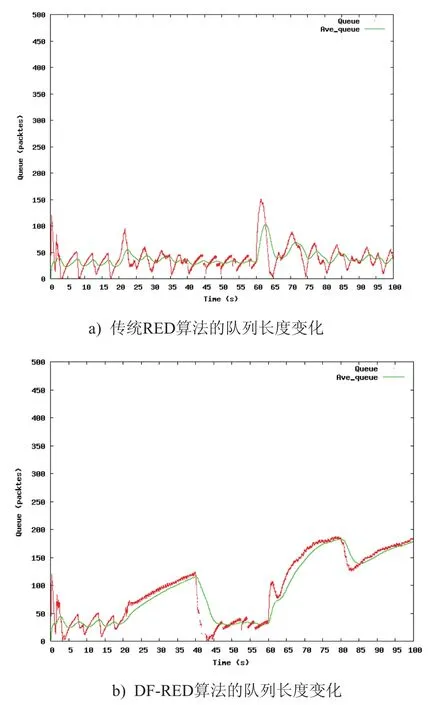
图7 DF-RED、FRED、RED的吞吐量对比
另一方面,在模拟仿真过程中,我们还发现了DF-RED在应对高带宽突发流时会有更高的缓冲利用率,但相比传统RED 和FRED则会增加网络延时。我们认为,这对于大部分实时性要求不高的网络应用来说,是可以接受的。下一步工作,我们主要是在有实时性要求较高的业务流共存情况下,如何保护这些实时业务流的问题进行研究,同时,我们还希望能更加精确的定义网络公平性的失衡。
[1] STALLINGS WILLIIAM,High-speed networks and Internets:performance and quality of service [M].Beijing:China Machine Press,2002.485-491.
[2] D LIN,MORRIS.Dynamics of Random Early Ddetection [C].SIGCOMM 1997:127-137.
[3] R PAN.B PRABHAKAR.K PSOUNIS.CHOKE.A Stateless Active Queue Management Scheme for Approximating Fair Bandwidth llocation[C].IEEE INFOCOM, March 2004.
[4] ION STOICA,SCOTT SHENKER, HUI ZHANG,Corestateless Fair Queue: Achieving Approximately Fair Bandwidth Allocations in High Speed Networks[J].IEEE/ACM Transactions on Networking,2003.
[4] R PAN,L BRESLAU,B PRABHAKAR,S SHENKER.Appro ximate Fairness Through Differential Dropping[C].ACM COMPUTER COMMUNICATION REVIEW, JULY 2003
[5] 高文宇,王建新,陈松乔.几种公平的主动队列管理算法的比较研究[J].微电子学与计算机,2005,22(7).
[6] FLOYD, SALLY;JACOBSON,VAN,Random Early Detection (RED) gateways for Congestion Avoidance[C]. IEEE/ACM Transactions on Networking 1 (4):397–413.
[7] The network simulator ns-2[EB/OL].http://www.isi.edu/nsnam/ns
[8] Step-by-Step Installation [EB/OL].http://www.cs.berkeley.edu/~istoica/csfq/step-by-step.html
[9] JAIN,R.,CHIU,D.M.and HAWE,W.A Quantitative Measure of Fairness and Discrimination for Resource Allocation in Shared Systems[C].DEC Research Report TR-301,1984.
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
计算机工程与设计(2022年3期)2022-03-22
计算机与数字工程(2022年1期)2022-02-16
农业工程与装备(2021年1期)2021-05-17
企业文化(2020年8期)2020-06-03
魅力中国(2019年6期)2019-07-21
中国信息化周报(2019年20期)2019-07-01
大科技·D版(2018年7期)2018-10-21
中小企业管理与科技·中旬刊(2017年7期)2017-09-08
铁道科学与工程学报(2015年4期)2015-12-24
