
基于RED技术的网络拥塞控制模拟
2011-07-03 08:58薛礼
制造业自动化 2011年24期
薛 礼
(湖北汽车工业学院 电信学院,十堰 442002)
0 引言
Internet进入90年代以来,用户数增长非常迅速,这促进网络应用向多元化方向发展,视频点播、多媒体会议、电子商务等新型的应用不断涌现,人们对Internet提供的带宽、服务以及安全性的要求也越来越高。但随着网络规模的扩大,随之而来的是Internet上流量急剧增长,其中除了传统的WWW、FTP、E-mail等数据流外,还出现了大量的实时多媒体数据流,由于网络中的多种数据流在路由器处交汇,因而给网络的路由节点造成很大的负担,严重时还能使整个网络系统发生崩溃。拥塞对Internet的威胁在其早期发展中就已经展露出来,1984年Nagle在其报告中提出了由于TCP连接中没必要的重传所引起的拥塞崩溃[1],这种现象在1986年至1987间发生了多次,严重时一度使LBL到UCBerkeley之间的数据传输率从32Kbps下降到40bps[2]。网络拥塞还容易造成延迟和延迟抖动等服务质量性能指标下降,是影响带宽、节点交换机缓存、吞吐量等网络资源利用率的关键因素。因此有效解决网络拥塞问题对于提高网络性能具有重要意义。
1 互联网拥塞控制策略概述
拥塞控制就是网络节点采取措施来避免拥塞的发生或者对拥塞做出反应[3]。根据拥塞控制的实施位置的不同,拥塞控制方法可以分为端到端的拥塞控制(End-to-end)和路由器拥塞控制(Routerbased)。端到端的拥塞控制在主机和网络边缘设备中,通过中间节点反馈的信息调整发送速率,使用的最广泛的是TCP协议中的拥塞控制算法,如TCP Tahoe,TCP Reno等。由于基于TCP的拥塞控制对具有相似的RTT时间、分组大小和拥塞程度的终端能够做出大致相似的响应,确保相似的应用能够获得大致公平的网络资源,具有公平性。但随着Internet上基于非TCP应用的数据流增加,端到端的拥塞控制对于一些诸如实时要求敏感的应用会不适用,在现在的网络拥塞控制中表现出诸多的不利因素,促使了端到端拥塞控制策略向基于路由器的拥塞控制策略的转变。
路由器拥塞控制在网络交换设备路由器中执行,目的是检测网络拥塞的发生情况以及产生拥塞反馈信息,常用的算法主要有传统的队列丢弃DropTail算法和目前研究的主动队列管理AQM算法。AQM在交换节点的缓冲溢出前就丢弃或标记分组,主动避免拥塞的产生,AQM的一个代表是随机早期丢弃(Random Early Discard, RED)算法,比常规的DropTail具有更好的性能。
2 RED算法性能分析
为了获得RED算法的相关数据,实验过程中采用NS网络模拟器模拟RED的工作,NS[5]全称是Net Simulator,即网络模拟器,是由美国DARPA支持的项目VINT(Virtual InterNet Tested)开发的通用多协议网络模拟软件。它能仿真一个网络的运行的全过程,在此基础上,可以把仿真的结果输出到一个trace文件中[6],通过对产生的trace文件的分析,可以了解网络的运行状况,从而分析网络故障以及产生的原因,进而对网络的拓扑结构、网络协议或相关算法等进行改进。
2.1 RED算法原理
RED算法在路由器中检测队列的平均长度,在拥塞即将发生时,按一定的概率丢弃进入路由器的数据包,这样就可以在拥塞发生之前及时通知发送端调整发送窗口大小,降低进入网络的数据流量,避免了拥塞发生之后丢弃更多的数据包。
运行RED算法的路由器的队列维持着两个参数,即队列长度最小阀值THmin和最大阀值THmax。RED对每一个到达的数据包都先计算平均队列长度Lav,若平均队列长度小于最小阀值THmin,则将新到达的数据包放入队列进行排队;若平均队列长度超过最大阀值THmax,则将新到达的数据报丢弃;若平均队列长度在最小阀值THmin和最大阀值THmax之间,则按照一定的概率P将新到达的数据包丢弃。
2.2 RED算法模拟
为了进一步说明RED算法较于其它算法的优点,使用了NS2做了RED及DropTail两种算法的模拟实验,网路模型采用经典双哑铃网络模型。通过NS2中的流监控对象来实现,打开一个文件用来记录一些统计数据,对于RED队列,记录两连接总的时延,两连接中总丢包数,两连接中总到达包数及两连接总共离开的包数用来计算链路丢包率、利用率和平均时延。同时计算出链路的吞吐量,并将它们的值写入相应文件中进行分析。在此基础上分析RED算法与DropTail算法的吞吐率及延时,并比较两种队列管理算法在路由器中性能。
2.3 RED算法分析
对于收集到的数据使用plot工具将数据画成相应图形进行各种分析,从而比较RED算法和DropTail算法之间的各种差异性。
1)图1是两种算法下吞吐率相对于不同缓冲区大小的仿真结果,红色代表RED,绿色代表DropTail。可以发现:瓶颈链路的吞吐量随着缓冲区容量增大而增加,但变化的幅度趋于平缓。当缓冲区大小超过一定值后,在相同缓冲区大小时,DropTail路由的吞吐量略高于RED路由的吞吐量,这说明当缓冲区容量不变时,将路由的队列管理算法由DropTail改为RED对吞吐量并没有改善。
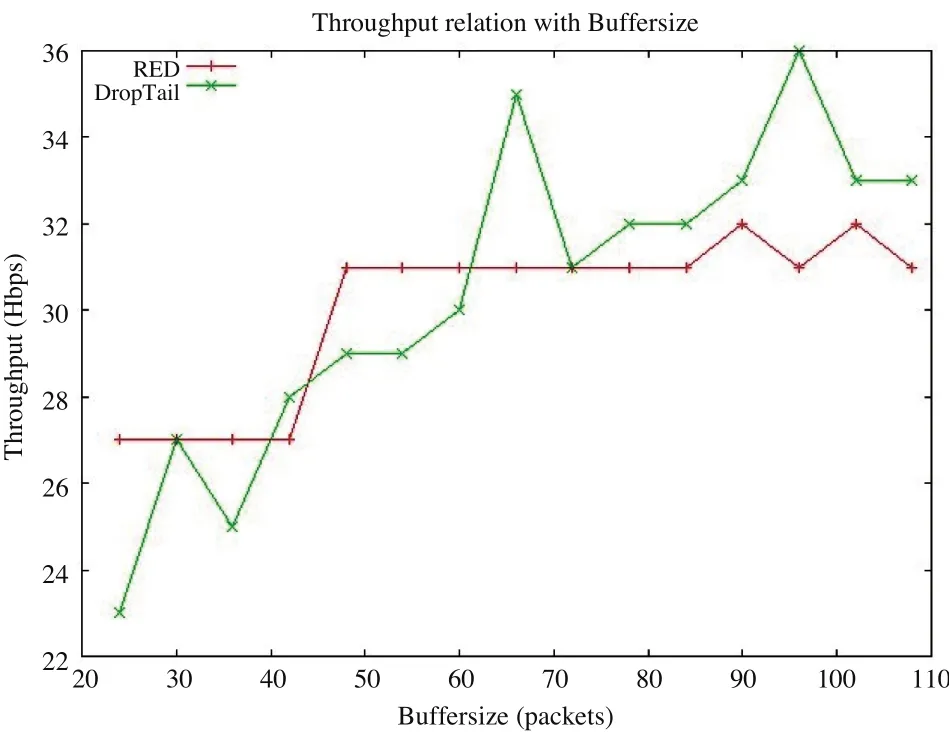
图1 DropTail和RED两种算法下的吞吐量比较
2)图2是两种算法下的延迟相对于不同缓冲区大小的仿真结果,分析可知,路由器中数据包的排队延迟随着缓冲区容量增大而增大,这是因为随着缓冲区增大,包在缓冲区中允许的平均队长增加,从而增大了路由器中队列排队时间。DropTail算法的增加速度很快,RED算法的增加较慢。在相同缓冲区大小时,DropTail路由的延迟高于RED路由的延迟。当缓冲区容量不变时,将路由的队列管理算法由DropTail改为RED对传输延迟有明显改善。
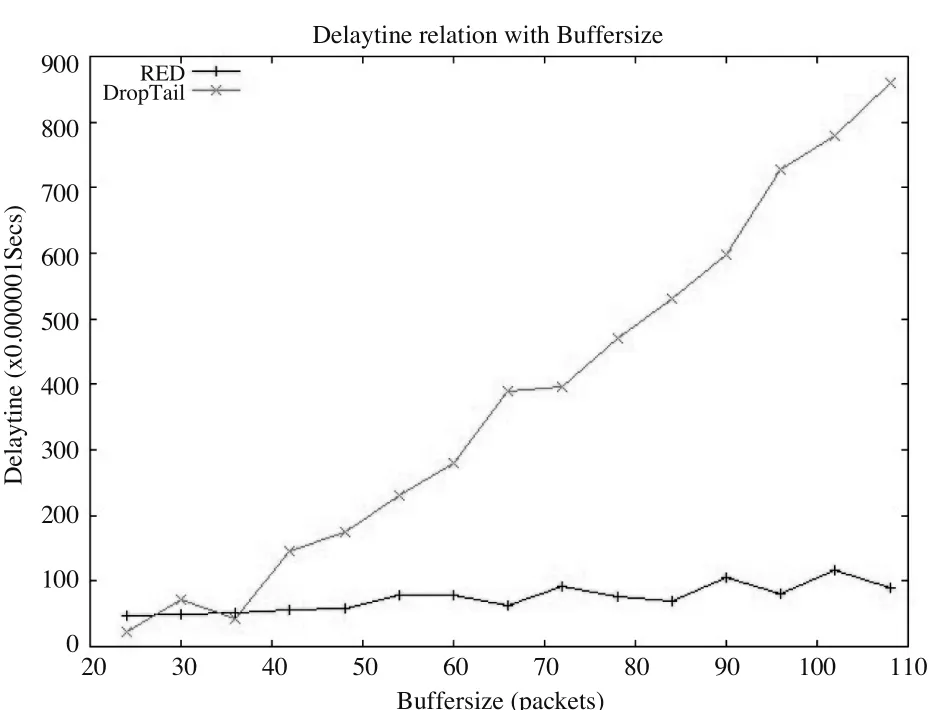
图2 DropTail和RED两种算法下的延迟比较
3)图3是两种算法下的路由器丢包率相对于不同缓冲区大小的仿真结果,分析可知从,当Buffersize<62以前,RED算法的丢包率大于DropTail算法,说明缓冲区比较小的时候,RED算法的优势并没有得到体现;但当Buffersize>62以后,RED算法的丢包率小于DropTail算法,而且随着Buffersize逐渐增大,RED算法的丢包率呈下降趋势,而DropTail算法丢包率变化趋势不确定,时而增加时而减少。通过分析可以看出,当Buffersize大于一定的数值后,RED算法的丢包率要小于DropTail算法的丢包率。
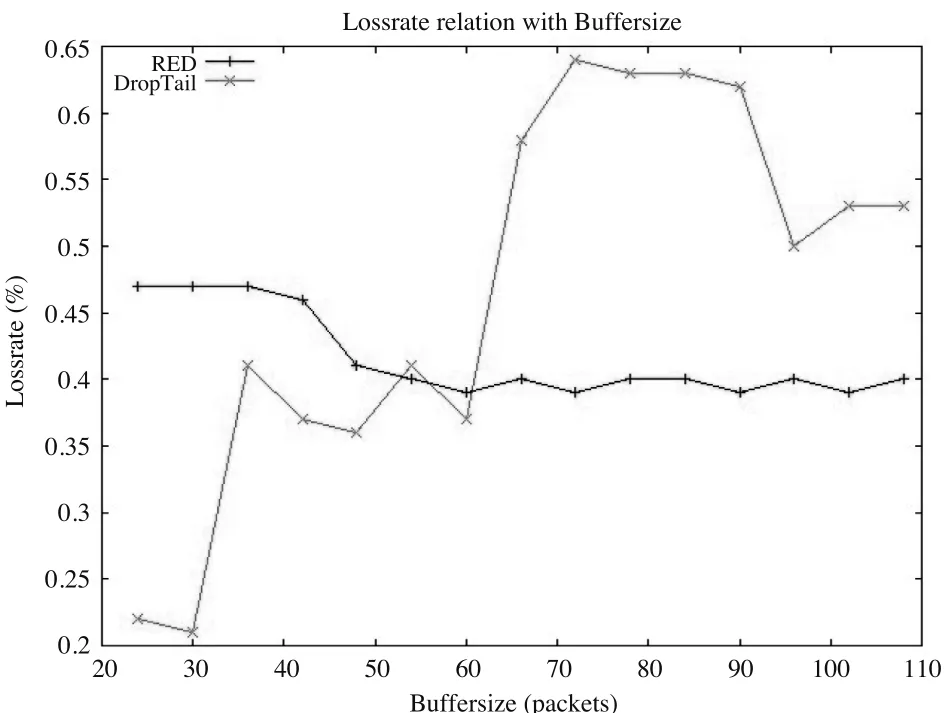
图3 DropTail和RED两种算法下的丢失率的比较
4)图4是两种算法下的路由器丢包率相对于不同缓冲区大小的仿真结果用率。分析可知,当Buffersize<54以前,RED算法的链路利用率小于DropTail算法,说明缓冲区比较小的时候,RED算法的优势并没有得到体现;但当Buffersize>54以后,RED算法的链路利用率大于DropTail算法,说明当缓冲区大于一定值之后,RED算法的链路利用率要高于DropTail算法。当缓冲区容量不变时,将路由的队列管理算法由DropTail改为RED对链路利用率有明显改善。
3 结束语
通过仿真试验分析了 RED 路由相对 DropTail路由对网络性能的改善。RED算法是基于路由器的更为有效的拥塞控制机制,通过仿真实验,总结出以下三点:
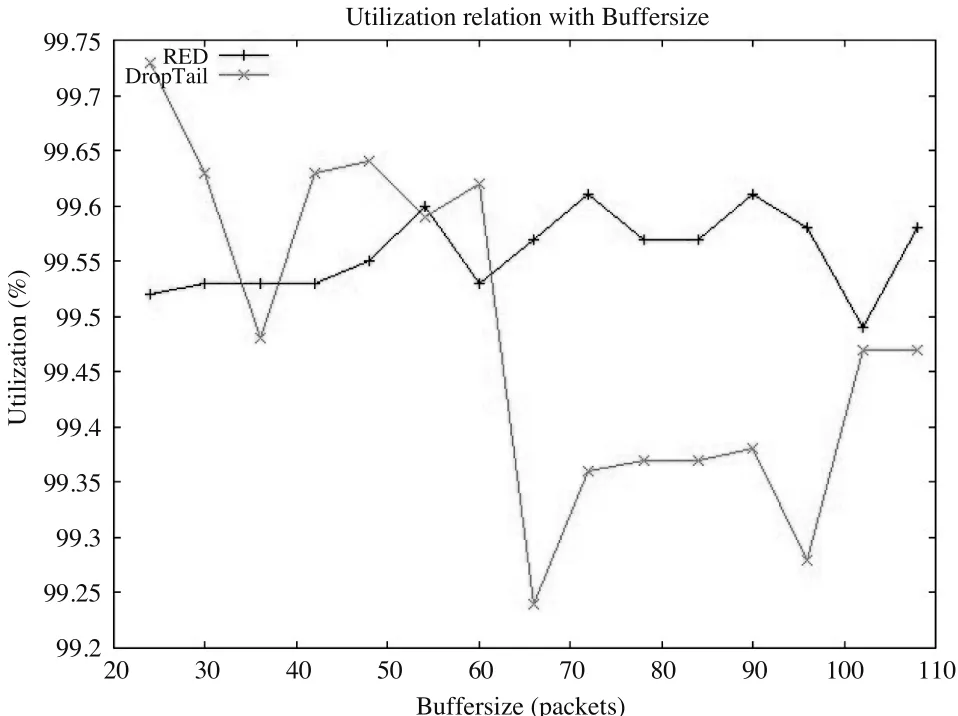
图4 DropTail和RED两种算法下的链路利用率的比较
1)当存在动态变化的负载时,RED 控制平均队长是很成功的:RED 在平均队长超过了最大阈值后就丢包,有效地控制了平均队长,限制了平均时延的大小,消除了对突发流的偏见。
2)RED 路由采用均匀随机分布丢包,在很大程度上缓解了 TCP 流的“全局同步”现象的发生。
3)RED 算法在不降低吞吐率的情况下可以大大降低传输延时,RED 路由的综合性能优于DropTail 路由的性能。
[1] Nagle, J. Congestion Control in IP/TCP Internetworks[J].RFC896, 1984.
[2] Jacobson,V. Congestion avoidance and control[J]. ACM Computer Communication Review, 1988, 18(4).
[3] Larry, L.Peterson. & Bruce,S.Davie. Computer Networks:A System Approach[M].Morgan Kaufmann Publisher,2000.
[4] Low, S.H. TCP congestion controls:algorithms and models[Z]. Tutorial Slides, 2000, http://netlab. caltech.edu.com.
[5] The Network Simulator:Building Ns[Z]. http://www.isi.edu/nsnam/ns/ns-build. html
[6] 徐雷鸣, 庞博, 等. NS与网络模拟[M]. 北京:人民邮电出版社, 2003.
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
计算机与数字工程(2022年1期)2022-02-16
农业工程与装备(2021年1期)2021-05-17
计算机系统应用(2018年3期)2018-04-21
北京航空航天大学学报(2017年5期)2017-11-23
商情(2017年1期)2017-03-22
建材发展导向(2016年2期)2016-05-19
中国工程机械学报(2016年5期)2016-03-07
铁道科学与工程学报(2015年4期)2015-12-24
电脑知识与技术(2015年24期)2015-11-17
